
基于自然驾驶数据的驾驶人跟驰行为内在异质性预测与建模
2023-10-30 11:38张铎饶红玉刘佳琦王俊骅孙剑
交通运输系统工程与信息 2023年5期
张铎,饶红玉,2,刘佳琦,王俊骅,孙剑*
(1.同济大学,道路与交通工程教育部重点实验室,上海 201804;2.杭州海康威视数字技术股份有限公司,杭州 310051)
0 引言
在由人-车-路-环境等组成的交通系统中,驾驶人是最核心的组成部分,也是最复杂且不确定性最强的要素[1]。受到自身驾驶经验技术、习惯偏好及心理生理状态等多方因素的共同影响,人类驾驶行为表现会呈现出人与人之间以及同一驾驶人自身内部的异质性特征,行为复杂且不确定性强,对驾驶行为建模精度产生显著影响。跟驰(Car-Following,CF)行为作为最核心的驾驶行为,占据总驾驶时长的80%以上,是交通流理论研究和高级自适应巡航控制开发的核心所在。因此,对驾驶人跟驰行为异质性进行预测和建模,可以更好地重现驾驶人的行为反应过程,实现更高精度的交通流仿真和更高接受度水平的高级辅助驾驶。
驾驶人异质性包括不同人之间的外在异质性(Inter-driver Heterogeneity)和同一驾驶人的内在异质性(Intra-driver Heterogeneity)。目前,大量研究重点关注人和人之间的外在异质性,包括跟驰过程中的不同驾驶人的行为特征、风格表现及技能差异等[2]。然而,驾驶人内在异质性作为驾驶人受多重因素组合影响产生的自身行为变化,却未能被深入地研究,甚至被忽视。现有研究通常通过特定现象分析驾驶人内在异质性,例如,驾驶人在加速和减速过程中存在的非对称驾驶行为[3],或是驾驶人被切入刺激之后所产生的期望-松弛现象[4],但是,无法扩展至跟驰全过程;另有少数研究试图从全局的视角理解驾驶人的内在异质性,例如,HIGGS 等[5]计算驾驶人跟驰驾驶模式分布,并通过分布离散度评价驾驶人的内在异质性程度;然而,类似研究更多地停留在内在异质性的后验分析之上,无法应用于内在异质性的预测和建模。
全面的驾驶人内在异质性研究需要对驾驶人长时驾驶行为观测的精确数据记录,以识别驾驶人在长时间驾驶过程中的短时变化,这是本文要面对的挑战。虽然随着当前数据收集和存储技术的发展,可以通过航拍等视频采集方法获取更丰富的驾驶行为轨迹,例如,经典的下一代模拟(Next Generation SIMulation,NGSIM)数据和最近应用广泛的HighD数据集等,但是无法提供对于单一驾驶员的长时域充足观察和建模支持;而对驾驶人行为研究的另一主要数据来源为驾驶模拟器实验,但是其本质属于受控型任务实验,驾驶人自身驾驶行为的保真度低,驾驶人与车、路及环境之间的交互弱,无法准确地提供驾驶人在自然状态下的行为变化特征,限制了建模成果的实际应用。
另一方面,驾驶人的驾驶行为是多方因素共同作用下的结果。过往的研究当中,驾驶人的社会经济属性、交通设施和环境以及车辆之间的交互均被证明对驾驶人的行为特征产生显著影响[2]。更具体地,在有限的内在异质性影响因素研究当中,ZHANG 等[6]发现,在地面道路场景中跟驰模型的标定误差显著高于城市快速路场景,说明驾驶人在地面道路中会表现出更强烈的内在异质性;RAO等[7]第一次综合分析驾驶人内在异质性的影响因素,并认为车辆之间的交互运动和环境因素均会导致内在异质性发生。因此,为准确地预测驾驶人内在异质性,需要具备不同驾驶人在行驶过程中的人-车-路-环境等全要素记录。
