
基于手机GPS数据的个体出行链提取方法研究
2023-10-30 11:38周洋杨超郭唐仪
交通运输系统工程与信息 2023年5期
周洋,杨超,郭唐仪
(1.南京理工大学,自动化学院,南京 210094;2.同济大学,交通运输工程学院,上海 201804;3.同济大学,城市交通研究院,上海 200092)
0 引言
居民出行调查是了解城市居民出行行为与出行需求的基础手段,为交通规划与政策制定提供重要依据。出行调查内容覆盖家庭、个人、车辆和出行各个方面,由政府部门牵头组织,工作人员上访社区,通过问卷填写完成相关调查。美国在1969—2017 年,已开展8 次全国家庭出行调查(NPTS/NHTS)[1],我国上海从1986年至今,已实施6次居民出行调查。传统问卷调查方式,包括:面询、邮件、电话、网页及微信小程序等,获取的出行数据具有成本高(大量人力投入)、规模小(抽样率约1%)、时间短(几日出行)且质量差(漏报或错报)等问题。基于智能手机的出行数据采集方法,是近年来智能设备与移动互联网迅速发展下产生的新调查技术,即智能手机主动采集居民日常出行GPS 轨迹并提取出行信息。借助智能手机丰富的定位和感应模块以及高市场渗透率和携带便捷性等优势,实现以较低成本获取大规模城市居民连续多天、时空精确且链接完整的出行数据[2]。然而,该技术的关键瓶颈在于,如何从智能手机采集的GPS数据中识别出行起讫点(即出行端点)、出行方式和出行目的等出行链信息。
GPS 数据根据个体活动-出行时空行为,可划分为活动轨迹段和出行轨迹段,前者表现出空间集聚与静止特征,后者表现为空间发散与运动特征。基于两者差异,学者们一般先从GPS轨迹中识别出行端点,划分活动段与出行段,再推断出行方式和出行目的。①针对GPS 数据的出行端点识别。现状方法包括:基于静止状态判别法[3],即提取连续静止状态轨迹点,根据时长推断是否为活动点;基于地理语义法[4],将静止点与兴趣位置匹配,以位于兴趣位置编码的地理几何实体内的停留作为活动点;基于时空聚类法[5],以时空距离为特征,建立非监督聚类模型提取轨迹点簇。②针对出行轨迹段的出行方式推断。由于一次出行可能包含多种混合交通方式,需将出行轨迹段分割为单方式段,即每段仅包含一种交通方式。单方式段的衔接点称为方式转换点,其识别方法包括:公交站点邻近匹配法[6],即利用公交站点GIS 数据检测出行途中停留点是否为公交换乘点;步行方式段分界法[7],检测步行方式作为非步行方式之间转换的衔接;运动特征变化判别法[8],检测运动特征发生显著变化的片段作为出行方式转换段;机器学习分类法[9],利用标签数据训练监督学习模型,推测停留点是否为方式换乘点。对于单方式段的交通方式推断,近年来方法包括支持向量机SVM[10]、随机森林RF[11]及长短期记忆模型LSTM[12]等方法。③针对活动轨迹段的出行目的推断,主要有规则方法和机器学习。XIAO等[13]提取家庭和个体属性、活动时空特征和交通方式等特征,运用人工神经网络-粒子群优化算法,推断居家、通勤、就餐、购物、社会访问及接送等。ERMAGUN等[14]将活动合并为五大综合类,以出行方式、活动类型、活动时间和时长、个人特征及POI数目等变量建立模型,推断准确率在60%左右。宗芳等[15]以多项Logit 模型划分日出行模式发现,基于模式框架能有效提升出行目的推断精度。
