
基于并行胶囊网络的声学场景分类*
2023-12-13 12:13杨立东赵飞焱
传感器与微系统 2023年12期
杨立东,赵飞焱
(内蒙古科技大学信息工程学院,内蒙古 包头 014010)
0 引 言
在拥有海量大数据和广泛应用云计算的人工智能(artificial intelligence,AI)时代[1],各个行业朝着网络化、智能化的方向发展,其中,计算机每天需要处理数以万计的音频数据,对所获音频数据分析和处理所涉及到的声学场景分类(acoustic scene classification,ASC)是其中不可或缺的任务[2],同时也是极具挑战性的难题。声学场景分类作为场景理解(scene understanding)的重要环节,主要任务是通过识别音频特征并将其归类到特定的环境类型[3],因为各类环境存在噪声干扰,所以声学场景分类任务很难研究出具有高精度且泛化能力强的分类器。
随着神经网络的兴起,在图像识别[4]、目标检测[5]、音视频识别[6]以及声学场景分类[2]等方向广泛应用并取得了一定的效果。其中卷积神经网络(convolutional neural network,CNN)[7]和循环神经网络(recurrent neural network,RNN)[8]是其中最具代表性的网络,CNN 可以通过卷积强化图像中的关键信息,进行特征提取,但是在提取特征时忽略了特征间的空间关系(spatial relationship)以及姿态信息(pose information);RNN是一种擅长处理和预测序列数据的网络模型,尤其是数据对时序有一定依赖性的时候,常被用于语音识别、文本分类、机器翻译、信息检索、声学场景分类等依赖时序的任务中。但是RNN却常难以训练[9],训练次数过多后,多数情况下梯度会趋向于消失,也有较少情况存在梯度爆炸的问题。
本文提出了并行胶囊网络(paralleling neural network with capsule,Caps-PNN)的声学场景分类模型,该模型由胶囊网络(capsuleNet)与双向门控循环单元(bidirectional gated recurrent unit,Bi-GRU)[10]并行组成,既可以利用CapsuleNet提取音频中CNN不能提取的姿态信息和特征间的空间信息,同时也可以利用Bi-GRU 解决传统RNN 长期依赖问题,更好地提取音频的时序性特征。
1 胶囊网络
