
SSRGFD:双目超分辨率图像通用篡改检测数据集
2023-11-22 01:18尹承禧张博林罗俊伟朱春陶付婧巧卢伟
中国图象图形学报 2023年11期
尹承禧,张博林,罗俊伟,朱春陶,付婧巧,卢伟*
1.中山大学计算机学院广东省信息安全技术重点实验室,广州 510006;
2.中山大学计算机学院机器智能与先进计算教育部重点实验室,广州 510006;
3.中山大学信息管理学院,广州 510006
0 引言
随着科学技术和数字成像设备的快速发展,数字图像已经遍布互联网和现实世界中的各个角落。在数字媒体技术的广泛应用和推动下,Photoshop、ACDSee等图像编辑软件逐渐普及,人们对数字图像进行恶意篡改越来越容易。但经过恶意篡改的数字图像很容易对生活甚至社会和国家造成恶劣的影响,因此,数字图像篡改检测技术研究对多媒体技术安全具有重要意义(李晓龙 等,2021)。近20 年来,国内外研究人员围绕数字图像篡改检测开展了大量的研究工作,提出了许多有效的检测算法和数据集。随着双摄像头在智能手机、自动驾驶和机器人领域的普及,双目超分辨率图像以更高的感知质量逐渐出现在人们的视野中,但其安全性问题却没有受到足够的重视。双目超分辨率图像成像经过超分辨率算法,与以往单摄像头成像的单目图像相比具有不同的图像特征,现有图像篡改检测方法在双目超分辨率图像上的性能需要重新验证并展开进一步研究。然而现有的图像篡改数据集大部分是单目图像数据集,缺少双目超分辨率图像篡改数据集。为了给双目超分辨率图像篡改检测研究提供可靠依据,本文提出了一个适用于通用篡改检测研究的双目超分辨率图像篡改数据集SSRGFD(stereo superresolution general forensic dataset)。
数字图像篡改检测是多媒体安全领域中一项重要的研究课题,通过分析数字图像特征和篡改痕迹识别并揭示图像的恶意篡改区域,能够保障数字图像的真实性和完整性。常见的篡改操作有复制黏贴、拼接和修复3 种。通过复制黏贴和拼接操作能够达到添加或覆盖图像内容的目的,主要区别在于复制区域和黏贴区域是否同源。图像修复可用于填充图像残缺区域或去除图像内容。为了提高篡改图像质量,篡改操作往往伴随着缩放、对比度变化、加噪和压缩等后处理手段,这一系列篡改操作在图像中引入的篡改痕迹,是图像篡改检测的关键。早期的图像篡改检测研究主要判断图像是否被篡改,通过检测图像是否经过重采样(Liu等,2020;Zhang等,2020)、压缩(Wang 等,2020)和模糊(Chen 等,2013)等后处理操作对图像真实性作出判断。图像篡改定位在篡改检测研究的基础上,通过滑动窗口的方式对图像篡改区域进行检测和识别,能够给出更细精度的决策,但存在滑动窗口大小和定位性能相互约束的问题。随着深度学习技术的不断发展,深度学习算法也广泛应用到图像篡改检测领域中,大幅提高了篡改检测准确率。越来越多复制黏贴篡改检测(Yang 等,2017)、图形拼接篡改检测(Zeng 等,2017;Kwon 等,2021)和图形修复篡改检测(Wan 等,2021;Guo 等,2021)技术不断涌现。深度学习算法在图像篡改检测领域的突破,得益于一系列的图像篡改数据集。数据集可以为理论研究提供一个窗口,研究者能够通过数据集了解待解决问题的复杂程度,高质量的数据集往往能够提高模型训练的质量和篡改检测的准确率。目前,已存在一些针对图像篡改检测的公开可用数据集,表1 展示了部分公开数据集的基本信息。
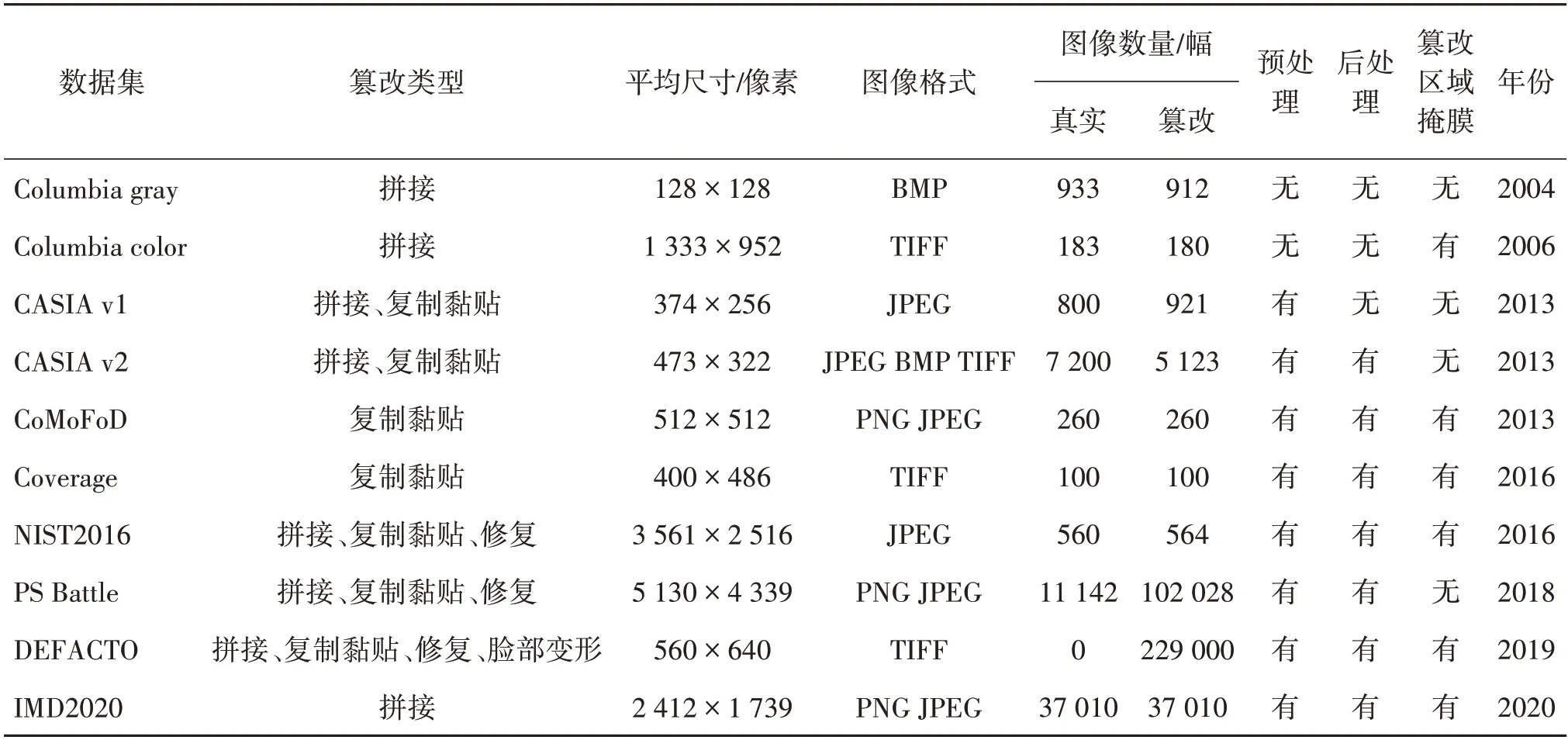
表1 常用数字图像篡改数据集Table 1 Common digital images tampering datasets
