
注意力引导的三流卷积神经网络用于微表情识别
2024-01-22 10:26赵明华董爽爽胡静都双丽石程李鹏石争浩
中国图象图形学报 2024年1期
赵明华,董爽爽,胡静*,都双丽,石程,李鹏,石争浩
1.西安理工大学计算机科学与工程学院,西安 710048;2.陕西省网络计算与安全技术重点实验室,西安 710048
0 引言
心理学家Albert Mehrabian 的研究表明:面部表情在传递信息的过程中占据大约55%的比例(Mehrabian,1965),远远高于语言沟通和肢体动作。因此,通过对面部表情进行分析可以很大程度上了解人们的情绪与心理。
面部表情按照持续时间和动作强度可以分为宏表情和微表情(Lu 等,2022)。近年来,学者们对宏表情的研究已经非常成熟,在很多领域都有实际应用。宏表情有两个明显的特点:一方面,宏表情通常是自发的且在有意识的状态下产生,适用于各种场景;另一方面,其动作幅度大,可作用于全脸。与宏表情不同,微表情有3 个显著特点:1)往往在高风险场景中于无意识状态下触发且难以掩饰;2)动作强度低,仅作用于局部人脸区域(徐峰和张军平,2017);3)持续时间很短,大约在0.04~0.2 s 之间(Porter 和Ten Brinke,2008;Zhang 等,2014),人眼难以察觉。所以,相比宏表情,微表情的研究面临着更大的挑战。
鉴于微表情自身的特点,人工识别微表情存在很大的困难,即使是经过专业培训的心理学研究人员对微表情的识别准确率也仅仅约47%(Frank 等,2009)。随着计算机视觉和机器学习技术的快速发展,越来越多的研究人员将机器学习算法应用到微表情识别问题中,解决了人工识别存在的很多困难,识别准确率也有了明显提高。但是,目前微表情识别在计算机视觉领域仍然是一个比较前沿的工作,针对这方面的研究主要存在两大挑战:1)由于微表情的数据采集与鉴定很不容易,现有的微表情数据集稀缺(Yan 等,2013,2014;Qu 等,2018;Li 等,2023;Li 等,2013;Davison 等,2018),这使得深度学习在微表情识别中的应用存在困难;2)微表情持续时间短、动作强度低的特点导致特征难以提取,因此需要进行合适的数据预处理与特征提取操作。
本文主要针对上述微表情识别存在的第2 个问题展开研究,采用CASME(Chinese Academy of Sciences microexpression)、CASME II 和SAMM(spontaneous actions and micromovements)的组合数据集(Yan 等,2013,2014;Davison 等,2018),以起始帧和峰值帧的3 个光流信息作为输入,设计并提出了一种注意力引导的浅层三流卷积神经网络(attentionguided three-stream convolutional neural network,ATSCNN)来识别微表情。本文的主要贡献概括如下:1)设计并提出了一种注意力引导的三流卷积神经网络(ATSCNN)用于微表情识别,可以有效防止过拟合、提升网络性能。2)使用ReLU(rectified linear unit)激活函数不仅计算简单,而且能够获得强大的学习和拟合能力。但是该函数可能会造成神经元坏死和梯度消失的情况。因此,本文尝试使用SELU(scaled exponential linear unit)激活函数来解决这一问题。3)在CASME、CASME II 和SAMM 组合数据集中,通过实验验证了本文方法在未加权平均召回率(unweighted average recall,UAR)和未加权F1-Score(unweighted F1-score,UF1)这两个评估指标下的有效性。与现有的主流模型相比,本文方法获得了先进的识别性能。
