
基于遗传算法的核电备件库存模型仿真优化
2024-02-20 09:56谢宏志韩亚泉
科学技术与工程 2024年1期
谢宏志, 韩亚泉
(中广核核电运营有限公司备件中心, 深圳 518124)
备品备件是为保持和恢复核电厂核安全、机组可用率及相关辅助功能所必需的零、部件及修理、更换所用的成品替换件,备件储备的充分性以及备件管理的有效性可以减少设备检修时间、缩短换料大修工期,保障机组安全稳定运行。核电备件的目标用户是现场维修活动,在不考虑产品设计制造缺陷和后期老化问题的情况下,在设备稳定运行期间,备件需求数量的随机性较大,对于任意一种备件而言,其对应的现场安装数量较少,需求数量有限。核电备件入库后两年内的平均领用比例约为60%,即储备的大部分备件在短期内不会被领用,备件周转率低,但若备件储备不足,供应不及时,将会降低设备可靠性,增加电站运行风险,甚至出现停机、停堆等问题,对核电厂正常生产活动造成影响,由此产生重大经济损失。
核电备件有着庞大的品种数量、较少的备件消耗量、较长的备件采购周期、难以预测备件的需求数量等特点。通过设置合理的备件库存模型,在确保备件供应的前提下,优化库存结构,降低整体库存成本[1-2]。库存控制模型主要分为定量订货模型和定期订货模型,其中定量订货模型主要是基于备件需求量的库存控制方法,定期订货模型主要是基于时间的库存控制方法[3],当前核电备件主要采用定量订货模型。定量订货模型的库存参数主要由再订货点和采购批量组成[4-5]。再订货点主要用于控制缺货风险,应至少满足采购周期内的需求量,理想情况下库存水平低于该点时备件触发采购。为防止不确定性因素对备件管理的影响,在基本库存之外需设定一定量的安全库存,因此备件实际再订货点为采购周期的领用量加上安全库存数量。采购批量是指某一次采购过程中备件的采购数量,采购批量的大小决定了备件采购订单发单间隔时间。采购批量主要分为最大库存模型和固定采购批量模型两类,最大库存模型是指每次采购的数量不固定,直接补货到最大库存数量,固定采购批量模型是指每次采购的数量是一个固定值。
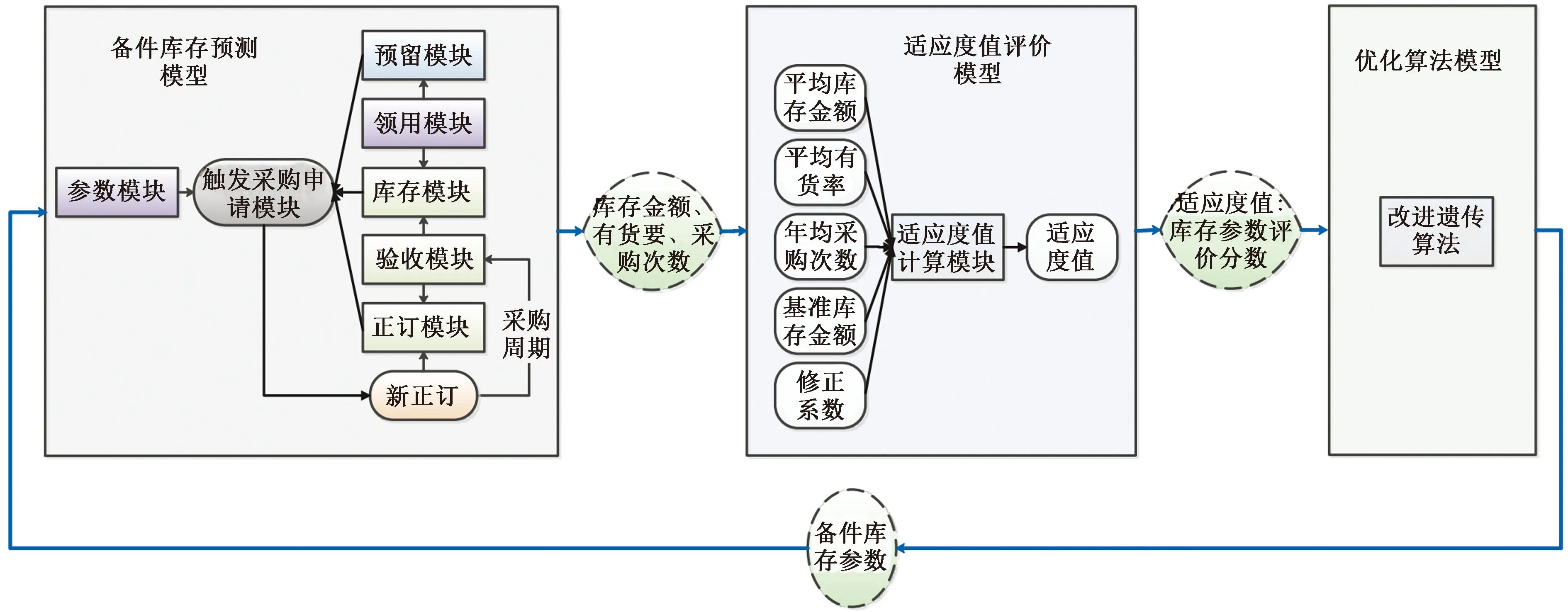
为解决库存策略模型的参数设置问题,文献[6]构建了联合补货与配送模型,使用遗传算法对模型进行求解;部分学者采用概率拟合方法,即假设备件领用需求服从某种分布,通过大量历史数据来拟合参数[7-10]。然而核电备件的领用数据量较小,且不同类型的核电备件差异性较大,无法通过概率拟合方法有效设置所有核电备件的库存参数。目前已有部分学者将仿生优化算法应用于库存优化[11-13]与核电厂维修策略优化领域[14],由于难以对核电备件的订购、缺货、储存等成本进行量化评价,尚无法使用优化算法直接计算核电备件库存模型参数。基于该问题,现设计一种可以量化评价核电备件库存参数的方法,应用备件库存金额、有货率、年发单次数、备件重要性等因素构建适应度值评价模型,使用改进遗传算法寻优计算备件库存参数。
1 改进遗传算法
1.1 改进遗传算法结构
遗传算法是一种全局式的搜索启发式算法,其模拟自然界的选择、交叉、变异的遗传方式,采用适者生存的进化思想来求解优化问题[15-16]。遗传算法将待求解问题通过染色体编码方法映射为编码空间中的染色体,染色体代表群体中的个体,染色体的集合被称为群体,遗传算法从某个初始群体开始,使用遗传算子作用于群体,从而产生下一代的群体,根据适应度函数从这些染色体中选取相对优秀的个体,并对这些个体采用迭代遗传操作,产生新一代种群,重复这一个过程,直到满足设定的收敛条件为止。
