
图像重定向质量评价的研究进展
2024-01-22 10:25胡波谢国庆李雷达李静杨嘉琛路文高新波
中国图象图形学报 2024年1期
胡波,谢国庆,李雷达,李静,杨嘉琛,路文,高新波*
1.重庆邮电大学图像认知重庆市重点实验室,重庆 400065;2.广阳湾实验室重庆脑与智能科学中心,重庆 400064;3.西安电子科技大学人工智能学院,西安 710071;4.阿里巴巴集团,北京 100020;5.天津大学电气自动化与信息工程学院,天津 300072;6.西安电子科技大学电子工程学院,西安 710071
0 引言
随着互联网、智能技术以及各种传感设备的普及,图像和视频等多媒体内容在人们的生活中扮演着越来越重要的角色。人们可以随时随地使用不同的终端设备(例如手机、笔记本、平板电脑等)通过图像或视频来方便快捷地获取各类资讯。由于不同的终端设备有着不同的尺寸和分辨率,因此如何将同一幅图像在这些设备上完整地显示并保证较高的视觉质量成为学术界和工业界共同关注的问题。
图像重定向是指在尽量不破坏图像内容的情况下,对图像分辨率进行调整以适应多终端的信息获取(郭迎春 等,2022)。图像重定向可以应用于图像摘要、图像合成、照片拼接、图像重组以及自动裁剪等多种场景(Tang 等,2020)。具体而言,在相机和手机等设备中通常存储着大量的图像和视频,为了更好地展示内容,可以利用重定向技术对数据进行处理,生成能提供概要信息的缩略图和视频封面;蒙太奇作为电影电视惯用的拍摄手法,通过将多个镜头和不同片段剪辑在一起,从而突出片段之间的相互联系以达到意想不到的效果,重定向技术同样可以应用到图像或视频合成中,将多个输入的图像和视频进行重定向处理,并自动合并为单个固定分辨率或长度的输出,以达到蒙太奇的拼接效果。
传统的图像重定向算法通过一些简单的操作(例如缩放、裁剪等)来达到这一目的,但这类方法通常会造成视觉内容严重扭曲,重要信息的大量损失,难以获得观感舒适的重定向图像。为了弥补传统算法的性能劣势,研究人员提出了一系列更为先进的基于内容感知的图像重定向算法。这类算法主要考虑了视觉内容的重要性,其核心是基于符合人类视觉感知的重要度图来进行图像重定向(郭迎春 等,2022)。然而,受限于现有图像处理技术的发展和对人类视觉系统(human visual system,HVS)的理解,在图像重定向过程中不可避免地会导致图像失真。例如,对像素的重复删除或添加会导致图像出现锯齿形边缘、伪影等失真;对视觉内容的挤压和扭曲会造成图像内容的过度拉伸或丢失。重定向图像的失真不仅会导致图像信息的丢失,破坏图像的美感,而且低质量的重定向图像会极大影响人们的观感体验。如图1 所示,重定向导致了人脸面部的严重扭曲,很可能造成观看者的心理不适。因此,研究重定向图像的质量评价具有重要意义。

图1 图像重定向造成的扭曲失真Fig.1 Distortion due to image retargeting
图像质量评价(image quality assessment,IQA)是图像处理和计算机视觉的一个基础问题(鄢杰斌 等,2022)。通常情况下,IQA 可以分为主观评价和客观评价。主观评价即通过测试人员对图像的质量进行评估;而客观评价则是通过构建模型来准确、自动地预测和评估图像的质量。相较于前者,客观评价具有低成本、可复用和易部署等优点,因此现有研究主要集中在客观评价方法(方玉明 等,2021)。根据不同的视觉内容,可将现有的客观IQA 方法大致分为针对自然图像的IQA 方法和针对其他内容图像的IQA 方法(周玉 等,2022)。目前的客观IQA 研究主要集中于自然图像领域,即针对模糊、压缩、噪声等常见失真类型设计客观质量评价方法。随着前沿技术的发展,针对其他内容的IQA 研究(例如,屏幕内容图像(Yang 等,2021,2022)、立体图像(Yang 等,2019a;Sim 等,2022)以及自由视点图像(Ling 等,2021))也逐渐受到关注。尽管这些方法在相应的数据集上取得了一定的进展,预测结果与人类视觉感知具有一定的一致性,然而这些IQA 方法无法直接应用于重定向图像。主要原因在于:其一,重定向图像中的失真是经重定向技术处理后产生的算法失真,这些失真主要包括内容失真和几何结构失真两个方面,而传统的IQA 模型通常设计为用于处理模糊和噪声等传统简单的失真;其二,重定向图像的参考图像和失真图像的分辨率不一致,而现有的传统全参考和半参考质量评价方法通常是应用于相同分辨率的自然图像,因此分辨率不匹配是限制它们的又一因素。基于以上分析,有必要针对重定向图像的失真特性设计模型,来对其质量准确、客观地评估,这对图像重定向算法的设计、优化及选择等具有重要的指导意义。
事实上,图像重定向质量评价(image retargeting quality assessment,IRQA)已经受到科研人员的广泛关注。中国科学技术大学、天津大学和西安电子科技大学等科研院校纷纷加入到该项研究工作中。具体地,科研人员基于主观评价方法构建了MIT RetargetMe(Rubinstein 等,2010)、CUHK(CUHK retargeting subjective quality database)(Ma 等,2012)和NRID(NTHU retargeting image dataset)(Hsu 等,2014)等数据集,用以测试客观评价方法的性能。针对客观评价方法,基于不同技术和策略的IRQA 方法不断涌现,有效地促进了图像重定向技术的选择、优化以及发展。早期的IRQA 方法主要从重定向图像失真特性入手,设计能够有效表示图像质量的特征,通过计算原始图像和重定向图像的特征相似性或分布距离来量化图像质量。现有的IRQA 方法通常以图像配准为基础,建立原始图像和重定向图像之间的对应关系,并基于配准关系提取相应的特征来评价图像质量(Li等,2021)。因此,本文针对目前图像重定向质量客观评价的研究现状、优缺点及发展进行较为全面的综述。具体地,将现有的客观IRQA 方法分为两类:基于传统特征相似性的方法和基于图像配准的方法,并分别介绍其基本思想,分析其优缺点。随后,对现有算法的性能进行了比较和分析。最后,总结了当前图像重定向质量评价领域面临的问题和挑战,并指明了未来可能的发展方向。
近年来,国内外研究人员已经发表了多篇关于图像质量评价的综述文献,但截至目前没有专门针对图像重定向质量评价的综述。具体地,王志明(2015)、方玉明等人(2021)、鄢杰斌等人(2022)和程茹秋等人(2022)均从不同的角度对现有的IQA 模型及相关数据集进行了详尽的回顾和分析,但这些综述均未涉及对图像重定向质量评价领域发展的详细介绍。根据前文所述,IRQA 问题和传统的IQA 问题存在较大差异,为客观评价模型的设计带来了诸多困难。本文针对现有的IRQA 工作进行综述,将有望帮助在图像重定向及其质量评价领域的研究人员快速了解相关技术,并为其提出更高性能的方法提供指导。
