
风格强度可变的人脸风格迁移网络
2023-12-23 10:14廖远鸿钱文华曹进德
中国图象图形学报 2023年12期
廖远鸿,钱文华*,曹进德
1.云南大学信息学院,昆明 650504;2.东南大学数学学院,南京 214135
0 引言
风格迁移技术可将艺术图像中的风格传输到原始的自然图像中,其中提供风格纹理和笔触等特征的图像称为风格图,而提供轮廓结构的图像称为内容图,风格迁移算法的目标是以风格图的纹理笔触与内容图的轮廓结构合成一幅新的风格化图像。图像风格迁移算法在航空航天,图像识别等领域中的应用广泛,如航拍测绘(Lin 等,2017)、图像分类(Huang 和Belongie,2017)等。人脸风格迁移算法作为风格迁移算法中一个分支,其内容图与风格图均为人类面部肖像,目标为将风格图的面部风格特征与内容图的面部内容合成为一幅新的面部图像,如图1 所示。如今人脸风格迁移算法已广泛应用于人脸识别(Nirkin 等,2018)和照片美化(Li 等,2018)等方面。

图1 人脸风格迁移算法示例Fig.1 Face style migration algorithm example((a)original image;(b)style image;(c)result image)
早期的人脸风格迁移算法(Shih 等,2014)使用了数学建模构建滤波器的方法,对所要得到其风格的目标图像的局部特征进行统计,并建立统计模型(Portilla 和Simoncelli,2000)描述其图像风格。这种算法只能针对一种单一风格进行生成,生成的结果图像风格不明显,且统计模型必须手动建模,因此算法效率较低,图2 显示了此算法的风格迁移结果。近年来,基于深度神经网络的算法已应用于人脸风格迁移工作中,Gatys 等人(2015a,b)首先提出基于深度神经网络的图像风格迁移算法,采用VGG-19(Visual Geometry Group)网络(Simonyan 和Zisserman,2015)代替了传统风格迁移算法中的统计特征模型,算法效率得到了较大提升。但由于VGG-19网络所生成的图像分布较为均匀,此时的风格迁移算法与纹理合成算法较为类似,风格传输效果不明显。

图2 早期人脸风格迁移算法示例(Shih等,2014)Fig.2 Early face style migration algorithm example((a)original image;(b)style image;(c)result image)
为了解决上述问题,将生成式对抗网络(generative adversarial network,GAN)(Goodfellow 等,2020)应用于图像风格迁移算法中。由于GAN 能够生成符合某一分布规律的图像,通过对GAN 网络进行训练即能生成与真实图像较为相似的目标图像。Isola等人(2017)提出了pix2pix 算法,使用条件生成对抗网络(Mirza 和Osindero,2014)学习从输入图像到输出图像的映射,以完成风格迁移任务,能够生成风格显著、质量较高的结果图像。Xie等人(2020)提出了一种基于相关对齐的总变分图像风格迁移模型。Zhu 等人(2017)采用了双判别器的结构,训练集可以指向两个不成对的图像集合,解决了风格迁移网络前期划分图像空间较复杂的问题。
Choi 等人(2018)提出的StarGAN(star generative adversarial network)采用前置编码器以实现风格迁移。此编码器可以实现图像到向量的转变,这个向量包含原本图像中的信息,再通过损失函数将向量规范至网络的潜空间中,以人为地修改网络中的潜变量。StarGAN 能够在保留原图像特征的同时学习到目标图像的风格,由于采用了前置编码器,风格迁移的多样性及强度都有所提升,但其自身存在着以下问题:1)StarGAN 生成的图像可能产生特征伪影,这种伪影有类似掩膜的性质,会在生成图像上呈现出多余的特征,造成生成图像失真;2)StarGAN 对于目标图像细节部分的特征学习有所欠缺,其原因在于此网络使用的风格向量较小,无法很好地归纳目标图像中的信息;3)StarGAN 对于每一对图像输入只有单一的风格迁移输出,不能较好地控制生成图像的风格强度。