传统的遗传算法可以在全局搜索空间进行快速探索,但对搜索空间的挖掘效果不佳,通常表现为遗传算法相对较快地接近某个最优值,然后出现慢整理问题,非常缓慢地接近最优值。此外,传统的遗传算法在选取下一代种群的过程中,个体的选择概率与适应度值高度相关,容易出现早熟现象,种群中所有个体的基因收敛到局部最优值,难以跳出局部最优解,遇到复杂多峰优化问题时优化精度不高。
为了解决传统遗传算法收敛慢,易陷入局部最优值的问题,设计了一种改进遗传算法,当个体处于较慢收敛状态或者已陷入局部最优值时,通过增加随机因子扩大个体的搜索空间,基于当前种群最优位置重置部分个体的位置。重置概率是动态变化的,在算法迭代的前期,重置概率较小,这样不会使个体在前期过早的围绕在当前最优值附近搜索,造成陷入局部收敛;在算法的中后期,重置的概率较大,可以使个体更多的在当前最优值附近搜索,加快收敛的速度。该算法的结构框架图和算法的伪代码如图1所示。

图1 改进遗传方法的流程图和伪代码图Fig.1 Framework and pseudo-code of MPSO
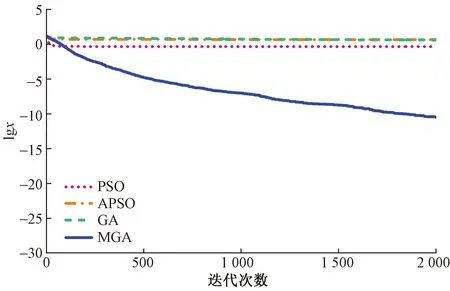
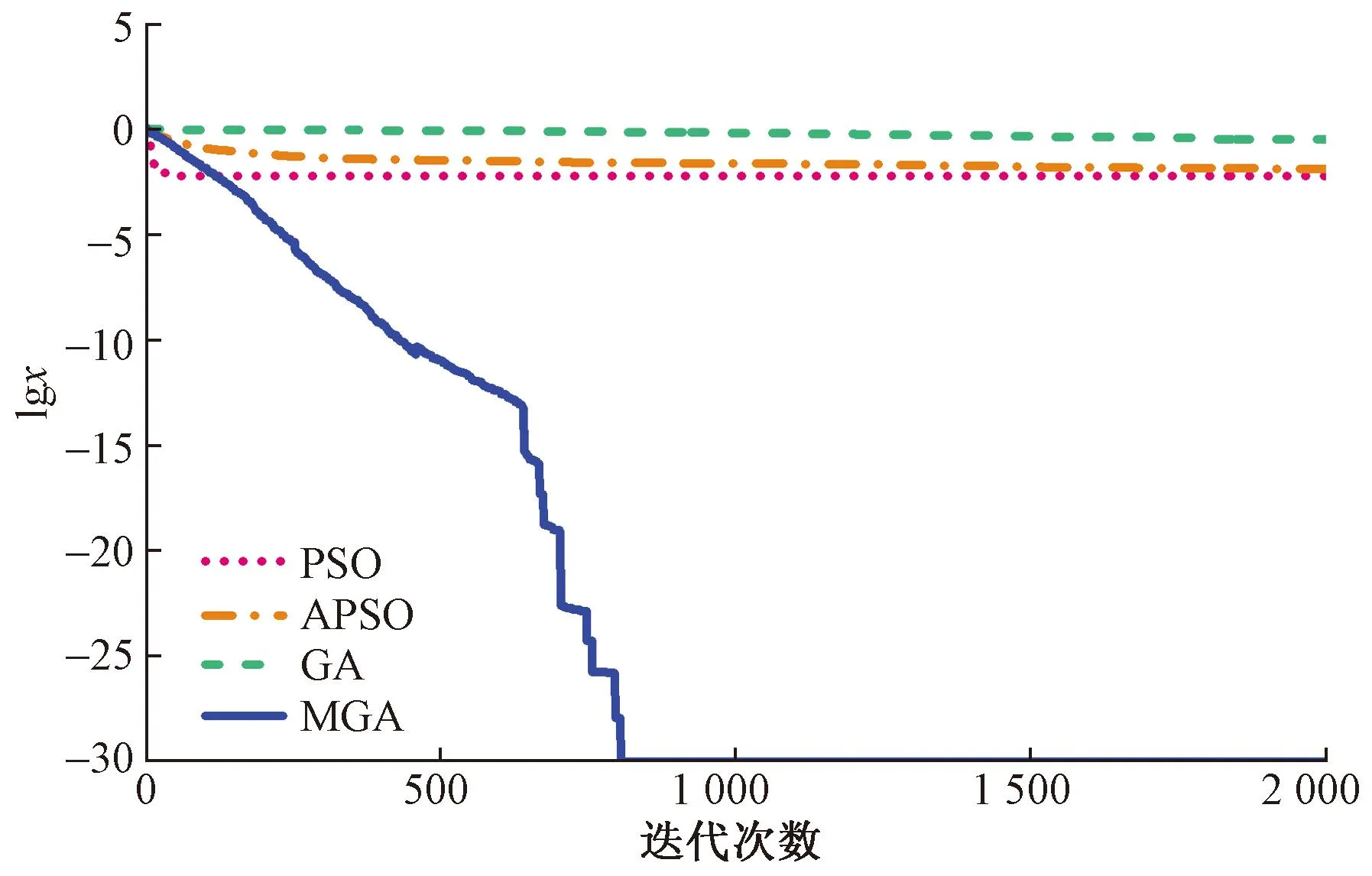
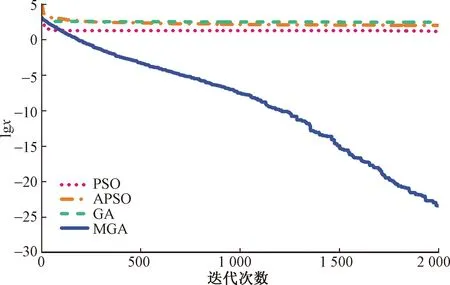
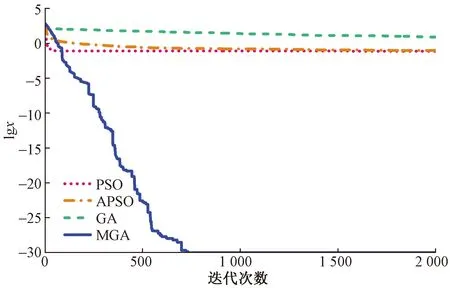
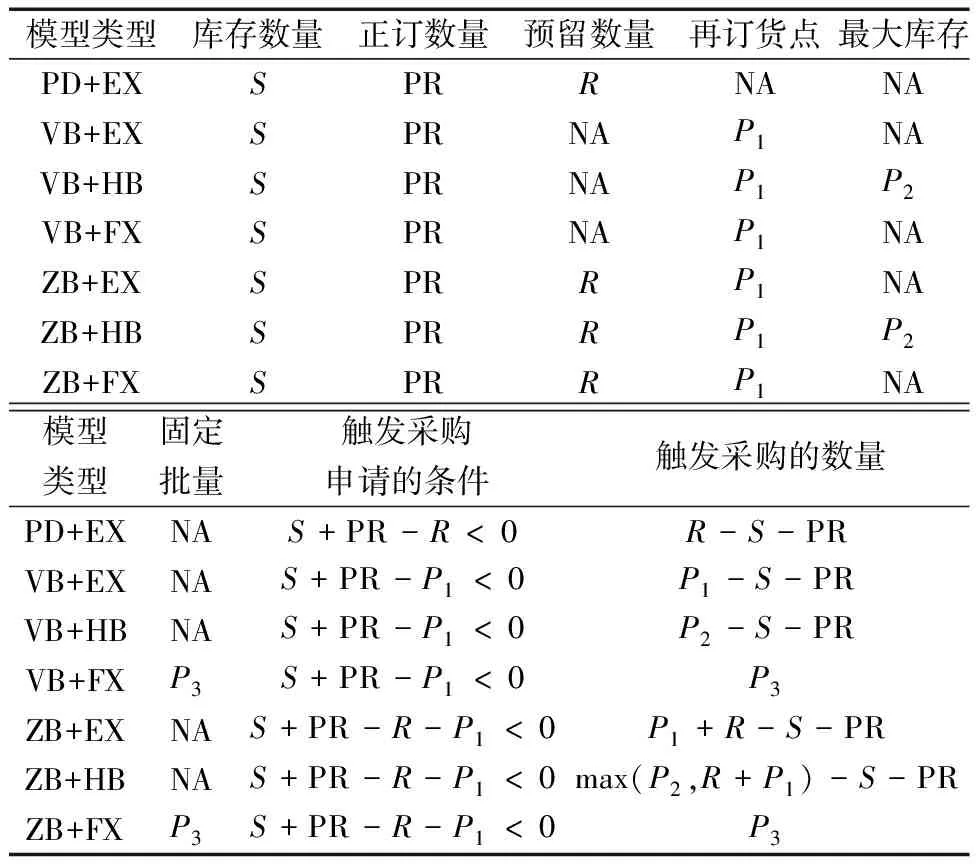
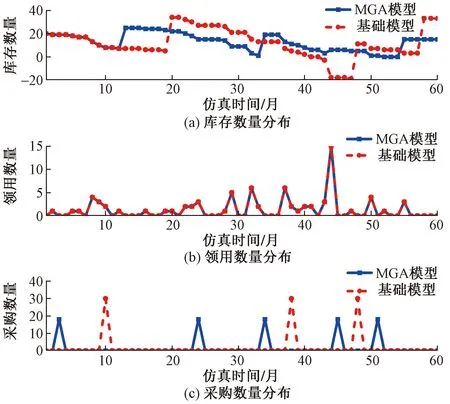
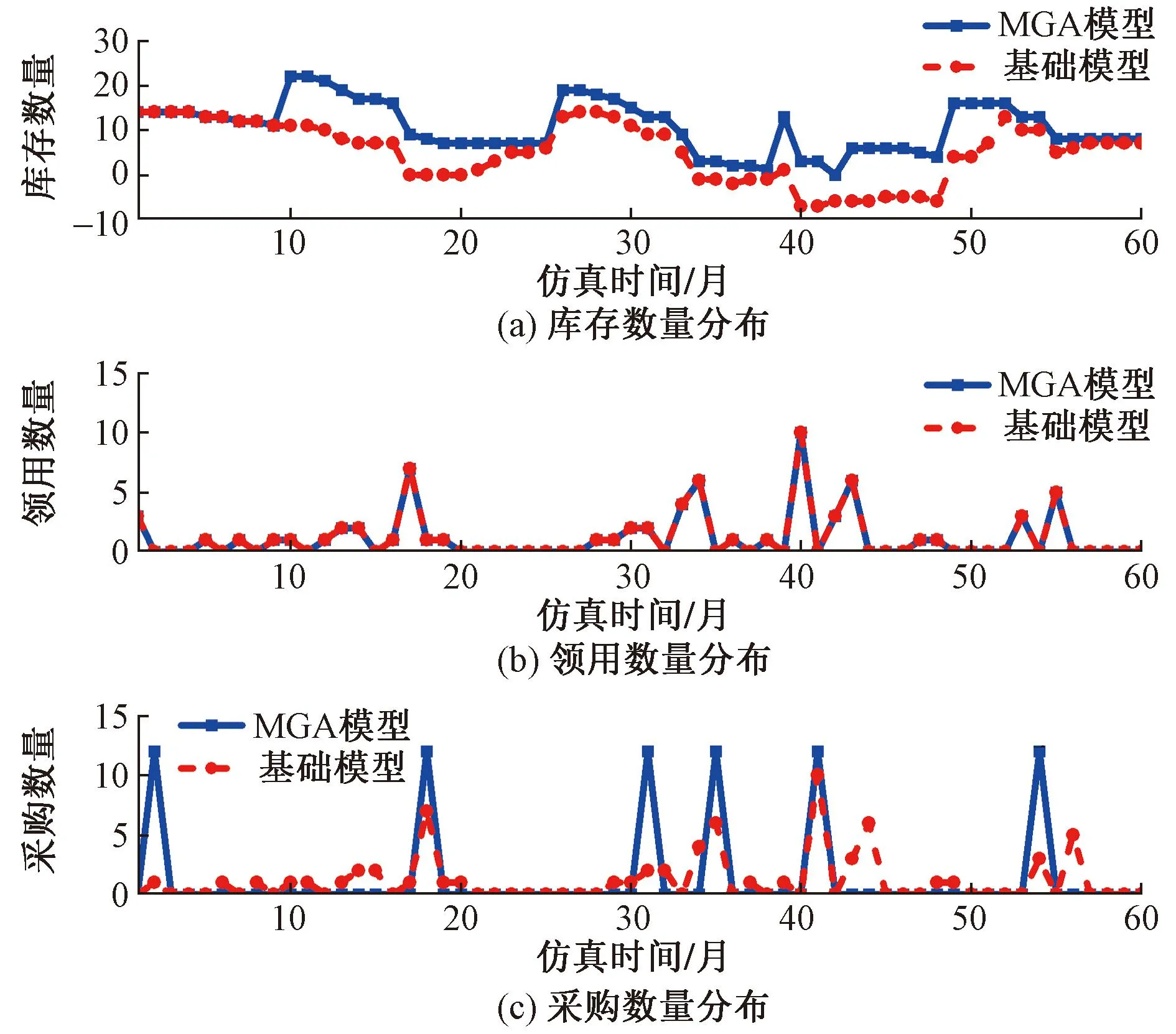
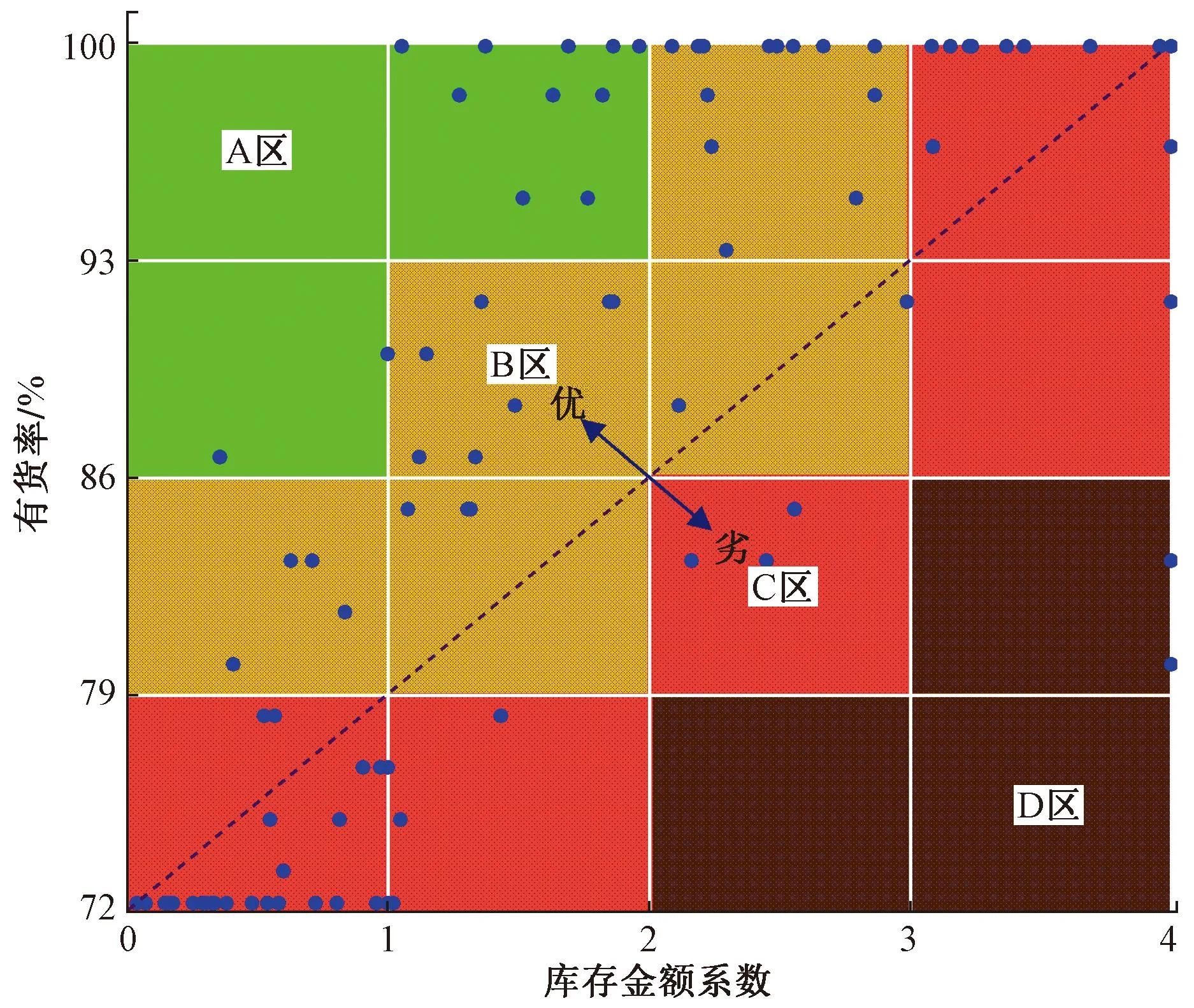
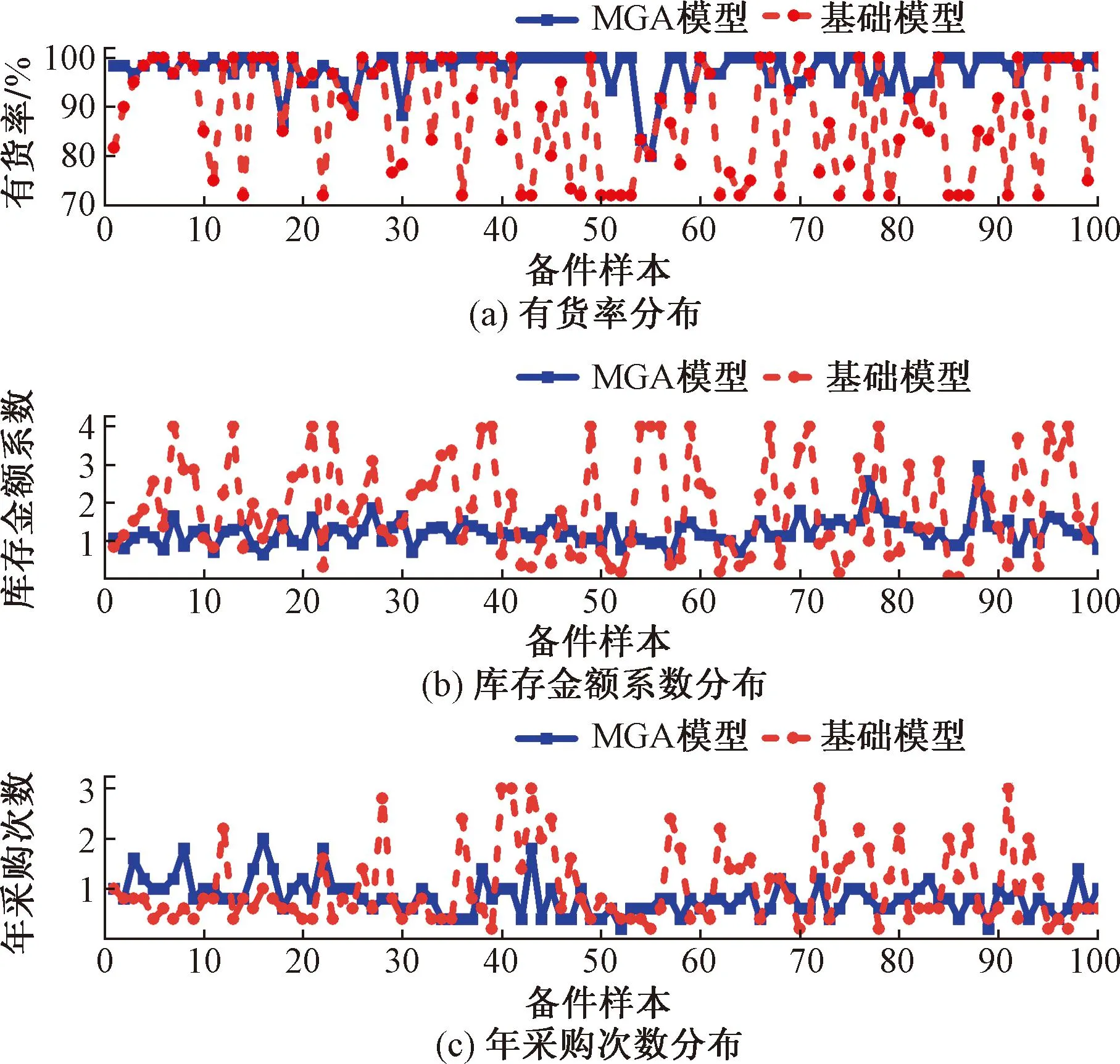
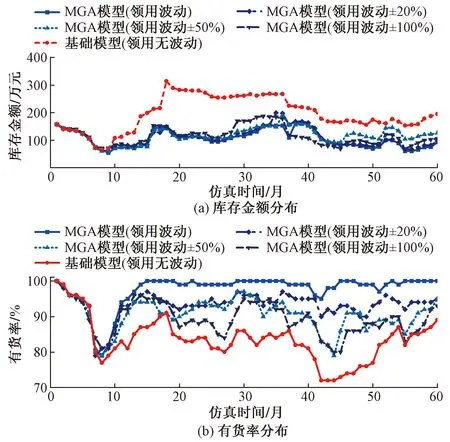
图1伪代码步骤2.7中,通过计算种群中所有个体的适应度值,比较种群中最优适应度值和中位数适应度值的偏离程度,当满足(f2-f1)/f2 图2 重新赋值后的个体位置分布图Fig.2 The distribution map of individual positions after reassignment 通过选用5个常用的基准函数测试改进遗传算法(modified genetic algorithms,MGA)的性能,这些基准测试函数的特点和计算公式如下所示。 