
深度学习背景下的图像语义分割方法综述
2023-11-22 01:18严毅邓超李琳朱凌坤叶彪
中国图象图形学报 2023年11期
严毅,邓超*,李琳,朱凌坤,叶彪
1.武汉科技大学汽车与交通工程学院,武汉 430063;2.武汉科技大学计算机科学与技术学院,武汉 430063;3.武汉理工大学交通与物流工程学院,武汉 430063
0 引言
计算机视觉的研究和各项相关技术取得了长足的进步。图像分类、目标检测和图像语义分割(image semantic segmentation,ISS)是目前计算机视觉领域的3个热点研究方向,如图1所示。图像语义分割是计算机视觉的经典任务,概念由Ohta 于1980年首次提出,其定义为:给图像中的每一个像素分配一个预先定义好的表示其语义类别的标签(Csurka和Perronnin,2011),从定义可以看出图像语义分割的实质是实现图像的场景理解。从实际应用层面来看,在自动驾驶、计算摄影、人机交互、图像搜索引擎和虚拟现实等领域都可以看见图像语义分割技术的身影,国内外许多大型科技公司(如谷歌、百度等)以及初创公司(如商汤、旷视等)也都在语义分割相关领域投入了大量财力物力。

图1 从粗粒度到细粒度的推理演化:分类、检测或定位、语义分割Fig.1 Inference evolution from coarse-grained to fine-grained:classification,detection or localization,semantic segmentation((a)image classification;(b)target detection;(c)image semantic segmentation)
全球众多的科研实验室针对基于深度学习的图像语义分割开展了研究工作,关于自动化、人工智能和模式识别领域的学术会议也对基于深度学习的语义分割研究成果做了报告。与传统的图像分割相比,基于深度学习的图像语义分割存在不小的优势,不仅能够充分地挖掘图像所蕴含的像素特征,也可以利用图像自身的场景和高级语义特征推理出图像所表达的信息,在分割准确度和效率方面远远超过传统方法。现代深度学习体系对图像语义分割的处理过程是一个从粗推理到细推理的自然步骤,其目标是对图像的每个像素进行密集预测并推断其所属标签。一般情况下,基于深度学习的图像语义分割都要经过以下3 个处理模块:特征提取模块、语义分割模块和精细化处理模块,处理流程如图2 所示,图中虚线表示选择处理步骤。

图2 基于深度学习的图像语义分割处理流程Fig.2 Image semantic segmentation process based on deep learning
据谷歌学术显示,研究者近10 年来在语义分割方面发表的论文超过12 000 篇,但是国内详细总结基于深度学习的语义分割方法的综述文献依旧较少,鉴于此,本文对近年相关研究成果做了系统梳理论述。
1 开源数据集与语义分割方法
1.1 常用的开源数据集
数据集是算法研究的先决条件,全球的部分科研机构、大型公司以及比赛项目开源了不少的大规模数据集,极大地推动了相关领域的发展。可用在图像语义分割方面的数据集按照图像数据性质可分为3 类:2D 数据集、RGB-depth(2.5D)数据集和3D数据集。
1.1.1 2D数据集
图像语义分割的研究主要集中在二维图像上。较为流行的2D数据集如下:
1)PASCAL VOC(pattern analysis,statistical modeling and computational learning visual object classes)(Everingham 等,2015)。PASCAL VOC 是国际著名的计算机视觉挑战赛,其开源的RGB 数据集均带有标签,可用于5 种不同的比赛:分类、检测、分割、动作分割和人员布局。VOC 2012是最常用的数据集,有21 个类别,训练集和验证集共包括11 530幅图像。
2)PASCAL Context(Mottaghi等,2014)。PASCAL Context 是由PASCAL VOC 2010 数据集扩展而来的,包含所有训练图像的像素级标签(10 103),该数据集共有540 个语义类别,但是通常选择由59 个语义类别组成的子集进行训练研究,而将其余语义类别标记为背景。
3)PASCAL Part(Chen 等,2014)。该数据集同样是PASCAL VOC 2010 的扩展,PASCAL VOC 的原始类被保留,但是将原始类划分得更细,例如,将自行车分解为车把、前轮、后轮、链轮和鞍座。PASCAL Part 分为训练集、验证集和测试集,每幅图像都有像素级标注,可以提供精细的语义信息。
4)SBD(semantic boundaries dataset)(Hariharan等,2011)。该数据集是从整个PASCAL VOC 比赛(不仅是分割比赛)中获得的,包含PASCAL VOC 2011 的11 355 幅标注图像,训练集有8 498 幅图像,验证集有2 857 幅图像。其除了注释每个对象的边界之外,同时提供了类别级别和实例级别的信息。由于其训练数据量增加,该数据集经常被用来代替PASCAL VOC进行深度学习。
5)COCO(Microsoft common objects in context)(Lin等,2014)。该数据集是微软公司开源的用于图像识别、语义分割的大型数据集。COCO 包含80 多个类别,训练集有82 783幅图像,验证集有40 504幅图像,测试集超过80 000幅图像。特别地,测试集又划分为4 个不同的子集:test-dev、test-standard、testchallenge和test-reserve,每个子集有具体的功能。
6)SYNTHIA(SYNTHetic collection of imagery and annotations)(Ros等,2016)。SYNTHIA是虚拟城市的大规模真实感知效果图集合,常用于驾驶领域的语义分割。拥有11 个类,提供了细粒度的像素级标注,训练图像有13 407 幅。数据集还具有丰富的场景学习,包括不同的地点、季节和天气。
7)Cityscapes(Cordts 等,2016)。Cityscapes 是一个专注于城市街景语义理解的大型数据集,该数据集分为8 个大类,30 个子类,提供了语义、实例和密集的像素标注。具有5 000 多幅精细标注图像和20 000 幅粗标注图像。其最初是作为视频录制的,采集了50 个城市几个月的情景,有大量的动态对象和场景布局。
8)CamVid(Brostow 等,2009)。CamVid 也是一个适应于驾驶领域的道路场景理解数据集,利用仪表盘上的摄像机采样出701帧图像,共有32个类。