为了解决以上问题,本文提出了MStarGAN(multi-layer StarGAN),采用权重解调(Karras 等,2020)方法解决StarGAN 网络中出现的特征伪影问题。为了解决传统编码器结构臃肿、参数量大、效率较低等缺点,采用Lin 等人(2017)提出的特征金字塔网络(feature pyramid network,FPN)模型作为前置编码器的基础结构,扩展了生成图像的风格多样性,并能得到不同风格强度的生成图像。本文的主要工作包括:1)提出一个能生成不同风格强度图像的人脸图像风格迁移网络,通过调整网络的参数,引入不同强度的目标图像特征,能够生成最多4 幅风格迁移强度不同的结果图像;2)采用权重解调方法重新构造生成器,减小了风格传输中的失真,减少了生成图像中的特征伪影;3)采用风格强度损失,保持了内容图特征与风格图特征在风格迁移过程中的平衡,避免生成图像风格偏向原图或风格图。
1 相关工作
1.1 GAN
GAN 网络可以生成满足特定分布规律的输出图像。Mirza和Osindero(2014)首先将标签信息编码为一个向量作为输入,约束隐变量与输出之间的关系,以控制GAN 的输出。Denton 等人(2015)将生成器由原本的多层卷积结构改为金字塔形结构,使用残差逼近,获得分辨率更高、质量更好的输出图像。Shrivastava 等人(2017)首次将图像作为生成器的输入,较好地学习到输入和输出两个不同数据分布间的映射。之后,基于GAN 的风格迁移算法(Elgammal 等,2017;Sbai 等,2018;Huang 等,2017)得以提出。但由于GAN 本身较难对隐变量进行修改,输出结果具有较大的局限性,仅通过GAN 实现的风格迁移算法无法很好地运用于实际。
1.2 编码器
目前主流的图像风格迁移算法分为两类:1)不使用前置编码器,仅对GAN 进行改进的网络,如pix2pix、CycleGAN(Zhu 等,2017)以及P2GAN(Zheng和Liu,2020)等;2)使用前置编码器的网络,由于在GAN 结构前增加了编码器,这种网络结构较为复杂,但能够得到更真实的结果,如StyleGAN(stylebased generative adversarial network)、StarGAN 等。StyleGAN 采用8 层的多层感知机(multilayer perceptron,MLP)作为基础编码器,通过将随机变量输入进编码器中,能够生成符合生成器分布的风格向量,将此风格向量输入到生成器中,即能达到控制输出图像风格的目的;DualStyleGAN(dual style-based generative adversarial network)(Yang 等,2022)在此网络的基础上将编码器扩展为两路18 层MLP,能够较为精细地控制图像细粒度风格;StarGAN 采用ResNet(residual network)(He 等,2016a,b)作为编码器,能够针对不同的图像风格域生成不同的风格向量。但这些网络采用的前置编码器效率较低,无法快速地将随机变量规范至网络的变量空间中。
1.3 风格学习模块
由于GAN 本身不具有学习风格向量中特征的能力,需要额外的模块进行风格学习。目前主流的方法是在生成器中采用AdaIN(adaptive instance normalization)(Huang 等,2017)算法。AdaIN 通过输入原图像与风格图像的均值与方差,对输入图像进行归一化,使处理后的图像具有风格图像的部分特征。但AdaIN 对输入图像的每个通道均进行了归一化,导致层与层之间相关联的信息受到破坏,输出图像原本信息量较高的部分进一步增强,导致结果图像失真。
