
基于CLIP与注意力机制的跨模态哈希检索算法
2024-03-21 01:59:50党张敏喻崇仁殷双飞张宏娟马连志
计算机工程与设计 2024年3期
党张敏,喻崇仁,殷双飞,张宏娟,陕 振+,马连志
(1.中国航天科工集团第二研究院 七〇六所,北京 100854;2.中国航天科工集团第二研究院 军代室,北京 100854)
0 引 言
跨模态数据所具有的高维、异构等特点使得检索过程耗费大量的时间和存储空间。如何提升跨模态检索[1]的检索效率并降低其存储消耗成为了目前学术界和工业界研究的重点。其中基于哈希码的跨模态检索方法由于其较低的存储消耗和快速的检索速度,成为了解决大规模跨模态数据检索的有效手段。
跨模态哈希检索[2]方法通过学习哈希函数将原始特征空间映射到低维的汉明空间,同时保持原始特征空间数据之间的相似性不变。跨模态哈希检索方法主要分为有监督的跨模态哈希检索与无监督跨模态哈希检索方法。现有的无监督跨模态哈希[3]方法更多关注哈希码的生成阶段,忽略特征提取阶段,导致检索性能受到影响。为解决上述问题,提出基于多模态预训练模型CLIP[4]与注意力融合机制[5]的无监督跨模态哈希检索算法CAFM_Net(CLIP-based attention fusion mechanism network)。
CAFM_Net主要贡献如下:
(1)使用CLIP提取原始样本特征,引入注意力机制加强显著区域的权重,弱化非显著区域的影响。
(2)设置模态分类器与特征提取器进行对抗学习,提取更丰富的语义特征,使不同模态特征与所生成哈希码语义趋于一致。
1 背景与相关工作
1.1 无监督跨模态哈希算法
现有的跨模态哈希方法主要有两大类:利用多模态数据已有标签的有监督方法和针对成对多模态数据的无监督方法。无监督方法因其标签的独立性而更具研究价值和应用前景。与以往的浅层哈希方法相比,基于深度学习的哈希方法[6]不仅提升了跨模态检索的效率和准确率,同时也提升了所生成哈希码的质量。因此深度无监督跨模态哈希检索吸引了广大学者的关注和研究。最具代表性的工作是深度联合语义重构哈希方法[7](DJSRH),此方法通过设计一种联合语义亲和矩阵来统一不同模态之间的相似性关系来重构多模态哈希矩阵。高阶非本地散列方法[8](HNH)则通过本地和非本地两个角度来考虑多模态数据之间的相似性关系,构建一个更全面的相似性矩阵。Hoang等提出了通过Transformer的无监督跨模态哈希检索方法[9]。使用Transformer提取模态特征挖掘模态内部的语义信息。尽管以上的方法都取得了不错的检索表现,但大多数方法不能有效的捕捉到不同模态之间的异质关联,忽视了模态内部的高阶语义相似性。
1.2 注意力机制
近年来,随着注意力机制在机器翻译和图像处理等方面取得的良好表现,注意力机制在工业界和学术界都得到了广泛的关注。注意力机制[10]通过关注大量输入中对于当前目标更关键的信息,减少对于其它信息的关注,过滤掉不相关的信息来解决信息冗余的问题,从而提高处理任务的效率和准确性。基于注意力机制的深度对抗性哈希网络[11]提出了一个带有注意力机制的对抗性哈希网络。该网络通过有选择地关注多模态数据中相关部分来提高内容相似性监测性能。自我约束的基于注意力的散列网络[12]提出了一种用于比特级跨模式哈希的方法。注意力引导的语义哈希采用了一种注意机制,该方法只关注相关的特征特性。它可以通过注意力模块保留不同模式特征中的语义信息,从而构建一个注意力感知的语义亲和矩阵。然而,无监督跨模态哈希检索[13]方面基于注意力机制的研究,仍然未广泛开展。
1.3 对比文本-图像预训练模型CLIP
CLIP(contrastive language-image pre-training)是一个采用图像-文本对进行训练的神经网络。CLIP采用对比学习的方式将图像和对应描述文本进行对比训练,最大化图像文本正样本的语义相似度以达到模态匹配的目的。CLIP模型普遍用于跨模态领域的数据预训练与特征提取。在CLIP模型出现后,一系列基于CLIP的下游任务都在相关领域取得了很好的实验效果。有学者提出了利用文字表述来对图像进行编辑的styleCLIP模型[14]。该模型借助CLIP模型“文本-图像”相关性能力和StyleGAN的图像生成能力,通过文本驱动生成图像。谷歌的研究人员提出了通过视觉和语言知识蒸馏方法建立ViLD模型[15],该模型将CLIP的图像分类模型应用到目标检测上。腾讯研究人员提出了CLIP2Video[16]模型,将CLIP模型从文本-图像拓展到文本-视频对,解决了视频文本检索问题。
2 CAFM_Net算法设计与优化
在本部分将详细介绍CAFM_Net设计的相关细节,包括以下几个方面:问题定义和符号、模型框架概述、目标函数与模型的优化。
2.1 问题定义与符号