9)KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)(Geiger 等,2013)。KITTI 是用于机器人和自动驾驶领域的最著名数据集之一。包含了由3 种传感器(高分辨率RGB、灰度立体摄像机和3D 激光扫描仪)记录的几个小时的交通场景,最初该数据集是没有标注的,后来由多个研究者分别进行了标注。
10)Youtube-Objects(Prest 等,2012)是一个从Youtobe 收集的视频数据集,其中包含10 个来自PASCAL VOC的类,图像分辨率为480 × 360像素。
11)Adobes Portrait Segmentation(Shen 等,2016)。其主要收集的是人像图像,图像分辨率为800 × 600 像素,训练集由1 500 幅图像组成,测试集由300 幅图像组成。该数据集是用半自动方式标注的,非常适合前景分割领域。
12)MINC(materials in context)(Bell 等,2015)。MINC 是一个用于贴片材料分类和全场景材料分割的数据集,提供了23 个类别:木材、玻璃、金属等。训练集有7 061幅图像,测试集有5 000幅图像,验证集有2 500 幅图像,图像分辨率约为800 × 500 像素或500 × 800像素。
13)DAVIS(densely-annotated video segmentation)(Perazzi等,2016)。DAVIS用于视频对象分割,数据集由50 个高清晰度序列组成,每一帧都提供了4 个不同类别的像素级注释:人类、动物、车辆和物体。
14)Stanford background(Gould 等,2009)。该数据集主要是户外场景图像,是从LabelMe、MSRC、PASCAL Voc 和Geometric Context 4 个数据集中获取的,包含715幅图像,尺寸为320 × 240像素。
15)SiftFlow(Liu 等,2009)。包含2 688 幅完全注释的图像,大多来自于LabelMe 数据集,包括街道、山脉、田野、海滩和建筑等8个不同的语义类别。
1.1.2 2.5D数据集
1)NYUDv2(Silberman 等,2012)。该数据集是用微软Kinect设备捕获的,共有1 449幅关于室内物体的2.5D图像,训练和测试集分别有795幅和654 幅图像,提供类别和实例级别的标注。该数据集特别适合室内工作的机器人,然而相对于其他数据集规模较小。
2)SUN3D(Xiao 等,2013)。SUN3D 是一个大规模2.5D 数据库,包含8 个注释序列,图像产生于41 个不同建筑中的254 个空间,一些地方在一天中的不同时刻多次拍摄。
3)SUNRGBD(Song 等,2015)。该数据集由10 000 幅2.5D 图像组 成,其来自NYU depth v2、Berkeley B3DO和SUN3D 3个数据集。
4)OSD(object segemntation database)(Richtsfeld,2012)。OSD 数据集中的大多数物体是存在部分遮挡的,专门用来评估分割方法。
5)RGB-D Object Dataset(Lai等,2011)。该数据集由300 个视频序列组成,分为51 个关于室内场景的类别。数据集是使用3D摄像机以30 Hz的频率拍摄的,每一帧的分辨率为640 × 480像素。
1.1.3 3D数据集
生成用于分割的大规模3D 数据集是非常困难的,也并没有很多的深度学习方法能够处理3D 数据。由于这些原因,3D 数据集目前不是很流行。尽管如此,依然有必要总结几个比较有名的3D 数据集,今后的研究工作更要重视。
1)ShapeNet Part(Yi 等,2016)。该数据集专注于细粒度的3D 对象分割,包含从16 个类别的原始数据集中采样的31 693个样本。数据集中的每个目标类都用2~5 个部件进行标记,例如飞机类用机翼、机身、尾部和引擎标记。
2)Stanford 2D-3D-S(Armeni 等,2017)。是一个多模态的大规模室内空间数据集,它提供的数据包括2D、2.5D 和3D(网格和点云)形式,由70 496幅完整的高清RGB图像(分辨率1 080 × 1 080像素)以及对应的深度图、表面法线、网格和点云(带有语义标注)组成,共有13 个类别。其是从6 个室内区域的271个房间采集的。
3)A Benchmark for 3D Mesh Segmentation(Chen等,2009)。该数据集一共分为19 个类别,380 个网格,每个网格都被人工划分为功能区,其主要目标是提供划分示例。
4)Sydney Urban Objects Dataset(Quadros 等,2012)是用Velodyne HDK-64E LIDAR 激光雷达扫描的,包含各种常见的城市道路物体,对车辆、行人、标志和树木进行了631 次单独点云扫描,而且还提供了完整的360°注释扫描.
5)Large-Scale Point Cloud Classification Benchmark(Hackel等,2016)。该数据集提供了各种自然、城市场景的人工注释3D 点云,静态捕捉的点云,具有非常精细的粒度,包含30 个大规模点云,15 个用于训练,15个用于测试。
1.2 面向2D数据的语义分割方法
目前,基于深度学习的2D图像语义分割方法有很多种,从方法特点上可分为3 类:基于候选区域的图像语义分割方法、全监督学习图像语义分割方法和弱监督学习图像语义分割方法。
1.2.1 基于候选区域的图像语义分割方法
基于候选区域的图像语义分割法由Carrerira 等人(2012b)首次提出,该方法先是利用区域生成算法在图像中生成一系列自由格式的候选区域(其中的每个候选区域都有可能包含潜在的目标物体),并利用卷积神经网络(convolutional neural network,CNN)对候选区域的图像特征和语义信息进行提取,再对这些区域进行分类,之后把关于分类区域的预测转化成关于像素的预测,像素得分最高的区域即可进行标签。基于候选区域的语义分割方法中,具有代表性的有RCNN(Girshick 等,2014)、SDS(Hariharan等,2014)、MPA(Liu等,2016)和Mask-RCNN(He等,2018)等。