美国哥伦比亚大学的研究团队(Ng 和Chang,2004)发布了首个图像拼接篡改数据集Columbia gray。该数据集由128 × 128 像素的灰度图像组成,包含912 幅拼接图像。该团队认为直接来源于成像设备的图像是真实的,并通过Photoshop 对真实图像进行裁剪和随机拼接。为了侧重拼接篡改检测,图像拼接篡改过程没有经过任何预处理或后处理。随后,该团队(Hsu 和Chang,2006)又发布了Columbia color 数据集对前一个数据集进行扩展。该数据集共有180 幅不同尺寸的彩色拼接图像,同样通过随机拼接的方式构建篡改图像,且没有对篡改区域进行任何后处理操作。这两个拼接图像数据集在早期的拼接篡改检测中应用较多,但数据集拼接图像的主观视觉质量较差,难以比拟真实情况中的拼接篡改图像。中国科学院自动化研究所(Dong 等,2013)发布了一个具有真实拼接篡改操作的自然彩色图像数据集CASIA(image tampering detection evaluationdatabase of Institute of Automation,Chinese Academy of Sciences)。该数据集通过Photoshop 对真实图像进行篡改,包括v1 和v2 两个版本。其中CASIA v1包含921幅尺寸为384 × 256像素的JPEG篡改图像,考虑拼接和复制黏贴两种篡改类型,而且在进行图像拼接前会通过旋转、缩放等方式对拼接区域进行预处理。而CASIA v2 的图像数量和格式类型更多,包括5 123 幅彩色图像。此外,CASIA v2 还引入了模糊、过滤等后处理手段掩盖篡改痕迹以提升篡改图像的视觉质量,使得篡改图像更加真实也更具有挑战性。与Columbia 数据集相比,CASIA 的篡改质量更高,也更符合实际篡改情景,可惜该数据集未提供篡改图像的篡改区域掩膜。
2016 年以来,美国国家标准与技术研究院(Guan 等,2019)提出了NIST16(the Nimble Challenge 2016 kickoff dataset)、NIST17(the Nimble Challenge 2017 development dataset)等一系列篡改图像数据集。其中,NIST16 数据集包含复制黏贴、拼接和图像修复3种篡改操作,共有564幅篡改图像。数据集中的篡改操作经过后处理隐藏了可见痕迹,还提供了篡改区域掩膜以进行模型评估。但数据集篡改图像数量不多,后续发布的NIST17 数据集进一步增加了图像的篡改类型、格式和数量,为图像篡改检测研究的分析和评估提供了良好的参考依据。
Heller 等人(2018)从一个大型图像处理爱好者社区收集了PS-Battles数据集。该数据集共91 886幅篡改图像,随着时间的推移,该数据集也会不断地扩展。但该数据集没有收集图像对应的篡改区域掩膜,在一定程度上限制了数据集的应用。Mahfoudi等人(2019)利用MS COCO(Microsoft common objects in context database)中的注释对伪造对象进行分割,并在此基础上生成了包含复制黏贴、拼接、移除和脸部变换4 种篡改类型的超过20 万幅篡改图像的DEFACTO 数据集。尽管通过脚本生成篡改图像时考虑了篡改对象的位置,但主观视觉质量仍然较差。Novozámský等人(2020)提出了 数据集IMD2020(large-scale annotated dataset),他们从市面上的相机产品中选择了2 322款相机,拍摄捕捉了大量真实图像数据,进一步通过多种图像处理操作和生成对抗网络(generative adversarial network,GAN)等深度伪造算法,最终得到了包含70 000幅算法合成和2 010幅手工生成的篡改图像数据集。但通过深度伪造算法合成篡改图像时随机选择篡改区域,伪造图像存在明显的篡改痕迹,因此大部分情况下只考虑使用收集的2 010幅手工篡改图像。
虽然现有篡改图像数据集已经广泛应用于数字图像篡改检测任务中,但这些数据集的原始图像主要来源于单目成像设备。而双目成像系统在智能手机、自动驾驶等多个领域占据越来越重要的位置,双目图像超分辨技术也随之快速发展。StereoSR(stereo image super-resolution network)(Jeon 等,2018)、PASSRnet(parallax attention stereo image superresolution network)(Wang 等,2019a)、SPAMnet(self and parallax attention network)(Song 等,2020)和CPASSRnet(cross parallax attention network)(Chen等,2022)等双目图像超分辨率算法相继提出,这些深度学习算法利用左右图的互补信息对图像进行恢复重建,合成具有更高分辨率的双目超分辨率图像。