现状基于GPS 数据提取出行链的研究不足之处主要表现为:割裂了出行端点、出行方式和出行目的的识别过程,忽略了三者之间的算法连续性;未建立完整的个体出行链提取算法。为此,本文构建系统的基于手机GPS数据的出行链提取方法,包括:基于时空密度聚类与规则算法的出行端点识别;基于活动链接特征与XGBoost模型的出行目的推断;基于出行微分与公交GIS特征的出行方式推断。本文的主要创新点在于:提出出行链自动提取方法,能够从GPS 轨迹数据中提取时空精确、链接完整且过程精细的出行链;探究出行端点与公交换乘点的区分问题,并分析出行目的和出行方式推断准确性与即时性影响。通过研究GPS 轨迹的时空特征挖掘方法,为智能手机居民出行调查现实应用奠定理论基础。
1 实验数据采集
实验数据主要包括个体出行GPS 轨迹与出行日志,日志记录个体真实的出行信息。为获取准确的出行日志,设计了城市居民出行调查系统,包括:数据采集端、数据处理端和数据验证端。数据采集端是智能手机App,用于采集用户出行GPS 轨迹,并上传至服务器数据库;数据处理端是服务器预置的解析算法,从后台解析GPS数据,获取出行时间、起讫点、交通方式和出行目的等信息;数据验证端是网页界面,从服务器调用出行解析结果并呈现给用户,具有编辑功能,帮助用户完成出行校正,而后将校正的出行信息作为出行日志存储于服务器数据库。与以往人工反馈出行日志的方式不同,本系统能够通过预置算法自动预捕捉详尽的出行信息,如多段交通方式和方式转换点,为本文方法验证奠定重要基础。某用户全日的数据样例如图1所示,左侧为手机GPS数据(频率为1 Hz),右侧为出行日志,两者以时间标签对应。该数据记录了用户07:55:02-20:27:01时段内的轨迹,出行链为{居家→<小汽车>→工作→<小汽车>→居家},包含3 个出行端点和2次出行。
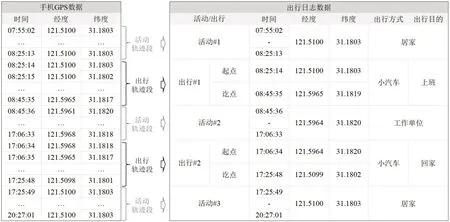
图1 某用户某日手机GPS数据与出行日志数据Fig.1 One person's daily smartphone-based GPS data and travel diary
2 出行链提取方法
2.1 整体框架
建立完整的个体出行链提取方法,包括:出行端点识别、出行目的推断与出行方式推断。如图2所示,数据基础包括:手机GPS 数据、出行日志、家庭个人属性,以及道路网/公交线网GIS数据和城市服务设施POI 数据,具体步骤包括:①应用时空密度聚类方法,从GPS 轨迹中识别停驻点,并建立停驻点时空特征的随机森林模型,将停驻点分类为公交换乘点与出行端点;②建立居住地与工作地空间近邻匹配方法,识别上班、上学和回家;提取家庭和个人属性、活动链与活动时空等多元特征,建立XGBoost模型,进一步推断非家非工作类型的出行目的;③以时间滑窗将出行轨迹段微分为出行片段单元,提取运动特征、出行特征与GIS特征,建立XGBoost模型推断各类出行方式。
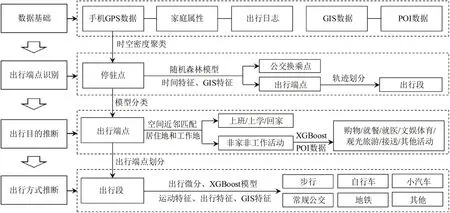
图2 基于GPS轨迹的出行链推断框架Fig.2 Framework of GPS trajectory-based trip chains inference
2.2 数据预处理
坐标转换:假设出行轨迹T={Pi},采用墨卡托投影将经纬度转换为平面坐标值,每个轨迹点表示为Pi=(ti,xi,yi),其中,ti为时间,xi,yi为转换后的平面空间坐标。
特征提取:对于轨迹点Pi,提取速度vi,加速度ai,加速度变化率ci,方向变化率wi等特征,即
噪音剔除:将速度和加速度绝对值从大到小排列,去除GPS轨迹中前1%的轨迹点。
缺失填补:假设轨迹片段{Pi,Pi+m} (m>1),针对缺失点Pi+l(0 <l<m),采用平均插值法填补;并设置缺失状态gi,若Pi为插值补全的点,则gi=1;否则,为0。平均插值法公式为
