
基于Adaboost 与LDP 算法的人脸识别研究∗
2023-10-20 08:24刘从军
计算机与数字工程 2023年7期
傅 铭 刘从军,2
(1.江苏科技大学计算机学院 镇江 212003)(2.江苏科大汇峰科技有限公司 镇江 212003)
1 引言
近些年来身份识别广泛应用于实际生活中,而人脸识别具有易用性、互动性、稳定性等特点受到更多青睐[1~2],例如购物结账时的刷脸付款和乘坐火车时的刷脸进站。
为了能够提高人脸识别的正确率、减少识别时间,首先利用基于YCbcr 模型的皮肤分割算法和Adaboost算法对采集到的图像进行人脸检测,确定人脸区域范围,之后再使用改进后的LDP算法提取特征识别人脸。
2 人脸检测
2.1 Adaboost
实际生活中采集到的人脸图像不但包括人脸部分还有非人脸部分,在进行人脸识别之前首先要做好人脸检测,人脸检测的效果越好,之后的人脸识别就更省时、成功率更高。在人脸检测阶段使用基于Adaboost 算法的人脸检测,主要有三部分工作,第一训练弱分类器,第二训练强分类器,第三得到级联分类器。
首先通过训练Haar-Like矩形特征得到弱分类ℎ(x)[3],公式如下:
x表示学习图像,f(x)即Haar-Like 特征值,λ表示区分人脸和非人脸区域的阀值,q为正一或者负一以此来控制不等号的方向,ℎ(x)为符号函数。但是弱分类器的分类能力不强,只比随机分类精确一些,容易检测错误。
第二将弱分类器训练成强分类器以提高人脸检测的效果[4]。训练过程如下:
1)选取T个弱分类器,m个非人脸图像样本,n个人脸图像样本[5]。设所有样本为(x1,y1) ,(x2,y2)… (xm+n,ym+n),且当yi=1时表示样本为非人脸,yi=-1时表示样本为人脸。
2)初始化样本权重,非人脸样本为ωt(i)=1/2m,人脸样本为ωt(i)=1/2n。
3)对当前样本权重ωt(i)做归一化处理:
4)每个Haar-Like 矩形特征训练一个弱分类器[6~7],再计算每个弱分类器的加权错误率之和εt,公式如下:
其中ωt(i)表示第i个样本的权重,ℎt(xi)-yi表示第t个弱分类器对第i个样本是否分类对。
5)在所有弱分类器中选出加权错误率之和εt最小的弱分类器ℎt(x)[8]。
6)更新样本权重,公式如下:
其中εt表示第t个弱分类器的加权错误率之和,ωt(i)表示第i个样本的权重,ωt+1(i)表示第i+1个样本的权重。
7)如果t≤T,重复3)至6)的过程。
8)最后得到强分类器为
其中αt=ln1/βt,ℎt(x)表示第t个弱分类器,H(x)为符号函数。
第三将若干强分类器依次相连组成级联分类器[9],前几级的强分类器由少量弱分类器训练得到,可以根据人脸典型特征快速区分人脸区域和非人脸区域,后几级的强分类器相对复杂,用以区分差异性较低的区域。
在得到级联分类器之后,就可以以此进行人脸检测,采集到的图像首先进入第一级强分类器,任何被判断为零的区域都会被去除,只有被判断为一的区域才能进入到下一级,以此循环,直到通过所有强分类器,就可以确定图像中的人脸区域。
2.2 改进Adaboost
基于Adaboost 算法的级联分类器在检测人脸存在用时较长,精确度有待提高的问题。因为Haar-Like 矩形特征是对整个采集到的图像提取的,包括人脸区域和非人脸区域,所以用于训练弱分类器的Haar-Like 矩形特征数量过多,大量时间浪费在对非人脸区域的特征提取上。
针对上述问题对Adaboost 算法做出了改进。利用基于YCbcr模型的皮肤分割算法,过滤掉采集图像中的非人脸部分,减少Haar-Like 矩形特性的数量,节约特征提取的时间。
将采集到的图像从RGB 模型向YCrCb 模型的转换[10~11],公式如下:
其中Y表示像素明亮度,Cb表示蓝色色度,Cr表示红色色度。
转换公式的计算过程中涉及到浮点数,考虑到在现实生活中计算机的运算特点,对于浮点数的计算较慢,应尽量用整数代替,因此对转换公式的系数作出优化,以计算像素明亮度的公式为例。
得到改进后的转换公式为
在YCrCb 模型下分量Y对是否是人脸的判断影响小,主要由Cb分量和Cr分量决定,如图1 所示,是人脸在YCrCb模型下Cb、Cr的分布。

