
基于预处理-枚举的子图匹配算法
2023-12-30 05:26:10巴伦敦顾进广
计算机技术与发展 2023年12期
巴伦敦,梁 平,顾进广
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引 言
近年来,图在各个领域发挥着越来越重要的作用。图分析中最基本的问题之一是子图匹配。给定一个数据图G和一个查询图q,子图匹配是在G中找到q的所有不同嵌入的问题。例如,对于图1中的查询图q和数据图G,{(u0,v0),(u1,v4),(u2,v5),(u3,v12)}是从查询图q到数据图G的一种子图匹配结果。子图匹配具有广泛的应用场景,如生物信息学[1-2]、社会网络分析[3-4]、化学复合搜索[5-6]等。在这些应用中,子图匹配是整体性能的瓶颈,因为它是典型的NP-hard问题之一[7-8]。
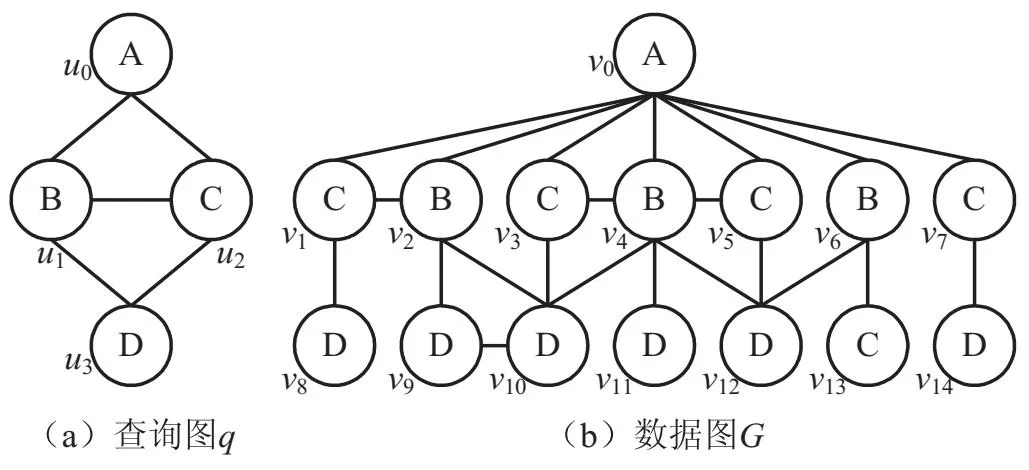
图1 查询图与数据图
由于子图匹配的重要性,目前已经提出了各种算法。这些算法专注于生成有效的匹配顺序,并设计强大的过滤策略来最小化数据图中候选的数量。SMID[9]提出了一种基于包含度的子图匹配方法,找到与给定查询图结构同构并且对应节点元素的加权集合包含度大于给定值的所有子图。AC-Match[10]是一种可以根据数据集的标签密度和图密度进行自适应调整的高效子图匹配算法。VEQs[11]采用静态等价和动态等价来解决响应时间和可扩展性有限的问题。QuickSi[12]设计了不常见的边优先排序技术,该技术根据数据图中出现的频率升序对查询图的边进行排序。GraphQL[13]采用贪心策略,设计了基于左深度连接的排序方法生成匹配顺序,将枚举过程建模为连接问题。SPath[14]将路径作为匹配的特征,在每一次的匹配过程中,将一次匹配一个节点优化成为一次匹配一条路径。Turbolso[15]设计了领域等价类来压缩查询图,针对压缩后的查询图进行过滤以减少候选节点,并且还对数据图进行了分区,针对不同数据图区域设计每个区域专属的最佳匹配顺序。CFL[16]提出了核-森林-叶分解技术,将查询图分解成核区域、森林区域和叶区域,并且通过优先匹配核区域中的节点来推迟进行笛卡尔积,从而减少候选节点。CECI[17]设计了紧凑嵌入聚类索引的辅助数据结构帮助过滤节点,同时采用了基于集合交集的枚举方法进行枚举结果。DP-iso[18]改进了CFL算法采用的生成树模型,以有向无环图模型代替生成树,以充分利用非树边的强大剪枝能力,并基于有向无环图设计了候选空间的辅助数据结构来帮助过滤候选节点。
可以将目前的研究算法分为三种类型。第一类算法(例如,QuickSi)遵循直接枚举框架,直接探索G枚举所有结果。大多数基于状态空间表示模型的算法也采用了这个框架。第二类算法(例如,SPath)利用索引枚举框架,该框架在G上构造索引,并在索引的帮助下完成所有查询。第三类算法(例如,GraphQL,TurboIso,CFL,CECI和DP-iso)采用预处理枚举框架,该框架广泛用于数据库社区的最新算法。一些研究发现现有工作可以从更强的过滤策略中受益,以最小化候选集,因为这样可以进一步减少部分结果的搜索广度,并为匹配顺序生成提供更准确的统计数据。
