
基于SVDD与VGG的纽扣表面缺陷检测
2024-03-21 02:00:22樊鑫江杨大利侯凌燕
计算机工程与设计 2024年3期
樊鑫江,佟 强,杨大利,侯凌燕,梁 旭
(北京信息科技大学 计算机学院,北京 100101)
0 引 言
纽扣作为纺织品中重要的组成部分,其质量直接影响到服装的销售。纽扣生产过程会在其表面出现多种瑕疵,检测这些瑕疵是纽扣生产工厂在使用人工检测纽扣表面缺陷的主要部分,如何高效检测纽扣表面缺陷成为当下纽扣生产工厂的一个难题。目前已有多种基于图像处理的方法来解决该难题,已有方法[1-3]在检测纽扣表面某些缺陷上均取得了不错的效果,但其无法检测纽扣表面所有的缺陷类型,不具实用性。近年来,深度学习及卷积神经网络已广泛应用在表面检测[4-7],已有方法[8,9]虽然均可对表面缺陷进行检测分类,但工厂并不需要对缺陷进行分类、定位或提取。
结合以上所述,本文提出一种基于DEEP SVDD[10]模型,以改进VGG16为其特征提取网络的方法,比起传统的图像处理方法及新兴的深度学习方法,本文方法可同时检测出多种纽扣表面缺陷,且无需对缺陷进行分类、定位、提取。
本文的主要创新点如下:
(1)为满足纽扣表面检测的实时性要求,在每一层卷积层后引入BN层来加快网络收敛;
(2)针对使用原始VGG16作为模型特征提取网络时,模型对纽扣表面缺陷检测的性能不够高,在每一个卷积块后引入SE注意力模块提升网络的特征提取能力;
(3)针对模型太大参数过多,不适用于实际纽扣检测的问题,将VGG16三层全连接层替换为全局平均池化层(global average pooling,GAP),减少模型参数量,使模型更加健壮。
1 模型简介
1.1 DEEP SVDD模型简介
DEEP SVDD模型由一个深度自编码器及一个DEEP SVDD超球体组成,其中超球体使用改进VGG16训练而成。
1.1.1 深度自编码器
深度自编码器是目前主流的无监督方法之一,包括编码器(encoder)和解码器(decoder)两部分。其功能是通过将输入信息作为学习目标,对输入信息进行表征学习,常用于数据降维及异常检测。


图1 深度自编码器原理
1.1.2 DEEP SVDD超球体
DEEP SVDD模型从输入空间学习带有权重W的神经网络φ(·;W),继而输出空间F,试图将大多数数据网络表示映射到一个以中心c和最小体积半径R为特征的超球体中。正常样本位于球内,而异常样本位于球外,以此判断数据是否为正常样本或异常样本。DEEP SVDD的原理如图2所示。

图2 DEEP SVDD原理
DEEP SVDD模型根据数据的分布不同,可分为两种方法:①当训练数据存在极少量或没有异常样本时,方法为Soft-boundary DEEP SVDD(软边界DEEP SVDD);当训练数据全部为正常样本时,方法为One-class DEEP SVDD(一类DEEP SVDD)。

