
标记分布与时空注意力感知的视频动作质量评估
2023-12-23 10:14张宇徐天宇米思娅
中国图象图形学报 2023年12期
张宇,徐天宇,米思娅
1.东南大学计算机科学与工程学院,南京 211189;2.东南大学软件学院,南京 211189;3.东南大学网络空间安全学院,南京 211189;4.紫金山实验室,南京 211111
0 引言
视频动作质量评估旨在评估视频中特定动作的完成质量,可以有效减少人为评判错误。该技术在技能教学(Doughty 等,2019)、体育竞技(Parmar 和Tran Morris,2017)以及医疗手术(Funke 等,2019)等领域有着潜在价值与广泛的应用,已成为计算机视觉领域一个新兴且具有吸引力的研究课题。2020年东京奥运会使用了能够对运动员进行评分的人工智能(artificial intelligence,AI)系统,以对运动员的运动情况进行反馈,减少因得分引起的争论。由于计算机视觉技术的成熟,研究对象也逐渐从视频行为识别到视频行为质量评估。传统的行为识别问题(Feichtenhofer 等,2019;Yang 等,2020;杨清山和穆太江,2022;臧影 等,2022)可以将整个视频序列分为某一类别,而动作质量评估(action quality assessment,AQA)任务需要考虑类内之间的差异,综合考虑整个视频的各个片段及其对动作得分的贡献度,以获得总体评估得分。因此,AQA 任务对同一类别视频的识别更具有挑战性。
在过去的几年中,有大量的AQA 方法相继提出。大部分是将动作质量评估简单地视为一个回归问题(Pirsiavash 等,2014;Tang 等,2020;Wang 等,2021),对所获特征进行回归,直接得到动作的预测分数,或是一个成对比较问题(Doughty 等,2019;Yu等,2021;Xu 等,2022),通过两两比较学习到质量特征。但是目前的方法效果有限,可以总结为以下问题:
1)目前大多数方法存在多尺度时空特征的问题。视频中动作的空间和时间位置对于动作质量评估而言十分关键,样本视频具有许多与动作无关的信息,因此目前的视频动作质量评估方法存在多尺度空间特征问题,即不同的视频在空间维度上可能存在主体尺度大小不同,导致动作信息难以捕获,如图1 所示,动作执行目标大小和位置在不断变化。此外,动作质量评估还存在多尺度时间特征问题,即在时间维度上可能存在的不同持续时间和执行速率,不同时间片段与标记的相关性也不同,例如图1(c)中,运动员摔倒片段与其相邻片段之间具有极高的正相关性,而与图1(a)之间的相关性很低,因为序列首部片段往往是不相关的背景内容,甚至呈负相关。

图1 动作质量评估时空多尺度问题示意图Fig.1 Schematic diagram of the spatio-temporal multi-scale problem of action quality assessment((a)soar;(b)landing;(c)failure)
2)现有方法忽略了标记的内在模糊性问题。以往的动作质量评估方法(Parmar 和Tran Morris,2017)往往关注于单个得分标记,忽略了分数标记内在的模糊性问题,不同裁判可能给出不同得分以及给出得分的主观性。例如跳水运动的得分由7 位裁判给出,并不是由一个标记确定。
3)目前提出的注意力机制的注意力头普遍存在冗余的问题。过去的工作中,自注意力机制头的数目往往比较大,Michel 等人(2019)在测试时发现部分注意力头是冗余的,即使是移除大多数注意力头之后,模型性能也没有很大的影响,在本文的实验中,当注意力头数目增多时,动作质量评估效果反而变差。
为解决上述问题,本文提出一种基于时空自注意力及标记分布学习(label distribution learning,LDL)的视频动作质量评估模型SALDL(selfattention and label distribution learning)。该模型将动作质量评估得分预测问题转化为一个预测不同得分估计的概率问题。本文假设样本标记服从某一概率分布,进而利用KL 散度(Kullback-Leibler divergence)损失函数学习样本的标记分布,从而解决上述的标记内在模糊性问题。本文使用I3D(inflated 3D ConvNet)模型进行特征提取,利用多种感受野大小的卷积核对各段视频序列进行特征提取,解决多尺度空间特征问题。同时,本文提出一种新的正负时间注意力模块(pos-neg temporal attention,PNTA)。PNTA 通过最大化各个片段之间的正相关自注意力特征与负相关自注意力特征之间的距离,保持正相关注意力头和负相关注意力头之间所学到的特征尽量不同。PNTA 模块可以在减少注意力头造成冗余问题的同时,获取样本各个时间片段之间的上下文依赖关系,解决了多尺度时间特征问题,从而更好地对特定动作进行评估。