Carrerira 等人(2012b)运用CPMC(constrained parametric min-cut)算法来生成候选区域,并计算候选区域属于某类标签的概率大小,从而得出分割结果。于此之上,Carrerira等人(2012a)将SOP(secondorder-pooling)算法应用在了特征提取阶段(SOP 算法能够将区域的局部特征进行聚合),进一步提高了分割精度。Girshick 等人(2014)提出了区域卷积神经网络模型(region-based convolutional neural network,RCNN),RCNN 通过SS(selective search)算法(Uijlings 等,2013)提取候选区域,既能够进行目标检测,也可以完成语义分割。SS 算法把候选区域的尺寸设置为227 × 227 像素,之后再利用卷积神经网络提取每个候选区域的特征,基于所提取的特征,利用支持向量机对其分类,得出最终的语义分割结果。RCNN 的缺点是:对候选区域具有较高的依赖性、语义分割精度较低、不能实时分割。Hariharan 等人(2014)在RCNN 算法基础上加入了SDS(simultaneous detection and segmentation)网络,SDS 网络能够采用MGG(multi-scale combinatorial grouping)算法(Arbelaze 等,2014)在候选区域和区域前景中自主提取语义特征,再交替训练所提取的两部分语义特征,最后运用非极大值抑制方法进行区域增强。MGG 算法对输入图像的像素大小不设限制。此工作的贡献在于扩展了算法的适用范围,且提高了语义分割性能。
之前的工作均是在RCNN 网络的基础上进行的,鉴于RCNN 有网络运算量大、产生的候选区域太多、生成速度慢以及生成的形状不统一等等不足,一些学者提出了Fast-RCNN 算法。Fast-RCNN 网络(Girshick,2015)将候选区域映射到卷积神经网络的特征图上,利用ROI池化层产生固定大小的特征图,候选区域的生成速度有了显著提升。Ren 等人(2015)提出了Faster-RCNN 网络,其利用区域建议网络(region proposal network,RPN)来快速生成候选区域,所产生的候选区域可以与检测网络共享卷积特征,对候选区域的产生速度和分割精度有了显著提升,缺点是对候选区域中的感兴趣区域不够敏感。Caesar 等人(2016)以Fast-RCNN 为基础提出基于区域的端到端图像语义分割算法,着重考虑了候选区域的感兴趣区域,通过自由形式的池化层捕捉其前景特征,兼顾上下文语境信息和区域的自由表示,可以更鲁棒的处理分割任务。He等人(2018)将ROI与分割子网络加入了Faster-RCNN 算法,提出了Mask-RCNN 算法,Mask-RCNN 可以完成目标检测和实例分割。Mask-RCNN 主干由两部分构成,第1 部分为Faster-RCNN,其主要功能是对候选区域进行分类和回归,从而实现目标物体的高效检测;第2 部分通过一个小型全卷积网络完成实例分割任务。Mask-RCNN的提出对图像语义分割领域做出了重大贡献。
总体来说,基于候选区域的图像语义分割方法具有以下优缺点。优点为:使用目标检测技术生成候选区域,可以同时完成目标检测任务和语义分割任务。缺点为:分割过程对候选区域过于依赖;不能充分地考虑图像中的全局语义信息,分割图像中的小物体或小面积区域时效果不理想。
1.2.2 全监督学习图像语义分割方法
基于深度学习的语义分割方法大多是全监督学习模型。全监督学习图像语义分割方法即采用人工提前标注过的像素作为训练样本,语义分割过程为:1)人工标注数据,即给图像的每个像素预先设定一个语义标签;2)运用已标注的数据训练神经网络;3)语义分割。人工标注的像素可以提供大量的细节语义信息和局部特征,以便高效精准地训练网络。全监督语义分割方法大多是在全卷积网络的基础上衍生出来的,可按照其改进特点分为下面几类,如表1所示。

表1 全监督学习语义分割方法Table 1 Fully supervised learning semantic segmentation method
1)FCN算法。Long等人(2015)提出了全卷积网络(fully convolutional network,FCN),它以全监督学习的方式分割图像,输入图像的大小不受限制,能够实现端到端的像素级预测任务。网络结构图如图3所 示,FCN 将VGG-16(Visual Geometry Group 16-layer network)算法的全连接层替换为卷积层。一幅RGB 图像输入卷积神经网络之后,进行一系列的卷积和池化操作提取特征图,再通过反卷积层对特征图进行上采样处理,最后进行像素分类并把粗粒度的分割结果转换成细粒度分割结果。FCN成功地将图像分类网络拓展为语义分割网络,可以在较抽象的特征中标记像素的类别,对图像语义分割领域做出了卓越贡献,但是仍面临着3 方面的挑战:池化层会使得特征图的分辨率下降,也会导致某些像素的位置信息损失;上采样处理会使得结果模糊,不能很好地理解图像的细节信息;分割过程离散,不能充分地考虑像素上下文语义信息,故无论是局部特征还是全局特征利用率均不高。
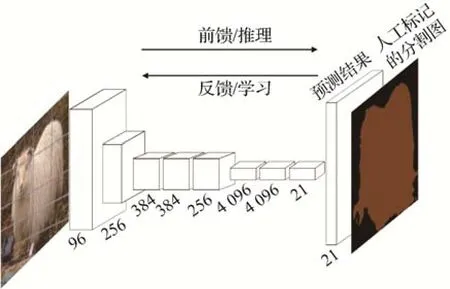
图3 FCN网络结构图(Long等,2015)Fig.3 FCN network diagram(Long et al.,2015)
2)基于全卷积的扩张语义分割算法。由于全卷积网络存在上述问题,Google在2014年提出了扩张语义分割算法,其能够扩大感受野并且不增加参数量,代表算法有DeepLab-V1、DeepLab-V2、DeepLab-V3和DeepLab-V3+。
Chen和Kokkinos(2014)把卷积神经网络与概率图级联而成了DeepLab-V1 网络,在全卷积网络的末端加入了FCCRF(fully connected conditional random field),FCCRF 可以对粗粒度分割图进行边界优化,同时加入了带孔卷积来增大特征图的感受野。图4为DeepLab-V1 的处理流程。DeepLab-V1 网络在PASCAL VOC 2012 数据集上的语义分割指标平均交并比(mean intersection over union,mIoU)达到71.6%。

图4 DeepLab-V1网络处理流程(Chen和Kokkinos,2014)Fig.4 Processing based on DeepLab-V1(Chen and Kokkinos,2014)
Chandra 等人(2016)提出基于高斯条件随机场(Gaussian conditional random field,G-CRF)的语义分割算法,其可以与任意损失函数进行联合训练,在同样的数据集上语义分割精度达到75.46%。
