
遮挡条件下的步态图像时空修复网络及其应用
2024-01-22 10:27阳强罗坚黄宇琛
中国图象图形学报 2024年1期
阳强,罗坚,黄宇琛
湖南师范大学信息科学与工程学院,长沙 410000
0 引言
步态识别可以通过人的走路方式来判别身份,具有采集方便、不易伪装等优点(贲晛烨 等,2012),该技术在医疗、体育和安防等领域有着广泛的应用前景,可以用于个体识别、疾病诊断、运动分析和安全管理等方面。
目前公开的步态数据集所提取到的步态轮廓都存有缺失的情况,但绝大部分步态识别研究方法都是隐式的基于完整的步态轮廓序列。然而在实际应用中,监控捕捉到的行人轮廓很可能是被遮挡的轮廓图像,如图1 所示,行人被识别对象被横幅、墙遮挡以及人与人相互遮挡等,这些限制因素的存在会使得提取轮廓的过程更加复杂,甚至难以提取到完整的步态轮廓序列。

图1 实际应用中的3种遮挡情况Fig.1 Three occlusion scenarios in real-life application((a)pedestrian is occluded by a banner;(b)pedestrian is occluded by the wall;(c)pedestrians are occluded by each other)
对遮挡步态的处理可以分为两种,一种是无需重建步态轮廓直接进行识别;另一种是将步态轮廓修复后用于识别。
在无需重建的方法中,大部分通过使用对遮挡具有鲁棒性的步态特征来提高识别率。Ortells 等人(2017)提出了一种稳健的统计方法,对步态能量图(gait energy image,GEI)、梯度直方能量图(gradient histogram energy image,GHEI)等几种步态表示方法使用加权平均值,而不是直接求平均,从而降低遮挡对平均模板等步态表示方法的影响。Nangtin 等人(2016)使用非遮挡区域进行步态识别,该方法将一个步态能量图分解为6 个模块,将GEI 按比例从上到下分为4个模块,其中上下3个相邻模块耦合形成另外2 个模块,识别时将存在遮挡的模块排除分别使用其余模块来识别。上述从步态轮廓中提取稳健特征的方法都需要在步态周期确定或完整的情况下才能使用,然而当步态序列发生遮挡时,步态周期并不能够准确地检测出来。Chattopadhyay 等人(2015)利用正面和背面两个视角的深度摄像机Kinect来获取受试者的步态序列,通过对齐的方式从骨骼信息提取动态特征信息来进行步态识别,验证了骨骼运动信息中对于遮挡的鲁棒性。Choi等人(2019)根据序列中每帧的完整性来为每帧分配不同的权重,以此来增强骨架对遮挡步态的鲁棒性。Chikano 等人(2021)提出了一种根据图像的遮挡部分自适应地选择要使用的特征组合来实现高精度验证的方法。许文正等人(2023)在综述中提出了通过解纠缠表示学习方法来增强对遮挡鲁棒性的可能性。
基于重建的步态识别方法中,大部分方法是基于步态轮廓序列的修复。Lee 等人(2009)通过在身体的手、脚和膝盖等处放置标记来检测是否有遮挡,并且提出了3 种不同的缺失帧重建技术。第1 种方法使用几何方法—多项式内插;第2 种方法使用基于随机线性时间序列的自回归预测;第3 种方法使用Papoulis 提出的凸集投影(projection onto convex sets,POCS)的方法。Uddin 等人(2019)针对整个序列都被部分遮挡的场景,通过端对端的方式,使用由三维卷积神经网络(3D convolutional neural network,3DCNN)组成的WGAN(Wasserstein generative adversarial network)网络来修复遮挡帧。