此外,驾驶人内在异质性是驾驶过程中的小概率事件,约占驾驶人驾驶时长的15%[7],其稀有性也使得对其实时准确预测成为挑战。现有的研究未能提供驾驶人内在异质性发生的明确诱因,例如,长时速度波动或者短时邻车刺激均有可能导致异质性的发生[7];而驾驶过程通常存在较强的随机性和非线性规律,也进一步增加了预测驾驶人内在异质性的难度。近年来,深度学习模型基于层次更深和更复杂的网络,相比传统统计学模型应对高维时序的能力更强,应对不同任务的灵活性更高,在驾驶人行为建模当中展现了较好的优势;但是,与此同时,常用的基于循环神经网络的模型仍存在“忘记”过去长期依赖信息的可能性,从而有可能影响对于稀有异质性事件的发掘。
为解决上述挑战,本文提出一种驾驶人内在异质性预测方法,并应用于驾驶人跟驰行为建模当中。本文的主要贡献为以下3点:
(1)引入包含41位驾驶人长期行为观测的大规模自然驾驶数据,基于精度最高且广为接受的智能驾驶员模型(Intelligent Driver Model,IDM),通过4100 个跟驰片段建立每位驾驶人的基线跟驰行为模型,识别提取出3194个驾驶人内在异质性事件。
(2)为解决高维跟驰行为时间序列中稀有内在异质性事件预测和分类的任务,引入具有自注意力机制的Transformer 模型,更好地发掘内在异质性产生和多因素作用之间的长短时依赖关系;并通过增加时序遮盖机制,实现准确预测驾驶人内在异质性。
(3)基于驾驶人跟驰内在异质性预测结果,考虑实际跟驰建模当中对内在异质性建模有效性和易用性的要求,设计3种依赖驾驶人跟驰模型动态参数变化的建模方法,分别为统一类别下建模、不同异质性偏离方向下建模和不同加速度状态下建模;进一步对比不同方案下的建模效果,确定最佳的驾驶人跟驰内在异质性建模方案。
1 问题描述与研究框架
驾驶人跟驰行为内在异质性是驾驶人在一次出行过程当中的短时行为变化,是从正常到异常再到正常的转变。正常行为是驾驶人在长时间之内保持的基本驾驶模式,可以在类似的刺激之下做出相似的行为表现,通过基线模型可以较好地重现出来;异常行为是脱离驾驶人本人基本的行为模式,在类似刺激之下做出的和正常行为具有显著差异的行为。内在异质性发生时的间距变化特征如图1所示。

图1 内在异质性事件发生Fig.1 Illustration of occurrence of intra-driver heterogeneity
因此,内在异质性发生时的行为无法被代表驾驶人原本行为特征的基线模型描述,对跟驰行为建模精度产生较强的负面影响,需要单独对其识别、预测与建模。首先,需要利用大规模的自然驾驶数据发掘小概率的驾驶人内在异质性事件以及事件中同步记录的全要素信息,为训练实时内在异质性预测器提供多驾驶人、多道路环境及多车辆交互状态下的数据基础;然后,依赖高维跟驰行为时间序列=(x1,x2,x3,…,xT),其中,xT为T时刻车辆跟驰的全要素信息,建立高精度深度学习(Deep Learning,DL)预测模型为
式中:FDL(·)为训练的深度学习预测器;YT+1为预测的T+1 时刻内在异质性事件类别标签,同时,考虑内在异质性中可能存在的不同行为类别,预测器被要求支持多分类预测;最后,基于每个时刻所预测的内在异质性标签,动态地选取行为建模参数,实现对于正常驾驶行为和内在异质性发生时异常驾驶行为的独立建模。驾驶人跟驰内在异质性研究框架,如图2所示。
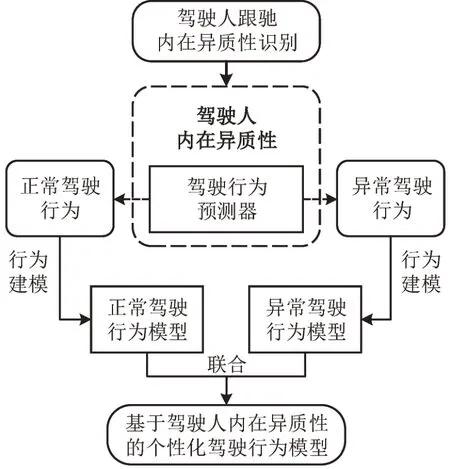
图2 研究框架Fig.2 Framework
2 驾驶人内在异质性事件提取
2.1 数据来源与跟驰样本提取
驾驶人内在异质性事件的稀有性和其诱因的复杂性,使数据成为开展驾驶人内在异质性研究的关键和基础。基于定点采集的数据或者基于驾驶模拟器的数据均无法满足发掘内在异质性多驾驶人长期观测和人-车-路全要素覆盖的要求,非受控状态下采集的大规模自然驾驶数据成为内在异质性研究的必需。因此,本文引入与通用、腾讯和华为等联合采集的自然驾驶数据[6]。首先,该自然驾驶数据中提供了41位具有充足跟驰样本记录的驾驶人,对每位驾驶人进行长达1个月的长期行为观测,参与驾驶人在性别比例、不同年龄段比例以及不同驾龄段的比例与公安部公布的中国普通驾驶人群的分布基本一致,最大比例差距保持在5%以内;其次,驾驶行为信息收集全面,包括多普勒雷达、三轴加速度计、GPS和4个同步摄像头,以0.1 s为步长记录实验车辆本车的运动信息和周围车辆的信息,如图3所示。原始数据集已完成多源数据的融合与同步,在此基础上,使用3 次样条插值修补数据,使用卡尔曼滤波对数据进行降噪处理。
