
基于端到端深度学习的声源特征清晰化方法
2023-11-14 05:29:30冯罗一徐中明张志飞李贞贞
振动与冲击 2023年21期
冯罗一,昝 鸣,徐中明,张志飞,李贞贞
(重庆大学 机械与运载工程学院,重庆 400044)
随着数据采集技术和计算性能的不断提高,各种声源识别算法不断发展。声源识别的波束形成算法主要包括传统波束形成(conventional beamforming,CB)[1],自适应波束形成[2],正交波束形成[3],函数波束形成[4]、广义逆波束形成[5]、反卷积波束形成[6]等。文献[7-8]对这些方法进行了综述。近年来,深度学习[9]在图像识别领域取得了迅速的进展。与传统的基于数学和物理模型的方法不同,基于深度学习的方法利用深度神经网络,从数据中学习到的特征表示来获得输入输出的复杂映射关系,从而可以绕过特定问题的复杂描述。除此之外,深度学习模型的计算速度远高于传统方法。深度学习模型在训练过程中所有的操作都包含在神经网络内部,不再像传统机器学习的流程那样分成多个模块处理,因此将其称为端到端深度学习。
随着深度学习模型的发展和其适用性的提高,深度学习在振动声学领域有了广泛的应用[10-12]。基于深度学习的声源识别方法主要可归纳为两类:基于网格的方法和无网格的方法[13]。对于基于网格的方法,Ma等[14]构建了卷积神经网络,将声源平面上的多个声源识别为声压分布图。这是首次将深度学习与波束形成算法相结合进行声源识别的研究。Xu等[15]使用密集连接卷积神经网络(densely connected convolutional networks,DenseNet)从互谱矩阵(cross spectrum matrix,CSM)生成声压分布图。该方法可实现单个频率下最多25个声源的高分辨率识别。为了提高基于网格的方法的精度,Lee等定义了一个新的目标函数,该函数依赖网格点和声源之间相对位置关系来构建目标地图,其中通过更精细网格点与预测强度之间的最小误差来确定准确声源位置,并运用编码器-解码器结构的全卷积神经网络(fully convolutional network,FCN),实现了高分辨率多声源识别。之后Lee等[16]将类似方法拓展到球面阵列的应用中。对于无网格方法,Kujawski等[17]使用了一个20层的残差神经网络(residual network,ResNet),用3个输出单元来估计单个声源的坐标和强度。在此基础上,为了提高低频情况的精度,Lee等[18]定义了一个频率加权损失函数和一个更深层次的DenseNet。