
自适应语义感知网络的盲图像质量评价
2023-11-22 01:19陈健万佳泽林丽李佐勇
中国图象图形学报 2023年11期
陈健,万佳泽,林丽,李佐勇
1.福建理工大学电子电气与物理学院,福州 350118;2.福建省信息处理与智能控制重点实验室(闽江学院),福州 350121
0 引言
伴随着采集设备及相关技术的持续更新,成像技术得到快速发展。然而,图像在采集、处理、传输及储存等各个阶段易受外部因素干扰,引入不同类型及程度的失真,从而导致图像质量下降。因此,图像质量评价(image quality assessment,IQA)在图像成像的过程中变得愈加重要。人类是图像的主要使用者,最为准确的评价方法是以人类视觉系统(human visual system,HVS)为标准的主观图像质量评价方法。但主观图像质量评价工作量大、耗时长,使用起来很不方便(陈健 等,2022),因此,构建一个合理且接近HVS 的客观图像质量评价方法至关重要。根据参考图像在质量评价中的作用,图像质量的客观评价方法通常分为3 类:全参考图像质量评价(full-reference image quality assessment,FR-IQA)、部分参考图像质量评价(reduced-reference image quality assessment,RR-IQA)及无参考图像质量评价(no-reference image quality assessment,NR-IQA)。其中,NR-IQA 也称为盲图像质量评价(blind image quality assessment,BIQA)。因为采用图像或图像特征作为参考,大多数FR-IQA 和RR-IQA 方法可取得令人满意的结果。但在实际应用中,由于往往得不到有效的参考图像或图像特征,BIQA 方法成为主流的研究方向。
高敏娟等人(2020)提出结合全局与局部变化相似度(global and local variation similarity,GLV-SIM)的图像质量评价算法模拟HVS 感知图像质量评价过程。陈勇等人(2020)基于像素之间的相关性,提出一种基于差异激励(differential excitation)的无参考图像质量评价算法,该方法中引入了支持向量回归(support vector regression,SVR)。但无论是基于空域或(和)频域还是基于机器学习的BIQA方法,评价过程均需要提取空域∕频域特征,因此,评价结果的优劣与提取的空域∕频域特征息息相关(陈健 等,2022)。由于深度学习网络不仅可以实现图像特征到质量分数的映射,也可以实现对图像特征的提取,实现端到端的评价过程,因此,基于深度学习的IQA方法得到了学者们的广泛关注,各种基于卷积神经网络(convolutional neural network,CNN)的评价模型层出不穷。尽管基于机器学习∕深度学习的方法在人工失真(鄢杰斌 等,2022)图像质量数据库中均取得了不错的评价结果,但在评价自然失真(鄢杰斌等,2022)图像时,上述方法的性能仍然不足,评价结果仍有待于进一步提高。自然失真图像质量评价主要有以下两个难点:1)与人工失真不同,自然失真情况更为复杂。自然失真图像不仅包含全局均匀失真(如失焦、高斯噪声),还在不同程度上受到局部区域非均匀失真(如过曝、重影)的影响。因此,BIQA 方法如何准确感知失真类型及分布是获得图像质量分数的关键。2)图像内容的变化也是BIQA 的难点之一。常见的人工失真图像质量数据库(如LIVE(Laboratory for Image &Video Engineering)(Sheikh等,2006)和CSIQ(categorical subjective image quality)(Larson 和Chandler,2010)等)仅包含不超过30 幅的参考图像,而自然失真图像质量数据库往往包含多达上千幅的图像,如LIVEC(LIVE in the Wild Image Quality Challenge)(Ghadiyaram 和Bovik,2016)和KonIQ-10k(Konstanz authentic image quality 10k database)(Hosu 等,2020)分别由1 162 幅和10 073幅内容不同的图像组成。因此,BIQA 方法需要较高的泛化能力去应对复杂的图像内容变化。大部分BIQA 方法在面对自然失真图像时,由于失真类型较多及图像内容变化较丰富,往往难以提取正确的图像特征,导致预测分数与平均主观得分(mean opinion score,MOS)或平均主观得分差异(differential mean opinion score,DMOS)的相关性较差。
