
基于多分支特征融合的密集人群计数网络
2024-03-21 02:01:02何立风张梦颖
计算机工程与设计 2024年3期
孙 爽,何立风,朱 纷,张梦颖
(陕西科技大学 电子信息与人工智能学院,陕西 西安 710021)
0 引 言
人群计数可以用于预测拥挤场景中人群数量和密度分布,有助于在人群拥挤场所下的人群管理和控制,在视频监控领域和公共安全管理领域都具有十分重要的应用价值[1]。
近年来,卷积神经网络被广泛应用于计数任务。MCNN[2]多列网络通过使用3个不同大小的卷积核来捕获不同的感受野以提取不同的尺度特征,得了不错的计数结果。但是当网络较深时,多列网络会导致更多的参数量和计算量,网络的训练难度较大。因此,Li等[3]提出了一种单列深层网络CSRNet,使用多个空洞卷积来提取多尺度上下文信息,在保留原图分辨率的情况下扩大模型的感受野,大大提高了人群计数精度。
然而,人头尺度多样性与复杂背景干扰等问题仍是人群计数任务的主要挑战[4]。以往方法在提取特征时,大多采用特征单向流动,并未充分利用网络浅层的细节信息与深层的语义信息,为了进一步学习到图像的尺度特征,同时排除复杂背景的干扰,本文提出了一种基于多分支特征融合的人群计数网络(multi-branch feature fusion network,MFNet),主要工作可以分为以下几个方面:
(1)提出一种多尺度特征增强模块(multi-scale feature enhancement module,MFEM)来提取连续变化的尺度特征,解决人群计数中的多尺度变化问题。
(2)提出一种多分支上下文注意模块(multi-branch context attention module,MCAM)来融合网络浅层和深层的特征,并使用注意力机制抑制背景噪声干扰。
(3)在3个公开数据集上进行训练和测试,本文提出的计数网络模型都表现出了良好的计数性能,验证了该模型的有效性。
1 相关工作
传统的人群计数算法可以分为基于检测和回归的计数方法[5]。基于检测的方法主要通过检测出图像中的单个个体并相加得到人群数量。该类算法在稀疏场景下的计数精度高,在密集的人群场景下性能较差。基于回归的方法可以分为基于数量回归和基于密度图回归[6]。基于数量的回归方法需要先从拥挤的图像中提取手工绘制的特征,然后利用回归函数来学习这些特征与人数之间的映射关系。提取的图像特征包括形状、大小、边缘等信息。使用回归函数如高斯过程回归、贝叶斯回归和线性回归等函数来回归拥挤图像中的总人数。然而,大多数基于回归的方法只提供了人群的数量而忽略了图像中人群分布的空间信息。针对上述问题,研究者提出基于密度图回归[7]的方法,通过使用人群密度图来表示图像中人群的分布信息,学习图像和密度图之间的映射关系。密度图既可以反映出人群分布情况,也可以得到人群数量,帮助我们获得更准确、更全面的信息,并大幅度提升了相关性能。
伴随着深度学习技术的进步,卷积神经网络(convolutional neural networks,CNN)也被应用于人群计数任务[8]。在人群计数领域,利用CNN生成人群密度图,密度中的每个像素表示该点周围区域内预测出现人物的密度估计值,然后对密度图进行逐像素求和获得图像中人群的数量。为了解决尺度变化问题,MCNN[2]网络通过设置多列不同大小的感受野来提取多尺度特征,计数准确性明显提高。在MCNN的基础上,研究者设计了一种多列计数网络Switch-CNN[9],该网络用一个密度分类器来为输入图像选择一个最优分支进行训练。由于多列网络中各列之间互相独立,缺乏关联,导致最终生成密度图质量不高。CP-CNN[10]通过融合从图像中学习全局和局部的上下文信息来获得高质量的人群密度图。Hossain等[11]提出的SAAN使用注意力机制自动选择全局和局部的上下文信息,人群计数精度进一步得到提升。然而使用多列网络存在参数量多、训练困难等问题,相比之下使用单列网络结构更简单,模型更容易训练。Li等[3]提出了一种单列深层网络CSRNet,该网络的特征提取部分采用VGG16的前10层,后端使用多个空洞卷积来提取多尺度信息,在保留原图分辨率的情况下扩大模型的感受野,提升了计数的准确性。Liu等[12]提出了一个上下文感知网络CAN,该网络可以自适应的预测人群密度所需要的上下文信息,减少了人头多尺度问题带来的干扰。Cao等[13]提出了一种尺度聚合网络SANet,它将多个不同尺寸的卷积核并联用于提取图尺度特征,并利用转置卷积来恢复图像的分辨率,从而生成高分辨率密度图。Gao等[14]提出的SCAR网络采用注意力机制来提取图像的像素级上下文信息和不同通道之间的特征信息,使模型在像素级水平上精确预测密度图。Shi等[15]提出的PA-CNN采用透视图和密度图相结合的方法生成高质量的密度图。PDD-CNN[16]通过金字塔空洞卷积模块来提取图像的多尺度信息生成密度图。这些方法都有着优秀的计数性能,但是在实际应用场景中,行人分布不均、复杂背景干扰、多尺度变化等问题仍是当前人群计数任务面临的挑战。
2 基于多分支特征融合的密集人群计数
2.1 网络整体结构
本文提出的基于多分支特征融合的密集人群计数网络(MFNet)的结构如图1所示。VGG-16[17]结构简单高效并且具有强大的特征提取能力,适用于准确快速的人群计数,本文采取VGG-16的前10层作为骨干网络,表1列出了VGG-16前10层的相关参数。同时本文在网络前端构建多分支上下文注意模块MCAM,使用一个自顶向下和自底向上的双向特征融合路径来提取网络不同深度的特征。在网络后端采用多尺度特征增强模块MFEM,通过密集残差连接的空洞卷积来应对人头尺度连续变化问题,提高网络多尺度特征信息提取能力,最后输出人群密度估计图,实现人群计数。