1 相关工作
1.1 图像重定向算法
图像重定向是指在保持图像几何结构和内容完整性的同时调整图像的宽高比。早期的传统重定向算法主要通过窗口裁剪和均匀缩放来调整图像的分辨率。窗口裁剪的方法直接去除不重要区域获得目标图像;均匀缩放的方法则是通过最近邻域插值、双线性插值等方法改变图像的大小(郭迎春 等,2022)。这些算法虽然可以达到调整图像尺寸的目的,但它们仅仅考虑了图像的几何约束,而没有考虑图像的内容信息。因此这些简单的操作对图像的显著区域和重要信息区域造成了严重的破坏,很容易导致图像失真,其使用范围和应用场景具有极大的局限性。
在过去十余年里,内容感知的图像重定向算法逐渐受到研究者们的关注。围绕如何在重定向过程中保持视觉感知质量这一重要问题,研究者提出了大量内容感知的算法。这些基于内容感知的图像重定向算法一般采用两阶段的框架:第1 阶段,对输入图像计算其重要性图,为每个像素分配一个重要性权值,权重越高代表其应该被保留的概率越高;第2阶段,执行相应的图像大小调整方法,在满足几何约束的情况下,尽可能地保留图像的重要内容(郭迎春 等,2022)。如图2 所示,基于内容感知的图像重定向算法大致可分为4 类:离散方法、连续方法、多算子方法和基于深度学习的方法,下面分别对其进行介绍。
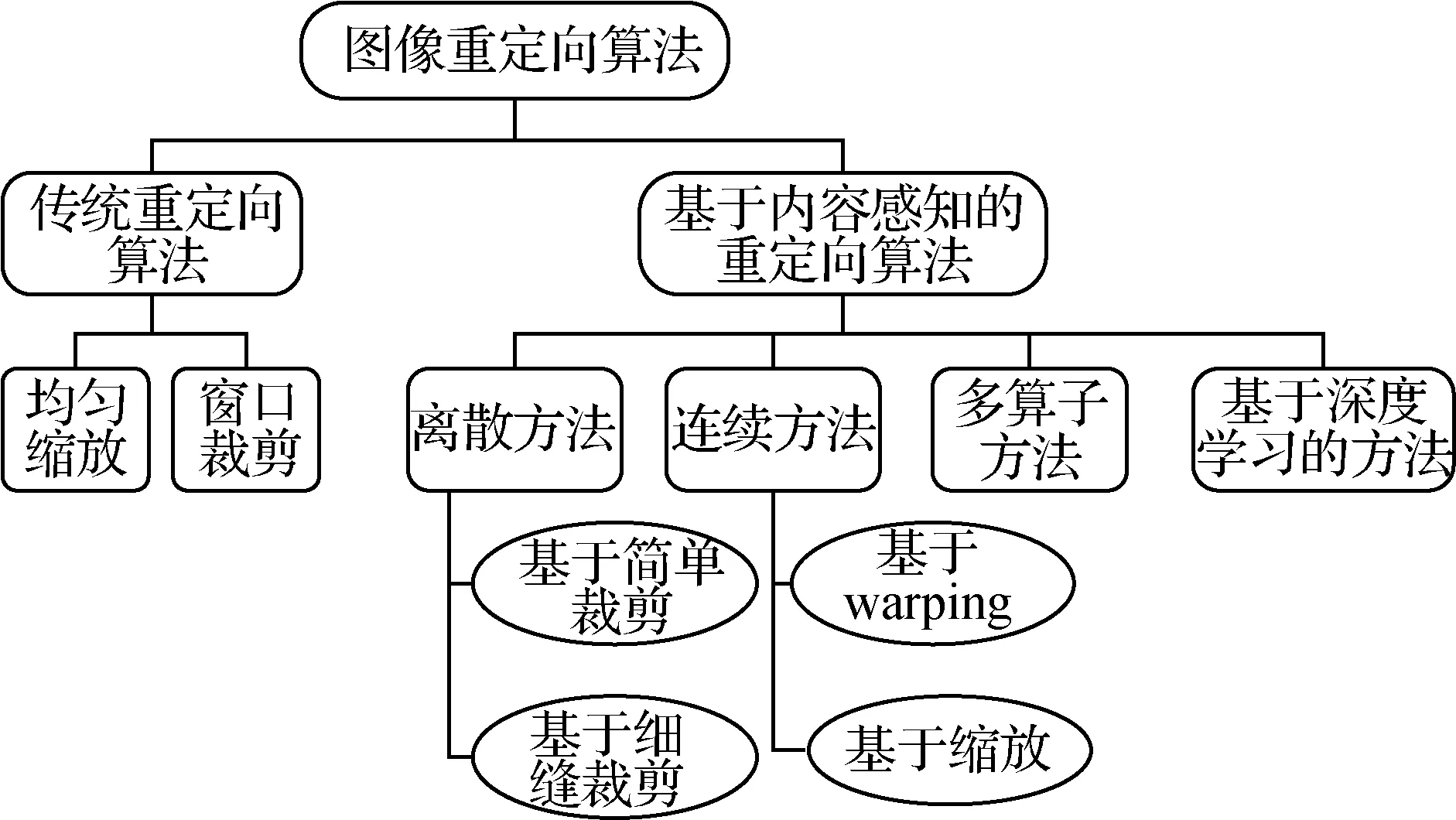
图2 图像重定向算法分类Fig.2 Classification of image retargeting algorithms
在离散方法中,直接通过相应的内容保留策略来决定图像像素的保留或去除。根据不同的图像内容保留策略又可将离散方法分为:基于简单裁剪的方法和基于细缝裁剪(seam carving,SC)的方法。基于简单裁剪的方法通常根据图像的内容重要性来选取裁剪窗口进行像素的移除。例如,Suh 等人(2003)的方法通过计算图像的显著性图,然后使用贪心算法搜索裁剪窗口的位置。类似地,Chen 等人(2003)的方法基于用户注意力来调整图像的大小以适应不同分辨率的设备。Santella 等人(2006)的方法根据眼动数据来获取图像的重要位置,以此来完成对图像的裁剪。内容感知的裁剪方法能够完整地保留图像的几何结构,但会造成裁剪窗口外的信息丢失,不适用于具有多个显著性目标的图像。基于SC 方法的基本思想是通过能量值来描述像素点的重要程度,并对连续像素点的能量进行累加,寻找图像中能量最低的细缝然后进行移除或插入,多次迭代直到图像的尺寸达到目标大小。Avidan 和Shamir(2007)将每个像素点的梯度值作为像素的能量,使用动态规划的算法来确定细缝的位置。Rubinstein等人(2008)对Avidan和Shamir(2007)的方法进行改进,使用细缝裁剪后产生的新边缘的梯度作为像素能量值来计算细缝。Guo 等人(2015)通过同时考虑原始图像的纹理、颜色信息以及邻域不均匀因子来计算显著性图,对以往的细缝裁剪方法进行了优化,在背景与内容高度相似时依然能实现鲁棒的重定向效果。此外,Pritch 等人(2009)提出一种基于原始图像块来生成重定向图像的离散方法,该方法将图像重定向转化为移位图的标注问题,通过寻找最优图标注,将源图像的重要内容重新分布在重定向图像上。基于SC 的方法在图像重定向的长宽比变化不大时,效果较好,但当目标图像的长宽比变化过大时,往往会引起图像信息的丢失以及视觉伪影。
连续重定向算法的基本思想是通过设定特定的约束能量项来保留图像中的关键物体,得到原始图像与目标尺寸之间的最佳映射(Kim 等,2018)。具有代表性的两类方法分别是:基于内容感知的缩放方法和基于warping 的方法。由于对象的边缘信息对确定对象在图像中的位置有很大帮助,Shi 等人(2008)首先通过形态学边缘检测器识别图像中的边缘,然后在这些区域运用两种插值算法对图像进行缩放。Liang 等人(2012)的方法通过显著图和Sobel算子(Sobel 和Feldman,1973)检测的边缘信息来确定图像的内容重要图,分别对重要块和非重要块选取不同的缩放因子实现图像分辨率调整。Du 等人(2013)提出的缩放方法同时考虑了梯度图、显著性图以及颜色等相关信息,通过计算图像的拉伸性,将图像分为可拉伸块和不可拉伸块,并确定每个块的缩放因子,最后,根据分配的缩放因子对每个块进行调整得到最终的图像。基于warping 的方法注重于保留图像的局部结构和最小化图像的局部失真。Liu 和Gleicher(2005)、Zhang 等人(2013)、Ren 等人(2008)以及Wang和Lai(2009)的方法首先检测图像中的感兴趣区域(region of interest,ROI),并在这些区域计算warping 函数得到重定向图像,但这类方法比较依赖ROI 区域检测的准确性,如果不能识别到正确的ROI区域就会导致重定向后的图像产生视觉伪影。Wang 等人(2008)的方法将warping 问题归结为非线性优化问题,通过计算每个区域的最优尺度因子对每个区域进行缩放和拉伸处理。Zhang 等人(2009)结合多尺度对比度和空间色彩分布提出的重要性图,定义二次畸变能量来测量形状畸变,通过最小化二次畸变能量的加权和来保留图像中重要的信息以及边缘结构。Kim 等人(2018)提出一种结构感知的轴对齐网格变形方法,通过由两个目标函数表示的二次优化找到目标图像的最优网格,该方法不仅实现了基于内容感知的图像重定向,而且对结构的失真也有很好的鲁棒性。Lau 等人(2018)提出了一种基于贝尔特拉米(Beltrami)表示的图像重定向方法,可以实现对不同情况下的图像进行分辨率调整,该方法具有较低的复杂度且性能较好。
单一重定向算子的方法由于其局限性,不能适用于所有类型的图像,通过组合这些算子来实现图像重定向的方法称为多算子方法(Tang 等,2020)。Fang 等人(2017)将CR(cropping)、WARP(warping)(Wolf 等,2007)、SCL(scaling)和SC(seam carving)(Avidan 和Shamir,2007)算子进行组合,使用结构相似性方法(Zhang 等,2019)来确定每次迭代中选取的重定向算子。Wang 等人(2016)提出一种结合了WARP、CR 和SCL 等3 种算子的自适应内容压缩的重定向方法,该方法具有高度的灵活性,能够最大程度保留图像中的视觉信息。Shafieyan等人(2017)的方法组合梯度图、显著性图和深度图,依次确定输入图像的区域重要性,根据重要性来设置选取SC 或SCL 算子的阈值。这种方法能够减少细缝裁剪带来的失真。
