
融合先验信息和特征约束的杆塔螺栓缺陷检测
2023-11-22 01:19阎光伟周香君焦润海何慧
中国图象图形学报 2023年11期
阎光伟,周香君,焦润海,何慧
华北电力大学控制与计算机工程学院,北京 100096
0 引言
螺栓作为紧固件在电力杆塔中起着连接、固定关键部件的作用(赵振兵 等,2020)。恶劣环境(如冰雹、酸雨和大风)、机械振动和材料老化等因素会导致螺栓的开口销脱落或脱出,影响输电线路上其他部件的正常运行(曾勇斌 等,2020)。为了保证电力系统的不间断运行,螺栓状态的监测、检测和维护发挥着至关重要的作用。过去几十年,电网公司采用了多种检查方法,包括徒步巡逻、直升机和攀爬机器人。无人机巡检因其便捷、安全及成本较低的特点被电力部门广泛采用。但航拍巡检图像数量庞大且价值密度低,依靠审核人员对海量巡检数据进行检查的方式效率低下。因此,基于计算机视觉技术的电力智能巡检开始兴起,并取得了一定的研究进展(赵振兵 等,2021)。
输电杆塔上存在带销和不带销螺栓,二者仅靠销钉或销孔这种细微特征区分。当天气环境和无人机拍摄角度不佳时,不同类螺栓的视觉形态相似。无人机在不同角度拍摄时,螺栓的三维结构会产生不同的二维视觉信息,这使得航拍图像中同类螺栓的视觉表现不一致(Toth 和Gilpin-Jackson,2010)。此外,光照和遮挡也使螺栓呈现多种形态。图1 展示了螺栓数据集中存在的类内多样性和类间相似性问题,这对螺栓缺陷检测造成很大的干扰。

图1 类内多样性和类间相似性Fig.1 Intra-class diversity and inter-class similarity((a)diversity within class of normal bolts;(b)diversity within class of defective bolts;(c)similarity between classes of defective bolts and bolts without pins;(d)similarity between classes of defective bolts and normal bolts)
研究人员一直在研究快速、准确的螺栓缺陷检测方法。早期研究大都基于传统图像处理算法。徐丹等人(2017)和冯敏等人(2018)分别提取螺栓的方向梯度直方图和局部二值模式后使用支持向量机分类。这种基于人工设计特征的缺陷检测方法难以提取到小尺寸螺栓的有效特征,无法真正应用于复杂的电力巡检场景(赵振兵 等,2021)。
自从卷积神经网络在图像分类任务中取得突破性成功,许多基于卷积神经网络的目标检测方法被提出,如两阶段R-CNN(regions with convolutional neural network)系 列(Girshick 等,2014;Girshick,2015;Ren 等,2017)和一阶段SSD(single shot multibox detector)(Liu 等,2016)以及YOLO(you only look once)系 列(Redmon 等,2016;Redmon 和Farhadi,2017,2018;Bochkovskiy 等,2020;Jocher 等,2021)。