胶囊网络是深度学习的开山鼻祖Hinton G 于2017 年提出的一种区别于CNN 和RNN 的新型神经网络[11],随之,胶囊网络也广泛用于声学领域的各项任务之中。Bae J等人首次在语音领域中应用胶囊网络代替CNN 去提取时频特征中的姿态信息和特征间的空间信息,构建了端到端的语音命令识别系统,在干净与嘈杂的数据中都取得了更好的效果[12];王金甲等人用基于注意力机制的胶囊网络进行了声学事件分类任务,在胶囊网络中加入了注意力机制,通过加权增加对重要时间帧的关注,在DCASE 2018 挑战任务5中,F1平均分数达到了92.1%[13];郑启航等人通过改进传统胶囊网络的间隔损失(margin loss)函数,使用了加性间距SoftMax函数作为目标函数,在DCASE 2018 挑战任务5中,F1平均分数达到了92.3%[14]。
胶囊网络将特征以向量的形式封装在胶囊单元中[11],替代了传统神经网络中以标量神经元作为网络输入的形式,向量的长度表示对应特征存在的概率,向量的方向表示对应特征内部的状态,特征通过动态路由机制在底层胶囊与高层胶囊之间传递。其中动态路由流程如算法1所示。
算法1动态路由算法
本文以3个胶囊单元为例,演示动态路由机制的过程,如图1所示,矩形框为一个胶囊单元,其中每个胶囊单元包含若干个向量神经元,每个向量神经元对应单个特征,一个胶囊单元就是多个特征的集合。经过多次迭代之后,如果高级胶囊层某个胶囊单元与预测向量输出较大的点积值,则此胶囊单元拥有更大的模长,所对应的类别的概率更大[15]。
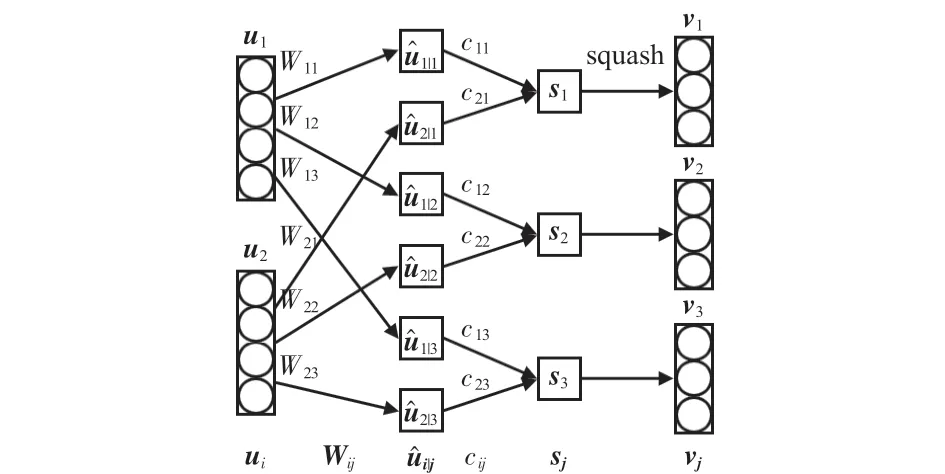
图1 动态路由示意
2 Bi-GRU
传统RNN网络在训练时序性数据容易出现长期依赖问题[9],针对上述问题,出现了长短时记忆网络(long shortterm memory,LSTM)[16],其中LSTM由输入门、遗忘门和输出门3个门组成,引入了记忆单元和门控记忆单元保存信息的历史状态和长期依赖,并使用门控机制控制信息的传输。门控循环单元(gated recurrent unit,GRU)[17]是LSTM的一种简化结构变体,收敛速度更快、训练时间更短,它由更新门和重置门组成,其结构如图2所示。

图2 GRU单元结构
其中,更新门z决定前面记忆单元信息保存到当前时间步的量,重置门r决定如何将前面记忆单元信息与新输入信息相结合。第t个隐含层单元重置门rt和更新门zt计算公式如下
重置门隐含状态˜ht计算公式如式(4)
更新门隐含状态ht计算公式如式(5)
式中 σ为Sigmoid激活函数,xt为t时刻的输入,ht-1为t时刻之前隐含层单元状态,⊙为同或运算,W和U分别为不同的权值矩阵,随着训练着更新,训练结束之后确定。