尽管双目超分辨率图像经过算法合成,但这个过程在设备成像过程中完成,不经过人工干预,从双目成像设备直接得到的双目超分辨率图像也应该认定为真实图像。因此,针对双目超分辨率图像的图像篡改检测研究也具有重要意义。然而,双目超分辨率图像的合成过程会破坏左右图像的模式噪声,生成新像素,提升图像分辨率的过程也会引入图像像素相关性的变化。双目超分辨率图像和单目图像具有不同的图像特征,对现有的在单目图像数据集上验证的篡改检测方法带来了极大的影响。因此,针对双目超分辨率图像的篡改检测是目前数字图像篡改检测领域的研究课题之一。
鉴于目前缺乏针对双目超分辨率图像的篡改图像数据集,本文提出了一个双目超分辨率图像篡改数据集SSRGFD,以推动双目超分辨率图像篡改检测研究工作的发展。数据集的真实图像通过PASSRnet 算法从Flicker1024(large-scale stereo image super-resolution dataset)(Wang 等,2019b)双目数据集中生成,涵盖复制黏贴、拼接和修复3 种篡改图像。本文结合PhotoShop 图像编辑工具软件和深度图像修复算法人工构建了复制黏贴、拼接和修复3 种类型的篡改图像。为了更贴合真实篡改场景,在构建篡改图像过程中采用了缩放、旋转和模糊等多种图像处理操作隐藏可见篡改痕迹,提高篡改图像的视觉质量,给双目超分辨率图像篡改检测带来了更大的挑战。
1 SSRGFD数据集介绍
1.1 数据来源和预处理
本文构建SSRGFD 数据集的双目超分辨率图像数据来源于双目图像数据集Flickr1024,该数据集由1 024 对立体图像对组成,涵盖了自然风景、街道和房屋等多种场景,通过对该数据集进行篡改操作能够更有效地贴合实际情况中的各种篡改情景。从Flickr1024获取立体图像对后,为模拟双目成像设备的成像过程,使用PASSRnet 以大小为2 的超分辨率因子生成双目超分辨率图像。通过PASSRnet 模拟双目设备成像过程,合成的双目超分辨率图像也被认定为真实图像。所有图像保存为PNG 格式,图像尺寸随Flickr1024 中原始立体图像对的尺寸变化,表2给出了SSRGFD数据集的具体信息。

表2 SSRGFD数据集概况Table 2 Overview of SSRGFD dataset
1.2 图像篡改操作
对图像的随机区域进行篡改能够快速地生成大量的篡改图像,但篡改区域往往在图像语义上没有意义,还会留下明显的可见篡改痕迹。为了满足实际篡改场景的应用,SSRGFD 数据集构建结合Photoshop图像编辑工具和深度学习算法对真实双目超分辨率图像进行篡改,篡改过程可能会经过缩放、拉伸和旋转等预处理操作,以及模糊、对比度变换和色彩变换等后处理操作以掩盖可见篡改痕迹,使得篡改数据集更符合真实场景和更具有挑战性。SSRGFD数据集包括复制黏贴、图像拼接和图像修复3 种篡改类型的篡改图像,每幅篡改图像仅包含一种篡改操作,接下来将详细介绍3种类型的篡改操作。
1.2.1 复制黏贴
复制黏贴篡改图像通过复制原始图像中的一部分内容并将其黏贴到原始图像的不同区域得到。在生成复制黏贴图像时,将遵循以下标准:
1)语义完整性。所有的复制区域都是一个完整的对象,具有完整的语义信息。当黏贴区域处于图像边界时,截断不会破坏黏贴对象的语义。
2)篡改可行性。复制区域和黏贴区域附近的环境信息应该相似。
3)检测挑战性。篡改图像有一个或多个复制区域,有一个或多个黏贴区域。
4)内容多样性。复制的对象可以包括动物、植物、交通工具和建筑等多种对象。
5)篡改痕迹隐蔽性。篡改过程可能经过旋转、缩放和变换等预处理操作,篡改区域可能经过模糊、加噪和对比度变换等后处理操作。
为了避免篡改对象没有明显语义或语义被破坏,黏贴区域和周围环境有明显语义区别,导致篡改图像语义不符合真实场景、在视觉上有明显的人工篡改现象,在进行复制黏贴篡改操作时,会严格保证复制和黏贴对象的语义完整性和篡改可行性。并且通过重复复制对象或复制多个对象进行黏贴篡改使得检测任务更具有挑战性。考虑内容多样性,复制的对象涵盖了动植物、汽车和房屋等在实际生活中常见的对象。为了进一步提升数据集质量,在篡改过程中会进行多种预处理和后处理操作以掩盖篡改痕迹,使篡改图像更接近实际篡改场景。为每幅复制黏贴篡改图像,都提供了对应的复制区域掩膜和黏贴区域掩膜,图1 展示了复制黏贴篡改图像及其对应复制区域掩膜和黏贴区域掩膜的示例。