日志标注:出行日志中活动-出行信息与轨迹点对应,定义运动状态si,si={0,1},若Pi为出行轨迹点,则为1,若为活动轨迹点,则为0。对活动轨迹点和出行轨迹点,分别标注出行目的类型pui和出行方式类型moi。pui={GS,EO,MS,ES,SS,PD,OA},其中,GS为购物,EO为就餐,MS为就医,ES 为文娱体育,SS 为观光旅游,PD 为接送,OA 为其他活动;moi={W,C,B,S,A,O},W 为步行,C 为自行车,B为常规公交,S为地铁,A为小汽车,O为其他。
2.3 停驻点识别
停驻点是个体轨迹中的显著停留,可能为出行端点或公交换乘点等。采用文献[16]提出的时空密度聚类算法识别停驻点,为活动轨迹段与出行轨迹段划分奠定基础。该方法借助了DBSCAN算法思想,用于处理时空轨迹的聚类问题。具体过程如图3所示:以轨迹点Pi为中心,选定长度为KS的轨迹序列,以空间邻域Eps与核心点最小数目MinPts搜索并标注轨迹序列内的核心点;对于所有轨迹序列的核心点,将相邻核心点组合为初始簇,并计算簇密度;以时间邻近Tau和空间邻近Eps为参数,根据密度依次将同时满足时间和空间邻近的初始簇合并为新簇,直至所有簇均完全合并;保留满足最小活动时长DT 的簇,去除出行途中延误等伪停驻。该算法能够较好地克服轨迹点定位漂移与出行路径重合等引起的聚类困难。
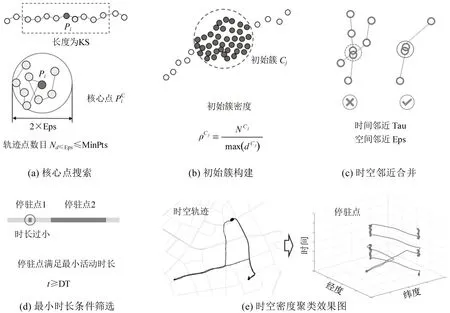
图3 时空密度聚类方法识别停驻点Fig.3 Spatio-temporal density-based clustering method for anchors extraction
针对识别的停驻点,进一步区分出行端点与公交换乘点,本文建立两种对比方法:规则方法和机器学习模型。基于公交换乘点邻近公交站的规则判断,即对于时长小于15 min的停驻点,若其100 m缓冲区内存在公交站或地铁站,则标注该停驻为公交换乘点;否则,为出行端点。基于机器学习模型,以开始时间、持续时长、至家距离、至工作地距离及至公交和地铁站点距离为特征,建立随机森林模型,识别出行端点。
2.4 出行目的推断
城市土地利用集约化与生活设施功能混合,给出行目的推断带来了较大难度。本文分二阶段推断出行目的,先判断上班/上学和回家,再区分非家非工作活动。假设活动轨迹段Tacti={}Pi,每个轨迹点表示为Pi=(ti,xi,yi,gi,pui)。
(1)家和工作判断
用户初次使用智能手机居民出行调查系统时,填报了家庭和个人属性,包括居住地和工作地。利用这一信息,建立基于职住距离的近邻匹配方法,能够快速准确地判断上班/上学和回家。参数包括:至家距离δH和至工作地距离δW,当出行端点与职住地距离分别小于阈值时,判断为居家/回家或工作/上学。各参数下F1 值表现如图4 所示,F1值是分类问题中综合考虑查准率P与查全率R的评价指标,其计算方式为F1=2·P·R(P+R),根据“居家/回家”与“工作/上学”的F1 值,此处,参数取δH=100 m 及δW=100 m。

图4 家和工作活动推断参数优化Fig.4 Parameters refining in home-related/work-related activities inference
(2)非家非工作目的推断