以上方法在计算图像重要性图时缺乏高层语义信息的参与,因此容易在图像重定向过程中破环图像的语义信息。深度神经网络能够提取丰富语义特征,在保留语义结构的情况下进行图像重定向,能够生成高质量的图像。因此,大量基于深度学习的重定向方法相继提出。Cho 等人(2017)首次应用深度神经网络生成重定向图像,该方法引入移位层建立原始图像和重定向图像的映射。Guo 等人(2018b)提出一种基于卷积神经网络(convolutional neural network,CNN)和级联回归的自动裁剪方法。首先在美学数据集上训练CNN 分类器,利用CNN 提取图像裁剪的有效特征,并使用级联回归器不断优化裁剪框。Tan 等人(2020)提出一种循环重定向网络,首次以无监督的方式来解决图像重定向问题,该方法首先根据原图生成具有两种分辨率的重定向图像,然后将生成的重定向图像分别输入网络来重建原始图像,基于循环感知一致性损失来优化网络。Shocher 等人(2019)基于生成对抗网络(generative adversarial network,GAN)的思想提出了一种名为InGAN(internal GAN)的模型。该模型利用GAN 网络在保持图像内部分布不变的情况下,生成多分辨率和多形状图像。Ahmadi 等人(2021)基于图像上下文和语义分割提出一种自上而下和自下而上的显著性检测方法,并以此促进图像重定向过程。Naderi 等人(2022)对输入图像及其掩膜,分别使用图像修复和图像超分技术处理其前景和背景,最终利用粒子群优化算法(particle swarm optimization,PSO)融合前后景得到重定向图像,该方法采用图像美学评价作为目标函数。
表1 总结了4 类重定向算法的基本思想及其优劣势。在大多数情况下,多算子重定向方法的性能是优于单一算子的。但应用多算子方法增加了算法的计算复杂度,而且在多算子方法设计中,往往需要设置算子之间的应用比例以及执行顺序,这无疑增加了算法的设计难度。深度学习方法的设计思想是通过提取与HVS 相关的语义特征,使得最终模型输出的重定向图像能够尽可能符合期望。综合现有的文献可知,基于深度学习的图像重定向方法可以显著提高重定向性能。但由于计算设备的高要求以及模型复杂度等问题,限制了该类方法在实际场景的部署和应用。
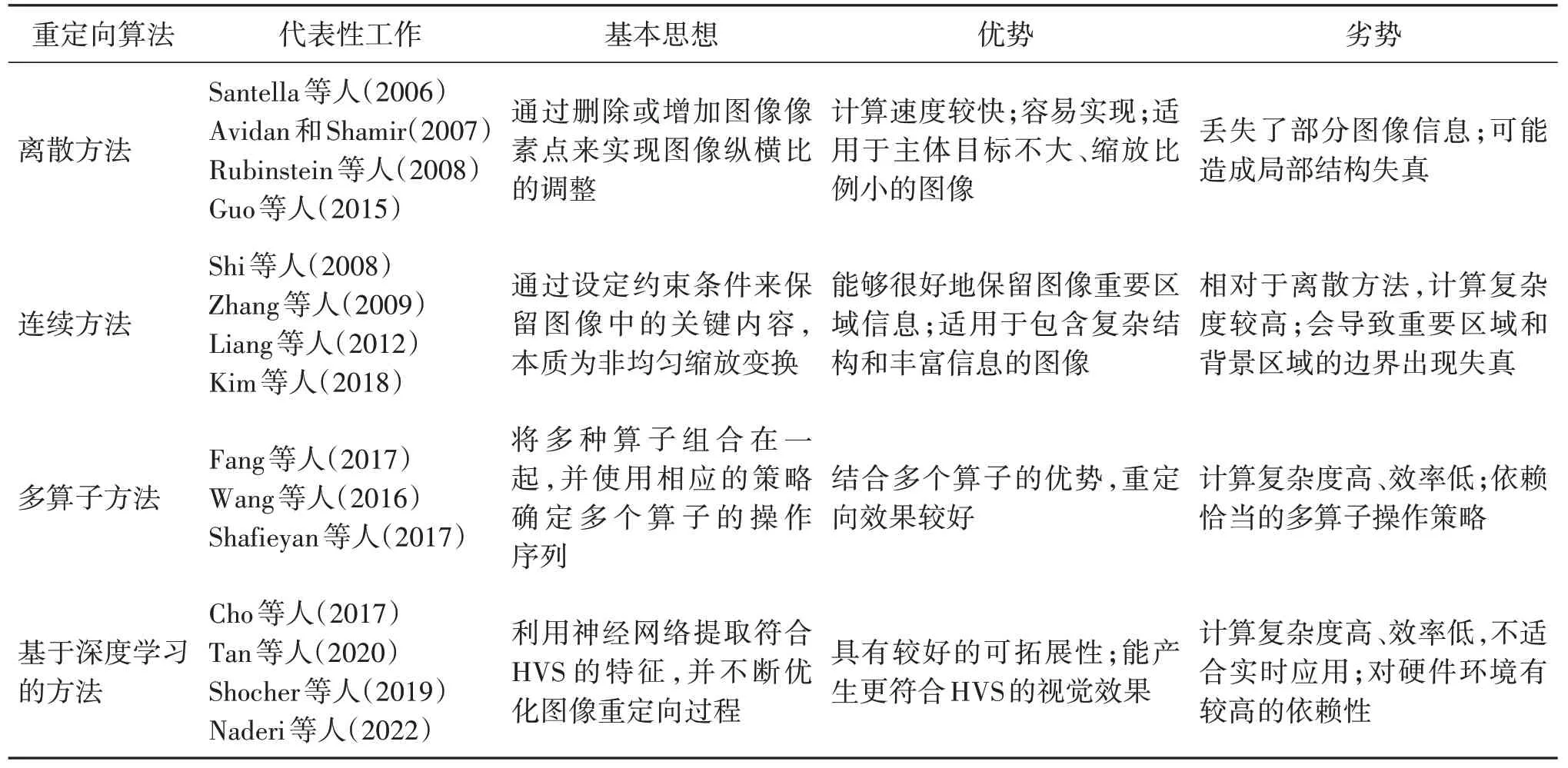
表1 4类重定向算法的比较Table 1 Comparison of four types of retargeting algorithms
1.2 传统图像质量评价
众所周知,在传输、接收、存储和显示等过程中不可避免地会造成数字图像的失真,导致其质量下降,影响人们的视觉体验(Yang 等,2019b;Sun 等,2021,2023)。更为严重地,重度失真将对目标检测、语义分割等下游视觉任务的可靠性带来极大挑战和严重威胁。因此,如何对图像的质量进行有效评估显得尤为重要。不可否认,依靠人眼来进行质量评价(即主观评价方法)最为直接且具有极佳的可靠性,但这种方式费时费力且无法满足实时要求。客观质量评价方法指利用设计好的算法来自动完成图像质量的预测评估任务,能够满足多种应用场景(Ma 等,2018)。如图3 所示,按照是否需要原始高清图像作为参考信息,可以将其分为全参考图像质量评价(full reference IQA,FR-IQA)、半参考图像质量评价(reduced reference IQA,RR-IQA)和无参考/盲图像质量评价(no reference/blind IQA,NR-IQA/BIQA)3 类(王志明,2015;方玉明 等,2021;Xu 等,2017)。本节将对上述3 类IQA 模型的现有研究工作进行阐述与分析。
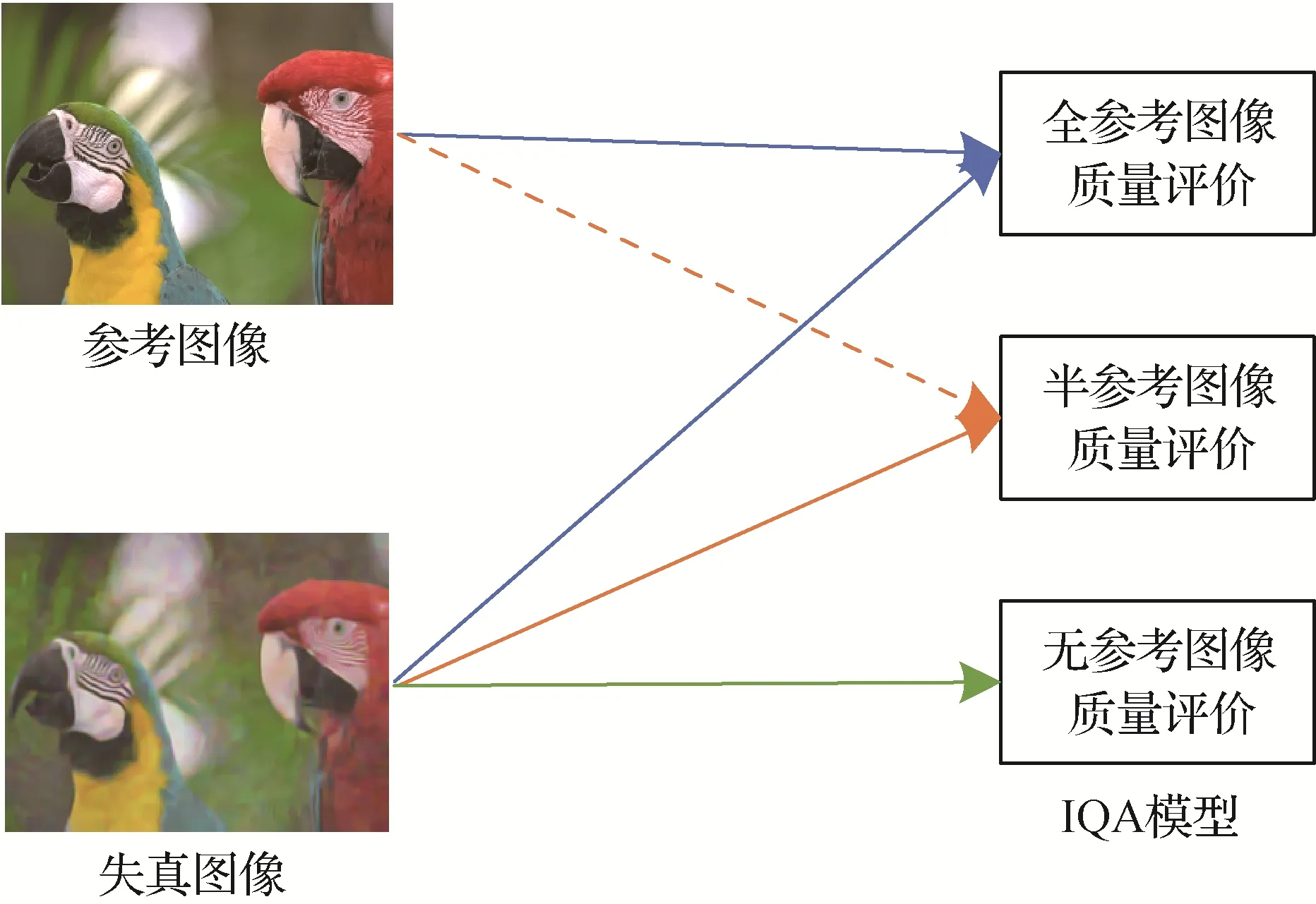
图3 IQA模型分类Fig.3 Classification of IQA models
FR-IQA 方法在构建质量评价模型的过程中使用无失真的高清图像作为参考信息(Zhu 等,2020)。该类方法通常分为3 个阶段:首先,分别从参考图像和失真图像中提取与图像质量相关的特征;其次,对这些特征进行融合或表示,并计算参考图像特征和失真图像特征之间的差异;最后,利用模型将两者的差异映射到合适的质量尺度。根据特征提取的方式不同,可以将FR-IQA方法进一步分为基于手工特征的方法(Wang 等,2004;Wang 和Li,2011;Liu 等,2012;Zhang 等,2011)和基于深度学习的方法(Gao等,2017;Liang 等,2016;Kim 和Lee,2017;Bosse 等,2018)。基于手工特征的方法从观察者的角度出发,设计视觉感知敏感的图像特征来表示图像的质量。基于深度学习的方法通常利用卷积神经网络自动学习质量感知的特征,由于数据集规模和模型复杂度的限制,该类方法通常将输入图像分块以提高图像特征的多样性,图像的最终质量由每个图像块的质量构成。RR-IQA 方法利用部分参考图像的信息完成IQA任务,可以将其分为基于空域的方法(Wu等,2013;Min 等,2018;Liu 等,2018)和基于变换域的方法(Gao 等,2008;Soundararajan 和Bovik,2012;Golestaneh和Karam,2016)。基于空域的方法通常提取两幅图像的颜色、对比度以及信息熵等空间域的特征,最后基于特征差异来回归图像质量。基于变换域的方法首先使用小波变换或离散余弦变换等变换分析方法对图像进行处理,然后在变换域中提取和表示特征,最终利用这些特征来评估图像的质量。FRIQA 方法的发展日渐成熟,在IQA 任务上的性能表现与主观质量评价有着高度的一致性,但FR-IQA方法和RR-IQA 方法在无法直接使用参考图像的应用场景下依然有其局限性。