Das 等人(2020)利用VGG16(Visual Geometry Group network)模型对序列中每一帧进行遮挡检测,利用帧与帧之间的连续性,使用完全卷积长短期记忆网络(fully convolutional long short-term memory network,FC-LSTM)重建遮挡帧。Kumara 等人(2021)使用关键姿势来修复遮挡帧,该方法构造了一个通用的关键姿势序列数据库,将遮挡序列的关键姿势序列与关键姿势数据库中进行匹配,获得一个最匹配的关键姿势序列,然后将关键姿势作为辅助信息嵌入到轮廓序列中,利用双向长短期记忆网络(bi-directional long shortterm memory network,BiLSTM)组成的网络来重建VGG 网络检测出的遮挡帧。这两种使用长短期记忆网络(long short-term memory network,LSTM)来修复步态序列的方法无法在整个步态序列都存在遮挡的情况下修复序列。Babaee等人(2018)提出了完全卷积神经网络(fully convolutional networks,FCNN)来修复不完整步态周期下的GEI。Babaee 等人(2019)给FCNN 加了两个判别器来优化网络。一个判别器判断修复的序列是否完整;另一个判别器判断修复序列和真实序列是否属于同一对象。上述两种修复GEI 的方法在步态周期中只有少数几帧时修复效果不是太理想。Gupta 和Semwal(2022)使用不同的内插方法和曲线拟合方法来修复因遮挡而Kinect摄像机没有获得的缺失关节数据。
为了修复步态序列中的遮挡区域并保持身份信息不变,本文提出了一种基于先验知识的步态时空序列重建网络(gait spatio-temporal reconstruction network,GSTRNet)。通过在多个数据集上进行实验评估,对不同遮挡程度、不同遮挡类型的遮挡序列,本文方法比当前的步态序列修复方法有更好的修复效果。
本文主要工作和贡献如下:1)使用目前主流的Transformer对深层特征进行时空信息的修复;2)使用YOLOv5(you only look once version 5)网络(Bochkovskiy等,2020)来检测序列中每帧的缺失区域作为先验知识,通过定义孔洞损失和非孔洞损失融合的联合重建损失函数,重点对局部遮挡区域进行修复,有效保留未遮挡区域信息;3)使用Gaitset(Chao等,2019)网络来提取三元组特征损失,在修复步态序列轮廓的同时保持其身份信息的一致性;4)在OU_MVLP(OU-ISIR gait database,multi-view large population dataset)数据集上进行了广泛的实验评估,对现实中常见的遮挡模式进行了测试,相比其他方法识别率有较明显提升。
1 本文方法
1.1 概况
本文提出了GSTRNet,GSTRNet 的总体架构如图2 所示。整个架构由3 部分组成:时空编解码器、遮挡检测网络(YOLOv5)和特征提取网络(Gaitset)。
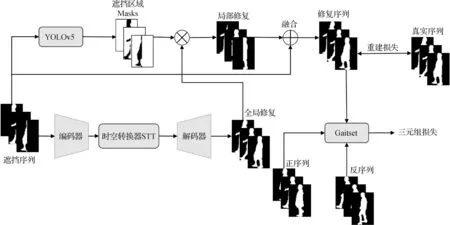
图2 GSTRNet架构Fig.2 Overview of GSTRNet
修复网络在训练阶段采用三元组输入,包括遮挡序列(Occlusion序列)、正序列(Genuine序列)和反序列(Imposter 序列),3 个序列的大小相同。Occlusion 序列是被遮挡需要修复的序列,Genuine 序列是和Occlusion 序列属于同一受试者的未遮挡的轮廓序列,但该序列和Occlusion 序列的真实序列(ground truth,GT)不是同一段序列,Imposter 序列是和Occlusion序列属于不同的对象。