图1 复制黏贴篡改图像及掩膜示例Fig.1 Copy-move forgery images and masks((a)copy-move forgery images;(b)duplicated region masks;(c)tampering region masks)
1.2.2 图像拼接
拼接篡改图像通过将原始图像中的对象黏贴到不同图像上得到。对于拼接图像,首先在真实图像中提取出具有完整语义的拼接对象,随后黏贴到另一图像的拼接区域上,完成异源图像间的拼接篡改。在进行图像拼接时,考虑以下拼接篡改标准。
1)语义完整性。所有提取的拼接对象都具有完整的语义信息。当拼接区域处于图像边界时,截断不会破坏对象的语义。
2)篡改可行性。拼接区域和拼接对象的源区域附近的环境信息应该相似。
3)检测挑战性。每幅篡改图像使用一个或多个拼接对象进行篡改拼接,每幅篡改图像包含一个或多个拼接区域。
4)内容多样性。选择的拼接对象可以包括动物、植物、交通工具和建筑等多种对象。
5)篡改痕迹隐蔽性。拼接对象可能经过旋转、缩放和变换等预处理操作,拼接篡改后区域会对图像进行模糊、亮度调整和对比度变换等后处理操作。
在拼接篡改过程中,同样严格遵循拼接对象的语义完整性和拼接区域的篡改可行性要求,以满足实际场景的篡改需求。为了提升篡改图像质量和丰富性,拼接篡改过程会从一幅或多幅真实图像中提取拼接对象,黏贴到一幅异源图像上。与复制黏贴篡改不同的是,复制区域和黏贴区域来自同一幅图像,而拼接对象和拼接区域来自不同图像,因此拼接篡改更需要考虑不同图像噪声、亮度和光照等因素的关系。针对这个问题,在拼接篡改中往往会更频繁地使用到对比度增强、亮度调整和模糊等后处理操作来掩盖拼接痕迹。对每幅拼接篡改图像,都提供了对应的拼接区域掩膜,图2 展示了拼接篡改图像及其对应拼接区域掩膜的示例。

图2 拼接篡改图像及掩膜示例Fig.2 Samples of splicing forgery images and masks((a)splicing forgery images;(b)masks)
1.2.3 图像修复
图像修复旨在恢复残缺图像中缺失的像素特征或通过背景内容填充的方式去除图像中的物体。在数据集构建中,修复篡改图像包括重建和移除两类。1)图像重建是根据残缺图像中缺失区域周围已知像素特征和图像背景分布对缺失区域进行修复的过程。图像修复篡改中的重建图像通过深度学习算法重建残缺图像得到。首先对真实图像进行破坏,然后通过图像修复模型HiFill(high-resolution image inpainting network)(Yi 等,2020)对破坏后的残缺图像进行修复。HiFill对输入图像尺寸没有限制,可以直接对各种尺寸的残缺图像进行修复,能够在较少计算资源的情况下实现超高分辨率图像修复,且图像分辨率和待修复区域尺寸不会显著影响模型处理速度和修复质量,能够高效完成双目超分辨率图像的修复篡改任务。首先将图像降采样到512 × 512像素,然后对其进行上采样,获得与原始输入相同大小的模糊图像。同时,生成器获取低分辨率的图像并填充这些漏洞,注意力计算模块计算注意力得分并通过从原始输入中减去模糊图像来计算上下文残差,然后通过注意转移模块从上下文残差和注意分数计算掩膜区域的聚合残差。最后,将聚合的残差添加到上采样的结果中,在掩膜区域输出,而掩膜外部的区域只是原始输入的副本。2)图像移除指从目标对象周围像素中采样,通过在目标区域填充采样像素的方式达到去除图像内容对象的目的。修复篡改图像中的移除图像使用Photoshop 人工合成,通过拾取一定范围内的像素进行模拟,参考真实图像的背景内容覆盖图像目标区域达到去除图像中物体的目的。在图像修复篡改过程中,图像重建和图像移除都遵循以下准则:
1)目标对象多样性。去除的目标是动物、植物和建筑等各种具有完整语义的对象,修复的目标也可以是天空、湖泊和墙壁等背景内容。
2)修复效果合理性。若通过深度学习算法得到的修复结果具有大量伪影或与其他区域具有较大的视觉差异,则将其从数据集中去除。通过Photoshop进行图像修复时参考区域和去除的目标区域应具有相似的环境信息。