这些方法在通用目标检测数据集上表现良好,因此研究人员开始使用上述算法识别电力巡检数据集中的螺栓缺陷。Jiao 等人(2021)在Faster R-CNN 的基础上引入残差单元和多尺度特征金字塔以弥补小尺寸螺栓因下采样信息丢失严重的问题。戚银城等人(2021)提出一种双注意力机制方法,分别对不同尺度和不同位置的视觉特征进行分析和增强,增大螺栓与背景的特征差异程度。李雪峰等人(2021)针对带销螺栓设计了PinFPN(pin feature pyramid network)网络,加强对低层语义信息和位置信息的提取能力。赵文清和徐敏夫(2022b)以SSD 模型为基础,加入隔级交叉特征金字塔结构,增强特征图的视觉信息和语义信息。赵文清等人(2022a)在YOLOv5s(YOLOv5 small)的基础上嵌入CA(coordinate attention)注意力模块,并新增一条“自顶向下”特征信息传递路径,增强对螺栓特征信息的学习能力。
以上方法重点针对螺栓物理体积小、特征语义信息不强以及背景复杂等问题进行算法设计,对螺栓存在的类内多样性和类间相似性问题关注较少。Zhao 等人(2020)通过对螺栓视觉形状聚类来构造关系树,以减少类内数据差异过大而形成的数据矛盾对神经网络学习的误导。但关系树对数据质量和标注质量要求较高,也未考虑类间相似性对模型的影响。
同类螺栓间视觉形态的差异性和不同类螺栓间视觉形态的相似性会加大模型的分类难度,从而影响目标的识别精度。针对这个问题,本文设计了一种基于密度空间聚类(density-based spatial clustering of applications with noise,DBSCAN)(Ester 等,1996)的数据预处理方法,能够将不同类螺栓安装在不同位置的先验信息引入模型,以此来辅助模型分类。在模型训练阶段,通过为Faster R-CNN 模型引入并学习费舍尔判别层(Fisher discriminant layer,FD),实现视觉特征的类内相聚和类间相离;然后利用K 近邻学习区分简单和困难样本,并依据近邻概率调整难易样本对分类损失的贡献,以引导检测模型重点关注难例。
1 研究方法
图2 展示了基于Faster R-CNN 模型构建的螺栓缺陷检测模型的整体训练流程。在数据预处理阶段,利用DBSCAN 算法对巡检图像进行预裁剪来获取感兴趣区域。预裁剪可以减少模型后续处理的数据量,获得螺栓所在的结构区域信息和抑制复杂背景对模型的干扰。本文对Faster R-CNN 模型结构进行微调,在第2 个全连接层(full connection layer,FC2)后添加一个新的全连接层FD 层。在训练阶段,首先通过对FD层的输出特征施加费舍尔约束训练该层,使其输出特征类内距离小、类间间隔大;然后使用K近邻算法对FD 层的样本特征进行处理,获得K近邻概率,并根据K近邻概率设计调节因子w缩放样本的交叉熵分类损失,引导检测模型重点关注难例。

图2 模型训练流程Fig.2 Process of model training
1.1 聚类裁剪