NR-IQA 方法不需要任何参考图像的信息就能进行图像质量预测,因此在科学研究和实际应用中更具吸引力和挑战性(Liu 等,2022;Wu 等,2021)。在早期的一些工作中,NR-IQA方法通常通过提取图像的自然场景统计(natural scene statistics,NSS)特征并使用回归模型来预测图像的质量分数。该类模型的理论基础是高质量图像的统计特性遵循着一定的分布规律,而图像的失真会破坏这种规律,该类代表性方法有BRISQUE(blind/referenceless image spatial quality evaluator)(Mittal 等,2012)、NIQE(natural image quality evaluator)(Mittal 等,2013)、BLIINDS(blind image integrity notator using DCT statistics)(Saad 等,2010)和NFERM(NR free energy-based robust metric)(Gu 等,2015)等。由于CNN 强大的特征提取和特征表示能力,在计算机视觉的各个领域均有大量基于CNN 的工作。质量评价领域也不例外,在Kang 等人(2014)首次将CNN 引入IQA 模型后,后续的相关工作开始井喷式地出现(Hou 等,2015;Kim 等,2019;Zhang 等,2020;Zhu 等,2020;Ma等,2021)。现有的基于CNN 的IQA 方法主要遵循以下基本框架:首先,对图像进行分块,利用CNN 从图像块中自动学习特征;然后,将每个图像块的特征映射为分数;最后,每幅图像的质量分数由图像块的质量分数加权得到。NR-IQA 方法由于不需要任何参考图像信息的参与,因此有着更广泛的应用前景。虽然目前NR-IQA 已经取得了长足的进步,但在面对复杂失真场景时,取得的效果距离实际的主观评价仍有一定距离。
研究人员在传统图像的质量评价领域已经取得了突破性的进展。然而,由于原始图像与重定向图像的尺寸不同,导致传统的FR-IQA模型无法直接用于重定向图像的质量评估。此外,传统的NR-IQA模型主要用于评估模糊、噪声等失真类型的图像,而重定向图像的失真主要是由重定向过程造成的几何失真和内容损失,与传统的IQA 应用场景并不相同,因此限制了该类模型在图像重定向质量评价领域的应用。
2 数据集
主观质量评价是通过用户调查的方式来对图像的质量进行评估,因此能准确地反映观察者感知图像时的直观感受。主观质量评价通常作为客观质量评价的性能上界,为客观质量评价算法提供评价标准和性能对比。一些工作基于主观质量评价来建立数据集,目前图像重定向质量评价领域存在3 个基准数据集:MIT RetargetMe(Rubinstein 等,2010)、CUHK(Ma等,2012)和NRID(Hsu等,2014)。
MIT RetargetMe 数据集由美国麻省理工学院于2010 年建立,包含80 幅原始图像,图像涉及的属性有人物/面部、线条/边缘、前景目标、纹理元素、特定的几何结构和对称性等。在主观实验中,选取其中的37 幅图像,经8 种不同的重定向算子处理获得对应的重定向图像,这些重定向算子包括CR、SCL、WARP、SC、SNS(scale-and-stretch)(Wang 等,2008)、MULTIOP(multi operator)(Rubinstein 等,2009)、SM(shift maps)(Pritch 等,2009)和SV(streaming video)(Krähenbühl 等,2009)。重定向图像的分辨率为原始图像的0.5或0.75。主观实验通过成对比较的方法进行,用户选择两幅重定向图像中质量更好的图像,最终的图像质量由投票数量来决定。
CUHK 数据集由香港中文大学于2012 年建立,包含57 幅原始图像,选用的重定向算子共10 种,涵盖MIT RetargetMe 数据集中使用的8 种算子以及额外选取的SCSC(seam-carving and scaling)(Dong 等,2009)和ENER(energy-based deformation)(Karni 等,2009)2种算子。在进行图像重定向时,随机选取10种算子中的3 种生成目标图像。图像缩放尺度与MIT RetargetMe一致,均为原始图像的0.5或0.75。采用平均意见分数(mean opinion score,MOS)衡量图像质量,MOS值越大表明图像质量越好。
NRID 数据集于2014 年建立,包含35 幅原始图像,对每幅图像应用5 种重定向算子,包括SC、SM、SCL、WARP 和MULTIOP。重定向图像的长或宽为原始图像的0.75。该数据集的主观评价方式与MIT RetargetMe 数据集一致,采用成对比较的方式进行主观实验。
3 个数据集的原始图像仅从水平或垂直方向任选一个进行相应比例的压缩。上述数据集的总结见表2,主要包括原始图像的数量、重定向图像数量、重定向算子、缩放比例以及进行主观评价的方法。从表2 可以看出,受到原始图像数量较少和缩放比例较为固定等限制,现有的数据集均存在规模小、图像内容不够丰富等缺点。

表2 图像重定向质量评价数据集Table 2 Image retargeting quality evaluation datasets
图4 展示了MIT RetargetMe 数据集的原始图像及不同重定向算子处理后的重定向图像;图5 展示了NRID 数据集中的两组原始图像和重定向图像。观察图4 和图5 发现,与原始图像相比,重定向图像中的实例对象均出现了严重的形状扭曲和内容丢失等现象。这一现象表明,现有的基于内容感知的重定向算法在重定向过程中仍然不可避免会导致图像的内容损失和几何失真,同时也充分说明研究图像重定向客观质量评价方法的必要性。

图4 MIT RetargetMe数据集示例图像Fig.4 Example images from the MIT RetargetMe dataset

图5 NRID数据集示例图像Fig.5 Example images from the NRID dataset
3 图像重定向客观质量评价
主观质量评价高度契合人眼感知图像的过程,但主观评价存在过程复杂、耗时耗力和无法用于实时场景等缺点,因此设计客观质量评价方法对图像质量进行自动预测显得尤为重要(Ma 等,2021)。在过去的十余年中,研究人员提出了一系列针对重定向图像的客观质量评价模型。如图6所示,根据对现有文献资料的归纳总结,本文将现有的模型大致划分为两类:基于传统特征相似性的IRQA 模型和基于图像配准的IRQA 模型。下面,本文主要针对以上两类模型进行阐述和分析。
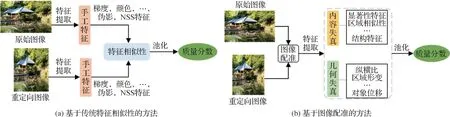
图6 重定向图像客观质量评价整体框架Fig.6 The overall framework of image retargeting objective assessment
3.1 基于传统特征相似性的IRQA模型