此外,为了提升网络的盲图像质量评价性能,部分学者并不直接将深度卷积神经网络(deep convolutional neural network,DCNN)提取到的语义特征映射到质量分数,而是经过后处理后再进行质量分数的映射(Li 等,2019;Su 等,2020),原因包括以下两点:1)高层获得的图像特征虽然具有丰富的语义信息,但缺乏局部细节信息,从而导致整个网络只注重全局失真情况,而忽略了局部失真,但对于多数自然失真图像,局部失真占据更大的比例(Su 等,2020);2)低层的语义特征包含准确的位置信息和边缘信息,但提取的语义信息较少,不能对图像信息进行全面地概括和理解。然而,人类对图像内容变化非常敏感,例如:从人类主观评价的角度,模糊的天空图像要比模糊的动物图像质量更高(Li等,2019)。并且,在HVS 中人类通常首先理解图像内容,随后才关注其他相关任务(如IQA)(Su等,2020)。
针对上述问题,本文提出基于图像特征提取、内容感知、多尺度失真类型感知和多级监督回归的BIQA方法预测图像质量分数。
本文的主要贡献如下:
1)多头位置注意力(multi-head position attention,MPA)模块对自注意力(self-attention)模块进行通道优化并添加绝对位置编码获得失真位置信息,建立特征图像素的长距离依赖关系,辅助网络对图像内容的理解,提升网络感知失真类型的性能。
2)自适应特征感知(self-adaptive feature awareness,SFA)模块结合图像内容理解,通过多尺度平均池化和特征块的重新排序,感知图像的不同失真类型,以捕获全局失真和局部失真情况。
3)多级监督回归(multi-level supervision regression,MSR)网络对深监督机制进行改进,设置可学习权重,提升网络对质量分数预测的准确度。
1 相关工作
1.1 人工失真图像质量评价
人工失真又称为模拟失真,常见的人工失真包括高斯噪声∕模糊、运动模糊及JPEG 压缩失真等,即通过人为添加各种降质因素实现图像质量退化(鄢杰斌 等,2022;Su等,2020)。针对人工失真图像,传统基于空域∕频域∕机器学习的质量评价方法一般结合图像的空域或(和)频域特征进行质量评估(Zhang和Roysam,2016;Qureshi 等,2016)。随着深度学习在计算机视觉任务方面取得成功(Krizhevsky 等,2012;He 等,2016),基于深度学习的图像质量评价方法被相继推出。Kang 等人(2014)利用CNN 进行特征提取,并结合回归网络进行质量回归。Bare 等人(2017)构建一个更深层次的DCNN,对图像质量进行预测。Ren等人(2018)利用生成对抗网络(generative adversarial network,GAN)获得参考图像,提高了预测准确性。李博文等人(2021)利用CNN 提取全局描述子集,并采用稀疏编码得到全局∕局部描述子码本,最后通过SVR预测图像质量。
由于人工失真数据库图像失真类型较为单一,上述方法在人工失真图像质量数据库上均取得了优异的结果。
1.2 自然失真图像质量评价
自然失真即在图像采集与处理过程中,由于环境、设备或人员操作不当等因素所引入的不同类型及不同程度的失真(鄢杰斌 等,2022;Su 等,2020)。如前所述,虽然基于学习的方法(尤其是基于深度学习的方法)在自然失真图像质量数据库上取得的结果优于基于空域∕频域的方法,但由于图像中失真情况复杂及内容变化大等问题,其评价性能仍有待于进一步提升(Zeng等,2017)。相关研究(Li等,2019)表明利用在大型数据库(如ImageNet)取得的预训练权重进行迁移学习可以提升IQA方法在自然失真图像质量数据库上的表现。Zhang 等人(2020)采用一种双网络架构,利用在人工失真图像质量数据库和自然失真图像质量图像库上的预训练权重,预测人工失真和自然失真图像的质量。Li等人(2019)利用多次重叠裁剪的图像通过ResNet-50(50 laryer deep residual network)进行图像质量预测。然而,上述方法只考虑了图像不同层次的空域特征信息,为了提高图像质量预测的准确性,捕获失真图像的失真类型至关重要。Su 等人(2020)利用结合ResNet-50 的混合框架,加强对局部失真类型的提取。Zhu 等人(2020)通过元学习利用已知失真类型的先验模型和双层梯度优化方法,在一些失真任务上取得了较好性能。随后,Zhu 等人(2022)提出一种基于构建合成人工失真和合成自然失真两个任务集的优化元学习方法,在评估未知失真任务上性能有所提升。然而,上述方法并未建立在充分理解图像内容变化的基础上,易导致捕获的失真类型不准确。Pan 等人(2022)利用视觉补偿模块和优化的非对称残差块构建畸变图像与其恢复图像之间的质量重建关系,提高网络应对自然失真图像内容复杂变化的能力。同样,这种结合重构图像的质量评价方法无法应对大数据库图像内容的变化,导致重构后的图像质量和原图像质量产生偏差。综上所述,虽然上述方法在内容变化不大的人工失真数据库取得了理想的评价性能,但在应对大型自然失真数据库时,因图像内容变化和失真类型多样性等挑战,方法的泛化性能仍不理想。因此,本文提出了一种新的网络框架来应对这些挑战。
