
含网关节点的高时隙复用率TDMA协议
2024-03-21 01:47张关鑫
计算机工程与设计 2024年3期
韦 亮,任 智,陈 凯,张关鑫
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
较于移动自组网,无人机自组网[1-7]的研究起步较晚。早期MAC层采用ALOHA协议,随后被载波侦听多路访问/冲突避免协议(carrier sense multiple access with collision avoid,CSMA/CA)取代,文献[8]对CSMA/CA协议的结构做了部分调整,但调整后仍不能满足无人机自组网的需求。文献[9]保证控制信息的及时交付,但其没考虑新节点的入网,灵活性较差。文献[10]采用定向天线,把每个节点的一跳邻域划分为完全连接的一跳邻域,在一定的程度下提高了时隙复用率,但该协议的帧结构较为复杂,且控制开销较大,并不适合无人机自组网。文献[11]中每个节点仅需要自己邻居节点的节点信息,不需要整个网络的拓扑和流量信息,因此降低了控制开销,但是由于无人机的移动性,使得天线难以实时校准。文献[12]提出一种基于闲置时隙预约传输机制的ISR-TDMA协议,但并未充分考虑业务优先级且灵活性不高。文献[13]动态地切换CSMA和TDMA状态,但仅适用于星型网络,仍不能较好满足无人机多跳网络的需求。文献[14]提出了一种双向管道TDMA协议,能够较好保障无人机节点在多跳网络场景中数据传输的可靠性,但也产生了一定的控制开销、部分信道资源的浪费和数据时隙冲突问题。文献[15]减少了现有协议的部分控制开销,改进了现有的TDMA协议在节点高速移动的情况下未及时更新时隙请求参数的问题,但也增加了节点时隙冲突的可能性。
为解决现有文献存在的问题,在文献[14,15]的基础上,提出了FU-TDMA协议。本文的贡献如下:①提出时隙请求时期快速收敛机制,对现有相关TDMA协议中的控制时期网络收敛慢问题进行改进;②空闲时隙公平重用机制,解决了现有相关TDMA协议中的中心节点时隙分配冲突的问题,提高了时隙的复用率;③一跳邻居多层次调度机制,保障了节点的公平性,降低了节点调度的时延性,增强了网络的可靠性。
1 网络模型、帧结构及问题描述
1.1 网络模型
网络拓扑如图1所示。由一个中心节点(central node,CN)、部分普通节点、个别网关节点(gateway node,GN)和一个地面站(ground station,GS)构成。CN负责在时隙分配时期广播全网时隙表;GN负责传递GS的指控信息给网络其余节点和把其余节点采集的数据信息发送给GS;普通节点负责数据的采集及其余信息的中继;GS负责控制空中无人机集群执行任务。

图1 网络拓扑
1.2 帧结构
协议的帧结构如图2所示。该帧结构由CMOP时期(CP)、Data时期(DP)和SMOP时期(SP)组成且各个时期长度受CN控制。在每个帧开始,CN在CP的第一个时隙广播新的时隙分配表,收到这个CMOP帧的节点更新自己在当前帧内新分配的时隙信息及梯度值(CN的梯度值为0,距离CN跳数为n跳的节点梯度值为n),然后在自己的CP时隙广播CMOP帧。在DP期间,节点根据在当前帧内的CP接收的时隙分配表,在自己的时隙传输上行监视、侦察数据和下行命令数据。在SP期间,节点发出SMOP帧,在自己的SP时隙传递自己的时隙请求和中继子节点的时隙请求;对于多个父节点存在的情况时,子节点依据上一帧收到的父节点的时隙请求消息,按照负载均衡的思想,选择目的父节点。在SP的竞争时期,用于处理新节点的入网请求及失败节点的重传。在CP期间,节点梯度值越大,时隙越靠前;在SP期间,反之。CMOP帧格式及SMOP帧格式如图3所示。