他们利用与Kujuswki等相同的训练数据,实现了单声源识别。为了使用无网格方法识别多声源,Castellini等[19]通过构建5个不同的多层感知器模型,提出了与类似的无网格方法来实现3个声源的定位任务。由于声源的数量决定了神经网络输出层的大小,无网格方法只能识别已知数量的声源。与基于网格的方法相比,无网格方法直接预测声源的坐标和强度,无需依赖网格点获得预测结果。
上述方法中采用的训练数据主要分为两种:CSM,包括非冗余形式和传统波束形成地图(conventional beamforming map,CB Map)。CSM的尺寸由所采用阵列的传声器数目决定,因此使用CSM作为输入必须预先确定传声器数目。CB Map的尺寸由网格点数目决定,因此不需要提前确定传声器数目。然而,当传声器数目减少时,CB Map的声源特征不再明显。因此,当使用较多传声器数阵列得到的数据训练得到一个深度学习模型,用来预测较少传声器数阵列得到的CB Map时,精度会下降。为了克服实际应用中所使用阵列的限制,增强深度学习声源识别方法的通用性,本文提出基于U-Net模型的阵列转换方法(array converted method,ACM),提升深度学习无网格识别方法(deep learning grid-free method,DL-GFM)的识别精度。首先使用18通道阵列CB Map作为输入、64通道阵列CB Map作为目标训练U-Net模型,然后使用训练好的模型对于不同频率和不同声源数目的输入评估模型的预测性能,并且对于三声源情况通过DL-GFM方法观察ACM方法对其性能的提升情况,最后通过1个、2个、3个声源的试验验证提出ACM方法的有效性和可行性。
1 理论方法
1.1 传统波束形成
波束形成是一种基于相控麦克风阵列的方法,其通过对每个麦克风采样的声压进行空间滤波。来自真实声源方向的信号增强,其他方向的信号减弱,形成“主瓣”和“旁瓣”,从而得到声源分布信息。传统波束形成CB的算法过程可以描述如下,其过程示意图如图1所示。
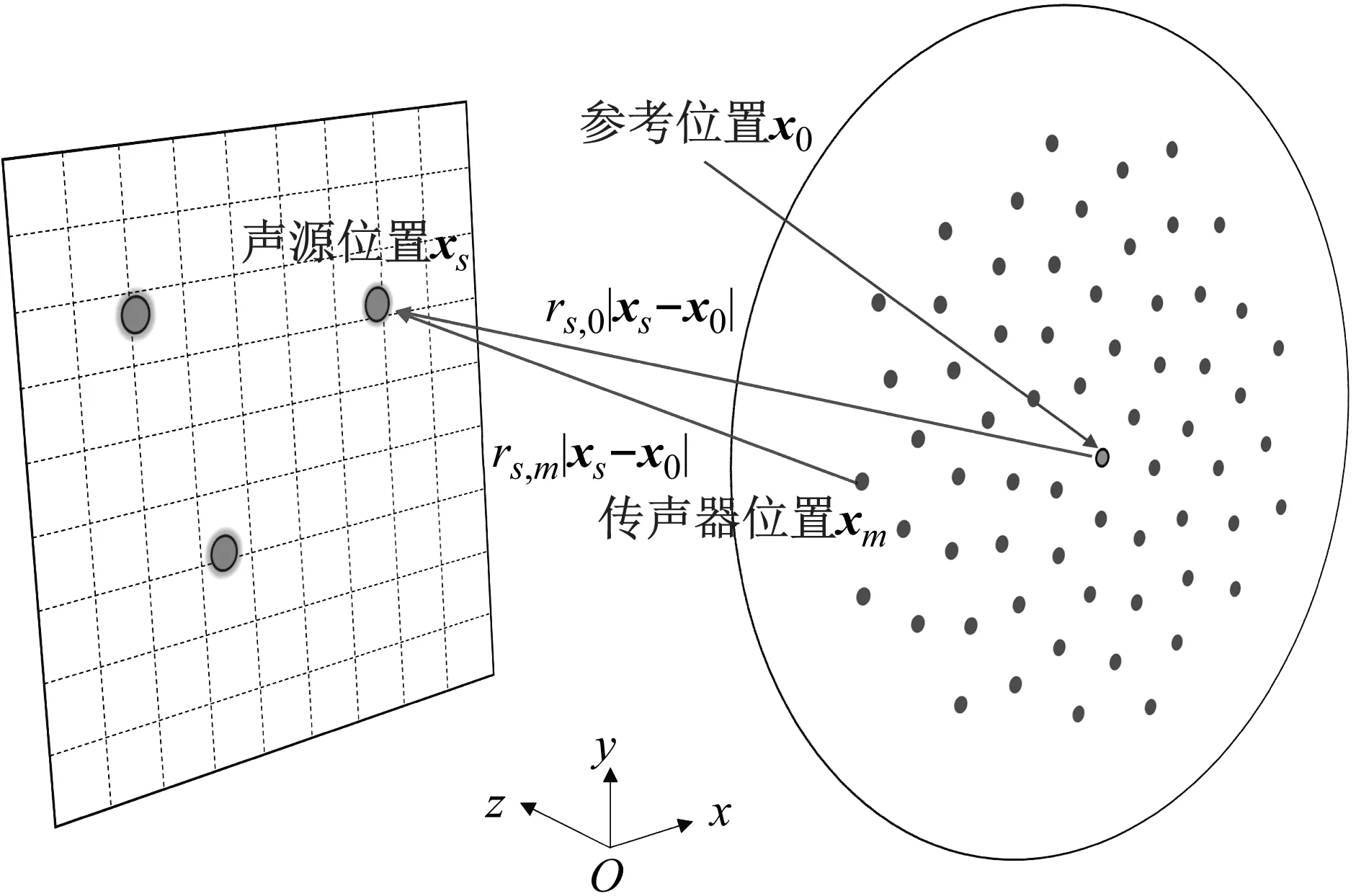
图1 传统波束形成示意图
假设麦克风阵列通道数为M,位于xm(m=1,2,…,M),麦克风位置测得的声压pm和在xs(s=1,2,…,S)位置的声源强度q的关系可以表示为
pm=qg(xs-xm)
(1)
式中,g(xs-xm)为转向向量。文献[20]中有4种可供选择的转向矢量公式,本文中为了将除声源位置的所有其他位置的信号都尽可能地减弱,采用了其中的Formulation III的形式,表示为
