
基于深度强化学习的无人机航路规划算法研究
2024-01-05 12:42毕文豪段晓波
航空科学技术 2023年12期
毕文豪,段晓波
西北工业大学,陕西 西安 710072
近年来,随着信息工程、控制理论、人工智能等技术的不断发展,无人机(UAV)在军事领域的应用越来越广泛。目前,军用无人机可以完成对地侦察、对地打击、无人货运等战术功能。同时,无人僚机、无人机编队协同作战和无人机集群作战等更高层次作战功能也在不断发展中。为了更好地完成上述任务,无人机需要具有根据战场环境和任务需求进行自主航路规划的能力。
航路规划是指在环境约束、飞行性能约束等约束条件下,寻找无人机从起始点到目标点、满足特定任务指标的飞行航路。航路规划可以帮助无人机在面对不同任务功能时,以最小的损失(如时间、受损程度等)完成相应的作战任务,其中主要需要考虑三个方面:(1)面向地形约束,考虑地形变化产生的碰撞威胁;(2)在飞机性能、燃油量和武器性能等约束下规划合理的飞行航路;(3)降低作战环境中无人机遇到不确定风险的可能性,如敌方雷达、防空导弹等战场威胁,提高飞行器安全冗余和作战效能[1]。
目前,航路规划主要包含三种方法:一是基于几何模型搜索的方法,如A*算法[2-3]、Dijkstra算法[4]等;二是基于虚拟势场的方法,如人工势场法[5]等;三是基于优化算法的方法,如蚁群算法[6]、遗传算法[7]、粒子群算法[8]、灰狼算法[9]等。
近年来,人工智能技术的快速发展为无人机航路规划技术的研究提供了新的思路。参考文献[10]提出了一种基于Layered PER-DDQN的无人机航路规划算法,通过战场环境分层将航路规划问题分解为地形规避问题和威胁躲避问题,有效解决了无人机在战场环境中的航路规划问题。参考文献[11]提出了一种基于REL-DDPG 的无人机航路规划算法,有效解决了复杂三维地形环境下的航路规划问题。
本文利用不同深度强化学习算法的优势,结合目标网络模型、竞争网络模型和优先级经验重现策略构建PER-D3QN模型,并将其应用于解决战场环境下无人机航路规划问题。搭建了包含战场三维地形和战场威胁的战场环境模型,通过与Double DQN、DQN 和A*算法的仿真结果对比,验证本文算法具有较好的收敛性、稳定性、适用性和实时性。