2 本文方法
为解决大多数BIQA 方法对图像内容变化的适应能力及感知局部失真类型性能不足的问题,本文提出一种自适应语义感知网络(self-adaptive semantic awareness network,SSA-Net),网络结构如图1 所示。SSA-Net 能在理解图像内容的同时感知图像的不同失真类型,其工作流程包含4 个部分:图像预处理、特征提取、语义感知和多级监督回归。首先,在图像预处理阶段,方法使用多次随机裁剪的方式提取固定尺寸的图像作为输入。其次,利用在ImageNet数据库上预训练好的ResNet-50权重提取图像语义特征,并通过MPA 模块利用提取到的各层次语义特征实现内容理解。在此基础上,通过SFA 模块结合图像内容信息来感知图像的不同失真类型。最后,将各级提取的信息送入MSR 网络中进行质量分数回归,通过低层语义特征辅助监督来提高预测分数的准确性。

图1 本文方法的网络框架图Fig.1 Network architecture of the proposed method
2.1 图像预处理
来自不同数据库的图像尺寸并不统一且往往较大,而深度学习网络则要求固定尺寸的输入图像,并且输入图像的尺寸受GPU(graphics processing unit)显存容量的限制,因此,基于深度学习的方法一般需要对原输入图像的尺寸进行调整与裁剪。虽然通过对原始图像进行调整(如缩放)可以较好地保证图像的全局信息(Pan 等,2022),但会影响原始图像的质量及最终的评价结果,尤其是压缩后图像分辨率很低时。此外,图像裁剪的方法一般有两种:中心裁剪和随机裁剪(Zhang 等,2020;Su 等,2020)。然而上述两种方法提取的图像都难以覆盖整幅图像,从而导致图像信息的缺失。
针对上述问题,本文选择对原始图像进行多次随机裁剪后的多幅图像来表示原始图像的信息分布。同时,为保证对整幅图像信息的覆盖,本文对多次随机裁剪采取以下两个方案:1)通过实验比较,选择合适的裁剪尺寸及合理的裁剪次数(见3.4 节实验参数选择部分);2)当图像分辨率较高时(如BID(blurred image database)数据库中部分图像的行或列大于1 000 个像素点),则先将图像压缩至一定分辨率,即保证图像质量的同时再进行多次随机裁剪,以确保随机裁剪次数的有效性。
2.2 特征提取
输入图像通过预处理后得到一组部分重叠的图像块{I1,I2,…,In},其中n代表随机裁剪的次数。为减少网络的训练次数,并使得到的语义信息包含丰富的图像内容,本文使用ResNet-50在ImageNet上取得的预训练权重进行特征提取,得到的图像特征计算式为
式中,Sk代表ResNet-50 的第k阶段特征层,I表示裁剪后输入的图像。
通过上述方法得到的语义信息虽然可以包含丰富的图像内容,但是得到的语义特征之间难以建立联系,尤其是浅层特征卷积次数少,感受野难以覆盖整幅图像,容易导致对图像内容理解的不足。因此,本文提出了多头位置注意力(MPA)模块。不同于传统的自注意力模块(Wang 等,2018a),提出的MPA模块首先引入了瓶颈结构(Sandler 等,2018)的设计原则以提高注意力机制的性能;其次,为减少网络的计算量进行了适当的通道优化;最后,在注意力机制中嵌入绝对位置编码,以获取固定的失真位置信息,加强对图像内容的理解,并提高后续感知失真类型的准确性。如图2 所示,该结构并不局限于邻近特征,而是通过构建一个特征图谱般大小的权重,建立像素的长距离依赖关系,来理解语义特征中的内容信息。首先,对输入特征进行降维操作,具体为

图2 多头位置注意力模块Fig.2 Multi-head position attention module
式中,输入特征F∈RH×W×C,H和W分别是输入特征图的高和宽,C是通道数。X∈RH×W×C∕g,g代表降维的比例,f(·)代表1 × 1卷积。

表1 用于对比实验的7个公开图像质量评价数据库Table 1 The seven public IQA databases for comparative experiments
然后,通过一组可学习的权重矩阵WQ,WK,WV得到3个包含输入信息的矩阵。具体为
接着,对上述矩阵进行位置编码嵌入和信息交互,并将两者相加得到