1 相关工作
自Haggard 和Isaacs(1966)在心理治疗研究中首次注意到微表情的存在之后,学术界针对微表情的研究逐步深入。然而直到2009 年,自动微表情识别才开始出现在计算机视觉领域(Polikovsky 等,2009),相比宏表情识别的研究要晚很多。
早期的研究以基于局部二值模式(local binary patterns,LBP)和光流的方法作为微表情识别的主要技术手段。Pfister 等人(2011)首次将来自3 个正交平面的局部二值模式(LBP from three orthogonal planes,LBP-TOP)应用于微表情识别任务,能够有效提取时空域的纹理特征。此后,LBP-TOP 作为一种经典算法,为后续研究提供基础和验证基准。基于光流的方法计算像素在时域中的变化以及相邻帧之间的相关性,从而找到前一帧和当前帧的对应关系。为了应对微表情持续时间短、动作强度低的挑战,Chaudhry 等人(2009)提出了定向光流直方图(histograms of oriented optical flow,HOOF),大多数基于光流的方法都是HOOF 的变体。此外,Liong 等人(2018)提出了加权定向光流(bi-weighted oriented optical flow,Bi-WOOF),选择图像序列中的起始帧和峰值帧并提取这两帧之间的光流,对HOOF 特征进行全局或局部加权。此后很多工作都利用起始帧和峰值帧来对微表情进行分析,以减少整个图像序列中可能存在的冗余现象。
近年来,深度学习已经成为人们研究的热点,很多学者开始尝试将深度学习应用于微表情识别。在第1 届微表情挑战赛(Yap 等,2018)中,Khor 等人(2018)使用富集长期递归卷积网络(enriched longterm recurrent convolutional network,ELRCN)来预测微表情。通过光流信息(光流水平分量、光流垂直分量和光学应变)学习空间关系,并利用VGG16(Visual Geometry Group)和预训练的VGGFace 模型来丰富输入通道和深层特征叠加。该论文在深度微表情识别工作中具有代表性,但是其相比传统方法仍然不具备优势。此后的第2 届微表情挑战赛(See等,2019)中,深度学习方法在微表情识别任务中已经初步显示出相比传统方法的优越性:Off-ApexNet(optical flow features from apex frame network)(Gan等,2019)网络及改进版本浅层三流三维卷积神经网络(shallow triple stream three-dimensional CNN,STSTNet)(Liong 等,2019)从每个视频的起始帧和峰值帧提取光流特征,然后将得到的光流特征送入浅层卷积神经网络中分类,由于网络层数较浅,减少了因微表情数据稀缺造成的过拟合;EMR(expression magnification and reduction)(Liu 等,2019)采用迁移学习的方法,提取微表情起始帧和峰值帧之间的光流,利用两种域自适应策略达到SOTA(state-of-theart)实验结果;另外,Dual-Inception 网络(Zhou 等,2019)同样是提取起始帧和峰值帧的光流特征,之后再送入两个Inception 网络拼接并分类,在CASME II数据集上的表现最好;而CapsuleNet(capsule network)网络(van Quang 等,2019)仅将峰值帧的像素值输入到预训练的ResNet18(residual network)(He等,2016)中得到特征图,再将所有特征图输入到胶囊网络中提取特征并分类,最终结果在整体上优于LBP-TOP基准网络和几种比较强大的卷积神经网络模型。