图2 帧结构

图3 帧格式
1.3 问题描述
(1)中心节点在全网广播CMOP帧之前(即在SP时期),其余节点会向中心节点发送SMOP帧用于申请时隙,其中申请的时隙信息包括节点自身和子节点的时隙请求。在此过程中,若网络节点数为N,SP时隙长度为L,因为在每个SP时隙,仅有一个节点占用该时隙并发送SMOP帧,那么SP时期则需要(N-1)*L个SP时隙。如图1所示,当节点信息传输满足一定范围互不影响时,带有粗线的节点9、节点11及节点13和带有粗线的节点4及网关节点就可以在两个SP时隙分别调度,因为在节点9、节点11及节点13同时发送SMOP帧时,不会产生冲突,不会造成节点重新发送时隙请求信息。此时原本需要5个SP时隙而现在仅需2个SP时隙就能把节点时隙请求传递成功,极大地节约了信道资源。在现有协议的标准中,由于在一个SP时隙仅由一个节点占用,浪费了大量的时隙资源,造成了网络在SP阶段收敛较慢。
(2)节点在发送SMOP帧时,采用单跳广播方式。节点梯度值小于SMOP帧字段Hop Count时,节点会聚合大于自身梯度值且与其为一跳邻居的节点发送的时隙请求消息,当部分节点存在多个小于其梯度值的一跳邻居时,节点广播SMOP帧,多个小于其梯度值的邻居节点都会中继其时隙请求。如图1所示,节点10广播时隙请求,节点5、节点6收到时隙请求信息并中继时隙请求信息。虽然现有的研究通过增加一个中继字段,采用负载均衡的方式,有效地解决了这个问题,但也增加了节点时隙冲突的可能性。在中心节点调度节点的时隙分配时,由于形成的拓扑存在偶尔不完整的情况,致使在拓扑图内三跳及以上跳数的节点在同一时隙发包时会产生冲突。如图1所示,节点2收到了节点5、节点6广播的时隙请求信息,因为节点5和节点6广播的时隙请求信息里都包括了节点10的时隙请求,然而节点2仅会留下节点10的一个时隙请求,在中心节点收到全网节点的时隙请求时,可能会误判节点10与节点5为一跳邻居而与节点6为3跳邻居或节点10是与节点6为一跳邻居而与节点5为3跳邻居,导致分配同一个时隙给节点10和节点5或节点10和节点6,发生时隙分配冲突。
(3)在竞争时期,节点调度形式过于单一化,时隙争用仅按照梯度值作为信道的访问优先级,极大可能存在部分同梯度节点同时发送SMOP帧,致使冲突,延长节点SMOP帧的重传时间,严重时可导致当前竞争时隙损坏,使得节点在下一帧无时隙分配。
2 FU-TDMA
针对上述问题,提出了FU-TDMA协议。该协议包含3个新机制:①时隙请求时期快速收敛机制,中心节点并行调度节点上传时隙请求,减少网络收敛时间;②空闲时隙公平重用机制,消除因中心节点维护的拓扑表不完整时所造成的冲突问题,挖掘出所有空闲时隙,提高信道利用率;③一跳邻居多层次调度机制,节点计算所有一跳邻居的优先级,使较高优先级节点先重传,降低碰撞概率。
2.1 时隙请求时期快速收敛机制
针对1.3节问题描述(1),本文提出时隙请求时期快速收敛机制。该机制的核心思想是:在SP阶段,考虑各节点控制时隙调度顺序。中心节点建立并维护全网拓扑后,制订一个用于触发部分节点并行调度的阈值,用于通知节点传递位置信息,然后再根据中心节点维护的包含位置信息的拓扑,采用基于距离的并行调度算法,快速地调度各节点控制时隙,以较短的时间获取全网拓扑及时隙请求信息。
2.1.1 基于距离的并行调度算法
基于距离的并行调度算法具体流程如下:
步骤1 从拓扑图中选出叶子节点及相连的父节点构建二部图G(v,e),记梯度值为奇数的节点集为V奇,梯度值为偶数的节点集为V偶,其中X∈V奇,Y∈V偶。
步骤2 根据形成的二部图,每个叶子节点计算与其余不相连的父节点的距离da→b,表示为
(1)