式中,WP∈RH×W×C∕g代表位置编码,AP、AC代表得到的包含固定失真位置信息的相关矩阵和内容信息相关矩阵。
为体现不同内容的重要性,对得到的包含失真位置信息和内容信息的相关矩阵APC进行softmax 函数归一化,并与V进行特征聚合。
最后,将聚合后的矩阵进行升维,并与输入相加以构建包含不同特征的长距离依赖关系,实现对特征图内容的理解。
上述整个过程可表示为
式中,Y∈RH×W×C代表输出特征。
2.3 语义感知
在图像质量较高的时候,HVS 更倾向于图像的局部失真(Su 等,2020),并且大部分自然失真图像均由多个失真类型不一的局部失真构成。因此,感受野固定的CNN 模型并不符合HVS 感知图像质量的方式。受Zhu 等人(2019)的启发,本文设计了一种更适用于图像质量评价任务的多尺度感知模块来应对失真类型多样性的挑战。虽然利用不同空洞率的卷积核获取不同感受野下多尺度信息的空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)也可以实现相似的功能,从而在一定程度上提高获取全局失真的性能,但在图像质量评价任务中,这种间隔像素点采样的方法容易导致局部信息丢失和信息在长距离上的不相关性(Wang 等,2018b),因此,不利于获取局部失真类型。针对上述问题,提出了如图3 所示的自适应特征感知模块(SFA)以替代传统的3 × 3卷积运算,即使用不同尺度的池化内核感知失真类型,并采用线性模块对得到的特征进行重新排布和线性变化,筛选出包含失真信息的最少特征块,以减少网络计算量和提升感知失真类型的准确性。

图3 自适应特征感知模块Fig.3 Self-adaptive feature-aware module
在理解图像内容的前提下,SFA 模块首先将输入特征X∈RC×H×W输入到一个1 × 1 卷积中进行通道缩减,以减少计算量。接着,进行多分支平均池化bi(i=1,2,3,4)来捕获不同失真类型,其中,b1采用全局平均池化,对全局失真类型进行感知。b2,b3,b4分别利用内核大小为3、5、7的平均池化捕获图像不同尺度的局部失真类型。随后,将不同分支获取的特征图划分为多个不重叠的特征块,沿着通道维度进行叠加,并对叠加的特征块进行一次线性变换,以获取不同失真类型。最后,将这些一维向量进行拼接,送入回归网络中。整个过程可以表示为
式中,Y∈R1×N代表维度为N的一维向量,Linear(·)代表线性变换,F(·)代表对特征图的重新排布,Pooli代表内核大小不同的平均池化。
2.4 多级监督回归
为避免梯度消失并增强网络的鲁棒性,深监督网络(deeply-supervised nets)(Lee 等,2015)提出一种新颖的监督机制,在网络早期的多个阶段加入损失函数,以产生辅助的局部映射,提升网络性能。同样,CSC-Net(scale and context sensitive network)(Wu等,2021)通过对侧面输出层设置固定的权重来强调不同阶段映射出特征的重要性。因此,为了获取更符合HVS 的分数,本文设计一种多级监督回归(MSR)网络,其结构如图1 所示(α,β,γ表示可学习参数)。该网络通过对输出层的不同阶段设置自适应权重以改进深监督机制。
虽然浅层特征感受野较小,但能获取更多的局部细节信息,有利于对局部失真信息的获取。因此,MSR 对ResNet-50 每个阶段的输出均采用两层的全连接进行回归,并且不同阶段的全连接层使用权重共享的方式避免引入过多的参数。其次,对浅层特征回归的分数分别设置一个可学习权重,使浅层特征辅助监督,从而提高预测准确性。整个过程可表示为
式中,xi代表ResNet-50 低层特征阶段,λ代表可学习的权重,L(·)代表全连接网络回归层,x4代表网络深层特征。
3 实验与结果分析
3.1 实验细节
本文代码的基础框架是Pytorch1.8.0,对模型训练与测试的实验平台为GeForce RTX3090,显存容量为24 GB。特征提取模块选用ResNet-50,初始化为ImageNet 数据库上预训练的权重。因此,在训练和测试期间,对图像进行25次224 × 224像素的随机裁剪,损失函数使用L1损失。其他模块的卷积与全连接层分别使用Kaiming 初始化(He 等,2015)和正态分布初始化,梯度下降使用Adam 优化器。特征提取模块的学习率是2 × 10-5,其他模块的学习率为2 × 10-4,并且每隔5 轮学习率下降为原来的一半,最小批量大小为64,迭代次数为30轮。
3.2 数据库