航拍巡检图像尺寸大,螺栓尺寸小。受计算资源的限制,检测模型训练时会将航拍图像调整到较小的尺寸。这导致原本就不多的螺栓像素信息丢失,使螺栓缺陷检测模型难以提取到有效特征进行学习和训练。
为了解决这个问题,目前常用的解决方案是将原始巡检图像均匀裁剪成多个子图,然后使用这些子图训练模型。均匀裁剪过程如图3 所示,在原始图像上从左到右、从上到下依次裁剪固定大小的子图。虽然这缓解了分辨率的挑战,但这种无差别的预裁剪方法不仅产生大量子图,造成计算资源的浪费,而且破坏了螺栓的区域结构信息。

图3 聚类裁剪和均匀裁剪Fig.3 Cluster cropping and uniform cropping
在电力杆塔上,带销和不带销螺栓被安装在不同的位置。带销螺栓通常安装于三角挂板、绝缘子串连接处。为了将这一先验信息引入检测模型,利用基于密度的空间聚类算法准确提取螺栓出现的上下文区域,然后模型在此区域上做进一步识别。这种预裁剪方法不仅可以减少模型后续处理的数据量,而且能够帮助模型隐式建模螺栓安装的位置信息,关注重点区域,提高模型的分类能力。
1.2 改进的费舍尔损失
由于拍摄角度、光照强度及遮挡等原因导致航拍图像中同一类别的螺栓视觉形态多样,类内差异大;而各类别螺栓之间仅靠销或销孔这种细微特征区分,类间视觉差异不明显。为了减少类内多样性和类间相似性对样本分类的影响,如图2 所示,本文在Faster R-CNN 模型的FC2 层后添加一个全连接层,称为费舍尔判别层。通过对其输出特征施加费舍尔约束来学习一个合适的空间变换,使其输出特征类内分散小,类间分隔大。
χFD=表示FD 层输出的样本特征,其中,c表示样本所属类别(包括背景类)表示第i类样本特征集合。除了最小化交叉熵分类损失ℓcls和回归损失ℓreg,费舍尔判别网络还要优化对χFD施加的费舍尔损失ℓFisher,表示为
借鉴费舍尔判别分析的思想,费舍尔损失ℓFisher可以通过最小化χFD的类内散度Sw和最大化χFD的类间散度Sb实现。Sw和Sb定义为
式中,C表示样本类别数,ni表示第i类目标的样本数,mi和m分别为和χFD的特征均值,具体为
式中,n表示χFD中的样本数量。
与Cheng 等人(2016)的方法不同,本文定义费舍尔损失ℓFisher为
式中,tr(·)表示矩阵的迹。
t-SNE 降维算 法(Van Der Maaten 和Hinton,2008)可以使降维后的特征保持高维空间中的分布,即在高维空间距离近的特征降维之后也很近;在高维空间距离远的特征降维之后也很远。为了观察改进的费舍尔损失对样本特征的约束效果,本文使用t-SNE算法对特征进行降维可视化,如图4所示。图4(a)是基线模型(未使用改进的费舍尔损失)中FC2层的特征降维后的结果,图4(b)是FD层的特征降维后的结果。从两幅图的对比中可以明显看出,改进的费舍尔损失可以使特征的类内距离较小、类间间隔较大。

图4 特征降维可视化Fig.4 Visualizing dimensionality reduction features((a)without Fisher loss;(b)with Fisher loss)