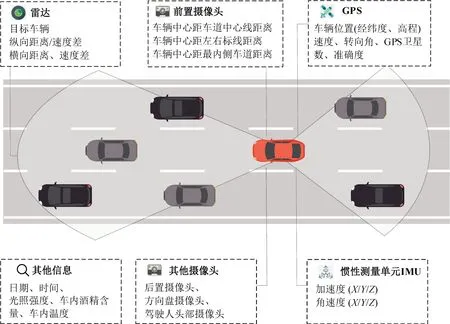
图3 自然驾驶实验数据采集Fig.3 Data information in naturalistic driving data
基于自然驾驶数据,完成每位驾驶人跟驰行为样本的提取。由于该数据已在ZHANG等[6]针对驾驶人跟驰行为的先行研究中得到应用,提取标准也一并参考。最终,提出41 位驾驶员每人100 个样本,每个跟驰样本超过30 s,共4100个样本,总时长超过3000 min。
2.2 内在异质性样本提取
驾驶人内在异质性是脱离驾驶人本身基本行为基准,在相同的刺激之下表现出不同行为倾向的事件,使原本代表驾驶人行为倾向的跟驰模型无法描述。因此,可以使用标定好的驾驶人跟驰模型作为基线,根据行为特征偏离情况识别相应的驾驶人跟驰内在异质性事件。
(1)驾驶人基线行为模型获取
异质性的提取首先需要对每个驾驶人标定其基线行为模型。为了能很好地捕捉驾驶人在大部分时间内保持的正常驾驶行为,本文选择智能驾驶人模型[8](IDM)作为基准跟驰模型。IDM模型是典型的基于驾驶期望的跟驰模型,能够智能地在各个状态之间切换,实现从自由行驶到跟驰状态的平滑过渡,被现有研究证实是常用跟驰模型中性能表现最好的之一[6]。其表达式为
式中:s0为静止状态下本车能接受的与前车间最小的间距;为本车期望的与前车之间的车头时距;Δvα为当前本车与前车之间的速度差;bcomf为本车的最大舒适减速度。在数据提取过程中,本文为每位驾驶员选取了100 条轨迹用于标定。标定过程参考了RAO等[7]的研究。
在标定基线模型的过程中,偏差的度量指标使用跟驰轨迹复现中最常用的跟驰间距[6],误差指标使用跟驰建模中常用的均方根百分比误差(Root Mean Square Percentage Errors,RMSPE)[7],即
(2)驾驶人内在异质性识别
内在异质性的识别本质等同于机器学习领域中的异常检测任务和多维时间序列预测任务的组合。参考异常检测中的常用方法,即对比自编码器中输出的时序和真实时序寻找异常片段的位置,可以识别驾驶人内在异质性时间。本文以每个驾驶人标定后模型作为每个驾驶人的基线行为模型,通过数值仿真求出目标车辆的仿真轨迹,将其作为未发生异质性情况下的基线轨迹。通过比较真实样本中驾驶人的轨迹和模型输出的基线轨迹的偏差,完成对内在异质性事件的识别。IDM 模型作为经过实证数据验证的优秀模型,能够在大多数情况下保持对于驾驶人基本行为特征的复现。正常事件和出现异质性事件如图4所示。
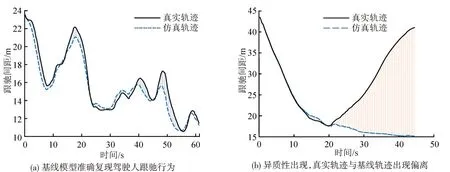
图4 正常行驶事件和出现异质性事件的事件Fig.4 Normal car-following event and event containing intra-driver heterogeneity
图4(a)中,虽然IDM与真实轨迹存在一定的偏离,但是,IDM的整体趋势与真实轨迹相符,且每个时刻的偏差较小。图4(b)中,IDM与真实驾驶行为的偏离十分明显,代表驾驶人基本驾驶偏好的IDM选择了缓慢靠近前车,但是,真实轨迹中,驾驶人却快速远离,此时,则认为驾驶人发生了内在异质性事件。