1 战场环境建模
战场环境建模是利用数学建模的方法对无人机作战场景进行抽象化表述。对于战场环境下无人机航路规划问题,需要考虑战场三维地形和战场威胁。
1.1 战场三维地形建模
本文利用数字高程模型(DEM)描述战场三维地形,该方法利用有限数量的地形高程数据对地面的地形构造进行数字化模拟,可表示为{Vi=(xi,yi,zi)|i=1, 2, …,n, (xi,yi)∈D} ,其中,(xi,yi)∈D表示平面坐标,zi表示(xi,yi)位置的高程信息。
数字高程模型可以通过简单的数据结构实现地形信息的表示,但由于数据总量和数据密度受数据来源的限制,无法获取地形上每一点的具体数据。本文采用双线性内插法[12]来解决这一问题,即根据待采样点与高程数据库中已有相邻点之间的距离确定相应权值,计算出待采样点的高度值,如图1所示。待采样点p的高程信息计算公式为
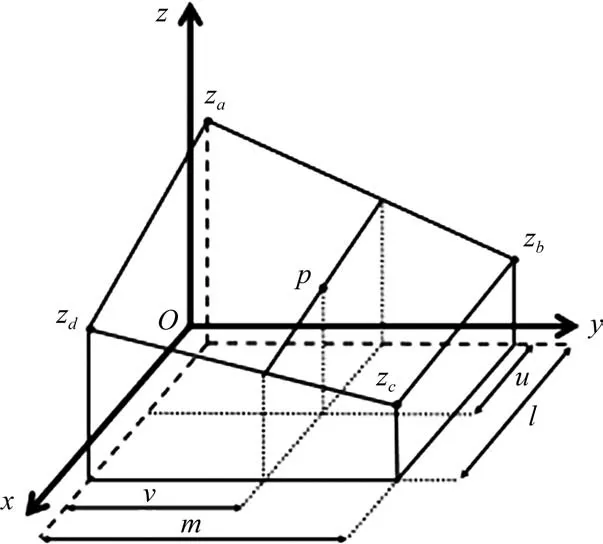
图1 数字高程模型双线性内插法示意图Fig.1 Bilinear interpolation for DEM
zp=(l-u)(m-v)za+(l-u)vzb+uvzc+u(m-v)zd(1)
其中,za,zb,zc,zd表示相邻点的高程数据。
1.2 战场威胁建模
在战场环境中,战场威胁是无人机航路规划中的重要约束之一,主要包括雷达探测、防空导弹、防空高炮等。无人机在执行航路规划时,需要对战场威胁区域进行规避,在自身不受损伤的前提下完成指定的任务。本文以防空武器所处位置为圆心,依据防空武器作战半径设定圆形威胁区。
2 基于PER-D3QN的无人机航路规划算法
2.1 深度强化学习
强化学习是一种基于马尔可夫决策过程框架,使用状态、动作和收益定义智能体与环境之间的交互过程,通过智能体在环境中不断探索、试错的方式进行学习,根据环境对当前状态下所选取动作的反馈收益调整探索策略的机器学习方法。
深度强化学习(DQN)在强化学习的基础上,通过构建深度神经网络(DNN)表征智能体的动作价值函数。动作价值函数表示为Q(st,at|θ),其中,st和at表示t时刻智能体的状态和动作,θ表示网络参数。DQN 算法通过最小化损失函数L(θ)的方式更新网络参数θ,使得网络Q(st,at|θ)的输出不断逼近最优动作价值。损失函数L(θ)的定义为