(2)
(3)
步骤4 在拓扑图中剔除筛选边的叶子节点,更新拓扑图。
步骤5 若在拓扑图中只剩下CN,则结束;否则,转步骤1。
2.1.2 时隙请求时期快速收敛机制具体流程
时隙请求时期快速收敛机制具体流程如下:
步骤1 在SP期间,由梯度值最大的节点发起时隙请求,该节点创建自己的所需时隙请求的聚合信息,广播SMOP帧。上层父节点收到子节点的SMOP帧后,更新自己的一跳邻居表,查看收到的SMOP帧里的ECG字段信息,将子节点发送的SMOP帧里的ECG字段的信息聚合在本节点待发送的SMOP帧里的ECG字段里,然后广播SMOP帧。
步骤2 CN收到所有下层普通节点发出的SMOP帧后,查看各普通节点的时隙申请信息并汇总创建维护全网节点拓扑图。根据其拓扑图的复杂程度及其规模来确定是否在当前帧内节点上传地理位置信息。若全网拓扑图还没到达阈值,继续执行步骤3,否则转步骤4。
步骤3 若不需要节点上传地理位置信息,在下一帧的CP,CN广播一个更新后的时隙分配图且在CMOP帧中的时隙分配字段按照节点梯度值顺序排列。普通节点收到CN发出的CMOP帧后,首先更新自己的一跳邻居信息表,然后查看自己申请的时隙位并在自己的CP时隙广播CMOP帧。转步骤1。
步骤4 若需要节点上传地理位置信息,在下一帧的CP,CN发放全网节点时隙分配图。其时隙分配图按照节点梯度值逆序排列,表明在当前帧的SP,如果各普通节点广播SMOP帧,不仅需要在ECG字段聚合子节点和自己的时隙请求信息还需要聚合当前所在的位置信息。然后节点在自己的CP时隙广播CMOP帧,转步骤5。
步骤5 各普通节点收到其由CN广播的CMOP帧,在当前SP,由梯度值最大的节点开始调度,向网络广播包含时隙请求和地理位置的SMOP帧。父节点收到子节点发送的SMOP帧,汇总自己的时隙请求、地理位置和子节点的时隙请求、地理位置,在自己的SP时隙广播聚合的SMOP帧。
步骤6 所有节点在SP期间上传地理位置,CN收到所有子节点发的SMOP帧。在形成新的全网拓扑图的基础上,CN根据各节点的位置信息,采用并行调度算法,在下一帧的SP,并行调度部分节点的时隙请求。
步骤7 CN按照所维护的全网拓扑图,在节点不冲突的情况下,计算普通节点SP时隙的分配。在下一个CP期间,CN广播CMOP帧,若其中时隙分配字段里节点时隙分配按照调度顺序顺序排列,则表明在当前SP,普通节点聚合的信息字段里,仍然需要包含节点当前所在的地理位置信息;如果时隙分配字段里的节点时隙分配按照调度顺序逆序排列,则表明在当前SP,普通节点不需要再上传自己当前所在地理位置信息。在时隙分配图中,节点ID、上行时隙和下行时隙顺序排列表示节点占一个调度时隙;节点ID、下行时隙和上行时隙逆序排列表示此节点同上一个节点一起调度。
步骤8 普通节点收到了CN广播的CMOP帧,记录自己的时隙信息,发现时隙分配图按照调度顺序顺序排列,继续在即将到来的SP聚合自己的位置信息;若发现时隙分配图按照调度顺序逆序排列,则在SP不聚合节点所在位置信息,并在自己的CP时隙广播CMOP帧。
步骤9 普通节点根据在CP时隙收到的CMOP帧里的时隙分配图的顺序,在SP时隙开始其节点的调度。并行调度的节点创建自己的时隙请求聚合信息,至SP结束。转步骤2。
基于上述方案设计的时隙请求时期快速收敛流程如图4所示。