非家非工作活动推断难度较大,可通过提取相关特征提升模型准确率。家庭结构和家庭角色对出行目的有很大影响,年龄和职业是影响活动模式的关键因素[17];个体的移动行为具有时空约束,家与工作在活动链中起着重要约束作用,其他活动的产生均受到主链的影响;不同的活动表现出不同的发生时刻和持续时长;活动位置选择与周边的土地利用及生活服务设施类型具有高度相关性。因而,从家庭属性、个人属性、活动链与活动时空等层面构建特征变量,如表1所示。

表1 出行目的推断相关变量Table 1 Features selection for trip purpose inference
活动类型包括:购物、就餐、就医、文娱体育、观光旅游和接送,从高德地图API中获取主要的城市POI数据,包括:I类(商场和超市)、II类(餐饮服务)、III类(医院和诊所)、IV类(博物馆/展览馆/娱乐场所/休闲场所)、V 类(公园广场和风景名胜)及VI 类(机场/火车站/汽车站)。由于实验GPS 轨迹数据中非家非工作活动类别多而样本少,采用居民出行调查数据进行模型训练与测试。
对类别变量采用one-hot 编码,所有变量标准化后,训练极限梯度提升(XGBoost)模型推断非家非工作类型目的。XGBoost 模型是一种基于梯度提升的集成算法,由多个基分类器累加求得预测结果[18]。每个基分类器为分类回归树(CART),用前一个基分类器的残差作为输入进行构建。假设fk为第k个分类回归树,q为树结构,ω为叶节点权重,分类回归树空间F={f(X)=ωq(X)},对于数据集D={(Xj,Yj)},模型可表示为
目标函数L为损失函数l和树模型复杂度Ω之和,其中,损失函数l以二阶泰勒展开,模型复杂度Ω以L2 正则化处理。对于多分类问题,损失函数采用softmax 函数。对于当前节点和数据集,采用贪心算法计算分裂前与分裂后损失,定义分裂增益,进而寻找最优树结构。
XGBoost 模型重要参数包括:学习率、基分类器数目、树最大深度、最小子集权重及学习目标等,利用二阶泰勒处理损失函数,预测更精确,在叶子权重中增加衰减因子,能防止过拟合。
2.5 出行方式推断
采用出行微分的方法推断交通方式,假设出行轨迹段Ttrip={Pi},每个轨迹点表示为Pi=(ti,xi,yi,gi,moi),其中,gi={0,1} 为缺失状态。
定义时间滑窗(长度为n),将出行轨迹切分为若干固定长度的片段单元,每个片段单元包含n个轨迹点,即片段单元Uj={Pi},i=(j-1)n+1,…,jn。若末尾片段单元长度小于n2,则去除。片段单元的出行方式Yj,为该片段内轨迹点最多的出行方式标签,其中,I(·)为指示函数。出行轨迹微分能有效处理混合交通方式情景。
对每个片段单元Uj={Pi},i=(j-1)n+1,…,jn,提取运动特征、出行特征及GIS特征,构建特征矩阵Xj,如表2 所示。运动特征包括:片段单元平均速度,平均加速度,平均加速度变化率,平均方向变化率。出行特征包括:出行距离dj,静止点比例rsj,轨迹点缺失比例rmj。GIS特征包括:轨迹点至常规公交和地铁线路的最小距离dblj和dslj,轨迹点至常规公交和地铁站点的最小距离dbsj和dssj。其中,静止点比例的速度临界值vs取1.6 km·h-1,distline(·)和distpoint(·)分别为点与线和点与点的直线距离公式符号,BL、SL、BS、SS分别代表常规公交线路、地铁线路、常规公交站点及地铁站点数据集合。GIS特征计算采用轨迹点1 km缓冲区处理公交数据,以提升运算效率。根据提取特征,训练XGBoost模型,推断出行方式。

表2 出行方式推断相关变量Table 2 Feature selection for travel mode inference
3 测试结果与讨论
3.1 实验测试结果