Ackley函数是一个复杂的多峰函数,该函数的定义域内有多个局部极小域,全局最优值的位置在一个狭小的区域,该函数的公式为 (1) Griewank函数是一个复杂的多峰函数,该函数中部分变量之间有着一定相互关联性,较难找到全局最优解位置,其公式为 (2) Rastrigin函数是一个复杂的多峰函数,该函数的搜索空间大,有多个局部最优位置,其被视为一个较难处理的多峰优化问题,其公式为 (3) Schwefel函数是一个复杂的单峰函数,该函数梯度方向不会沿着轴线方向变化,具有较大的寻优难度,其公式为 (4) Sphere函数是一个容易求解的单峰函数,该函数较为容易收敛到全局最优位置,常被用于测试算法的基本性能,其公式为 (5) 式中:e为自然常数;n为基准测试函数的总维度;i、j为指定的某一维度值;xi、xj为在第i、j维度的位置值。 Ackley函数、Griewank函数、Rastrigin函数、Schwefel函数、Sphere函数的全局最优位置为0,为了更好地分析MGA算法收敛速度和搜索精度,同时测试了标准粒子群算法(particle swarm optimization,PSO)[17-18]、自适应粒子群算法(adaptive particle swarm optimization,APSO)[19]、标准遗传算法(genetic algorithm,GA)在以上基准函数下的优化效果,并进行对比分析。基准函数的维度设置为30,各种优化算法的种群个体数量设置为40,初始位置设置在 (-10, 10),最大迭代次数为2 000,每种算法均会独立运行10次,保存每次迭代时的适应度值,并计算平均值。多种优化算法在5个基准函数的收敛速度和搜索精度如图3~图7所示,其中,x为实际适应度值,lgx为对适应度值进行以10为底数的对数运算。为便于对比不同基准函数的测试效果,当计算的适应度值小于10-30时,将其值设置为10-30。可以得知,MGA算法的优化结果更接近0,即各个基准测试函数的全局最优值,其收敛速度和搜索精度都要高于用于对比的几种优化算法。除了MGA算法外,其他优化算法都在搜索的中后期出现收敛速度变慢、搜索精度停滞不前的情况,这些都是算法无法跳出局部最优值的表现。 图3 多种优化算法在Ackley函数下的测试效果Fig.3 Comparison of various algorithms on Ackley 图4 多种优化算法在Griewank函数下的测试效果Fig.4 Comparison of various algorithms on Griewank 图6 多种优化算法在Schwefel函数下的测试效果Fig.6 Comparison of various algorithms on Schwefel 图7 多种优化算法在Sphere函数下的测试效果Fig.7 Comparison of various algorithms on Sphere 通过对每种优化算法独立运行10次,提取每次运行时的最优适应度值,分析结果如表1所示。在这几种基准函数测试中,MGA算法的优化效果均优于用于对比的优化算法,且在Griewank测试函数和Sphere测试函数中,该算法的最优适应度值等于测试函数的全局最优值。 表1 多种优化算法在独立运行10次后的均值和标准差Table 1 Mean and standard deviation of multiple optimization algorithms after 10 independent runs 备件库存参数优化模型如图8所示,针对任意备件,当给备件赋值某库存参数,基于备件库存预测模型,可以计算出该备件在未来一段时间的库存分布,包含了库存金额、有货率、年均采购次数,基于适应度值评价模型,可以计算出在某库存参数下的评价分数,由此可以构建库存参数和评价分数的对应关系。