为充分验证模型的性能,在7 个公开的图像质量数据库上进行测试,如表1 所示。实验中,共使用4 个自然失真图像质量数据库:LIVEC、BID(Ciancio等,2011)、KonIQ-10k 和SPAQ(smartphone photography attribute and quality)(Fang 等,2020),其 中LIVEC 和BID 均来自真实世界不同场景、不同曝光和相机镜圈产生的图像,分别包含1 162 幅和586 幅图像。KonIQ-10k 的图像来自于YFCC 100m(Yahoo flickr creative commons 100 million)大型公开数据库,包含10 073 幅不同类型的失真图像。SPAQ 数据库由66 部智能手机在不同的视觉场景下拍摄得到的11 125 幅自然失真图像组成。
同时,实验中引入3 个人工失真图像质量数据库。其中LIVE 和CSIQ 分别由29 幅和30 幅参考图像产生共779 幅和866 幅不同失真类型的图像。而Waterloo Exploration 数据库(Ma 等,2016)则是由4 744幅参考图像生成的94 880幅合成图像组成。
3.3 评价指标
在方法性能评估方面,采用两个常用的评价指标:斯皮尔曼等级相关系数(Spearman rank-order correlation coefficient,SRCC)和皮尔逊线性相关系数(Pearson linear correlation coefficient,PLCC)来衡量预测分数的准确性。两个评价指标的数值越接近于1,表明方法评价结果越接近主观评价分数。SRCC及PLCC分别计算为
式中,N表示数据库中的图像数量,di代表第i幅主观图像与客观图像的秩差。si代表第i幅主观图像得分,代表所有si的平均值,fi代表第i幅预测得分,代表所有fi的平均值。
在实验中,数据库中80%的随机数据作为训练集,其余20%的数据作为测试集。同时,为充分体现方法的性能,每个数据库的实验重复10 次,最后的结果取10次结果的中值。
3.4 实验参数讨论
3.4.1 裁剪尺寸对网络性能的影响
对所有输入图像进行多次随机裁剪以表示图像信息,并用于后续图像质量评价值的计算。由于裁剪尺寸会影响网络的评价性能和运行时间,因此针对裁剪尺寸进行对比实验,不同的裁剪尺寸在LIVEC 数据库上的结果如表2 所示,其中,不同裁剪尺寸的运行时间通过测试所有输入图像并取平均得到。从实验结果可以看出,当裁剪尺寸小于224 ×224 像素时,网络性能出现比较明显的下降,而增加裁剪尺寸对网络性能的提升并不明显,但会增加网络的运行时间。综合上述因素,本文选取224 × 224像素作为输入图像的裁剪尺寸。

表2 不同裁剪尺寸在LIVEC数据库上的测试结果Table 2 Results on LIVEC database for different crop sizes
3.4.2 不同的裁剪次数对网络性能的影响
为寻找合适的随机裁剪次数以覆盖整幅图像信息,实验中在LIVEC 数据库上使用不同的随机裁剪次数n(其中,n=1,5,10,15,20,25,30,35),对比不同裁剪次数对网络性能的影响,最终结果如图4所示。从统计结果可以看出,在裁剪次数n∈(1,10)时,随着裁剪次数增加,覆盖的信息能力增加,网络性能大幅度上升。当裁剪次数n∈(10,25)时,由于裁剪的随机性,裁剪得到的图像还不能完整地表示原始图像信息,导致评价结果上下波动。当裁剪次数n∈(25,35)时,虽然裁剪仍然具有随机性,但多次裁剪结果已经基本可以完整表述原始图像信息,评价结果趋于稳定。考虑到增加随机裁剪的次数会导致运行时间增加,本文对原始图像进行25 次随机裁剪。
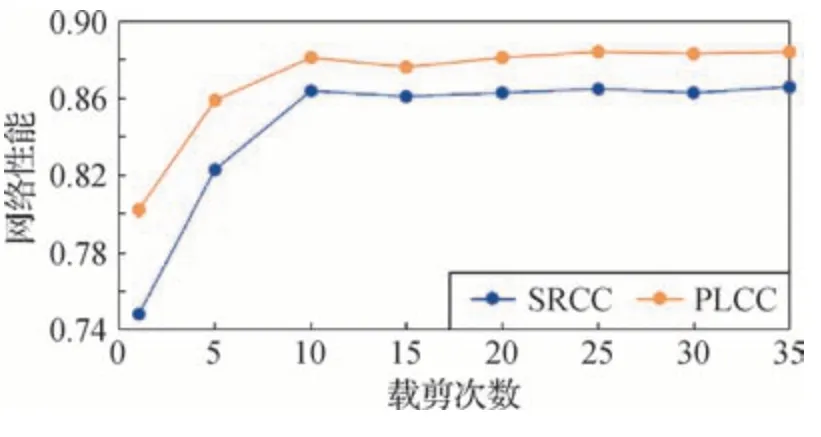
图4 裁剪次数实验结果对比Fig.4 Comparison of experimental results obtained via different cropping times
3.4.3 MSR模块加权策略对网络性能的影响
为验证MSR 模块的加权策略对网络性能的影响,在LIVEC 数据库上设置不同的超参数λi(数值从0 开始)进行实验。相对于不采用加权的方式,通过对不同特征层进行数值加权,更有利于表征不同层次特征信息对质量评价的贡献,实验结果如表3所示,其中,w∕o MSR 表示无MSR 模块,训练结果为网络最后一层线性回归得出的结果。w MSR 表示有MSR 模块得到的预测结果。从表3 可以看出,当λi数值高时(λi=0.7),则更强调对应层次的特征信息。较多的高层信息(λ1=0.7)辅助深层特征网络回归时,冗余的深层语义特征对评价效果的提升并不明显。同样,当浅层信息较多时(λ3=0.7),过多的边缘信息会影响深层特征在线性回归中的作用,因此,网络性能的提升同样不明显。而当λi数值较均衡时(λ1=0.4,λ2=0.3,λ3=0.3),网络性能得到了一定程度的提升,但其性能仍不如MSR 模块表现优异(如图1 所示,当λ1=α,λ2=β,λ3=γ时,参数均为通过学习得到的数值)。因此,手动调整λi数值难以平衡各个阶段信息的重要性,导致最后结果出现不同程度的偏差。而设置可学习参数能使网络更好地融合不同阶段的信息,提升网络的性能。