图像重定向技术在改变原始图像分辨率的同时会造成图像本身特性的丢失,如梯度、颜色和结构等。早期的IRQA 模型分别从参考图像和重定向图像中提取感知敏感的特征,通过计算其特征相似度来量化重定向图像的失真程度。
在早期的工作中,EH(edge histogram)(Manjunath等,2001)、CL(color layout)(Kasutani和Yamada,2001)、BDS(bidirectional similarity)(Simakov 等,2008)、BDW(bidirectional warping)(Rubinstein 等,2009)、EMD(earth-mover’s distance)(Pele 和Werman,2009)和SIFT-flow(Liu 等,2008)等6 种指标用来评估重定向图像的质量。其中,EH 和CL 将图像视为整体,利用颜色和梯度等低层次特征来反映图像的质量;BDS 和BDW 搜索图像之间的中级语义对应关系,以此计算图像质量;EMD 和SIFT-flow 通过对齐图像来捕捉图像的结构特性,相较其他4 种方法能够更有效地表示图像的质量。Rubinstein 等人(2010)在提出的MIT RetargetMe 数据集上对以上6 种指标进行了评估,发现这些方法与主观评价结果存在明显的差异。Ma 等人(2012)在所提出的数据集CUHK 上对EH、EMD、BDS 和SIFT-flow 4 种指标进行了性能测试。Ma 等人(2014)针对一些经典的特征描述符进行大量实验,结果表明考虑几何形状失真和内容失真能够提高图像重定向质量评价算法的性能。Ma 等人(2016)将图像对表示为GIST(Oliva 和Torralba,2001)特征向量,分别从自然度、开阔度、粗糙度、扩展度和险峻度等多个感知维度来描述图像的场景信息,根据对应的主观分数训练一个基于排名的预测模型,方法框架如图7所示。
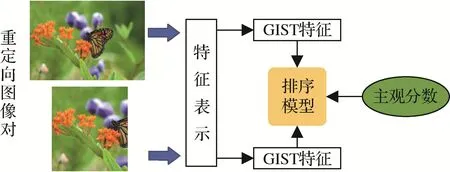
图7 Ma等人(2016)方法的基本框架Fig.7 The framework of Ma et al.’s method(2016)
由于人们观察图像会分配更多的精力在显著性区域,所以位于显著性区域的失真对图像的整体质量影响更大,直接对两幅图像提取特征计算其特征相似度的方法不符合人眼感知过程。因此,研究人员将显著性图引入到IRQA 模型中。Wei 等人(2021)提出了一种基于EMD 的RR-IRQA 方法,该方法从局部和全局两个方面计算图像特征分布的EMD,并将其映射为质量分数。Chen 等人(2017a)对同一源图像生成的重定向图像从显著性区域、伪影、全局结构、美学以及对称性等多个方面来描述特征,并使用通用回归网络(general regression neural Network,GRNN)(Specht,1991)进行特征的组合建模,将输出的相对分数转化为全局排名。Chen 等人(2017b)的方法利用图像的NSS特征、显著性全局结构失真和双向显著性信息损失3 个指标来衡量原始图像和重定向图像之间的差异。与Chen 等人(2017a)方法类似,Liang 等人(2017)考虑重定向图像的显著性区域保留、伪影影响、全局结构保留、美学质量以及对称性,提出了一种简单有效的客观质量评价方法。Liu等人(2020)基于Chen等人(2017a)的工作,提出一种基于学习的IRQA 方法。该方法使用新的训练方案训练GRNN 模型,预测来自不同原始图像的重定向图像的质量排名。
上述方法基于重定向图像的失真特性来设计特征,计算原始图像和重定向图像之间的特征相似性来表征图像的质量。这类方法在一定程度上解决了图像重定向质量评价的问题,并促进了更先进的图像重定向质量评价方法的研究与发展。该类方法的不足在于:1)高度依赖于手工设计特征的有效性;2)通常不符合HVS 感知特性;3)显著性算法的性能决定部分方法的性能。
3.2 基于图像配准的IRQA模型
重定向图像的失真主要包括几何结构失真和内容失真两个方面,而重定向的图像与原始图像的尺寸不同,限制了质量评价方法的性能。因此,如何高效地获得原始图像和重定向图像之间的对应关系尤为重要。基于图像配准的IRQA 模型在进行特征提取之前,先将两幅图像进行稀疏或密集的图像配准,能够有效地建立图像间的关系,从而改善算法的效果。
Zhang 和Kuo(2014)首先对两幅图像进行特征点匹配,然后以全局结构失真、局部区域失真和显著信息损失为指导来获取图像的特征。Liu 等人(2015)在空域获取图像的形状失真、局部和全局的内容失真,此外还考虑频域中图像的几何失真和内容失真,最后利用支持向量回归(support vector regression,SVR)来回归图像的质量。由于目前大多数图像质量评价算法都使用回归方法来获得质量分数,与人眼感知过程的一致性不高。Lin等人(2015)提出了一种基于混合失真融合的IRQA 模型,首先利用尺度不变特征变换(scale invariant feature transform,SIFT)来提取参考图像和重定向图像的相似特征,计算其结构相似度来表示图像的局部特征以及内容损失特征,同时还考虑基于灰度共生矩阵(gray level co-occurrence matrix,GLCM)的结构失真检测。考虑到图像重定向会造成严重的结构变形,Zhang和Ngan(2016)首先将重定向后的图像与原始图像进行线段匹配,然后根据重定向过程造成的线丢失、线伪影以及线旋转来反映图像的结构失真,从而解决图像质量问题。Jiang 等人(2020)提出了一种基于栈式自编码器的IRQA 方法,分别利用几何形状特征和内容匹配特征来训练两个栈式自编码器,最终通过加权将两个模型得到的分数进行合并。Wang等人(2012)利用梯度、颜色和方向特征来匹配原始图像和重定向图像的显著区域,然后基于特征距离和显著区域相似性来提供重定向图像的质量评分。Afshar 等人(2017)利用图像的结构相似度和全局信息设计了一种IRQA 方法。Yan 等人(2017)将图像的复小波结构相似性、图像美学评价指标以及其他8 种重定向图像评估算法的输出作为特征,使用了简单的径向基函数(radial basis function,RBF)(Schwenker等,2001)神经网络来组合特征并预测图像质量。Oliveira 等人(2018)提出基于双向重要性图相似性的客观IRQA 方法。具体地,首先使用加速鲁棒特征(speeded-up robust features,SURF)(Bay等,2006)算法来检测源图像和重定向图像的关键特征点,并利用显著点帕尔森图(salient point Parzen map,SPPM)算法生成双向重要性图,然后计算其相似性。最后,将该特征与关键点匹配特征以及纵横比特征进行融合来表示图像的感知质量。Jiang 等人(2018)提出了一种基于稀疏表示的IRQA 方法,与基于密集对应算法设计特征的方式不同,该方法利用过完备字典来表示图像中对失真敏感的局部和全局特征,然后基于稀疏表示来计算其相似性,最后将多个质量分数通过SVR 融合得到最终的质量分数。Zhang 等人(2019)利用SURF 对两幅图像进行特征匹配,从局部结构相似度、内容损失和显著区域相似性3个方面来描述重定向图像的质量。