(2)
式中:k为波数;rs,0=|xs-x0|,rs,m=|xs-xm|分别为声源位置xs与参考位置x0和麦克风位置xm之间的距离,x0设置为传声器阵列中心
(3)
将式(1)写成向量形式为
p=qg
(4)
直接波束形成器的目标就是在声源位置xs上确定声源强度q,即求解式(4)。通过解最小化问题
(5)
得到以下形式的最小二乘解
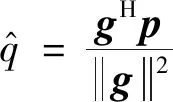
(6)
式(6)可以重新整理之后获得功率意义的波束形成结果
(7)
式(7)为传统波束形成,将由此方法得到的矩阵图像称为CB Map。式中:C=ppH为麦克风测量的声压得到的CSM;上标“H”为共轭转置。
在稳定声场中,首先对自谱和互谱进行平均处理。因为自谱中包含了阵列麦克风的自通道噪声且其中没有任何相位信息,对波束形成过程没有帮助,因此除去CSM的自谱,即除去矩阵对角线,处理过程可表示为
(8)
本文使用针对64通道Vogel螺旋阵列和18通道扇形轮阵列两种阵列形式来进行研究,其传声器分布图如图2所示。在传声器间距接近的情况下,18通道阵列的孔径0.38 m小于64通道阵列孔径1 m,这是导致两者CB性能差异的主要原因。将两种阵列的传统波束形成结果简称为CB Map_64和CB Map_18。
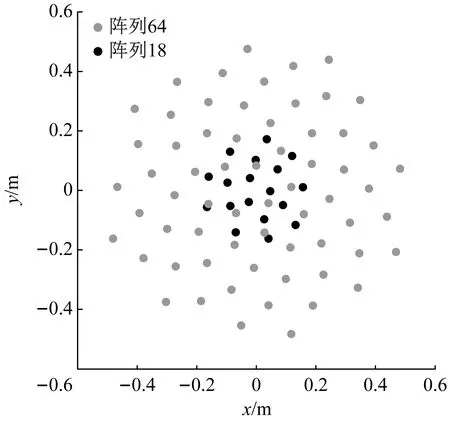
图2 阵列分布形式
1.2 深度学习无网格方法
本文中以三声源为例介绍一种基于ResNet-50-V2[21-22]的深度学习无网格方法DL-GFM,其中只关注声源位置,不关注声源强度。ResNet-50-V2来源于是残差神经网络ResNet的一种包含50层卷积层的优化结构。ResNet的出现解决了使用深度神经网络模型架构时梯度爆炸和梯度消失的问题,在此之后才出现了更深层(可达上千层)的神经网络,在分类和回归任务上的表现相比之前已知的架构更加优异。
ResNet的结构与普通卷积神经网络相比,多了快捷连接。快捷连接中输入数据可以并行地从输入层流向输出层,因此在输出中,前一层的映射与卷积处理后的数据相加,进而ResNet只学习输入和输出之间的残差。残差映射的过程可描述为
(9)