将备件的库存参数作为种群个体的位置,库存参数评价分数作为适应度值,使用改进遗传算法寻找备件的最优库存参数。 图8 备件库存参数优化模型结构图Fig.8 Structure diagram of spare parts inventory parameter optimization model 备件库存金额和有货率都与备件库存数量有关,当某期的库存数量为非负数时,其库存金额等于库存数量乘以单价,有货率为1;当某期的库存数量为负数时,相当于现场维修活动需要某备件,但仓库中无该备件,即处于等备件状态,库存金额赋值为0,有货率为0。通过对库存金额和有货率取均值,可以得到该备件在未来某段时间内的平均库存金额和平均有货率。 通过迭代计算,可以得到备件的库存数量。备件库存数量的计算公式如式(6)所示,备件的库存数量是由上一期库存数量、上一期领用数量和上一期到货验收数量所决定。以下进一步介绍领用模块、预留模块、正订模块、验收模块、触发新采购申请模块的计算过程。 St+1=St+Yt-Lt (6) 式(6)中:S为库存数量;Y为验收数量;L为领用数量;t为仿真的时间。 2.1.1 领用模块 计算备件未来的领用即对备件未来的需求进行预测,通过对备件需求进行分类,基于历史领用数据预测未来领用需求。核电备件的领用需求可以分为计划性领用需求和突发性领用需求[20],其中计划性需求是根据维修大纲开展的维修活动,突发性需求是在现场设备发生故障时开展的维修活动。针对计划性备件需求,根据维修大纲、标准包,生成备件未来领用需求;针对突发性备件需求,通过读取该备件的历史突发性备件领用数据,随机生成相同领用频次、相同领用均值、相同领用标准差的备件突发性领用需求。再对计划性备件需求、突发性备件需求进行求和,得到备件未来的总领用需求。 为简化备件领用数量的计算过程,可以使用移动平均法计算备件在未来的领用数量。例如按照月度进行仿真计算,需要对备件未来m个月的领用数据进行预测,从数据库中导出该备件在过去m+2个月领用数据,令历史领用数据分别为N-m-2、N-m-1、N-m、…、N-1,使用式(7)计算备件未来领用数据。实际应用中,可以进一步简化,假设备件未来的领用需求与历史领用数量相同,进行仿真运算。 Nt=(N-m-3+t+N-m-1+t)/2 (7) 2.1.2 预留模块 为提升备件保障能力,核电维修用户在开展计划性维修工作前会对部分备件进行预留。备件预留类似于提前对备件未来的需求进行预测,明确备件在未来的需求时间和需求数量,以便及时开展备件采购工作。影响备件预留有效性的因素为:预留提前期、预留比例、预留准确率。由于备件预留会同时影响备件库存金额和有货率,为减少预留对备件库存参数设置有效性的影响,仿真试验中,未使用预留模块,即所有备件的预留数量均为0。 2.1.3 正订模块 备件正订是指备件的采购申请已经审批生效,当前处于采购过程的数量。当审批了新的采购申请,备件的正订数量增加,当采购的备件到货验收后,备件的正订数量减少。备件正订的计算公式如式(8)所示,备件的正订数量与上一期的正订数量、上一期的新正订、上一期的验收数量有关。 