Chen 等人(2018a)改进了DeepLab-V1网络特征图分辨率下降、不能准确定位等问题,提出了DeepLab-V2 网络。该算法通过带孔卷积作为上采样滤波器用来提取特征,并且结合空间金字塔池化(spatial pyramid pooling)提 出ASPP(atrous spatial pyramid pooling),使得其可以更好地提取多尺度特征。DeepLab-V2 网络扩大了感受野,语义分割精度有了显著提高,在PASCAL VOC 2012数据集上mIoU指标达到了79.7%。
Chen 等人(2018a)提出了DeepLab-V3 算法,DeepLab-V3改变了ASPP的空间结构,先将4个带孔卷积并联成一个新的ASPP,再把多个带孔卷积和新的ASPP串联,组成一个端到端的分割网络,其可以捕捉多尺度的图像语义信息。DeepLab-V3 在PASCAL VOC 2012数据集上mIoU指标达到了85.7%。
Chen等人(2018b)在DeepLab-V3网络结构中加入了编码—解码算法和Xception 网络,从而提出了DeepLab-V3+语义分割网络。其可以更好地保留分割的细粒度特征,更好地理解图像的上下文语义信息,也能够显著提升网络的分割准确度和运算速度。DeepLab-V3+网络在PASCAL VOC 2012 数据集上mIoU达到了89.0%。
3)基于全卷积的对称语义分割算法。在图像语义分割领域,对称结构的语义分割网络是解决“池化处理会使得特征图分辨率会下降、部分像素空间位置语义信息缺失”问题的一类重要方法。对称结构的语义分割网络也叫做基于编码器—解码器的网络,该方法的原理是通过深度学习中的卷积、池化等步骤组成编码器来提取图像特征,然后通过反卷积、上池化等步骤组成解码器来恢复图像的一系列像素特征。
Noh等人(2015)提出的DeconvNet网络为第1个对称语义分割模型,将VGG16 的softmax 层换成了上池化和反卷积层,上池化能够进行目标的准确定位,并将特征图的大小还原到池化前的水平从而得到稀疏特征图,反卷积层又会把稀疏特征图转化为稠密特征图,但是该模型参数较多,运算复杂。
针对DeconvNet 网络参数量太大的问题,Badrinarayanan 等人(2017)提出了SegNet 网络。SegNet网络的编码器部分与VGG16相同,由13个卷积层和5 个池化层构成,解码器部分由9 个上采样层、13 个卷积层和1个softmax分类器组成,
如图5 所示。SegNet 网络运算简便,涉及的参数数量和占用的存储空间均较小,但是该网络是通过先验概率来进行像素点的分类,无法预测分割结果的置信度。

图5 SegNet网络结构示意图(Badrinarayanan等,2017)Fig.5 Schematic diagram of SegNet network structure(Badrinarayanan et al.,2017)
Ronneberger 等人(2015)提出了专门适应生物医学图像语义分割的U-Net 算法,该网络模型编码器部分进行下采样处理,逐渐降低特征图的分辨率,解码器部分进行上采样处理,还原图像细节信息。U-Net网络可以通过图像切块扩充数据量,所以在训练图像较少的情况下同样具有较高的不变性和鲁棒性。U-Net网络的确有不错的分割效果,然而只适用于2D 图像。Milletari 等人(2016)把全卷积、神经网络和3D 体积结合提出了一种V-Net 网络,用来处理3D 数据,而且对于前景和背景数量不匹配的问题设计了目标函数,可以用少量数据进行训练,加快了训练速度。
Peng 等人(2017)提出了一种GCN(global convlutional network)网络,该网络把CNN 的全连接层换成了卷积核较大的卷积层,GCN 网络的编码器由ResNet 网络构成,解码器由GCN 和反卷积构成,并且加入了小型残差块进行边界优化,显著提高了分割边界的清晰度和分割准确率。
总体来说,基于全卷积的对称语义分割网络主要具有以下优缺点,优点为:还原图像的空间维度和像素的位置信息,解决池化操作后特征图分辨率降低的问题;缺点为:网络训练参数过多,计算量大,无法实现实时分割。
4)基于特征融合的算法。特征融合的主要思想是兼顾考虑图像的高级特征、中级特征、低级特征以及全局特征、部分特征,通过对各层次、各区域特征的融合来更好地获取图像深层的上下文信息,其能够对图像的上下文信息进行整合加工,提高各种特征的利用效率,以解决之前算法运算量大,训练时间长的问题。
Liu 等人(2015)首先将全局特征进行上池化处理,再将其融合到局部特征中得到图像的上下文信息。Ghiasi和Fowlkes(2016)用拉普拉斯金字塔重构低层特征,提出了LRR(Laplacian pyramid reconstruction and refinement model)模型。LRR 模型将特征图表示为一组基函数的线性组合,并通过跨层方法引入边界特征,融合了低层、高层特征,显著提高了分割精度。
Li 等人(2017)提出了深层级联(deep layer cascade,LC)方法,该方法通过区域卷积处理各阶段感兴趣的区域,忽略其余不感兴趣的区域。并且具有一定的自主学习能力,当图像区域的复杂程度不同时匹配不同深度的处理网络,从而进行针对性训练。
Lin 等人(2016b)提出了RefineNet 网络,网络结构如图6 所示,图像输入网络之后,通过卷积神经网络得到4 种分辨率不同(1∕4,1∕8,1∕16,1∕32)的特征图,之后将特征图与对应的精细模块(由一些残差组件组成)融合。经过几次迭代,融合不同的特征图之后得到分割结果。RefineNet 网络能够高效的利用粗粒度高层语义特征和细粒度低层语义特征,更好地理解上下文语义信息,其在PASCAL VOC 2012 数据集上的分割精度为83.4%。

图6 RefineNet网络结构示意图(Lin等,2016b)Fig.6 Schematic diagram of RefineNet network structure(Lin et al.,2016b)
Zhao 等人(2017a)提出PSP(pyramid scene parsing)网络,图像输入该网络之后先通过ResNet 网络和扩张网络进行预训练,预训练之后特征图的大小变为原来的1∕8,再将其同时送入4 个并行的池化层进行池化处理,融合4 种不同尺寸的特征图,最后上采样还原特征图的大小。PSP 网络处理流程如图7所示。PSP 网络显著提高了语义分割精准度,其在PASCAL VOC 2012 上的分割精度为85.4%。Zhao等人(2017b)在之前的基础上提出了图像级联网络(image cascade network,ICNet),其在保证分割精度的同时实现了实时分割。受其启发,构建了双流图像分割网络(dual image segmentation,DIS)(Luo 等,2017),该网络在PASCAL VOC 2012 上的分割精度为86.8%。