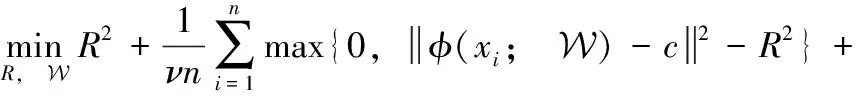

(1)
式中:c是超球体的圆心,R是超球体的半径;v是惩罚参数,n是样本数量,x1,…,xn代表样本数据;W为神经网络权重,φ(·;W) 为神经网络权重W的特征表示;λ控制正则化的权重;L为神经网络总层数,且∈{1,…,L},W为每一层的权重。
式(1),第一项最小化超球体的体积;第二项惩罚超球体外的数据;第三项防止网络过拟合。式(1)可得优化出的权重W*和超球半径R*,同时使得样本数据映射在超球体的球心附近,并允许一些点存在于边界之外。
就软边界DEEP SVDD算法来说,对于数据集X中的每一个待测样本x,将该样本映射到高维空间中,得到该样本在超球体空间的映射后,再计算该点到超球体球心的距离与球体半径之间的大小,以此作为该点的异常分数值s(x),如式(2)所示
(2)
一类DEEP SVDD:当所有的样本均为正常样本,DEEP SVDD 目标函数可简化为下式
(3)
式中:c是超球体的球心;n是样本数量;x1,…,xn代表样本数据;W为神经网络权重,φ(·;W) 为神经网络权重W的特征表示;λ控制正则化的权重;L为神经网络总层数,且∈{1,…,L},W为每一层的权重。
式(3)中第一项惩罚每个网络数据表示到超球体球心的距离;第二项防止网络过拟合。
就一类DEEP SVDD算法来说,对于数据集X中的每一个待测样本x,将该样本映射到高维空间中,得到该样本在超球体空间的映射后,再计算该点到超球球心的距离,作为该点的异常分数值s(x)
(4)
DEEP SVDD模型通过联合训练得出异常分数值,继而判断样本属于正常或异常样本。
1.2 VGG16简介
VGG由牛津大学在2014年提出,其中VGG16被广泛应用在图像分类与目标识别领域,因而本文中使用VGG16进行训练。VGG16采用3×3的卷积核来提取特征,与之前使用一个卷积核较大的卷积层的网络模型相比,VGG16使用多个较小卷积核的卷积层,不仅减少了参数,还增加了非线性映射,增强了网络的拟合能力。VGG16由13层卷积层和3层全连接层组成,每个卷积块之间由最大池化层相连。VGG16网络结构如图3所示。
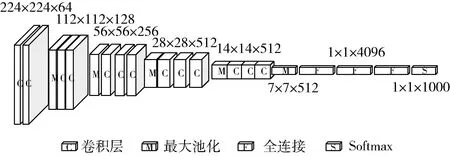
图3 VGG16网络结构
2 改进VGG16
针对原始VGG16模型复杂,网络参数量过多,训练时长过久,结合纽扣表面存在细小弱瑕疵难以检测等问题,如左侧中间有一处小划痕右侧字母R印成P等,纽扣表面细小弱瑕疵示例如图4所示。

图4 纽扣表面细小弱瑕疵
作出的改进见第2.1节、第2.2节、第2.3节。
2.1 卷积后引入BN层
卷积神经网络学习过程本质就是为了学习数据分布,随着网络层数加深,能够提取到的信息也越来越多,分类结果也越来越精准,但也伴随着风险,卷积层数的增加,训练时长也随着变长,过拟合风险随之增大,造成模型识别效果不好,网络泛化能力也随之降低;且模型训练时是将数据集分为多个批次(batch)进行训练,并非一次性全部训练完,每个batch输入一定数目的数据,当每批训练数据的分布差异较大时,网络就要在每次训练时去适应不同的分布,这样就会降低网络的训练速度,而实际生产检测中纽扣检测需要达到每秒几十个纽扣的速度,模型学习速度过慢会导致无法实时化,即无法投入实际使用。
为解决以上问题,对每一个卷积层输出的值进行规范化,使相邻两个卷积层的输入数据的分布相对稳定,使网络训练过程更加稳定,提高网络泛化能力[11],提高训练速度,达到纽扣检测的实时性要求。
2.2 引入SE注意力模块
SE注意力模块由Hu等[12]提出的注意力机制,且是目前主流的注意力机制之一。SE注意力模块是一种通道注意力,通过网络计算出输入图像各个特征通道的权重,从而实现对特征通道的校正,强调有用信息,剔除无价值的信息,提高特征表示能力,且该模块是一种轻量级的模块,可轻易地加入模型中,一般加在卷积块后,在模型上只增加少量的模型复杂度及计算量。SE模块的原理如图5所示。

图5 SE注意力模块原理
SE注意力模块主要包含Squeeze和Excitation两部分。
图5中,Ftr表示卷积操作;X表示Ftr的输入;U为Ftr的输出;C、W、H分别表示图像的通道数、宽度和高度;C′、W′、H′为Ftr之前的图像通道数、宽度和高度。
Ftr卷积公式如式(5)所示
(5)
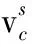
将生成的特征图U经过全局池化层Fsq压缩操作成C个维度为1×1的实数,Fsq操作如式(6)所示
(6)
为捕获通道之间的相关性,将压缩后的c个实数进行Fex激励操作,以W为参数为所有的通道生成权值,Fex激励操作如式(7)所示
Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(7)
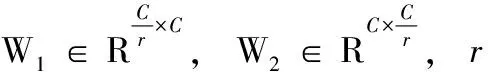
最后将激励层的输出作为衡量每个通道的重要性的参数,通过Fscale操作将该参数添加到各个通道的原始特征中,实现对原始特征权重的重新标定。Fscale的公式如式(8)所示
(8)
简而言之,Squeeze,即图中Fsq,通过在Feature Map层上执行全局池化,得到当前Feature Map的全局压缩特征量,1×1×C;Excitation,即图中Fex,通过两层全连接得到Feature Map中每个通道的权值,并将加权后的Feature Map作为下一层网络的输入。
在图像分类任务中,网络经常会因为对细小弱目标的漏检而造成整体正确率的下降,在纽扣检测中,有些瑕疵相较于纽扣本身,过于细小,肉眼难辨,结合其种类不同产生瑕疵也不同,造成模型检测精度不理想。
为解决上述问题,本文通过在网络中嵌入SE注意力模块,一方面对模型整体参数量影响不大,相对于原模型,加入SE注意力模块后的参数量及模型大小仅提升0.05%,另一方面提升网络的特征提取能力,使网络对纽扣表面的细小弱瑕疵更加注重,提高网络对这些细小弱瑕疵的检测能力,从而提高分类的正确率。VGG16改进前后参数及模型大小情况见表1。