本节提到的编码器、GAN 网络以及风格学习模块为目前人脸风格迁移网络的主要组成部分。网络存在以下问题:1)编码器结构较简单,提取的风格向量无法完整表达风格图像的特征,通过增加编码器网络层数的方式能得到较好的风格向量,但参数量巨大,耗费时间久;2)采用AdaIN 的方法会在特征图中产生特征伪影,使生成图像失真;3)无法控制生成图像的风格强度,传输多少风格到生成图像中是随机的。为了解决以上问题,本文提出了MStar-GAN。
2 本文方法
2.1 网络整体结构
MStarGAN 的整体结构如图3 所示,整个网络包含4个子网络:Style Encoder、Mapping Network、生成器和判别器。其中,Style Encoder 提取输入图像中的特征信息,将其转化为风格向量w;Mapping Network 可以将随机变量转变为风格向量w;生成器和判别器即为GAN 网络中的生成网络与判别网络。与StarGAN v2相比,MStarGAN 采用FPN网络作为编码器的主要结构,替代了原本的ResNet 编码器,并需要原图像与风格图像作为编码器的输入,以提高生成的风格向量的精度及风格多样性。此外,本文还对StarGAN v2 的生成器部分进行了改进,使生成图像不易失真。
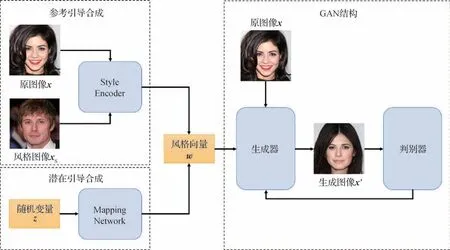
图3 网络整体结构Fig.3 Overall network structure
采用编码器的风格迁移算法通常采用两种方式获取风格向量w,一种方式为将风格图像输入编码器,从中提取出符合风格图像分布的风格向量,使用此向量进行风格迁移的过程即为参考引导合成;另一种方式为将随机变量z输入编码器,由于z是随机生成的,导致生成的风格向量w表达的特征也为随机的,使用此向量进行图像风格迁移的过程即为潜在引导合成。
参考引导合成与潜在引导合成具有不同的功能。参考引导合成通过输入原图像及风格图像,能够生成具有风格图像风格的原图像;潜在引导合成不需要输入风格图像,通过输入原图像生成具有随机风格的图像。本文采用参考引导合成、潜在引导合成的风格迁移方法如图4所示。

图4 两种风格迁移方法Fig.4 Two style transfer methods((a)reference-guided synthesis;(b)latent-guided synthesis)
设输入原图像为xo,风格图像为xs,风格向量为w,输出图像为xt,随机变量为z,则两种不同的风格迁移方法如下:
1)参考引导合成的风格迁移方法为
2)潜在引导合成的风格迁移方法为
式(1)—式(4)中,HSE为Style Encoder 模块,HMN为Mapping Network模块,G为生成器。
2.2 子网络结构
2.2.1 编码器
在GAN 网络结构前添加的编码器模块Style Encoder用于提取风格输入图像xs中的图像特征,并将此特征编码为风格向量w,输入生成器模块中实现参考引导合成。本文的Style Encoder 结构如图5所示。
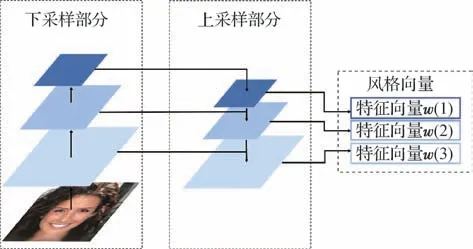
图5 Style Encoder网络结构Fig.5 Style Encoder network structure
FPN 最初应用于多尺度目标检测,其目的是通过网络重建部分产生的多个高层特征去提取目标图像中不同尺度的信息。FPN 网络结构包括一个下采样层和一个上采样层,对应层之间存在横向连接。FPN 通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。通过高层特征进行上采样和低层特征进行自顶向下的连接,而且每一层都会输出结果,重建上采样层中高层的特征图更容易提取图像的细节部分特征,而底层更容易提取出图像的全局轮廓特征。
基于FPN能够生成多层信息不同的特征图的特点,本文采用FPN 网络构造Style Encoder,通过提取FPN 网络中重建部分的特征图,生成对应不同图像细粒度的图像风格向量,并根据所得到的图像风格向量进行风格迁移操作。
