
基于虚拟模型重建与智能校核的电力工程数据处理技术研究
2024-02-27 12:17彭露苇李寿山张四江岳铁军王亚丽
电子设计工程 2024年3期
彭露苇,李寿山,张四江,岳铁军,王亚丽
(国网甘肃省电力公司建设分公司,甘肃兰州 730050)
推进电力工程建设是国民经济发展的重要保障,但该工程具有实施周期长、投资成本大及建设环境复杂等特点。因此,如何通过有效的管控手段保证电力工程造价的科学性与合理性,进而实现投资资金与电力资源的优化配置,是一个值得研究的关键问题[1-3]。
目前,电力工程造价的预测方法可分为两类:1)统计学、模糊理论(Fuzzy Theory)等数学分析方法;2)支持向量机(Support Vector Machine,SVM)[4]、神经网络(Artificial Neural Network,ANN)[5]等人工智能算法。上述方法虽在电力工程造价预测方面获得了诸多应用效果,但单一的预测模型仍具有一定的局限性,故无法适应日益复杂的电力工程技术需求[6-8]。而融合多种算法的组合预测模型,能够有效结合不同算法的优势,并充分利用各个系统的信息,从而进一步提高预测结果的准确性。
文中通过研究融合多类型智能算法的电力工程数据处理技术,并运用大数据分析算法来实现相关工程造价的精准预测,进而为电力工程的科学管控提供技术支撑。
1 基于虚拟模型重建的数据处理系统
电力工程数据处理系统如图1 所示,其包括用户层、展示层、业务层、数据层与数据库。

图1 电力工程数据处理系统
建筑信息模型(Building Information Molding,BIM)技术在电力工程项目的管理过程中被广泛应用。通过其所构建的虚拟模型,可实现工程建筑全生命周期的信息共享,进而提升电力工程规划设计、施工运维等环节的效率与智能化水平。基于虚拟建模的电力工程项目信息处理流程如图2 所示。设计单位利用电力工程CAD 平台及BIM 模型族库来完成图纸设计与电力工程的虚拟模型重建,并利用该模型的关联数据实现工程量与工程造价的自动计算,从而为施工过程的项目管控提供辅助服务。
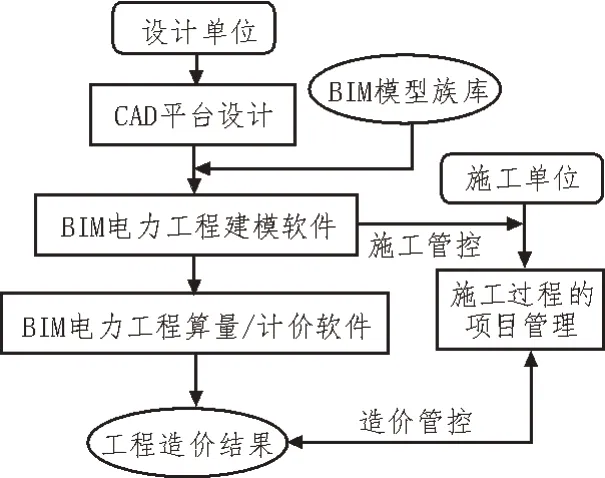
图2 电力工程项目信息处理流程
2 电力工程数据处理技术
针对电力工程数据处理分析,文中提出了基于虚拟模型重建与智能校核的PCA-PSO-SVR 算法,其框架如图3 所示。首先,利用虚拟模型重建技术获取电力工程数据;然后采用格拉布斯法(Grubbs)对其进行智能校核,并剔除异常数据,提升数据的质量;接着使用主成分分析算法(Principal Components Analysis,PCA)进行数据降维,从而提高数据处理及分析的速度;同时利用粒子群优化算法(Particle Swarm Optimization,PSO)对支持向量回归(Support Vector Regression,SVR)的惩罚系数C与核参数σ进行优化,以提高其性能;最终即可实现电力工程造价评估。