多尺度卷积神经网络(multi-scale convolutional neural network,MACNN)模型(Lai 等,2020)利用残差块和空洞卷积在低响应时间内对微表情进行分类;唐宏等人(2022)基于光流信息并采用伪三维残差网络学习微表情的时空特征,识别性能优于一些较先进的方法。上述几种网络模型都是以关键帧的光流值作为输入,并且取得了不错的效果。基于此,本文考虑将起始帧和峰值帧这两个关键帧的光流信息作为输入,观察在利用浅层卷积网络进行特征提取的优势。
上述几种神经网络架构均比较简单,没有用到复杂的模块(如注意力机制)。注意力机制最初用于计算机视觉,之后逐渐广泛应用于自动问答、情感分类等机器学习任务中。注意力模块可以给输入的不同部分分配不同的权重。卷积块注意力模块(convolutional block attention module,CBAM)从通道维度和空间维度进行双重特征权重标定,其根据多方向的特征来改善网络的识别效果(Woo 等,2018)。后来,Chen 等人(2020)提出用于微表情识别的带有CBAM 的时空卷积神经网络,该网络以自适应的方式分配特征权重。Micro-attention(Wang等,2020)将微注意力和残差网络相结合,设法通过增加微注意力模块来提高ResNet 在微表情识别中的性能。Off-TANet(optical flow feature-triplet attention net)(Zhang等,2021)是一个基于光流的包含空间注意力、通道注意力和自注意力的轻量级神经网络,利用三重注意力机制改善微表情识别效果。mini-AORCNN(mini-attention-based optical flow residual convolutional neural network)(张嘉淏 等,2022)将残差模块与Bottleneck Transformer 相结合,可以有效避免过拟合并减少模型的参数复杂度。以上几种方法中都用到了注意力机制,在识别性能方面均表现不错,说明注意力机制在微表情识别中的应用是可行的。所以,本文尝试将注意力机制引入微表情识别中,以期获得良好的结果。
2 本文方法
本文的微表情识别算法框架如图1 所示。主要包括两个步骤:光流特征提取和神经网络学习。首先,为了便于提取微表情特征并减少非面部区域的影响,对原始图像进行简单的预处理,并利用(total variation-L1)能量泛函(Pérez 等,2013)提取光流信息;然后,将光流水平分量、光流垂直分量和光学应变这3 个光流值分别送入ATSCNN 中提取微表情特征并得到分类结果。
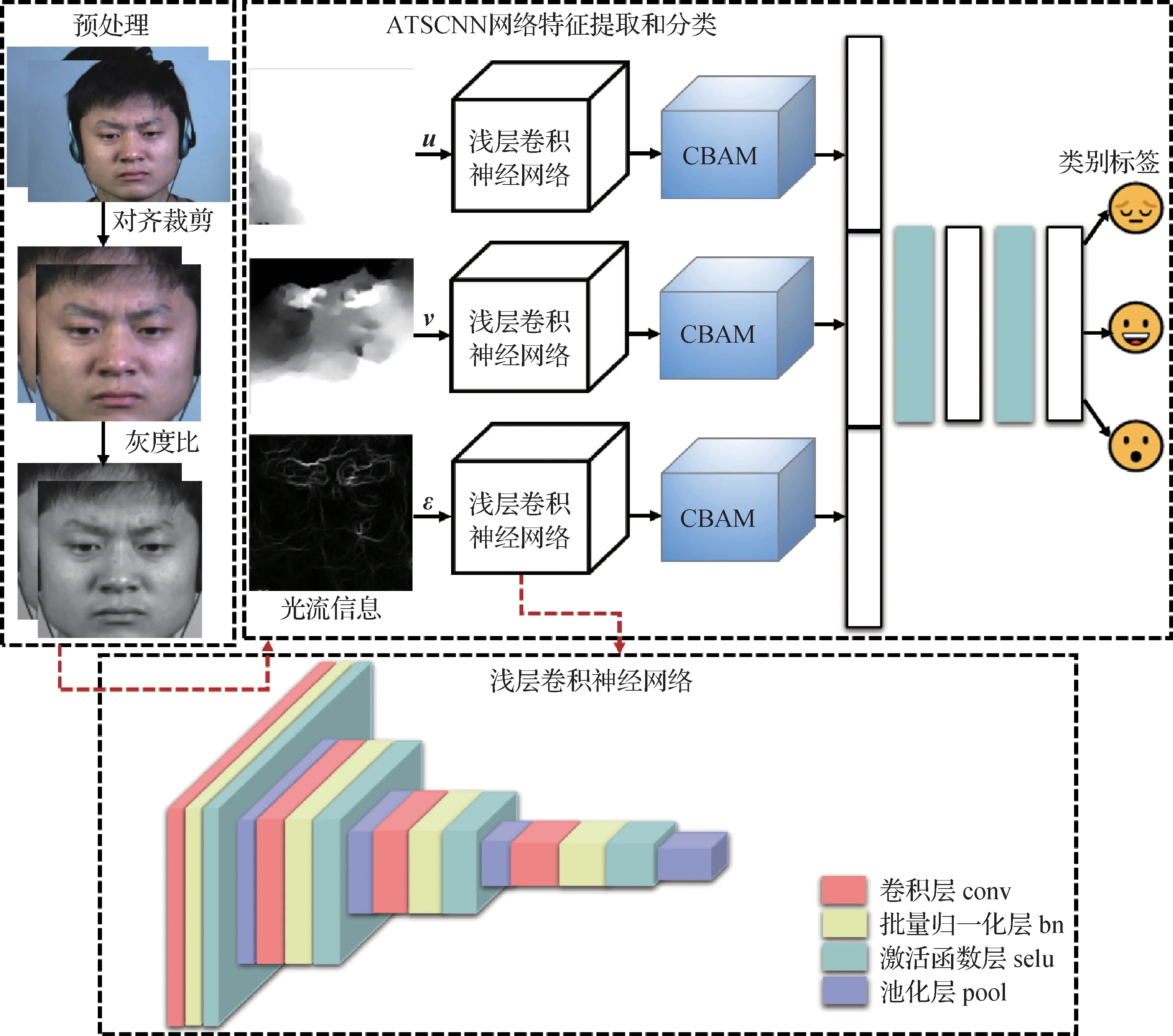
图1 算法框架流程图Fig.1 Algorithm framework flow chart
2.1 光流特征提取
光流法通常基于两个前提假设:1)前后帧的光照亮度保持恒定;2)同一像素在相邻帧之间的运动变化很小。对于微表情而言,一方面,其从起始帧到偏移帧之间的时间间隔很短,所以帧间图像序列的亮度基本保持不变;另一方面,微表情相邻像素之间存在相似的运动,帧之间的相对位移很小。基于此,微表情的特点决定了其满足上述两个基本假设。