另外一类方法基于SIFT-flow(Liu 等,2011a)或光流(Xu 等,2012)来获取原始图像与重定向图像之间的密集对应关系,并基于这种密集对应关系完成质量评价任务。例如,Hsu 等人(2014)基于SIFTflow 来建立两幅图像之间的密集对应关系,并测量其向量场的局部方差和显著性图的比值来分别衡量几何结构失真和内容信息损失。基于结构相似性(structural similarity,SSIM)在传统图像质量评价中取得的成功,Fang 等人(2014)提出了应用于重定向图像的相似性方法IR-SSIM(image retargeting SSIM)。首先应用SIFT-flow 寻找两幅图像的对应关系,然后计算局部结构相似度,最后利用显著性图进行加权融合得到最终的图像质量。Zhang 和Ngan(2015)的方法将图像表示为超像素区域,通过探索源图像和重定向图像在区域级别的信息损失和失真来预测图像质量。Zhang 等人(2016b)认为重定向图像质量的下降与几何变化有着密切关系,提出了一种基于局部图像块纵横比相似性(aspect ratio similarity,ARS)以及视觉重要性的方法。Zhang 等人(2016a)利用马尔可夫随机场(Markov random field,MRF)来对重定向图像的后向配准问题建模,提出了一种基于局部块几何变化以及视觉重要性的质量评价方法。Zhang等人(2017a)的方法从局部相似性、全局相似性和信息损失3 个方面量化重定向导致的图像失真。Zhang 等人(2017b)首先将源图像和重定向图像进行对齐,从区域、图像块和像素3 个层次分别计算图像的保真度;接着,根据保真度来反映图像的几何形变、不一致性和信息损失;最后进行特征融合预测其质量。Karimi 等人(2017)的方法使用光流来建立图像的对应关系,设计了基于区域特征、局部形状和纵横比特征的IRQA 模型来预测与主观一致的排名信息。为了缓解现有IRQA 方法仅仅利用低层次特征来估计图像质量以及高度依赖视觉重要性的局限性,Zhang 等人(2018)提出了一种基于多层次特征的客观IRQA 方法。该方法分别从长宽比相似性、边缘相似性和人脸相似性自下而上描述原始图像和重定向图像之间的差异,最后使用机器学习方法来进行特征融合。Fu 等人(2018)基于原始图像和重定向图像之间的相似性变换来提取结构失真和区域内容失真,同时将深度学习方法用于提取纹理特征和语义特征。为了提高IRQA 模型与人类主观感知的一致性,吴志山等人(2019)用不同的尺度提取ARS 特征,并融合显著性图以及脸部特征和边缘线条特征来预测重定向图像的质量。Guo 等人(2018a)从全局和局部两个方面来量化图像的失真,利用前景保留率、全局形变、纵横比和集中删除率4 个特征来表示重定向图像失真程度。Yao 等人(2021)提出一种基于显著性ARS 的方法来评价重定向图像的质量。Niu 等人(2021)提出一种基于配准置信度和显著性聚合的方法来解决IRQA问题。首先将重定向图像和原图像进行配准,提取网格形状相似性、纵横比等图像块级的特征,最后使用基于显著性的特征聚合方法来进行特征融合,该方法能够获得与HVS 更一致的感知质量。由于HVS 的感知高度依赖于边缘信息,图像重定向会导致边缘形变。因此,Peng 等人(2022)首先使用基于sketch-token 的局部边缘描述符来估计图像的局部几何失真;然后使用空间金字塔改进的bag-oftoken 模型来表示全局结构失真;最后结合现有ARS模型提出了一种IRQA 方法。考虑到高级语义信息对视觉感知的引导作用,Li 等人(2021)将图像实例作为基本语义单元,重点考虑实例单元的形状、位置、大小和信息失真,并结合全局特征获得感知质量,其基本框架如图8 所示。Shao 等人(2021)提出一种通用的框架来估计重定向图像的质量,首先对两幅图像进行双向匹配;然后,根据匹配结果来计算双向变换的相似性变换矩阵,基于相似性矩阵来测量重定向图像的几何失真、信息损失以及全局的结构性失真;最后,使用SVR 来建立特征到质量分数的映射。Tang 和Yao(2022)提出了一种基于显著性驱动分类的IRQA 方法,首先将原始图像和重定向图像配准,然后计算原始图像和重定向图像的几何失真、信息损失和结构退化。同时基于显著性图将图像分类,然后根据图像类型使用不同纵横比相似性测量方案,最终整合以上两种方案估计图像质量。
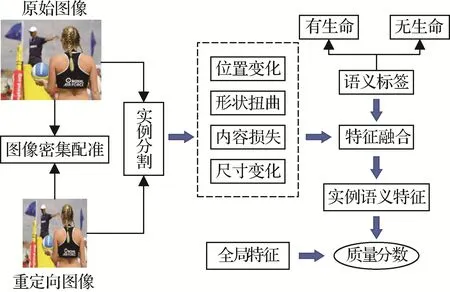
图8 INSEM(Li等,2021)基本框架Fig.8 The framework of INSEM(Li et al.,2021)
近年来的方法致力于建立原始图像和重定向图像之间的稀疏或密集对应关系,从局部到全局反映图像的失真程度。该类方法的优势在于能够从多尺度描述图像的失真,在建立两幅图像对应关系的情况下,模型对于内容失真和几何失真更加敏感。同时,有的方法(Zhang 等,2018;Li 等,2021)引入了高层次的语义特征,能够预测符合HVS 的感知质量。不足之处在于,基于图像配准的方法计算复杂度高,并且图像配准的误差会影响对图像质量的判断。
3.3 现有IRQA方法的优缺点
表3 总结了现有IRQA 方法的主要思想和优缺点。从表中可知,现有的基于传统特征相似性的IRQA方法主要通过设计有效的失真感知特征,对两幅图像进行特征提取和特征表示,最后通过计算特征相似性来实现质量预测。该类方法的优势在于简单高效,计算速度较快,能够较直接完成质量评估任务。但是该类方法的性能极其依赖于手工设计的特征,并且由于该类方法未能考虑HVS 的感知过程,其质量预测结果往往与人眼的感知差异较大,泛化能力也较弱。现有的基于图像配准的方法在进行特征提取和表示之前会先建立两幅图像之间的对应关系,然后主要从图像的几何结构失真和内容损失两个方面估计图像质量的退化。该类方法的优势在于能够更好地从多个层次(例如,像素、区域和全局)获取对应位置的失真,能够有效地量化质量的退化。