(1)

2.2 模型框架
本文所提出的方法框架如图1所示,整体的模型由3个主要部分组成,分别是:深度特征提取模块、模态相似性增强模块以及哈希编码模块。

图1 CAFM_Net框架结构
2.2.1 深度特征提取模块
特征提取模块主要包括两个主要的网络:图像特征提取网络与文本特征提取网络。在本文中,对于图像采用CLIP编码器进行特征提取,其输出结果为Fv。对于文本模态,用Transformer编码器进行特征提取,其输出结果为Ft。同时设计模态分类器、特征提取器作为生成器,与特征模态分类器作为判别器进行对抗学习,使得公共特征空间中提取的不同模态特征趋于一致。v,t分别表示图像和文本的训练样本,θv和θt表示图像和文本特征编码的参数,用Ev和Et分别表示图像编码器和文本编码器,则Fv=Ev(V,θv),Ft=Et(T,θt)。
接着把提取到的图像与文本特征输入到注意力融合模块。计算模态间相关特征向量F=Fv·Ft。将相关特征向量F输入到以ReLU为激活函数的全连接层中得到注意力概率向量P=relu(F),分别计算得到注意力关联特征向量Z*=P·F*,其中*∈{v,t}。最后即可计算出注意力融合图像特征与文本特征
(2)
式中:μ为超参数。
2.2.2 模态相似性增强模块
2.2.3 哈希编码模块



(3)
使用哈希相似度矩阵与模态相似性增强模块构造的矩阵SM构建损失函数



Lintra表示模态内的损失函数,Lcross表示模态间的损失函数,⊗表示矩阵之间的点积计算,ξ是调节增强矩阵量化范围的超参数,m为每次训练的mini-batch中样本数。
2.3 目标函数与模型优化
在训练过程中,使用反向传播来迭代更新整个网络的参数,当整个网络趋于收敛,哈希重构阶段也将结束。整个过程中总的损失函数为
(4)
其中,超参数α和β分别起到调节模态内部和模态之间语义一致性的作用。在迭代过程中最小化损失函数即可以使得具有语义相似性的数据生成更加一致的哈希码。本文提出的方法通过注意力融合机制与对抗学习结合的方法有效捕捉原始数据中的共有信息,从而生成更高质量的哈希码。
由于二进制的哈希码不能直接通过深度神经网络进行优化。为了解决常见的梯度消失的问题,本文在生成哈希码的过程中使用了tanh函数,可以在反向传播的过程中能够很好地避免梯度为零的情况。在训练的过程中整个网络模型使用SGD算法和Adam算法进行优化。
算法1:CAFM_Net算法
输入:训练集Q,迭代次数σ,mini-batch数目m,哈希码长度K,超参数α,β,μ,ξ,γ,ε
输出:CAFM_Net的各项参数:θv,θt,θHv,θHt
(1)初始化迭代次数n=0
(2)重复
(4)随机选取数目m的图像-文本对作为训练数据。在图像上进行数据增强与归一化
(5)通过图像和文本特征提取网络提取Fv,Ft,计算相似度矩阵Sv,St
(6)通过模态相似性增强模块计算语义亲和矩阵SA与相似度增强矩阵SM

