
基于词嵌入的元组级数据溯源方法
2023-12-30 06:50高俊涛王志宝江树涛
计算机技术与发展 2023年12期
杨 彬,高俊涛,王志宝,李 菲,马 强,江树涛
(1.东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318;2.黑龙江八一农垦大学 信息与电气工程学院,黑龙江 大庆 163319)
0 引 言
在大数据时代下数据生成规模激增,原生数据经过多次复制、迁移、集成、抽取等操作后形成海量派生数据,使数据来源及衍生路径表现出多样化、复杂化的特点[1]。若原生数据的来源模糊不清,则会极大程度地影响派生数据的可靠性[2]。数据溯源技术能够监控与评估数据质量,有助于定位错误根因,追踪错误路径,还可以对数据进行安全管控,能够帮助企业确定字段敏感信息。数据的可靠性和安全性是有效决策的基础,为加强数据质量,由此产生了数据溯源技术[3]。
目前数据溯源在溯源理论、溯源模型以及方法实践上都开展了研究工作,但仍有不足,标注法的实现需要为元组保存完整的半环多项式(即标注),由于通过查询产生的元组依赖于先前查询的元组,导致半环多项式的数量大量增长,存在存储空间爆炸的问题。因此,国外学者Leybovich M等[4]提出基于词嵌入的元组级数据溯源方法,该方法有效避免存储数据标注。文中主要贡献如下:
(1)在元组向量化编码机制的基础上给出属性重要性优化算法,解决词嵌入方法中溯源精确率低的问题。
(2)引入近似最近邻搜索算法后又给出元组过滤优化策略,解决时间消耗长溯源效率低的问题。
1 相关工作
目前在数据溯源研究中主要有以下几方面工作。从溯源概念上,Lanter[5]首次提出“Data Lineage”用以描述目标数据的来源转化过程。Cui等[6]从关系代数角度出发,定义了View Data Lineage用来标识数据仓库视图中目标数据的源数项集。Buneman等[7]进一步将数据溯源进行分类,提出了why溯源和where溯源。Green等[8]以半环多项式的形式提出了how溯源。从溯源粒度上,数据溯源被分为3个不同层次,第1层次是表级的数据溯源,其目标是获得目标表与源表之间的转换,是一种粗粒度的数据溯源;第2层次是字段级(列)的数据溯源,其目标是获得源表字段和目标表字段之间的属性映射关系,它是表级溯源的细化;第3层次是元组级(行)的数据溯源,其目标是获得目标表元组的源元组集合,是一种细粒度的数据溯源[9]。
从溯源模型上,W3C发布的PROV[10]是目前为止最成功的模型,成为数据溯源史上的里程碑。此后,围绕PROV,专家学者对各个领域进行深入更深层次的研究。Niu X等[11]将PROV引入关系数据库,将溯源信息存储成PROV-JSON的形式进行数据溯源。燕杨月[12]将PROV应用到物联网数据场景,实现对物联网起源信息的描述。杨斐斐等[13]对PROV进行扩展,构建了面向数据融合的溯源模型─PROV-Semi。