式中:F为需要被学习的残差映射;X为卷积层的输入;wi,b分别为卷积层的权重和偏置;Ws为一个线性投影矩阵,用来匹配与卷积层结果相加的维数。式(9)中代表了残差学习的两种不同方式,区别在于式(9)上式为恒等映射,在维数匹配的情况下可以实现;式(9)下式的方式由于增加了卷积过程从而增加了参数数量,解决了维数不匹配的问题。He等研究中对两种方式的区别、处理方式和性能做了具体的分析,感兴趣的读者可以进行阅读。其中ResNet-50-V2中运用的full pre-activation结构,可以加快模型的训练速度、提高精度,并且更有效地避免过拟合的问题。
图3所示为DL-GFM方法的主要过程。DL-GFM方法首先使用麦克风阵列采集多通道数据,然后通过传统波束形成算法获得CB Map,将其作为输入训练好的ResNet-50-V2模型获得3个声源的坐标输出,分别为a1,b1,a2,b2,a3,b3。训练过程中采用均方误差(mean square error,MSE)作为损失函数,ADAM[23]作为训练算法更新网络的参数。ResNet-50-V2模型的构建与训练在Python Keras库中进行。

图3 DL-GFM方法主要过程
表1所示为模型训练的数据集设置,包括波束形成过程的关键参数、数据集大小。本文使用的训练数据和测试数据主要通过Acoupipe[24]和Acoular[25]生成。后文U-Net模型的训练所采用的数据集的区别在于将两种通道数的CB Map分别作为输入和目标,即替换了声源坐标作为输出。除此之外,两者训练算法和损失函数均一致。
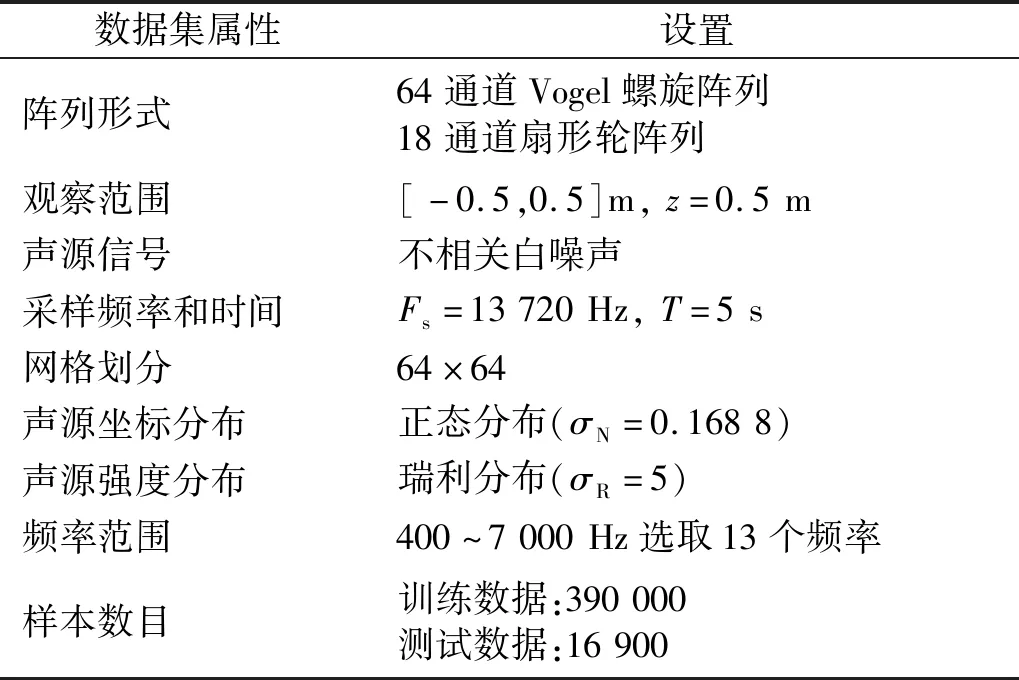
表1 数据集设置
1.3 阵列转换法
本文使用CB Map_18作为输入、CB Map_64作为输出,使用U-Net模型训练阵列转换器,故将此方法命名为阵列转换法ACM。使用ACM可以使得用在一定频率下采用18通道阵列达到使用64通道阵列的效果,进而利用DL-GFM方法进行更精准的识别。
U-Net模型是一种全卷积神经网络FCN,最早由Ronneberger等[26]提出,用于生物医学图像语义分割。因其形状与字母“U”相似,故被命名为“U-Net”。这种全卷积模型相比于带全连接层的神经网络模型可以接受任意大小的图像输入,并且采用了上采样的方法来恢复图像,从而可以实现像素到像素更精细的预测。常用的上采样方式是转置卷积。采用矩阵乘法的方式简介转置卷积的原理。假设输入图像的尺寸为4×4,卷积核大小为3×3,如式(10)和式(11)所示
(10)
(11)
令步长为1,则输出大小为2×2,如式(12)所示
(12)
其中,
(13)
同理可得,由卷积核滑移到不同位置之后点乘得出y2,y3,y4。将Input和Output分别按行展开为x=[x1x2x3x4x5x6x7x8x9x10x11x12x13x14x15x16]T和y=[y1y2y3y4]T,则卷积过程可以表示为