(8)使用Adam算法进行随机梯度下降
(9)直到网络收敛
(10)返回网络参数:θv,θt,θHv,θHt
3 实验与分析
为了验证CAFM_Net的有效性,本章选择3个典型的基于图像与文本的跨模态检索数据集,即MIRFlickr25k、NUS-WIDE和MSCOCO,来进行实验对比。本章节的所有实验均在一台主机(Ubuntu 14.04,Python 3.8,Pytorch 1.13)上完成。
3.1 数据集
3个数据集的对比见表1。MIRFlickr25k包含从Flickr网站收集的25 000个图像-文本对。该数据集每个图像-文本对使用38个类别标签进行标注,每幅图像具有多个类别标签。在本文中选取20 000对作为实验数据,选取其中2000对作为查询数据集,其余的用作检索数据集,训练数据需要再从检索数据集中选取10 000对。

表1 跨模态数据集对比
NUS-WIDE包含了从真实场景中收集的269 648个图像-文本对,该数据集总共包含了81个类别。选择了10个使用最广泛的标签和对应的180 000对数据。随机选取2000个样本作为测试集和5000个样本作为训练集。
MSCOCO包含训练集中约80 000个图像-文本对和验证集中40 000个图像-文本对。这些数据分属于80个类别。在本实验模型中选取120 000个作为实验数据集。并从中随机选择5000对作为查询数据集,其余的用作检索数据集。
3.2 评价标准
在本文中,通过两种常用的评价准则来评估本文模型的优劣:Top-N准确率曲线(topN-Precision,Top-N)以及平均准确率均值(MAP)。前一种方法基于汉明距离排序,后一种基于哈希表查找的方式。对于Top-N准确率曲线越高,检索方法性能越好。平均准确率均值是用来衡量每个查询样本在进行检索后的准确率平均值。
CAFM_Net的对照方法有传统浅层哈希方法和深度学习的哈希方法。并在多个哈希编码长度上与以往的算法进行比较。
3.3 实验设置
在实验中,使用CLIP与Transformer对图像和文本特征进行提取,构建不同模态的相似度矩阵。实验中将batch-size设置为32,使用动量为0.8,权重为0.0005的Adam优化器进行算法优化。对于3个数据集MIRFlickr25k、NUS-WIDE、MSCOCO,分别将μ设置为0.4,0.5,0.3,γ设置为0.3,ε设置为0.5,0.6,0.9。通过交叉实验验证将α设置为0.15,β分别设置为0.3,0.5,0.6。
3.4 实验结果与分析
表2展示了CAFM_Net与其它方法在MIRFlickr25k数据集上MAP值的对比。