从溯源方法上,林悦邦[14]和张苒[15]等对支持全特性查询语言的逆置函数溯源方法进行研究。逆置函数法是指在计算时通过逆向查询或构造逆向函数对查询求逆,求逆的结果就是目标数据的源数据。其优点是只需存储少量的元数据就可实现数据溯源;缺点是具有一定局限性,需要提供逆置函数(并不是所有的函数都具有可逆性)和相对应的验证函数。Leybovich M等[4,16]和Hofmann F A等[17]提出一种数据溯源的近似总结方法,其优点是可应用于派生数据更为膨胀的海量数据场景;缺点是以丢失一些信息为代价压缩表示溯源信息。Pierre Senellar等[18-19]开发的ProvSQL系统[20]利用标注法实现元组级数据溯源。标注法是指记录数据的出处、产生过程、流转信息等作为数据标注,通过查询目标数据的标注来获得数据的溯源信息。其优点是实现简单,且容易管理;缺点是需要详细记录所有的数据转换信息,会出现元数据多于原始数据的情况。在实际应用中,细粒度形式的溯源信息标注通常会产成大容量存储,如何优化关系数据库下的溯源方法,成为亟待破解的难题[21]。
2 溯源定义及问题描述
2.1 元组级数据溯源

2.2 问题描述
该文的主要内容是:研究元组级数据溯源方法,为数据库管理系统(DBMS)中元组的存在提供解释。即给定一个查询(Q)和查询输出的数据元组集合(T),在来源表中找出对产生每个元组(t∈T)有贡献的源数据元组集合(S)。
示例1:SQL语句示例用来帮助理解元组级数据溯源定义。

Q: INSERT INTO results(title, rating, timestamp)SELECT m.title,r.rating,r.timestampFROM ratings r,movies mWHERE m.movieId=r.movieIdAND r.userId=4;
表1(a)为执行语句Q后获得的查询结果表(results),每个元组包含userId为4的用户观看的电影名,所给评分及评价时间。表1(b)为评价表(ratings),每个元组包含有关用户表达的电影偏好的信息(0~5星评分)。表1(c)为电影表(movies),每个元组包含有关电影的基本信息。
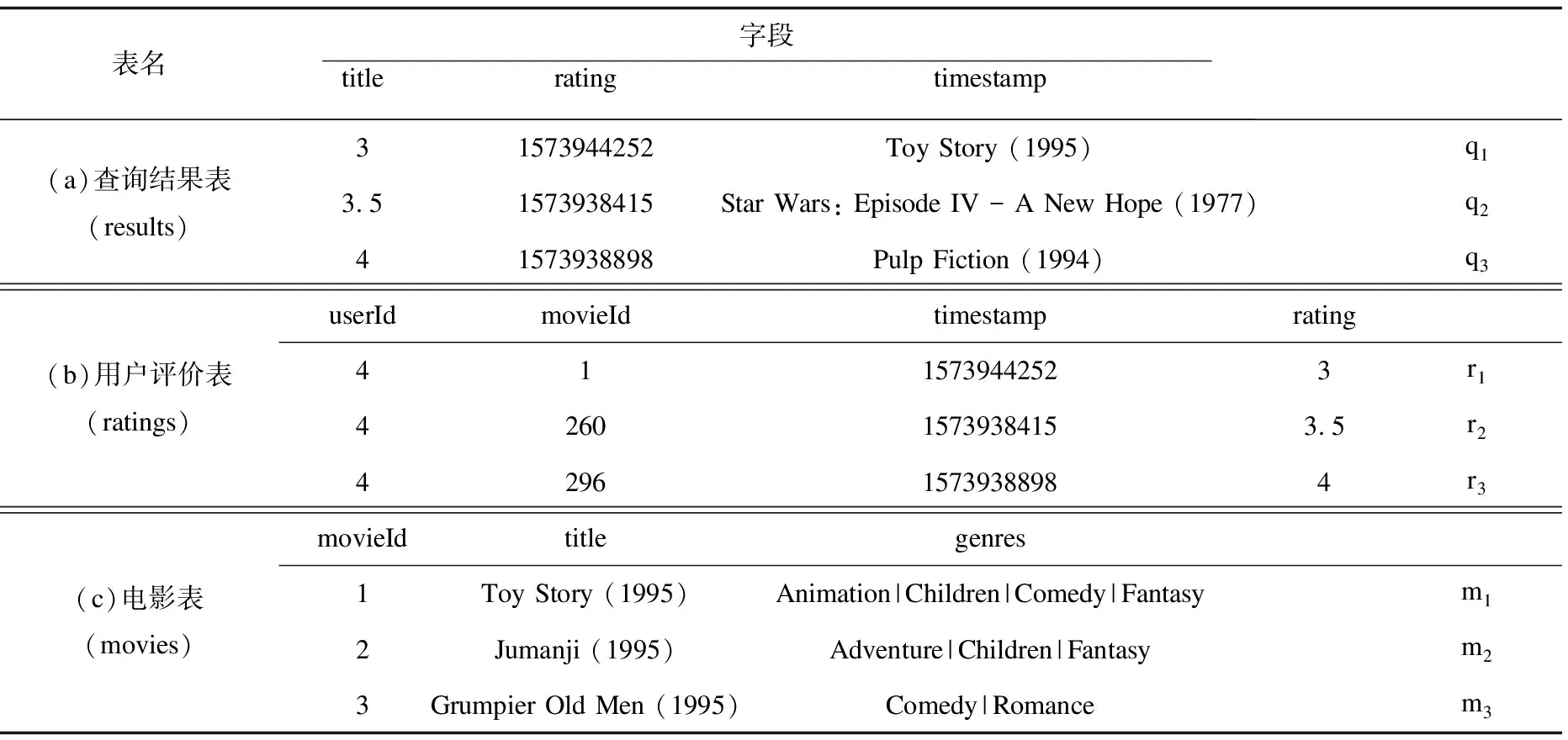
表1 数据统计表
通过分析可以得到,表1(a)中标注为q1的元组由表1(b)中标注为r1的源元组和表1(c)中标注为m1的源元组结合形成,如图1所示,以此实现元组(q1)的一次溯源。

图1 元组(q1)的溯源过程描述
同理,可以对目标元组(q2,q3,q4)直至qn进行溯源。并且可以对元组(r1,m1)向上溯源,最终形成一个有向无环图,即全链路数据溯源关系图。
3 元组级数据溯源方法
该文在ProvEmb[4]的基础上增加了精确率优化机制和搜索效率优化机制,设计了一种基于词嵌入技术的元组级数据溯源改进方法(ProvEmb-X),其想法受生物学“基因”的启发,使寻找元组的源数据类似于通过DNA查找其前辈。
3.1 方法框架