本文的主要贡献包括:1)设计一种新的视频动作质量评估模型SALDL,该模型能关注视频序列中不同时空位置的动作信息,并通过标记分布学习方法生成细粒度标签来处理标记模糊性问题;2)提出一种正负时间注意力模块PNTA,通过该模块使不同注意力头之间学习的内容尽可能不同,在增强视频片段的上下文信息的同时解决了注意力头冗余及收敛困难的问题;3)提出一种注意力感知结构(Attention-Inc)将自注意力机制渐进式地融入Inception 模块,获得不同尺度卷积特征之间的上下文信息,从而关注更有利于动作质量评估任务的特征;4)本文所提出的SALDL 方法在多个行为视频数据集上取得了优异的效果,均取得了以往最佳结果,并通过大量的消融实验证明了各模块的有效性。
1 相关工作
1.1 动作质量评估
目前绝大多数动作质量评估工作使用基于深度学习的方法(Pan等,2019;Xu等,2022),该方法提取出视频数据中的局部或全局特征,然后利用全连接层或其他特征融合方式汇集特征,最后使用回归、成对排序或标记分布学习等方法生成对视频质量的评估。Zeng 等人(2020)训练两个图卷积网络单元和一个注意力单元,前者用来表示动态信息和姿态相关性,后者赋予每个姿态相应的权重。Yu 等人(2021)通过I3D 网络分段提取视频特征,然后利用对比回归的方法,先学习输入视频相对于样例视频的差异,然后将差异的得分加上样例视频得分得到动作质量评估结果。Wang 等人(2021)同样用I3D网络作为视频表示框架,提出一种时空管道方法来获得复杂多变的动作位置特征,最后采用回归的方式预测动作得分。Xu 等人(2022)将样例视频和查询视频分段之后,将对应片段的视频块输入至同一个Transformer 解码器中,最后相加得到动作质量评估结果。
1.2 自注意力机制
自注意力机制最早用于学习文本表示,通过自注意力机制的QKV(query,key,value)三元组来提取上下文特征。因为其有效性,自注意力机制广泛应用于视频序列建模,例如Wei 等人(2022)将视频序列切分为时空立方块,然后利用Transformer 中的多头自注意力模块对时空立方块进行建模。Fan 等人(2019)提出的MviT(multiscale vision Transformer)系列模型同样将视频序列切分为时空立方块,提出池化自注意力机制,将池化操作和自注意力机制结合,以达到构建多尺度ViT(vision Transformer)并进行多尺度视频序列建模的目的。ViViT(video vision Transformer)(Arnab 等,2021)提出多种类型的时空注意力建模方式。该方法采用自注意力机制对时空进行建模,图像向量(token)数量与注意力机制计算量成平方关系,因此效率较低。上述方法均使用自注意力机制同时对视频的时空特征进行建模。而本文提出的SALDL 模型首先通过Attention-Inc 结构进行多尺度的空间特征建模,然后使用正负时间注意力模块(PNTA)对视频时间序列进行建模。
此外,Michel 等人(2019)证明传统的自注意力机制的头数存在冗余的现象,自注意力机制需要捕捉全局的上下文特征,导致其计算量比较大且难以收敛。为解决该问题,Lin等人(2022)利用光流网络计算并估计相邻帧索引的key 值,这是从减少自注意力机制参考的key 值数量的角度出发。而本文为解决这个问题,从减少冗余的自注意力头的角度出发,提出PNTA 模块。PNTA 通过最大化各个片段之间的正相关自注意力特征与负相关自注意力特征之间的距离,保持正相关注意力头和负相关注意力头之间所学到的特征尽量不同,从而达到降低计算量的同时提高动作质量评估效果。
1.3 标记分布学习