在GRU网络中,传输状态为单向传播[17]。双向GRU由2个单向的GRU 组成,能在2 个方向上学习上下文信息,不仅可有效地解决传统RNN 的长期依赖问题,提高模型的表现力,而且还可以更好地拟合音频信号的长期时间模型[18]。Bi-GRU结构示意如图3 所示,在每个t时刻,输入、输出都由2个正反方向的GRU共同决定。
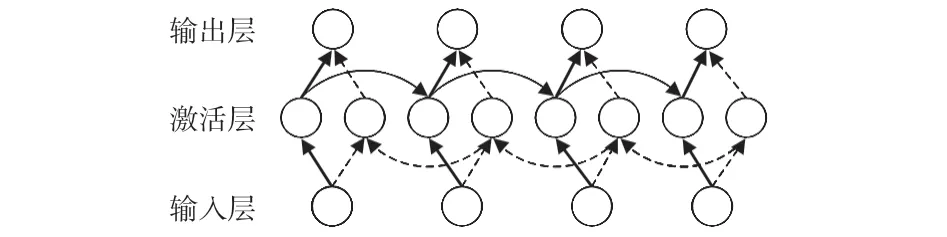
图3 Bi-GRU结构示意
3 并行胶囊网络模型
本文运用了基于并行胶囊网络的网络模型完成音频分类任务,网络模型框架如图4所示。
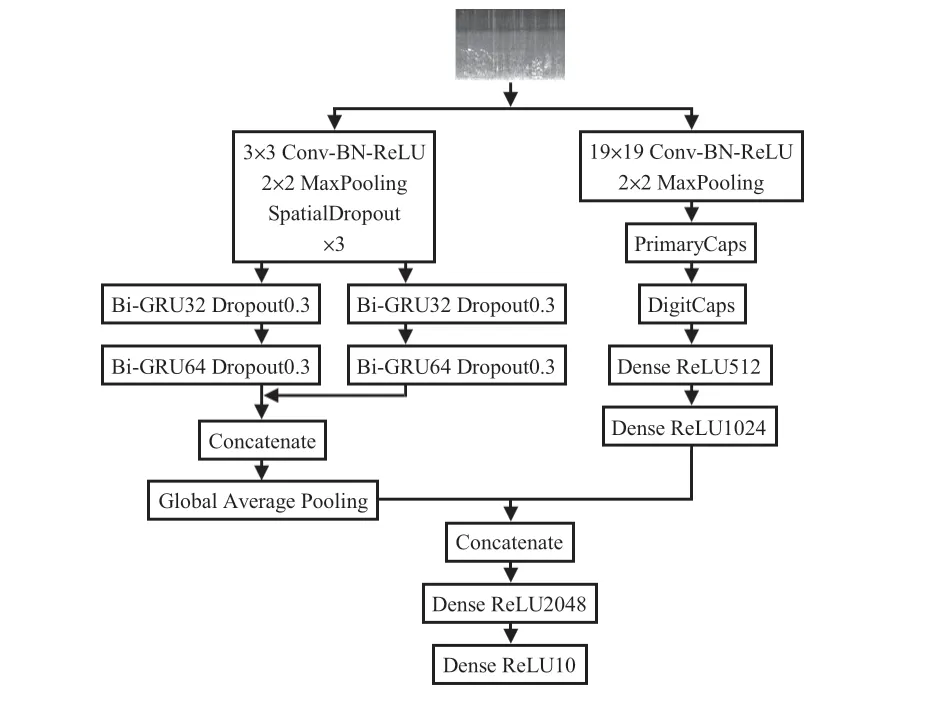
图4 并行胶囊网络模型框架
网络模型主体是Bi-GRU 与胶囊网络并行的基本架构。左侧为Bi-GRU架构,首先,将提取的对数梅尔能量谱特征输入到网络中;其次,利用CNN将音频特征进行处理,初步提取音频的低级特征;然后,经过2 组并行的Bi-GRU框架提取音频的时序性特征,为防止网络过拟合和提升网络的泛化能力,同时加入了正则化以及批标准化机制。右侧为胶囊网络架构,其具体结构如图5 所示,首先,通过卷积提取音频的低级特征并传输到主胶囊层(primarycaps layer),将音频特征封装到胶囊单元中,生成特征的组合;其次,通过数字胶囊层(digitcaps layer)存储高级别的特征向量;然后,输出到不同的胶囊单元;最后,经过Concatenate函数将左侧Bi-GRU 架构与胶囊网络架构相连接,再通过全连接层完成分类。

图5 胶囊网络分支
4 实验与分析
4.1 数据集及实验环境
本文采用了DCASE 2019[19]挑战任务1 中的数据集,它包含十类音频场景:飞机场(airport)、乘坐巴士(bus)、乘坐地铁(metro)、地铁站(metro station)、城市公园(park)、公共广场(public square)、室内购物广场(shopping mall)、中等车流量的街道(traffic street)、步行街(pedestrian street)、乘坐电车(tram),其中音频录制于欧洲主要的12 个城市(Amsterdam、Barcelona、Helsinki、Lisbon、London、Lyon、Madrid、Milan、Prague、Paris、Stockholm、Vienna),总时长约40 h,包含14 440个片段(每类声学场景包含1 440 个音频片段),本文实验随机选取12 446 个音频片段作为训练集、516个音频片段作为开发集、1 478个音频片段作为验证集。