表3 MSR模块中不同加权策略在LIVEC数据库上的性能比较Table 3 Performance comparison of different weighting strategies in the MSR module on LIVEC database
3.5 不同图像表示方法的比较
由于使用预训练ResNet-50 模型作为特征提取网络,因此,SSA-Net 需要固定输入图像的尺寸。考虑到不同数据库中图像尺寸不一致以及GPU 显存容量的限制,实验分别使用中心裁剪图像、固定尺寸缩放图像和多次随机裁剪图像进行对比实验。同时,实验中增加384 × 384 像素这一尺寸进行对比,实验结果如表4所示。从表4中可以看出,中心裁剪方式由于损失大量图像信息,导致网络性能最差,但随着裁剪尺寸的增加,性能有所提升。固定尺寸缩放方式由于保留了大部分原图像信息,其效果优于中心裁剪方式,且性能随着缩放尺寸的增大有所提升。多次随机裁剪方式虽然每幅裁剪后的图像尺寸较小,但由于经过多次裁剪且未对图像进行缩放(当图像尺寸较小时),较好地保留了原图像的信息,其性能明显优于前面两种方法。
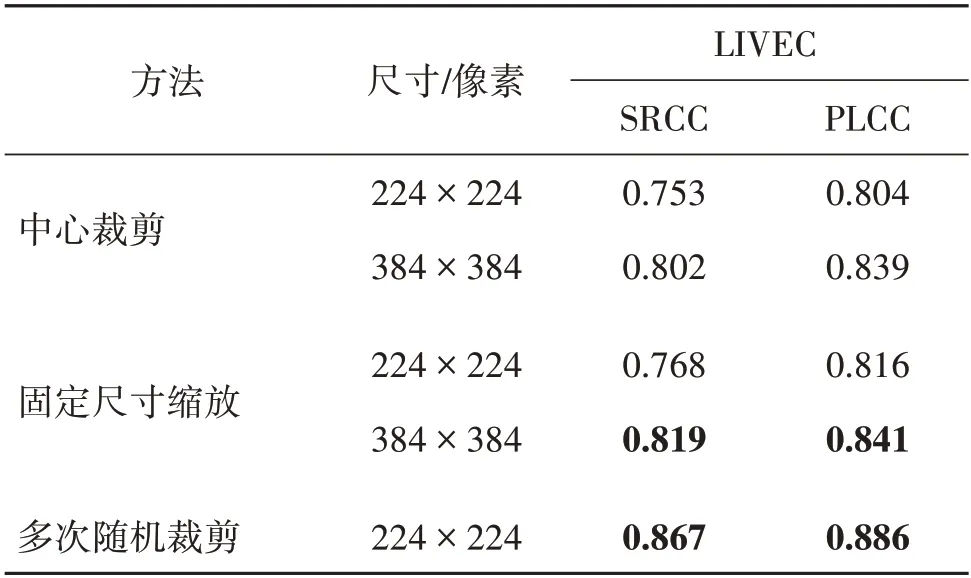
表4 不同图像表示方法在LIVEC数据库上的结果Table 4 Results of different image representation methods on LIVEC database
3.6 消融实验
为验证SSA-Net 各个组件的有效性,设计了一系列在LIVEC数据库和LIVE数据库的消融实验,不同组件的统计结果如表5 所示。其中,Baseline 表示只有ResNet-50的预训练权重网络。

表5 LIVEC数据库和LIVE数据库消融研究的统计比较Table 5 Statistical comparison of ablation studies on LIVEC database and LIVE database
首先,将MPA 模块加入到Baseline 中形成“Baseline+MPA”结构。针对SRCC、PLCC 结果,在LIVEC 数据库上与“Baseline”相比,“Baseline+MPA”的组合将网络性能从83.1%、85.0%提升至84.9%、86.2%。在LIVE 数据库上,“Baseline+MPA”的组合将SRCC、PLCC 的结果增加了1.4%、1.0%。这表明对图像内容的理解有助于提升评价性能。
其次,进一步将SFA 模块嵌入到“Baseline+MPA”中,形成“Baseline+MPA+SFA”结构。从表5可以看出,针对SRCC∕PLCC 结果,添加SFA 后的网络在LIVEC 数据库上增加了0.6%、1.6%,在LIVE 数据库上增加了0.6%、0.7%。这表明捕获不同尺度的局部失真位置信息可以提升评价准确性。
最后,为证明MSR 的有效性,将MSR 嵌入网络中,形成本文所提出的SSA-Net。从表5 的统计结果可以看出,结合了上述3 个模块的SSA-Net 在LIVEC数据库和LIVE 数据库中均取得了最优的结果。这表明利用深监督机制,使用低层特征辅助网络回归有利于提高网络的性能。
3.7 与其他方法对比
为凸显本文方法的优越性,实验中选取了11 种具有代表性且性能良好的BIQA 方法进行比较,包括:BIECON(blind image evaluator based on a convolutional neural network)(Kim 和Lee,2017)、WaDIQaM(weighted average deep image quality measure)(Bosse等,2018)、SFA(NR-IQA method based on semantic feature aggregation)(Li 等,2019)、PQR(probabilistic quality representation approach to deep blind image quality prediction)(Zeng 等,2017)、DB-CNN(deep bilinear convolutional neural network)(Zhang 等,2020)、HyperIQA(self-adaptive hyper network)(Su等,2020)、MetaIQA(meta-learning based image quality assessment)(Zhu 等,2020)、IE-IQA(intelligibility enriched generalizable no-reference image quality assessment)(Song 等,2021)、UNIQUE(uncertaintyaware blind image quality assessment)(Zhang 等,2021)、MetaIQA+(meta-learning-based IQA plus)(Zhu 等,2022)和VCRNet(visual compensation restoration network)(Pan 等,2022)。