虽然微表情的持续时间短、变化速度快,但光流仍然可以捕捉到微表情相邻帧之间具有代表性的运动特征。与原始数据相比,其能够获得更高的信噪比,为网络提供丰富且关键的输入信息。即,光流对面部区域微弱运动的估计很大程度上决定了微表情识别的准确性。本文拟使用噪声鲁棒性较好的TVL1 能量泛函进行光流估计。设u和v分别代表光流场的水平分量和垂直分量。其可以表示为
式中,dx和dy分别表示沿x和y维度的像素变化,dt表示时间变化。
光学应变能够近似面部变形强度,通过计算光流的导数可以得到光学应变,并且可以定义为
式中,对角线应变分量中,(εxx,εyy)是法向应变分量、(εxy,εyx)是剪切应变分量。可以通过取法向应变分量和剪切应变分量的平方和来计算每个像素的光学应变大小,从而有
最后,将u,v,ε这3个包含丰富微表情的光流信息作为3 个输入流分别送入融合了CBAM 注意力机制的浅层三流卷积神经网络中。
2.2 浅层三流卷积神经网络
为了避免过拟合,深度卷积神经网络通常需要大量样本进行训练,然而,目前可用于微表情识别的样本量十分有限。为了在有限的数据集中训练卷积神经网络,本文采用由4 个子网络组成的浅层三流卷积神经网络进行特征提取,每个子网络包括卷积层(conv)、批量归一化层(bn)、激活函数层(selu)和池化层(pool)。利用浅层三流卷积神经网络提取输入3 个光流信息的特征,以缓解过拟合,改善网络性能。表1显示了每个子网络的具体配置。
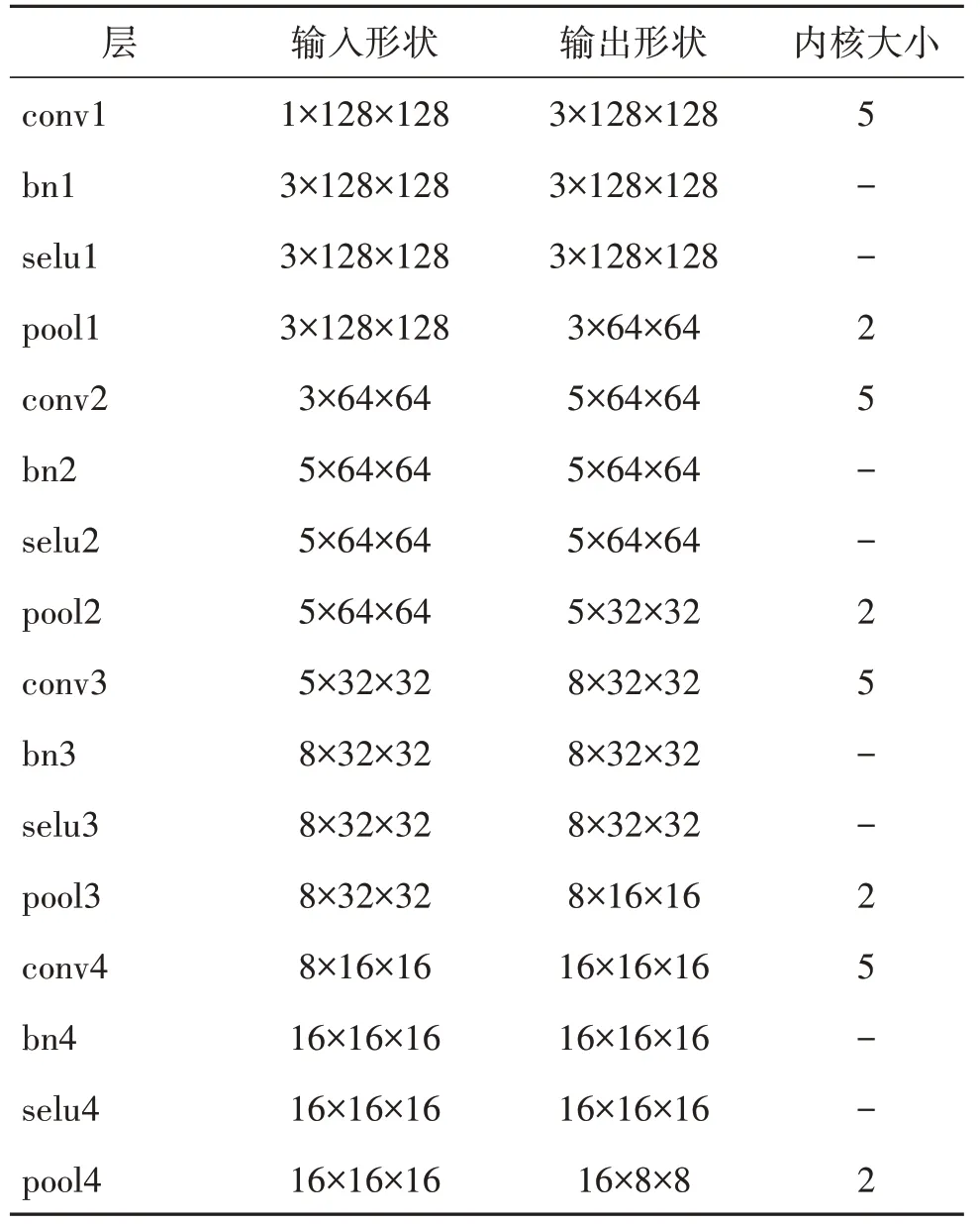
表1 每个子网络的具体配置Table 1 The specific configuration of each sub-network
2.3 CBAM
传统的卷积网络模型可能无法对微小的特征进行有效的捕捉和学习,从而限制了模型的识别性能。此外,微表情通常在时空上分布不均匀,这也需要网络能够有效关注到重要的时间和空间区域。基于上述分析,本文在卷积神经网络之后引入了CBAM 注意力机制。
CBAM(Woo 等,2018)是一种轻量级卷积块注意力模块,可以集成到任何卷积神经网络中,且能与卷积神经网络一起进行端到端训练。如图2 所示,CBAM 将通道注意力和空间注意力两个子模块串联,同时关注通道维度和空间维度的信息,以提高网络获取有效特征的能力。下面将详细说明本文使用的CBAM 中通道注意力和空间注意力这两个子模块。
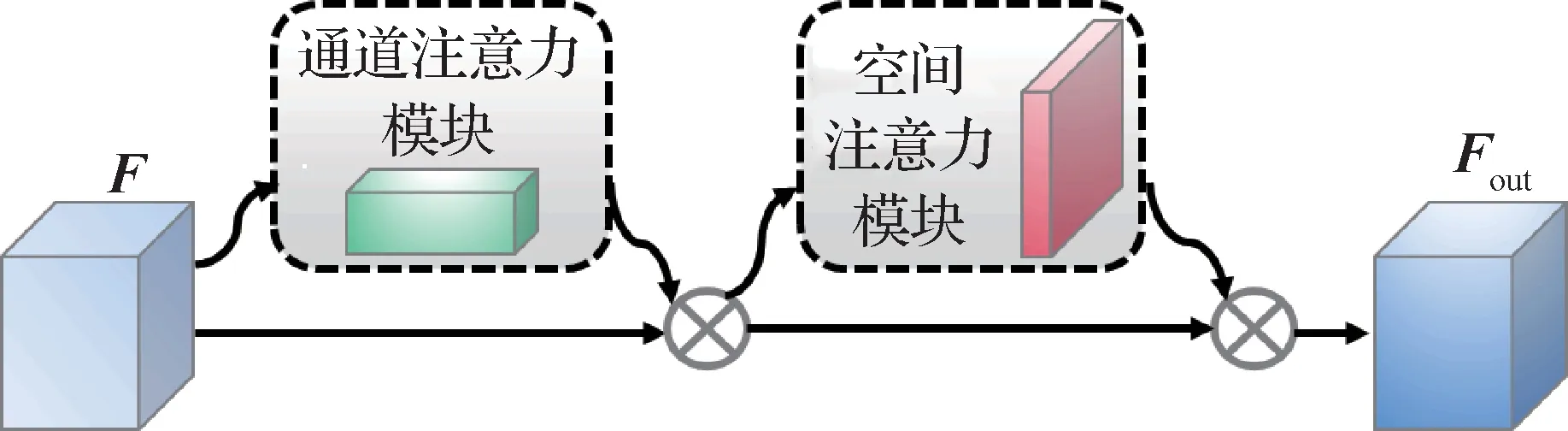
图2 卷积块注意力模块Fig.2 Convolutional block attention module
通道注意力模块主要关注什么样的特征是有意义的,让神经网络自动判断哪个通道重要,从而帮助网络提取包含有用信息的通道。如图3 所示,为了完成特征提取,减少数据丢失,首先,通道注意力机制同时使用平均池化操作和最大池化操作这两种方式将输入特征图F在空间维度进行压缩,保留通道信息,得到两个空间维度为1 的特征图;然后,将这两个空间维度为1 的特征图分别送入共享的多层感知器(shared multilayer perceptron,Shared MLP)中进行处理,得到两个特征图并将其相加;最后,通过sigmoid激活函数,得到最终输出的特征图MC。通道注意力具体可以表示为
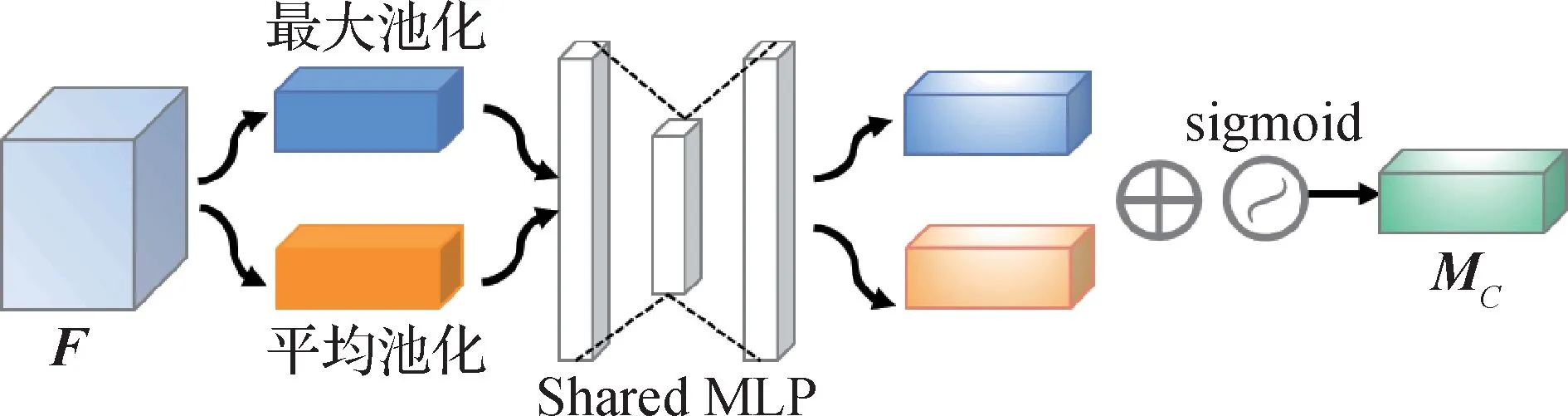
图3 通道注意力模块Fig.3 Channel attention module