1.3 基于K近邻的难例挖掘
从图4(b)可以看出,样本特征整体呈现出类内相聚和类间相离的特点,但仍有一些特征处于类别交界处,较难区分。受Focal loss(Lin 等,2017b)和K近邻用于小样本学习(Wang等,2019)、图像分类(Jia等,2021)的启发,本文提出使用K近邻学习识别这些难例,并引导模型关注它们。如图2 所示,可分为以下4个步骤(沿用1.2节中的符号描述):
1)寻找K近邻。首先计算χFD中任意两个特征之间的欧氏距离d(χ1,χ2),∀χ1,χ2∈χFD。然后为每个χ选择K个除了它本身之外,距离最近的特征,记为M。Mc表示M中属于类别c的特征集合。
2)计算相似度。两个特征之间的距离越大,相似度越低;距离越小,相似度越高。定义相似度计算函数为
采用指数衰减的形式主要是考虑放大近邻之间的差异。只要近邻距离变大,相似度迅速减少。这有助于降低较远的邻居对后续概率计算的影响。
3)计算概率分布。样本特征χ与其K个近邻的距离被转换为C个类别上的概率分布。样本χ被预测为类别c的概率为
4)难例挖掘。样本被预测为真值类别的概率pknn作为难易样本的指示。pknn越大,样本越容易区分;pknn越小,样本越难区分。结合图4(b),相比其他样本,处于类别交界处的样本的pknn会相对较小,易被模型误判。为引导检测模型更加关注这些误判样本,本文定义调节因子w=(1 -pknn)2来调整简单样本和困难样本对总损失的贡献。如图5 所示,pknn越大,调节因子w越小,简单样本对总损失的贡献越小;pknn越小,调节因子w越大,困难样本对总损失的贡献越大。最终式(3)可表示为
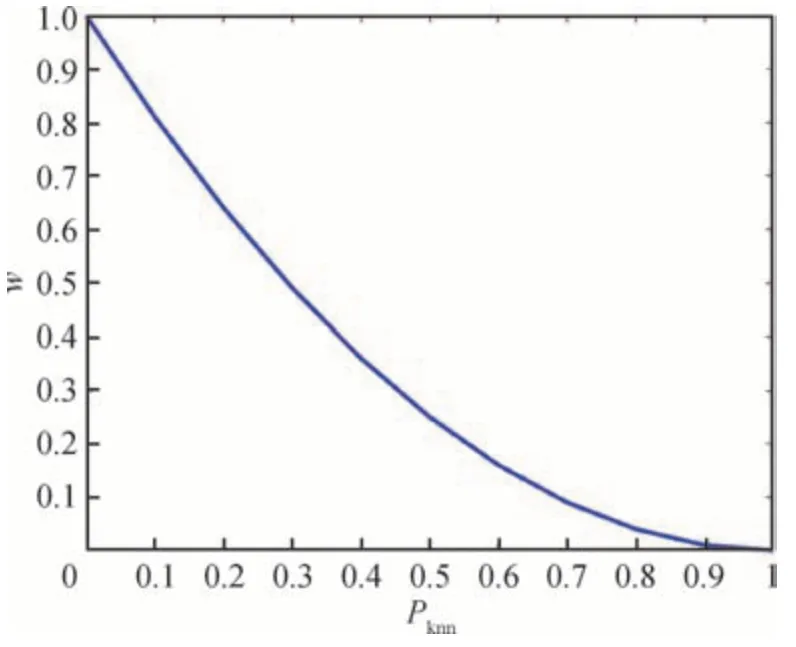
图5 调节因子曲线Fig.5 Regulatory factor curve
2 实验结果及分析
2.1 数据集
本文使用的所有数据都是来自华中地区一家电力公司的真实航拍巡检图像。电力杆塔上的螺栓可分为带销螺栓和不带销螺栓。带销螺栓起到连接和固定关键部件的作用,需要承受较大的作用力,相比不带销螺栓更容易发生缺陷,因此本文的研究对象是带销螺栓。根据螺栓上开口销的状态,将带销螺栓分为正常螺栓和缺陷螺栓,其中缺陷螺栓是指开口销脱落或松动的螺栓。数据集中有28 887 幅图像,每幅图像分辨率约为5 000 × 3 000 像素,按照8∶1∶1的比例划分训练集、验证集和测试集。
2.2 环境设置和评价指标
本文模型使用Python 3.7.12 和PyTorch 1.8.1实现,并在配置为NVIDIA GeForce GTX 2080Ti GPU的本地服务器上训练和测试。采用Faster R-CNN+FPN(feature pyramid network)(Lin 等,2017a)作为基线模型,使用在ImageNet(Deng等,2009)数据集上预训练的ResNet-50(deep residual network)(He 等,2016)作为特征提取网络。训练时设置batch size 大小为8,迭代12个epoch,初始学习率为0.02,并在第8个epoch和第11个epoch时衰减为原来的1∕10。