实验中对比方法的结果来自于文献中最优的数据,缺失的部分结果使用作者提供的源代码与训练权重进行测试,其中部分论文并未公开源代码。
3.7.1 不同数据库上的性能比较
为体现方法在不同数据库中的评价性能,将SSA-Net与其他方法在同一个数据库进行性能比较,如表6所示。

表6 不同方法在6个图像质量评价数据库上的性能比较Table 6 Performance comparison of different methods on six IQA databases
WaDIQaM 和BIECON 实现端到端的图像质量评价,在自然失真数据库中SRCC 和PLCC 值并不理想。SFA、PQR、DB-CNN、HyperIQA、VCRNet 这5 种方法均利用预训练权重,在自然失真图像质量数据库中取得了较好的结果,但性能仍然表现不足。主要原因如下:SFA 的自适应层选择(adaptive layer selection)忽略了低层特征中丰富的细节信息,DBCNN 缺少捕获局部失真的模块,HyperIQA 的低层特征难以正确理解图像内容,VCRNet构建的畸变图像与其恢复图像之间的质量重建关系依然难以适应自然失真图像的变化。MetaIQA和MetaIQA+缺少对图像内容理解作为先验知识。IE-IQA 的输入图像的尺寸为缩放的224 × 224 像素,虽然在训练速度上有所提升,但是对于原图像尺寸较大的SPAQ 数据库(常见尺寸为4 000 × 3 000 像素),这种缩放的插值算法会导致新的图像失真,改变原图像的图像质量分布。而本文方法则针对上述问题进行了改进,因此,本文所提出的SSA-Net 在4 个自然失真数据库(LIVEC、BID、SPAQ 和KonIQ-10k)中取得的评价结果均优于其他方法。
在人工失真图像质量数据库中,基于深度学习的方法在这两个人工失真图像质量数据库中均获得了优异结果,其中VCRNet 及WaDIQaM 分别在LIVE及CSIQ 数据库上取得了最好的评价结果。而SSANet 虽然没有添加额外的人工失真权重(如DBCNN)或其他关于人工失真的处理模块,但在人工失真图像质量数据上的评价结果仍具有一定的优势。其中,在LIVE 数据库上的SRCC 值仅低于VCRNet,在CSIQ数据库的性能也仅次于WaDIQaM。
3.7.2 不同失真类型的性能比较
为体现本文方法在不同失真类型图像上的性能优势,实验将SSA-Net 与其他先进方法在LIVE 数据库的5 种失真类型(JP2K、JPEG、WN、GB 和FF)和在CSIQ 数据库的6 种失真类型(WN、JPEG、JP2K、FN、GB 和CC)上分别进行性能比对,实验结果如表7 所示。与其他BIQA方法相比,本文网络仍获得了较为优异的性能。尤其在LIVE 数据库的JP2K、WN、GB和CSIQ数据库的各类单一失真类型的人工失真图像中,本文方法均取得了优异的结果。这表明,本文方法提出的在理解图像内容前提下结合低层语义信息的结构在处理均匀的人工失真图像时仍具有优势。

表7 在LIVE数据库和CSIQ数据库上的单一失真SRCC结果Table 7 Single distortion SRCC results on LIVE database and CSIQ database
3.7.3 泛化性能比较
为验证本文提出网络的泛化性能,本节采用上述实验中效果最好的几个先进方法进行不同失真图像质量数据库之间的交叉测试。跨数据库测试的SRCC结果如表8和表9所示。结果显示,SSA-Net在多个自然失真图像质量数据库测试验证中取得了理想的结果,尤其是在超大自然失真图像质量数据库KonIQ-10k中训练的模型,在LIVEC 数据库和BID 数据库测试中均得到了最高的SRCC 值,这表明SSANet 在大型自然失真图像质量数据库捕获丰富的语义信息后,更容易在小型自然失真图像质量数据库上获得良好的评价结果。同时,从表9 可以看出,SSA-Net 在人工∕自然图像质量评价数据库交叉测试中也获得了良好的评价结果。这表明本文为自然失真图像质量评价所设计的方法同样适用于人工失真图像,并且能取得优异的评价结果。