3)篡改痕迹隐蔽性。在完成图像修复后,可能会对修复篡改图像进行缩放、模糊和对比度调整等多种后处理操作。
在实际的图像修复任务中,图像的残缺区域是不确定的,而对图像对象进行去除时通常针对完整对象。因此,依据目标对象多样性对图像进行修复篡改能够有效拟合真实场景中的图像修复。由于深度学习模型训练所使用的图像与需要修复的图像有一定的差异,部分修复图像会存在明显的篡改痕迹(强振平 等,2019),因此不考虑将这部分修复质量较差的图像加入数据集中。此外,在手工进行目标去除时也需要保证修复效果的合理性,修复的参考对象区域与去除目标对象区域应该接近或相似,避免修复区域不符合现实逻辑。在进行图像修复篡改后,同样对篡改图像进行后处理达到弱化篡改痕迹的目的,提高图像质量。对每幅修复篡改图像,都提供了对应的修复区域的掩膜,图3 展示了修复篡改图像及其对应的修复区域掩膜的示例。

图3 修复篡改图像及掩膜示例Fig.3 Samples of inpainting forgery images and mask((a)original images;(b)inpainting forgery images;(c)masks)
1.3 数据集特点
本文提出的SSRGFD数据集具有以下特点:
1)面向双目超分辨率图像。以往的图像篡改数据集主要关注单目图像上的篡改操作,尽管已经存在许多类型丰富、数据规模大的篡改图像数据集,但依旧缺乏针对双目超分辨率图像的篡改数据集,难以满足各方向研究对数据的需求。本文提出的SSRGFD 数据集为双目超分辨率图像通用篡改检测研究工作提供了可靠依据。
2)图像内容丰富。SSRGFD 中的所有图像具有高分辨率,涵盖了现实中的各种场景。图像的篡改对象都经由人工设计,而且大部分篡改图像都经过后处理操作隐藏篡改痕迹,篡改图像具有较高的视觉质量,能够较好地拟合真实的篡改情景。
3)类别分布均衡。每种类型的篡改图像的数量比较接近,不容易出现过度依赖不均衡的数据样本导致过拟合的问题,能够应用于双目超分辨率图像的通用篡改检测研究工作中。
2 数据集图像视觉质量评估
随着图像编辑软件和技术的发展,真实场景中的篡改图像的视觉质量越来越高,人眼越来越难以察觉篡改图像,为图像篡改检测任务带来了更大的挑战。为此,对本文提出的SSRGFD 数据集从主观和客观两方面进行图像视觉质量评估,验证SSRGFD数据集中篡改图像的视觉质量。
2.1 主观图像质量评估
图像质量主观评价以人为观测主体,根据视觉系统对图像质量做出主观评价,能够真实反映人对图像的视觉感知。主观图像质量评价方法主要分为绝对评价法和相对评价法两类。
绝对评价法在对图像质量进行评价时需要将待评价图像与客观参考图像进行比较,对图像质量作出绝对好坏的评价;相对评价法则不需要参考图像,由评价者对一批待评价图像进行互相比较,给出每幅图像的质量优劣顺序。为了对不同篡改类型的篡改图像质量进行主观质量评估,实验采用国家广播电视总局(2021)超高清晰度电视图像质量主观评价方法中的双刺激连续质量分级法DSCQS(double stimulus continuous quality scale)对数据集图像进行主观质量评价,通过将待评估的篡改图像和对应篡改前的真实图像作为参考基准交替展示给评估者,评估者在不知道哪幅是篡改图像的前提下对篡改前后的图像进行直接的质量比较,对篡改图像和真实图像的视觉质量进行打分,计算真实图像和篡改图像的平均主观得分差作为该篡改图像的图像质量评分结果。通过这种方式能够最大程度地降低图像场景、情节等对主观测评的影响,主观图像质量的评价尺度共分为5 个评级:1)十分严重妨碍观看;2)清楚看出图像质量下降,对观看稍有妨碍;3)图像质量有所下降,但不妨碍观看;4)观看有妨碍图像时,质量有所下降,但不妨碍观看;5)丝毫看不出图像变化。以上5个评级的对应评分为1~5分。
实验分别从3 种篡改类型的图像中各选择了30 对篡改图像和真实图像对,邀请了数字取证领域相关和无关的评估者共15 名交替观看篡改图像和真实图像,并对篡改图像质量打分。评估员对篡改图像和真实图像给出的评分差值的均值将作为各类篡改图像的主观视觉质量评分结果。