目标检测中两个常用的评价模型性能的指标是平均精度(average precision,AP)和平均精度均值(mean average precision,mAP)。Everingham等人(2010)给出了AP 的详细计算方法,mAP 是各类别AP 的平均值。一般来说,某一类目标的AP 值越高,模型对该类别的检测效果越好。
2.3 实验结果
为了验证本文模型的性能,将螺栓数据集在其他模型上进行了实验,包括两阶段模型Cascade RCNN(Cai 和Vasconcelos,2018)、Double Head R-CNN(Wu 等,2020),单阶段模型YOLOv5,基于Transformer 的检测模型Deformable DETR(deformable detection Transformer)(Zhu 等,2020)和 以Swin Transformer(Liu 等,2021)、ResNest(deep residual network with split-attention)(Zhang 等,2022)作为骨干网络的检测模型。实验结果如表1 所示,本文模型相比于其他模型在正常螺栓识别AP、缺陷螺栓识别AP 和mAP 等3 个指标上均有更好的表现。特别地,相比于基线模型,本文模型使缺陷螺栓识别AP提高了12%。与两阶段模型Double Head R-CNN、单阶 段模型YOLOv5、Deformable DETR和以ResNest作为骨干网络的检测模型相比,本文模型使缺陷螺栓识别AP 分别提高了5%、3.8%、2.4%和1.3%。这说明本文模型针对螺栓类间相似和类内多样问题所做的改进是有效的。

表1 本文模型与其他模型的对比Table 1 Comparison between the model in this paper and other models/%
P-R 曲线是以准确率(precision,P)为纵坐标,以召回率(recall,R)为横坐标绘制的,可用于衡量目标检测模型性能。P-R 曲线与横纵坐标轴围成的面积表示AP 值。图6 展示了基线模型和本文模型的P-R 曲线。从图6 中可以看出,本文模型在两个类别上的P-R 曲线均高于基线模型,特别是在缺陷螺栓的P-R 曲线上。这表明在相同的召回率下,本文模型的准确率更高,检测结果更好。
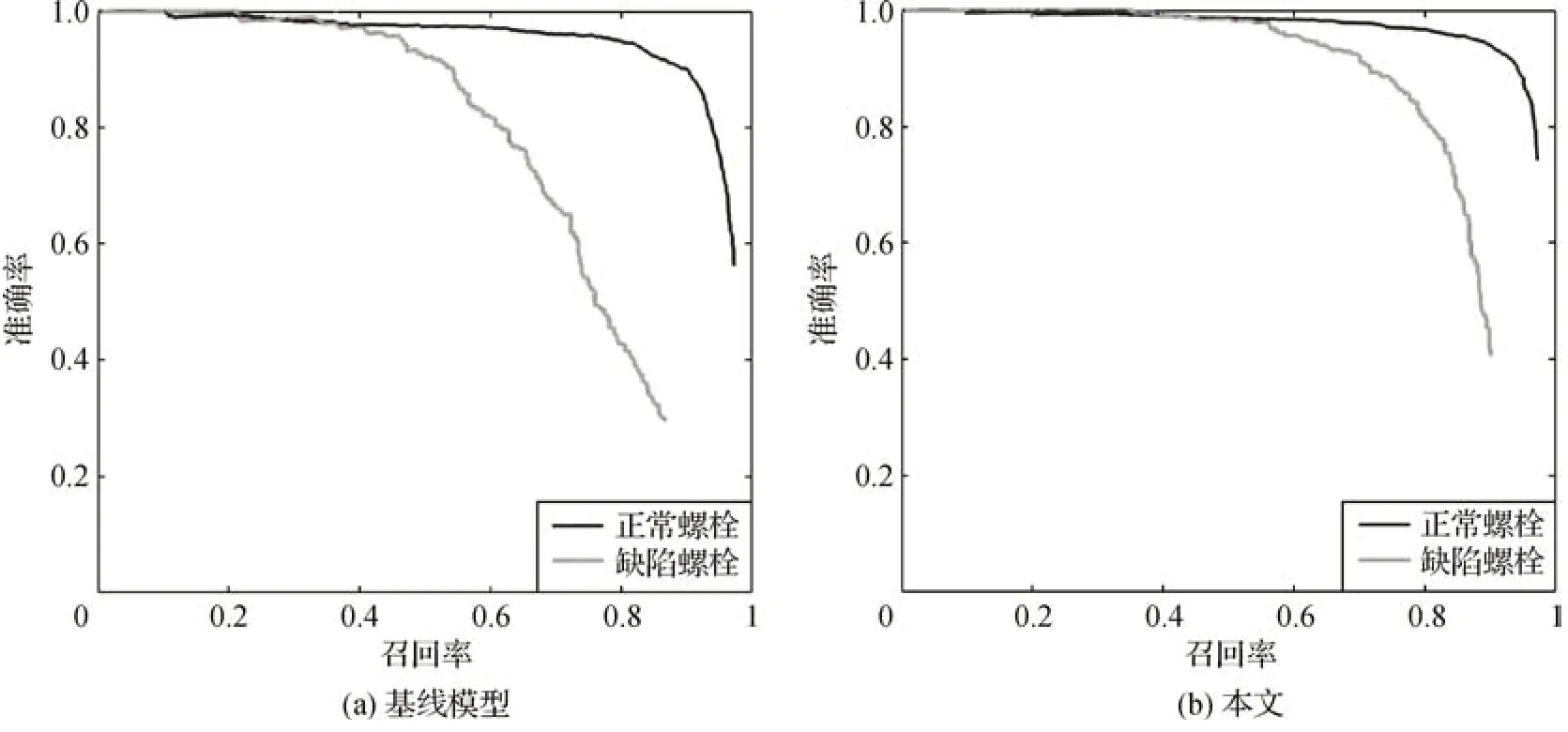
图6 不同模型的P-R曲线对比Fig.6 Comparison of PR curves of different model((a)baseline model;(b)ours)
图7 展示了基线模型和本文模型检测的可视化结果,包括预测框、预测类别和置信度分数。对于图7中的第1幅图像,基线模型将铁架上的两个不带销螺栓误检为销丢失螺栓,而本文通过帮助模型建模不同类螺栓安装在不同位置的先验信息避免了这种误判;一个正常螺栓由于拍摄角度等的原因仅能看到开口销的头部,视觉分类特征不明显,基线模型将这个正常螺栓误判为缺陷螺栓,而本文模型则将其正确分类且获得了较高的置信度分数。图7第2幅图像中的两个销孔不明显的缺陷螺栓,基线模型虽然分类正确但置信分数较低,但本文模型则给出了较高的置信分数。