式中,y为网络更新的目标值;γ∈[0,1]为折扣系数;Rt+1为收益函数。
2.2 PER-D3QN算法
在DQN算法中,智能体的动作价值函数网络在更新过程中存在由于训练样本相关性强导致的过拟合问题和网络更新参数相关联导致的网络优化不稳定问题。针对上述问题,相关研究人员提出了Double DQN、Dueling DQN等方法。
Double DQN[13]在DQN 算法的基础上引入目标网络Q(st,at|θ-)解决过拟合问题。Double DQN首先利用预测网络Q(st,at|θ)选取最大价值的动作,然后利用目标函数计算该动作对应的价值,并与收益函数共同构成目标更新值y',其表达式为
Dueling DQN[14]将竞争网络模型引入DQN 算法中,通过将动作价值函数分解为状态价值函数和动作优势函数,提高对最优策略的学习效率。竞争网络的表达式为
式中,V(st|θ,α)为状态价值函数,A(st,at|θ,β)为动作优势函数,α和β为对应网络的参数。
此外,相关研究人员提出在DQN算法中加入经验重现策略,将智能体与环境交互得到的样本数据存储至经验重现池,当进行网络更新时,从经验重现池随机提取小批量的样本数据进行训练,消除样本之间的关联性,从而提升算法的收敛效果和稳定性。
优先级经验重现(PER)[15]是指在经验重现策略的基础上,根据经验重现池中数据样本的优先级进行采样学习,从而提升网络的训练效率。在网络训练过程中,目标值与预测值之间的误差越大,预测网络对该状态的预测精度越低,则其学习的优先级越高。定义第i组数据样本的优先度为

PER-D3QN 算法是一种结合Double DQN、Dueling DQN 和优先级重现策略的深度强化学习算法。该方法联合了上述方法的优势,有效地提高了复杂环境下智能体的学习效率和准确性。
本文利用PER-D3QN算法解决无人机航路规划问题,构建如图2所示的算法模型。本文所提算法旨在让无人机能够根据当前在战场环境中的所处状态st,利用PERD3QN 算法选择飞行动作at并获得相应收益Rt+1,实现无人机在战场环境中的全局航路规划。