该文提出了一种基于预处理-枚举的子图匹配算法(Preprocessing-Enumeration,PE),整体包含四个步骤:(1)计算查询图q生成候选顶点的索引顺序;(2)根据步骤1顺序正向地生成候选集,逆向地对候选集进行精化;(3)根据候选的统计数据生成匹配顺序;(4)基于辅助数据结构枚举所有结果。该算法通过考虑相邻顶点之间的边来计算候选顶点集的生成顺序,根据前向邻居顶点来生成顶点的候选集,再根据后向邻居顶点来对顶点的候选集进行精化。与树结构索引相比,将非树的边也考虑到了,从而细化得到一个更小的候选集。在此基础上,根据查询顶点的候选数量和度生成匹配顺序,从而消除了基于树结构的路径和只考虑候选数量生成匹配顺序带来的限制。
1 相关定义
1.1 图与子图匹配
文中采用的图均为具有标号的无向连通简单图。通过简单处理,文中算法也可适用于其他简单图的子图匹配。图G定义为G(V,E,∑,L),其中V={v1,v2,…,vm}表示顶点集合;E={(vi,vj)|vi,vj∈V}表示边的集合;∑是顶点标签集;L是一个将顶点v与标签L(v)∈∑相关联的函数。
表1给出了与子图匹配相关的经常使用的一些符号的定义。定义1~定义2给出了子图同构及子图匹配的定义。

表1 常用符号定义
定义1(子图同构):给定一个查询图q=(V,E,∑,L)和一个数据图G=(V',E',∑',L')。子图同构是一个单射函数f:V->V',满足:
(1)∀u∈V,L(u)=L'(f(u));
(2)∀e(u,v)∈E,∃e(f(u),f(v))∈E'。
如果从q到G存在子图同构,则q是与G同构的子图,表示为q⊆G。
定义2(子图匹配):给定一个数据图G和一个查询图q,子图匹配是找到G中所有与q同构的子图。
1.2 候选顶点集与匹配顺序
定义3~定义6给出了与候选顶点集及匹配顺序相关的一些定义。
定义3(完整的候选顶点集):给定q和G,u∈V(q)的完整候选顶点集C(u)是一组数据顶点,使得对于每个v∈V(G),如果(u,v)存在于从q到G的匹配中,则v属于C(u)。
定义4(匹配顺序):匹配顺序π是V(q)的排列。π[i]是π中的第i个顶点。

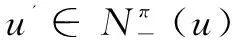
2 基于预处理-枚举的子图匹配算法
为了提高算法性能,提出的预处理-枚举的子图匹配算法在枚举之前引入了一个预处理阶段,以减少每个查询顶点的候选大小,获得准确的统计量来优化匹配顺序。特别的,预处理阶段是为每个查询顶点生成一个完整的候选顶点集。整个算法过程分为候选集生成、匹配顺序和枚举三个阶段。