图7 检测结果可视化Fig.7 Visualization of detection results((a)baseline model;(b)the proposed model)
2.4 消融实验
为了验证各个方法的有效性,在螺栓数据集上对各个方法进行实验,结果如表2所示。由于基于K近邻的难例挖掘是在改进的费舍尔损失的基础上提出的,因此模型Ⅲ同时使用这两种方法。

表2 消融实验Table 2 Ablation experiment
1)由表2 知,与使用均匀裁剪的基线模型相比,聚类裁剪使正常螺栓识别AP和缺陷螺栓识别AP分别提升了0.9%和7.2%,mAP 提高了4.1%。这表明利用基于密度的空间聚类算法对原始航拍图像进行预裁剪,帮助模型聚焦关键区域,可以有效地提高检测模型对缺陷螺栓的识别精度。
在图3 中,均匀裁剪获得了5 个目标稀疏的子图,分别包含3、2、2、2、1 个螺栓,且存在螺栓被割裂的情况(红色椭圆圈出的螺栓不完整);而聚类裁剪仅生成了3 个子区域,分别包含5、2 和6 个螺栓。均匀裁剪破坏了图3 中原始巡检图像右边的三角挂板结构,将其分割到3 幅子图中;而聚类裁剪则完整地保留了这一区域结构信息。
图8 展示了使用这两种预裁剪方法处理训练集后获得的子图情况。均匀裁剪产生了86 199 幅子图,其中约43%的子图仅含有1个带销螺栓;而聚类裁剪产生了59 676 幅子图,相比均匀裁剪减少了约31%。这导致基线模型的训练时间比模型Ⅰ要长,造成计算资源的浪费。

图8 两种裁剪方法获得的子图对比Fig.8 Comparison of subgraphs obtained between two cropping methods
通过上述分析可知,基于密度空间聚类的预裁剪算法不仅可以减少模型后续处理的数据量,节省计算资源,而且能够提取目标的上下文区域,帮助模型聚焦关键信息,提高模型的识别能力。
2)由表2 知,相比于基线模型,使用改进的费舍尔损失训练的模型使正常螺栓识别AP 和缺陷螺栓识别AP分别提高了0.7%和7%,mAP提高了3.8%。费舍尔损失通过对特征施加约束,使特征类内相聚、类间相离。这增大了不同类螺栓的特征差异度和同类螺栓的特征相似度,更有助于螺栓分类。
3)由表2知,基于K近邻的难例挖掘使模型Ⅱ的性能进一步提升,缺陷螺栓识别AP达到了81.1%,提高了2.2%。由此可知,通过K近邻学习引导模型关注难例可以提高不易辨识螺栓的识别效果。
近邻数K的取值会对模型性能产生影响。本文对K为3~8的取值进行了实验,结果如表3所示。可以看出,当K=5时模型达到最佳效果;而随着K值的增大,模型效果开始下降。这说明选择合适的K值对基于K近邻的难例挖掘方法是有必要的,若选取的K值过大,这时无关样本也会影响K近邻概率。

表3 近邻数K的取值对检测结果的影响Table 3 The influence of the value of the nearest neighbor number K on the detection results