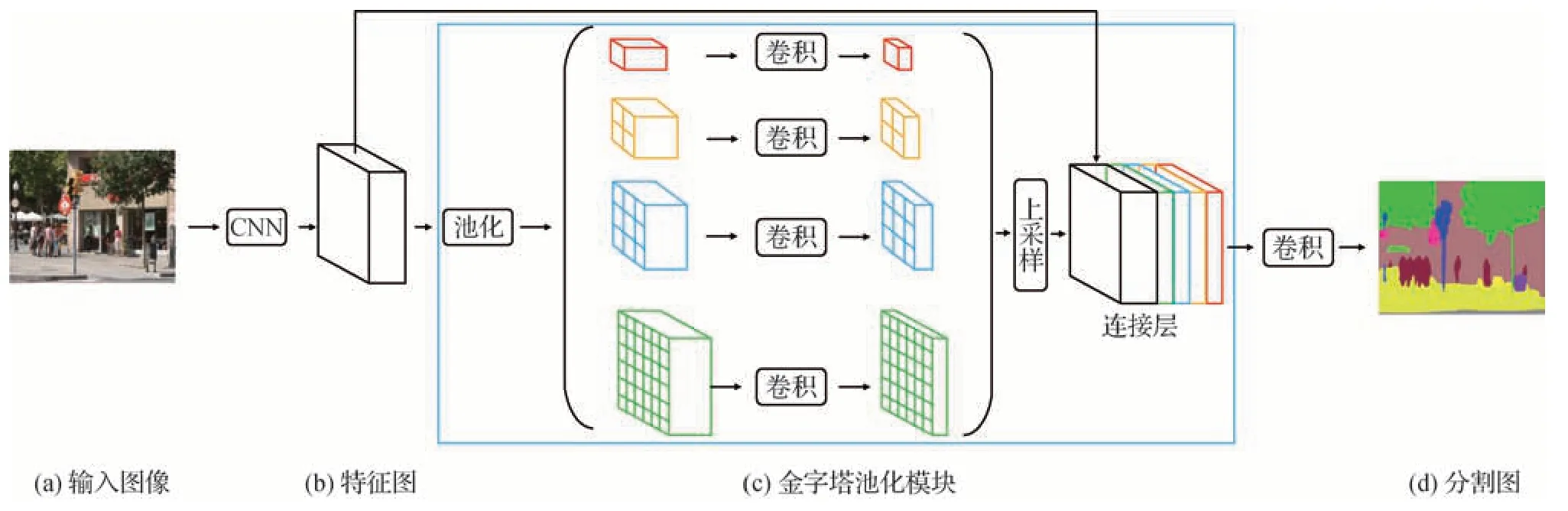
图7 PSP网络处理流程(Zhao等,2017a)Fig.7 Processing based on PSP(Zhao et al.,2017a)((a)input image;(b)feature map;(c)spatial pyramid pooling;(d)image semantic segmentation)
PointRend(Kirillov 等,2020)是一种针对点渲染的神经网络,核心思想是将图像分割视为图像渲染,即在2D 平面上表现3D 物体。PointRend 网络由3个模块构成:第1 个模块是关于有效点的选择,只选择物体边缘的点;第2 个模块是关于点的特征表达,此模块会运用双线性插值算法推理被选点的特征;第3 个模块是对点的特征进行预测。核心模块是点的选择,可以节约大量的算力。PointRend 也可以与DeepLab、Mask R-CNN(He等,2018)网络融合。
条纹池化(strip pooling)是一种新型的池化方法,不同与普通的池化法,条纹池化核为1 ×n或n× 1,可以精确地捕捉矩形结构的物体。SPNet 网络(Hou等,2020)是由条纹池化模块和混合池化模块(Yu等,2014)融合而成的分割算法。条纹池化模块首先会对输入图像进行水平条纹池化和竖直条纹池化两种处理,每幅输入图像会产生两幅特征图,再将两个特征图融合,经过融合的特征图与原图进行像素相乘处理后输出。混合池化模块则是将金字塔池化方法加入到了条纹池化模块,混合池化和条纹池化配合使用,可对不同形状的物体进行分割。SPNet 分割效果良好。
除此之外,还有学者主张融合不同阶段提取的图像特征,例如将上一阶段提取的特征和下一阶段提取的特征进行融合。Raj 等人(2015)提出了一种多尺度深度卷积神经网络,其首先将不同尺度的卷积层植入到VGG-16 网络中,捕捉不同尺度的特征之后,融合上下两个阶段的特征。该网络能够捕捉到粗粒度和细粒度的特征。
5)基于循环神经网络的算法。循环神经网络(recurrent neural network,RNN)利用其拓扑结构,成功地应用于长时间序列和短时间序列的建模。循环神经网络具有两方面的特点:能够对历史信息进行递归处理;能够对历史记忆进行建模。图像语义分割过程中通过循环神经网络可以更好地捕捉上下文信息,更充分地利用全局特征和局部特征。基于循环神经网络的语义分割模型,一般都是在卷积神经网络中加入了RNN layer,卷积层用于捕获图像的局部空间特征,RNN layer 用于捕获有关像素序列的特征,很多方法用到了图像分块。基于循环神经网络的图像语义分割处理流程如图8 所示。图像首先通过卷积神经网络提取特征,然后将特征图传送到循环神经网络中捕获上下文信息,用RNN 层序列化像素,分析像素之间的依赖关系后得到全局语义特征,最后通过反卷积上采样得到分割结果。

图8 基于RNN的算法一般处理流程Fig.8 General processing of algorithm based on RNN
Pinheiro 和Collobert(2014)首次将泛化后的循环神经网络应用于图像语义分割领域。Visin 等人(2016)在图像分类网络ResNet 的基础上,提出了ReSeg 语义分割体系。图像输入ReSeg 网络后首先用第一层的VGG-16 算法生成特征图,再将生成的特征图输入到一个或多个ResNet 层进行微调,最后用基于反卷积的上采样层来恢复特征图的大小。在这种方法中,还使用了门控循环单元(gated recurrent unit,GRU),因为其在内存占用和计算能力方面取得了良好的性能平衡。
普通的循环神经网络序列在建模长期依赖关系时存在梯度爆炸或梯度消失的问题,于是有学者建立了长短期记忆网络(long short-term memory,LSTM)模型和GRUs技术来解决该问题。通过LSTM和GRUs 处理图像时,保留图像的时间序列特征和高级语义信息,可以得到更好的分割结果。Li 等人(2016)同样受到ResNet 网络架构的启发,提出了一种新的适应于场景标注的LSTM-CF 模型,该方法使用了两个不同的数据源:RGB和depth。RGB管道依赖于DeepLab架构的一个变体,将3种不同尺度的特征连接起来一丰富特征表示。
6)基于生成对抗网络的算法。生成对抗网络(generative adversarial network,GAN)由Goodfellow等人(2014)首次提出。在图像语义分割过程中,用生成对抗网络获取上下文信息可以解决CRF 运算量大、内存占用过高和训练时间长等问题。基于生成对抗网络的语义分割算法基本结构框架如图9 所示。生成器网络一般是FCN、SegNet 或PSPNet 等分割网络,图像输入以后先经过生成器生成大量的人造样本,再将检测数据集输入判别器网络,判别器网络会对人造样本和检测数据集学习,并进行对抗训练。当样本的真假被输出后,生成器网络和判别器网络会自动进行修正调节,迭代训练过程中会不断提高生成器的分割准确率和判别器的判断能力。
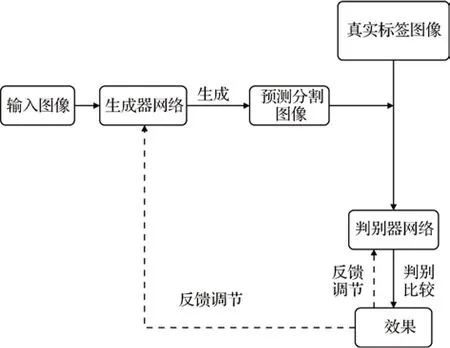
图9 基于GAN的语义分割算法基本结构框架Fig.9 Basic structure framework of semantic segmentation algorithm based on GAN
Luc 等人(2016)首次把生成对抗网络引入到了图像语义分割领域,输入图像首先由卷积神经网络处理成为分割结果,再将其送入生成对抗网络判别真假,对抗学习训练不断提高分割准确率。Hoffman等人(2016)结合了生成对抗网络和领域适应性思想,并对损失函数进行了再次调整优化,创建了语义分割的适应性框架。Kozinski 等人(2017)用生成对抗网络来规范化分割网络的参数。Souly 等人(2017)通过条件生成对抗网络(conditional generative adversarial network,CGAN)生成人造样本。
基于生成对抗网络的算法能够生成样本并且判断真假,可以解决卷积神经网络、全卷积网络进行语义分割时的一些问题。但是该类算法在进行大规模训练时效果并不好。
7)基于注意力机制的算法。注意力(attention)机制主要用在自然语言处理领域(natural language processing,NLP),但有研究者开始尝试将注意力机制用在语义分割上。把注意力机制融入语义分割算法,突出的贡献就是可以在大量的语义信息中捕获最关键的部分,更加高效的训练分割网络。自注意力机制模型的分割效果远远优于通道注意力机制模型。