PRt+1=PRt+NPRt-Yt (8) 式(8)中:PR为正订数量;NPR为新增正订数量;Y为验收数量;t为仿真的时间。 2.1.4 验收模块 备件的验收数量与新增正订数量有关,即在出现新增正订时,经过采购周期时间后会产生对应数量的备件验收。初始化验收表时,使所有时间段的验收数量均为0,在仿真过程中,若满足NPRt>0,则按照式(9)计算验收数量。 Yt+ΔT=Yt+ΔT+NPRt (9) 式(9)中:ΔT为该备件的采购周期。 2.1.5 触发采购申请模块 新增正订NPR与备件的库存量S、预留量R、库存参数、正订PR有关,核电备件常用的库存模型类型以及其运算逻辑如表2所示,通过输入库存参数、库存数量、正订数量、预留数量,计算新触发的采购数量。当满足触发采购申请的条件时,NPRt的值为新触发的采购数量,备件的总采购次数加1;当不满足触发采购申请的条件时,NPRt的值为0。例如某备件的库存模型类型为ZB+HB,再订货点为3,最大库存为6,其在t时间的库存量S为1,预留数量R为0,正订数量PR为1,满足触发采购申请的条件,触发的采购数量NPR为4。 表2 备件库存模型类型Table 2 Spare parts inventory model 当前常用的需求预测准确度检测方法主要用于比较两个模型偏离真实值的偏离程度,由于核电厂应用的备件库存策略模型是通过设置库存参数,利用库存缓冲等方法来应对备件需求的发生,难以通过库存参数计算出未来某一时间端的准确需求数量,故该评价方法不适用评价当前的库存策略模型和库存参数的设置效果。通过读取平均库存金额、平均有货率、年均采购次数、基准库存金额、备件的重要性,从模型参数设置后对库存管理和备件保障的效果,综合评价库存参数的优劣程度。其中基准库存金额是指备件的库存模型类型为ZB+EX,再订货点设置为采购周期内平均领用量,基于备件库存预测模型计算得到的平均库存金额。 备件有货率和库存金额是一对相互制约的指标,通常情况下,若要提升备件有货率,需增加库存储备量,由此会提升库存金额。基于这两个数据,以平均库存金额为横坐标,以平均有货率为纵坐标,建立模型效果网格分布图,使用综合距离法进行评估,即通过计算各模型参数与理论最优值的距离,得到参数评价分数。当备件的平均库存金额越低,平均有货率越高,此时库存参数越优。 读取备件的平均库存金额S1、平均有货率P、年采购次数M、基准库存金额S2、备件重要性I;计算采购次数修正系数C1,若M>1,则按照式(10)计算,否则令C1=1;计算备件重要性修正系数C2,若I=1(该备件为重要备件),则C2=0.825,否则C2=0.675;计算库存金额的影响值X,如式(11)所示,若X>14.1,则令X=14.1;计算有货率的影响值Y,如式(12)所示,若Y>14.1,则令Y=14.1;计算适应度值(评价分数)F,如式(13)所示,适应度值在0~10,适应度值越小,备件库存参数越优。 C1=1+0.25(M-1) (10) (11) (12) (13) 核电备件库存模型种类较多,基于表2中各种模型的运算逻辑,可以将优化问题细化为求解最优的再订货点、最大库存、固定批量。由于此次仿真试验中,所有备件的预留数量均为0,因此可以用ZB类型的模型替代VB类型的模型。当库存模型为ZB+EX,再定点设置0时,其效果等同于PD+EX。