图4 展示了不同类型篡改图像的平均评分差异的均值。可以发现,评估者给出的图像对平均评分差异基本都低于1.5。其中,复制黏贴篡改图像的可视篡改痕迹最小,复制黏贴图像对的平均评分大部分低于0.5。通过深度学习算法重建图像残缺区域时更关注图像像素的分布特征,对人类主观视觉质量考虑较少,导致篡改图像存在较为明显的篡改痕迹,重建图像区域像素的修复篡改图像对的评分差异较大。而通过Photoshop 人工移除目标对象进行修复篡改时,能够更好地满足对图像主观视觉质量的要求,评分差异基本小于1。通过对篡改图像的主观质量评价实验,说明了SSRGFD 数据集能够保持良好的主观视觉质量,有效贴合真实篡改场景。

图4 SSRGFD篡改图像和真实图像对主观质量平均评分差异Fig.4 The mean of subjective quality scores difference between tampering images and the real images of SSRGFD
2.2 客观图像质量评估
图像客观质量评价可分为全参考、半参考和无参考3 种类型。其中全参考和半参考评价方法都需要理想图像或其特征作为参考对待评价图像进行质量分析。在实际的篡改场景中,通常无法获取篡改前的真实图像,因此实验选择无参考评价方法,脱离对参考图像的依赖,直接对待评价图像进行客观质量评价,实验考 虑BRISQUE(blind∕referenceless image spatial quality evaluator)(Mittal 等,2012)、NIQE(natural image quality evaluator)(Mittal 等,2013)和PIQE(parent institute for quality education)(Venkatanath 等,2015)3 个无参考图像质量指标。BRISQUE 是一种无参考的空间域图像质量评估算法,通过将从图像空域中提取的MSCN(mean subtracted contrast normalized)系数拟合为非对称性广义高斯分布后提取出特征向量,使用支持向量机(support vector machine,SVM)进行分类给出质量评估。NIQE 基于NSS(natural scene statistics)模型得到一组图像质量感知特征,将其拟合到MVG(multivariate Gaussian model)模型中,将该模型与从自然图像中提取的质量感知特征的MVG 模型之间的距离作为质量评价指标。PIQE 则在图像块级别从感知上显著的空间区域来估计图像质量。
表3 展示了篡改图像和真实图像的无参考图像质量评估分数均值。3 种无参考图像质量评价方法的评估分值越低,说明图像质量越好。从表3 数据可以发现,双目超分辨率真实图像与SSRGFD 的篡改图像的无参考图像质量评估结果十分接近,表明SSRGFD 双目超分辨率图像篡改数据集具有良好的图像质量。尤其是复制黏贴篡改图像,由于复制区域和黏贴区域同源,篡改内容和非篡改内容的像素强度分布相似,复制黏贴篡改操作对图像像素强度分布的影响最小,在BRISQUE 和NIQE 上的评价结果也都较好。可以看到,尽管SSRGFD 中不同类型的篡改图像由不同的篡改标准生成,不同篡改类型的篡改图像的评价结果都非常接近,表明篡改图像质量受篡改类别的影响较小。此外,对于图像修复篡改图像,基于深度学习修复算法HiFill 合成和基于Photoshop 人工篡改在不同的无参考图像质量评价方法上有不同的表现。这是由于HiFill 通过学习图像背景像素分布来合成修复篡改区域,篡改区域和真实图像具有相似的分布,在基于图像空域统计规律的BRISQUE 和NIQE 方法具有更好的评估结果。而利用Photoshop 进行人工篡改时会更关注图像显著部分的篡改效果,因此,相比基于深度学习算法的修复篡改图像,手动篡改的修复图像在PIQE 方法上取得更好的结果。客观图像质量评估实验验证了SSRGFD 数据集在不同篡改类别图像都能保持良好的视觉质量,表明了本文对不同篡改类型提出的篡改标准的有效性,进一步说明了SSRGFD 有效拟合现实的篡改场景,能够为双目超分辨率图像带来新的挑战。

表3 双目超分辨率篡改图像和真实图像的无参考质量平均评估分数Table 3 The mean of no-reference image quality evaluation scores on SSRGFD