首先将遮挡步态图像序列送入编码器,先后经编码器、Transformer 和解码器网络,得到全局修复步态图。同时,使用训练好的YOLOv5网络检测Occlusion 序列中每一帧的遮挡部分作为局部修复的先验知识。然后,使用先验知识从解码器输出得到遮挡区域的局部修复结果。最后,将局部修复的步态图与原始遮挡步态图中的未遮挡部分信息相融合,得到完整的步态图像修复序列。融合后的步态图既完成了遮挡修复,又最大限度地保留了原始步态轮廓数据。
1.2 遮挡检测网络YOLOv5
1.3 时空编解码器
遮挡序列修复网络遵循编码解码器的架构,如图3 所示包括3 个组件:编码器(encoder)、时空转换器(spatio-temporal Transformer,STT)和解码 器(decoder),使用端对端的方式对遮挡序列进行修复,步态序列是一种时序数据,因此在对遮挡序列修复时,不仅需要修复每一帧中缺失的区域,而且修复的帧要保持运动上下文信息不变。Zhang 等人(2019)使用3 层LSTM 在时间序列中聚合这些姿势特征以生成最终步态特征;Fan 等人(2020)利用一维卷积神经网络(1D convolutional neural networks,1DCNN)来提取局部时间线索;Lin 等人(2020)通过3DCNN 来提取小时间尺度和大时间尺度的时空信息。上述方法说明了1DCNN、LSTM 和3DCNN 能够有效处理步态序列的时间信息。本文使用3DCNN网络构造时序编码—解码器,3DCNN 可以在修复序列中的每一帧空间信息的同时修复帧之间的时序信息,同时具有较好的数据并行能力。为了训练更稳定和更快的收敛,本文使用He等人(2015)的方法来初始化神经网络参数。
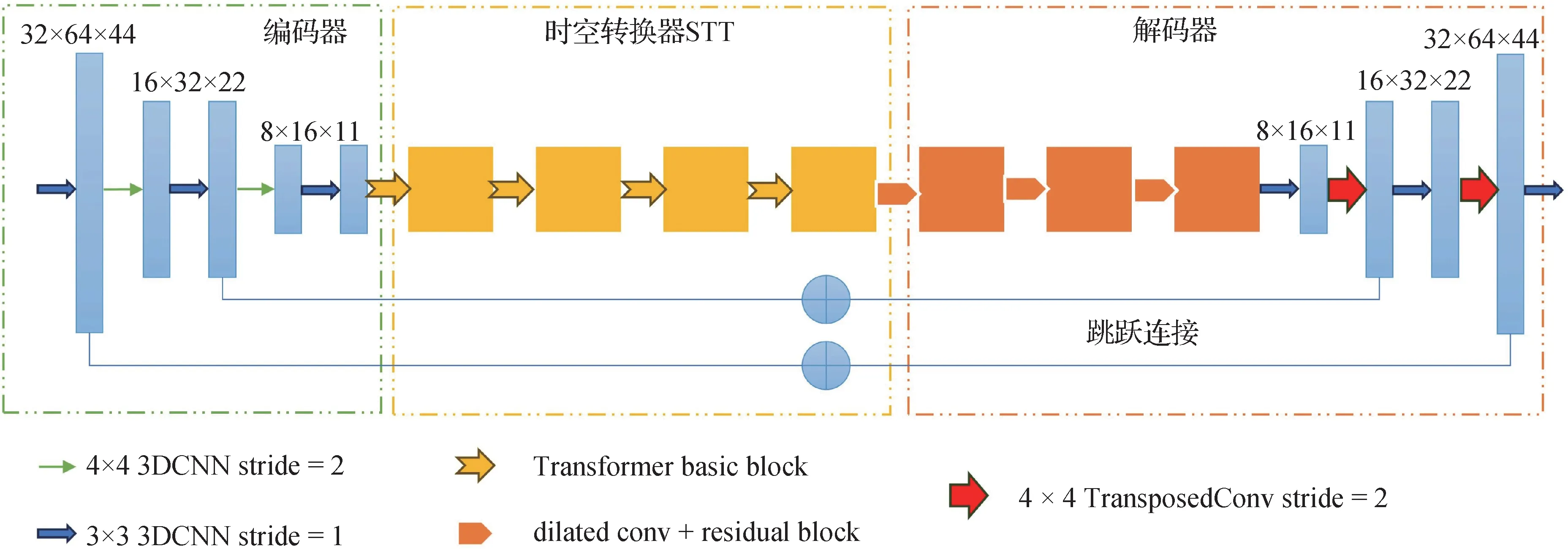
图3 遮挡序列修复网络Fig.3 Illustration of the architecture of occlusion sequence reconstruction network
1.3.1 编码器
编码器Encoder 首先对遮挡序列进行卷积,获取具有时空信息的低维特征f。
Encoder 由一个kernel 为3 × 3 × 3、stride 为1 × 1 × 1 的卷积层和两个卷积块组成,每个卷积块由一个kernel 为3 × 3 × 3、stride 为1 × 1 × 1 的卷积层后接一个kernel 为4 × 4 × 4、stride 为2 × 2 × 2 的卷积层组合而成,卷积核的个数也由64增长到256,每个卷积层中都使用批归一化(batch normalization,BN)和ReLU 非线性激活。使用stride 为2 的卷积来代替池化层,这样可以在图像下采样的时候让每一个元素都参与进来,保留更多的细节信息,同时在每次下采样之前都首先进行一次卷积,以便保留更多的时间信息。
1.3.2 STT
本文和Weissenborn 等人(2020)一样以中间特征f作为Transformer 的输入。在编码器和解码器之间加入一个时空转换器STT,通过STT 可以在全局范围内对步态帧缺失部分进行空间信息和时间信息的修复,适当地减少模型的参数量。
STT 由4 个Transformer block 组成,如图4(a)所示,Transformer block 分为多头注意力(MultiHead)和多层感知机(multi-layer perceptron,MLP)两个子层。MultiHead 结构如图4(b)所示,MultiHead 是一种多尺度的自注意力模块,headi(hi)对应不同尺度的注意力操作,设计不同尺度的注意力可以从局部和全局获取时空信息来修复遮挡部分。MLP 子层使用两个kernel 为3 × 3、stride 为1 的2D 卷积残差块处理多头注意力的时空特征。图4 中⊕代表残差连接 。