标记分布学习是一种新型的机器学习范式,模型对所有标记的描述程度构成类似概率分布的结构,用于学习样本分布而不是单个标记的方法,最早由Geng 等人(2013)提出利用LDL 来实现面部年龄估计,其提出IIS-LLD 和条件概率神经网络(conditional probability neural network,CPNN)算法提取面部特征。而后来随着深度学习的发展,越来越多依靠深度学习和标记分布森林方法进行标记分布学习,在人脸关键点检测(Su 和Geng,2019)、人流检测(Ling 和Geng,2019)等任务中广泛使用。在动作质量评估任务中,Tang 等人(2020)提出利用LDL 方法预测输入动作视频的分数分布,而不是单一的分数数字,以便能够很好地处理严重的分数不确定性,这很大程度上限制了AQA(action quality assessment)任务的性能。在视频分布方面,Geng 和Xia(2014)提出一种软语法解析方法用于视频解析,该方法通过不同子动作来描述视频段。Ling 和Geng(2019)利用混合高斯分布来模拟不同视频帧中人群数量的变化,用于室内人群计数。而本文采用的LDL 算法利用高斯分布函数将得分标记转换为分布标记,并行训练多个多层感知机生成直接生成分布标记,提供更加精准的动作质量评估结果。
2 SALDL模型
下面对SALDL 算法流程进行描述,首先对视频进行预处理,将原视频抽帧得到总长度为L的输入视频F={F1,F2,…,FL},FL表示第L帧,然后将其分段为n个相互重叠的片段C={C1,C2,…,Cn},Cn表示第n个片段,每个片段包含m帧,对每个片段中的每一帧进行下采样和随机数据增强,实施细节见3.2 小节。然后将各个视频片段输入视频表示模块,提取每个片段时空特征α={α1,α2,…,αn},将各视频片段的时空特征α作为序列输入PNTA模块,得到序列之间包含上下文信息的注意力特征β={β1,β2,…,βn}。接下来将所有正负时间注意力特征β拼接并输入给LDL 模块,得到预测标记分布和真实标记分布,最后以两者之间的KL 散度作为损失函数,对模型进行训练。本文提出的SALDL 网络结构如图2 所示,主要由视频表示模块、正负时间注意力模块(PNTA)以及标记分布学习模块(LDL)构成。

图2 SALDL网络结构图Fig.2 The structure of the SALDL model
2.1 视频表示模块
由于I3D 网络具有多种感受野大小的卷积核,能够对输入特征分别执行不同尺度的卷积及池化操作以获得多尺度空间特征。故本算法使用具有Inception 模块的I3D 网络结构。下面对其进行详细介绍。I3D 具有三维卷积层、最大池化层、平均池化层以及Inception 结构。由于ReLU(rectified linear unit)激活函数具有单侧抑制的作用,又具有稀疏激活性的特点,可以减少一部分参数量,达到防止过拟合的目的,具有相对较宽的兴奋边界,能够对任意输入特征进行激活;梯度恒为常数,不会产生梯度消失或梯度爆炸的现象,故均使用ReLU 作为激活函数。本算法的I3D 模型预训练于Kinetics 数据集。具体来说,视频表示模块以n个视频片段作为I3D网络的输入,通道数、帧数、宽高分别为3、16、224。在通过各层之后,在时间上进行卷积,并进行平均池化操作对各个特征进行聚集,得到大小为[1,1 024]的特征an。
此外,由于传统的Inception 模块没有考虑不同感受野卷积特征之间的上下文关系,本文进一步提出渐进式的注意力感知结构(Attention-Inc),Attention-Inc 将不同感受野大小的卷积特征编码至同一维度,通过多头自注意力机制(multi-head selfattention,MHSA)获得不同卷积特征的上下信息,利用1 × 1 卷积还原卷积特征大小,最后与原特征拼接。结构如图3 所示,φ和θ分别表示Inception 和Attention-Inc特征。在Inception结构中通过3 × 3 × 3以及1 × 1 × 1 不同感受野大小的卷积核进行卷积之后,将所有尺度特征进行拼接,形成一个能够代表更多信息、更有深度的特征,以此解决时空多尺度问题。在Attention-Inc 结构中利用1 × 1 × 1 大小的卷积层和平均池化层将第i个卷积特征φi表征为一组尺寸相等的向量,然后通过多头自注意力机制使不同尺寸卷积特征之间获得上下文关系,最后将经过1 × 1 × 1 大小的卷积和扩展操作的注意力特征θi与φi进行拼接,输入给下一个模块,获得不同尺度卷积特征之间的上下文信息,从而关注更有利于动作质量评估任务的特征。

图3 注意力感知结构(Attention-Inc)示意图Fig.3 The structure diagram of Attention-Inc
2.2 正负时间注意力模块