3 数据集检测性能评估
为了验证双目超分辨率图像对现有图像篡改检测技术的冲击,本文考虑MantraNet(manipulation tracing network)(Wu 等,2019)、RRU-Net(ringed residual U-Net)(Bi 等,2019)、QMPPNet(Yin 等,2021)和DenseFCN(dense fully convolutional network)(Zhuang 等,2021)4 个有效的深度学习篡改检测模型,分别在本文提出的SSRGFD 双目超分辨率图像通用篡改检测数据集上进行实验评估。
MantraNet 将篡改定位问题转化为局部异常检测问题,使用Z-score 特征标准化图像局部异常特征,使用长短期记忆网络(long short-term memory,LSTM)从不同分辨率汇聚特征图得到最终的检测结果。RRU-Net 是一个图像分割网络,针对传统卷积神经网络使用图像块作为输入容易丢失上下文信息的问题,通过环形残差U-Net 结构充分利用图像空间域上下文信息有效减小检测误差。QMPPNet 是一个多任务预测金字塔网络,设计了专门的块预测模块和特征正则化方法Pixel Norm,通过提取篡改块和非篡改块的统计分布,由粗到细的定位篡改区域的边缘,最后结合语义分割网络,进一步提升定位的精确度。DenseFCN 是一个多维密集特征连接的端到端网络,设计了金字塔特征提取器(pyramid feature extractor,PFE)来提取多维和多尺度的密度特征,通过相关特征匹配FCM(fuzzy C-means)学习深度特征的相关性后,进行分层后处理(hierarchical post-processing,HPP),能够高效率地保持高检测性能。实验中各神经网络模型所使用参数、输入图像尺寸与原方法设置一致。实验硬件配置为Intel Xeon Gold 6161 CPU,主频2.20 GHz,内存128 GB,显卡为GeForce RTX 3090 GPU。
实验使用查准率(precision)、召回率(recall)、像素级F1 分数(F1-score)、马修斯相关系数(Matthews correlation coefficient,MCC)和交并比(intersection over union,IoU)5 个性能评估指标。在篡改检测任务中,precision 代表预测的篡改像素中正确预测的准确率,recall反映了正确预测的篡改像素占所有篡改像素的准确率,F1 分数综合考虑查准率和召回率,F1值越高代表性能越好。MCC系数的值在-1和1 之间,取值大小表示分类器的分类性能,常用于类别不均衡分类问题。IoU 即预测的篡改区域与实际篡改区域交集面积和并集面积之比,与F1 分数正相关。
表4 展示了4 个有效的图像篡改检测深度学习模型在SSRGFD 数据集上的检测性能。QMPPNet 在各个指标上都达到最优性能。但这些方法在SSRGFD 上的检测性能远不如它们在单目图像篡改数据集上的性能。从图5 可以看到,现有的图像篡改检测方法都受到了双目超分辨率图像的影响。MantraNet 将图像篡改痕迹应用于异常检测任务中,尽管双目超分辨率图像未经过恶意篡改,但通过双目超分辨率技术合成双目超分辨率图像的过程会不可避免地在合成图像中引入图像处理操作痕迹,导致MantraNet 对非篡改区域具有较高的误检率。虽然RRU-Net 准确率不高,但能够较为有效地检测出篡改区域。基于语义分割和边缘特征的QMPPNet具有最为准确的检测结果。但如图5中QMPPNet的检测结果所示,当图像内容影响边缘检测的结果时,结合语义信息进行篡改定位容易产生较大的误检区域,这也造成了QMPPNet 的假阳性过高。虽然DenseFCN 的准确率为32.21%,但其召回率却高达89.61%。从检测结果来看,DenseFCN 容易将非篡改区域误判为篡改区域,这也体现了双目超分辨率图像特性对现有篡改检测方法的影响。深度学习模型在常见单目图像篡改数据集CASIA v2 和DEFACTO 中的表现如表5 所示。其中,针对拼接篡改检测的RRU-Net和针对篡改边缘特征的QMPPNet在这两个以拼接篡改图像为主的数据集上的性能优于其他两个深度模型。从表4 与表5 的性能对比可以看出,双目超分辨率图像对现有图像篡改检测方法性能造成了很大的影响,现有的图像篡改检测方法难以在双目超分辨率图像上取得理想效果。对比结果表明,现今亟需展开对双目超分辨率图像的篡改检测研究工作,以保障双目超分辨率图像的安全性问题。