参考RMSPE 的表示形式,以百分比形式计算偏差。为方便表示,将其命名为异质性偏差(Heterogeneity Bias,HB)。t时刻的RHB(t)为
根据RHB的大小判定异质性时间的发生。由于过往研究中对于异质性的定义和研究角度并不统一,无法沿用其应用的指标或者阈值标准。在本文中,根据统计所有驾驶员的历史集计分布,以RHB分布的85%分位数作为阈值,用于区分RHB是否处于异质状态,即只有误差最大15%的偏差(在所有RHB中)才被视为显著偏差。使用85%分位数作为本文阈值标准的原因:一是,85%分位数是长期以来交通工程实践当中最常用的用于交通安全分析和设计标准的度量;二是,在驾驶行为的分析当中被广泛作为行为划分的阈值[9]。跟驰间距异质性偏差分布和阈值选取如图5 所示。图5 中41 位驾驶人跟驰间距的百分比误差分布表明,阈值为39.63%。根据阈值对重构误差进行划分后,识别出3194个异质性时间段。

图5 跟驰间距异质性偏差分布和阈值选取Fig.5 Distribution of HB and intra-driver heterogeneity threshold selection
3 驾驶人内在异质性事件预测与建模
驾驶人内在异质性事件发生概率小且随机,同时,驾驶人内在异质性事件也存在着不同的表现。因此,本文研究方法分为递进的两部分:首先,是“预测”部分,提出一个在复杂因素作用下预测驾驶人内在异质性类别的预测模型;然后,是“建模”部分,基于预测的异质性时间标签,选用合适的建模方法,通过数学解析模型准确描述驾驶人内在异质性行为。
3.1 内在异质性事件预测方法
驾驶人的驾驶行为受人-车-路环境的动态综合作用,一方面,目前的研究未能通过解析的方式发掘驾驶人内在异质性的影响显式诱因[7];另一方面,内在异质性事件的预测本质上属于高维度(跟驰全要素)时间序列的预测和分类问题。传统统计学模型处理复杂和强非线性数据的能力有限,对比之下,深度学习模型作为机器学习的分支,已经在复杂的分类问题中展现了更强的适应性和更好的准确性表现,而且能够处理更大规模的数据和更多维度的输入特征。长短时神经网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)作为经典的循环神经网络模型(Recurrent Neural Network,RNN)在交通领域当中已经得到了大量的应用[10],但是,由于RNN 自身的模型结构限制,不能并行计算,导致计算效率较低;同时,由于隐藏状态保留机制,在处理长期依赖时可能存在信息遗忘的不足。近年来,具备自注意力机制的Transformer被提出[11]并且广受关注,其特殊结构使其并行处理整个序列,计算速度快;同时,不依赖于过去的隐藏状态捕获对先前动作的依赖性,在发掘时序当中的长期依赖特征和时间序列预测任务上得到应用,并且取得了较好的表现[10]。因此,本文提出一个基于Transformer 自注意力机制的模型,以学习长短时因素对稀有内在异质性事件的影响,实现准确预测内在异质性事件。
(1)内在异质性预测器输入
深度学习模型能够更好地应对高维度的特征输入,且对多重共线性问题不敏感。因此,在对驾驶人的内在异质性进行预测建模时,模型将使用自然驾驶数据中涉及的所有特征(由于特征将作为序列被输入,所以,不包括其最大最小值等指标)作为输入。此外,根据文献[7]的驾驶人内在异质性的影响因素分析结果,不同驾驶人或驾驶人在不同次行程中的驾驶行为特征可能会存在区别,所以,分类器的特征输入中还包含了驾驶人和行程的编号。输入特征如表1所示。

表1 驾驶异质性预测器的输入特征Table 1 Input attributes of deep learning predictors