图4 时隙请求时期快速收敛流程
2.2 空闲时隙公平重用机制
针对1.3节问题描述(2),为了充分地使用信道和消除中心节点分配时隙时导致的冲突问题,本文提出空闲时隙公平重用机制。该机制的核心思想是:CN根据分配给各个节点的时隙,详细地挖掘出每个节点的空闲时隙。针对空闲时隙,CN消除其中会致使冲突的时隙,进行公平的时隙分配。
空闲时隙公平重用机制具体步骤如下:
步骤1 普通节点在SP上传时隙请求信息且携带位置信息,SP结束,中心节点查看各节点的时隙请求。
步骤2 CN依据各节点时隙请求分配时隙。
步骤3 针对已分配的时隙,CN记录给每个节点分配的时隙ASk。
步骤4 对各个节点,计算各节点未使用的时隙NASk,则NASk表示为
NASk=Ttotal-ASk
(4)
Ttotal为数据时期的总时隙数。
步骤5 根据节点传递的位置信息,计算dk->i≤2R,找出该节点所有两跳内的节点,并求出节点可采用时隙PUSk。dk->i≤2R、PUSk表示如下
(5)
(6)


图5 两跳内邻居数计算

(7)
步骤7 对于两跳内节点共有的部分时隙,CN按照每个节点申请时隙权重的比值进行公平的分配,故所有时隙已完全分配。
基于上述方案设计的空闲时隙公平重用算法流程如图6所示。

图6 空闲时隙公平重用算法流程
2.3 一跳邻居多层次调度机制
针对1.3节问题描述(3),本文提出一跳邻居多层次调度机制。该机制的核心思想是:相邻的一跳邻居节点分别计算各自邻居的优先级,依据优先级的多样性,使优先级高的节点优先使用时隙,增强了网络可靠性。
考虑节点在竞争时期调度单一的问题,加入邻居节点请求时隙数量、子节点数量、平均时隙请求数量及子节点变化率(sub-node change rate,SCR),多层次调度节点争用顺序,保证各节点公平性。一跳邻居多层次调度机制具体步骤如下:

(8)
其中,Nrn为节点n的一跳邻居集、Subk为节点k的子节点集。在竞争阶段,对于邻居节点时隙请求数量、邻居携带子节点数量及平均时隙数量较大的邻居节点优先级更高,这些节点可以获得较低的端到端时延,从而降低整个网络的时延。

(9)
子节点变化率反映了邻居节点部分的拓扑变化状况,变化率越大,说明拓扑稳定性较差,对于变化率较小的优先级越高,可以减少节点因为不稳定因素导致的数据丢失,提升网络稳定性。
步骤3 在竞争阶段,一跳邻居节点内优先级表示为
(10)
步骤4 在一跳邻域内,节点按照梯度值和Pk的大小及优先级大小对时隙争用,梯度值越大节点优先争用,同梯度值节点,Pk越大的节点在竞争阶段优先争用。
基于上述方案设计的一跳邻居多层次调度算法流程如图7所示。

图7 一跳邻居多层次调度算法流程
3 仿真验证
本文使用OPNET14.5通信网络仿真软件,对比CSMA协议、BiPi-TMAC协议、ERMH-TDMA协议以及FU-TDMA协议的性能,分析仿真结果。
3.1 仿真流程
(1)设置MAC层进程模型及应用层模型。其中MAC层进程模型包括INIT、CMOP、Data及SMOP状态机,用于完成初始化和时帧的控制信息及业务信息传输;应用层模型包括Sink和Source模块,用于数据包的发送与接收。
(2)设置节点模型。物理层采用全向天线,网络层采用OLSR协议,传输层采用透传模块。
(3)设置网络模型。4种协议采用一样的场景,中心节点处于网络中心,其余普通节点围绕中心节点层层摆放,地面站与网络边界的网关节点通信。
(4)收集所需的统计量。
(5)仿真结果分析。对收集的统计量进一步分析,得出吞吐量、数据传输时延及时隙利用率。
3.2 仿真参数设置
仿真参数设置见表1。