传统的视频动作质量评估方法中卷积核大小固定,无法获得视频不同时空片段的上下文交互信息。与此同时,传统自注意力机制又存在自注意力头冗余及难以收敛的问题,具体细节见1.2 小节。针对上述问题,本文提出正负时间注意力模块(PNTA),当前注意力头称为正相关头(positive head,PH),其他注意力头称为负相关头(negative head,NH)。正相关头用于表征与动作质量评估相关片段的特征,负相关头用于表征与动作质量评估非相关片段的特征。PNTA 通过最大化各个片段之间的正相关自注意力特征与负相关自注意力特征之间的距离,保持正相关头和负相关头之间所学到的特征尽可能不同。在减少过多注意力头造成的冗余问题的同时,解决了多尺度时间特征问题,加快SALDL 模型的收敛,达到提高模型效果、减少注意力头冗余的目的。PNTA 模块可以随意嵌入所有的多头子注意力机制中。
将PNTA 模块扩展至h维,可以提出PNTA 损失函数L1,具体为
式中,γ表示PNTA 损失的比例系数,n和h分别表示片段数目和注意力头数目表示第i个视频片 段的第j个正相关注意力特征表示第i个视频片段的第f个负相关注意力特征。
PNTA 模块计算方式如图4 所示,将第i个片段的I3D 特征αi输入至正相关和负相关。相当于增加了一个维度,该维度包含序列中多个片段之间的正相关特征以及负相关特征。在第j个自注意力头中通过3 个线性层分别输出维度为dk的query、key,用qi,j和ki,j表示,以及维度为dv的value,用vi,j表示。其中query 用来匹配key,value 表示从输入特征ai中所提取的信息。接着,计算qi,j和序列中其他片段kay值的点积,为防止数据过大,导致后面使用激活函数计算之后的结果恒取0 或1,将点积结果除以之后使用softmax 函数对结果进行计算,以获得该序列片段value 值的权重,最后,与当前片段的value 值vi,j做点积运算,具体为
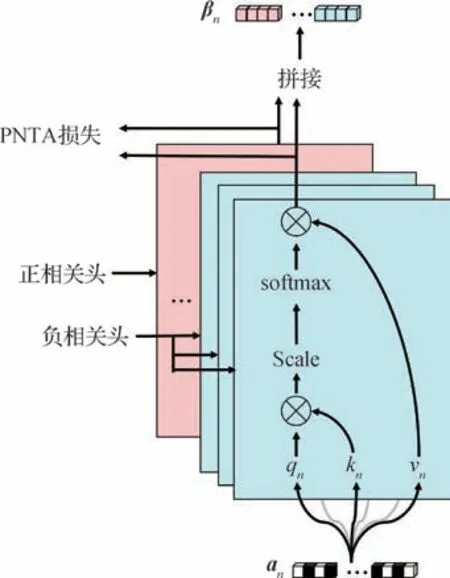
图4 正负时间注意力模块结构示意图Fig.4 The structure diagram of pos-neg temporal attention module
式中,v表示属于1到n的其他片段序号,将两者拼接在一起得到第i个片段的第j个正负时间注意力特征表示softmax激活函数。
在实际计算过程中,二维的视频片段序列组合在一起形成矩阵,SALDL 算法将所有片段结果并行运算,具体为
式中,Q、K、V分别表示将各片段特征向量通过线性层映射得到的query、key、value 堆叠而成的矩阵,dk表示K的维度,τ表示拼接。最后得到参考了所有视频片段的具有上下文信息的特征Fβ={β1,β2,…,βn}。
2.3 标记分布学习模块
动作质量评估任务的标签由多位裁判主观打分构成,标签分布在一定的范围内。因此本文通过标记分布学习的方法利用该分布提高动作质量评估效果。此外,相比于单标记学习和多标记学习,标记分布学习在动作质量评估任务中更加灵活通用。标记分布学习可以表示为以下形式:xi表示第i个示例,第j个标记用表示对于xi的描述度用表示,xi的标记分布用向量表示,因此gi∈[0,1]m,且,其中m表示可能标记数目,由数据集的取值范围确定。对于单标记而言,其只有一个标记,因此单标记学习及多标记学习可以视为标记分布学习的特例,标记分布学习是更加灵活通用的方法。具体来说,SALDL 模型使用全连接层预测不同标记的描述度gi获得预测标记分布。然后利用标记增强(label enhancement)的方法将原始标记转化为标记分布。SALDL 引入真实标记服从某种分布的先验知识,这里假设服从高斯分布,标记增强过程中分布函数的选取细节可见4.7 小节。通过原始标签可以生成均值为μi、标准差为σ的高斯方程,具体为
式中,σ既是标准差也是一个超参数,评估一个动作质量的好坏的不确定性。
式中,k表示实例数,下标gt 和pre 分别表示真实值和预测值,以下省略符号i。
在MTL-AQA 和JIGSAWS 数据集中,总标记由多个子标记之和组成,定义子标记的真实标记分布为子标记的预测标记分布 为其中,k表示子标记数目。标记分布学习模块由多个多层感知机网络构成,多层感知机学习各个子标记分布。将正负时间注意力特征βn作为输入,网络使用线性层进行维度变换,使用ReLU 激活函数添加非线性因素。接着使用softmax 函数激活。输出维度转换为m的预测标记分布,感知机结构如表1 所示,其中n表示视频片段数量。