y=Ax
(14)
式中,A为卷积核在输入图像上的滑移运算过程,可用稀疏矩阵表示为
(15)
其中每一行向量表示在一个位置的卷积操作,“0”填充表示卷积核未覆盖到的区域。转置卷积的操作式(14)的逆运算,可以表示为
x=ATy
(16)
U-Net模型架构如图4所示,其组成为编码器-解码器结构。编码器网络由多个通道组成的特征图通过一系列卷积运算与训练过的滤波器进行分层计算,旨在从CB Map_18中生成具有空间代表性的特征。本文使用修正线性单元(rectified linear unit,ReLU)作为激活函数,可表示为

图4 U-Net模型架构
(17)
此处卷积过程可以定义为
(18)

解码器网络旨在将编码器部分生成的空间表示转换为目标图CB Map_64。解码层中的特征图通过转置卷积逐渐放大。转置卷积通过对输入特征图进行适当的填充和跨步操作,最后通过网络末端的1×1卷积层获得64×64的预测图。图4中箭头代表跳跃连接,目的是将下采样的特征图和上采样的特征图合并,增强恢复图像的特征。
本文中结构与文献[26]中的区别在于:①图像尺寸分别为224×224×3与64×64×1,为了加快训练速度,将卷积核数减半;②ACM方法是回归任务,所以在输出层用ReLU代替Softmax作为激活函数,且用MSE函数替代其中的带边界权值的损失函数。
2 仿真结果
2.1 预测表现
在U-Net模型的训练中,只使用了3声源的训练数据,即模型只“见过”3声源的CB Map,因此所有不是3声源的CB Map对于训练好的模型来讲都是未见场景,包括单声源和双声源。为了体现模型的泛化性能,用未知声源数目的CB Map进行仿真试验,观察预测结果,仿真与试验信息处理流程图如图5所示。

图5 信息处理流程图
图6、图7分别展示了1~3个和4~8个声源的CB Map通过ACM方法的预测表现,包括输入图(input)、预测图(prediction)、目标图(target)。其中:“*”为声源实际位置;“×”为DL-GFM方法的预测位置;“input”为CB Map_18;“prediction”为ACM方法清晰化后的成像图;“target”为CB Map_64;N为声源数目;f为频率。从图6中可以观察到,ACM方法对于CB Map_18具有明显的清晰化效果,并且预测图与目标图接近。具体表现在低频时减小了主瓣宽度;中频时减小主瓣宽度进而能有效地分离多声源;高频时减小主瓣宽度并降低旁瓣水平甚至消除旁瓣,这是CB Map_64中没有达到的效果。这说明U-Net模型“智慧地”将图中的旁瓣当作无用信息,因此在进行上采样恢复图像时,直接忽略旁瓣从而达到了消除旁瓣的效果。DL-GFM的识别结果在选取的频率下都是准确的,只在图6(f)中的弱声源位置出现了少许偏差。