同时,考虑到工作领域、天气、驾驶人编号和行程编号等离散变量的分类数大于1 且各分类之间不存在有序特征,而常用的独热编码(One-hot Encoding)会占用非常大的特征空间影响训练效率,本文选择特征空间占用少和泛化能力好的K 折目标编码(K-fold Target Encoding)方法,并参考AHSAN 等[12]的研究,将K设置为5。此外,由于模型会分批训练数据集,而同一批次数据的长度可能会不同,为了能同时训练这些数据,需要对其中较短的数据进行填充(Padding)操作,将其长度用0 补长至与该批次中其他数据相同。为减少填充数据对分类器精度产生的负面影响,本文将待填充位置处的驾驶行为分类进行单独设置,并将其所有的输入特征设置为某一足够大的常数值,区分其与正常训练数据。
(2)Transformer变体模型
Transformer 模型于2017 年被提出,它是一种基于注意力机制的深度学习模型,在除自然语言处理之外的多个领域均具有广泛的应用,例如,自然语言处理和时序预测等[10]。虽然本文中的跟驰样本不是标准意义上的长时序,但是Transformer的核心是其采用的自注意力机制(Self-attention mechanism),使其可以更好地聚焦于不同位置的信息,从而更好地捕捉时序数据中的局部和全局依赖关系。因此,本文提出一个基于Transformer 的预测模型,输入为跟驰轨迹数据中的驾驶行为特征指标,输出为预测出的下一个时刻的驾驶行为分类。
考虑到该任务本质上并不属于传统Transformer 序列到序列的结构,因此,在结构上保留Encoder 部分,然后,在原本Encoder 的输出之上添加一个全连接层和一个Softmax 层,以供模型输出预测分类。这样做的主要原因是:原始Transformer 当中,Decoder 中的输入序列采用了teacher forcing[13]的技术,这种技术使训练时Decoder强制使用真实目标序列中的前一个时刻的标签作为输入,而内在异质性事件的预测输出是离散01 结构(类似于[000111…]的序列),且0 和1 通常是连续出现,因此,当读取到上个时刻的真实序列变化(例如,真实序列里从0 变成了1),使得Decoder“偷看到了答案”,知道应该从0 变到1,从而可能无法学到内在异质性本质的特征。而Encoder依旧保留其核心的多头自注意力机制模块,仍然具有识别长短时依赖关系的能力。Transformer变体的结构如图6所示。

图6 Transformer变体结构Fig.6 Modified Transformer structure
自注意力机制是Transformer 模型最核心的内容,也是在进行驾驶人内在异质性预测建模时需要重点关注的关键。简而言之,注意力机制的本质就是从全局中找出最值得关注的重点,并将有限的注意力集中在重点信息上,从而达到节省资源,快速获得有效信息的目的。而自注意力机制中的“自”是在对输入的序列数据进行注意力运算时,只会使用到其自身的信息,计算序列中不同位置的数据之间的某种特殊的“注意”关系。输入自注意力模块的序列经相应运算后,会得到一个与输入序列长度和格式均相同的输出序列,输出序列中每个位置的数据均包含该位置与其他位置上数据之间的注意力信息。X为输入矩阵,乘3 个系数矩阵WQ、WK及WV,得到查询(Query,Q)、键(Key,K)和值(Value,V)这3 个矩阵,进而将Q矩阵乘K矩阵的转置得到分数(Score,S)矩阵,将S矩阵中的每一个元素做除以的标准化,得到自注意力机制的输出Z矩阵。如图7(a)所示。自注意力机制和多头自注意力机制的具体计算参见VASWANI等[11]的详细介绍。
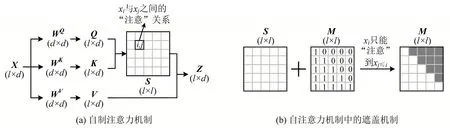
图7 自注意力机制Fig.7 Simplified illustration of self-attention mechanism