DANet(dual attention network)(Fu 等,2019)将ResNet(带有空洞卷积)作为主干网络,卷积后的特征图送入两个并行的自注意力网络(位置注意力网络和通道注意力网络)。位置注意力网络能够获取特征图上任意两点之间的空间依赖关系,通道注意力网络能够获取特征图上任意两个通道之间的通道依赖关系。再将经过注意力机制处理过的两幅特征图融合,最后进行分割。
增加卷积层的个数可以增大网络的感受野,但是也会不断地增加算力需求,还会造成图像信息的流失。non-local(Wang 等,2018)就是可以解决上述问题的自注意力机制模块。non-local 能够轻松计算出任意两点之间的关系,也能使得输出图像的尺度与输入图像保持一致。Zhu 等人(2019)在ResNet 中加入了non-local,计算效率有了不少的提升。EMANet(Li 等,2019)称为期望最大化注意力机制网络,相比于non-local 更加简单,但性能显著优于nonlocal。
HANet(Choi 等,2020)也是融入了自注意力机制的网络,其专门适应于城市场景(该类图像每行像素均含有显著差异的上下文信息)语义分割,能够捕获上下文信息,而且可以算出每行像素的注意权值。HANet也能够加入现有的分割网络。
1.2.3 弱监督学习图像语义分割方法
全监督学习的图像语义分割方法在图像语义分割领域占了很大的比例,卷积神经网络、全卷积网络等的应用也取得了不错的效果。但是制作像素级精确标签图像的过程成本很大,往往需要花费大量时间去进行人工标注。因此有一些学者开始研究基于弱监督学习的语义分割方法,该系列方法使用弱标注的图像训练分割模型。弱标注数据相较于像素级标注人工操作较少,比较容易获取。目前,主流的弱监督学习标注方法可分为以下4 类:边界框标签、简笔标签、图像级标签和点标签。
1)基于边界框标签的方法。边界框的标注过程需要的时间较少,该类方法的训练样本即为边框级标注图像,分割效果并不比全监督学习的语义分割方法(相同条件下)差很多。
Dai等人(2015)以全卷积网络为基础,通过边框级标注图像训练分割器,提出了BoxSup 算法。该网络首先使用MGG 算法候选出语义标注区域,再将语义标注区域设置为监督信息送入到全卷积网络中训练,训练之后全卷积网络会输出精度更高的标注区域,这些标注区域又会被送入全卷积网络再次训练,如此迭代至准确率收敛。Rajchl 等人(2016)创立了DeepCut 分割模型,同样用边框级标注数据集进行训练,不过是用卷积神经网络重复迭代。
2)基于简笔标签的方法。基于简笔标注的方法,语义分割流程简洁明了,制作训练样本的成本也较低。简笔标注对图像中的不同语义画线标注即可,如图10所示。

图10 简笔标注示意图Fig.10 Stick figure annotation schematic diagram
Bearman 等人(2016)提出了点监督方法,其使用随机简笔标注的点当成监督信息,并与卷积神经网络相结合,分割效果良好。Lin 等人(2016a)创立了ScribbleSup 网络,ScribbleSup 能够分为两个过程:自动标记过程与图像训练过程。自动标记过程首先对图像简笔标注之后,图像训练过程再通过图模型对卷积神经网络进行训练,最后完成分割。
3)基于图像级标签的方法。基于图像级标注的方法,其训练样本不用进行像素标注,制作成本非常低,故成为弱监督学习语义分割的主流方法。图像级标注的缺点是只标注了语义的种类信息,而对语义形状没有进行标注。
Pinheiro 等人(2015)将多示例学习(multipleinstance learning,MIL)技术引入了弱监督学习领域,MIL 技术被用来构建像素语义与图像标签间的关系,其首先通过ImageNet图像级标注训练模型,然后通过卷积神经网络生成特征平面,后续处理阶段还用到了超像素和MCG 等技术,显示了良好的分割结果。在此基础上,Pathak 等人(2015)通过约束卷积神经网络(constrained convolutional neural network,CCNN)来分割图像,使用图像级标注进行训练,训练过程即为求约束条件的最优解。Kolesnikov 等人(2016)提出了可以结合多个损失函数进行语义分割的思想,创立了SEC 算法,其损失函数由3 个子损失函数构成。
基于图像级标注的分割方法的显著问题是不关注语义目标的位置信息。针对此问题,Wei 等人(2017)提出了一种由简到繁的分割模型,即STC 算法。第1 步通过显著性目标检测方法计算出敏感区域;第2 步融合区域特征并且构建像素语义关系,再通过卷积神经网络生成一组敏感区域图;第3 步由简到繁进行迭代。经过上述步骤不断提高分割精度。
Jin 等人(2017)受其启发,同样通过图像标注进行监督训练,先训练浅层神经网络,之后再将不同的浅层网络合成为一个深度神经网络。其的工作在PASCAL VOC 2012 数据集中进行了端到端测试,显示出良好的分割效果。
Qi 等人(2016)为了解决弱监督学习语义分割的误差累计问题,将增强反馈思想引入到了迭代训练过程中,首先进行目标定位,再通过反馈结果逐渐改善分割性能;Hou 等人(2017)在分割图像时将EM(expectation maximization)算法和卷积神经网络结合,显示出良好的分割效果;Durand 等人(2017)在全卷积网络基础上,通过弱监督学习选取出图像的显著性区域,再利用显著性区域的特征信息进行图像分割;
4)基于点标签的方法。图像级标签与点标签的不同之处仅在于点标签需要一个“点”大致标记出目标的中心位置,基于点标签的方法分割性能远远优于基于图像级标签的方法。点监督类激活图(point supervised class activation maps,PCAM)算法(McEver等,2020)通过点标签提升定位和分割能力,首先用ResNet50 为基础的CNN 处理点标签图像计算点监督类激活图,并生成类别标签,再对比点标签与输出的差异,更新PCAM 网络的消耗。然后利用IRNet与PACM 联合构建伪语义标签,将伪语义标签视为真实语义标签训练分割网络。
1.3 面向2.5D数据的语义分割方法