图1 Cb、Cr 的分布图
由实验可知YCrCb模型下人脸Cb分量主要在80~125之间,Cr分量主要在130~170之间,由此得到肤色分割的公式如下:
其中Cb(x)表示像素点的蓝色色度,Cr(x)表示像素点的红色色度。YCrCb 模型效果图和肤色分割效果图如图2所示。

图2 处理效果图
3 特征提取
3.1 LDP
在完成采集图像的人脸检测后,使用Local Directional Pattern(LDP)即局部方向模式进行人脸特征的提取,包括边缘响应值的计算[12]和编码[13]两个步骤。
计算边缘响应值的公式如下:
其中I表示输入的人脸图像,Mi表示第i个方向上Kitch 算子,*表示卷积计算,mi为第i 个方向上的边缘响应值。
Kitch算子模板[14]如下所示。
编码的公式如下:
其中LDP(x,y)表示坐标(x,y)像素点的LDP 编码,|mk|为 |mi|中第k大的值,|mi|为mi的绝对值,s(x)为符号函数。
实现原理如下,以人脸图像中一个像素点为中心建立3×3 的矩阵,这样中心像素点周围就存在八个方向上的外围像素点,再让这些像素点分别与其方向相同的Kitch算子进行卷积运算得到八个边缘响应值[15],取绝对值并按照从大到小的规则排序。令前k 个边缘梯度值为1,后8-k 个边缘梯度值为0。最后按照一定次序取出,得到一个二进制数,转为十进制,这个数就是该像素点的LDP 编码值。LDP编码过程如图3所示。
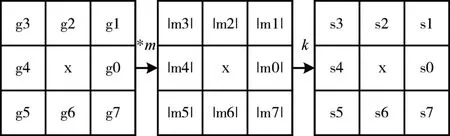
图3 LDP编码过程
在LDP 算法中,一般取k 为3,k=3 时的LDP 编码过程如图4 所示。经过LDP 编码后可得到二进制数00011010,转为十进是26,那么点x 的LDP 编码值为26。

图4 k=3时LDP编码值
3.2 改进LDP
图像的方向信息对于人脸识别来说非常重要,而在LDP算法的第二步编码中,对计算得到的边缘响应值mi进行了取绝对值的操作,容易丢失图像的方向信息。为了更好地反映人脸图像的方向信息,对LDP算法做出了改进。
第一步计算边缘响应值与传统LDP算法相同,在第二步编码中,取消对边缘响应值mi的取绝对值操作,改进后的编码公式如下:
其中mk为mi中第k 大的值,s(x)为符号函数。人脸图像经传统LDP 和改进LDP 提取特征后的效果图如图5所示。

图5 特征提取效果图
4 实验与分析
选用耶鲁大学的Yale 人脸库作为实验的样本库进行实验,实验结果如表1和表2所示。
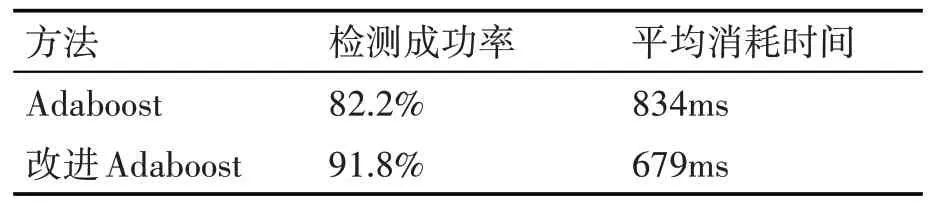
表1 人脸检测效果比较

表2 人脸识别效果比较
从实验结果可以看出改进后的Adaboost 算法不仅人脸检测成功率有所提高,而且耗时也有减少。改进后的LDP 算法因为只是对第二步编码中的取绝对值操作进行了调整,所有耗时几乎没有差别,但是提高了人脸识别成功率。
5 结语
本文对人脸识别算法进行了系统性地研究。首先是采集图像中人脸区域的检测,使用基于Adaboost 的级联分类器,因为其存在检测时间较长,精确度不大的问题,对传统Adaboost进行了改进。之后是特征提取阶段,利用LDP 算法、改进后的LDP算法对人脸区域进行特征值提取。最后在yale 人脸库进行了实验验证。
猜你喜欢
作文中学版(2022年1期)2022-04-14
科教导刊·电子版(2021年1期)2021-03-28
现代电子技术(2021年1期)2021-01-17
学生天地(2020年31期)2020-06-01
环境与发展(2019年11期)2019-02-12
山东化工(2019年1期)2019-01-24
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
计算机工程(2015年8期)2015-07-03