如图6 中结构所示,另外一个改动是对Transformer-Encoder 部分中的多头自注意力机制进行了时序掩码。原本的Encoder 当中,由于全序列输入,位置i可以注意到之前或者之后的任意位置;但是,对于驾驶人内在异质性预测问题而言,在实际应用中由于时间的单向性,分类器无法获取完整输入序列中后验部分的驾驶行为特征信息。因此,为了保证与实际应用的一致性,Transformer 模型在计算某一时刻的输出时,使用输入序列中位于该时刻之后的特征信息是“非法”的。因此,需要将原本Transformer-Decoder 当中的时序遮盖机制迁移到Encoder当中。图7(b)展示了用于预测所应用的自注意力遮盖机制。构造一个与S矩阵形状相同的遮罩(Mask)M矩阵,M矩阵中存储的布尔值记录了S矩阵中对应位置的元素是否需要被遮盖的信息;然后,对照M矩阵,将S矩阵中需要被遮盖的元素的值填充为0,相当于完全抹除了某位置对处于其之后位置的“注意”信息,即可达到在输出某时刻的驾驶行为分类时,只能利用输入序列中该时刻及其之前时刻的特征信息的目的。
3.2 内在异质性事件建模方法
基于驾驶人内在异质性预测结果,对内在异质性进行建模,提高驾驶人跟驰行为复现精度的方法。内在异质性的产生使原有的基线模型不再适用,需要在内在异质性事件发生时,动态调整模型结构或参数适应新的行为模式。目前,对内在异质性事件的特征研究有限,不足以为修改模型结构提供足够的指导;同时,动态调整模型参数的建模方法已经在文献[5]行为变化相关的研究中被证明是一种简单有效的方案,因此,本文提出一种动态参数建模逻辑,驾驶行为分类器在每一仿真时刻(0.1 s)均会根据0 时刻到当前时刻的跟驰轨迹数据,预测输出下一个时刻的驾驶行为分类,指导驾驶行为模型在当前时刻为驾驶人适用相应的模型参数,如图8 所示。同时,虽然已知内在异质性不同于正常行为模式,但内在异质性行为自身是否存在不同类别还有待商榷,因此,存在对不同类型异质行为分别建模的潜在需求。
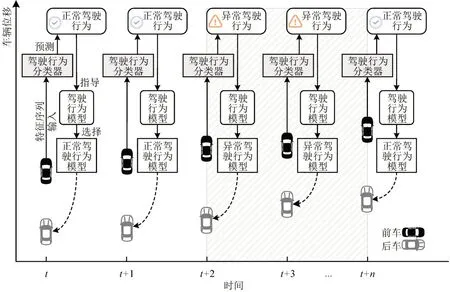
图8 基于预测结果建模驾驶人内在异质性的逻辑示意Fig.8 Logic of intra-driver heterogeneity modeling based on prediction results
通过对不同内在异质性事件的对比分析发现,内在异质性行为自身可以从两个角度进行分类:第1种划分方法是基于内在异质性行为相对于基线行为的偏离方向,一类异质性事件是真实轨迹比仿真轨迹大幅靠近前车,作为一类激进的异质性行为,如图9(a)所示;另一类异质性事件是真实轨迹相比仿真轨迹大幅远离前车,作为另一类保守的异质性行为,如图9(b)所示。第2 种划分方法是基于内在异质性行为发生时的加减速操作,根据主车分别处于加速、减速及匀速(加速度绝对值小于0.3 m·s-2)进行分类。

图9 驾驶人内在异质性分类及标签示意Fig.9 One intra-driver heterogeneity classification and corresponding labels
综上,本文提出内在异质性行为的3 种方案:第1种是只区分基线行为和内在异质性行为,为异质性行为标定1套额外的IDM模型参数,用以内在异质性行为建模,为二分类方法;第2 种方法是将内在异质性行为根据其相对于基线行为的偏离方向进行划分,在正常行为基础上为2类异质行为额外标定2 套IDM 参数,为三分类方法;第3 种方法是根据异质性产生时后车处于的加减速状态不同将内在异质性划分为3 类异质行为,然后,在正常行为基础上额外标定3 套IDM 参数,为四分类方法。基于偏离方向的分类预测标签进行不同类别内在异质性建模的方法如图9所示。