表1 输出预测分布的多层感知机网络结构Table 1 Multi-layer perceptron network structure for output prediction distribution
由于标记分布可视为一种概率分布,而KL散度是一种用于衡量两个概率分布之间差异的非对称性度量,因此在训练阶段,使用KL 散度作为标记分布学习的损失函数计算sgt,k和spre,k之间的损失,利用梯度下降法最小化KL损失函数对其进行优化,使得两个概率分布之间的差异最小,即预测分布和真实分布越相似越好。因此模型损失函数由两部分组成,分别为预测分布与真实分布之间的KL损失L2,以及正负时间注意力损失L1。具体为
式中,L表示对于每一个训练样本的总体损失,γ1和γ2分别表示PNTA 损失和KL 损失的比例系数,spre,k表示样本中的第k个预测分布,sgt,k表示样本中的第k个真实分布表示第k个预测分布中第i个标记的描述度表示第k个真实分布中第i个标记的描述度,使用Adam 优化器对上述损失函数进行优化。
在推理阶段,从每一个预测的子标记分布spre,k中选择概率最大的一个作为第k个子标记的预测得分,获得k个子得分,然后子标签得分中最大的两项以及最小的两项,最终得分为剩余子得分之和。推理过程如图5 所示。其中,Ji表示第i个子标签得分,蓝色曲线表示利用标记分布学习获得的标记分布,红色曲线表示真实标记分布,取概率最大的点作为预测的子标签得分,然后去除两项最高分以及两项最低分之后求和并乘以难度系数作为最终得分。
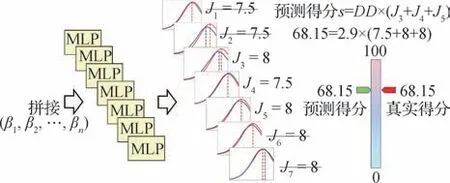
图5 标记分布学习模块推理过程示意图Fig.5 The inference diagram of label distribution learning module
在MTL-AQA数据集中,需要将最终得分乘以难度系数,而JIGSAWS 不存在难度系数参数。得到最终的预测得分s,具体为
式中,DD表示该样本的难度系数,k∈U表示在剔除两项最大值和两项最小值之后的所有得分。
3 实验实施
3.1 数据集
目前视频动作质量评估主要使用以下3 个数据集,本文使用四折交叉验证划分训练集以及测试集。
1)AQA-7。由Parmar(2019b)提出,包含7 个动作类别(跳水、跳马、双板滑雪、单板滑雪、双人2 m跳水、双人10 m 跳水、蹦床),共1 189 个样本。标注信息有动作类别、采样序号、得分。相比于AQA 增加了一个蹦床的类别。
2)MTL-AQA。由Parmar(2019a)提出的多标记跳水运动数据集,标记内容由3 个部分组成,动作类别、动作质量分数、动作描述。得分部分包含多个裁判给出的分数以及动作难度系。
3)JIGSAWS。由Gao 等人(2014)提出的医疗手术数据集,具有3 个动作类别:打结、穿针和缝合,但样本数量较少;标记数据种类包含开始帧、结束帧、类别id、得分。
上述3 个数据集的样本数量、类别数量以及标记数量如表2所示。

表2 数据集基本信息Table 2 Basic information about the datasets
3.2 实施细节
本文在Intel(R)Xeon(R)Platinum 8260C CPU主机训练模型,使用两块NVIDIA GeForce RTX 3090(M)显卡,显卡内存为24 GB,可使用内核数为12,内存大小为86 GB,每秒浮点运算次数为17.37 TFLOS。模型训练学习率设为10-4,权重衰减设置为10-5,正负时间注意力损失的比例系数为10-4。I3D模型预训练于Kinetics数据集,梯度下降时优化器选用Adam 优化器,其每一次迭代学习率都有确定的范围,参数比较平稳,对于不同的任务而言,具有自适应的学习率。
SALDL 模型预处理阶段与对数据集进行随机的数据增强,包括对样本进行旋转、翻转,随机对样本进行最近邻插值、二次插值、三次插值以及Lanczos插值方法等。在数据量不变的情况下,增加样本的数量和多样性,有效地防止了因为数据单一而产生的过拟合。接下来对数据集及标记进行归一化处理。旨在将非整数型标注转化为整数型标注,以便对标记分布生成模块的输出维度进行定义。样本视频被逐帧提取和分段之后进行Z-score 标准化。传统动作质量评估方法直接进行分段,每一段的首尾帧互不重叠,因此缺少上下文之间的联系,而本文采用每一段之间部分重叠的方式进行段的划分。具体分段方法见4.6小节。
3.3 评估方法
