
基于深度学习的贝类海产品分割算法*
2023-12-09 08:50孙小龙
计算机与数字工程 2023年9期
孙小龙 潘 丰
(江南大学轻工过程先进控制教育部重点实验室 无锡 214122)
1 引言
中国不仅是一个海洋大国,更是一个海产养殖大国,2020 年,全国海产品总产量为3082.72 万吨,其中贝类海产品总产量为1516.27 万吨,占比49.19%[1]。丰富的海产品为人们的餐桌提供更多选择之余,也为渔民带来了致富之路。现在,每天都有数量庞大的海产品送往国内外各地的市场。贝类海产品的等级分选能够直接影响着贝类海产品的销售价格,按照规格大小分级进行出售能够明显提高售价,带来更高利润,因此高效、高精度的对贝类海产品进行等级分选显得尤为重要。
传统的贝类海产品等级分选方法为人工分选,即依赖人的眼睛看,手工称重的方法进行分级,这种分级方式的缺点明显,分级速度慢、精度低,同时耗费大量的人力,不利于生产的自动化。称重分级设备出现,很大程度上提升了贝类海产品等级分选的精度和效率,但是这种分级方法的决定要素只有重量,当水产表面附着冰水混合物时会对分级的精度造成一定的影响。同时具有称重和视觉检测功能的新一代分级设备具有更好的精度,然而在视觉检测部分,仍然存在着许多不足,如精度低,速度慢,泛化性差等缺点[2],而良好的图像分割算法有利于对产品的外观和尺寸等进行检测。
近些年来,深度学习在图像处理领域迅速发展,Berkeley 团队提出图像分割算法FCN(Fully Convolutional Networks)[3],使用卷积层替代全连接层,可以使用任意大小的图像作为网络的输入,取得了不错的效果。Ronneberger 等提出的U-Net 网络[4],给出了一个具体的编码器-解码器网络结构,编码器用于特征提取,解码器恢复目标的细节和相应的空间维度。王井东等提出的HRNet[5],与其它网络不同的是,特征提取部分使用了不同分辨率的特征图并联,同时保留着高分辨率和低分辨率的特征,在并联的基础上,添加不同分辨率特征图之间的信息交互,得到了非常好的效果。
本文提出了一种编/解码模式的贝类海产品分割算法,受到HRNet 网络和ShuffleNet 网络[6]的启发,编码模块采用并联双分支网络结构,来减少空间细节的损失,获得多尺度特征,使用带有深度卷积的残差模块作为基础层,提升网络的运行速度,同时添加注意力机制,产生更具分辨性的特征表示,提高分割的精度;使用多任务分割分类解码器代替多分类分割解码器,避免一个目标中出现多个类别的分割结果;在分割解码器部分,融合多尺度的特征,提高对不同大小目标的表示能力,同时保留图像的空间细节和深层语义特征;添加一个分类解码器,获得目标的具体类别。
本文提出的编码-解码模式的贝类海产品分割算法如图1所示,输入的是工业相机采集的RGB图像,输出的是一个二值化图像和当前图像的类别。