实验在Ubuntu18.04系统上,选用框架为Tensorflow深度学习框架,版本为Tensorflow-GPU1. 6,Python 版本为2.7.12,用2块Tesla V100 显卡训练网络模型,Epoch 设定为150个,Batch size设定为128,采用了Adam优化器,初始学习率设定为0.001。
4.2 数据预处理
数据集中音频格式为. wav 文件,时长10 s,采样率为48 000 Hz,本文实验对实验音频进行下采样,采样频率为44 100 Hz,并选取音频的对数梅尔能量谱作为提取特征,首先,将音频分帧,帧长为46 ms,帧移为23 ms,将一段音频(10 s)划分为434 帧,并对每帧信号使用汉宁窗函数进行加窗;其次,再通过短时傅里叶变换生成声谱图;最后,使用包含40个三角形滤波器的梅尔滤波器组滤波,并进行对数运算,获得对数梅尔能量谱。其中,各个场景的对数梅尔能量谱图如图6所示。
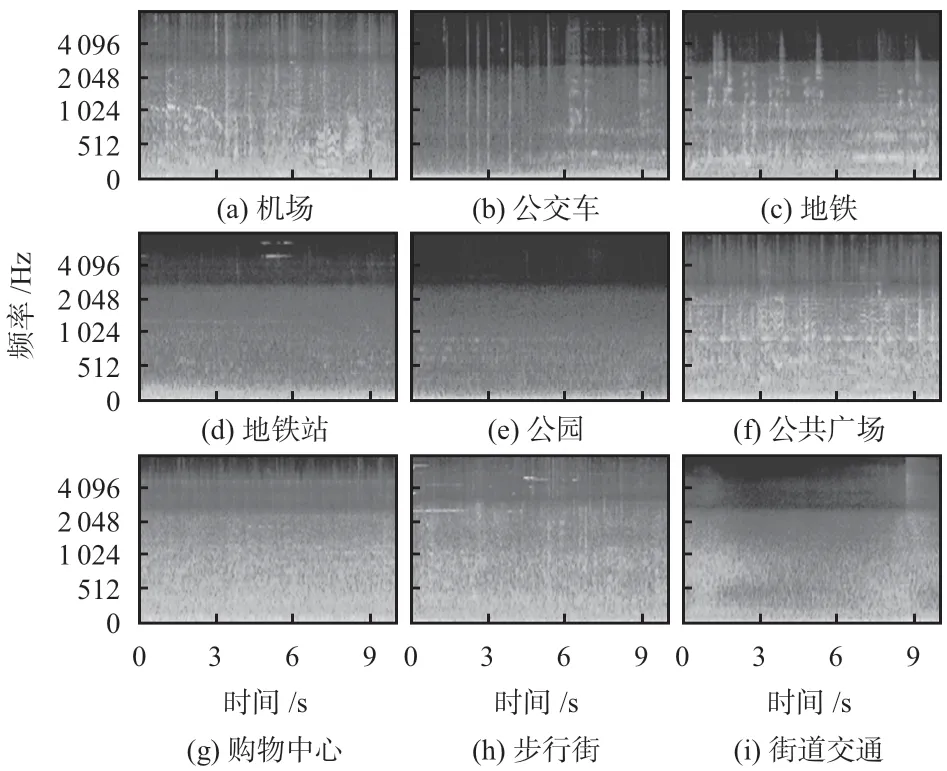
图6 各类场景对应的对数梅尔能量谱图
4.3 基线系统
基线(baseline)系统[16]应用CNN 完成分类任务。首先经过2层卷积层(其中包含批标准化层、最大池化层和Dropout层)提取音频特征,然后进行扁平化处理,最后经过全连接层完成分类。基线系统选用了音频的对数梅尔能量谱特征,特征数设为40,帧长为40 ms,帧移为20 ms。优化器采用Adam 优化器,初始学习率为0. 001。Epoch 为200个,Batch size设定为16。
4.4 实验与结果
为了验证本文网络模型中的各部分所起作用,设计多组对比实验进行比较,同时与RW-CNN[20]和CNN9-AVG[21]网络模型进行对比。
本文实验采用准确率(accuracy)作为评估方法,计算方法如式(6)所示
式中 TP(true positive)为实际分类正确与预测正确的标签数量,FP(false positive)为预测标签中分类错误的标签数量,FN(false negative)为实际分类标签中分类错误的标签数量。
在计算验证集的准确率(Val_acc)时,本文综合考虑模型的泛化能力,将不同城市的不同音频场景随机划分,测试准确率时看不见音频所属城市(unseen cities)。