式中,δ表示sigmoid激活函数。
空间注意力模块主要关注空间中哪部分的特征是有意义的。如图4 所示,首先对原始输入的特征图F′分别进行一个通道维度的最大池化和平均池化,然后将得到的结果按照通道维度拼接成两个通道,再经过一个3 × 3 的卷积层降为一个通道,最后通过sigmoid 激活函数得到最终的特征图MS。空间注意力具体可以表示为
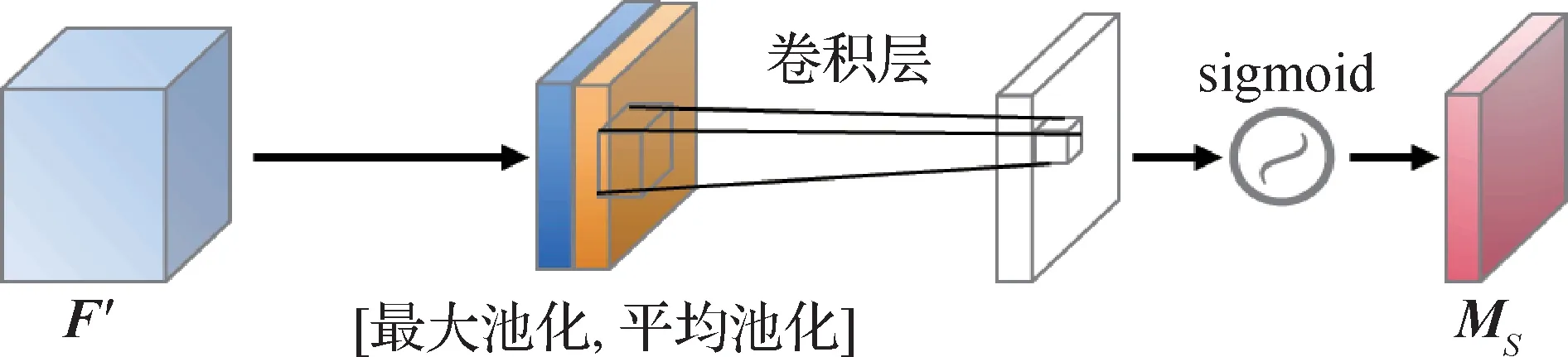
图4 空间注意力模块Fig.4 Spatial attention module
式中,δ表示sigmoid 激活函数,f3×3为3 × 3 的卷积运算。
本文将CBAM 模块添加在浅层卷积神经网络之后,同时关注通道维度和空间维度,期望聚焦输入的重要信息且抑制不相关信息,从而提升微表情的识别效果。
2.4 SELU激活函数
激活函数(Scardapane 等,2020)在神经网络中主要用来完成数据的非线性变换,通过加入非线性激活函数促使网络获得更强的学习和拟合能力。典型的ReLU(rectified linear unit)激活函数(Yarotsky,2017)就是其中之一。其主要包括两个优点:一方面,该函数只需要一个阈值就能计算得到激活值,非常简单;另一方面,ReLU 会使一部分神经元的输出为0,减少参数间的相互依赖关系,能缓解过拟合。但是,ReLU仍有其局限性。当函数在负半轴上的值都为0 时,负梯度经过ReLU 单元不会被激活,导致该神经元坏死;且ReLU 在正半轴的导数恒为1,当梯度过小的时候,经过该函数容易导致梯度消失。ReLU以及ReLU的导数可以分别表示为
SELU 激活函数(Klambauer 等,2017)是基于ReLU 的一种变体,其正半轴导数λ>1,因此可以在方差过小的时候通过乘以λ增大方差,能有效避免梯度爆炸和梯度消失现象;同时,在负半轴不再简单地用0 来表示,而是采用两个超参数λ和α进行调整,从而解决ReLU 中可能存在的神经元坏死问题,增强了网络的表现力和泛化性能。SELU 以及SELU的导数可以分别表示为
式中,超参数λ和α的值是给定的,即:λ≈1.050 7,α≈1.673 26。
因此,本文尝试使用SELU 激活函数以弥补常用的ReLU 激活函数中存在的问题,提高神经网络的收敛速度。
3 实验结果与分析
3.1 数据集与实验设置
3.1.1 数据集
CASME(Yan 等,2013)包含19 名受试者自发产生的195 个微表情样本,其中包括从起始到偏移的所有帧。CASME 由高速摄像机以60 帧/s 的速度记录,样本分辨率为1 280 × 720 像素(section A)或640 × 480 像素(section B)。CASME 数据集中的样本分为8 个微表情情感类别(“happiness”、“surprise”、“disgust”、“repression”、“sadness”、“contempt”、“fear”和“tense”)。情绪的标注部分基于AUs(action units),同时考虑了受试者的自我报告和视频片段的内容。除了起始帧和偏移帧,也标记了贡献情绪最多的峰值帧。
CASME II(Yan 等,2014)是CASME 数据集的改进版本。其微表情样本增加到255 个,包含26 名有效的受试者,由高速摄像机以200 帧/s 记录,样本分辨率为640 × 480 像素。因此,与CASME 相比,CASME II 具有更高的时间和空间分辨率。样本标记了起始帧、峰值帧和偏移帧。情绪类别包括:“happiness”、“surprise”、“disgust”、“repression”、“fear”、“others”和“sadness”,共7类。