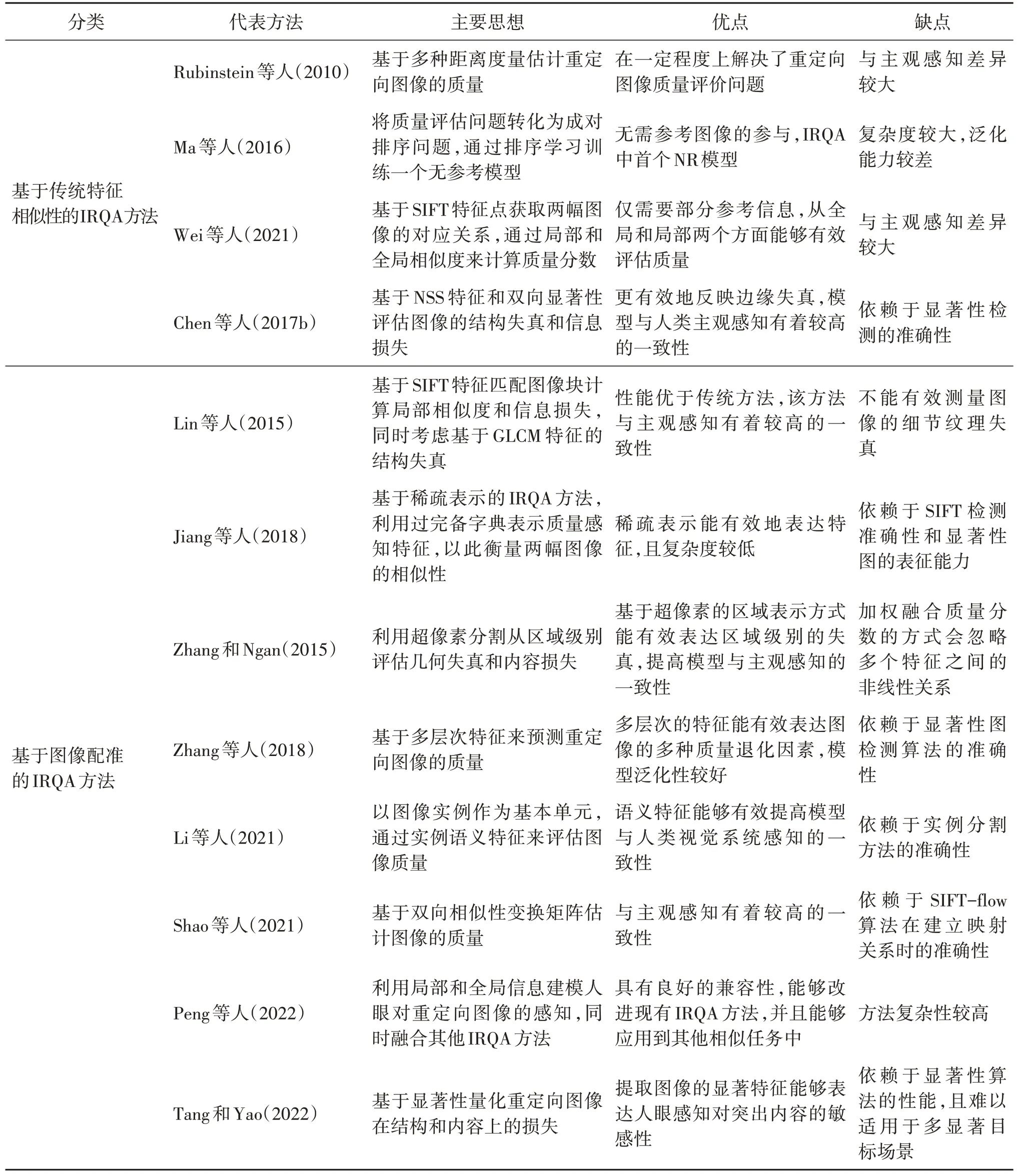
表3 图像重定向质量评价方法的主要思想和优缺点总结Table 3 Summary of main ideas,advantages and shortcomings of image retargeting quality evaluation methods
相较于传统的方法,该类方法在质量预测能力以及与主观感知的一致性方面都有着显著的提升。由于这类方法需要建立图像之间的对应关系,这也导致了模型的性能同时受限于图像配准算法的性能。
综上所述,基于传统特征相似性的方法在质量预测能力及模型泛化能力方面均有诸多限制,但该类方法为如何解决重定向图像的质量评价问题提供了思路和方向。基于图像配准的方法相比基于传统特征相似的方法提供了更多解决IRQA 问题的可能性,在现有的IRQA 领域中占据主导地位。但现有的该类方法仍然受限于图像配准方法的性能,并且特征提取和表达的方式方法较为单一。研究更具优势的图像配准方法,继续探索更有效的特征提取和特征表达方式是提升基于图像配准的IRQA 方法性能的关键。
4 实 验
为了更直观地了解当前IRQA 方法的性能表现,本节在3个基准数据集上对现有的部分IRQA 模型进行了性能对比和分析。
4.1 评价指标
与传统图像质量评价指标类似,IRQA 模型的性能通常从预测的准确性、单调性和一致性3 个方面进行评估。
4.1.1 评估准确性的指标
评估准确性的指标为均方根误差(root mean square error,RMSE)和皮尔逊线性相关系数(Pearson linear correlation coefficient,PLCC),RMSE 主要描述了预测分数和主观分数之间的偏差,PLCC则反映预测分数与主观分数之间的相关性。在计算PLCC 之前,需要对质量分数进行5 参数的非线性拟合(Sheikh等,2006),具体为
式中,o表示原始客观质量分数;p表示经过回归操作后的客观质量分数;β1,β2,β3,β4和β5为拟合参数。
皮尔逊线性相关系数(PLCC)具体计算为
式中,si和pi分别表示第i幅图像的主观质量分数和经过非线性拟合的模型预测分数,分别表示所有主观分数和预测分数的均值。
均方根误差(RMSE)具体计算为
式中,N表示图像的总数,si和pi分别表示第i幅图像的主观质量分数和模型预测分数。
4.1.2 评价单调性的指标
评价单调性的指标为斯皮尔曼秩相关系数(Spearman rank order correlation coefficient,SRCC)和肯德尔秩相关系数(Kendall rank order correlation coefficient,KRCC)。
斯皮尔曼秩相关系数(SRCC)具体计算为
式中,N表示图像的总数,di表示第i幅图像主观质量分数排名与模型预测分数在N幅图像中排名的差值。
肯德尔秩相关系数(KRCC)具体计算为
式中,N表示图像的总数,Nc表示样本中一致对的个数,Nd是样本中不一致对的个数。一致对指一对样本的主观分数与预测分数保持一致的单调关系,反之称为不一致对。
4.1.3 评估一致性的指标
离出率(outlier ratio,OR)用于模型在预测一致性方面的表现,通过描述预测分数和主观分数之差大于主观分数两倍标准差的个数在所选样本中所占百分比来体现,OR 值越低,说明模型性能越好。
离出率(OR)具体计算为
式中,Nout表示主观质量分数和模型预测分数的差值大于该图像主观质量分数两倍标准差的图像数目,N表示所要预测图像的总数。
4.1.4 其他评价指标
除了上述5 种指标以外,Ma 等人(2017)提出了3 种新的评价指标,分别为原图/失真图辨别性测试(pristine/distorted image discriminability test,D-test)、序列排序一致性测试(listwise ranking consistency test,L-test)以及成对偏好一致性测试(pairwise preference consistency test,P-test)。D-test 用于评估模型对原始图像和失真图像的鉴别能力,L-test用于评估模型对同一内容、同一失真类型下不同失真程度图像的失真级别预测的鲁棒性,该指标可以借助SRCC或KRCC 来实现,P-test 用于评估模型对质量可分图像对的偏好预测一致性。
原图/失真图辨别性测试(D-test)指标具体计算为
式中,Sp和Sd分别表示原图和失真图像的索引,T为分类阈值,pi表示第i幅图像的模型预测分数。
序列排序一致性测试(L-test)指标具体计算为
式中,N表示图像数量,K表示失真类型数,lij和pij分别表示第i幅图像的失真等级及其模型预测分数。
成对偏好一致性测试(P-test)指标具体计算为
式中,M和Mc分别表示质量可分图像对的数量以及模型预测正确的质量可分图像对的数量。
4.2 性能比较
本节在MIT RetargetMe、CUHK 和NRID 3 个基准数据集上对现有的具有代表性的IRQA 方法进行了性能测试。对比的算法包括8 种基于传统特征相似性的方法:EH(Manjunath 等,2001)、BDS(Simakov等,2008)、EMD(Pele 和Werman,2009)、CSim(Liu等,2011b)、SIFT-flow(Liu 等,2008)、Ma 等 人(2016)、Chen 等人(2017b)、Liang 等人(2017)和10种基于图像配准的方法:ARS(Zhang等,2016a)、IRSSIM(Fang 等,2014)、PGDIL(image retargeting based on perceptual geometric distortion and information loss)(Hsu 等,2014)、Yan 等人(2017)、Karimi 等人(2017)、MLF(multiple level feature based quality measure)(Zhang 等,2018)、RN-IRQA(IRQA based on registration confidence measure and noticeabilitybased pooling)(Niu等,2021)、LGGD+(image retargeting quality assessment by measuring local and global geometric distortions)(Peng 等,2022)、INSEM(image retargeting based on instance semantics)(Li 等,2021)、TRASIM(transformation-aware similarity)(Shao 等,2021)。MIT RetargetMe 数据集和NRID 数据集中根据图像属性划分了6 个子集,并且采用成对比较的方式进行,最终主观质量由用户投票数确定。因此使用KRCC 来衡量算法预测结果的单调性,包括每种对比方法在每个子集上的性能以及总体的性能,KRCC 值越大,表示性能越好。而在CUHK 数据集中使用了与传统图像质量评价类似的评价指标,包括PLCC、SRCC、RMSE 和 OR。一般来说,PLCC 和SRCC 值越大,RMSE 和OR 值越小,表示该方法性能越好。