斯皮尔曼等级相关系数(Spearman rank correlation coefficient,Sp.Corr)可以衡量两个序列之间的相似程度,也可认为斯皮尔曼等级相关系数为经过排行得到的两个随机变量的皮尔逊相关系数。因此,本文使用斯皮尔曼相关系数来衡量本文模型所预测的标记和真实标记之间的相关性,利用该单调方程来评价两个统计变量之间的相关性,以检验模型效果。斯皮尔曼相关性定义为
式中,p表示按照预测结果对序列进行排序生成序列,q表示按照真实得分进行排序的序列,ρ表示斯皮尔曼等级相关系数,即评估结果。其取值范围为-1~1,ρ值越大说明相关性越高,模型效果越好。
4 实验结果
4.1 基准方法对比
将本文SALDL 模型与其他动作质量评估模型在MTL-AQA 数据集进行对比,如表3 所示。结果表明SALDL 模型的动作质量评估能力要优于以往最佳方法,在其他实验条件相似的情况下取得了最佳结果,其斯皮尔曼等级相关系数为0.941 6。充分证明了该方法在动作质量评估任务中的有效性。此外,SALDL 模型和C3D-AVG-STL、C3D-AVG-MTL 等方法相比,虽然FLOPS 更高,但是其参数量只有后者的1/5;SALDL 模型与MUSDL 相比,两者具有几乎相似的参数量和FLOPS,但是本文模型的Sp.Corr取得了更好的结果。
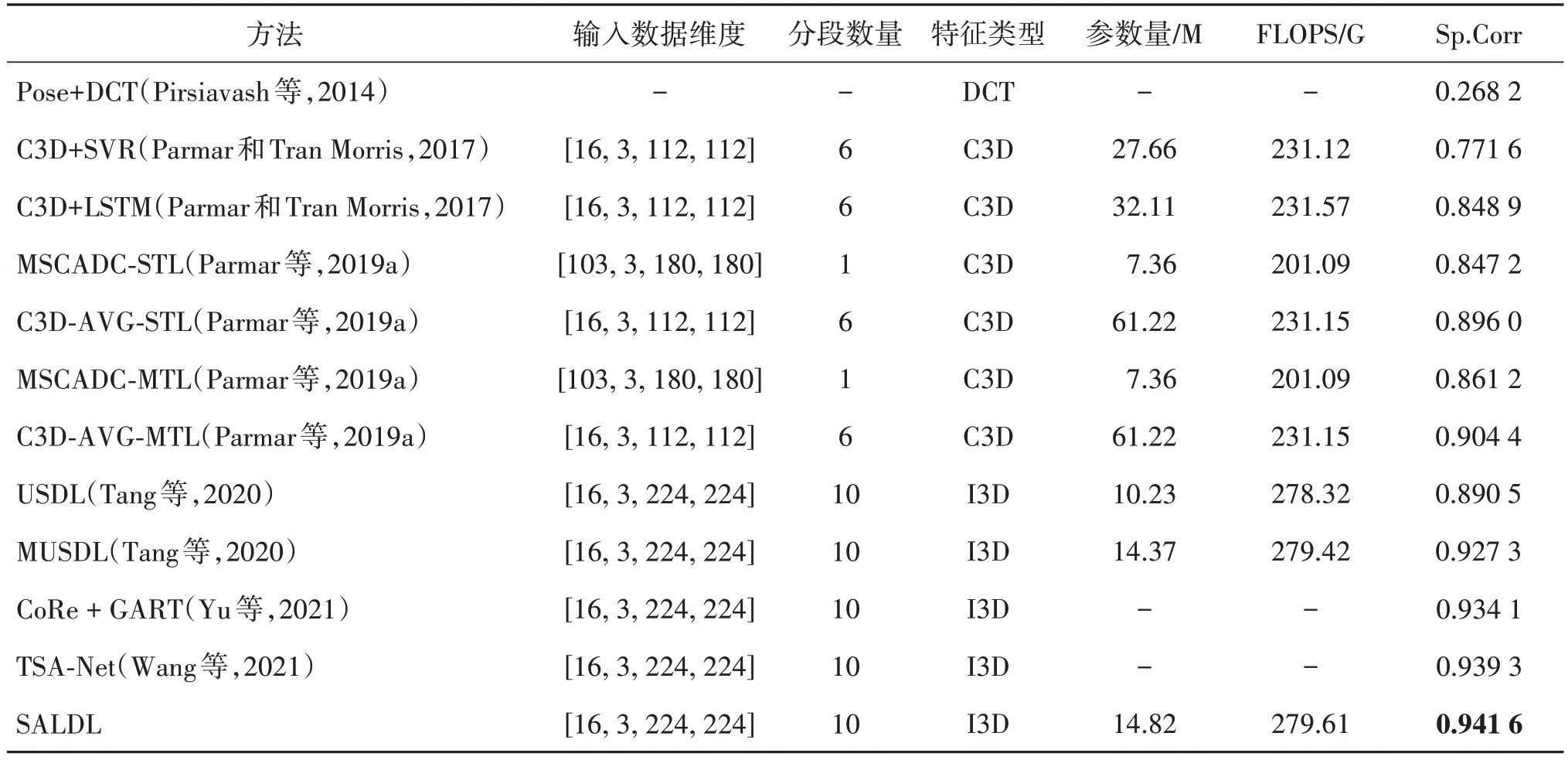
表3 SALDL模型在MTL-AQA数据集与基准方法对比Table 3 SALDL model on MTL-AQA dataset compared with benchmark methods
将SALDL 模型与其他基准方法在JIGSAWS 数据集中的打结(knot_tying)、穿针(needle_passing)和缝合(suturing)3个任务中进行测试。JIGSAWS数据集的视频帧数随样本视频长度动态变化,因此本文随机采样出160 帧作为模型的输入,然后与MTLAQA 数据集相同,将视频分为10 段,每段16 帧,实验结果如表4 所示,将实验结果与基准方法结构对比们可以发现,本文提出的SALDL 模型在打结(0.836 4)和穿针(0.866 0)任务中的表现优于其他所有基准方法,且在3 个任务中的平均斯皮尔曼等级系数为0.818 3,达到了最优结果。
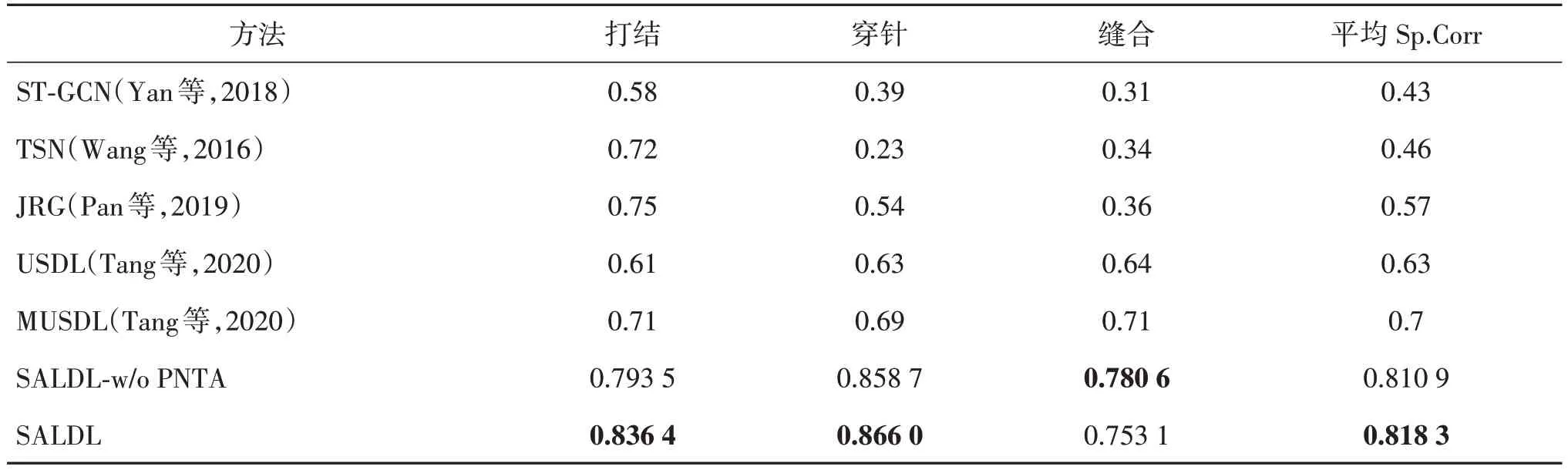
表4 SALDL模型在JIGSAWS数据集与基准方法对比Table 4 SALDL model on JIGSAWS dataset compared with benchmark methods
4.2 标记分布学习对动作质量评估的影响
为研究LDL 模块对动作质量评估的影响,利用散点图将基于标记分布学习的方法与基于回归的方法进行对比,图6(a)表示的是使用回归方法的结果,其将SALDL 模型全连接层的输出维度改为1,并剔除softmax 函数,直接输出预测得分。图6(b)表示的是使用标记分布学习方法的结果。蓝色标点为网络的预测,y轴表示预测得分,x轴表示真实得分,真实样本用虚线表示。散点分布越集中,表示预测结果越接近真实样本,模型准确的更高。对实验结果进行定性分析,可以发现基于回归的SALDL 模型在高分段部分明显偏离真实得分,整体得分偏低,而基于标记分布学习的动作质量评估方法更加接近真实样本数据,实验结果表明,引入标记分布学习显著提升了模型在高分段的表现,整体准确率有所提升,充分证明了标记分布学习的泛化性及有效性。
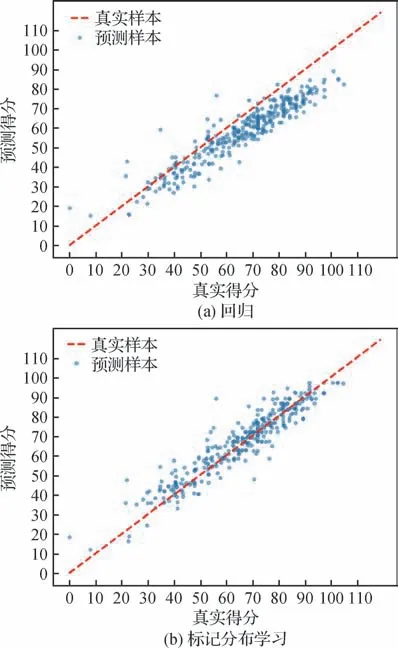
图6 基于回归的方法与基于标记分布学习方法的评估结果Fig.6 Regression-based versus label distribution learning-based methods to evaluate results((a)regression;(b)label distribution learning)
4.3 研究注意力结构对动作质量评估的影响
PNTA 模块是SALDL 模型中的重要组成部分,为探索注意力模块及其结构在SALDL 模型中对视频质量评估结果的影响,本小节对不同结构的SALDL 模型进行训练,包括不包含注意力模块(No_Attention),单注意力头(Single_Head),正负注意力头(Pos&Neg_Head)以及多注意力头(Multi_head),得到在打结、穿针、缝合和跳水动作质量评估任务中各模型的Sp.Corr如图7所示。