大量的语义分割工作是在2D 数据集中完成的。加入深度信息能够一定程度地区分易混淆的像素,从而提高分割精度。但RGB 图像中只包含颜色纹理等外观特征,三维几何信息不能被获取。低成本RGB-D 传感器的出现也进一步降低了研究门槛,开始有部分学者研究立体数据,一些专注于RGB-D 场景分割的论文开始发表。近些年,许多学者把二维信息与深度信息进行了拼凑,分割精度确有提高。Gupta 等人(2014)首先把RGB-D 信息进行了编码操作,再将编码后的深度信息与颜色信息输入到并联的卷积神经网络中,最后将预测到的两个语义分割概率图融合。Li等人(2016)将深度数据的每个像素编码为3 个不同的通道,通过这种方式可以将深度图像输入到RGB 数据分割模型中,并从结构信息中学习新的特征。Zeng 等人(2016)提出了一种利用多视图RGB-D 数据、自我监督和数据驱动学习的语义分割方法,训练了多个用于特征提取的网络,其最大的贡献是能够将捕获的RGB-D 图像输入到FCN网络中进行场景分割。上述研究的确取得了较好的效果,但也有不足之处:1)将二维特征与RGB-D 特征简单地拼凑融合,不能很好地提取并运用二者在空间上的互补信息;2)CNN 高层特征中的各通道均会对特定类别的语义信息进行编码,上述方法没有考虑到高层特征间语义信息的相互关系。针对以上问题,Duan 等人(2021)研究了一个融合注意力机制(开发了一种跨模态注意力机制)和语义感知的端到端训练网络,可以高效率地融合2 维信息与深度信息。实验结果显示,该方法即使不用很深的网络也能得到不错的分割结果。
Ma 等人(2017)提出了一种基于FuseNet 算法的RGB-D 图像分割方法。首先利用移动的RGB-D 摄像机获取视图,在训练阶段通过SLAM 技术获取摄像机轨迹,然后将RGB-D 图像扭曲成真实标注的帧用于分割。
1.4 面向3D数据的语义分割方法
3D 数据(如点云或多边形网格)的额外维度提供了丰富的空间信息。面向3D 数据的语义分割方法可以分为间接处理法和直接处理法。典型的卷积架构需要高度规则的输入数据格式,由于点云或网格不是常规格式,故研究者一般都会将非结构化、无序的点云或网格转化成规则的3D 体素网格或图像集合,再输入分割网络。
1.4.1 间接处理法
Su 等人(2018)将一个三维物体映射为多个不同角度的二维图,再用卷积神经网络提取特征,但是该方法在(多个二维图)还原3D物体时不太理想。
Wu 等人(2018a)提出了Squeezeseg 网络框架,该框架是可以进行端到端训练。其先把点云通过球面投影处理得到前视图,再用SqueezeNet(Iandola等,2016)提取图像特征,最后分割图像并优化。在此基础上,SqueezesegV2(Wu 等,2018b)也相继被提出,SqueezesegV2 能够更鲁棒地减少点云噪声。Imad 等人(2021)提出了一种通过迁移学习进行3D分割的算法,该算法首先把3D 点云投影成2D 数据,再利用2D 迁移学习分割图像,最终将2D 分割结果反投影到3D 数据中。Le 等人(2018)开发了基于三维形状理解的PointGrid 网络,PointGrid 在每个体素单元网格中提取数量一致的特征点,从而采样几何细节,解决了卷积神经网络对空间稀疏的体素不能高效处理的问题。Meng 等人(2018)则致力于研究点云分布的稀疏性与不均匀性,把不规则的点云转化成规则的体素网格,再通过插值自动编码器对各体素信息进行编码。
间接处理法最大的优势是弥补了CNN 不能处理3D 数据的缺陷,但仍然面临一些问题,比如过程复杂、精度不高以及重要信息丢失严重等。
1.4.2 直接处理法
直接处理法不用进行繁琐的数据形式转换。斯坦福大学的Qi 等人(2017)提出了第1 个直接处理点云数据的神经网络PointNet,PointNet 网络结构简单,如图11 所示,可以很好地解决点云在空间排列上的无序性问题,能够进行物体分类、分割、场景语义转换等任务。然而PointNet 网络只能独立学习每个点的特征,不能良好地学习点之间的关系。
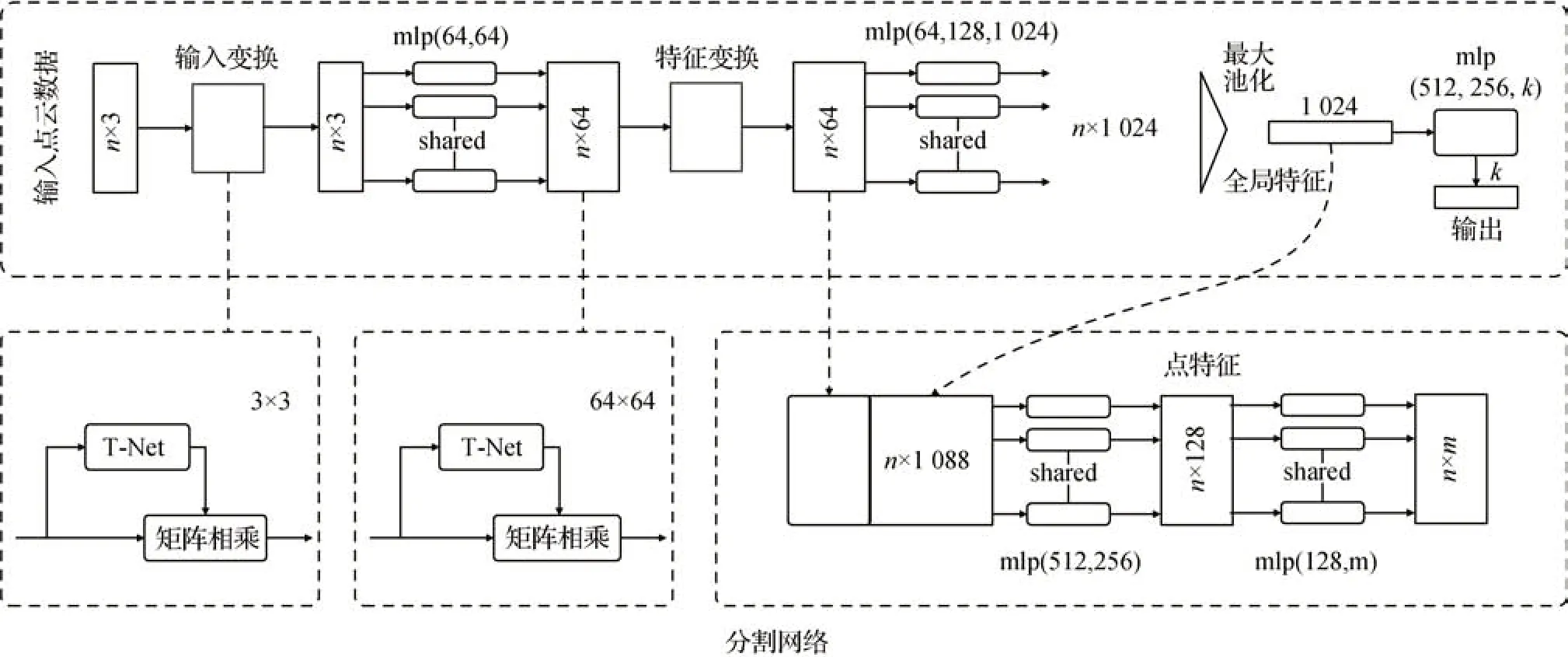
图11 PointNet网络结构(Qi等,2017)Fig.11 Network structure of PointNet(Qi et al.,2017)
之后提出的PointNet++网络用以解决上述问题,但导致运算成本太高。Engelmann 等人(2017)受PointNet 网络的启发,提出了分块处理点云的思想,目的在于增大网络的感受野,学习点云间的关系。
Engelmann 等人(2017)的实验表明了点云关系融合的重要性。Huang 等人(2018)提出了一种基于3D 卷积神经网络的点云分割方法,该方法不需要人工制作标签,可以处理大规模的数据。在包含7 类对象的城市点云数据集上进行实验后表明该方法具有较高的鲁棒性,但其较大的缺点是空间信息丢失严重。KPConv(Thomas 等,2019)是一种能够分割点云数据的扩张神经网络,KPConv 的卷积核由多个带权重的核点构成,并且能够灵活地设置。Tatarchenko 等人(2018)提出了基于切线卷积的3D 数据神经网络,能够直接处理曲面几何。该方法尤其适用于大规模点云,实验结果显示出良好的分割性能。
2 语义分割相关实验分析
如何客观公平地评价某种方法的分割性能是十分重要的问题,因此有必要总结统一的评价指标,总结相关实验并进行对比分析。
2.1 性能评价指标
在图像语义分割领域,分割性能评价指标有7种:平均精度(average precision,AP)、平均精度均值(mean average precision,mAP)、平均准确率(mean accuracy,MA)、平均召回率(average recall,AR)、平均交并比(mIoU)、像素准确率(pixel accuracy,PA)和频率加权交并比(frequency weighted intersection over union,FWIoU),比较常用的有两种:平均准确率、平均交并比。
2.2 2D数据集的相关实验分析
近年计算机硬件条件发展迅速,数据的处理能力也有了很大程度的提升。在基于深度学习的语义分割领域内,大部分的学者都将研究重点放在了提高分割准确率,对于计算性能的研究相较于前者比较少,尤其是基于候选区域的语义分割方法和弱监督学习语义分割方法。所以对以上两种方法的相关实验仅从分割准确率上展开分析,而全监督学习的语义分割算法对于计算性能也是非常关注的,其相关实验将从分割准确率和计算性能两个方面进行阐述。
2.2.1 基于候选区域的语义分割方法相关实验分析
相关实验对比如表2 所示。基于候选区域的语义分割方法都是以mIoU 作为评价指标,RCNN 是基于候选区域的第1个开源算法,mIoU指标并不高,但是其分割性能稳定,开源时间较早,已经被大量应用,其余几种方法的结构框架都是以RCNN 为基础。

表2 基于候选区域的语义分割方法实验对比Table 2 Experimental comparison of semantic segmentation algorithms based on candidate regions
2.2.2 全监督学习语义分割方法相关实验分析