表1 VGG-16前10层相关参数

图1 MFNet网络结构
2.2 多分支上下文注意模块
网络浅层可以提取到图片的低级特征,例如边缘信息等;而网络深层则可以更好的提取高级语义信息[18]。此前多数研究进行特征融合时多采用单向特征流动的方式进行,这导致网络浅层与深层的特征不能被很好的利用起来。使用双向特征流动的方式进行特征提取,可以更充分地融合浅层与深层的特征,从而有效提高模型的性能表现。在目标检测领域中,研究者提出了一种自顶向下的特征融合策略即特征金字塔结构(feature pyramid network,FPN)[18],它能够整合不同尺度的特征图,使其同时具有深层的语义信息和浅层的纹理信息。受FPN启发,本文引入多分支特征注意模块,使用一个自顶向下和自底向上的双向特征融合路径来提取前端网络的特征。为了对多尺度变化的人头特征进行有选择性的加强,使用通道注意力和位置注意力来优化融合后的特征。如图2所示,MCAM模块将网络的浅层和深层特征结合起来,并分别通过位置注意力机制(position attention module,PAM)和通道注意力机制(channel attention module,CAM)进行特征加权,使得网络能够更好地注意到人头位置,以从主干网络中获取并融合足够多的特征。

图2 MCAM模块结构
2.2.1 双向特征融合路径
双向特征融合路径如图2所示。本文根据VGG16前十层的池化层位置将其划分为4个子模块,在文中分别用Conv1_1、Conv2_2、Conv3_3、Conv4_4来表示。为将网络深层的语义信息传递到网络浅层特征层,首先由Conv1_1、Conv2_2、Conv3_3、Conv4_4这4个特征层构造一个自顶向下的融合路径,由于经过最大池化后的4个特征图尺寸大小不一,Conv1_1、Conv2_2、Conv3_3、Conv4_4大小分别为原图的1/2、1/4、1/8、1/8,所以在构建融合路径时需要统一特征图尺寸。将Conv4_4与Conv3_3进行特征拼接融合得到特征图P2。将融合后的特征图P2采用双线性插值法进行上采样并与Conv2_2进行特征拼接融合得到特征图P3。同理,将P3进行上采样并与Conv1_1进行特征拼接融合得到特征图P4。
随后将网络浅层的空间信息传递到网络深层。将特征图P4进行下采样并与P3进行特征融合得到新的特征图Q2。将Q2下采样并与P2进行特征融合得到特征图Q3,将Q3与P1进行特征拼接融合得到特征图Q4,由此构造出一条自底向上的特征融合路径。将得到的特征图Q1、Q2、Q3、Q4进行特征拼接融合后最终得到一个同时具有高级语义和空间细节的特征图。
2.2.2 混合注意力模块
在实际的密度图估计过程中,往往会将一些杂乱的背景误识别为人群,影响了模型预测的准确性。在人群计数过程中,可以通过引入注意力机制帮助网络更加准确地关注图片重要区域和关键通道,增强特征表示,从而提高计数准确性[19]。Liu等[20]采用注意力机制获取特征图中的局部位置信息,但是忽略了特征通道之间的全局相关性。Sindagi等[21]通过注意力机制将前景和背景分割信息注入到计数网络中,但是没有考虑到图像中各个位置之间的关系。针对上述问题,我们提出了一个融合位置注意力和通道注意机制的混合注意力模块。
混合注意力模块如图2所示。首先将双向特征融合路径提取到的特征输入到位置注意力模块,经过3个1×1卷积层,然后通过重置或转置操作得到3个特征映射S1,S2和S3,其中 {S1,S2,S3}∈RC×H×W,C为特征映射的通道数,H×W表示空间维度。对S1和S2进行矩阵乘法和Softmax运算得到一个大小为HW×HW的空间注意力图Sa,其计算公式如式(1)所示
(1)