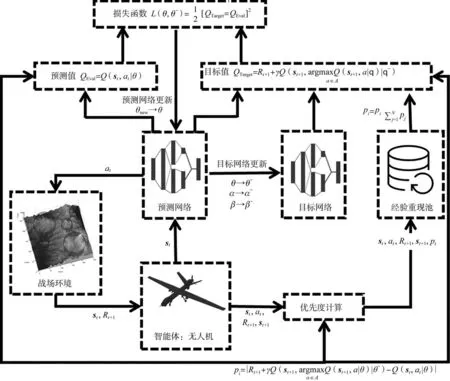
图2 基于PER-D3QN的无人机航路规划算法网络模型Fig.2 Network model of UAV path planning method based on PER-D3QN
2.3 航路规划算法实现
2.3.1 状态空间
在战场环境下,无人机的状态空间包含地形环境状态、威胁区域状态和与目标点的相对状态。
地形环境状态用于描述无人机当前时刻与其周围地形环境的相对位置关系,其表达式为
威胁区域状态用于表示无人机当前时刻与战场威胁区域的相对位置关系,如图3所示,其表达式为
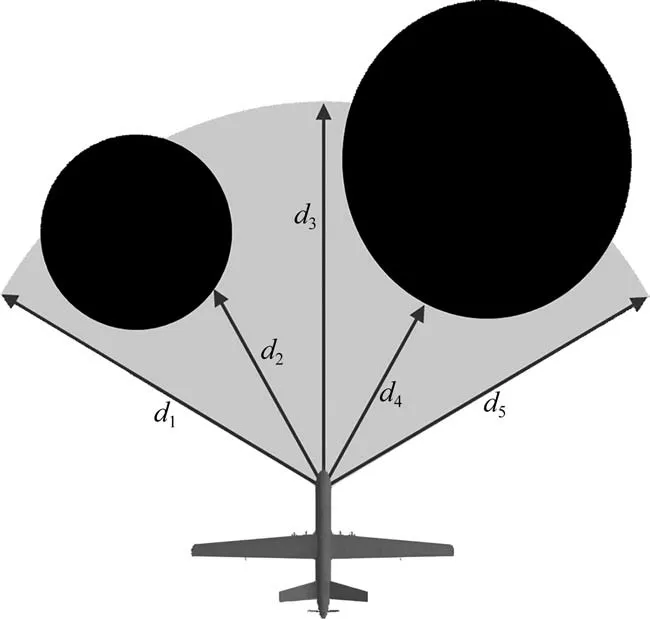
图3 威胁区域状态示意图Fig.3 Diagram of threat area state
式中,R表示威胁区感知半径。
无人机与目标点的相对状态用于引导无人机飞向目标位置,其表达式为
式中,φt和γt分别为无人机所处位置与目标点的航向角度差和俯仰角度差,如图4所示。
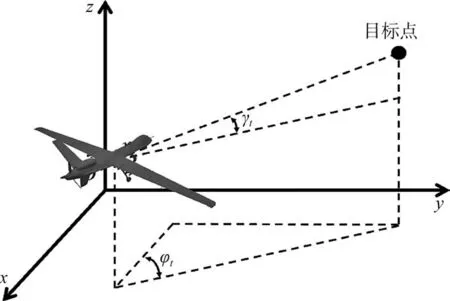
图4 无人机与目标点相对状态示意图Fig.4 Diagram of the relative state of the UAV and the target point
根据以上三个状态即可得到无人机在t时刻的状态矢量,即
2.3.2 动作空间
综上可见,除个别BITs“保护与安全”条款相对较理想、较适合目前和未来中国防范在发展中国家投资的安全风险外,与多发展中国家的BITs“保护与安全”条款空泛和模糊,总体上未能超越国际习惯法最低待遇标准,其国际法效果是,中国难以主张东道国对安全风险损害承担国家责任,不能为中国投资者及其投资和人员提供充分有效的保护与安全。
动作空间是无人机可采取的行为集合,本文采用的动作空间共包含9个离散动作,分别为向右下方飞行a1、向下方飞行a2、向左下方飞行a3、向右方飞行a4、向前方飞行a5、向左方飞行a6、向右上方飞行a7、向上方飞行a8和向左上方飞行a9,如图5 所示。无人机可根据当前状态从上述离散动作中进行选择。动作空间A可表示为