图2为文中方法的研究框架,该方法支持范围广泛的非聚合SQL查询。输入数据是执行SQL后的查询结果元组集(即目标元组),输出数据是为该条元组返回其源元组id,目的是对目标元组集中的每一条元组进行溯源。基本方法首先是通过一组向量来代表每个元组。其次,通过计算源表元组向量与目标元组向量的相似度,来识别溯源关系。再次,对仅依赖相似度比较导致相似的元组间可能没有溯源关系的问题,给出优化方案提高精确率,并对溯源效率进行优化以减少时间消耗。最后,与基于词嵌入的数据溯源方法(ProvEmb)进行对比,验证文中方法的优化效果。该方法具有以下特点:

图2 ProvEmb-X方法框架
(1)该方法适合大规模数据集。通过分析SQL语句来精准定位所需要的数据库表,即便是派生数据更为膨胀的海量数据场景,仍可以快速过滤无用数据。
(2)该方法支持复杂的数据变换。可解决范围广泛的非聚合SQL查询的数据溯源问题,通过解析SQL语句中的连接、选择、分组、投影、集合和排序操作获取查询结果字段(目标字段)与数据库源表字段的对应关系,进而应用到方法中的属性重要性优化机制。
(3)该方法可实现自动化溯源。无论是纯手工收集的标注法,还是基于SQL的半自动标注法,都需要进行人工标注的工作。文中方法可实现自动化,提高溯源效率。
3.2 元组向量化编码机制
该文在元组向量化编码机制中进行目标元组向量和源表元组向量的两部分编码。该文使用NLP技术,词向量通过预训练的多语言词嵌入模型在基础文本上获得。文中元组向量化编码机制与ProvEmb不同的是,ProvEmb是将元组中的每个列的文本组合起来形成一条没有语义的句子后进行词嵌入,该文是直接将每个元组中不同列的文本进行词嵌入后再组合,为后续属性重要性优化机制提高溯源精确率做准备。算法1为元组向量生成算法。
算法1:元组向量生成算法(TPVEC)
输入:预训练的词嵌入模型(ST),输入数据表(Ti)
输出:为Ti中的每个元组(t)计算其元组向量(vectort)并存在tuplevector中
1. list vectort//存储每列文本的词向量
2. list tuplevector //存储生成的元组向量集
3. fort∈Ti.tuples do //遍历Ti中的每个元组
4.vectort=create(t) //调用对t构造元组向量方法
5.tuplevector.append(vectort)
6.end for
7. return tuplevector
8. function create(t) //定义构造元组向量方法
9. list wordvector
10. list tuplevector
11.//w是t中的每列文本,[]为构造wordvector列表
12. wordvector=[ST(w)|w∈t]
13. vectort=weight(wordvector)
14. return vectort
4 溯源方法优化机制
由于仅依赖目标元组向量与源元组向量的相似性,会出现两者间并无溯源关系,却还是错误地将该元组识别为溯源结果的情况。因此,该文提出了改进方案,通过以下4个步骤使算法在溯源精确率和效率上有较大的提升。(1)使用局部敏感哈希算法(LSH)提高溯源效率。(2)通过解析查询语句中FROM条件直接定位源表,初次过滤无关元组集合。(3)利用时间戳过滤目标元组的派生元组,再次过滤无关元组集合。(4)对于元组中的关键属性,采用加强其特征再组合的方式,形成独有的遗传密码“基因”,从而提高溯源精确率。