表1 主要的仿真参数设置
3.3 仿真结果分析
本文通过以下性能指标来验证网络性能:
(1)SP时期网络收敛时间:全网节点在上传SMOP帧至中心节点所需的总时间。
(2)数据传输平均时延:数据包从源传输到目的地的平均时间。
(3)数据传输成功率:目的地收到的数据包与源产生的数据包之间的平均比值。
3.3.1 SP时期节点收敛时间
图8为不同网络规模下FU-TDMA、ERMH-TDMA、BiPi-TMAC和CSMA协议的SP时期网络收敛时间对比。由图可知,随着节点个数增加,SP时期收敛时间逐渐增大,这是因为更多的节点上传时隙请求。仿真结果表明,在节点数低于7时CSMA在SP时期是最快收敛的,但是随着节点数的增多,导致SMOP帧的数量增多,从而导致无线信道中碰撞概率增大,因此在节点数8及其以后网络的收敛时间是偏高于另3种协议。ERMH-TDMA与BiPi-TMAC收敛时间一致,其原因为:在SP时期中心节点会给各节点分配一个不同的SMOP时隙(分配的总时隙数为节点数减一)。在节点数为30时,FU-TDMA相比于ERMH-TDMA和BiPi-TMAC下降了17.2%,其原因为:FU-TDMA的时期请求时期快速收敛机制采用基于距离的并行调度算法相比于ERMH-TDMA和BiPi-TMAC的每个节点分配一个不同的SMOP时隙的方式,FU-TDMA在一个SMOP时隙并行调度节点上传时隙请求信息,因此收敛更快。注意在节点数25时,FU-TDMA相比于ERMH-TDMA 和BiPi-TMAC降低了20.8%,比节点数30时更小,这是因为基于距离的并行调度算法计算的结果不一定是全局最优的,但整体而言FU-TDMA的收敛时间低于ERMH-TDMA和BiPi-TMAC。