(a) N=1,f=537 Hz,input
值得一提的是,对于3个及以上的声源数目,ACM方法也有良好的表现。从图7中可以观察到,对于3个以上声源的情况,预测图与目标图相比主瓣宽度稍大,声源特征分离不够明显,但是相对于输入图有明显的提升,同时继续展现出良好的旁瓣消除性能。如图7(j)所示,当声源数目达到8个时,预测结果出现了较大偏差。说明本文中训练的U-Net模型在更多声源数目上的表现有局限性,但总体表现良好。可以推测通过更多数目的训练数据集可以提升ACM方法的声源识别范围。
2.2 误差评估
本文中使用平均绝对误差(mean absolute error,MAE)(EMA)作为评估训练好的模型性能的指标,可表示为
(19)
图8展示了在不同声源数目和频率下ACM方法的误差表现,首先可以观察到随着频率的增大MAE值逐渐降低,说明ACM方法的中高频表现优于低频。同时可以看出随着声源数目的增大MAE值随之增加,这个差距主要体现在1 608 Hz以下的低频段。在中高频段,MAE误差几乎没有差距。综上所述,在只用3声源数据集训练的情况下,U-Net模型拥有很好的泛化能力,并且在中高频段表现更加出色。
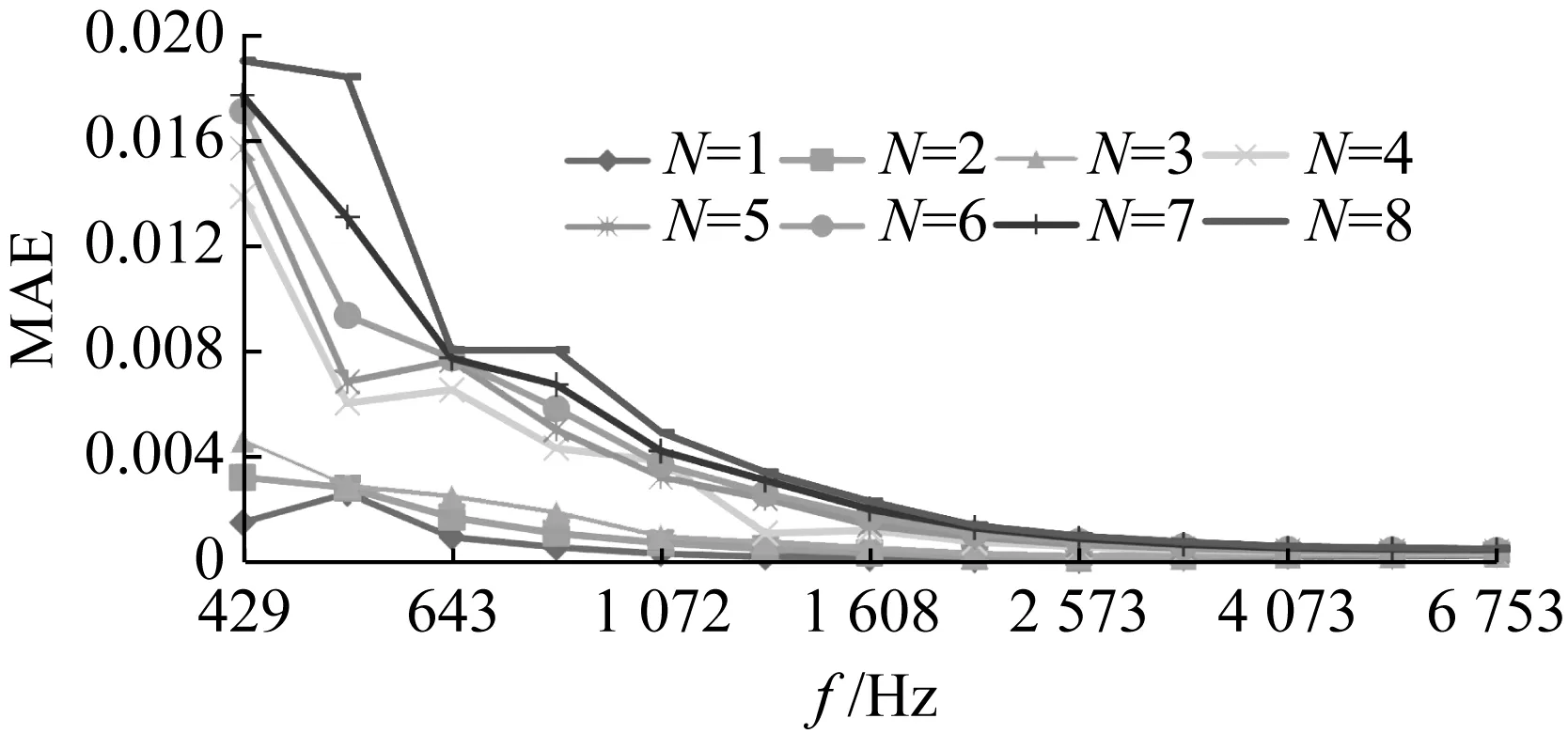
图8 ACM方法总体性能
图9展示了使用经过ACM方法处理之后,DL-GFM方法的预测性能。以3声源情况为例展示结果。图9中曲线的命名代表训练数据和测试数据进行波束形成时所使用的阵列。例如,“DNN_64-18_ACM”代表训练数据使用64通道阵列,测试数据使用18通道阵列并且使用ACM方法之后的评估结果。对比“DNN_64-18_ACM”和“DNN_64-18”可以看出,使用ACM方法之后MAE误差大幅降低,说明ACM方法对于CB Map的处理效果十分显著。与“DNN_18-18”相比,在整个频段上,使用ACM方法的误差几乎都低于DNN_18-18,并在858~2 037 Hz频段效果较明显,但与“DNN_64-64”在429~858 Hz的低频段相比仍有一定差距。这说明ACM方法优于专门用对应阵列的CB Map数据训练的DL-GFM方法。