图4 转换器块和多头自注意力Fig.4 Transformr block and multihead((a)Transformr block;(b)MultiHead)
每个MLP 子层中,将上一层输出的低维特征作为该层的输入其中,t,h,w,c分别表示低维特征的时间维度、高度、宽度和通道数。在c维度等分为n个特征n为多头注意力中head的个数,每个特征作为对应MultiHead中的hi的输入,在hi中首先被映射为qi、vi和ki。qi,vi,ki分别对 应注意 力机制中的query、value 和key。具体为
然后,qi和ki进行矩阵相乘获得注意力,最后将注意力作为权重和vi矩阵相乘作为hi的输出,具体为
式中,σ代表softmax 激活函数,“·”表示矩阵的乘积,size表示qi中元素数量。
将所有hi输出进行特征拼接后与做残差连接,经卷积和激活函数就得到MultiHead 的输出,其中t,h,w,c值与相同,具体为
式中,ρ代表Leaky ReLU(leaky rectified linear unit)激活函数,3_2C代表kernel 为3 的二维卷积神经网络(2D convolutional neural network,2DCNN),concat表示在通道数维度进行拼接。
1.3.3 解码器
解码器Decoder 首先用3 个由膨胀卷积组成的残差块,然后采用交替排列的3层卷积和2层反卷积层,kernel 与stride 和Encoder 一样,除最后一层外,所有卷积层都经过批归一化和ReLU 非线性激活,最后一层卷积层之后使用Tanh 激活函数将数据都映射到[-1,1]之间来保持和输入数据范围的一致性。使用跳跃连接的方式将编码器和解码器中的特征混合,减缓编码过程中下采样时的细节损失,并将梯度消失问题的影响降至最低。
式中,⊙表示元素点乘。
1.4 特征提取网络Gaitset
对于训练时的B×V(B是受试者对象数,V是每个受试者的步态序列数)在计算三元组损失Lt时的计算为
式中,i和j表示第i个和第j个受试者,α和β分别为第i个受试者的第α和β个序列,γ为第j个受试者的第γ个序列,表示三元组中正样本对的相似度,表示负样本对的相似度,margin表示三元组损失的边界距离。
1.5 损失函数
本文使用修复序列的重建损失Lr和三元组损失Lt作为联合损失来对网络进行修复。通过优化Lr来保持修复序列和原始序列内容上的一致性,具体为
式中,为遮挡序列的原始未遮挡序列,Lr被先验知识分为孔洞区域损失Lh和非孔洞区域损失Lv,γh和γv分别为Lh和Lv的损失权重。使用Lt来使得修复序列的特征和原始序列保持一致性。联合损失L的计算为
式中,ωr和ωt分别为Lr和Lt的损失权重。
2 实验和分析
为评估本文方法对各种遮挡步态序列的修复效果,使用公共数据集OU_MVLP(Iwama 等,2012)进行验证。在OU_MVLP 中,使用3组实验来评估本文方法,分别为遮挡模式已知,gallery 和probe 遮挡模式一致;遮挡模式已知,gallery 和probe 遮挡模式不一致;遮挡模式未知。
2.1 遮挡模式