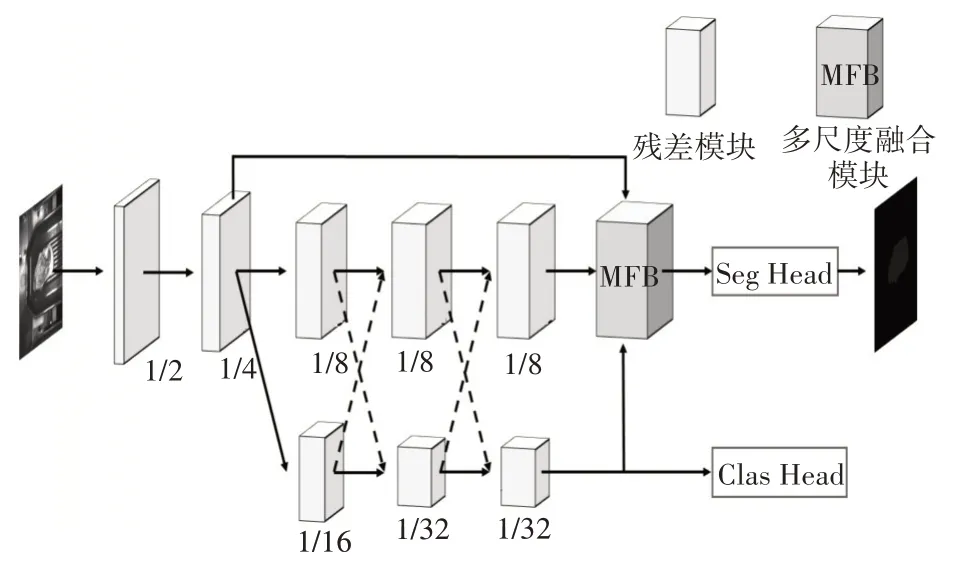
图1 网络结构图
2 本文算法原理
2.1 网络模型
本文提出一种编/解码模式的贝类海产品分割算法,主要包含三个部分:编码模块,分割解码模块和分类解码模块。网络结构如图1所示。
编码模块:在贝类海产品图像中,需要分割的目标尺寸差异大,具有不同的尺度,并且目标边缘不规则。在传统的图像分割领域,为了解决多尺度下的目标分割问题,获得图像的多尺度信息,通常会进行一系列的下采样操作,如UNet,但是随着网络深度的增加,图像的空间细节会逐渐损失,常见的方法,如VNet 网络[7],采用跳级连接来恢复解码器模块中的图像细节,进一步加强不同深度语义信息的融合。然而,由于较深的编码器模块缺乏低层语义特征和空间信息,因此无法很好地对贝类海产品的边缘结构进行判断。为了改善这个问题,本文采用并联双分支网络结构,同时使用两种不同分辨率的特征图分支,同时保留高层和低层语义特征,为了更进一步进行不同尺度信息之间的交互,并联分支之间通过上采样和下采样操作进行了两次特征交互融合。由于高分辨率特征(低层特征)会给网络的实时性带来不利影响,本文设计了一种带有通道分离和混洗的残差模块,主要由深度卷积、普通卷积和注意力模块组成,可以显著提升网络运行速度,如图2所示。
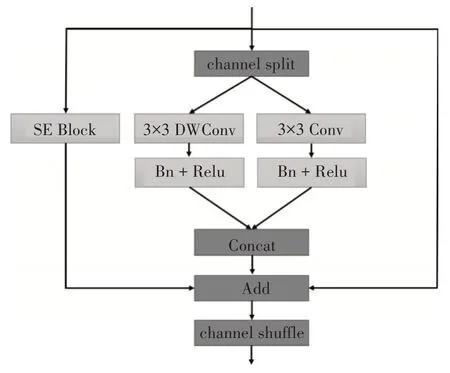
图2 残差模块
残差模块:由三条分支构成,第一条分支为SE(Sequeeze-Excitation)模块[8],解决卷积过程中特征层的不同通道所占的重要性不同带来的损失问题,这里使用的是SE 模块的一种变体,首先对输入的每个通道进行全局平均池化操作,然后使用一个具有非线性的全连接层,最后使用一个Sigmoid 激活函数生成通道权值,相比于原始的SE 模块,具有更少的参数量和更优的效果。
第二条分支为主分支,模块的输入首先经过一个通道分离操作,将原始输入按照通道数分为两组,这样将卷积运算限制在每个组内,能够显著地降低模型的计算量,同时,因为基础模块的输出通道数是输入通道数的两倍,当输入通道数和输出通道数的值接近1∶1 时,能减少内存访问成本,所以这里的通道分离操作既能够减少计算量,又能够降低内存访问成本。当输入经过通道分离操作分成两组后,其中一组输入到一个3×3 的深度卷积,另一组输入到一个3×3 的普通卷积,同时在每一个卷积后面都加上批归一化层(Batch Normalization,BN)和ReLU 激活函数,深度卷积能够降低参数量,但缺少通道间的信息交互,普通卷积参数量较大,通道间有着信息交流,两者组合在一起,在参数量和信息交互中做了平衡,然后将两组输出按照通道顺序上连接在一起。第三条分支为跳跃连接[9],在这里可以解决网络层数较深的情况下梯度消失的问题,同时有助于梯度的反向传播,加快训练过程。最后,将三个分支的输出叠加起来。由于通道分离操作使得模型的信息交互限制在了各个组内,组与组之间缺少有效的信息交互,这会影响模型的表示能力,因此在最后添加一个通道混洗操作,进行组间信息的交换。