FPN 网络的层数与所想得到的风格向量维度成正相关,FPN 网络层数越多,风格向量的维度也就越高,表达的信息就越丰富,但生成器生成图像的性能会变低,由于层数增加,相邻层之间信息差异缩小,导致生成的不同风格强度的图像间差异缩小。因此,本文采用6 层FPN 网络构造Style Encoder,每层上采样层中能够输出1 × 256 大小的向量,共能得到6 × 256 大小的风格向量。后续参考引导合成实验表明,生成图像在包含了更多图像风格信息的同时,不同风格强度图像间仍存在较大差异。由于采用了FPN 网络提取图像风格向量,因此这些向量也具有特征分层的特性,高层的向量包含图像的细节部分特征,而低层的向量包含图像的轮廓部分特征。由此,通过结合不同图像的风格向量并输入到生成器中,生成具有丰富多样性的风格迁移图像。
为了对输出图像的风格强度进行控制,本文的编码器输入由原来的风格图像变为同时输入原图像及风格图像,因此,通过编码器可以得到两个风格向量,分别为原图像的风格向量wo及风格图像的风格向量ws。本文将ws中的底层部分和wo中的高层部分组合,得到具有原图像轮廓特征和目标图像细节特征的新的风格向量w。同时,还可以通过调整目标图像的层数分布与数量,以调整最终结果的风格迁移强度。整体过程如图6所示。
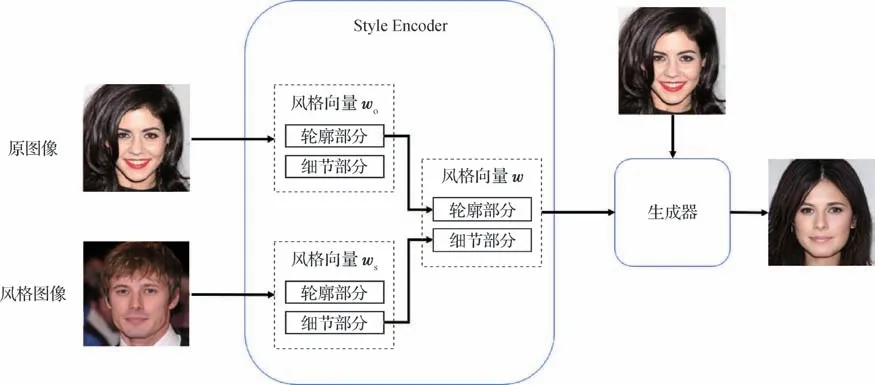
图6 风格迁移过程Fig.6 Style transfer process
在GAN 网络结构前添加的编码器模块Mapping Network 主要功能为将随机变量z转化为风格向量w,输入生成器模块中实现潜在引导合成。通过这种方法生成的风格向量具有较好的随机性,能够满足随机风格迁移的需求。本文采用的网络结构为8 层MLP 网络,在潜在引导合成实验中能够得到较好的结果。
2.2.2 GAN
生成器通过输入原图像x及风格向量w来得到具有w内含特征的图像风格迁移结果图像x′。本文生成器结构如图7所示。
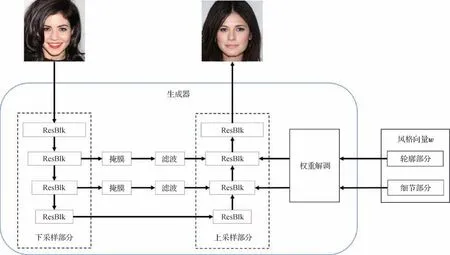
图7 生成器网络结构Fig.7 Generator structure
生成器采用了经典的图像重建网络结构,由一个下采样区域和一个上采样区域两部分组成,其中下采样区域提取输入图像的图像特征,上采样区域进行图像重建,两部分之间采取了横向连接的方式,使输入图像特征能够传递到生成图像中,确保生成图像正确。为了防止横向连接输入的信息对生成图像多样性带来影响,在横向连接中采用了掩膜(Wang 等,2019)及高通滤波器处理,使通过此横向连接的图像信息只保留图像轮廓部分。
StarGAN v2 在生成器中采用了AdaIN 模块提取风格向量w中的特征信息,计算为
式中,μ(x)和σ(x)分别表示原图像的均值与方差,μ(y)和σ(y)分别表示风格图像的均值与方差,通过AdaIN 方法使生成图像具有原图像与风格图像的特征。现有研究(Karras 等,2020)表明,使用AdaIN 模块是出现特征伪影问题的原因,如图8 所示,左侧为生成图像,右侧为放大后的特征伪影区域。因此,基于权重解调不破坏特征图关联性的优点,本文采用权重解调算法代替AdaIN 归一化算法作为风格的传输模块,该方法在保留完全可控性的同时消除了伪影。

图8 特征伪影现象Fig.8 Water droplet artifacts
AdaIN 结构可以拆分为两部分:标准化部分与调制部分。其中,标准化部分负责将输入标准化,调制部分负责将目标图像的信息通过参数的方式导入,即标准化外层的σ(y)与μ(y)部分。这种方法分别对每个特征图的均值和方差执行归一化,因此会破坏特征维度中相互关联的信息,导致生成器在生成图像时产生针对特征的局部峰值,从而产生特征伪影。权重解调算法通过去掉AdaIN 中的归一化部分,并通过卷积的方式代替,避免了对关联特征信息的破坏,从而避免特征伪影问题。在调制之前插入一层卷积,缩放卷积权重计算为