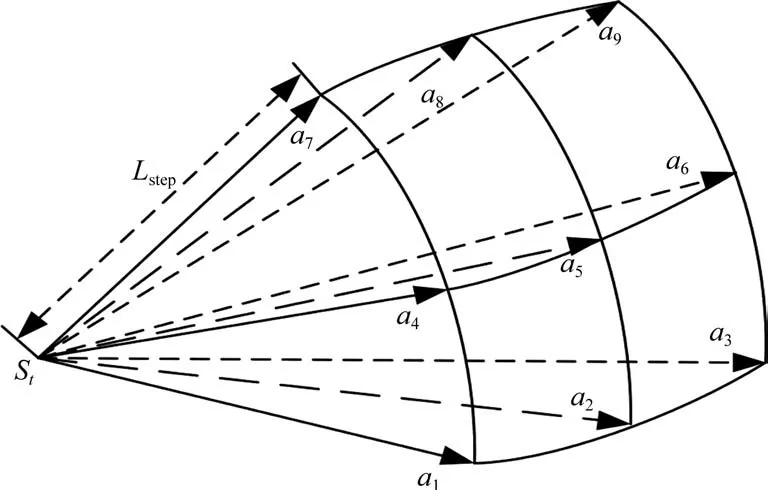
图5 动作空间示意图Fig.5 Diagram of action space
2.3.3 收益函数
针对无人机规划问题的特点,从任务完成、地形避障、威胁区域躲避、飞行高度控制、飞行引导等角度设计深度强化学习的收益函数。
(1) 任务完成收益函数
无人机航路规划的首要目标是规划出从初始点到目标点的飞行航路,当无人机完成航路规划时给予其正向奖励,表达式为
式中,kM为无人机抵达目标点给予后的激励值,sTarget为无人机抵达目标点时的期望状态。
(2) 地形避障收益函数
无人机在飞行过程中需要及时躲避地形障碍,当无人机与地面发生碰撞时给予惩罚反馈,表达式为
式中,kG表示惩罚反馈;zt表示无人机当前时刻飞行高度;hsafe表示无人机与地面的安全距离;zt,G表示无人机所处位置的地形高度。
(3)威胁区域躲避收益函数
在战场环境下,无人机需要尽量避免进入敌方防空武器的威胁区,根据进入威胁区的距离设计反馈函数,表达式为

式中,kL>0 为飞行引导奖励系数,Distance(st,sTarget)为无人机当前位置与目标位置的距离,sigmoid(·)用于调整数值区间,其表达式为sigmoid(x) =(1 + e-x)-1。
综合以上收益函数,得到总收益函数,即
式中,γM,γG,γT,γH和γL分别为任务完成收益函数、地形避障收益函数、威胁区域躲避收益函数、飞行高度控制收益函数和飞行引导收益函数的权重系数。
3 试验与结果分析
本文在Python 编程环境中利用PyTorch 框架构建PERD3QN 网络,用于算法训练和测试的计算机配置为Intel i7-12700H CPU,NVIDIA RTX 3060 GPU,32GB运行内存。
为验证本文算法的可行性和有效性,使用Double DQN、DQN 和传统A*算法进行对比试验。试验在随机生成的100幅战场环境地图中进行,其中,训练过程使用80幅战场环境地图,测试过程使用20 幅战场环境地图。A*算法只在测试过程的战场环境地图中进行仿真。PER-D3QN、Double DQN和DQN在训练过程中的学习曲线如图6所示。