表1 VGG16改进前后参数及模型大小
2.3 替换全局平局池化层
VGG16模型由13层卷积层和3层全连接层组成,总参数量为136 349 440,其中三层全连接层的参数量占总量89.21%,参数量过大,占用大量计算资源,降低模型学习速度,易过拟合,降低模型泛化能力。在纽扣实际生产检测环境中,工厂应用于纽扣检测的硬件设施往往不够好,此时若模型太大,不利于纽扣检测,影响检测的实时性和准确率。
为解决全连接层带来的负面影响,提高纽扣检测的速度,引入全局平均池化层,使用全局平均池化层代替VGG16中三层全连接层,大幅减少参数量,使得模型更加健壮,降低过拟合风险[13],同时也节省了硬件开支。由表1可知,将全连接层替换为全局平均池化层后,参数量和模型大小均下降了87.51%。
3 实 验
本文实验的硬件环境为CPUE5-26502.20 GHz,GPUTESLA P100,16 G,软件环境为Python 3.8.8,Pytorch 1.8.1,Cuda 11.1。
3.1 数据集
分别采集5种纽扣的正负样本作为实验数据集。其中训练集全部由正样本组成,测试集由剩余的正样本及负样本组成,其中测试集由300张正品及100张次品组成。负样本中包括划痕、内孔缺少/多、轮廓凸起、轮廓缺陷、字母漏印等。数据集分布见表2。

表2 数据集分布
其中Blue纽扣次品分别为内孔缺失、轮廓缺失;Gray纽扣次品分别为字母漏印、轮廓瑕疵;White1纽扣次品分别为内孔缺失、边缘缺失;White2纽扣次品分别为划痕、内孔缺失;White3纽扣次品分别为边缘瑕疵、内孔增多。正负样本例图见表3。

表3 纽扣正负样本示例
3.2 评价指标
本文引入ROC_AUC(receiver operating characteristic-area under the curve)作为模型的性能评价指标。AUC即ROC曲线下的面积,而ROC曲线的横轴是FPR,纵轴是TPR。真正率(True Positive Rate,TPR):所有真实类别为正的样本中,预测类别为正的比例,混淆矩阵见表4。