式中,si是第i个输入特征图的缩放比例。经过缩放和卷积后,输出激活的标准差为
获得标准差后,还需要对缩放后的权重进行解调,将输出特征图变为原来的单位标准差,解调部分计算为
式中,ϵ为极小量,避免分母为0。权重解调方法遵循归一化的思想,使输出的特征图有统一的分布均值和方差,在实现风格迁移的同时,避免了特征伪影的产生。
判别器Discriminator 通过输入图像x以判断此图像的真伪,并输出一个0~1 之间的值。输出越靠近1,说明图像大概率为真,反之则图像大概率为假。
本文的判别器结构为6层的ResNet组成的多任务判别器,输出有多个枝干,每个枝干对应着一个域,枝干的输出即为输入图像在这个域中的概率。因此在训练生成器时,判别器有两个输入:生成器的输出图像x与此图像应属于的域y,输出则为x属于y的概率。
2.3 损失函数
为了使生成器能够生成同时具有原图像与风格图像特征的图像,本文主要使用了以下5类损失:一般GAN 损失、风格重建损失、风格多样性损失、图像重建损失和风格强度损失。
一般GAN 损失用于规范生成器和判别器进行的博弈训练,使判别器能够更精准地分辨真实图像与生成器生成的图像,计算为
式中,D代表判别器,G代表生成器,x为输入图像,y为图像所在的风格域,z为随机变量,s为生成的风格向量。此外,本文还使用了R1 正则化(Mescheder等,2018),通过梯度惩罚来稳定训练过程并防止模式崩溃,计算为
风格重建损失要求在进行风格迁移后,得到的图像能够产生相同的风格向量,具体为
风格多样性损失要求生成的图像风格多样性尽可能高,具体为
图像重建损失要求图像经过网络两轮转换后,图像可以复原,具体为
风格强度损失为
这两个损失用于衡量生成图像与原图和目标图之间的差异。由于这两个损失互斥,若将这两个损失的加权和作为一个整体损失,能够在一定程度上保证图像风格迁移的质量,整体计算为
最后,总损失表示为
3 实验结果与分析
3.1 数据集构成
本文使用CelebA-HQ 数据集对网络进行训练,此数据集为高清人脸数据集,包含28 000 幅人脸图像。本文将CelebA-HQ 数据集拆分为男性和女性两个域,其中男性图像有10 057幅,女性图像有17 943幅。除了这两个域标签外,本文不使用任何其他的域标签。所有数据集中的图像大小均调整为256 ×256像素分辨率进行训练。
3.2 实验设置
本文实验使用python 进行编程并在NVIDIA RTX 2080Ti 上进行训练。对于CelebA-HQ 数据集,本文训练100 000轮,每轮2个batch。本文对比的基准模型为MUNIT(multimodal unsupervised image-toimage translation)(Huang 等,2018)、DRIT(diverse image-to-image translation)(Lee 等,2018)、MSGAN(mode seeking generative adversarial network)(Mao等,2019)、pix2pix、CycleGAN、StyleGAN 以及Star-GAN v2(Choi 等,2020)。所有这些模型学习的均为两个域间的多模态映射,实验条件与数据集均一致。
本文采用FID(Frechét inception distance score)(Heusel 等,2017)和LPIPS(learned perceptual image patch similarity)(Zhang 等,2018)评估生成图像的视觉质量和多样性。通过计算数据集中每对图像域的FID和LPIPS及计算其平均值,作为图像风格迁移的量化评价指标。对于所有生成模型,取200 幅生成图像并计算其平均值以进行量化评价指标对比。
3.3 潜在指导合成实验结果