4 实验与结果分析
首先,基于本文提出的方法框架,完成Transformer模型代码搭建,并通过超参数寻优确定最佳超参数和模型在不同类别异质性事件上的预测结果,同时,为对比本文模型的效果,与时序预测分类任务当中常用的LSTM模型进行了预测精度对比,确立本文模型的有效性;然后,基于训练好的Transformer预测模型,根据预测异质性类别动态选择跟驰模型参数,得出3种建模方法的跟驰轨迹还原误差,同时,对比3 种方法的精度提升能力;最终,确定最佳的建模方案。
4.1 内在异质性事件预测结果
本文基于4100个跟驰场景,总长度为3003 min的数据训练驾驶行为分类器。将跟驰场景按6∶2∶2的数量比例随机划分为训练集、验证集和测试集,并基于划分好的数据集对工作领域、天气、驾驶人编号和行程编号4 个输入特征进行K 折目标编码。最后,为减小同批次中跟驰场景之间的长度差距,尽可能地减少对序列进行填充的长度,在每个数据集中均对跟驰场景按其持续时长进行排序。为避免每个跟驰样本初始阶段信息过少导致无法学习依赖特征,预测器从第5 s开始进行预测。
本文驾驶行为分类器的代码基于Python 编程语言中的Pytorch框架实现,并在Linux平台上使用型号为NVIDIA RTX3090 的GPU 进行训练,CPU为至强银牌4214R,内存为128 GB。将训练中的优化器设置为Adam 优化器,且初始学习率设置为0.001,衰减率设为0.9,每批次训练的跟驰场景数为100,训练轮数为300轮。此外,考虑正常和异常驾驶行为存在样本不平衡现象,为得到更好的训练效果,将分类器的损失函数设置为加权交叉熵。训练过程中Transformer 模型的超参数设置通过Optuna工具包[14]进行寻优,如表2所示。

表2 Transformer模型超参数设置Table 2 Hyperparameter setting for Transformer model
为能更好地说明上述驾驶行为分类器的分类效果,本文将其与另外2种建模方法进行对比。包括文献[15]中采用的回归分析模型和在时序数据预测问题中最常用的长短期记忆神经网络。最终结果使用通过混淆矩阵计算的预测精确率(Precision)、召回率(Recall)和F1分数(F1-Score)。精确率反映分类器或者模型正确预测异质性样本的能力,即预测的正样本当中有多少是真正的正样本;召回率考虑的是预测的另外一个方面,即反映分类器或者模型正确预测正样本全度的能力,即被正确预测的正样本占总的正样本的比例。F1分数是两者的加权调和平均,反映模型综合的预测能力。测试集预测结果如表3所示。

表3 测试集预测结果对比Table 3 Comparative results of investigated prediction model (%)
从驾驶行为分类标签的准确率中可以看出,训练得到的基于Transformer 模型的分类器有着较好的表现,对比LSTM 有着更高的准确率,说明基于自注意力机制的深度学习方法能够很好地预测驾驶人的内在异质性。相比于二分类预测,三分类预测的任务难度提高,使预测效果有些许下降。同时,模型对于异质性的精确率普遍大于召回率,说明模型对于异质性时间的预测偏向谨慎,即更多地保证预测出来的异质性时刻为真正的异质性时刻。与本文异质性事件由主观阈值划分有关,因为,行为是连续的,而分类是通过主观阈值划分出的离散值,导致模型在异质性开始和结束时段出现预测不精准的情况。此外,本文还统计了内在异质性事件预测起讫点与真实起讫点相比的延迟或者提前量绝对值,结果显示,均值在0.46 s,方差在0.73 s,说明模型能够在较短时间内预测内在异质性事件。预测结果示例如图10所示。