通过剔除VB类型和PD类型后,待求解的库存模型类型为ZB+EX、ZB+HB、ZB+FX。 针对ZB+EX类型,需计算最优的再订货点值,相当于求解1维优化问题。针对ZB+HB类型,需计算最优的再订货点和最大库存,相当于求解2维优化问题。针对ZB+FX类型,需计算最优的再订货点和固定批量,相当于求解2维优化问题。 通过使用改进遗传算法分别计算ZB+EX、ZB+HB、ZB+FX的最优适应度值,再比较3种库存模型类型的适应度值,选取其中适应度值最小的库存模型类型为最优模型类型,并读取相应的库存参数。 为了测试改进遗传算法在核电备件库存参数设置的应用效果,选择了大亚湾核电厂100个有领用记录的备件,读取了备件的单价、采购周期、重要性、近5年领用数据、当前数据库中备件库存参数。通过构建仿真模型,对备件未来60个月的库存数据进行仿真分析,在给备件输入不同库存参数时,自动计划备件的平均库存金额、平均有货率,并对输入的库存参数进行评价。 为确保数据测试数据的一致性,所有备件的初始库存数量设置为该备件1.5倍采购周期内的领用量,初始正订数量为0。备件在当前数据库中的库存参数作为基础模型,用于与MGA模型进行对比分析。 通过仿真运算,备件甲在不同库存模型类型下的仿真结果如表3所示。改进遗传算法先分别计算ZB+EX、ZB+HB、ZB+FX的最优适应度值,其ZB+FX的适应度值为0.44,优于ZB+EX和ZB+HB类型的适应度值,故MGA模型选用了库存模型类型为ZB+FX的数据。基础模型参数是维修用户在数据库中设置的库存参数,该备件的基础模型参数为ZB+FX,再订货点为12,固定批量为30,其库存模型类型与MGA模型计算的结果相同,但是其再订货点小于MGA模型,固定批量大于MGA模型。基础模型采用了储备较少量的最小库存,每次采购较大批量的策略,然而最小库存数量过低,导致出现等备件情况,单次采购批量较大,导致平均库存金额较高情况,基础模型的平均库存金额和有货率均劣于MGA模型。 平均库存金额是判断库存参数有效性的重要指标,通过选取3项典型的备件,分别对比MGA模型和基础模型的有效性。其中备件甲中两个模型的平均库存金额较为接近,备件乙中MGA模型的平均库存金额低于基础模型的平均库存金额,备件丙中MGA模型的平均库存金额高于基础模型的平均库存金额。各项备件的库存数量、领用数量、采购数量在每个时间点的仿真分布如图9~图11所示。 图9 备件甲的仿真结果Fig.9 Simulation results of spare part A 在这3项备件中,MGA模型的适应度值均优于基础模型的适应度值。如图9所示,当MGA模型的库存金额与基础模型的库存金额接近时,前者的有货率较高;如图10所示,当MGA模型的有货率与基础模型的有货率相同时(均为100%),前者的库存金额较低;如图11所示,当MGA模型的库存金额高于基础模型的库存金额时,MGA模型的有货率领先幅度更大,故MGA模型的参数更优。 图10 备件乙的仿真结果Fig.10 Simulation results of spare part B 图11 备件丙的仿真结果Fig.11 Simulation results of spare part B 通过将各模型中备件平均库存金额除以该备件的基准库存金额,可以得到库存金额系数,如某备件的平均库存金额为1.5万元,该备件的基准库存金额为1万元,其库存金额系数为1.5。