算法1给出了PE算法描述,它以q和G作为输入,输出从q到G的所有匹配。首先为每个查询顶点提取G中的候选者,提取过程在算法2进行了详细描述(第2行)。接下来,生成匹配顺序π,在算法3给出了匹配顺序的计算过程(第3行)。第4行建立辅助数据结构A。将这三个步骤称为索引阶段。在索引阶段之后,枚举阶段基于辅助数据结构A沿匹配顺序π递归地扩展部分结果,并将结果存放在M中,算法4给出了完整的枚举过程(第5行)。
算法1:PE算法
输入:查询图q和数据图G
输出:从q到G的所有匹配
1.begin
/*提取候选集 */
2.C← ExtractCandidates(q,G);
/*生成匹配顺序 */
3.π← GenerateMatchingOrder(q,G,C);
/*建立辅助数据结构 */
4.A← BuildAuxStructure(q,G,C,π);
/*枚举方法 */
5.Enumerate(q,G,C,A,π,M,u,i);
2.1 过滤方法
通过枚举查找所有的匹配结果前,为了降低枚举的耗时,在获得一个完整候选集的前提下,需要通过过滤算法让候选集尽可能的小。目前大部分算法直接采用标签和度过滤方法(LDF)或邻居标签频率过滤方法(NLF)来进行过滤。LDF基于L(u)和d(u)生成候选集,C(u)={v∈V(G)|L(v)=L(u)∧d(v)≥d(u)}。NLF利用u的邻居顶点N(u)过滤C(u)来获得更精确的候选集,即给定v∈C(u),如果存在l∈L(N(u))使得|N(u,l)|>|N(v,l)|,其中L(N(u))和N(u,l)分别满足L(N(u))={L(u')|u'∈N(u)}和N(u,l)={u'∈N(u)|L(u')=l},就从C(u)中删除v。由于直接使用LDF或NLF提取的候选集存在大量错误候选顶点,所以该文利用下述定理1得到新的生成规则1和过滤规则1,以提高算法在提取候选集时的过滤能力。
除了候选顶点集,还设计了一个辅助数据结构A,用于存放压缩路径索引。A的空间复杂度为O(|V(q)|×|E(G)|)。
定理1:假设对于每个u∈V(q),C(u)都是完整的。Su'表示N(v)∩C(u'),其中V∈C(u),u'∈N(u)。如果映射(u,v)存在于从q到G的匹配中,则v必须满足每个u'∈N(u),Su'≠∅。
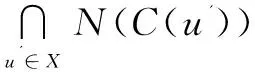
过滤规则1:给定X∈N(u)和v∈C(u),其中u∈V(q),如果存在u'∈X使得C(u')∩N(v)=∅,那么可以安全地从C(u)中删除且不会破环完整性。
算法2:ExtractCandidates(提取候选集)
输入:查询图q和数据图G
输出:候选集C
1.begin
2.π'← GenerateIndexingOrder(q);
/*前向邻居顶点生成候选集 */
3.u←π'[1], setu'.Cto empty for allu'∈V(q);
4.foreachv∈V(G) do
5.if LDF(u,v) is true and NLF(u,v) is true then
6.u.C←u.C∪{v};
7.fori←2 to |π'| do
8.u←π'[i];
