
基于图文多模态融合的文档片段语义相似度判定算法
2024-02-27 12:16潘媛梁国迪邵馨叶李芹
电子设计工程 2024年3期
潘媛,梁国迪,邵馨叶,李芹
(云南电网有限责任公司信息中心,云南昆明 650214)
图文多模态融合是在图文融合机制基础上发展起来的新型图文混排信息标注方法,能够根据多模态特征的排列形式,将文本参量与图片像素点结合起来;并可以联合自然语言、计算机视觉等多项应用技术,建立完整的图文标记向量集合,以供网络主机的直接调取与利用[1-2]。由于图片像素点的排列始终满足统一性原则,所以在实施图文多模态融合技术时,要求文本参量与像素点信息之间的对应性关系必须保持不变。
相似性文本是指信息权重部分相同的文本数据参量。在互联网环境中,相似性文本存储于同一数据库主机中。由于文档片段语义迁移行为的存在,如何保障网络主机对于相似性文本的差异性赋值能力,成为一项亟待解决的应用难题[3]。基于半监督AP 聚类的判定算法通过精准定义文档片段语义特征的方式,确定相似性文本参量之间的细微差异性,再联合互联网应用主机,完成对这些数据信息参量的按需判别[4]。然而,与此方法相关的差异性赋值指标的均值水平相对较低,并不能完全保障网络主机对于相似性文档片段语义信息的准确判别能力。为解决上述问题,引入图文多模态融合技术,并以此为基础,设计一种新型的文档片段语义相似度判定算法。
1 基于图文多模态融合的文档片段标注
1.1 图像区域检测
图像区域检测决定了图文多模态融合技术的实践能力。对于既定文档片段参量而言,图像区域检测指标的取值结果越大,单一文档片段的待检长度值越大。倾斜校正系数也叫图像区域内的倾斜校正指标,为避免局部偏差融合行为的出现,在定义图像区域的倾斜校正系数时,应同时考虑局部量差值在x轴、y轴、z轴方向上的数值分量[5-6]。设Gx表示图像局部量差在x轴方向上的数值分量,Gy表示y轴方向上的数值分量,Gz表示z轴方向上的数值分量。联立上述物理量,可将图像检测区域内的倾斜校正指标G表示为:
规定ax表示x轴方向上的图像待检系数,ay表示y轴方向上的图像待检系数,az表示z轴方向上的图像待检系数,aˉ表示系数ax、ay与az的平均值,ϕ表示图像区域内的文档片段语义信息检测特征。图像区域检测定义式为:
对于文档片段语义信息参量而言,图像区域检测表达式决定了待检数据信息的实际分布形式。
1.2 文本区域检测
文本区域检测决定了图文多模态融合技术对于待匹配数据信息参量的处理能力[7]。在图文多模态融合算法的认知中,文本区域检测表达式的定义必须以图像区域检测结果为基础,故而后者的定义数值越大,待检测文本区域内所包含的文档片段语义信息参量也就越多[8]。设χ表示文档片段语义信息的区分系数,α表示语义参量识别指征,ΔK表示文档片段语义信息的单位迁移量,A表示文档片段语义信息的实时累积量。在上述物理量的支持下,联立式(2),可将文本区域检测条件定义为:
在实施相似性文档片段语义信息参量判定处理的过程中,图文多模态融合条件的建立必须同时参考图像区域检测表达式与文本区域检测表达式。
1.3 词袋模型
词袋模型也叫文本信息检索模型,在图文多模态融合算法的作用下,单一词袋模型中所包含的相似性文档片段语义信息越多,系统主机所承担的数据判别压力也就越大。为实现对文档片段语义相似度的准确判定,在建立词袋模型时,要求图像区域检测表达式与文本区域检测表达式应同时取得最大或最小赋值结果[9-10]。设δ1、δ2表示两个不相等的相似性文档片段语义信息检索系数,f表示基于图文多模态融合条件的语义信息检测向量,β表示语义信息的相似性度量值,L表示图文信息匹配特征。基于图文多模态融合的相似性文档片段语义信息词袋模型表达式为:
若互联网应用主机的处理能力始终保持不变,在判定相似性文档片段语义信息时,应对词袋模型表达式进行全局性取值。
2 文档片段语义相似度判定算法设计
2.1 文本数据预处理
相似性文档片段语义信息文本是大量关键词数据按照图文多模态融合排列规则,所形成的关键词序列条件。在实施信息操作指令前,应对相似性文档片段语义信息文本数据进行初步预处理[11]。在制定判定指令的过程中,若相似性文档片段语义信息为中文文本,则应遵循完整性原则对文本数据进行预处理;若相似性文档片段语义信息为英文文本,则应遵循时态变化规则对文本数据进行预处理[12]。设p͂基于图文多模态融合的文本信息取值系数,wmin表示已定义相似度文本的语义判别特征最小值,wmax表示语义判别特征最大值,φ表示相似度语义信息度量系数,ε表示相似度文档片段语义信息的初始赋值。在上述物理量的支持下,联立式(4),可将相似度文档片段语义信息文本数据的预处理表达式定义为:
在图文多模态融合原则的作用下,文本数据预处理表达式可以同时影响关键词权值指标与相似性度量值的计算结果。
2.2 关键词权值计算
关键词权值计算是实现文档片段语义相似度判定处理的关键执行环节,在已知文本数据预处理结果的前提下,关键词权值指标的物理取值越大,就表示互联网主机对于相似度文档片段语义信息的处理能力越强[13-14]。规定γ、ι表示两个随机选取的文档片段语义信息敏感性度量值,且γ≠ι的不等式条件恒成立。设cγ表示基于度量值γ的语义信息相似度标记参量,cι表示基于度量值ι的语义信息相似度标记参量。相似度文档片段语义信息关键词权值计算表达式为:
式中,κγ表示基于度量值γ的语义信息判别权限量,κι表示基于度量值ι的语义信息判别权限量。在实际运算过程中,要求κγ≠1、κι≠1、κγ≠κι的不等式条件同时成立。
2.3 相似性度量值
相似性度量值指标决定了文档片段语义信息之间的可替代关系。在图文多模态融合技术的支持下,只有确保待检信息参量之间的相似性度量指标取值不完全相等,才可以实现对文档片段语义信息的准确判定[15-16]。设ϖ表示可替代参量的一般性赋值条件,θϖ表示文档片段语义信息的向量残差值,θ0表示向量残差的初始赋值,ϑ表示相似性指标的初始赋值,b1、b2、…、bn表示n个不同的相似度文档片段语义信息分类指标。联立上述物理量,可将相似性度量值表达式定义为:
按照图文多模态融合技术,对所求得数据参量指标进行处理,实现文档片段语义相似度判定算法的顺利应用。
3 实例分析
为突出基于图文多模态融合的文档片段语义相似度判定算法的实用性价值,设计如下对比实验。首先,选择型号为W4900os 的互联网主机作为实验设备,通过人工调试的方式,使实验主机的各项指标示数趋于稳定。然后,利用基于图文多模态融合的文档片段语义相似度判定算法对实验主机进行控制,将所得实验数据作为实验组变量。其次,利用基于半监督AP 聚类的判定算法对实验主机进行控制,将所得实验数据作为对照组变量。最后,对比实验组、对照组变量指标,总结实验规律。图1 为在实验组、对照组算法的作用下,互联网主机对于相似性文档片段语义信息的处理原则。
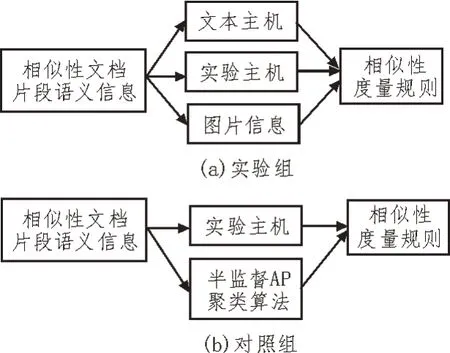
图1 实验数据处理原则
选择六种不同相似性文档片段语义信息作为实验数据,分别将其定义为“1 号文本”“2 号文本”“3 号文本”“4 号文本”“5 号文本”“6 号文本”。表1 给定了六种不同相似性文档片段语义信息差异性指标的初始取值。