将备件的平均库存金额转换为库存金额系数,消除了备件单价的影响,可以在同一维度上对比分析不同单价的备件。通过仿真可以得到100项备件在MGA模型和基础模型下的有货率与库存金额系数分布,如图12、图13所示。应用基础模型时,部分备件的库存金额系数大于4,有货率低于72%。为了便于对比分析,对图13中部分备件的库存金额系数和有货率进行了修正,当备件的库存金额系数大于4时,将其赋值为4,当备件的有货率低于72%时,将其赋值为72%。 图12 MGA模型效果网格分布图Fig.12 Grid distribution diagram of MGA model 图13 基础模型效果网格分布图Fig.13 Grid distribution diagram of basic model 图12中,越往左上方(即库存金额系数越低,有货率越高),其模型参数的效果越好,因此这几个区域按照从优到劣的排序为:A区域、B区域、C区域、D区域。应用MGA模型的效果如图12所示,其中92%的备件分布在A区域,8%的备件分布在B区域,0%的备件分布在C区域,0%的备件分布在D区域;应用基础模型的效果如图13所示,其中12%的备件分布在A区域,30%的备件分布在B区域,56%的备件分布在C区域,2%的备件分布在D区域。 MGA模型和基础模型的备件有货率、库存金额系数、年均采购次数分布如图14所示。在MGA模型中,所有备件的平均有货率为97.6%,平均库存金额系数为1.27,年均采购次数为0.83;在基础模型中,所有备件的平均有货率为83.6%,平均库存金额系数为1.88,年均采购次数为1.02。通过对比,MGA模型的各项指标均优于基础模型,且在各项备件样本间的波动范围更小。 图14 MGA模型和基础模型的仿真结果Fig.14 Simulation results of MGA model and basic model 为了进一步分析基于MGA模型得到的备件库存参数有效性,在确定备件库存参数后,通过调整备件的领用数量,测试MGA模型应对备件领用波动情形下的鲁棒性。首先使用MGA模型计算所有备件的最优库存参数,再调整每项备件的领用数量,基于图8中库存预测模型,计算存在领用波动情况下的库存金额和有货率分布情况。备件领用波动范围设置为±20%、±50%、±100%,计算公式如式(14)所示。例如某项备件在某个时刻的领用数量为10,在增加±20%波动影响后,其领用数量在[8,12]分布;在增加±50%波动影响后,其领用数量在[5,15]分布;在增加±100%波动影响后,其领用数量在[0,20]分布。 (14) 增加领用波动后,所有备件在不同模型下的总领用金额和有货率分布如图15所示。这批备件采购周期的平均值为9.6个月,标准差为3.3个月,在仿真的前8个月中,备件首次触发的正订采购到货验收比例较低,备件的领用数量大于到货验收数量,备件消耗后未能有效补货,因此备件的库存金额和有货率都呈现下降趋势。在仿真8个月以后,前期触发的正订采购到货验收比例升高,备件的到货验收数量大于领用数量,因此备件的库存金额和有货率都呈现上升趋势。在仿真20个月以后,备件的到货数量与领用数量处于动态平衡中,因此备件的库存金额和有货率均在一定范围内进行波动。