将得到的空间注意力图Sa和S3进行矩阵乘法操作,并将得到的特征图还原为原始输入特征大小C×H×W。最后用一个尺度参数λ对输出进行缩放,得到最终输出特征S,其计算公式如式(2)所示
(2)
式中:λ是可学习参数,其初始化为0并逐渐学习一个权值。
上述公式表明,输出特征S是注意力图和原始局部特征图的加权和,其中包含全局上下文特征,并且能够根据空间注意力图有选择的聚合语境。
同样,将双向特征融合路径提取到的特征输入到通道注意力模块。通道注意力的主要操作与位置注意力基本相同,不同的是通道注意力不需要通过卷积重新生成新的特征图,而是直接通过输入特征图F来计算通道注意力图Ca,其定义如式(3)所示
(3)

(4)
式中:μ为可学习参数,其初始化为0并逐渐学习一个权值。
位置注意力可以捕捉图像的全局位置的相关性,感知更广泛的上下文信息,从而增强局部特征表示。而通道注意力可以关注特征映射中不同通道之间的相关性,减少背景噪声引起的无用特征映射的影响。同时使用通道注意力机制和位置注意力机制,能够反映出通道和位置之间的依赖关系,提高模型的鲁棒性。
2.3 多尺度特征增强模块
上文所述的MCAM模块融合了网络的浅层和深层特征,在此基础上,本文通过设计多尺度特征增强模块(multi-scale feature enhancement module,MFEM)来提取密集人群的多尺度特征。该模块主要由3个具有不同空洞率的密集空洞卷积块(dense dilated convolution module,DDCM)组成,每个DDCM模块又由3个密集残差连接的空洞卷积组成。
MFEM模块结构如图3所示。多列的CNN方法由于列数有限,只能处理几种不同尺度的人群特征,本文针对多尺度变化问题采取一种尽可能密集的连接方式来捕获连续变化的尺度特征。DenseNet[22]中使用密集残差连接的方式将所有的网络层连接起来。网络的每一层都会接收前面所有层的输入,并将其进行串联,形成了一个多通道特征图,在每个层之间相互传递特征信息,这种方式可以使得不同层之间的信息传递更加充分,同时能避免梯度消失和参数过多的问题,提高模型的准确性。本文通过采用密集残差连接的方式来连接具有不同空洞率的空洞卷积以捕获更多的尺度特征,使得后续层的输入特征更加丰富,促进信息的连续传递,有助于网络更大限度的提取人头信息。
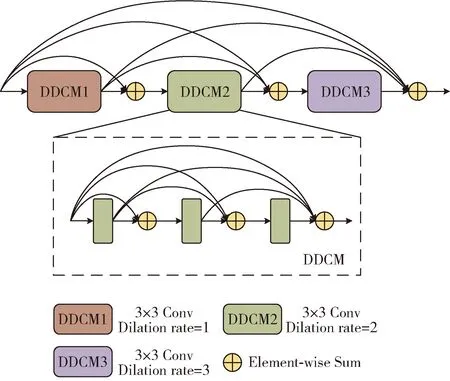
图3 MFEM模块结构
普通卷积使用池化层来增大感受野,同时也缩小了特征图尺寸,再利用上采样还原图像尺寸。而特征图在先缩小后放大的过程中会丢失一些细节信息,容易造成精度上的损失,从而导致还原的图像质量下降。相较于普通卷积,空洞卷积可以在不引入额外参数的前提下扩大感受野,同时又不丢失图像信息[24],因此空洞卷积更适用于人群计数。图4展示了空洞率分别为1、2、3的空洞卷积。