4.1 近似最近邻搜索
在进行实验时发现,暴力穷举式扫描对源表元组向量和目标元组向量进行相似度比较时,时间复杂度为O(dN),当数据的维度(d)以及数据的规模很大时,巨大的计算量与存储需求使得该搜索方式难以在效率上满足需求。
针对此问题,为满足大规模数据场景下的最近邻搜索任务需求,该文采用局部敏感度哈希算法(LSH)进行高维向量近似最近邻搜索(ANN),在损失一定精度的条件下,能够有效平衡精度与资源消耗,以更快的搜索速度和更少的内存负载得到查询项的近似精确甚至精确的搜索结果。LSH的基本思想是将原高维空间的点都映射至1个或多个哈希表的不同位置(桶),原高维空间内距离较近的点会以较大概率映射至同一桶内,从而可直接在该桶内搜索元素,大大提高搜索效率。当哈希函数(h)满足以下两个条件,称h为局部敏感哈希函数[22]:
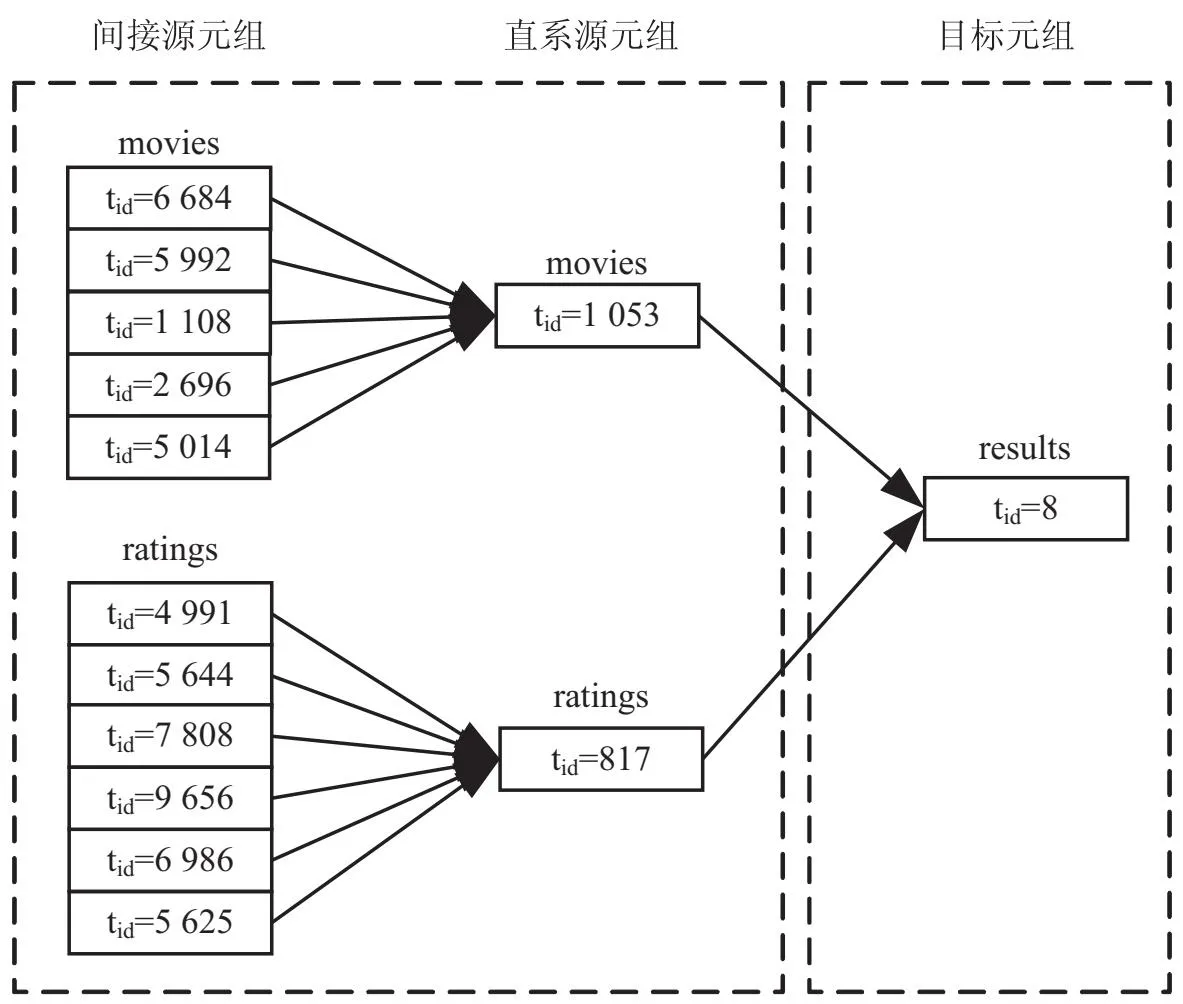
(1)如果L(q1,q2) (2)如果L(q1,q2)>d2,则P[h(q1)=h(q2)]≥p2。 条件(1)保证2个相似点以较高概率被映射进同一个哈希桶;条件(2)保证2个不相似的点以较低概率映射进同一个哈希桶。其中,d1,d2,p1,p2是给定的常数,d1 H(V)=sign(V·R) (1) 其中,R是一个随机向量,V·R可以看作是将V向R上进行投影操作,其是(d1,d2,(180-d1)/180,(180-d2)/180)敏感。 在对目标元组溯源时,源表中存在许多无关元组,若对这些无关元组也进行词嵌入生成元组向量,会浪费大量时间。因此,在本节中通过2个步骤过滤无关元组,加快搜索效率并提高溯源的精确率。 首先,解析SQL语句中的FROM条件进行筛选,因为FROM条件可以直接定位来源表,缩小查找范围。然后,在筛选后的元组中使用算法2元组过滤算法(TPFIL),通过元组创建时间戳过滤元组,能够帮助过滤掉非常相似但非源数据的元组,解决了完全依靠相似度的弊端,对查询远距离数据溯源尤其重要且加快了源元组的搜索效率。 算法2:元组过滤算法(TPFIL) 输入:源数据表(Ti),查询结果表(R) 输出:经过where条件和时间戳过滤后的元组向量集(tuplevector) 1.list tuplevector 2.list vectort 4.//对每条查询结果元组在源表中进行时间戳过滤 5.fort∈R.tuples do 7. ift'.timestamp>t.timestamp 8. //调用构造元组向量方法,将t作为参数传入 9. vectort=create(t) 10. tuplevector.append(vectort) 11. end if 12. end for 13.end for 14.return tuplevector (1)跟踪元组的创建时间戳。 ①如果元组(t)被直接插入到DB,则t.timestamp是其插入时间。 ②如果元组(t)是通过查询计算的,则t.timestamp是查询的执行时间。 (2)当将一个元组(t)与一组其他元组(T')进行比较时,该文在计算元组向量生成之前进行判断:如果t'.timestamp>t.timestamp (t'∈T'),则t'比t更新,并且不能成为其源元组的一部分。 由于TPVEC生成的元组向量不具备其本身特征,因此会导致溯源结果的精确率不高。为提高精确率,对数据库表结构进行研究发现,某些属性可能比其他属性更重要。例如,主键、外键或者是某些参与了数据库查询的重要属性。这意味着可以通过给这些属性的词向量赋予较高权重的方法来加强此元组向量的特征,进而提高相似度匹配的精确率。 该文通过解析SQL语句的方式寻找真正参与SQL运算的源属性和目标属性。解析SQL语句的主要步骤为:首先,对SQL查询语句进行词法分析和语法分析得到抽象语法树。然后,遍历以Root为节点的抽象语法树,得到INSERT INTO target_table(target_attribute_list)目标表(目标属性)、SelectList源属性、FromClause源表,再遍历WhereClause没有聚合函数的选择操作、GroupClause分组操作、HavingClause有聚合函数的选择操作、SortClause排序操作等节点,从中获得目标属性和源属性的对应关系,以此来为目标属性和源属性的词向量加大权重。 以示例1所示的查询语句为例,遍历抽象语法树后得到的可视化关系如图3(a)所示。由图3(b)可知结果表(results)中title来自于movies表,rating和timestamp来自于ratings表。因此在movies表中元组向量生成时,应该为title赋予比movies表中其他属性要高的权重,说明title更能代表movies中元组的特征。同样,results中的title权重也要加大。因此对每个属性进行词嵌入,将词向量加权平均生成元组向量后,再计算相似度从而提高匹配的精确率。权重计算公式如下所示(对于∀wi都有0≤wi≤1): 图3 属性权重获取流程 (1)moviesvectort=w1×movieId+w2×title (w1 (2)resultsvectort=w1×title+w2×rating+w3×timestamp (w1>w2,w1>w3且w1+w2+w3=1) 在ratings表中的元组向量生成时,需要为rating和timestamp赋予较高的权重,且results表中也要加大其对应的权重,权重计算公式如下所示(对于∀wi都有0≤wi≤1): (1)ratingsvectort=w1×userId+w2×movieId+w3×rating+w4×timestamp(w3=w4>w1,w3=w4>w2且w1+w2+w3+w4=1) (2)resultsvectort=w1×title+w2×rating+w3×timestamp(w1 算法3为属性权重获取算法,该算法结合深度优先搜索的思想,递归调用visit方法获取目标表属性和源表属性的对应关系用attribute_r_list存放,即应赋予高权重的重要属性。