10.if LDF(u,v) is true and NLF(u,v) is true thenu.C←u.C∪{v};
/*后向邻居精化候选集*/
11.fori← |π'| to 1 do
12.u←π'[i];

14.removevfromu.C;
算法2给出了候选集的提取过程:首先生成查询顶点的连接顺序(第2行),为了与匹配顺序区分开,将提取候选者的顺序命名为索引顺序,表示为π'。索引顺序的初始点综合考虑了通过LDF计算后的候选顶点数和顶点的度,后面的顺序通过选择与已排序的顶点相邻最多的顶点。第4~6行得到π'中起始顶点的候选集,满足LDF和NLF的过滤条件。接下来,沿着π'通过前向邻居顶点生成候选集(第7~11行)。在第12~15行沿着π'相反的顺序,由后向邻居顶点对候选集精化,得到一个更小的候选集。算法2的时间复杂度为O(|E(q)|×|E(G)|)。
2.2 匹配顺序
由于基于路径的排序没有考虑路径中邻接点之间的影响,在本质上限制了算法性能,所以采用基于左深连接的方法来生成匹配顺序,将查询图建模为左深连接树。同时,因为现有子图匹配实验结果中存在稀疏查询图往往会比同顶点数的稠密查询图消耗更多时间的问题,所以为提高稀疏查询图的查询效率,在计算匹配顺序的开始顶点时,不仅考虑了顶点候选数量,也将顶点的度带入计算。

算法3:GenerateMatchingOrder(生成匹配顺序)
输入:查询图q,数据图G和候选集C
输出:匹配顺序π
1.begin
2.π[1]← selectStartVertex(q,C);
3.fori← 2 to |π| do
4.foreachu∈qdo
5.if unvisited(u) &adjacent(u) is true then
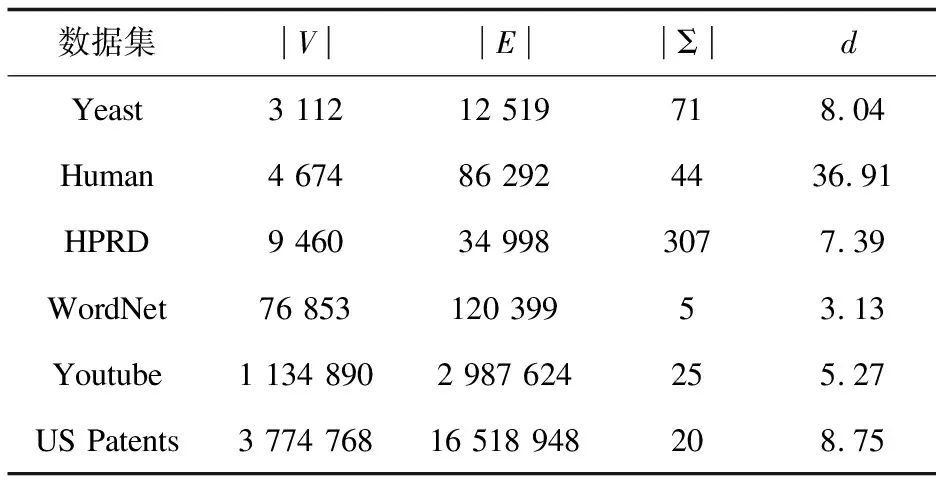
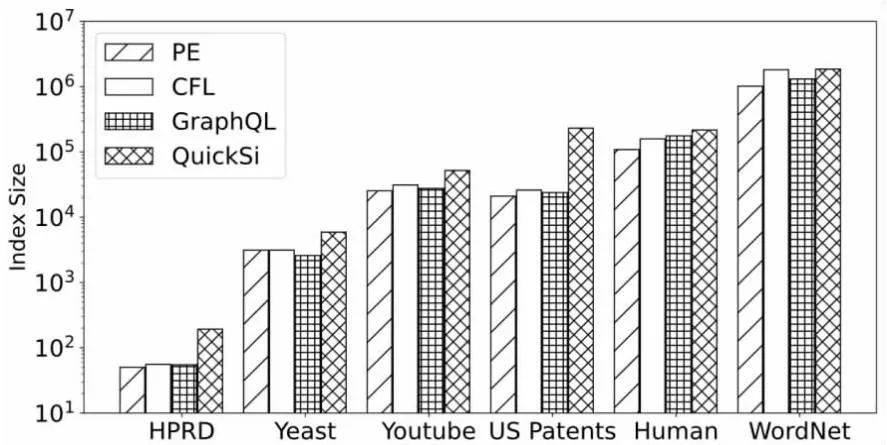
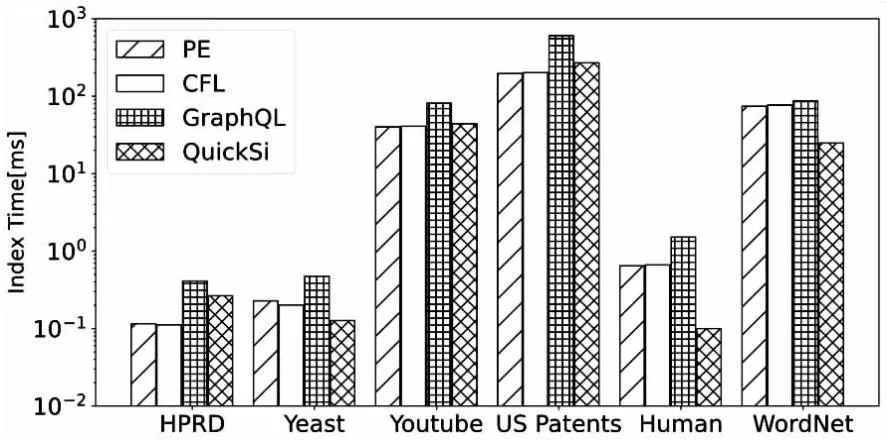
6.if |C(u)| 7.π[i] =u; 8.returnπ; 枚举算法采用递归的方式来查找所有的匹配,为了方便计算,在辅助数据结构A中维护了候选点之间的边。 算法4:Enumerate(枚举) 输入:查询图q,数据图G,候选集C,辅助数据结构A和匹配顺序π 输出:子图匹配结果M 1.begin 2.Enumerate(q,G,C,A,π,M,i); 3.Procedure Enumerate(q,G,C,A,π,M,i); 4.ifi=|π|+1 then OutputM, return; 5.u←π[i]; 6.ifi=1 thenC'←C(u); 8.foreachv∈C'do 9.ifv∉Mthen 10.Add(u,v)toM; 11.Enumerate(q,G,C,A,π,M,i+1); 12.remove (u,v) fromM; 实验主要评估并比较了以下具有不同索引和排序策略的算法: PE:基于预处理-枚举的子图匹配算法。 QuickSi:没有任何索引并采用不常见的边优先排序策略。 