本研究使用Uddin 等人(2019)的遮挡类型来构造Occlusion序列,即相对动态遮挡、相对静态遮挡和随机遮挡,遮挡程度分为30%、40%和50%这3 种情况。相对动态遮挡分为从左到右(relative dynamic occlusion from left to right,RDLR)和从下到上(relative dynamic occlusion from bottom to top,RDBT)类型,RDLR 在现实中类似于被树或电线杆等物体遮挡,通过设置一个垂直方向的符合遮挡范围大小的掩码区域(遮挡区域设置为0),首先覆盖一个人从右向左行走的轮廓序列中第一帧的最右侧,然后逐渐移动掩码的位置,最终掩码位于最后一帧的最左侧,从而完成了从左到右的相对动态遮挡的模拟实现。类似地,通过设置一个水平方向的掩码从下到上滑动模拟实现RDBT。对于相对静态遮挡,在一个步态序列中的所有帧的固定位置设置掩码,本文模拟了底部(relative static occlusion in bottom,RSB)、顶部(relative static occlusion in top,RST)、左侧(relative static occlusion in left,RSL)和右侧(relative static occlusion in right,RSR)位置的相对静态遮挡。对于随机遮挡,分为水平随机遮挡(relative occlusion vertically,RandV)和垂直随机遮挡(relative occlusion horizontally,RandH)。水平随机遮挡通过在步态序列的每一帧中随机水平方向设置掩码;垂直随机遮挡通过在垂直方向随机来模拟实现。总共模拟了24 种遮挡模式。图5 显示了50%遮挡程度的各种模拟遮挡轮廓序列。在图5 中,图左侧为遮挡模式,英文简写代表遮挡类型,数字代表遮挡程度。

图5 OU_MVLP中的模拟遮挡Fig.5 Example of simulated occlusion in the OU_MVLP
2.2 数据集
OU_MVLP数据集包含10 307名受试者,每个受试者有14 个观察视角,且每个视角包含两个序列(00序列和01序列),是目前公布最大的具有广泛视角变化的步态数据集。
在本文中,该数据集测试协议与Uddin 等人(2019)一样,从10 307 个受试者去除只包含一个序列的受试者,选择9 001个受试者的侧面视角进行实验。将9 001 个受试者随机分为3 个大小大致相等的互不相交的集合:3 000 个训练组、3 001 个验证组和3 000个测试组。然后,将验证集和测试集分为两个子集:gallery 集和probe 集。验证集用于选择实验中识别性能最好时的迭代次数n,而测试集用于评估本文方法和其他最新方法的准确性。
OU_MVLP数据集提供的是黑白轮廓图像,首先提取步态对象的重心和步态轮廓的顶部、底部和水平中心来归一化大小,获得64 × 64 像素的黑白轮廓序列。然后在训练时进一步裁剪,最终生成了64 × 44像素的轮廓图像送入网络。
Occlusion 序列从受试者的00 序列选取连续的32 帧,然后如图5 模拟实现在序列中相应的位置将元素值改为0;Genuine 序列从同一受试者的01 序列选取连续的32 帧;Imposter 序列为batch 中其他受试者的序列;Genuine 序列和Imposter 序列都是未遮挡的序列。每个序列都从1 号图像开始选取,如果一个序列的帧数少于32,就重复最后一帧使序列保持一致。
2.3 训练细节
本文使用B×V为4 × 2 的batch_size 进行训练网络,N设置为32,采用Adam 随机优化方法,Adam中的α和β为0.5 和0.999,学习率l为0.000 1,Gaitset 网络中的其余设置与原来的网络一样,公式中的margin值为0.2,损失权重γh和γv的值为5 和1,ωr和ωt的值都为10。