后执行算法1(TPVEC),并更改由算法3(PREUP)生成的重要属性的weight值。 算法3:属性权重获取算法(PREUP) 输入:数据库语句(Q) 输出:目标表属性与源表属性的对应关系attribute_r_list 1.Procedure AnalyzeDatalineage(Q) 2.List results_r_list //存放目标表的表名和目标属性的关系 3.List source_r_list //存放源表表名和源表属性的关系 4.List attribute_r_list //存放目标表属性和源表属性的关系 5.QT←generateSQLAST(Q); //根据语句(Q),生成抽象语法树(QT) 6.Function visit(r) //对根节点为r的抽象语法树(QT)进行遍历 7.ifR(r)≠∅then 8.String results_table //初始化,定义变量string型 9.String source_table 10.String results_attribute 11. forcin childs do //对节点进行类型判断 12. //如果节点c是结果表类型 14.results_table←c//记录结果表表名 17.results_r_list←([results_table,c]) 19.source_table←c//记录源表表名 24.attribute_r_list←([results_attribute,c] ) 25. Else ifR(r)≠∅ then 26.visit(c) 27. End if 28. End for 29.End if 30. Return attribute_r_list 综上所述,文中方法在第1阶段元组过滤优化机制时,FROM过滤源表的时间复杂度为O(m),共m个源表,每个表有k个元组n个属性。时间戳过滤元组的时间复杂度为O(i·k·m'),表示进行i·k·m'次比较,i为目标元组数,m'为FROM过滤后的源表数量;在第2阶段属性重要性优化机制的时间复杂度为O(max(m'·n'+j'+1)),n'为遍历抽象语法树得到的源表的重要属性,j'为遍历抽象语法树得到的目标表的重要属性(j为目标表的所有属性);在第3阶段元组向量生成时的时间复杂度为O(i·j'+k'·n'·m'),k'为时间戳过滤后得到的元组;在第4阶段近似近邻搜索的时间复杂度为O(i·j')。因此,ProvEmb-X的时间复杂度为O(max(m'·k'·n'+i·m'·k)),而ProvEmb为O(max(m·k·n+i·m·k)),m'·k'·n'远远小于m·k·n。由此可知,文中方法能够有效降低时间复杂度。 基于提出的ProvEmb-X元组级数据溯源方法,在3种不同的数据集上进行实验,并与精确溯源系统ProvSQL[20]进行对比,验证ProvEmb-X的精确率;与ProvEmb[4]进行对比,验证ProvEmb-X的优化效果;最后展示对比实验结果。