潜在指导合成指不提供参考图像,通过输入随机变量引导生成器进行图像生成。通过这种方法生成的图像风格由随机变量决定,具有不确定性。本文通过Mapping Network 结构生成随机风格向量,实现潜在引导合成。输出结果如图9 所示,其中图9(a)为输入的原始图像,图9(b)为男性域下输出的随机风格迁移结果,图9(c)为女性域下输出的随机风格迁移结果。

图9 潜在引导合成生成结果图Fig.9 Latent-guided synthesis results((a)original images;(b)random male style;(c)random female style)
本文模型能够在潜在引导合成实验中生成风格差异较大且质量较高的风格迁移图像。量化指标如表1 所示。表中同时对比了几个经典图像风格迁移算法。FID 指标主要评估生成图像与原图像的相似性,此指标越小,说明与原图像越相似;LPIPS 指标主要评估生成图像的多样性,此指标越大,说明图像多样性越丰富。由于本文在构建数据集时采用了性别作为域标签,表中的FID 及LPIPS 指标为两组域标签指标的平均值。

表1 潜在引导合成实验量化指标Table 1 Latent-guided synthesis quantitative indicator
在潜在引导合成实验中,本文提出的模型能够达到更优的指标,对比原模型StarGAN v2 可以获得更优的输出结果。StarGAN v2在潜在引导合成实验中采用了AdaIN 归一化方法,这种方法在实现风格迁移后会出现特征伪影问题。而本文方法则使用了权重解调方法,减小了结果图像的失真,因此在本实验中能够取得较好的结果。此外,本文模型在算法效率方面也优于StarGAN v2,生成时间平均缩短了约8%。特征伪影消除结果如图10 所示,其中第1 行为风格图像,第2 行为本文得到的结果,第3行为StarGAN v2 网络得到的结果。

图10 特征伪影消除结果Fig.10 Remove water droplet artifacts results
3.4 参考指导合成实验结果
参考指导合成指提供目标图像,通过网络学习目标图像中的风格生成具有目标图像风格的原图像。本文通过Style Encoder 结构实现参考引导合成,输出结果如图11 所示,最左侧一列为原图像,第1 行为风格图像,后两行为风格迁移结果。可以看到,本文得到的结果不仅保留了原图像的轮廓,同时学习到了风格图像的特征。

图11 参考引导合成生成结果图Fig.11 Reference-guided synthesis results
本文实验结果与pix2pix 及CycleGAN 算法结果的量化指标比较如表2 所示。可以看出,本文提出的模型同样能达到最优指标。对比StarGAN v2,本文模型提取了更丰富、层次更多的风格向量,能够在细节层面上还原参考图像的特征。此外,Star-GAN v2 使用的Style Encoder 模块结构为ResNet 网络,对于图像细节部分的信息提取较为困难。而本文模型采用了FPN 网络较好地提取了图像的细节特征,并且对图像的特征进行分层处理,进一步提高风格迁移质量。图12 显示了本文与其他算法结果的对比情况。

表2 参考引导合成实验量化指标Table 2 Reference-guided synthesis quantitative indicator

图12 参考引导合成对比图Fig.12 Reference-guided synthesis comparison results((a)original images;(b)style images;(c)DRIT;(d)MSGAN;(e)StarGAN v2;(f)ours)
3.5 多风格强度实验结果
本文提出的模型可以通过调整Style Encoder 中的参数δ调整输出图像的风格强度,δ取值为1~6间的整数,数值越小越接近原图,越大越接近风格图,输出如图13所示。
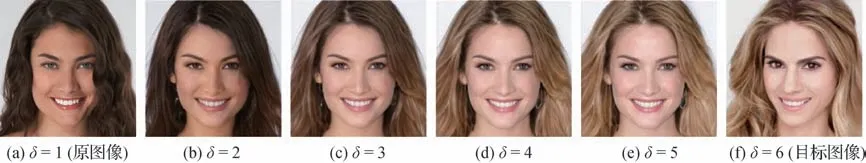