2.4 对比方法和评判标准
本文中对遮挡步态序列的修复效果检验是将修复后的步态序列使用对应数据集的评估方法;健壮性测试通过将遮挡的步态序列直接送入步态识别网络,判断识别率高低。
由于只有三元组视频生成对抗网络(sequence video Wasserstein generative adversarial network based on triplet hinge loss,sVideoWGAN-hinge)(Uddin 等,2019)在OU_MVLP 中做了步态修复的工作,本文额外使用视频生成对抗网络(generative adversarial network for video,VideoGAN)(Vondrick等,2016)、改进的视频生成对抗网络(improved video Wasserstein generative adversarial network,iVideoWGAN)(Kratzwald等,2018)等方法来修复步态序列,并与GSTRNet 比较修复效果,同时测试Gaitset网络、上下文感知学习网络(context-sensitive temporal feature learning,CSTL)(Huang 等,2021a)和3D局部卷积网络(3D local convolutional neural networks,3DLocal)(Huang 等,2021b)对遮挡序列的健壮性。
GEI 是步态识别中使用最广泛的特征,并且可以达到很好的识别准确率,本文与Uddin 等人(2019)一样,将GEI 作为步态特征来进行评估修复效果。本文通过在修复后的轮廓序列中获取一个周期内的轮廓序列并平均受试者的轮廓图像序列来构建 GEI。本文使用归一化自相关方法(Iwama 等,2012)来检测步态周期。归一化自相关函数为
式中,N为序列中帧的数量,w和h分别为步态帧的宽和高,C(n)表示每个步态帧与间隔n帧的步态帧之间的相似度之和,x和y分别表示图像中的第x列和第y行,g(x,y,i)表示第i帧中(x,y)处的元素值。由于步态序列在某种程度上是一种周期运动,所以通过C(n)的峰值来确定步态周期。如果检测到多个步态周期,那么选择第1 个步态周期。最后,计算两个GEI(即probe和gallery)之间的欧氏距离来判断相似度。通过计算所有测试样本的Rank1 和Rank5级别的识别率来判断修复方法的优劣。
2.5 遮挡模式已知,galley和probe遮挡模式相同
针对两种相对动态遮挡类型(RDLR 和RDBT)下30%和50%的遮挡程度进行实验,因此准备了4种模式:RLDR_30(RLDR表示遮挡类型,30代表遮挡程度)、RDLR_50、RDBT_30、RDBT_50。由于gallery 和probe 的遮挡模式相同且已知,修复网络训练时只选择一种遮挡模式下的步态序列进行训练100 K 次,测试时probe 和gallery 都采用与训练时一样的遮挡处理。
由于数据集较大且遮挡程度较高,实验提升效果根据遮挡条件会有差异。OU_MVLP 数据集上使用真实序列Rank1 和Rank5 识别率分别为88.5%和92.3%。
从表1 中数据可知,本文GSTRNet 在OU_MVLP数据集上Rank1 识别率比sVideoWGAN-hinge 在RDLR_30、RDBT_30、RDBT_50 遮挡模式下分别有4.1%、3.4%、3.1%的提升,但是在RLDR_50的遮挡情况下提升不明显;在RDLR_50 大面积遮挡模式下识别率GSTRNet比3DLocal网络仅有1.6%的提升。
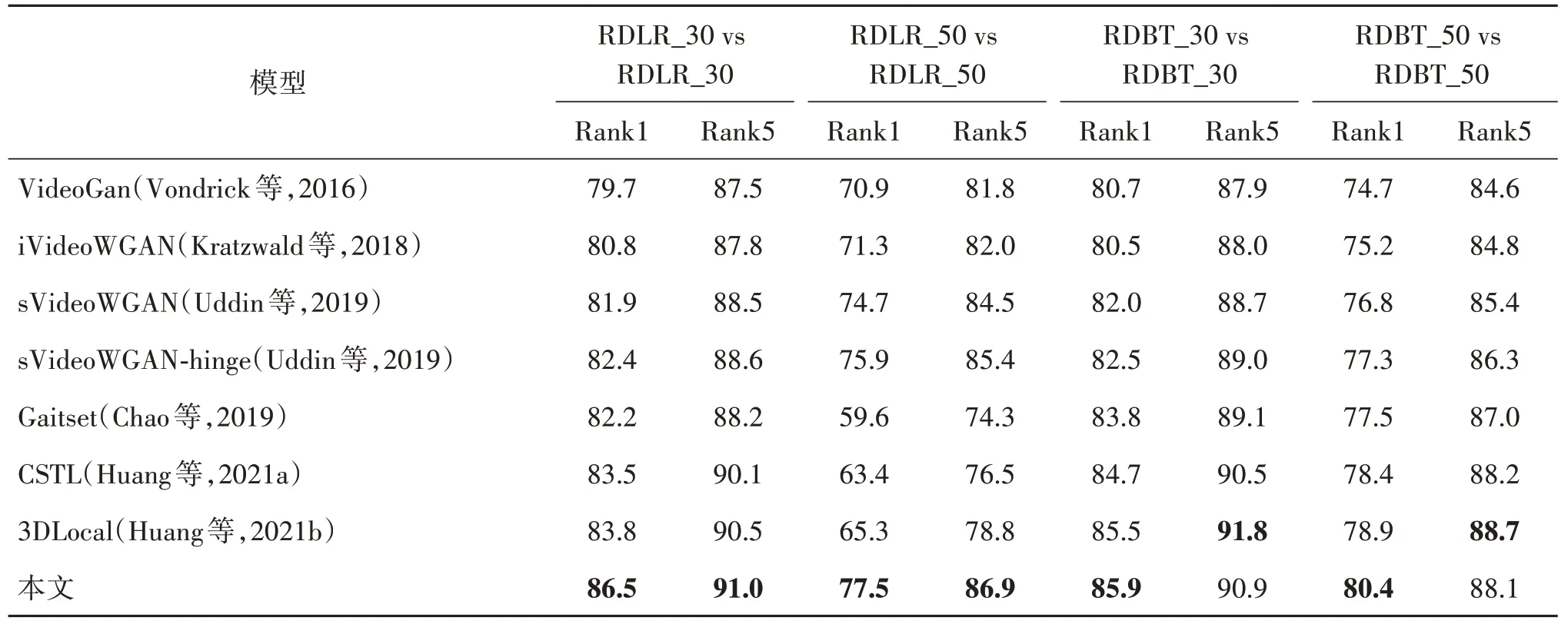