表4 混淆矩阵
结合表4可得式(9)
(9)
假正率(False Positive Rate,FPR):所有真实类别为负的样本中,预测类别为正的比例,结合表4混淆矩阵可得式(10)
(10)
AUC越大,越趋近于1,模型性能越好。
3.3 实验方案与流程
3.3.1 实验方案
本文对VGG16进行了3处改进,设计了3组实验分别验证改进的有效性。
(1)实验一:对比VGG16加入BN层前后AUC值及程序时长,检验BN层是否具有加快收敛,提高模型速度的功能;
(2)实验二:对比VGG16_BN在引入SE注意力模块前后的AUC值,验证SE注意力模块的有效性及对原模型参数量及大小的影响;
(3)实验三:将VGG16_BN_SE在替换全局平局池化层后,与替换前及传统单分类/异常检测方法IF、OCSVM、SVDD等对比其结果的AUC值及模型大小,检验模型是否能在保证AUC的前提下,降低模型大小。
3.3.2 实验流程
首先,使用正样本组成的数据集作为训练集进行训练,通过深度自编码器降维并求解出DEEP SVDD超球体的圆心及网络权重,再配合改进VGG16进行训练,将正样本紧缩在一个超球体中,测试时,使用正负样本组成的测试集,并通过训练出的模型测试得出每个样本的分数,不同类别的纽扣得出的圆心及半径各不相同,因此每个类别正次判断的标准并不一致,根据每个类别训练得出的圆心及半径数据,由异常分数判断纽扣是否合格。实验流程如图6所示。
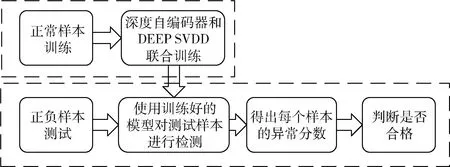
图6 实验流程
3.4 本文方法与其它单分类/异常检测方法比较
3.4.1 孤立森林(Isolation Forests,IF)
孤立森林是一种经典的异常检测算法,无需标签,属于无监督方法。孤立森林认为异常样本比正常样本少,特征差异较大,因此异常样本容易被孤立,孤立森林通过构建二叉树的方式孤立每一个异常样本,以此来判断样本正次。该算法具有线性时间复杂度和计算率高的特点[14]。
3.4.2 单类支持向量机(oneclass support vector machine,OCSVM)
OCSVM的基本思想是建立一个超平面,将两个类别以最大间隔分开,在正常数据点和原点之间具有最大间隔的方式来构造分离的超平面,一个新的数据样本如果位于边界之内,则将被分类为正常样本;反之,当其位于边界之外时被视为异常[15]。
3.4.3 支持向量数据描述(support vector data description,SVDD)
SVDD的基本思想是建立一个尽可能小的超球体,利用这个超球体去包含所有的数据,当要测试一个新的数据时,只需判断数据是在超球体内还是超球体外即可实现分类,与本文中DEEP SVDD方法原理类似,但SVDD为浅层方法。当SVDD使用高斯核时,SVDD与OCSVM等价,因此本文将OCSVM与SVDD视为一种方法。
3.5 结果与分析
VGG16改进前后程序运行时间,包括训练、测试时长、总时长,及平均每幅图像测试时间。由表5可知,在DEEP SVDD的两种方法ONECLASS及SOFT-BOUNDARY(以下简称SOFT)中,VGG16的训练时长最久,加入BN层后训练时长明显下降,引入SE注意力模块后,训练时长略微有所下降,替换全局平均池化层后,即本文方法,训练时长相较以上方法均有下降;平均每幅图像测试时间方面,表5各方法差距不大,均在4.5 ms/幅。VGG16改进前后程序运行时长分布见表5。VGG改进前后在DEEP SVDD两种方法的AUC值见表6。
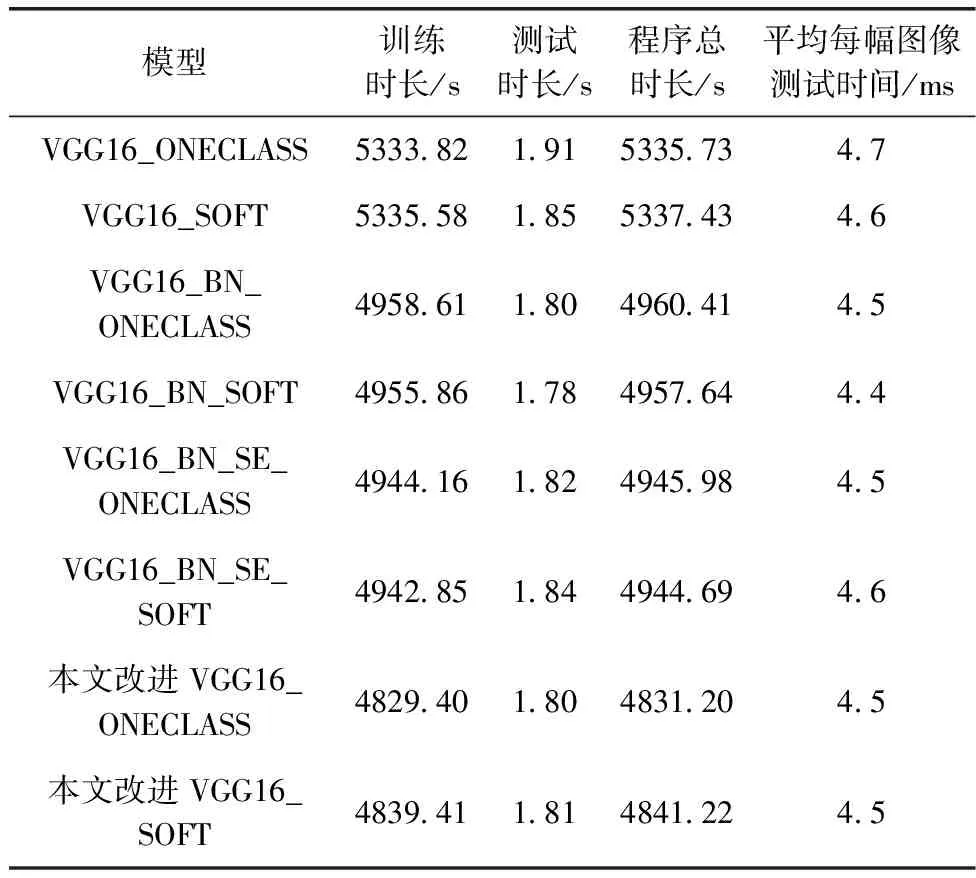
表5 VGG16改进前后程序时长对比