SAMM(Davison 等,2018)从32 名受试者中收集了159 个微表情样本。与之前缺乏种族多样性的数据集不同,受试者来自13 个不同的种族。样本是在受控照明条件下以200帧/s的速度采集的,分辨率为2 040 × 1 088 像素。实验过程中捕捉到的微表情类别包括:“happiness”、“surprise”、“anger”、“contempt”、“disgust”、“fear”、“sadness”和“other”。样本基于AUs标记了起始帧、峰值帧和偏移帧。
本文使用上述3 个数据集中包含丰富微表情的样本得到新的组合数据集进行实验。舍弃了CASME(Yan 等,2013)中情绪类别为“contempt”、“fear”和“tense”的所有样本、CASME II(Yan 等,2014)中情绪类别为“fear”、“others”和“sadness”的所有样本及SAMM(Davison 等,2018)中的“other”样本。为了缓解所使用的数据集之间存在的类别不平衡问题,本文将原始情绪标签映射到“negative”、“positive”和“surprise” 3 个类别中。表2 列出了本文使用的微表情组合数据集的分类信息。
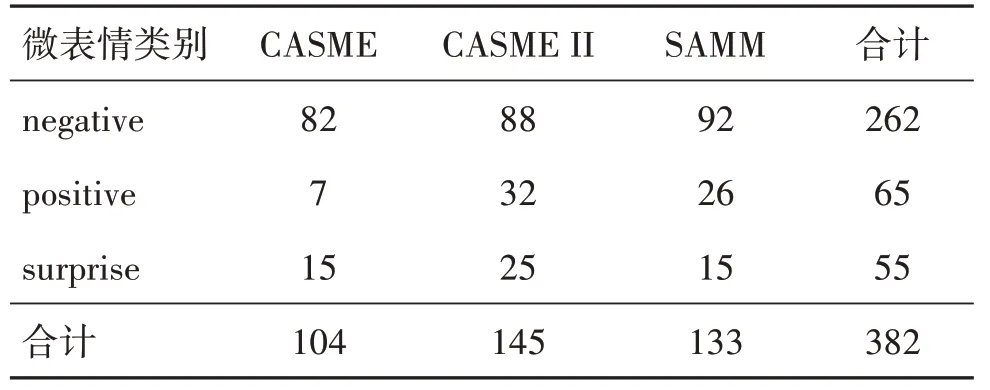
表2 微表情组合数据集的情绪分类信息Table 2 Emotion classification information of micro expression combination dataset
为了最大程度上减少图像序列中非面部区域对微表情识别的影响,本文利用dlib 库提供的68 个人脸关键点检测的模型来实现面部对齐操作,并将样本分辨率统一调整为128 × 128 像素。由于颜色容易受到光照影响,造成RGB 变化较大;且三通道转换为单通道,无需进行加和操作,计算量大大减少。因此,在提取光流特征之前,将RGB 图像转换为灰度图以减少计算量。另外,考虑到微表情相邻帧之间的变化非常微小,为了减少冗余,本文选取每个样本的起始帧和微表情变化最大的峰值帧进行处理。
3.1.2 数据集性能评估指标
由于表1 中选取的组合数据集情绪类别依然具有不平衡性,使用传统的性能评估指标(如:精确度)将会导致过拟合。因此,本文使用UAR 和UF1 这两个性能度量指标以减少所提方法潜在的偏差。
UF1也称为宏观平均F1分数,通过对每类F1分数进行平均来确定。其中,F1 分数可以解释为精度和召回率的加权平均值,当F1 分数等于1 时达到最佳值,等于0时达到最差值。精度(precision,P)和召回率(recall,R)对F1 分数的相对贡献是一样的。F1分数可表示为
UAR 可以表示为每个类别的平均精度除以类的数量,而不考虑每个类的样本。UAR 能减少由于类别不平衡而引起的偏差,也称为平衡精度。UAR具体可以表示为
式(12)—式(17)中,C是所划分的情绪类别数(C=3),S是受试者个数(S=67)。TP(true positive)表示真阳性,即实际是正样本、分类器预测也是正样本。FN(false negative)表示假阴性,即实际是正样本,分类器预测是负样本。FP(false positive)表示假阳性,即实际是负样本、分类器预测是正样本。
3.1.3 实验设置