4)在统计分类问题中,混淆矩阵是一种特定的表格布局,用于可视化分类算法的性能。检测任务的混淆矩阵与分类任务的非常相似,区别在于分类任务的对象是整幅图像,而检测任务的对象是图像中的各个目标。因此,为了能够绘制检测任务中混淆矩阵的正负例,需要根据预测框和真实框的交并比(intersection over union,IoU)区分哪些预测结果是正确的,哪些是错误的。
为了验证费舍尔损失和基于K近邻的难例挖掘方法对模型分类效果的提升,本文绘制了基线模型和模型Ⅲ检测结果的混淆矩阵,结果如图9 所示。在绘制过程中,IoU 阈值设置为0.5,且只统计置信度分数大于0.3 的预测框。测试集中正常螺栓有2 540 个,缺陷螺栓有556 个。与分类任务的混淆矩阵不同,该混淆矩阵某一行的数量之和不代表该类目标的真实数量。因为模型的检测结果中存在对螺栓的重复检测,即一个螺栓对应两个类别不同的预测框,这导致非极大值抑制算法无法剔除掉任何一个检测框。
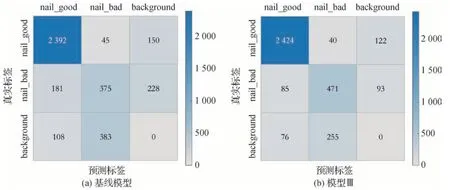
图9 检测任务的混淆矩阵Fig.9 The confusion matrix of the detection task((a)baseline model;(b)model Ⅲ)
从图9(a)(b)的对比中可以看出,模型Ⅲ相比基线模型在正常螺栓和缺陷螺栓的召回率和准确率方面均有提升。基线模型在缺陷螺栓上的召回率和准确率分别为67.4%和46.7%,模型Ⅲ相比基线模型在缺陷螺栓上的召回率和准确率分别提高了17.3%和14.7%。
3 结论
本文工作为电力公司基于航拍图像进行螺栓故障巡检提供了一种有效的方法,能够减少螺栓类间相似性和类内多样性对螺栓故障检测的干扰。主要贡献有以下几个方面:
1)在数据预处理阶段,利用DBSCAN 算法对巡检图像进行预裁剪来获取感兴趣区域。预裁剪不仅可以加快模型训练速度,帮助模型聚焦关键区域,而且能够将不同类螺栓安装在不同位置的先验信息引入模型,以此来辅助模型分类。
2)为了学习到更有区分性的特征,引入并改进费舍尔损失来约束样本特征的学习过程,使得最终的样本特征类内分散小、类间分隔大。
3)针对不容易分类的螺栓,提出利用K近邻学习将样本特征与近邻特征的距离分布转化为概率分布,并将其作为难易样本的指示以引导模型在训练时更多地关注难样本,以提高难样本的识别效果。
本文方法仍存在一些问题,如目前仅通过空间聚类算法将不同类螺栓安装在不同位置的先验信息引入模型,但电力部件间存在的空间结构知识尚未充分挖掘利用。未来的工作将围绕这一课题展开,探究部件间结构知识的提取方法和基于结构知识的网络建模方法。
猜你喜欢
高技术通讯(2021年3期)2021-06-09
无线互联科技(2020年22期)2021-01-11
科学(2020年5期)2020-11-26
弹箭与制导学报(2020年2期)2020-09-01
传感器与微系统(2018年7期)2018-08-29
自动化学报(2017年4期)2017-06-15
舰船电子对抗(2016年5期)2016-12-13
航天器工程(2014年5期)2014-03-11
中国新闻周刊(2004年16期)2004-05-11