下采样模块:当特征图的大小变为原来的1/2时,都会串联一个下采样模块,下采样模块由两个部分组成,分别是最大池化层和步长为2 的3×3 卷积层,并将它们的输出叠加后串联批归一化层和Relu激活函数。其结构如图3所示。
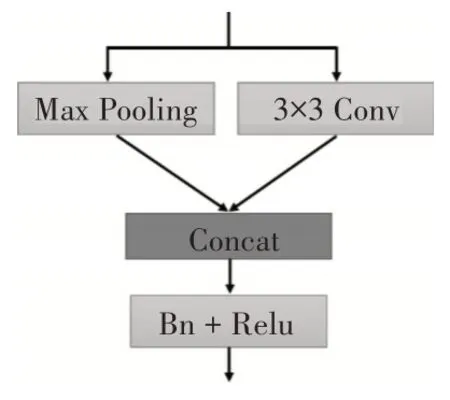
图3 下采样模块
由于从分选现场采集的贝类海产品图像中,每张图像中只包含一个贝类海产品,为了提高分割的准确率,使用多任务分割分类解码器代替了传统的多分类分割解码器,这样可以保证同一图像中只得到同一类贝类海产品的分割结果;解码模块分成两个部分,一个部分为分割解码模块,其输出为一个二值化图像,通过识别每个像素点是前景还是背景来预测出目标的位置和尺寸;另一个部分为分类解码模块,其输出值为当前图像中贝类海产品的类别。
分割解码模块:下采样倍数小的特征层感受野较小,特征图较大,保存的贝类海产品的空间细节较多,对贝类海产品的边缘细节的还原较好,同时对于尺寸较小的贝类海产品更加友好。下采样倍数较大的特征层感受野大,语义信息表征能力强,能够使网络更准确的分割出贝类海产品。所以为了获得更好的表征能力,进行了多尺度融合的操作,具体而言,对32 倍下采样的特征图进行上采样操作,变换为尺度与8 倍下采样的特征图相同的尺度,并添加3×3卷积、批归一化和Relu激活函数,与8 倍下采样的特征图进行通道方向的连接,进行同样的操作变换到4 倍下采样的特征图,就完成了多尺度融合的操作。最后再添加3×3 卷积和上采样的分割头部,就得到了与原图大小一致的特征图。
分类解码模块:用于分类任务的卷积神经网络,网络末端通常是几层的全连接层,这是因为普通卷积层的特性是局部连接和权值共享,它的特征提取过程是局部的,对位置不敏感的,对于分类任务,不仅需要考虑输入图像中的各个元素,还需要考虑它们之间的关联关系。而全连接层的每个输出分量都与所有的输入分量相连,并且连接权重都是不相同的,但是全连接层存在着参数量大,计算速度慢的缺点。全局平均池化[10]同样可以提取全局信息,并且有着参数量和计算量低的优点,同时可以知道特征图上哪个部分对最后的分类贡献最大。所以分类解码模块由全局平均池化层构成,在编码层的并联结构的低分辨率分支后,连接一个1×1 卷积层、批归一化层和Relu 激活函数,再连接一个最大池化层,得到最后的分类输出,得到当前图像中的贝类海产品的类别。
2.2 损失函数
本文提出的算法是多任务模型,共有分割和分类两个任务输出,故算法训练的损失函数需要同时考虑分割和分类,总的损失函数定义如下:
其中Lclas为分类输出的损失函数,Lseg为分割部分的损失函数,β为分类损失和分割损失在总损失函数中的权重参数,这里取0.7。