表1 差异性指标的初始赋值
分析表1 可知,相似性文档片段语义信息差异性指标赋值的最大值为1.21,与1 号文本相对应。差异性指标赋值的最小值为0.98,与6 号文本相对应,二者之间的指标赋值差等于0.23。
在不超过差异性指标初始赋值条件的情况下,所得实验数值越大,就表示网络主机对于相似性文档片段语义信息的准确判别能力越强。表2 记录了实验组、对照组相似性文档片段语义信息差异性指标的实验数值。

表2 差异性指标的实验数值
利用表2 中的记录数据,计算实验组、对照组相似性文档片段语义信息差异性指标的平均值,具体记录数值如图2 所示。

图2 差异性指标平均值
分析图2 可知,在整个实验过程中,实验组、对照组相似性文档片段语义信息差异性指标平均值都没有超过差异性指标的初始赋值。但明显实验组指标的平均值水平更高,实验组最大值为1.1,与1 号文本相对应,对照组最大值为0.9,与1 号文本、3 号文本相对应。综上可知,在图文多模态融合技术的作用下,相似度文档片段语义信息差异性赋值指标的均值水平得到了明显提升,对于网络主机而言,其在准确判别相似性文档片段语义信息方面的应用能力确实得到了有效保障。
4 结束语
新型文档片段语义相似度判定算法在图文多模态融合技术的作用下,通过建立词袋模型的方式,对文本数据进行初步处理,又根据关键词权值计算结果,实现对相似性度量值指标的按需统计。在实用性方面,随着这种新型判定算法的应用,差异性赋值指标的最大值达到了1.10。且在整个实验过程中,赋值指标均值始终没有超过其初始赋值结果,在准确判别相似性文档片段语义信息方面具有较强的实用性价值。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
榆林学院学报(2022年4期)2022-08-02
文萃报·周二版(2022年3期)2022-01-20
河北画报(2020年8期)2020-10-27
计算机与生活(2018年8期)2018-08-15
浙江大学学报(工学版)(2016年2期)2016-06-05
理科考试研究·高中(2016年9期)2016-05-14
绍兴文理学院学报(自然科学版)(2013年2期)2013-12-19
海外英语(2013年9期)2013-12-11
海外英语(2013年10期)2013-12-10