各网络模型性能如表1所示。1)基线系统在开发集上的准确率比测试集上的准确率高16.4%,说明基线网络模型不具备很好的泛化能力;2)使用CapsuleNet时,开发集准确率远低基线系统,说明虽然CapsuleNet 具备捕获音频姿态信息和特征间空间信息的能力,但处理音频局部特征的能力弱于CNN;3)为了验证Bi-GRU架构所起的作用,使用了CNN +Bi-GRU的网络结构,首先通过CNN 提取音频的低级特征,其次输入到Bi-GRU,提取音频的时序性特征,在开发集上和验证集上分别取得了70.5%和68.2%的准确率,表明时序性特征在声学场景分类任务中起着重要作用;4)为了验证胶囊网络架构所起的作用,使用本文所提出的并行胶囊网络模型CNN +Bi-GRU +CapsuleNet,在开发集和验证集分别获得了71.1%和70.2%的准确率,比基线方法分别提升了8.6%和24.1%,说明通过CNN模型提取音频的低级特征信息,输入到胶囊网络提取音频的姿态信息和特征间的空间信息,外加Bi-GRU 架构提取音频的时序性特征适用于声学场景分类任务,并且具有很好的泛化能力。

表1 各网络模型性能
在胶囊网络中,主胶囊层输入向量维度(CapsinputVec)和数字胶囊层输出向量维度(Caps-outputVec)是胶囊网络中2 个重要的超参数[22],影响着网络模型的性能,于是在本文实验CNN +Bi-GRU +CapsuleNet 的网络模型下进一步探究了二者对网络性能的影响,Caps-inputVec和Caps-outputVec对网络性能的影响如表2所示。

表2 Caps-inputVec和Caps-outputVec对网络性能的影响
由表2可知,输入向量维度和输出向量维度的取值对网络模型性能影响很大,且不呈现一定的规律性,当输入向量维度为4、输出向量维度为16 时,CNN +Bi-GRU +CapsuleNet的网络模型性能最佳,且具有较好的泛化能力。
5 结束语
本文提出了一种基于并行胶囊网络模型用于复杂声学场景分类任务,针对CNN 提取音频时序特征困难,提出使用Bi-GRU架构捕获音频上下文联系;针对传统神经网络忽略音频中姿态信息和特征间空间信息,提出使用胶囊网络处理每个音频帧;针对传统神经网络中低级特征和高级特征联系缺失,提出使用动态路由机制强化特征之间的联系,同时结合了CNN、Bi-GRU和胶囊网络各自的优点。通过实验,在开发集和验证集准确率分别高达71. 1 %和70.2%,性能明显优于其他网络模型,证明了并行胶囊网络模型适用于复杂声学场景分类任务。
猜你喜欢
家庭影院技术(2020年6期)2020-07-27
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
家庭影院技术(2018年10期)2018-11-02
电子制作(2017年9期)2017-04-17
人间(2015年8期)2016-01-09