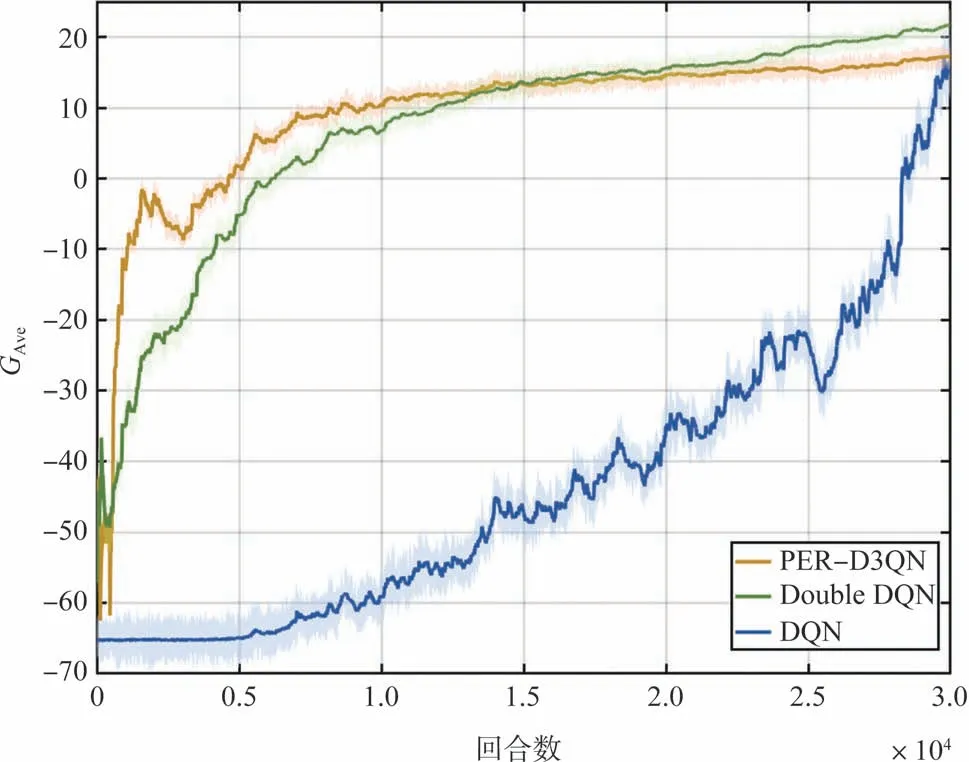
图6 PER-D3QN,Double DQN和DQN的学习曲线Fig.6 Reward curve for PER-D3QN, Double DQN and DQN
在训练过程中,智能体采用PER-D3QN、Double DQN和DQN算法各进行了30000回合的探索与学习。图6展示了智能体在训练过程中获得的平均收益,其中,PER-D3QN在训练至7500回合后达到收敛状态,收敛效果优于Double DQN和DQN。
为验证智能体训练过程的有效性,对训练好的算法模型进行测试。在测试过程中,对20幅战场环境地图各随机生成50 组起始点和目标点,共构建1000 个仿真场景。将PER-D3QN、Double DQN、DQN和A*算法在上述仿真场景中进行测试,对航路规划成功率、平均航程和算法平均计算时间进行计算和统计。
航路规划成功率是指测试过程中成功完成航路规划的次数与总测试次数的比值,其计算公式为
式中,Ns表示成功完成航路规划的次数;Na表示总测试次数。
平均航程和平均计算时间在4种算法均成功完成航路规划的仿真场景中计算并统计。平均航程是指各算法规划得到的飞行航路航程的平均值,其计算公式为
式中,Lave为平均航程;Nv指飞行航路的个数;Mi为第i条飞行航路的节点数量;si,j为第i条飞行航路的第j个航路节点。
平均计算时间是指算法运行所消耗时间的平均值,其计算公式为
式中,Tave为平均计算时间;tc,i为规划第i条飞行航路的计算耗时。
测试过程的统计结果见表1,得到的部分航路规划结果如图7所示。
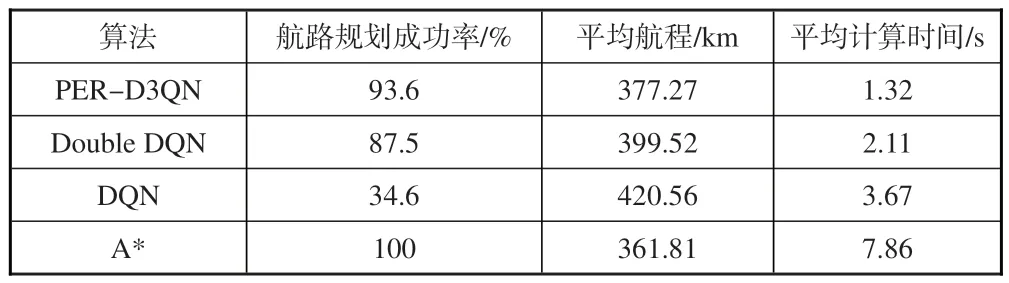
表1 算法测试结果统计Table 1 Method test result statistics
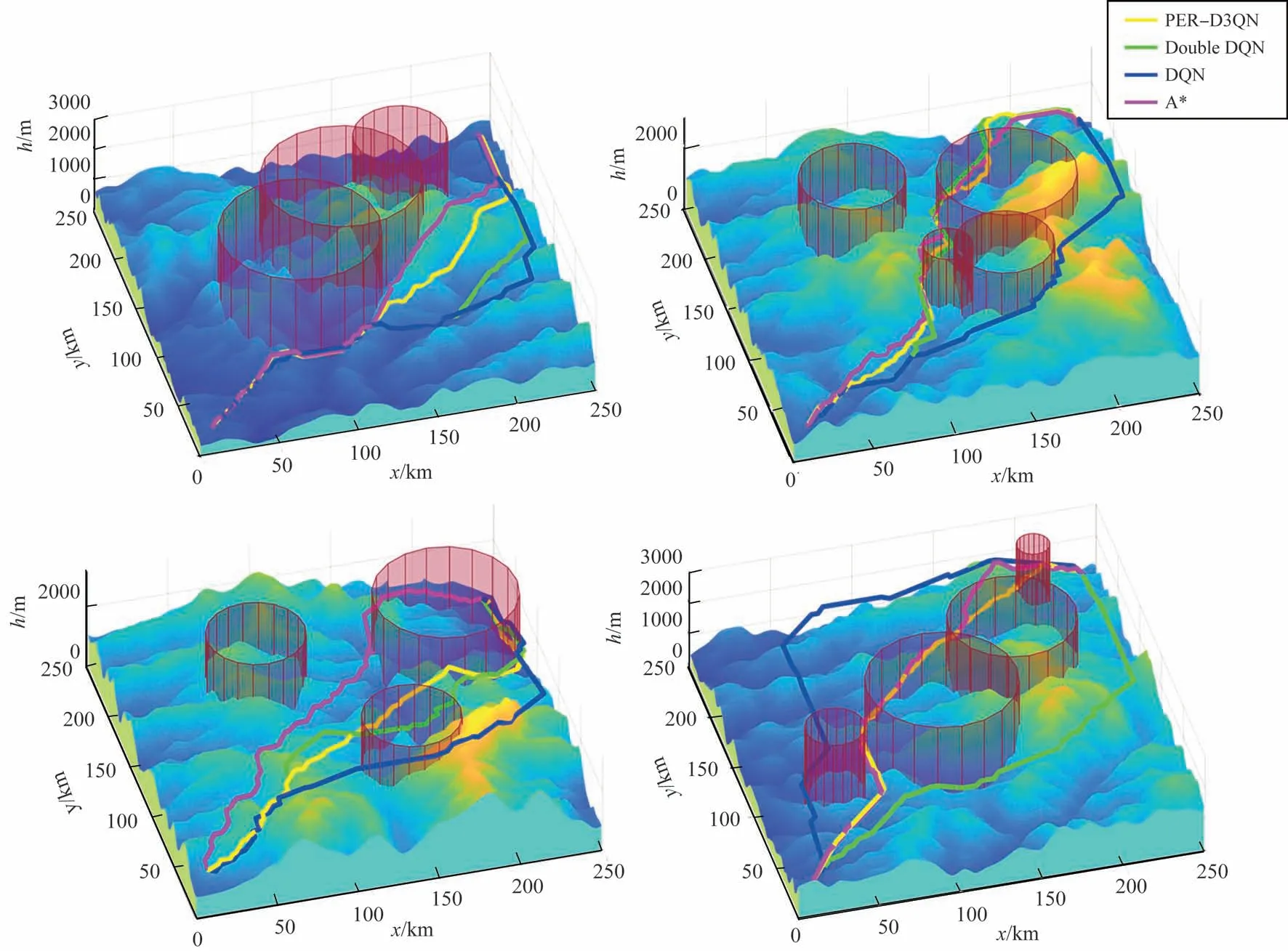