本文网络模型基于Python3.7.15 版本、利用PyTorch1.13.0 框架训练,显存为10 GB。本文方法使用的初始学习率为0.000 1,batch_size 设置为64,epoch 为200。在训练模型时,使用交叉熵损失函数和自适应矩估计优化器(Adam)优化。
本文采 用留一被试(leave-one-subject-out,LOSO)交叉验证策略,其中,每个受试者都被作为测试集,所有剩余的样本用于训练。本文使用的组合数据集一共包括67 个受试者(15 个受试者来自CASME,24 个受试者来自CASME II,28 个受试者来自SAMM),因此,一轮实验需要重复评估67 次。这种验证方法能充分利用样本并且具有一定的泛化能力,在目前微表情识别的研究工作中普遍应用。
3.2 算法比较
将本文方法与其他主流方法进行对比,在组合数据集上得到的结果如表3 所示,表3 中包括性能评价指标UAR 和UF1。此外,还提供了所有模型的总参数量(total params)、总浮点运算次数(total flops)和总内存读写量(total MemR+W)。表3 中涉及的所有实验结果均是重新实现的。
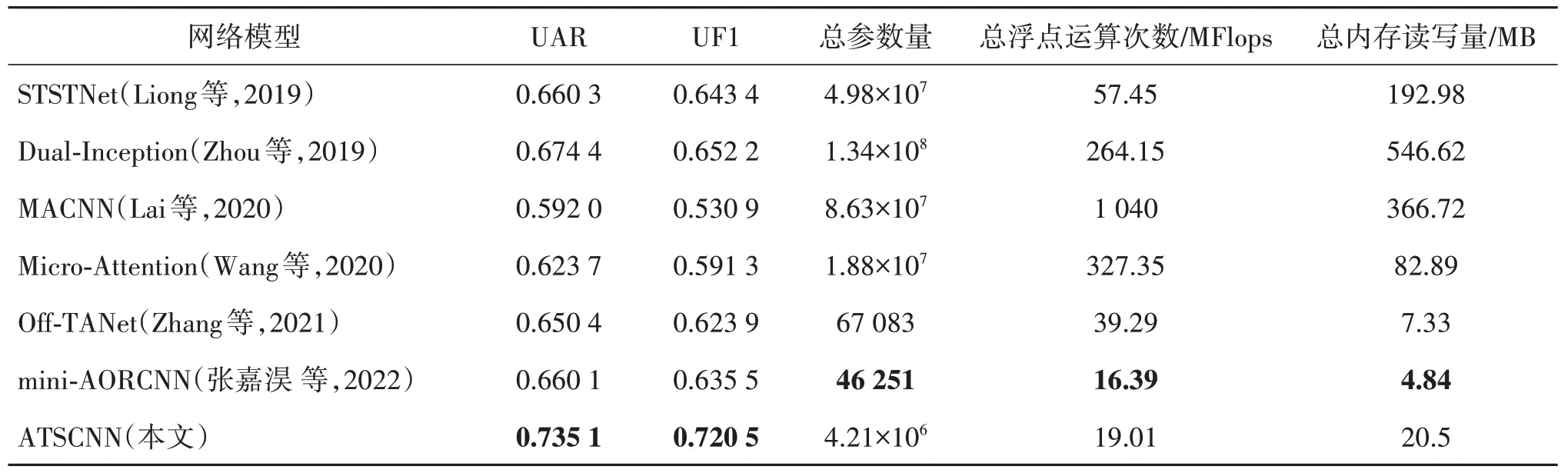
表3 本文方法与主流算法的对比Table 3 Comparison between this method and mainstream algorithms
根据表3 中的结果可以看出,本文提出的ATSCNN模型在组合数据集上获得的UAR(0.735 1)和UF1(0.720 5)性能最优。具体来讲,与应用浅层卷积网络的STSTNet(shallow triple stream threedimensional CNN)(Liong等,2019)相比,UAR 提高了0.074 8,UF1 提高了0.077 1,证明本文在设计的卷积网络基础上引入注意力机制效果显著。与使用两个Inception 网络进行特征提取与分类的Dual-Inception(Zhou 等,2019)相比,UAR 提高了0.060 7,UF1 提高了0.068 3。一方面说明光学应变信息对于提取面部特征的重要性;另一方面也说明了注意力机制对重要信息的关注度。与采用残差块和空洞卷积的MACNN(multi-scale convolutional neural network)(Lai 等,2020)模型相比,UAR 提高了0.143 1,UF1 提高了0.189 6,识别性能大幅提升,进一步证实了本文方法的有效性。与结合微注意力和残差网络的Micro-Attention(Wang 等,2020)模型相比,UAR提高了0.111 4,UF1 提高了0.129 2,说明本文方法将注意力与浅层卷积网络相结合在特征提取方面的效果更好。与基于三重注意力机制的微表情识别网络Off-TANet(optical flow feature-triplet attention network)(Zhang 等,2021)相比,UAR 提高了0.084 7,UF1 提高了0.096 6,这可能得益于本文提出的浅层卷积网络在有限样本量上较好的特征提取能力。与融合了残差模块和Bottleneck Transformer 的mini-
AORCNN(mini-attention-based optical flow residual convolutional neural network)(张嘉淏 等,2022)网络模型相比,UAR提高了0.075 0,UF1提高了0.085 0,虽然该方法的参数量是几个对比方法中最少的,但是在识别性能上仍然低于本文方法。综上所述,本文提出的ATSCNN 模型在对比方法中取得了最好的微表情识别效果。