分类部分的损失函数使用的是交叉熵损失,其公式定义如下:
其中,pi为样本标签,qi为预测输出。
分割部分的输出是基于像素点的二分类,由于最终需要的结果是需要分割出目标的区域,而Dice损失函数正是基于区域的损失函数,这与我们的真实目标最大化IoU 度量相近,而且Dice 能够优化样本不均衡问题,所以选择Dice损失函数作为分割部分的损失函数,其定义如下:
其中,q代表真实值,p代表网络的预测值,v代表每个图像块的体素点的个数。
3 实验结果与分析
3.1 实验数据集
本文的数据集来自分选现场采集的真实数据,共有900 张由工业相机采集的现场图像,尺寸为640×480,包含三类贝类海产品:生蚝、鲍鱼和海螺,每类有300张图像。训练集、测试集随机划分为8:2,即训练集含有720张图像,测试集有180张图像。
为了提高分割和分类的精度,同时提高模型的泛化性能,本文对数据进行了数据增广操作:第一,考虑到图像的多尺度变化,采用了随机缩放裁剪的操作,具体来说,先利用随机数生成函数随机生成一个0.5~1.5 之间实数f,再将图像缩放到原来的f倍,最后再随机裁剪出一个640×480 的图像用于训练。第二,为了增强数据的多样性,对图像采用了随机左右翻转、随机亮度对比度变化和随机旋转一定角度的方法。第三,为了加速网络的收敛,对输入图像进行归一化和标准化,归一化将图像归一化到[0,1]区间内,标准化通过计算数据集的均值和方差,对所有像素点进行标准化。
3.2 参数设置
实验中,所有网络均使用Kaiming 初始化[11]的方法对网络的权重进行初始化,使用SGD 优化器,其参数为momentum=0.9,decay=1e-5,学习率使用的warm up和指数衰减策略,其基础学习率为0.01,warm up 阶段的epoch 设置为5,训练的batch size 取16,epoch取72。
3.3 评价指标
为了定量地评估本文算法的性能,本文选用平均交并比(mean Intersection over Union,mIoU)作为分割精度评价指标,其定义如下。
其中,pii表示真实值为i、预测值为i的像素点数量,pij表示真实值为i、被预测为j的像素点数量,pji表示真实值为j、预测值为i的像素点数量,k+1 是类别个数,包含背景类。当mIoU接近1时候,预测值越逼近真实值。
分类效果评价指标为F1 score,其定义如下:
其中,TP(true positive)为真阳性,FP(false positive)表示假阳性,FN(false negative)表示假阴性。
推理速度评价指标为FPS,定义如下:
其中Time为单张图片的推理时间。
3.4 实验结果
3.4.1 数据增广对实验结果的影响
本文对未进行数据增广的数据集和进行过数据增广的数据集分别采用本文提出的网络进行训练,进行相同的训练批次后,结果如表1所示。