实验环境为:Intel(R) Core(TM)i7,16 GB内存,Windows 10操作系统。 MovieLens数据集描述MovieLens电影[23]推荐系统网站中人们对电影的喜爱程度,数据集中的每部电影都有一个唯一标识符movieId。固井作业数据集来自中国石油冀东油田公司实际固井数据,数据集中的每个井筒都有唯一标识符wellbore_id。Olist电子商务数据集[24]来自巴西市场上最大的百货商店Olist,数据集中的每个订单都有一个唯一标识符order_id。 数据集统计信息如表2所示。 表2 数据集统计信息 5.2.1 精确率对比 (1)精确率评价指标。 ProvSQL是基于标注的方法,由Pierre Senellart等人开发的开源项目,支持范围广泛的非聚合SQL查询,是目前为止较为精确的数据溯源系统。因此,该文使用公式(2)来计算实验结果的精确率,ApproxLineage(t)是该文实验结果元组的集合。ExactLineage(t)是由ProvSQL系统返回的关于t的精确源元组集合。Precision(t)代表返回的近似溯源结果与精确溯源结果的重合占比,该文将所得到的重合占比结果作为精确率的评价指标。 Precision(t)= (2) (2)精确率优化消融实验。 在3种数据集上分别对70条SQL语句的查询结果进行溯源,将平均精确率作为实验结果。 由表3的精确率对比结果可知,ProvEmb-X在3种数据集上的精确率均优于ProvEmb(baseline)。在Movielens数据集和Olist电子商务数据集上的精确率优化效果不如固井作业数据集明显,是由于固井作业数据集中属性数量较多,由w/o PREUP与完整的ProvEmb-X相差0.07左右可以看出,PREUP算法在极大程度地发挥作用提高精确率。由图4(a)的增长情况也可得知PREUP算法表现较好。最终结果显示,在Movielens数据集上精确率整体提高了2.35%,在固井作业数据集上精确率提高了10.08%,在Olist电子商务数据集上精确率提高了3.53%。 图4 对比实验结果 表3 消融实验结果 5.2.2 溯源效率对比 (1)溯源效率评价指标。 该文将单条元组的溯源消耗时间作为溯源效率的评价指标,单位为分钟。 (2)溯源效率优化消融实验。 在3种数据集上分别对70条SQL语句的查询结果进行溯源,最后将单条平均耗时作为实验结果。 由表3溯源效率对比结果可知,ProvEmb-X在3种数据集上的时间消耗均小于ProvEmb。由w/o FROM与完整的ProvEmb-X差值得知“FROM定位”表现最为突出,其次是LSH算法。 由图4(b)的4次对比实验可知,ProvEmb的穷举式扫描对所有元组都进行元组向量生成,计算量巨大导致消耗时间也相对较长。因此,使用FROM+LSH算法将范围固定在少部分相关元组中。但是在实验中发现耗时仍然过大,继而使用TPVEC+LSH+TPFIL算法过滤非源数据的元组,再次缩短时间消耗。最终结果显示,在Movielens数据集上耗时减少了13.13%,在固井作业数据集上减少了13.33%,在Olist电子商务数据集上减少了13.36%。 