3.3 消融实验
如表4 所示,为了进一步证实本文ATSCNN 架构的有效性,使用LOSO 交叉验证方法设计了6组对比实验。
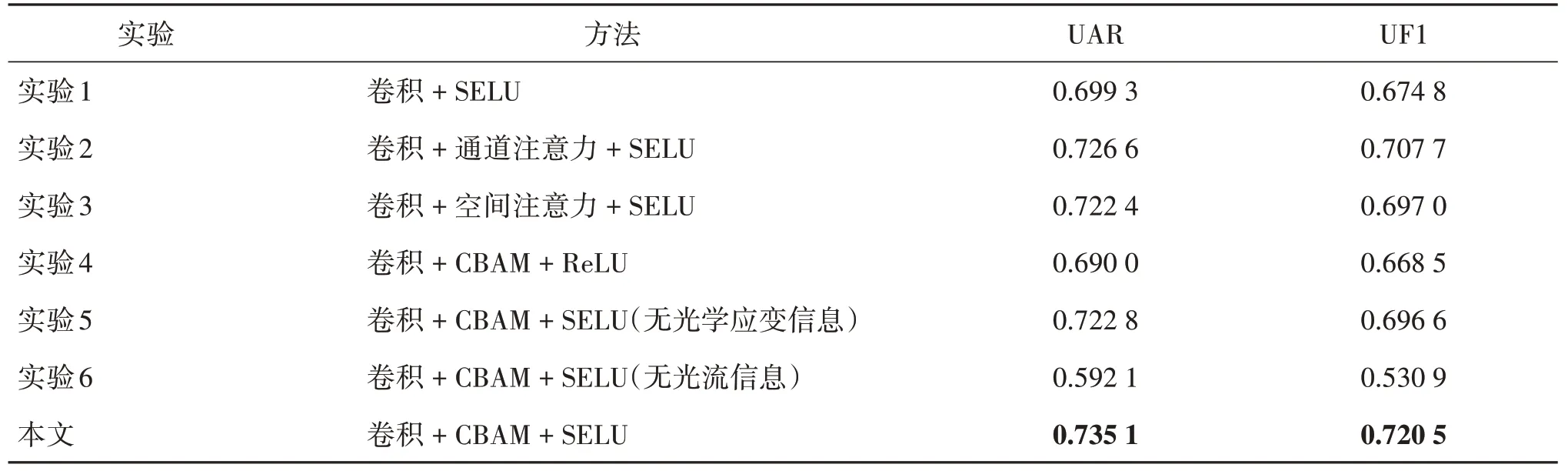
表4 消融实验结果Table 4 Results of ablation experiments
实验1 中,不添加注意力机制,仅使用浅层三流卷积神经网络进行实验,对比发现本文引入CBAM注意力机制明显提高了微表情识别结果:UAR 增加了0.035 8,UF1增加了0.045 7。
实验2 中,仅利用通道注意力模块进行实验,结果表明引入通道注意力模块对识别效果有一定的提升:UAR增加了0.008 5,UF1增加了0.012 8。
实验3 中,只使用空间注意力模块进行实验,以证明同时关注通道和空间两个维度确实能够提升识别性能:UAR增加了0.012 7,UF1增加了0.023 5。
实验4 中,利用ReLU 激活函数进行实验,发现相比ReLU,本文使用SELU 激活函数能够提高神经网络的收敛速度,识别性能显著提升:UAR 增加了0.045 1,UF1 增加了0.052 0。原因是SELU 激活函数解决了ReLU 激活函数中可能会存在的神经元坏死以及梯度消失问题。
实验5 中,不计算光流的导数,即不添加光学应变,只利用光流水平分量和光流垂直分量两种光流信息,发现本文增加光学应变这一输入流可以很好地近似面部变形强度,微表情识别效果有一定幅度提升:UAR增加了0.012 3,UF1增加了0.023 9。
实验6 中,只利用单通道灰度图作为输入,不计算光流信息,从而证明利用光流信息能够提供更加丰富的输入,获得与原始数据相比更高的信噪比,从而显著增强后续网络的特征提取能力:UAR 增加了0.143 0,UF1增加了0.189 6。
4 结论
微表情自身运动幅度微弱、持续时间短暂的特性决定了对其进行特征提取的难度。本文提出了一种基于光流的用于微表情识别研究的神经网络架构ATSCNN,由融合了CBAM 注意力机制的浅层三流卷积神经网络组成,在有限的样本量下实现了对微表情的高效特征提取。其中,浅层卷积神经网络主要用于缓解小数据集上存在的过拟合问题,同时,考虑到浅层卷积神经网络在捕捉微小特征方面的局限性,引入CBAM 注意力机制以聚焦重要特征并抑制无关特征。此外,在整个模型中采用SELU 激活函数替代常用的ReLU 激活函数,明显提高了神经网络的表达能力和收敛速度。本文采用LOSO 交叉验证策略,在使用的组合数据集(CASME、CASME II 和SAMM)中测试了ATSCNN 模型,并与现有基于深度学习的6 个主流模型进行对比,UAR 和UF1 都达到了最优结果,证实了所提方法在识别性能方面具有一定的优势。同时,执行6 组消融实验以进一步确保本文网络模型在微表情识别中的有效性。
虽然本文方法取得了不错的识别效果,但是距离投入工程应用仍需进一步研究与探索。因此,未来的工作将着力解决微表情数据集中样本稀缺以及类别不平衡的问题,使现有方法可以呈现出更好的识别效果。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电光与控制(2018年10期)2018-10-13
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国铁道科学(2014年6期)2014-06-21
电视技术(2014年19期)2014-03-11