在上海招募了22 名志愿者,运用自主开发的城市居民出行调查系统,完成1 周的出行调查实验,获得109 条全天有效轨迹,每条轨迹包含10000~50000 个轨迹点,基本覆盖了用户的主要时空移动过程。停驻点识别为无监督过程,运用所有实验数据测试结果,以查准率和查全率为指标;出行方式和出行目的推断需训练监督模型,以出行方式分层抽样轨迹数据,训练集与测试集比例设为7∶3,以准确率为评价指标。
停驻点识别上,设置时空密度聚类算法最佳组合参数:KS为180,MinPts为180,Tau为180,Eps为60,DT为120,其中,最小停驻时长DT根据文献[19]取120 s,即提取的所有停驻点时长大于等于2 min。实验数据停驻点共584个,运用算法得到停驻点查准率和查全率分别为96.7%和96.4%。进一步,区分停驻点类型,应用规则算法得到出行端点查准率和查全率为99.8%和83.2%,公交换乘点查准率和查全率为47.5%和98.7%;运用随机森林得到出行端点和公交换乘点查准率分别为97.6%和91.8%。
出行目的推断上,422 个活动点中,有238 个“居家/回家”与83 个“上班/上学”。职住近邻匹配方法识别“居家/回家”准确率为100%,“上班/上学”准确率为89.8%。运用XGBoost 模型推断非家非工作出行目的综合准确率为87.6%,如表3所示。
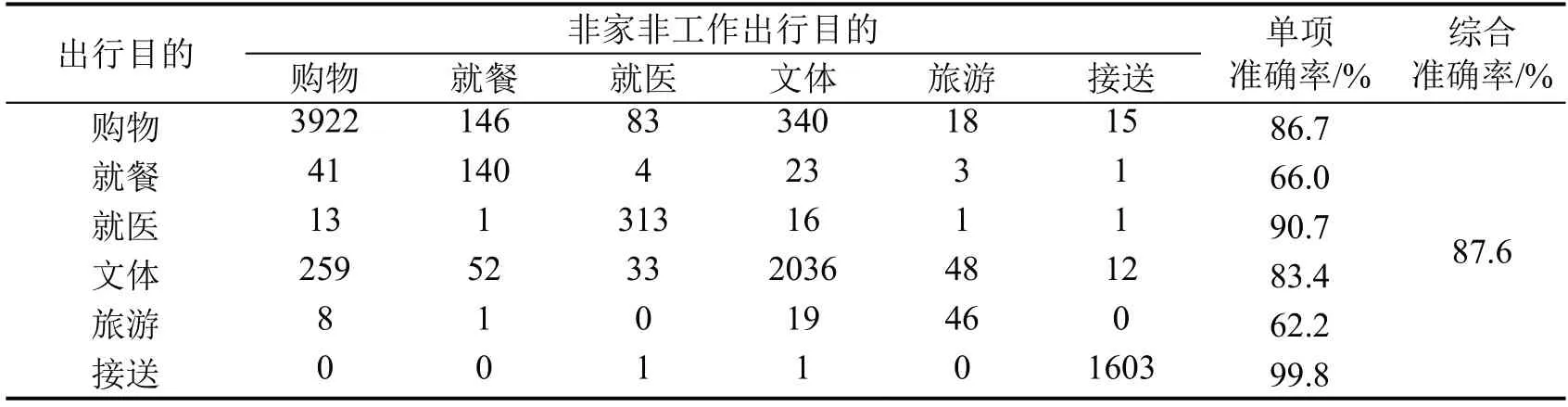
表3 非家非工作出行目的推断混淆矩阵Table 3 Confusion matrix of non-home-non-work trip purpose inference
出行方式推断上,从模型角度,通过对比逻辑回归(LR)、支持向量机(SVM)、人工神经网络(ANN)、随机森林(RF)和极限梯度提升(XGBoost),得到XGBoost模型对出行方式推断表现最佳,综合准确率达到95%,如表4 所示。从特征角度,仅用GPS 数据得到准确率为85.7%,耗时约1 min;使用“GPS+GIS”,准确率为95%,模型训练与预测共耗时约20 min,如表5所示。运用GIS特征后,综合准确率提升了9.3%,但运行时长增加了20倍。

表4 各模型出行方式推断结果Table 4 Accuracy of travel mode inference across models

表5 XGBoost模型推断出行方式结果Table 5 Results of travel mode inference with XGBoost model
将出行端点、出行目的及出行方式等信息整合,得到出行链推断结果。根据两位用户GPS轨迹自动提取的出行链结果如图5 所示,用户1 出行链为:{居家→<小汽车>→工作→<小汽车>→居家};用户2 出行链为:{居家→<步行-地铁-公交>→工作→<公交-地铁-步行>→居家}。通过运算,能够得到全时段、多交通方式且完整链接的个体出行链。
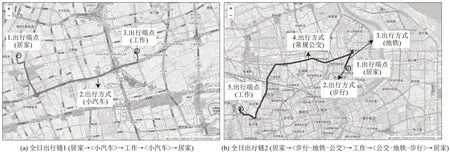
图5 个体出行链推断结果Fig.5 Results of trip chain inference of two cases
3.2 分析与讨论