图5 图像篡改检测方法在SSRGFD的检测结果展示Fig.5 Results of image tampering detection methods on SSRGFD((a)original images;(b)mask;(c)MantraNet;(d)RRU-Net;(e)QMPPNet;(f)DenseFCN)
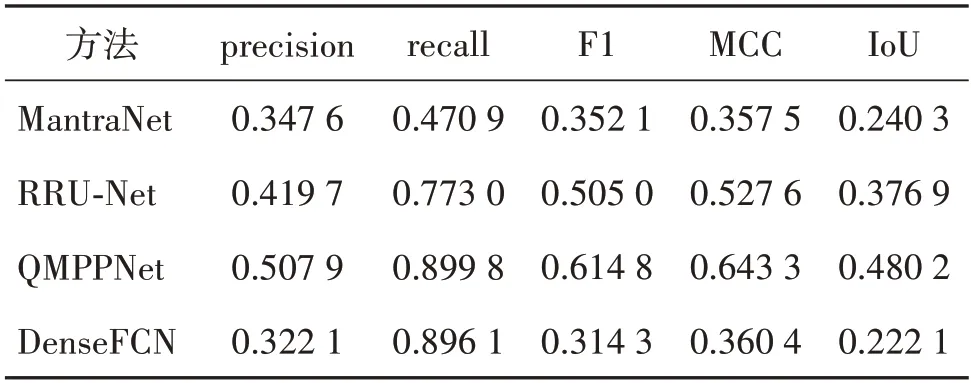
表4 图像篡改检测方法在SSRGFD的检测性能Table 4 Performance of image tampering detection methods on SSRGFD

表5 图像篡改检测方法在CASIA和DEFACTO的检测性能Table 5 Performance of image tampering detection methods on CASIA and DEFACTO
实验表明,现有的通用图像篡改检测方法在双目超分辨率图像篡改数据集上往往无法达到预期性能,难以有效地定位篡改区域。同时,由于双目超分辨率图像和单目图像定位具有不同的图像特征,会对基于图像特征和操作痕迹进行篡改检测的方法造成一定的影响。实验充分展示了在双目超分辨率图像上展开篡改检测和研究的需要,也说明了本文构建的双目超分辨率图像通用篡改检测数据集SSRGFD的重要性。
4 数据集应用及展望
双目成像设备的推广和图像超分辨率技术的发展给现有的图像篡改检测技术带来了新的挑战。实验验证了目前面向单目图像的深度学习检测模型不适用于具有不同图像特征的双目超分辨率图像的篡改检测问题,双目超分辨率图像的安全受到威胁。为此,本文提出的SSRGFD 数据集能够应用于双目超分辨率图像篡改检测的研究工作中,为领域研究和技术评估提供了数据基础。
针对双目超分辨率图像和单目图像的差异性,将来在SSRGFD 数据集上进行图像篡改检测研究时可以在以下方向展开工作:
1)挖掘独立于图像特性的篡改痕迹。双目超分辨率图像的特性很大程度上影响了现有篡改检测方法的性能,基于独立于图像特性的篡改痕迹,能够设计实现同时应用在单目图像和双目超分辨率图像上的篡改检测方法,更有效地保障数字图像安全。
2)高效的通用检测方法。单一类型的篡改检测方法面对多种篡改方式的检测效率越来越低,为应对实际场景中层出不穷的篡改手段和场景,如何更好地结合多种可用篡改特征和方法也是双目超分辨率图像篡改检测的重要研究方向之一。
5 结论
针对目前缺乏双目超分辨率图像篡改数据集的问题,本文构建了SSRGFD 双目超分辨率图像篡改数据集,包含复制黏贴、拼接和修复3 种常见篡改类型的篡改图像,每幅篡改图像都有对应篡改区域的掩膜。本文为每种篡改类型设计了不同篡改标准,通过Photoshop 或深度学习算法得到图像内容丰富且具有较高的视觉质量的篡改图像。
实验结果表明,本文提出的双目超分辨率图像篡改数据集SSRGFD 具有较高的图像质量,能够有效拟合真实篡改场景,使得图像篡改检测任务更具有挑战性。现有主流图像篡改检测方法在SSRGFD 上的实验评估,展示了双目超分辨率图像对现有图像篡改检测技术有效性造成的冲击和影响,亟需展开面向双目超分辨率图像的篡改检测技术的研究。本文提出的SSRGFD 数据集能够为双目超分辨率图像篡改检测的研究工作提供良好的参考依据。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
计算机与数字工程(2022年5期)2022-06-16
中国体视学与图像分析(2021年3期)2021-11-24
装饰装修天地(2020年1期)2020-02-14
电子制作(2019年20期)2019-12-04
橡塑技术与装备(2018年1期)2018-12-25
制造技术与机床(2017年10期)2017-11-28
科技资讯(2016年21期)2016-05-30
现代计算机(2016年11期)2016-02-28
机械与电子(2014年2期)2014-02-28