图7 战场环境下PER-D3QN,Double DQN,DQN和A*算法航路规划结果Fig.7 Results of path planning based on PER-D3QN, Double DQN, DQN and A* in battlefield environment
由表1可以看出:在成功率和平均航程上,传统A*算法的成功率为100%且平均航程最短,可在任一仿真场景中实现航路规划;PER-D3QN算法的成功率和平均航程稍逊于A*算法,但优于Double DQN 和DQN 算法,具有较好的稳定性,可胜任绝大部分仿真场景。在平均计算时间上,PER-D3QN 算法相较其他三种算法具有较大优势,可在较短时间内完成航路规划任务,更符合无人机作战的实时性需求,具有更好的适用性。
仿真结果表明,本文所提出的基于PER-D3QN的无人机航路规划算法,相较于Double DQN和DQN,在训练过程和测试过程中均具有较好的表现;相较于传统A*算法,虽在航路规划成功率和平均航程上稍有劣势,但在平均计算时间上具有较大优势。
4 结束语
为解决无人机在战场环境下的航路规划问题,本文提出了基于PER-D3QN 的无人机航路规划算法。构建了包含战场三维地形和战场威胁的战场环境模型。通过设计网络模型、状态空间、动作空间和收益函数实现无人机航路规划算法。在仿真验证中,验证了所提算法相较于Double DQN和DQN具有更好的收敛性、稳定性和适用性,相较于传统A*算法具有较好的实时性。在下一步研究中,应考虑多无人机协同作战的任务场景,基于多智能体深度强化学习方法研究复杂战场环境下多无人机协同航路规划问题,以进一步提升无人机作战效能。
猜你喜欢
小哥白尼(军事科学)(2022年1期)2022-04-26
小哥白尼(军事科学)(2021年10期)2021-02-12
意林(2020年20期)2020-11-06
红领巾·探索(2020年5期)2020-05-19
小学科学(学生版)(2018年9期)2018-09-21
家教世界(2017年11期)2018-01-03
哈尔滨商业大学学报(自然科学版)(2016年4期)2016-09-02
海军航空大学学报(2015年3期)2015-11-11
中学历史教学(2015年11期)2015-11-11
中国民航大学学报(2015年3期)2015-03-01