CFL:最先进的算法之一。采用树结构索引CPI和基于路径的排序策略。 GraphQL:采用邻域签名过滤器和左深度连接排序策略。 实验共选择了六个真实数据集,这些数据集在以前的工作中被广泛使用[19-20]。各数据集及属性如表2所示,其中|V|表示顶点的个数,|E|表示边的个数,|Σ|表示标签的类别数,d表示顶点的平均度。Yeast,Human,HPRD和WordNet数据集都包含标签,而Youtube和US Patents数据集没有标签,实验采用随机分配不同标签的方式进行。 表2 数据图集及其属性 查询集通过数据图中随机选择子图来生成查询图,以保证至少存在一个匹配。对于每个数据图,实验生成八个查询集作为默认查询来评估不同算法的性能。每个查询集包括200个具有相同顶点数的查询图,每个查询图都是连通图。有一半查询集包含非稀疏查询图(平均度数大于等于3),另外的查询集包含稀疏查询图(平均度数小于3)。 实验中不同算法整体性能比较主要考虑了以下评估指标: (1)执行时间:在查询集中处理查询图的平均时间,这排除了将数据从磁盘加载的时间。它由索引时间和枚举时间组成。 不同算法的过滤方法性能比较则主要考虑了以下指标: (1)索引时间:在处理查询图的索引阶段花费的平均时间。 (2)索引大小:用于处理查询图的索引中候选的平均数量,用于评估索引的过滤能力。 实验运行环境如下:16 GB内存的AMD Ryzen 7 4800H八核电脑;所有涉及的算法均采用C++编程语言实现,使用的编译器GCC版本为11.3.0。 3.2.1 算法整体性能 算法整体性能比较不同算法在不同数据集的执行时间和相对性能。在实验中发现WordNet,Youtube和US Patents有相近的实验结果,Human与Yeast实验结果也相近。所以选择了HPRD,Yeast和Youtube的实验结果进行展示。 (1)执行时间。 不同算法在三个数据集上的执行时间如图2~图4所示,其中每个数据集都按稠密查询图及稀疏查询图规模来显示实验结果。可以发现所有算法通常在更大的查询上花费更多的时间,相比于非稀疏查询图,稀疏查询的查询难度可能会提高不止一个数量级。PE,QuickSi,GraphQL和CFL的性能在不同的数据图上有所不同。PE在不同数据图上始终优于其他算法,这证明了PE的效率和稳定性。GraphQL,CFL和PE之间的性能差距在HPRD上很小,因为大量不同的标签使得HPRD成为查询的简单数据集。在图4中,PE,QuickSi,GraphQL和CFL的执行时间变化对查询大小的增加不敏感。这是因为大量的查询无法在时间限制内完成,并且它们的执行时间被替换为10分钟。 图2 数据集HPRD上的执行时间 图3 数据集Yeast上的执行时间 图4 数据集Youtube上的执行时间 (2)相对性能。 算法的相对性能受到查询时间的影响,当查询时间越短,相对性能的值越小,代表算法的性能越好。从图2~图4的实验结果可以发现,PE在不同数据集的运行时间都是最短或者接近最短,因此PE相对性能是最接近1的。