5.2.3 存储开销对比 该文采用计算ProvSQL/ProvEmb(-X)相对比例的方式,对比标注法与词嵌入法的存储开销,等于1代表存储开销一样,小于1代表词嵌入法开销大,大于1代表标注法开销大,计算结果如表4所示。由结果可知标注法与词嵌入法的存储比较相差较小,是因为文中实验设备能力有限,实验数据体量相对较小且SQL语句数量较少,导致数据标注占用的存储空间不大,若是在大规模数据集上则会有较大的差异。且ProvEmb-X的存储开销比ProvEmb稍高,是由于在属性重要性优化机制阶段对解析SQL语句得到的JSON进行了存储。 表4 存储开销相对比例 5.2.4 溯源结果展示 该文只对表1(a)中tid=8的元组results(Monty Python's Life of Brian (1979),3.5,1 573 944 005)进行溯源结果展示。由于文章篇幅限制,在相关表中各取相似度排名较高的前7个元组,并对其在ProvSQL中进行比较,最终实验结果如表5所示。其中,results表中tid=8的元组的直系源数据是由movies表中tid=1 053的元组和ratings表中tid=817的元组组合而成。其他元组为tid=8的元组的间接源元组,如图5所示,可以清晰地展现tid=8的流转路径。 图5 tid=8的元组溯源关系 表5 results表中tid=8实验结果 为解决传统方法中存储开销大的问题,该文提出了基于词嵌入的元组级数据溯源改进方法,并通过实验证明了该方法的有效性和普适性。该方法可应用于派生数据更为膨胀的海量数据场景,能够有效追溯元组级数据的来源,并通过溯源方法优化机制提高溯源精确率和时间效率,能够作为元组级数据溯源的有效方法。 目前数据溯源领域的研究成果相对较少,基于词嵌入的元组级数据溯源方法研究现仍然存在一些问题。通过计算相似度,以丢失一些信息为代价来压缩海量信息,最终实现元组级数据溯源。下一步研究内容为如何进一步提高精确率,以此来减少有用信息的丢失。并且目前在国内外关于元组级数据溯源方法的研究中,都没有解决聚合查询的溯源问题,下一步也可由此展开研究,从而提高方法的适用范围。4.2 元组过滤优化机制

4.3 属性重要性优化机制
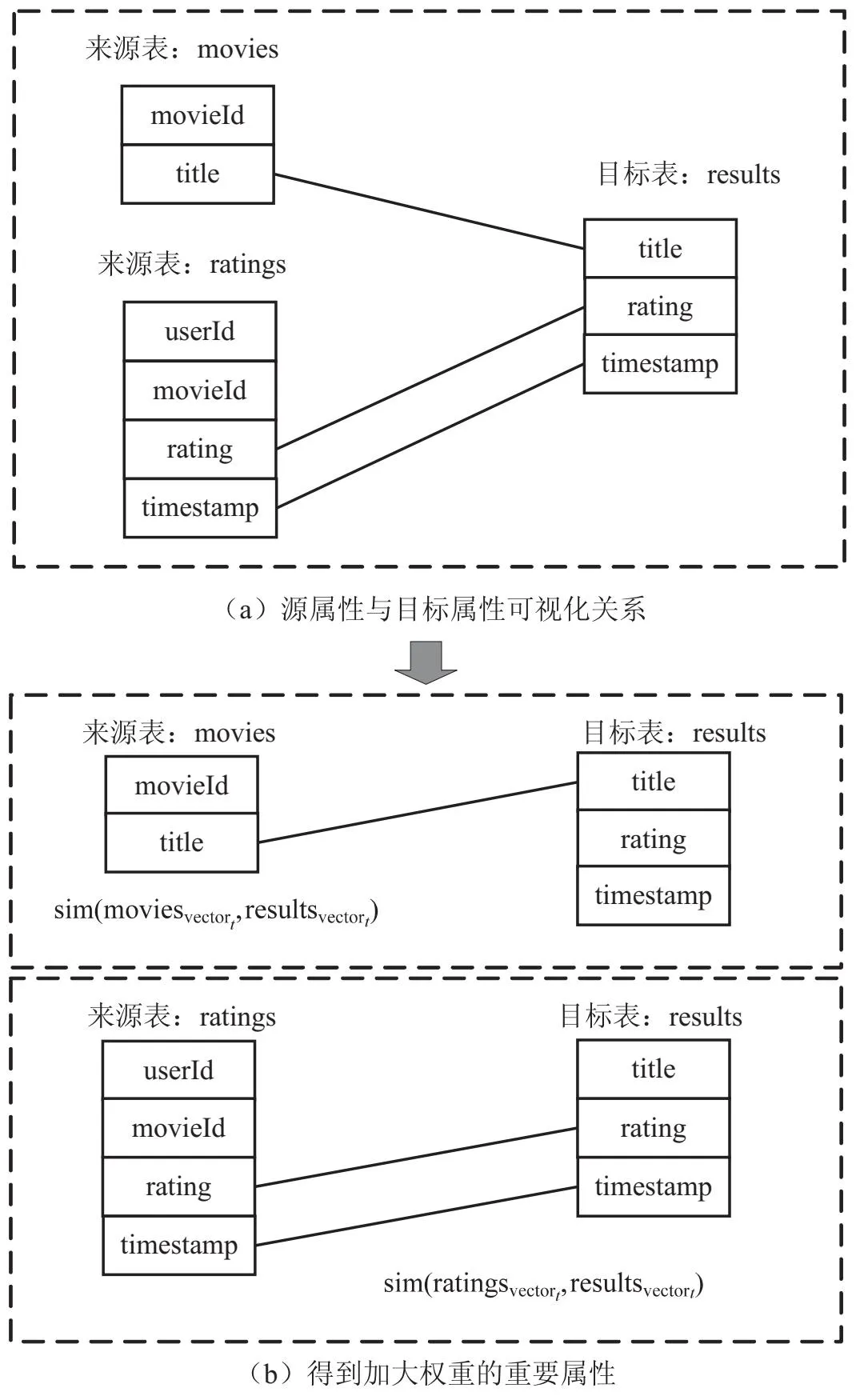



5 实 验
5.1 实验数据

5.2 实验结果及分析




6 结束语
猜你喜欢
电脑报(2021年14期)2021-06-28新世纪智能(语文备考)(2020年4期)2020-07-25数学年刊A辑(中文版)(2020年2期)2020-07-25数学物理学报(2019年6期)2020-01-13计算机与生活(2019年5期)2019-07-18吉林大学学报(理学版)(2018年2期)2018-03-29数学物理学报(2017年5期)2017-11-23语文知识(2014年4期)2014-02-28电信科学(2013年10期)2013-08-10新课程学习·中(2013年3期)2013-06-14