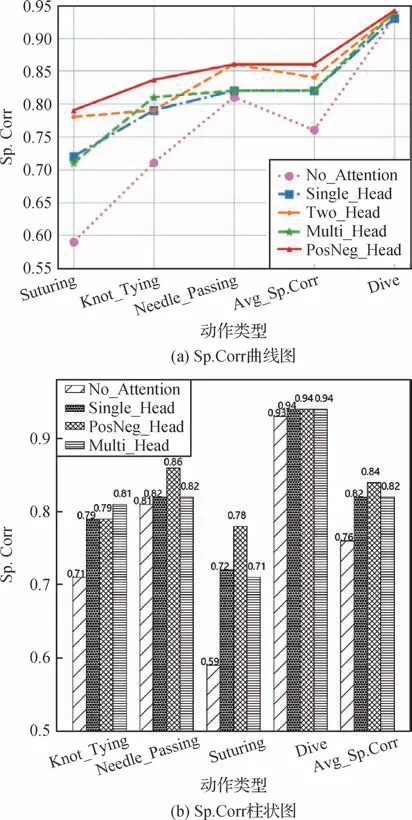
图7 不同类型自注意力对动作质量评估的影响Fig.7 The effect of different types of self-attention on the action quality assessment((a)Sp.Corr plot;(b)Sp.Corr histogram)
不使用自注意力机制时模型在所有动作类型中的评估效果最差,其平均斯皮尔曼等级相关系数为0.759 1,而添加自注意力模块之后,动作质量评估的性能有明显提升,相较于不使用自注意力机制的模型,单注意力机制和多注意力机制分别提升了7.78%和7.95%,而使用了PNTA 模块以后的SALDL 模型,其在所有动作类型中的平均斯皮尔曼等级相关系数达0.842 8,提升了11.01%。其次,单个注意力头的评估结果最差,拥有正负注意力头的模型效果最好,其相比于单自注意力头,平均斯皮尔曼等级相关系数增加了3.2%,相较于多注意力机制增加了2.8%,说明自注意力头的个数与动作质量评估性能成非线性相关。注意力头过少可能使得上下文信息不够完整;注意力头过多可能增加大量参数,导致过拟合,且增加了计算复杂度。而正负注意力头能够较完整地提取视频段序列之间上下文信息,同时防止过拟合并降低计算复杂度。
4.4 优化器的消融实验
梯度下降是目前神经网络中使用最为广泛的优化方法之一,合理的选择优化器,在深度学习的理论以及工程任务中都是非常核心的问题。为研究优化器在梯度下降过程中对SALDL 收敛速度的影响,对使用不同优化器的SALDL 模型在JIGSAWS 数据集上进行实验。实验结果如图8所示,Adam 在第10个epoch 时达到了最高值,大于所有其他优化器;SGD(stochastic gradient descent)优化器的学习速率较慢且出现波动,而RMSprop 的效果与Adam 类似,但是相关系数没有Adam高。Adagrad优化器虽然有错误梯度方向上的阻力,但是优化速度和相关系数都比较低。基于实验结果本文选用Adam 作为梯度下降的优化器,一方面Adam 优化器的收敛速度最快,且其在梯度下降过程中使SALDL模型能找到最优解。

图8 不同类型优化器对动作质量评估的影响Fig.8 The effect of different types of optimize on the action quality assessment
4.5 SALDL各模块的消融实验
针对SALDL 模型的PNTA、LDL 以及Attention-Inc 结构进行消融实验,表5 中SALDL-Regression 表示基于回归的SALDL 模型,其Sp.Corr 为0.932 0。SALDL-w/o PNTA 表示没有使用PNTA 模块的SALDL 模 型,其Sp.Corr 为0.938 4。SALDL-w/o Attention-Ins 表示没有使用Attention-Inc 结构的SALDL 模型,其Sp.Corr 为0.939 9。消融实验结果表明,即使是单独去除了各个模块之后的SALDL 模型,也能够达到与以往方法相媲美的动作质量评估结果。但是与完整的SALDL 模型相比,分别去除各个模块之后的Sp.Corr均有一定程度的下降,充分说明了各个模块的有效性及重要性,下降程度由高到低排序为LDL 模块、PNTA 模块以及Attention-Inc结构。
4.6 分段策略对动作质量评估的影响
为研究视频段序列长度以及视频段长度的选取对模型的影响。本文将各分段策略的SALDL 算法在MTL-AQA 数据集上进行实验,取前20 个epoch 中最优结果,实验使用7-clip 表示,以[0,16,32,48,64,80,96]为帧首。将其分成7段,每段包含16帧。Pan 等人(2019)指出,对于大多数任务,段内帧的数量为10 时最合适。在此基础上,进一步研究了两种方案。第1 种方案以[0,10,20,30,40,50,60,70,80,87]作为这10 段(记为10-clip-s1)的起始帧索引。将步幅设为10,由于视频的长度是103帧,而每段包含16 帧,故将最后一个开始索引设置为87。第2 种方案采用[0,9,19,29,38,48,58,67,77,87]作为这10 段(记为10-clip-s2)的起始帧索引,使用I3D 模型作为特征提取网络。它以16 帧作为输入。结果如表6 所示,将视频分为10 段,且每段为16 帧的效果最好,其斯皮尔曼等级相关系数为0.941 6。而分成7 段,每段包含16 帧的效果最差,其斯皮尔曼等级相关系数不到0.925 4。说明并不是将视频段分得越大效果越好,分成10段每段16帧,且与段具有6 帧重合能够捕捉到更多视频中的时序特征,同时避免了段与段之间动作特征的割裂。