图4 空洞卷积
然而较大的空洞率可能会导致感受野增加过快,从而在人群密集区域出现网格效应,导致原始特征映射的局部信息缺失,对计数精度造成影响。为解决上述问题,同时考虑到密集场景下人头的连续尺度变化问题,本文选取3个空洞率分别为1、2、3的空洞卷积进行特征提取。为了让3个DDCM模块之间的特征被充分利用,产生更连续的信息传递,本文再次使用密集残差连接将DDCM模块连接起来,提取的特征尺度多样性进一步扩大。最后将MFEM模块提取的特征输入到由两个3×3卷积和一个1×1卷积组成的密度图生成模块来得到最终的人群密度图。
3 实验与结果分析
3.1 训练细节
实验基于Pytorch框架,在windows10系统下进行,训练时使用的GPU为NVIDIA GeForce GTX 3090。实验中使用Adam优化器对网络模型进行优化,用标准差为0.01的高斯函数随机初始化其它层,网络的初始学习率为0.000 01,衰减率为0.995,迭代次数为800,batchsize设置为1。
3.1.1 人群密度图的生成
为了生成高质量密度图,提高计数精度,本文采用自适应高斯核的方法生成标签密度图,自适应高斯核可以根据人头的尺度自适应的改变高斯核大小。对于人群相对稀疏的数据集如ShanghaiTech Part_B则采用固定高斯核来处理人群场景生成密度图。使用自适应高斯核的方法计算出真实人群密度图Yi,其表示为
(5)
式中:Gσi为高斯核滤波器,σi为高斯核大小,由k最邻近算法得出,δ(x-xi) 表示在像素点xi处的人头标注,di表示点xi和k个头部之间的平均距离,本文将k设置为3,β为0.3。最终生成的人群密度图标签如图5所示,从左到右依次为原图、人头位置标注图、人群密度图。

图5 人群密度图示例
3.1.2 损失函数
损失函数用于衡量网络输出与真实标签之间的误差。本文采用欧几里距离损失,其计算公式如式(6)所示
(6)

3.1.3 评价指标
本文采用平均绝对误差(MAE)和均方误差(MSE)来评估网络模型的性能,MAE反映计数模型的准确性,MSE反映模型的鲁棒性,其计算公式如下
(7)
(8)
其中,N为测试集中的图像数,yi为输入图像的预测人数,Yi为输入图片的真实人数。
3.2 实验结果分析
3.2.1 实验数据集
本文在常用的大规模数据集ShanghaiTech,UCF_CC_50和UCF-QNRF上进行实验。
ShanghaiTech数据集[23]分为Part_A和Part_B两个子集。该数据集共有1198张图片,330 165个注释头。其中Part_A由482张图片构成,这些图片是从网络上随机下载得到的,图片分辨率不统一。其中训练集有300张图片,测试集有182张图片。Part_B共有716张图片,图片来源于上海某街道的监控录像,图片分辨率为768×1024。其中训练集有400张图片,测试集有316张图片。其中Part_A数据集人群密度相对较高,Part_B部分人群密度相对稀疏。
UCF_CC_50数据集[24]是一个小样本数据集,其来源于网络上的图片,场景类型包含了音乐会、体育场等多个场所的图片。该数据集共有50张图片,图片分辨率大小不一,标记总人数达到63 075人,如片中的人群密度变化极大,人群数量从94到4543不等。实验过程中随机抽取其中40张图片进行训练,10张图片进行测试。由于该数据集样本数量较少,我们采用五折交叉验证的方法来评估模型。
UCF-QNRF数据集[25]由1535张高分辨率图片组成,包含多个视角、多种光线及多种密度变化的大规模场景。图片分辨率不统一,平均分辨率为2013×2902。该数据集人群密度变化较大,单张图片最大人数可达到12 865。其中训练集1201张,测试集334张。
3.2.2 结果分析
为了验证MFNet在人群计数任务上的有效性,本文在3个公开的人群计数数据集ShanghaiTech、UC_CC_50以及UCF_QNRF上进行了训练和测试,通过与近几年的先进算法进行对比,验证了MFNet计数性能的优越性,对比结果见表2。