图10 驾驶人内在异质性分类预测结果示例Fig.10 Example of prediction result of intra-driver heterogeneity event
4.2 内在异质性事件建模结果
基于上述异质性事件预测结果,对驾驶人表现出异常驾驶行为的时间段重新建模。3 种针对于异质性事件的建模结果被提出,最终结果如表4所示。

表4 内在异质性建模结果对比Table 4 Comparative results of three modeling methods integrating intra-driver heterogeneity (%)
首先,未对驾驶人的异常驾驶行为进行分类,直接对其进行建模的情况下,仅使用1套额外IDM模型参数的标定结果不够理想,整体的驾驶人平均标定误差(跟驰间距的均方根百分比误差)相较于在这些跟驰场景全程中均使用基准跟驰模型的对照情况,仅有4.0%的下降。说明为了能在个性化驾驶行为模型中更好地还原驾驶人变化的驾驶行为,有必要对其异常驾驶行为进行更精细化的分类和建模。
然后,从表4 中可以看出,按跟驰间距大小进行分类后,驾驶人异常驾驶行为建模的平均标定误差最小,其对比基准跟驰模型的误差降幅达到21.08%。说明基于变化的跟驰模型参数,可以比较好地还原原先单独使用基准跟驰模型无法还原的驾驶人内在异质性现象。
基于个性化模型进行轨迹仿真的具体结果示例如图11所示。

图11 驾驶行为模型在长时间跟驰中的仿真结果示例Fig.11 Example of a car-following events described by models with or without intra-driver heterogeneity modeling
由图11可以看出,在单个跟驰场景中,对比常规仿真中的非个性化的驾驶行为模型(跟驰场景全程仅使用基准跟驰模型)而言,本文提出的个性化驾驶行为模型能够更好地还原驾驶人变化的驾驶行为。此外,在长时间的跟驰中,即使驾驶人多次表现出内在异质性,该个性化驾驶行为模型也能准确地预测异常驾驶行为的出现,并更加精确地还原车辆的跟驰轨迹。
5 结论
驾驶人驾驶行为的内在异质性分析是个性化驾驶行为建模的关键,也是实现更高精度的交通流仿真和更高接受度水平的高级辅助驾驶算法开发的基础。本文基于大规模自然驾驶数据提取出大量驾驶人内在异质性事件,实现驾驶人内在异质性动态预测和高精度建模。主要结论如下:
(1)驾驶人内在异质性广泛存在于跟驰行为驾驶任务中。通过引入大规模全要素自然驾驶数据,基于41位驾驶员的长时间观测建立基线跟驰行为模型,在4100 个跟驰片段中完成3194 个内在异质性发生事件的识别,以及与事件相关联的多维潜在影响因素提取。
(2)内在异质性行为可被动态预测。考虑内在异质性成因的不确定性和影响因素的复杂性,提出基于Transformer 模型的预测方法,并通过时序掩码的方式完成对内在异质性持续时间的预测。在建模表现最佳的三分类任务上,事件发生时刻点预测精确率为88.39%,召回率为85.92%,F1分数达到87.13%;相较于LSTM 模型,F1 分数绝对值高出了4.96个百分点,增幅为6.04%。
(3)内在一致性建模可显著提高跟驰行为建模精度。基于驾驶人跟驰内在异质性预测结果,设计3 种依赖驾驶人跟驰模型动态参数变化的建模方法,其中,基于跟驰间距偏离方向对内在异质性分类的建模方案效果最好,跟驰间距RMSPE 误差降低了21.08%。
猜你喜欢
现代企业(2021年2期)2021-07-20
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
邯郸职业技术学院学报(2016年2期)2016-02-27
首都外语论坛(2014年1期)2014-03-20