表2 不同模型在MIRFlickr25k数据集上MAP值
由表2可知,随着哈希码长度的不断增加,在图像检索文本和文本检索图像的两个任务上,本文所提出的CAFM_Net相较于传统的非深度哈希方法IMH准确率分别至少提升16%与9%。与以往的深度哈希方法相比较性能提升较少。这是由于在训练过程中本文所选取的查询样本个数较少导致的。
表3展示了CAFM_Net与其它方法在NUS-WIDE数据集上MAP值的对比。
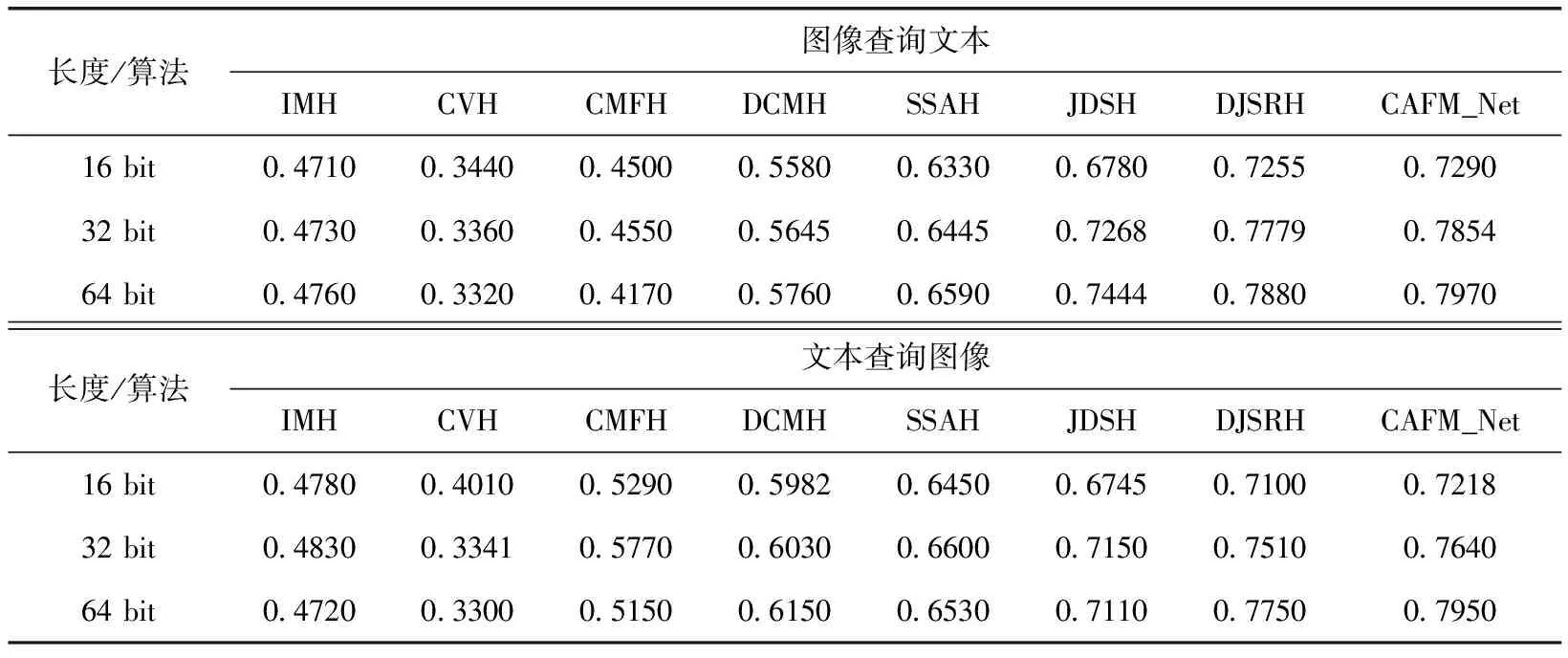
表3 不同模型在NUS-WIDE数据集上MAP值
由表3可知,在NUS-WIDE数据集上,CAFM_Net相比其它非深度哈希方法与深度哈希方法在MAP值上均有提升。在图像检索文本任务上CAFM_Net比性能最好的DJSRH方法MAP值在16,32,64比特上分别高出12.43%,10.75%,12.3%。在文本检索图像任务上,MAP值在16,32,64比特上分别高出11.12%,10.04%,12.50%。
表4展示了CAFM_Net与其它方法在MSCOCO数据集上MAP值的对比。

表4 不同模型在MSCOCO数据集上MAP值
由表4可知,在MSCOCO数据集上CAFM_Net相比于所有方法均取得了最佳的MAP值。
上述实验结果表明,在跨模态检索任务中深度方法的检索效果往往优于非深度方法。同时,随着哈希码长度的增长,检索的精确率也会更高。本文所提出的CAFM_Net算法在3个数据集上精确率均有所提升,说明了使用CLIP与Transformer分别对图像和文本进行特征提取并通过注意力融合机制后生成的哈希码能够更好挖掘原始样本的语义信息。其检索效率优于传统使用CNN和文本编码器进行特征提取的方法。
在数据集上对CAFM_Net与CVH、DJSRH的Top-N曲线进行对比,采用的哈希编码长度为32位。Top-N曲线检索样本数目从1~5000,反映了随着检索数量的增加,模型检索精度波动的情况。在两个查询任务上的结果如图2所示。

图2 CAFM_Net与其它方法Top-N曲线对比
从图中可以看出CAFM_Net方法在MIRFlickr25k数据集上的Top-N曲线明显高于其它的对比方法。
4 结束语
为解决无监督跨模态数据检索准确率低等问题,提出一个有效的基于CLIP模型与注意力融合机制的跨模态哈希检索算法CAFM_Net。使用CLIP和Transformer对图像和文本进行特征提取。使用注意力融合机制对模态间的样本特征进行融合找出模态间的共有语义特征,引入对抗学习的思想设计模态分类器,使公共特征中不同模态语义更趋于一致。相关实验结果表明,与现有的代表性哈希方法相比,CAFM_Net在3个数据集上检索效果均取得明显的提升。有效验证了该算法的准确性和鲁棒性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
电子制作(2018年19期)2018-11-14 02:37:08
传媒评论(2017年3期)2017-06-13 09:18:10
自动化学报(2017年11期)2017-04-04 02:52:58
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
噪声与振动控制(2015年4期)2015-01-01 07:08:21
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