全监督学习语义分割经常涉及实时分割,所以实验分析不但要考虑分割准确率,也要考虑网络运行速度。
1)关于分割准确率的相关实验对比。全监督学习语义分割方法实验对比如表3 所示。从表3 可以看出:(1)算法的应用场景和分割特点不同时,选择的数据集也不同。分割常规静态图像时,PASCAL VOC 2012通常。而CityScapes 数据集常被一些用于动态场景解析或实时分割的算法进行分割测试。(2)算法的精度在不断提高。DeepLab-V3+网络整合了FCN、ResNet等许多算法的优点,mIou指标最高。由于其优异的性能,在工业界常用来分割静态图像,受到了广泛的应用。(3)从算法分类来看,基于注意力机制的算法整体上分割精度最高,可能是今后的热点研究方向。(4)大多数的分割方法都是以FCN 和ResNet 这两种网络结构为基础,由此也能看出FCN网络和ResNet网络是具有重要意义的。
2)关于网络运行速度的相关实验对比。网络运行速度也是分割算法性能的重要参考点。由于一些论文中没有提到算法的运行速度,故只比较部分算法。所有参与比较的算法都在CityScapes 中进行实验测试,结果如表4 所示。其中,“运行速度”表示分割每一幅图像需要的时间,“每秒帧数”是“运行速度”的倒数。表4 显示,ENet 算法的运行速度最快,每秒可以分割76.9 幅图像,ICNet 和SegNet 算法也具有较好的分割速度,这3 种网络均可以进行图像实时分割和动态场景理解。FCN网络由于上采样过程比较耗时,其运行速度一般,FCN网络难以进行图像实时分割等任务。而DeepLab-V1 和DeepLab-V2过程会涉及到对图像结构化预测,该过程也非常耗时,所以运行速度更低。

表4 全监督学习语义分割方法运行速度实验对比Table 4 Experimental comparison of computational performance of semantic segmentation algorithms based on fully supervised learning
2.2.3 弱监督学习语义分割方法相关实验分析
弱监督学习语义分割方法相关实验对比如表5所示。基于弱监督学习的语义分割方法大多都用较权威的PASCAL VOC 2012 数据集进行实验,表5直观地反映出该类方法mIoU 指标整体显著低于前两类方法,而且标注方法越简单,分割精度也越弱。

表5 弱监督学习的语义分割方法实验对比Table 5 Experimental comparison of semantic segmentation algorithms based on weakly supervised learning
2.3 RGB-D数据集的相关实验分析
目前,适应于RGB-D 数据集且开源的分割算法不多,实验数据集也都不同,将mIoU 视为评价指标进行简单总结,如表6所示。可以看出,RGB-D 数据的分割准确率还有很大的提升空间,这也是目前面临的最大挑战;融合不同模块的办法有一定的作用,但显然效果有限。

表6 RGB-D数据相关实验Table 6 Related experimental of RGB-D data
2.4 3D数据集的相关实验分析
3D数据相关实验对比如表7所示。

表7 3D数据相关实验Table 7 Related experimental of 3D data
2.5 实验总结
目前,针对2D 数据的分割算法各方面都取得了不错的成绩,部分已经应用在了实际生活中。其中DeepLab-V3+网络的分割精度最高,mIoU 达到了89.0%,并且分割速度较快,具有较高的应用价值。存在的问题主要有以下3 个方面:1)大量算法没有在权威数据集上实验,故得出的算法性能需进一步探究;2)部分算法没有开源,不能再次复现实验;3)某些实验没有详细的描述设置过程、实验参数、训练权重等内容,影响该领域的研究进展。
3 存在的问题和未来研究方向
1)分割算法在精确度和实时性之间往往是顾此失彼。算法终究要落实到应用中,视频分割、无人驾驶等应用领域对实时性要求很高,常见的摄像机帧率为25帧∕s,大多数方法远没有达到该速度,例如FCN-8s在PASCAL VOC上处理一幅低分辨率的图像需要100 ms。目前对该问题的探讨工作尚且不足,未来必须在大量实验的基础上找到广泛认可的平衡点。
2)分割网络通常需要大量的内存来实现推理和训练,在一些设备上并不适应。虽然该问题可以简单地通过降低网络复杂性来解决,但会丧失分割精确度。剪枝是一个很有前途的研究方向,其可以简化分割网络,使网络轻量化,并且保留网络原有的分割能力。这个问题非常值得进一步研究。
3)适应于3D 数据的分割算法设计是当前的研究热点,但非常缺乏高质量的3D 数据集,目前已有的3D 数据集都是拼凑数据集。即使有新的算法提案,也难以客观地评估其性能。3D 数据集比低维度的数据集更难创建并且之前存在技术限制,所以这方面的工作具有较大的发展空间。从2018 年开始,各大顶级会议都提到该问题,可见其重要程度。
4)针对RGB-D 数据和3D 数据的分割算法依旧很少,尤其是3D 数据,已开源的算法精度也普遍不高。由于其无序和非结构化的性质,普通的架构不能对其直接处理。故该问题需要研究者进行深入的开发探索。
5)序列数据的时间一致性:一些方法解决了视频或序列分割的问题,但是有些未利用时间序列信息来提高准确率或分割效率。然而,没有一种方法解决了一致性的问题。一致性信息对于一个应用在视频流上的分割系统非常重要,要求其不仅可以逐帧地处理数据,还要求其对整个片段的处理保持一致。
6)已有论文提出可以在不进行训练深度神经网络的情况下实现人脸检测,是否也可以不训练网络实现语义分割。
4 结语
语义分割是近年新兴研究方向,具有很高的研究价值,目前较全面的语义分割综述文章依旧较少。本文致力于语义分割问题,对此进行了总结,涵盖了该领域经典和先进的方法、权威通用的数据集以及相关实验。仔细描述数据集的特征,能够使研究者快速选取适合其需求的数据集;分割方法从设计特点、优缺点和分割准确度方面做了介绍,便于研究者熟悉其架构并改进缺点;而分析实验有助于学习实验经验,重新审视分割网络,精益求精。本文对研究结果进行了讨论,并对该领域未来的研究方向和待解决的问题提出了有益的见解。然而尚存在如下不足之处:由于大部分论文都没有介绍实验设置,所以在实验分析部分也未涉及该内容,整体上不够完整。语义分割已经有了很多成功的应用案例,期待将来会出现更多的精彩算法。
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
CHIP新电脑(2016年3期)2016-03-10
大连民族大学学报(2015年2期)2015-02-27