从停驻点识别出行端点,运用公交站点匹配规则方法,得到公交换乘点查准率为47.5%,表明有一部分非常规的方式转换点被错误分类为出行端点。在本文实验中,这些方式转换点来源于面向单位内部人员的公交班车站点,由于在地图中无对应的POI 数据,造成规则算法误判。4 类停驻点的时空特征如图6 所示,持续时间上,出行端点平均218.2 min,公交换乘点7.2 min,地铁换乘点1.7 min,班车换乘点12.4 min;至站点距离上,公交换乘点至公交站平均62.1 m,地铁换乘点至地铁站86.3 m,出行端点和班车站点至公交站点分别为308.4 m和426.5 m。进一步表明,规则方法难以应对非常规停驻点,而机器学习模型能够通过用户App校正反馈提供的正确标签,提升区分能力。

图6 公交换乘点与出行端点区分参数Fig.6 Parameters to distinguish trip ends from transit transfer nodes
对于出行目的推断,就餐和观光旅游的准确率较差,通过分析混淆矩阵,发现19.3%的就餐被错误判别为购物,25.7%的观光旅游被错误判别为文体娱乐。其原因在于,一方面,购物类和餐饮类POI 分布位置相近,两者具有较高的混淆度;另一方面,就餐与旅游数据量较少,模型训练上存在偏差。购物、就医、文娱体育和接送均取得较好的精度,出行目的综合准确率能够达到85%以上。对于样本较少的部分活动,后期可通过补充调查优化模型。
对于出行方式推断,GIS特征能够较大提升公交车的准确率(12.6%),对路面上公交车和小汽车能有效区分,但同时也极大降低了模型训练和识别效率。出行微分方法有利于实现GPS 轨迹出行方式实时预测,但公交线路GIS数据处理占用了大量运行时间。若计算轨迹与全市公交线网距离,模型训练耗时2 h,本文采用轨迹点1 km 缓冲区处理公交线路,时长下降为20 min。通过轨迹点缓冲区,能有效提升轨迹与GIS数据处理速度。
4 结论
本文基于智能手机采集的GPS数据,研究个体出行链提取方法,得到的主要结论如下。
(1)提出个体出行链提取系统方法,包括:以时空密度聚类算法与随机森林识别出行端点,以职住邻近匹配及XGBoost模型推断出行目的,以出行微分与GIS 特征推断出行方式;通过实验数据测试,得到停驻点查准率和查全率分别为96.7%和96.4%,家和工作相关出行目的推断准确率分别为100%和89.8%,非家非工作目的准确率为87.6%,出行方式综合准确率为95.0%。
(2)出行端点是划分活动轨迹段与出行轨迹段的关键节点,是出行链提取的首要步骤。出行链提取方法应用于现实手机出行调查,不仅需要利用时空密度聚类方法准确识别停驻点,还需建立线上机器学习模型,通过用户反馈的真实标签不断更新,以提升非常规停驻点区分能力。
(3)出行目的与出行方式推断的准确性和即时性,是现实调查的重要技术需求。就餐与购物之间以及观光旅游与文体娱乐之间存在的混淆,对出行目的推断准确率有很大影响,需要更多的轨迹数据与出行调查数据训练模型;轨迹与公交线路匹配能有效提升公交方式识别精度,但极大降低了模型效率,可通过GIS数据简易化存储与缓冲区等处理方式提升运算速度。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
数学物理学报(2022年2期)2022-04-26
小学生学习指导(低年级)(2020年11期)2020-12-14
中学生数理化·教与学(2019年8期)2019-09-18
作文大王·低年级(2018年10期)2018-12-06
现代城市轨道交通(2018年1期)2018-01-25
数学物理学报(2017年1期)2017-06-05
小猕猴智力画刊(2016年5期)2016-05-14
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
都市快轨交通(2014年4期)2014-02-27