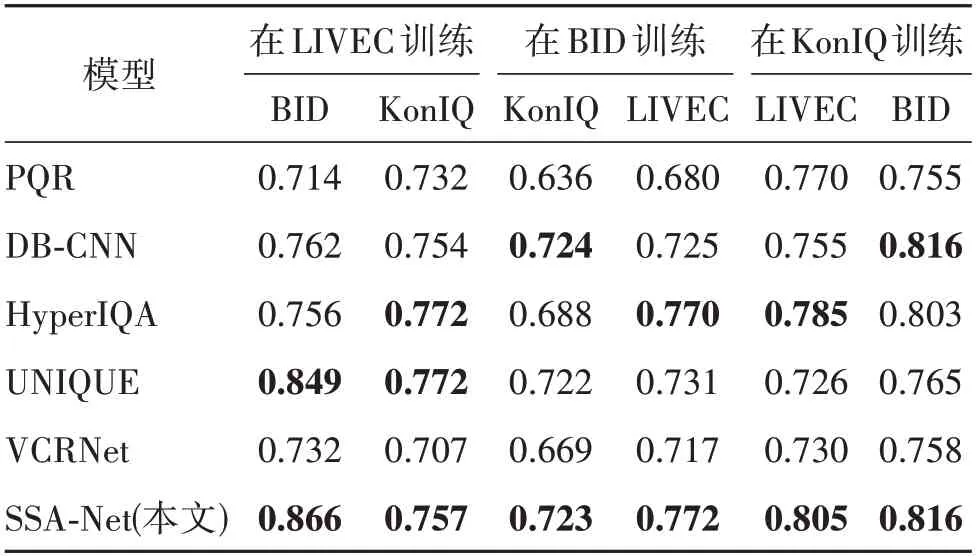
表8 自然失真图像质量数据库交叉验证的SRCC值Table 8 SRCC results for cross validation with authentically distorted image databases
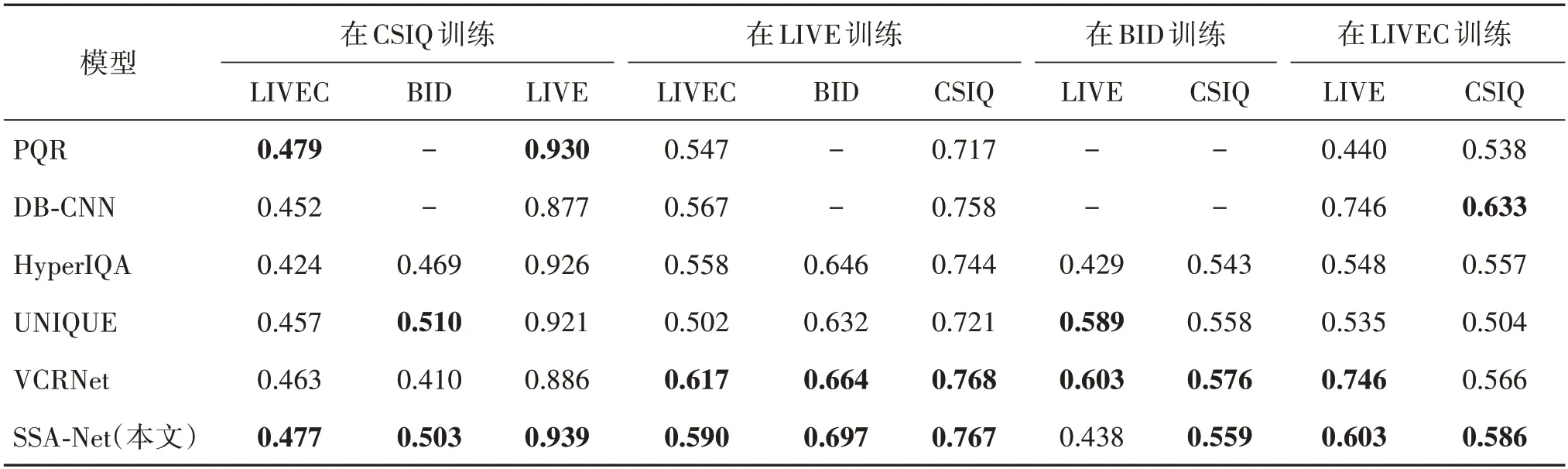
表9 不同图像质量评价数据库交叉验证的SRCC值Table 9 SRCC results for cross validation with different IQA databases
3.7.4 在Waterloo Exploration 数据库上的性能比较
由于真实世界的失真图像是不计其数的,传统的评价指标在有限的数据中评估IQA模型的性能缺乏一定的客观性。因此,本文利用各个模型在同等条件下获取CSIQ 数据库中的预训练模型,得到在Waterloo Exploration 数据库中的预测MOS 值进行gMAD 竞赛(Ma 等,2017)。gMAD 通过进攻方IQA模型从防守方IQA模型预测相同等级的图像中挑选出预测的最大差异图像来评判两种模型的鲁棒性,实验结果如图5 所示。当SSA-Net 作为进攻方IQA模型时,与VCRNet 模型预测的结果相比,同等级图像差异较大,对高质量和低质量等级图像的预测分数更符合主观评价,这表明SSA-Net 具有更强的鲁棒性,如图5(a)与图5(b)所示。SSA-Net 作为防守方在图5(c)中成功抵御VCRNet 的进攻,而在图5(d)中可以看出,SSA-Net 预测的两幅图像并不在一个等级内,这表明由于没有加入处理人工失真的模块,SSA-Net对高斯模糊的评价性能仍有所欠缺。从图6可以看出,SSA-Net在与HyperIQA 的gMAD 竞赛中,无论处于进攻方还是防守方均能给出正确的预测结果。

图5 VCRNet和SSA-Net在Waterloo Exploration 数据库上的gMAD竞争结果Fig.5 gMAD competition results of VCRNet and SSA-Net on Waterloo Exploration database((a)SSA-Net as attacker at the high-quality level;(b)SSA-Net as attacker at the low-quality level;(c)SSA-Net as defender at the high-quality level;(d)SSA-Net as defender at the low-quality level)

图6 HyperIQA和SSA-Net在Waterloo Exploration 数据库上的gMAD竞争结果Fig.6 gMAD competition results of HyperIQA and SSA-Net on Waterloo Exploration database((a)SSA-Net as attacker at the high-quality level;(b)SSA-Net as attacker at the low-quality level;(c)SSA-Net as defender at the high-quality level;(d)SSA-Net as defender at the low-quality level)
4 结论
本文提出一种基于自适应语义感知网络的盲图像质量评价方法来应对评价自然失真图像的两个挑战:图像内容的变化和图像失真类型的多样性。方法模仿人类感知图像质量的方式,提出多头位置注意力模块来帮助网络理解图像内容,并在理解图像内容的基础上提出自适应感知模块来捕获全局及局部图像的不同失真类型,最后提出多级监督回归得到准确的质量分数。
在不同图像质量数据库上的实验结果和交叉验证的实验结果表明,本文方法在真实图像质量数据库上的评价质量分数更接近人类主观评价结果,并且具有更强的泛化能力,进一步提升了BIQA方法在自然失真图像质量数据库上的评价性能。同时,本文方法也在人工失真图像质量数据库上取得良好的评价性能。
虽然方法通过结合裁剪尺寸及次数的方式保证对图像信息的覆盖,但仍可能存在极端情况下,即原始图像中部分信息的缺失与部分图像信息的过度冗余。同时,多次裁剪图像的操作增加了方法的计算量。因此,如何保证输入网络时图像信息的完整性及方法的实时性有待于进一步的研究。
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13
家庭影院技术(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