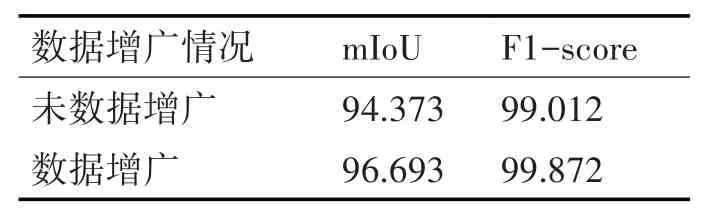
表1 不同数据增广实验结果对比
从实验的结果来看,经过数据增广的分割精度明显高于未经过数据增广的分割精度。本文的数据增广操作,由于添加的随机缩放裁剪的操作,在一定程度上可以增强对小样本的分割能力,同时增加样本多样性,增强泛化性,提高实验精度。海产品图像测试集部分分割结果如图4所示。

图4 分割结果对比
3.4.2 分割部分不同loss对实验结果的影响
由于实验数据集的目标尺寸差异较大,前景背景的占比不平衡,会使得模型的训练困难。常用的交叉熵损失函数有着一个明显的缺陷,对于只分割前景和背景时,当前景像素的数量远远小于背景像素的数量时,损失函数中的背景像素值占据主导作用,导致模型严重偏向于背景,导致效果不好。为了证明本文选择的Dice损失函数在当前数据集中能够有效提升分割效果,本文分别使用交叉熵损失函数和Dice损失函数进行模型训练,结果如表2所示。

表2 不同损失函数实验结果对比
由实验结果来看,使用Dice损失函数可以有效地提升分割精度,主要原因是因为Dice损失函数是基于区域的损失函数,这与最大化IoU 度量的目标相近,而且Dice能够优化样本不均衡问题。
3.4.3 分割部分不同算法对比结果
为了验证本文所提出算法的性能,使用已有的实时分割算法与本文的分割输出部分进行比较,算法对比结果如表3所示。
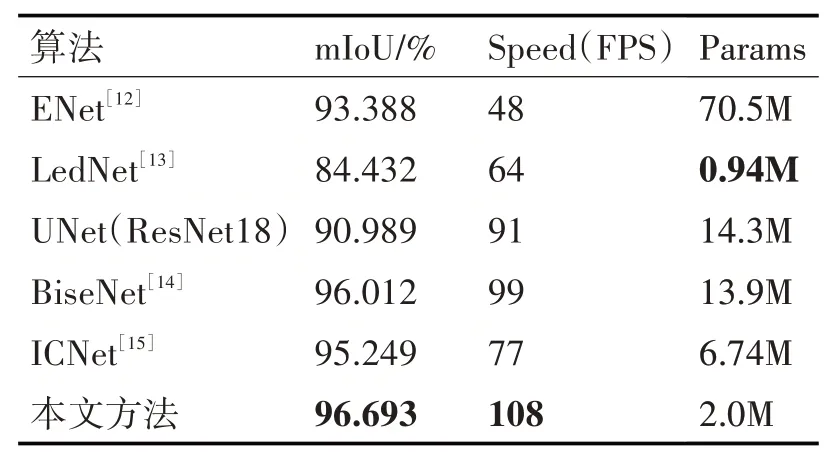
表3 不同分割算法的比较
对比发现,在当前场景中,本文提出的方法在mIoU 和FPS 指标上都不同程度的优于其它算法,分别达到96.693%,108FPS。这说明本文提出的算法适用于贝类海产品分割,模型的运行速度快,适用于算法的工业落地。
4 结语
本文建立了贝类海产品分割的数据集,提出了一种编/解码模式的轻量型贝类海产品分割算法。一方面在编码模块采用并联双分支结构,增强网络的深层语义特征表示能力和空间细节特征表示能力;另一方面,使用通道分离混洗模块和深度分离卷积减少模型的参数量和计算量,提升网络的推理速度;最后通过多尺度融合,充分提取上下文多尺度信息。实验结果表明,本文方法能够有效地提取贝类海产品的目标区域,分割效果好,推理速度快。
猜你喜欢
海洋通报(2022年5期)2022-11-30
数学小灵通·3-4年级(2021年5期)2021-07-16
理化检验-化学分册(2020年5期)2020-06-15
食品与生活(2019年8期)2019-10-30
今日农业(2019年15期)2019-01-03
WTO经济导刊(2016年12期)2017-01-06
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
——以青岛市为例
海洋经济(2014年4期)2014-02-25
食品科学(2013年22期)2013-03-11