表6 不同的分段策略对动作质量评估的影响Table 6 Effect of different segmentation strategies on the action quality assessment
4.7 分布函数对动作质量评估的影响
LDL 模块将得分标记转换为得分分布,并对所有的分布截断离散化,重新标准化以符合分数范围。然而不同的分布所适用的场景不同,例如t分布适用于小样本且方差未知,而高斯分布适用于均值方差较稳定的情况。为探究分布函数的选取对于实验结果的影响,本文对各种分布函数进行了实验,如表7所示,实验选取χ2分布、t分布以及SALDL 模型所使用的高斯分布3 种分布在JIGSAWS 和MTL-AQA 数据集上进行实验,χ2分布的自由度(df)取2,t分布的自由度取10,均值(s)取标准化之后的分数,高斯分布遵循2.3小节实现。

表7 不同分布函数对动作质量评估的影响Table 7 Effect of different distribution functions on action quality assessment
实验结果表明,使用高斯分布模型在所有任务中的平均斯皮尔曼等级相关系数最高,达到0.849 2,而χ2分布的效果最差。然而,没有一个分布可以在所有的动作类型中均表现得最好,例如χ2分布在缝合任务和打结任务中具有最好的准确率,其原因可能是JIGSAWS 数据集样本数目较少,而高斯分布模型在穿针和跳水质量评估任务中的评估结果明显更好。
对MTL-AQA 和JIGSAWS 数据集进行实例分析,研究不同分布函数选取对于动作质量评估的影响,并可视化标记分布学习结果,如图9 所示。利用不同分布函数对各个数据集实例进行的标记分布学习。图中分别标注了实例类型及其编号,紫色直线表示样本标记,红色线条表示高斯分布、蓝色线条表示t分布、绿色线条表示χ2分布。实验结果表明,SALDL 模型在各个实例中能够学习标记在不同得分下的概率分布,使得学习过程更加透明,减少了标记的模糊性问题,充分验证了该模型的有效性。
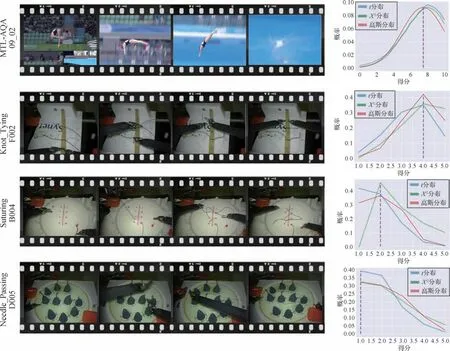
图9 不同标记分布函数的动作质量评估结果可视化Fig.9 Visualization of action quality assessment results with different label distribution
5 结论
本文研究的视频动作质量评估能够自动化地对特定动作的完成情况和执行质量进行评估,减少人力资源的消耗以及误判的现象,具有很强的扩展性和实用性。视频动作质量评估任务主要的难点在于特点动作的时空位置难以判断及认知差异导致的标记的内在模糊性。本文研究如何高效地利用自注意力机制挖掘不同尺度时空特征的上下文关系,研究如何通过标记增强及标记分布学习解决标记的内在模糊性。提出一种新的视频动作质量评估方法SALDL,为解决目前动作质量评估任务普遍存在的动作在视频内多尺度空间特征问题,通过Attention-Inc 结构使得模型能够获得不同尺度卷积特征之间的上下文信息;为解决标记的内在模糊性问题,使用标记学习方法获得细粒度标签;为了解决多头自注意力机制中注意力头的冗余及内在多尺度时间特征问题,通过PNAT 模块使不同注意力头之间学习的内容尽可能不同。本文进行了大量对比和消融实验,证明了SALDL 模型各个模块的有效性。实验结果表明,SALDL 模型在MTL-AQA、JIGSAWS 等数据集中均取得了当前最优的结果。
本文提出的模型引入了动作质量标记天然服从某种分布的先验知识,虽然能够有效解决标记的内在模糊性问题,但是分布函数的选取仍然需要人为干预。进一步的工作可以考虑研究如何动态确定选取分布函数、对不同分布函数进行融合等方法实现自适应的标记增强。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小学生作文(低年级适用)(2018年3期)2018-04-17
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
少儿科学周刊·少年版(2015年4期)2015-07-07
电视技术(2014年19期)2014-03-11