表1 遮挡模式已知,遮挡模式一致下的Rank1和Rank5Table 1 Rank1 and Rank5 for the experiment for known and same occlusion mode/%
根据上述分析,可知本文方法在单一遮挡模式下相比其他的修复网络效果有明显提升;遮挡程度大的序列修复效果都要低于遮挡程度小的序列修复效果,这是因为归一化之后的步态序列中每帧的缺失信息重合率高,3DCNN 无法从上下帧和遮挡区域的周围元素获得信息来填充遮挡区域。
2.6 遮挡模式已知,gallery和probe遮挡模式不同
该组实验中,gallery 和probe 的遮挡模式不一致,训练时需要每个batch在已知的遮挡模式中随机选择遮挡模式进行训练,训练迭代次数也是100 K,测试时gallery 和probe使用不同的遮挡处理,然后进行修复识别。实验中考虑了遮挡类别相同但遮挡程度不同(RDLR_30、RDLR_50)和遮挡类别不同且遮挡程度也不同(RDLR_30、RDBT_50)两种情况,实验结果如表2所示。
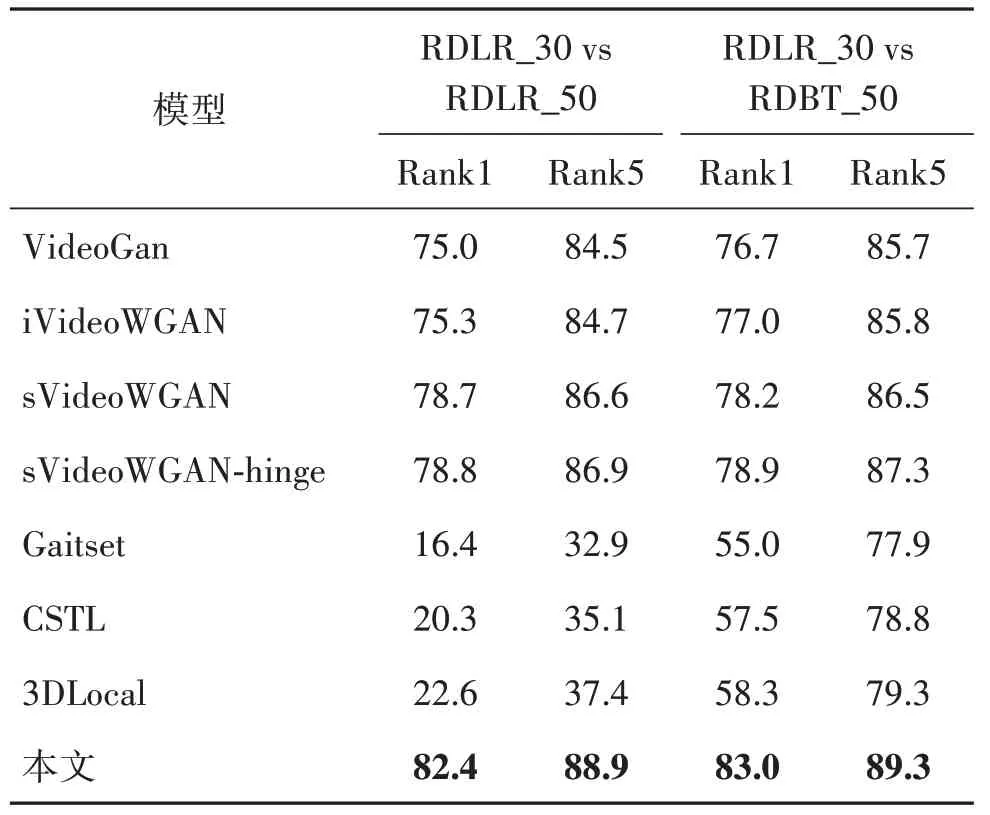
表2 遮挡模式已知,遮挡模式不一致下的Rank1和Rank5Table 2 Rank1 and Rank5 for the experiment for known but different occlusion mode/%
观察表2 结果可以发现,GSTRNet 比sVideoWGAN-hinge 在两种情况下Rank1 识别率分别有3.6%和4.1%的提升,相比3DLocal 网络有59.8%和24.7%的提升。与表1 结果比较可知,相同遮挡类型时,随着遮挡程度变大,序列修复效果会降低,3DLocal网络等方法在两种遮挡模式下识别率急剧下降,说明3DLocal网络等方法只有在gallery和probe 都是同一遮挡模式且遮挡程度低时才有较高的识别率。
2.7 遮挡模式未知
2.7.1 遮挡模式随机
前面实验都是在遮挡模式已知情况下,训练时只需要针对知道的遮挡情况进行训练即可。然而,现实应用中由于步态识别是采取不合作的方式,那么一个人的步态是否被遮挡、是何种模式的遮挡就无法确定,因此在本组实验中,本文使用所有的24种遮挡模式对网络参数进行训练,以便其对任何一种遮挡模式都有一定的修复效果,并且可对未知遮挡模式下的识别率进行验证,训练时迭代200 K次。
测试过程选择Cooperative 和Uncooperative 设置的实验来验证本文方法的可应用性。
测试时,Uncooperative 实验时每个受试者的probe从24种遮挡模式中随机选择一种,gallery 从中随机选择5组遮挡模式;Cooperative实验时每个受试者的probe 序列随机选择一种遮挡和gallery 序列选择原始序列进行评估。实验结果如表3所示。
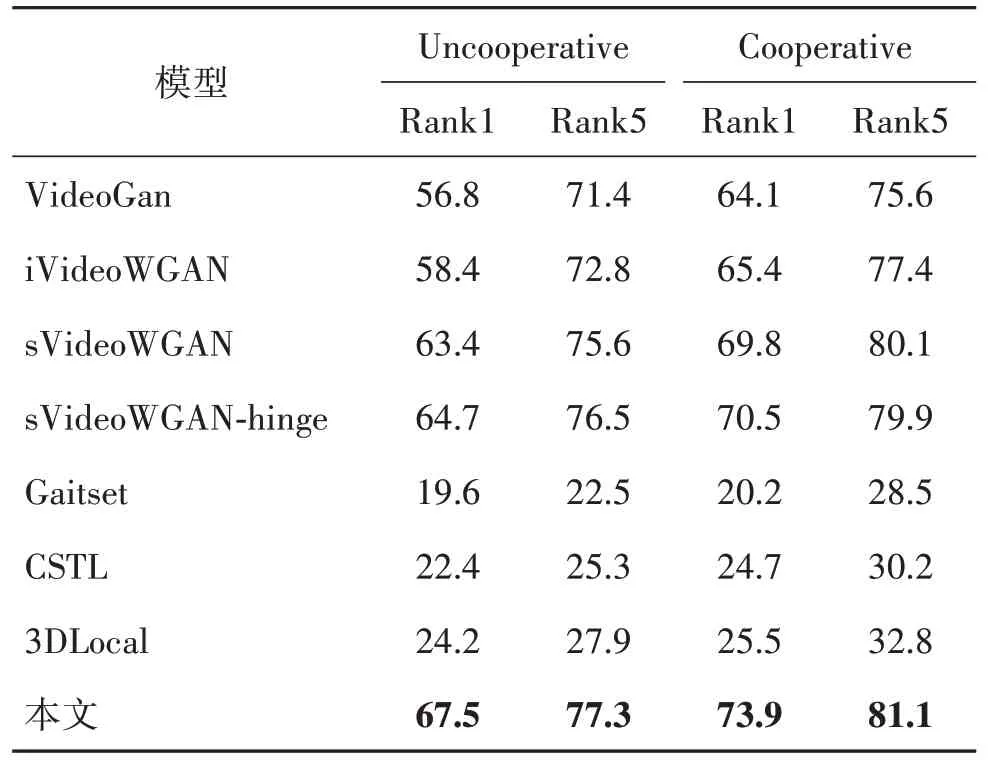
表3 遮挡模式未知,Cooperative与Uncooperative下Rank1和Rank5识别率Table 3 Rank1 and Rank5 for unknown occlusion mode under Cooperative and Uncooperative setting/%
根据表3结果可以发现,Cooperative实验下的识别率要高于Uncooperative 实验下的识别率;本文GSTRNet 相比sVideoWGAN-hinge,Rank1 识别率分别有2.8%和3.4%的提升;未知遮挡模式时,3DLocal 网络识别性能较差,GSTRNet 将遮挡步态序列修复后再用于Gaitset 识别有明显的提升效果,说明将修复网络应用在生活中具有较强的可行性。