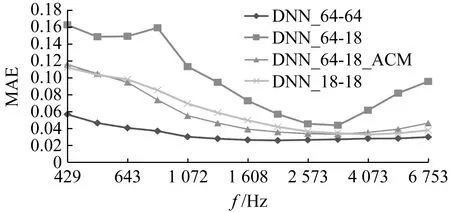
图9 DL-GFM方法总体性能
值得一提的是,本文工作中使用的硬件配置是型号为NVIDA QUADRO P4000的GPU。其训练一个DL-GFM方法中的ResNet-50-V2模型的时间大约30 h,而训练ACM方法中的U-Net模型只需要大约2 h。因此使用ACM方法既提高了深度学习无网格方法DL-GFM的精度,在不同的阵列测试中又无需多次训练模型,在实际应用中具有很强的实用性。除此之外,本文中根据测试数据中的表现设置MAE=0.06为DL-GFM方法的合格阈值,即只有当MAE≤0.06时才被认为准确识别出了全部声源坐标。据此判断ACM方法对于3声源的有效频段在1 072 Hz以上。
3 试验验证
仿真结果表明ACM方法能够消除旁瓣,降低主瓣宽度,提高CB Map的声源特征清晰程度,进而可以提升DL-GFM方法的识别精度。为了进一步验证该方法的有效性和可行性,进行了声源识别试验。试验测量中采用了Brüel &Kjær公司的18通道扇形轮式阵列,集成Brüel &Kjær4951型传声器,试验设置如图10所示。

图10 试验设置
图10中声源平面到阵列平面距离为0.5 m,3个声源坐标分别为:声源1中心是(0,0.2,0.5)m,声源2中心是(0.2,0,0.5)m、声源3中心是(-0.2,-0.1,0.5)m。此处3个声源刻意避免设置在阵列中心对应位置,以排除设置位置带来的偶然性。声源采用受白噪声激励的小型扬声器模拟点声源。采样频率为16 384 Hz,采样时间为10 s。通过控制开启扬声器的个数来分别布置单声源、双声源、三声源的场景。
图11~图13分别展示了不同频率下单声源、双声源、三声源的试验结果,包括输入图CB Map_18和ACM预测图。图例与图6、图7中一样。采集到的信号获得CB Map之后输入DNN_64获得预测结果。结合图11~图13按照频率由低到高观察。

图11 单声源试验结果

图12 双声源试验结果

图13 三声源试验结果
如图11~图13所示,512 Hz的预测结果中3种试验结果都类似,输入图中一个“大主瓣”被分离成了3个主瓣,DL-GFM识别出了错误位置。