相比于其他3个算法PE具有更强的竞争力,原因在于这3类算法的候选集存在大量错误候选顶点,并且生成匹配顺序也比PE差。 3.2.2 过滤方法性能 由于实验中所有算法的空间复杂度均为O(|E(G)|×|V(q)|),实际索引的内存成本非常小,在每个数据集上消耗不到10 MB,因此在验证过滤方法的有效性时,忽略了索引内存成本,只需比较四种算法的索引策略在索引大小和索引时间两个指标上的性能。 (1)索引大小。 不同算法在6个数据集上的索引大小如图5所示。可以看到QuickSi比其他算法生成更多的候选者,QuickSi本身没有过滤算法,实验是使用NLF作为替代与其他算法进行对比。PE在大部分数据集上都获得了比其他算法更少的候选者,这表明PE具有更强的过滤能力。由于Human是密集的,WordNet中的大多数顶点具有相同的标签,PE在这两个数据图上过滤效果对比其他算法更加显著。 图5 真实数据集的索引大小 (2)索引时间。 不同算法在6个数据集上的索引时间如图6所示。可以看到QuickSi通常比其他算法运行得更快,因为QuickSi使用的过滤算法NLF只有一趟候选集生成过程。NLF算法在Human和WordNet索引建立时间优势更加明显,因为其他算法在密集数据图和标签种类少的数据图计算量更大,性能更差。PE在标签类别多的HPRD和Yeast时间略慢于CFL,但是在其他四个数据图有一定优势。从整体性能表现上来看,PE还是最具有竞争力。 图6 真实数据集的索引建立时间 为了提高子图匹配算法的性能,提出了一种基于预处理-枚举的子图匹配算法(PE)。该算法在预处理阶段,通过将过滤阶段分为索引顺序生成、自前向邻居生成候选集和自后向邻居对候选集进行精化,以得到一个更小的候选集。同时,为了提高稀疏图查询的效率,在生成匹配顺序时,将顶点的候选集大小和度作为条件进行计算,以解决现有排序策略只考虑候选顶点数量的问题。模拟实验结果表明,基于预处理-枚举的子图匹配算法(PE)与现有算法相比,在候选集过滤效果及匹配速度上有一定的优势,具有更好的整体性能。2.3 枚 举

3 实验结果及分析
3.1 实验环境

3.2 实验结果分析



4 结束语
猜你喜欢
速读·上旬(2022年2期)2022-04-10 16:42:14
中等数学(2021年9期)2021-11-22 08:06:58
新一代信息技术(2021年8期)2021-07-30 13:37:14
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
山东科学(2018年6期)2018-12-20 11:08:58
电子科技大学学报(2016年2期)2016-08-31 02:50:00
科技创新与应用(2016年6期)2016-05-14 13:09:56
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:50
电子设计工程(2012年21期)2012-09-26 02:27:30