图3 智能校核与PCA-PSO-SVM融合算法框架
2.1 基于Grubbs法的智能校核模型
将新获取的数据与已有的合理数据按照增序排列,则形成的数据序列{x}如下:
若新获取的数据xi位于序列{x}的中间,判定其为合理数据;若位于首尾段,则应利用Grubbs 法加以判断。
Grubbs 法需首先设置一个异常数据识别阈值,该值为较小的概率值。其物理意义为:利用Grubbs法进行数据校核出现误判的可能性[9]。数据xi校核结果的置信概率为:
式中,α为异常数据识别阈值,且其通常设置为0.010、0.025 和0.050 等。
进一步计算数据xi的判定值κ,具体计算公式如下:
式中,与s分别为数据序列{x}的平均值和标准偏差,则二者的计算可表征为:
式中,n为数据序列{x}的样本总数。然后根据数据样本总数n及置信概率P通过查询经验表来获取λ(P,n)值。最后根据κ与λ(P,n)的大小进行判定:
若κ>λ(P,n),xi为异常数据;否则,xi为合理数据。
2.2 PCA-PSO-SVR算法
1)PCA[10-11]是一种多维数据处理技术,其通过投影映射方式实现数据空间的降维与特征提取。
对于包含N个数据样本,且每个样本均具有M维特征的数据集,所构建的原始数据矩阵为:
其中,xnm为第n个数据样本第m维的特征值。
为避免不同特征量纲对计算结果的干扰,需对原始数据进行标准化处理:
式中,为标准化后的数据值,和σm为所有数据样本在m维特征值的平均值与标准偏差。
计算相关系数矩阵R=[rij]m×m:
计算相关系数矩阵R的特征值及特征向量:
式中,假设相关系数矩阵R共有P个特征值,则第p个特征值为λp,其所对应的单位特征向量为:
计算各个影响因素的贡献度可得:
按照贡献度大小进行降序排列,则有:
计算前h个影响因素的累计贡献率,直至大于设置阈值εp,由此得到h个主要影响因素。前h个特征值对应的特征向量为:
则通过PCA 算法进行映射降维后,得到的数据样本矩阵XPCA为:
2)支持向量回归[12-13]通过非线性函数φ(x)将数据x映射至高维度空间,从而完成原求解问题的线性转换。对于已知的数据集A={(xi,yi)|i=1,2,…n},可采用以下方法进行回归拟合:
式中,w为权重矩阵,b为截距。
SVR 分析的关键在于求取w的值,通常利用最小化风险函数来求取:
式中,C为惩罚系数;L为损失函数,其计算方式如下:
其中,ξ为误差均值。
通过求解式(16)的对偶问题可得到解ai和,则w表示为:
将式(18)代入式(15)可得:
式中,K(xi,x) 为核函数,通常取为径向基核函数,则有:
式中,σ为核函数参数。
3)PSO[14-16]是常用的一种仿生智能算法,对于D维空间的寻优问题,粒子i具有位置及速度两个特征,可表示为:
二者的更新机制如下:
综上所述,文中所提PCA-PSO-SVR 算法流程如图4 所示。
3 算例分析