基础模型中部分备件的库存参数值过高或过低,当备件的库存参数过高时,采购到货后无法在短期内被完全领用,导致库存金额持续处于高位;当备件的库存参数过低时,备件储备量不足,经常出现缺货情况,导致有货率持续处于低位。 图15 领用波动的影响Fig.15 The influence of materials requisition fluctuations 当使用原始领用数据计算出备件的库存参数后,若备件后续的领用数量发生变化,则其库存金额指标和有货率指标都会变差,具体数据如表4所示。若领用无波动,使用MGA模型计算的库存参数,在将所有备件的库存金额控制在105万元的情况下,平均有货率可以达到97.6%。当引入领用波动时,整体库存金额会上升,整体有货率水平会降低。通过对比MGA模型和基础模型,当给MGA模型增加了±100%的领用波动时,其库存金额指标和有货率指标均优于未增加领用波动的基础模型。 表4 增加领用波动后的备件总库存金额与有货率数据Table 4 The influence of adding requirement fluctuations 设计一种改进的遗传算法用于解决核电备件库存参数优化问题。通过建立核电备件库存策略模型评价方法,基于备件库存预测模型、适应度值评价模型,将备件的库存参数作为待求解变量,库存参数评价分数作为适应度值,使用改进遗传算法寻找备件的最优库存参数。 经过对大亚湾核电厂100项备件进行仿真测试,改进遗传算法可以有效计算出核电备件的库存参数,通过引入该批备件在数据库中库存参数进行对比分析,使用改进遗传算法计算的备件库存参数,其库存金额指标和有货率指标均优于当前数据库中的参数。为测试改进遗传算法计算的备件库存参数应对备件领用波动情形下的鲁棒性,增加了3组领用波动对照试验,当引入领用波动时,整体库存金额会上升,且随着波动幅度的增加,平均有货率会逐渐降低。在增加±20%、±50%、±100%的领用波动时,使用改进遗传计算的库存参数均优于备件当前数据库中的库存参数。 当前备件库存预测模型中,备件的预留数量设置为0,通常情况下,提前对备件进行预留会提高备件的库存金额和有货率,因此备件预留对备件库存参数设置都有一定的影响,后续可进一步将研究不同类型备件预留设置方案,以及备件领用数量、备件预留、备件库存参数之间的关系。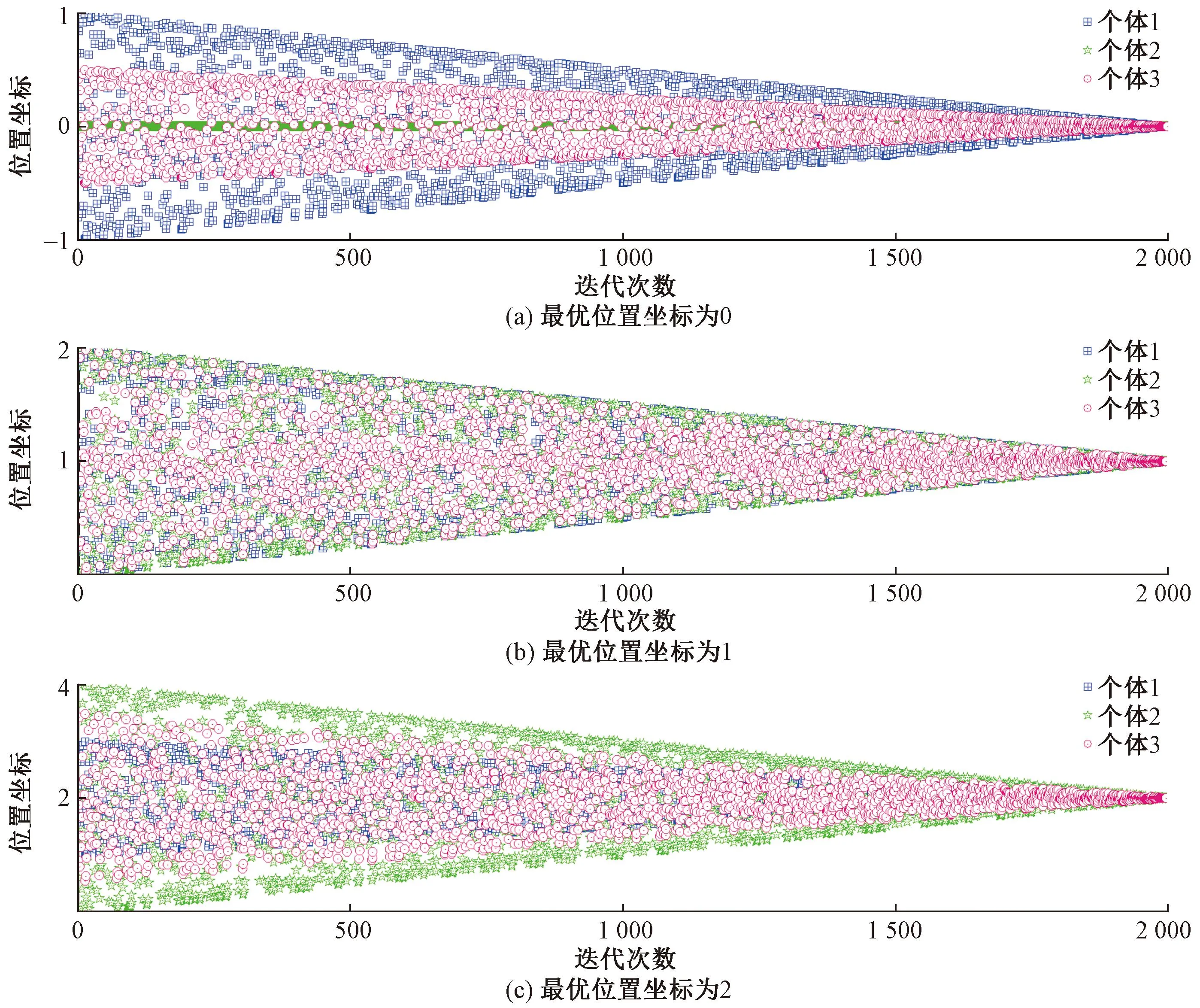
1.2 基准测试函数
1.3 性能测试结果

2 备件库存参数优化模型
2.1 备件库存预测模型
2.2 适应度值评价模型
2.3 优化算法模型
3 仿真分析


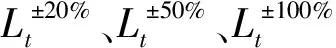

4 结论与展望
猜你喜欢
水泥技术(2023年4期)2023-09-07
计算机仿真(2022年8期)2022-09-28
水泥技术(2022年4期)2022-07-27
科学与信息化(2019年34期)2019-10-21
活力(2019年15期)2019-09-25
今日财富(2018年26期)2018-05-14
中国核电(2017年1期)2017-05-17
当代经济(2016年2期)2016-12-30
中国塑料(2016年11期)2016-04-16
教育与职业(2014年16期)2014-01-19