图8 SP时期网络收敛时间
3.3.2 数据传输平均时延
图9为节点数20时,3种协议的数据传输平均时延对比。由图可知,随着节点速率的增加,端到端时延逐渐增大,这是因为节点移动过快,导致链路稳定性下降,从而导致部分帧重传。上行端到端时延与下行端到端时延有显著差距是因为上行优先级高于下行,可能会导致部分节点上行数据队列更长。况且时隙请求大小与队列长度成正比,这使得节点为上行业务存储更长的时间,从而增大了下行业务的传输时延。仿真结果表明,在上行端到端平均时延中,BiPi-TMAC较CSMA下降了32.2%~36.1%,ERMH-TDMA较BiPi-TMAC下降了3.2%~4.7%,FU-TDMA较ERMH-TDMA下降了5.5%~8.9%;在下行端到端时延中,BiPi-TMAC较CSMA下降了47.1%~50.8%,ERMH-TDMA较BiPi-TMAC下降了2.6%~7.7%,FU-TDMA较ERMH-TDMA下降了4.5%~11.1%。主要原因有如下3点:①CSMA通过竞争的方式争用信道,随着节点移动性的增大,使得业务在队列里持久堆积,所以端到端时延较大,且调度类的BiPi-TMAC有时隙的分配,所以时延较小;②ERMH-TDMA相比于BiPi-TMAC及时更新节点时隙请求信息,减少重传次数及丢包率,从而降低了时延;③FU-TDMA相比于ERMH-TDMA采用“SP时期快速收敛”新机制,中心节点基于距离的并行调度算法,使得网络在SP时期快速收敛,缩短时帧长度,从而导致中心节点更新拓扑快,增强链路的实时性,可有效降低时延;采用“空闲时隙公平重用”新机制,消除了中心节点调度节点时隙时产生的冲突问题,使节点充分公平地利用时隙,提高了时隙复用率,减少了数据和指控业务的排队时延,增加了网络的吞吐量;采用“一跳邻居多层次调度”新机制,让优先级高的节点优先争用竞争时隙,防止因节点调度太过单一造成碰撞,降低了节点重传和节点入网的时延。
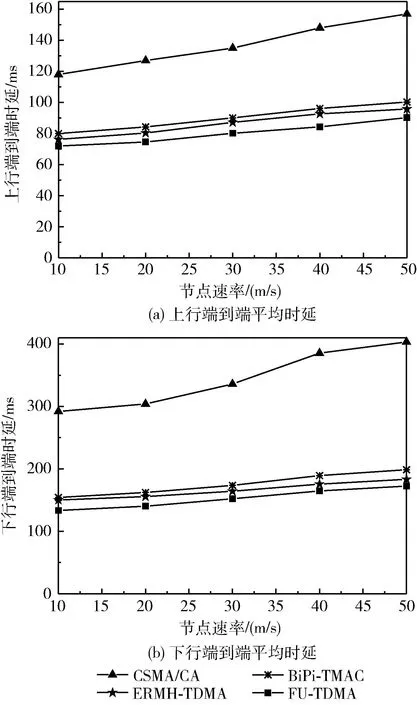
图9 数据传输平均时延
3.3.3 数据传输成功率
图10为节点数为20时,数据传输成功率在不同的移动性下的映射。因为节点移动性越高会导致节点邻居关系变化越快,丢包率越大,所以随着节点移动性的增加,4种协议的数据传输成功率呈下降趋势。由图可知,BiPi-TMAC较CSMA成功率提高了7.2%~17.3%,ERMH-TDMA较BiPi-TMAC提高了0.9%~2.1%,FU-TDMA较ERMH-TDMA提高了2.2%~3.9%,其原因为:①由于节点移动性,相对于CSMA,调度类的ERMH-TDMA、BiPi-TMAC和FU-TDMA协议有动态分配的属于节点的时隙,且在SMOP时期紧随一个竞争时期,所以具有更高的可靠性;②相比于BiPi-TMAC,ERMH-TDMA降低了时隙请求的开销,实时让节点更新拓扑,提高了时隙请求成功率,从而提高了数据传输成功率;③FU-TDMA相比于ERMH-TDMA,使得网络快速收敛,缩短了时帧长度,提高了拓扑更新频率,链路实时性更高,从而提高了数据传输成功率;解决了时隙复用导致的冲突问题,提高了时隙复用率,增强了网络可靠性,从而提高了成功率;通过在竞争阶段,计算一跳邻居优先级,降低了节点的碰撞率,增加了时隙请求成功率,进一步增强网络可靠性,从而提高成功率。

图10 数据传输成功率
4 结束语
针对无人机自组网控制时隙收敛慢,时隙冲突,时隙未充分利用及SMOP帧重传易碰撞等问题,提出了一种名为FU-TDMA协议。机制一中心节点通过维护的全网拓扑图,依据位置信息计算并行调度的节点。机制二中心节点消除了时隙分配时产生的冲突问题,挖掘出浪费的时隙并对此时隙公平的利用。机制三普通节点计算自己一跳邻居内节点的优先级,降低了碰撞概率,保证了更高的可靠性。仿真验证了FU-TDMA协议的有效性,可应用在无人机移动场景。在未来的研究中,可针对TDMA协议仍然存在的问题,深入挖掘时隙的复用性,进一步提高网络性能。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
应用数学(2020年2期)2020-06-24
电子制作(2019年23期)2019-02-23
数学年刊A辑(中文版)(2018年2期)2019-01-08
测控技术(2018年6期)2018-11-25
铁道通信信号(2018年9期)2018-11-10
舰船电子对抗(2016年3期)2016-12-13
广西大学学报(自然科学版)(2016年5期)2016-11-12
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