2.7.2 遮挡模式未知,gallery 和probe 遮挡一致与不一致
验证遮挡模式未知情况下gallery 和probe 使用相同或不同遮挡模式的识别率。使用RDLR_30 作为probe 遮挡模式,gallery 分别选择RDLR_30、RDLR_50、RDBT_30、RDBT_50 遮挡模式和GT 未遮挡序列,分为5 个测试子集。实验结果如表4所示。
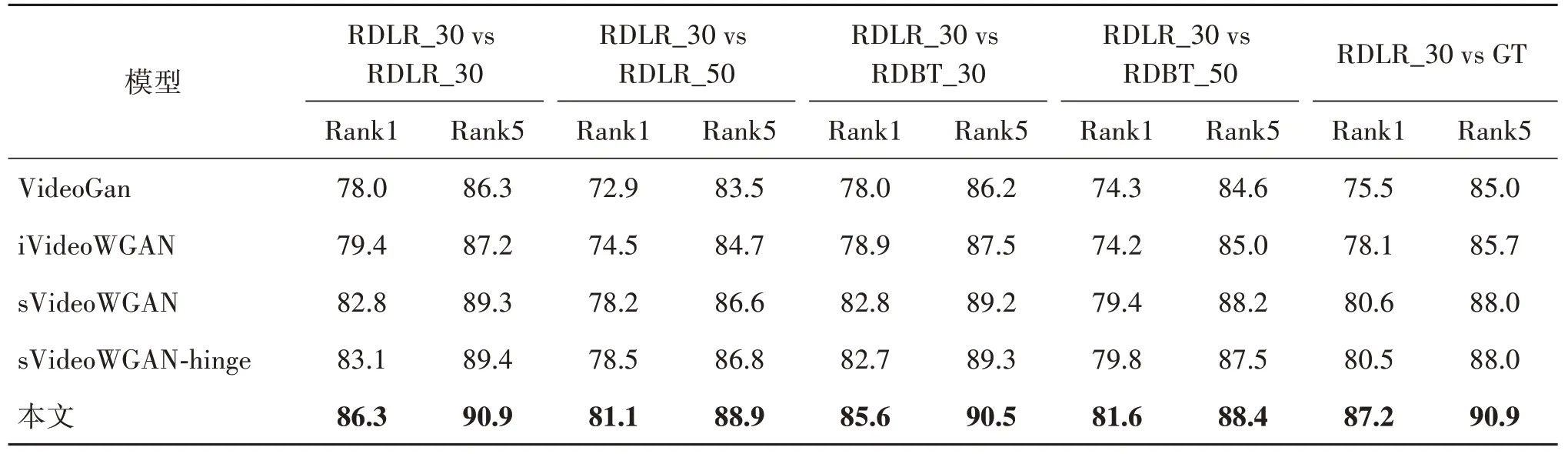
表4 遮挡模式未知,遮挡一致与不一致Rank1和Rank5识别率Table 4 Rank1 and Rank5 for unknown and same or different occlusion mode/%
从表4 中结果可以发现,本文GSTRNet 相比sVideoWGAN-hinge 在5 个测试子集下Rank1 识别率分别有3.2%、2.6%、2.9%、1.8%和6.7%的提升;对比表1和表2中结果可知,由于遮挡未知时需要考虑的遮挡情况较多,GSTRNet 的修复性能提升比遮挡已知情况下要差,且各种方法在遮挡模式未知下的各种识别率都比遮挡模式已知的情况下要低。如本文GSTRNet 在遮挡已知的情况下RDLR_30 vs RDBT_50 中Rank1 识别率为83.0%,而在未知遮挡模式下测试时只有81.6%。
3 结论
针对步态识别中存在遮挡的问题,本文提出了基于3D 卷积神经网络和Transformer 的步态时空序列重建网络(GSTRNet),该模型通过3D 卷积神经网络提取时空特征,再利用Transformer 在低维时空特征中基于不同尺度获取时空信息来修复遮挡内容,在利用深层神经网络的高精度和泛化能力的同时减少模型参数数量,最终使用Gaitset 网络提取特征作为三元组损失,保证了修复序列与真实序列的特征一致,从而提高了修复后遮挡序列的识别率。该模型可以与任何步态识别系统集成,以提高在真实场景中出现遮挡时的识别性能。
在OU_MVLP 数据集上的实验结果表明,在各种遮挡模式下,本文方法相比目前主流的遮挡步态修复算法修复效果更好,与其他步态识别算法相比,该算法可以在整个序列存在遮挡或遮挡程度比较大的时候,不需要已知步态周期直接将遮挡步态序列用于识别。
然而,本文方法也有一些局限性,首先本文方法中使用YOLO 来检测遮挡轮廓图中的有效区域,然而实际应用中,步态识别的场景是基于RGB 图像,且识别场景可能比较复杂,不同行人检测和分割算法生成的步态轮廓图也不尽相同,导致YOLO 确定的掩码区域可能不稳定;其次,人工合成的遮挡数据都是基于侧面视图的,没有对不同视角下的遮挡数据进行训练测试;另外,在遮挡程度较大时修复效果并不很好。在未来的工作中,将围绕上述不足进行改进。一方面采用合适的语义分割网络从RGB 图像中来获取更准确的遮挡区域;另一方面调整网络结构,使其适应不同角度下的步态轮廓修复以及提高遮挡程度较大时的修复效果。
猜你喜欢
科学大众(2024年5期)2024-03-06
装备制造技术(2020年1期)2020-12-25
计算机工程(2020年3期)2020-03-19
制造技术与机床(2019年11期)2019-12-04
中国听力语言康复科学杂志(2019年3期)2019-06-24
电子制作(2018年18期)2018-11-14
自动化学报(2018年6期)2018-07-23
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
计算机工程(2015年4期)2015-07-05