图13 多风格强度实验结果图Fig.13 Multi-style intensity test results((a)δ=1(origin);(b)δ=2;(c)δ=3;(d)δ=4;(e)δ=5;(f)δ=6(target))
由于StarGAN 等人脸风格迁移网络提取了图像的整体风格特征,忽略了局部细节特征,因此不能较好地控制输出图像的风格。这些网络中生成的风格向量为一个耦合的整体,内部的风格特征难以单独解耦。而本文使用的Style Encoder 模块所提取的风格向量具有多层结构,每一层所蕴含的风格特征各不相同。因此,通过输入不同的参数δ,Style Encoder可以将由原图像得到的风格向量wo及由目标图像得到的风格向量wt进行结合,生成不同的风格向量w,以实现对风格强度的控制。
3.6 消融实验结果
本文在参考引导合成实验中,对比了FPN网络、权重解调方法和添加风格强度损失这3 项改进对量化指标的提升,如表3所示。

表3 参考引导合成实验中的模型优化提升Table 3 Reference-guided synthesis model optimization and promotion
由表3 可知,在添加FPN 网络之后,提升了整体模型的FID 指标,这是因为FPN 网络提取的风格向量大小为6 × 256,大于原来的1 × 64,包含了更多的风格特征信息,使生成器生成的图像更偏向于风格图像,而FID 指标评估的是生成图像与原图像的相似度,因此FID 指标得以提升。通过添加风格强度损失规范原图像与风格图像之间的风格平衡,本文模型即能得到更优秀的指标。
3.7 非正常面部实验结果
本文模型对非正常面部的风格迁移结果如图14 所示。由于非正常面部图像与正常图像相比,存在不同程度的面部特征损失,且结构上具有较大差异,因此本文模型无法很好地对非正常面部图像进行风格迁移,亟待后续解决。

图14 非正常面部实验结果图Fig.14 Abnormal face test results((a)hair covering;(b)eyeglass;(c)side face)
4 结论
本文针对人脸风格迁移的问题,提出了一种能够生成不同风格强度图像的算法MStarGAN,使用FPN 构建前置编码器,采用特征分类的思想提取信息更丰富且表达特征分层的风格向量。通过对原图像及风格图像的风格向量进行不同层数的合成,可以对生成图像的风格迁移强度进行一定的控制。此外,采用权重解调算法作为生成器中风格的传输模块,能够生成细节更加丰富的结果图像。
实验结果表明,本文算法在人脸迁移算法领域中能够得到良好的量化指标。与目前主流的人脸风格迁移网络相比,本文提取到更多的局部细节特征、减小了生成图像失真并使生成图像风格可变。
尽管本文方法能够得到良好的结果,然而,对于原图像中的细节特征解耦仍存在不足,无法将单一特征独立解耦,如鼻子、眼睛等特征。此外,对于一些非正常面部图像,如戴墨镜、遮眼、侧脸等,由于非正常面部图像与正常面部图像存在较大结构性差异,本文的迁移效果不尽如人意。
在未来的工作中,考虑参考Re-GAN(史彩娟等,2021)等方法,对编码器及生成器进行优化,使网络能够解耦出更细节的特征,并考虑在判别器部分添加约束条件,对生成器生成的图像进一步优化,获得对非正常面部图像的高质量风格迁移结果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国医疗器械信息(2019年3期)2019-03-09
中国医学影像学杂志(2018年9期)2018-10-17
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
高中生学习·高三版(2016年9期)2016-05-14
中国卫生标准管理(2015年4期)2016-01-14
中国医学装备(2015年10期)2015-12-29
电子器件(2015年5期)2015-12-29