表6 VGG16改进前后AUC值
由表6可知,VGG16的平均AUC值分别为88.48%及90.83%;引入BN层后,5种纽扣的AUC值各有升降,平均AUC值变化不大;引入SE注意力模块后,5种纽扣的AUC值均有上升;本文改进VGG16在5种纽扣的AUC值相较于以上方法均有上升,其中SOFT方法平均AUC值在所有方法中最高。
3.5.1 实验结果
(1)实验一结果
由表5及表6可知,在网络中加入BN层,可以提高训练速度,加快收敛,但在AUC值上影响不大。
(2)实验二结果
由表6可知,在加入SE注意力模块后,模型对5种纽扣的AUC值均有不同程度的提升,平均AUC值分别提升7.28%、4.89%。结合表1、表5和表6可知,实验二验证了引入SE注意力模块一方面提高了AUC值,一方面只增加了少量了参数量及模型大小,仅为原模型的0.05%。
(3)实验三结果
由表5可知,将全连接层替换为全局平均池化层,降低了参数量,对模型训练速度有一定提升。单分类/异常检测方法AUC值见表7。

表7 单分类/异常检测方法AUC值
由表7可看出,IF、OCSVM、SVDD等浅层方法对纽扣的检测精度都不够高,其中IF平均AUC可达到89.72%。
结合表5、表6可知,使用DEEP SVDD模型时,5种纽扣的AUC值明显增加,其中改进VGG16在Blue纽扣上可达到100%的AUC,ONECLASS方法在White3类型纽扣上的AUC值超过了SOFT方法,在Gray、White1、White2这3种纽扣类型上,SOFT方法胜过了ONECLASS方法。且两种方法在5种纽扣均达到了96%以上的AUC,在平均AUC值方面,使用改进VGG16时的软边界DEEP SVDD算法效果最好,达到了96.73%,平均每幅图像测试时间仅需4.5 ms。
3.5.2 分析
结合表5~表7及实验一、实验二、实验三可得出结论,本文对于VGG16的3处改进,相较于原模型,收敛速度加快,程序运行时长减少,平均AUC值提高,参数量减少,模型大小降低。此外,本文方法在纽扣表面缺陷检测上的性能表现比单分类/异常检测方法要好。
通过对检测失败的纽扣图像进行观察发现,由于采集图像时没有使用固定光源,自然光源下中午及傍晚采集效果相差较大,导致部分正品纽扣图像被误检为次品,由此可知,工厂在使用机器检测纽扣表面缺陷时,需安装固定光源,保证采集到的图像不会因为光源问题影响检测结果。
4 结束语
本文针对人工检测纽扣效率低且无需对瑕疵分类的现状,提出一种基于DEEP SVDD与改进VGG16的纽扣表面缺陷检测模型。在VGG16模型基础上,为加快模型训练及收敛速度引入BN层;为增强网络特征提取能力引入SE注意力模块;为减少模型参数量,降低过拟合风险,替换VGG16的全连接为全局平均池化层。相较于VGG16,本文方法提升了模型的分类能力,此外,与传统单分类方法相比,本文方法的平均AUC值高于这些方法,在本文中实验平均AUC可达到96%以上,单张纽扣图像的检测时间为4.5 ms,满足实时性及精确度要求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
消费电子(2020年5期)2020-12-28 06:58:27
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
学生天地(2017年36期)2018-01-31 02:05:44
池州学院学报(2017年5期)2018-01-23 02:54:31
娃娃乐园·综合智能(2017年11期)2017-07-07 13:23:32
小学生作文(低年级适用)(2017年4期)2017-07-07 10:10:34
少儿科学周刊·儿童版(2017年3期)2017-06-29 17:15:38
Chinese Journal of Chemical Engineering(2016年10期)2016-05-26 09:28:34