表2 不同方法在多个数据集上的结果对比
由表2可知,本文提出的MFNet在3个数据集上都表现出了优秀的计数性能。在ShanghaTech数据集中,在人群密度较高的Part_A子集上实现了较低的MAE和MSE,分别达到了62.4和101.4。与经典的多列网络MCNN相比,MFNet的MAE和MSE分别降低了43.4%和41.5%,与经典的单列网络CSRNet相比MAE和MSE分别下降了8.5%和11.8%,但MSE比PD-CNN稍差。同时在人群相对稀疏的Part_B子集上也达到了最低的MAE和MSE,分别为7.9和11.7,与MCNN相比MAE下降了70.1%,MSE下降了71.7%,与CSRNet相比MAE下降了25.5%,MSE下降了26.7%。
在小样本数据集UCF_CC_50中,MFNet达到了与先前方法相比最低的MAE和MSE,分别为201.4和302.8。与MCNN相比MAE下降了46.7%,MSE下降了39.7%,与CSRNet相比MAE下降了24.3%,MAE下降了23.8%。
在场景丰富,人群数量差异较大的UCF_QNRF数据集上,本文提出的MFNet达到了最低的误差,其中MAE为105.5,MSE为182.8。与MCNN相比MAE下降了61.9%,MSE下降了57.1%,与CSRNet相比MAE下降了13.0%,MAE下降了12.1%。
上述实验结果表明本文提出的网络MFNet在人群不同拥挤程度的场景下均表现出优秀的计数准确率,并且在尺度变化较大、背景噪声干扰严重的情况下,MFNet也能够保持较高的计数精度。
图6展示了在不同数据集上的部分可视化结果。图中展示的4个场景包括了人群稀疏场景、人群密集场景和具有复杂背景干扰的场景,可以看出,在这些不同的场景下使用MFNet生成的人群密度图均能够估计出与标签人数接近的人群数量,再一次验证了MFNet的有效性。

图6 不同数据集生成的密度图
3.3 消融实验
为了验证MFNet中每个模块的有效性,本文在ShanghaiTech Part_B数据集上进行了消融实验,并将其对比结果列于表3中。

表3 Shanghai Part_B数据集的消融实验
首先在基线网络VGG-16上进行了训练和测试,并在其基础上分别增加MFEM模块和MCAM模块来验证两个模块的有效性。由表3可知,基线网络VGG16在ShanghaiTech Part_B上的MAE和MSE分别为11.2和17.1。在VGG16网络基础上增加了MFEM模块后,MAE和MSE分别为9.4和16.2,其中MAE较基线网络下降了16.1%,MSE较基线网络下降了5.3%,该实验验证了MFEM模块的有效性。在VGG16网络基础上增加了MCAM模块后,MAE为8.4,较基线网络下降了25%;MSE为15.5,较基线网络下降了9.3%,该实验验证了MCAM模块的有效性。最后在VGG16上同时增加MFEM模块和MCAM模块,最终的MAE和MSE下降了29.5%和30.4%,验证了本文所提的两个模块的有效性。其中,在加入MCAM模块进行训练之后,MSE明显降低,表明了该模块很好的提升了模型的鲁棒性。
上述消融实验验证了本文提出的两个模块都对网络性能有一定的提升,验证了MFNet合理性和有效性。
4 结束语
本文提出了一种基于多分支特征融合的人群计数网络,在网络前端利用自顶向下和自底向上的双向特征融合路径来促进浅层和深层特征之间的融合,并结合位置注意力和空间注意力加强人头信息的权重,增强网络的表征能力。在网络后端建立密集残差连接来提高多尺度信息传递能力。在3个公开数据集上的实验结果表明,与其它主流算法相比,所提方法具有更高的准确性和鲁棒性。但是在实验过程中发现该模型存在参数较多、计算量过大的问题,导致计数效率偏低,后续可引入轻量化的网络模型进行研究,以降低模型的复杂度和提高计数准确度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:20
中等数学(2020年8期)2020-11-26 08:05:58
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
数学小灵通·3-4年级(2017年11期)2017-11-29 01:35:42
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