在输入图类似的情况下,U-Net模型容易识别成训练数据中的三声源场景,导致低频时ACM和DL-GFM方法效果较差;1 024 Hz的单声源预测图减小了主瓣,并且基本准确地识别出了声源位置;双声源预测图中明显观察到两个声源,但产生了较大旁瓣,导致DL-GFM没有正确识别声源位置;三声源预测图中有两个清晰主瓣和一个“浑浊”主瓣,同时声源位置也被准确识别;2 048 Hz的3种声源数目的输出图相较于低频时ACM清晰化效果和DL-GFM位置识别精度都有较大的提升;4 096 Hz的输入图中出现了较大的旁瓣,很容易被DL-GFM识别为弱声源,而3种试验结果都完全清除了旁瓣同时减小了主瓣宽度;8 192 Hz是在试验采样频率下的最大分析频率,可以看到在3种声源数目的情况的输入图中都出现了密集的旁瓣,其大小与声源主瓣宽度相当。最终预测结果成功清除了所有旁瓣,并且声源预测位置与实际位置接近重合。
综上所述,试验结果验证了提出ACM方法的可行性,其作为前处理过程与DL-GFM方法结合,具有高精度的声源位置识别效果。但与仿真结果一致,其在低频段表现出了局限性,这在今后的研究中仍需继续关注。
4 结 论
本文提出了一种基于端到端深度学习模型U-Net 的阵列转换法ACM,将18通道阵列的传统波束形成结果转换为64通道阵列的传统波束形成结果,实现了成像图的清晰化,其旁瓣消除效果优于目标图CB Map_64。相比于DNN_64-18和DNN_18-18,明显提升了深度学习无网格方法DL-GFM的精度,增强了已训练模型的阵列通用性。1个、2个、3个声源的验证试验证明了提出方法的有效性和可行性。结论如下:
(1) 在只有三声源训练数据集的情况下,ACM方法在1~8个声源范围内均有良好的清晰化效果,但在多于3个声源时表现有一定的局限性。
(2) 在本文使用的两种阵列条件下,对于三声源的情况,ACM方法在中高频段清晰化效果好于低频段,并将DL-GFM方法有效频率下限提升到1 072 Hz左右。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15 07:54:30
舰船科学技术(2022年11期)2022-07-15 07:54:10
海军航空大学学报(2020年2期)2020-07-27 02:12:42
通信技术(2019年3期)2019-05-31 03:19:08
电子制作(2019年23期)2019-02-23 13:21:12
电子测试(2018年6期)2018-05-09 07:31:54
电子技术与软件工程(2017年12期)2017-07-05 13:53:25
声学与电子工程(2017年1期)2017-06-22 11:30:09
噪声与振动控制(2016年5期)2016-11-09 09:09:47
电测与仪表(2016年14期)2016-04-11 12:32:48