表4 提供了共18 种IRQA 方法在MIT RetargetME 数据集上的性能表现。实验结果表明,RNIRQA 在多个子集和总体性能上均优于其他方法,INSEM在具有线边缘和纹理属性的子集中的性能表现达到了最优。其中RN-IRQA 通过显著性图和图像块级特征来预测图像质量,INSEM 以实例作为基本单元,利用高层次语义特征从多个方面来表示图像的失真。
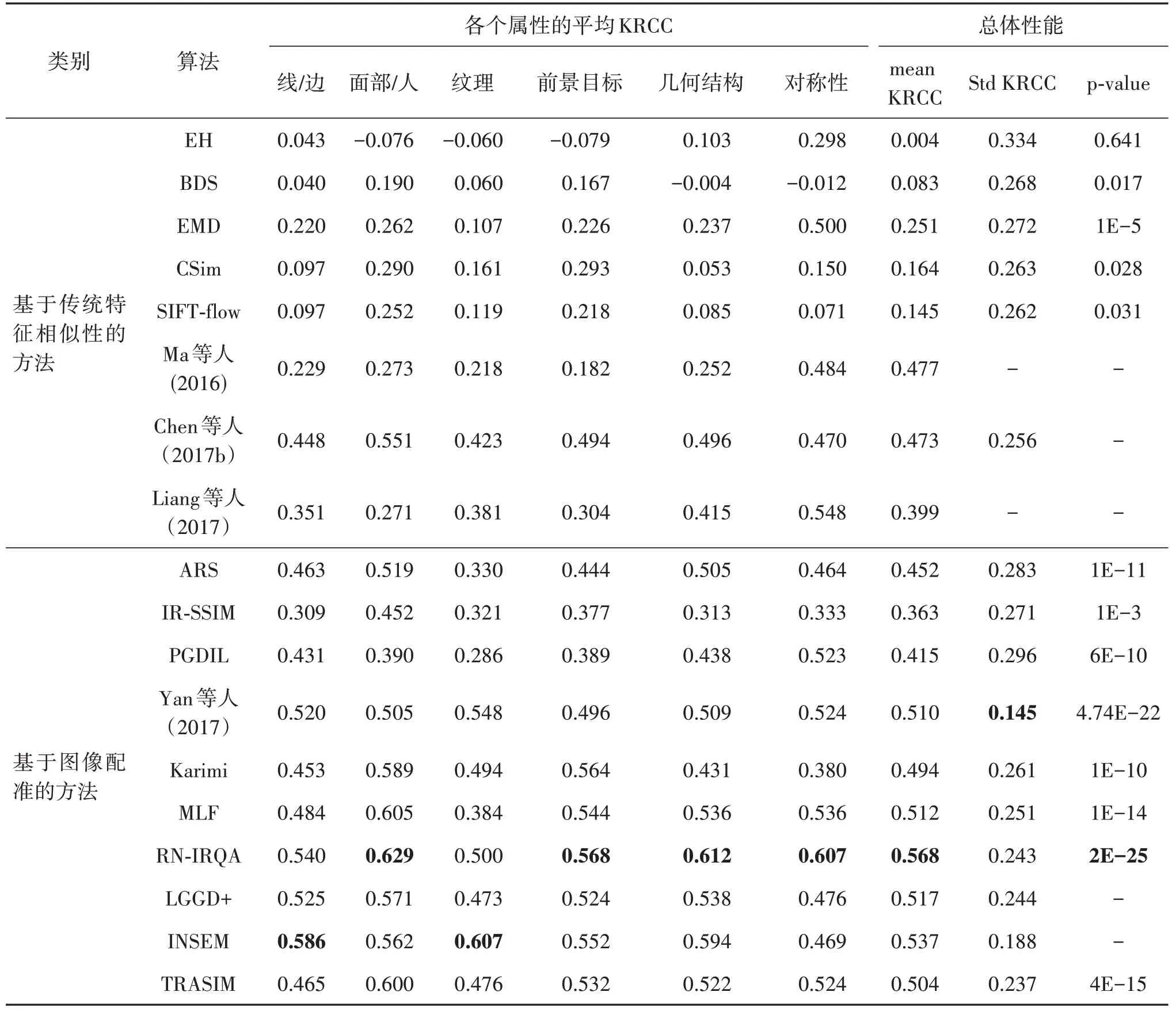
表4 MIT RetargetMe数据集上的性能对比结果Table 4 Performance comparison results on the MIT RetargetMe dataset
由于Karimi 模型和Liang 等人(2017)方法没有提供在CUHK 数据集上的结果,表5 对比了其他16种方法的性能。Yan等人(2017)利用简单神经网络从多个IRQA 方法的输出中学习更好的特征表示,该模型在CUHK 数据集上的性能远高于其他方法。
表6 提供了上述方法和Jiang 等人(2018)方法在NRID 数据集上的性能结果。通过表6 可知,PGDIL 方法具有最佳的性能表现,Li 等人(2021)提出的INSEM方法获得了次优的性能。
综合上述3 个数据集上的实验结果可以得出以下结论:1)现有的IRQA 方法在不同数据集上的性能表现波动较大,因此亟待提高模型的泛化能力及其鲁棒性;2)在设计IRQA 模型时考虑多层次、多尺度以及高层语义等符合HVS 感知特性的特征能够显著提升算法的性能;3)综合来看,基于图像配准的方法由于其能够准确建立两幅图像的映射关系,在表示重定向图像的几何失真和内容损失方面均有其独特的优势,该类方法的总体性能表现普遍优于基于传统特征相似性的方法。
5 结语
5.1 研究总结
随着5G 技术和互联网的发展以及社会生活发展的需要,图像重定向技术的应用引起了社会各界的关注。由于图像重定向质量评价对图像重定向技术的优化和设计具有指导作用,因此对IRQA 模型的研究已经成为图像处理领域的热门方向。本文主要对图像重定向质量评价进行了综述,包括数据集的介绍和客观质量评价两个方面。客观质量评价部分对现有的IRQA 方法进行了较全面的总结。现有的IRQA 方法主要包括基于传统特征相似性的方法和基于图像配准的方法两类。基于传统特征相似性的方法主要依赖于对图像失真特性的分析和研究,通过设计适当的特征描述符,来量化原始图像和重定向图像的质量。这类方法高度依赖手工设计的特征,并且该类方法并不能准确反映HVS 的感知特性,因此其性能有所受限。基于图像配准的方法首先建立原始图像与重定向图像之间的映射关系,基于映射关系计算相应的特征并从内容和几何结构两个方面反映图像的质量。这类方法的计算复杂度较高,且性能受限于图像配准算法的精度。根据对文献的综述及分析,可以看出现有的大多数IRQA 方法均采用手工设计特征的方式来提取特征,并且大多方法仅仅利用低层次特征来估计图像质量。综上分析,图像重定向质量评价领域仍然具有相当大的研究意义和发展空间。
5.2 未来发展方向
相较于其他内容的图像质量评价,目前对IRQA的研究还处于发展阶段,该领域面临着一系列挑战,本节对未来IRQA领域的发展方向进行了展望:
1)构建大规模的图像重定向质量评价数据集。数据集是客观质量评价的数据来源和算法性能评估的标准。根据第2 节所述,目前构建数据集的方法均是通过传统重定向算法处理原始图像来生成重定向图像,并未在构建过程中应用基于深度学习的重定向算法。这也导致了现有数据集存在规模小、失真类型单一等问题,不利于重定向算法及其客观质量评价算法的研究,也限制了图像重定向质量评价领域对于深度学习等技术的应用。因此,亟需构建大规模的图像重定向质量评价数据集,进一步研究基于数据驱动的IRQA方法。
2)研究基于小样本学习的图像重定向质量评价方法。图像质量评价一直以来都存在数据集规模小、失真类型和图像内容不够丰富等限制,是图像处理领域经典的小样本问题。当前IRQA 领域中3 个基准数据集MIT RetargetMe、CUHK 和NRID,包含的重定向图像数量分别为296 幅、171 幅和175 幅,存在失真类型单一和数据量严重不足的问题,不利于对基于学习的IRQA 模型的研究。通过研究基于小样本学习的图像重定向质量评价方法来解决数据匮乏问题,是未来研究中需要重点关注的方向之一。
3)探索基于主观认知的图像重定向质量评价方法。对一幅图像进行图像重定向处理可以得到分辨率不一的多幅图像,这一处理过程导致了不同程度的内容丢失和几何形变。对于同一幅重定向图像,用户的内容偏好和失真容忍度是不一致的。与传统的图像质量评价任务相比,IRQA任务更容易受到用户个体差异的影响。因此,在估计图像质量时,不仅需要度量图像的失真,而且应当考虑用户的主观认知。在以往的一些工作中(Chen等,2017a;Liang等,2017),借助了用户对图像美学质量感知来估计重定向图像质量。基于IRQA 任务的特性,探索主观认知在IRQA 领域的应用是未来可能的发展方向之一。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
作文小学中年级(2020年6期)2020-07-24
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
计算机与网络(2018年19期)2018-09-10
科学与财富(2018年12期)2018-06-11
数学小灵通·3-4年级(2017年9期)2017-10-13
移动通信(2017年13期)2017-09-29
河南科技(2014年23期)2014-02-27
自然资源遥感(2014年3期)2014-02-27