以某电网公司输电工程相关数据作为训练集,验证所提算法的正确性及有效性。
3.1 Grubbs数据校核结果分析
基于Grubbs 的智能数据校核过程分析如下:已存在一组合理的工程基础土石方数据,且对于A 工程,其基础土石方为920.3 m3/km。将其按照从小到大排列,具体如表1 所示。该组数据平均值为581.45,标准偏差为161.92,利用式(3)计算得到κ值为2.09。根据经验数值表可知,在95%的置信度下,λ(0.95,8)=2.03,即κ>λ(0.95,8),因此该数据为异常数据,需要剔除。

表1 电力工程基础土石方数据
采用相同训练集进行模型训练,并对比分析基于Grubbs 的智能数据校核对电力工程造价预测结果的影响,具体如表2 所示。Grubbs-PCA-PSOSVR 算法的平均相对误差为3.69%,而PCA-PSOSVR 算法误差则为4.54%。由此可见,Grubbs 模型能够有效降低异常数据对工程造价预测结果的影响。

表2 智能校核模型对预测结果的影响
3.2 算法准确性对比
利用Grubbs 模型对训练集进行数据校核、剔除异常数据等操作,并将其作为后续预测算法模型的输入。对比文中所提组合模型与BP 神经网络、SVR及PCA-SVR 等算法模型的预测准确性。所得结果如表3 所示,由数据可知,单一模型(BP、SVR)的平均相对误差均大于10%;相比于单一模型,PCASVR 则经过数据降维处理,使得算法的平均相对误差降低至8.07%;而文中算法在PCA-SVR 算法的基础上,利用PSO 对SVR 模型的参数加以优化,进而得到具有最优性能的SVR 模型,故其平均相对误差仅为3.73%。
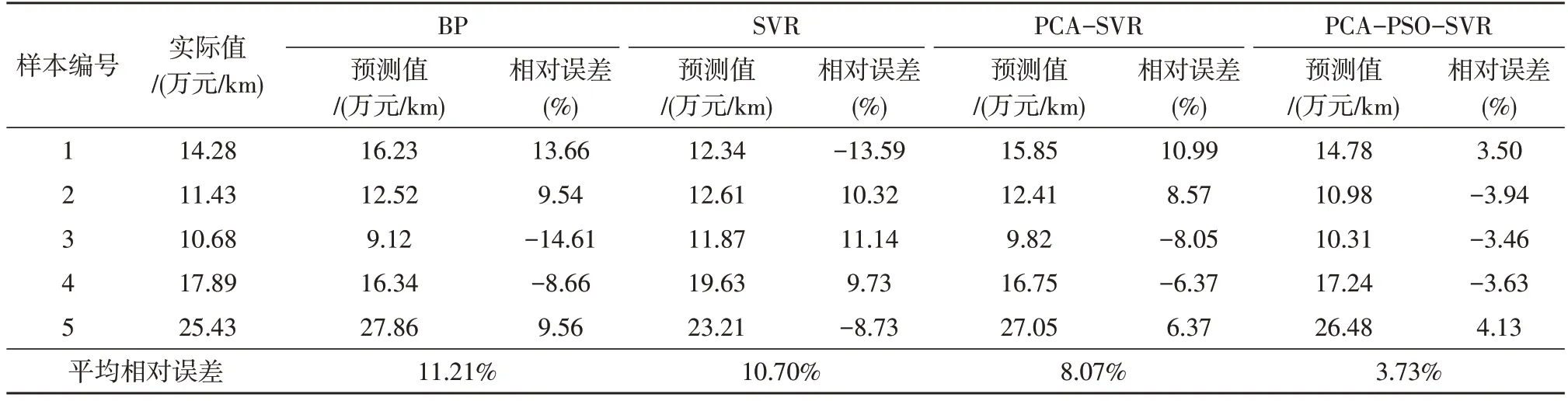
表3 不同模型的预测结果对比
4 结束语
文中分析了电力工程数据处理系统架构及虚拟模型重建流程,提出了一种融合智能数据校核及组合预测模型的电力工程造价预测算法。仿真算例表明,Grubbs 校核方法能够准确识别异常数据,PCAPSO-SVR 组合模型则能够有效提高电力工程造价预测的准确性。但该算法并未考虑市场、政策等因素的影响,故仅适用于电力工程的静态造价预测。因此,这将在后续研究中进行改进。
猜你喜欢
大电机技术(2022年5期)2022-11-17
消费电子(2022年7期)2022-10-31
数学物理学报(2021年5期)2021-11-19
建材发展导向(2021年13期)2021-07-28
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
中国交通信息化(2020年12期)2020-02-06
建材发展导向(2019年5期)2019-09-09
山东工业技术(2016年15期)2016-12-01
东北电力大学学报(2015年1期)2015-11-13
水电站机电技术(2014年4期)2014-10-13
