
基于改进K-means 算法的研究与分析∗
2023-10-20 08:23杨俊成李淑霞
计算机与数字工程 2023年7期
杨俊成 李淑霞
(1.武汉大学计算机学院 武汉 430072)(2.河南工业职业技术学院电子信息工程学院 南阳 473000)
1 引言
随着大数据的发展,数据挖掘迎来了机遇,聚类挖掘在数据挖掘技术中起着关键作用。K-means 算法作为聚类挖掘算法中的热门算法之一,具有效果好、思想简单的优点,同时也具有聚簇个数K 难确定、聚类中心随机性等缺点,为了解决这些问题,它的改进算法越来越受相关研究学者的青睐。
K-means 算法是一种在聚类算法中较为流行的无监督机器学习算法。该算法由MacQueen[1]首次提出,应用广泛,如市场分析[2~3]、特征学习[4~5]、文档聚类[6~7]、图像分割[8~10],具有效果好、思想简单、聚类速度快等优点。文献[11]提出基于K-means的矩阵分解算法(Matrix Decompositon Based on K-means,KMMD),即将K-means 算法与矩阵分解算法相结合,从而提高算法的精度。文献[12]引入欧氏距离,提出基于大数据K-means 的优化算法,解决传统模糊K-means 算法中局部最优解的缺陷问题,提高聚类的准确性和速度。
层次聚类中的典型算法之一BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)是1996 年由Tian Zhang[13]提出的,目前一些学者分别从改进聚类特征的计算方式、阈值以及与其它聚类算法结合等方面对BIRCH 算法进行改进,本文结合K-means 算法和BIRCH 算法构建核心树,完善核心树的各个特征数据,用于解决用户的推荐问题。
2 传统K-means算法和BIRCH算法
2.1 传统的K-means算法
K-means 算法是一种基于目标函数的硬聚类算法[14~16],被广泛应用在数据挖掘和机器学习,该算法可以使用函数求极值的方法对目标函数进行规则调整,该目标函数以距离作为优化,该算法以评价函数最少为目标,以误差平方和的基准为依据,采用欧氏距离作为相似度计算,以初始距离中心开始进行分类,准则函数采用误差平方进行聚类。当聚类类别数已知时,K-means算法可以通过计算,将杂乱无章的数据集合成为K 个类别簇,其中包含所有类别数据样本。
K-means算法是一种基于聚类数k的硬聚类算法,其具体过程如下:首先,随机选择k 个聚类簇中心,并计算数据点与簇中心的相似度,将每个数据点分配给最近的簇中心。然后,重新计算每个簇的中心点,并再次计算数据点与簇中心的相似度,重新分配数据点。这个过程不断迭代,直到聚类结果稳定不再变化,最终得到每个数据点所属的聚类簇。文献[17~18]中有关于该算法的详细讨论。
K-means算法以既定的K值进行簇的聚类[17~18],随机选择k 个聚类簇中心,将数据点分配到最近的簇中心,重新计算簇中心并重新分配数据点,不断迭代,直到聚类结果稳定不变。详细描述如下:
1)从数据集中随机抽取一定数量K 个文档作为初始聚类中心;
2)确定归类的条件,将剩余文档与聚类中心的欧式距离作为归类条件;
3)根据欧式距离的测量方式,将每个文档与最近的聚类中心进行比较,将其分配到距离最近的簇中;
4)对每个簇中的数据点进行重新计算,即每个簇中文档对象均值,同时计算所有簇的聚类结果好坏SSE;
5)如果SSE 值发生变化,重复2),否则算法结束,给出聚类结果。
以同样的方式计算提取到的所有数据,即计算数据特征间的相似性,使用均值算法对不同的数据样本进行迭代,以确定它们所属的不同类别。最终,我们可以根据提取到的用户数据所属的类别,为用户提供符合其习惯的个性化推荐服务。
2.2 BIRCH算法
BIRCH算法是层次聚类算法之一[19],也是根据平衡迭代规约和聚类的典型方法。该算法通过扫描数据集构建聚类特征树,根据聚类特征树的类别判断汇总数据信息,聚类数据的分布数据集很容易受离群点的影响,从而影响距离中心的计算结果。该算法适用于大数据集的处理,可以通过单遍扫描数据集进行有效聚类,最小化数据集的输入输出,算法描述如下:
1)扫描整个数据集,建立尽可能包含所有属性信息的初始化聚类特征树。建立聚类特征树中插入对象的过程类似于B+树的插入和分裂过程,通过簇的半径和阈值的比较来确定叶节点是否被分割(Split)[20]。
2)利用聚类算法对聚类特征进行聚类。
3 改进K-means算法
3.1 改进K-means算法原理
K-means 算法的第一步是计算数据点与聚类中心之间的距离,只有定义了距离度量,才能使用该算法进行数据聚类。若无法定义距离,则数据与聚类中心间不能建立联系,也会使K-means算法不能更新聚类中心。该算法输入是聚类类别,在很多应用场景的海量数据中,聚类类别不好确定,一般只能以历史经验为依据给出聚类类别,这种方式得到的结果不太准确,但K-means算法可以通过选择适当的距离度量方式降低离群点对聚类中心的影响,从而提高数据聚类的准确性和精度。
BIRCH算法容易受到离群点的影响,导致聚类结果不准确。影响距离中心的计算结果,难以准确展现汇总信息,所以此算法不适宜处理数据分类。传统BIRCH 算法由三元组表示,并将聚类信息集合到下面的三元组中CF=(N,LS,SS)。该三元组中N 代表聚类数据个数,LS 代表N 个对象的线性和,SS代表N个对象的平方和。
BIRCH算法和K-means算法各有优劣,结合两者算法构建核心树,利用BIRCH 算法树形结构对时间复杂度较低的数据进行运算处理,利用K-means 算法对离群点干扰较大的数据进行运算处理,以获得更好的聚类效果,并基于此算法完成对用户的数据推荐。另外本文通过对数据变量的研究,结合传统BIRCH 算法的表示形式,将聚类特征定义为CF=(n,I,S)。其中n表示要分类的数据量总和,I表示所有对象的类别集合。S表示数据样本的个数。
由于用户数据量与集合I 呈现正比关系,所以很难通过常规模式表示大量数据集合,因此需要用聚类特征替代原有海量数据,具体过程可以描述如下:
1)确定最佳中心点,即处于特征数据最中央位置的特征数据点;
2)确定次中心点,即接近中心点的数据点,次中心点能够最大程度辅助确定最佳中心点;
3)确定亚中心点,亚中心点对于最佳中心点的确定也能起到辅助计算作用;
4)确定核心数据,这些核心数据是一种压缩形式,可以统计表示出的某些特征;
5)确定核心树,由子类类别中心构成平衡树,由聚类特征构成增量距离算法,有效完成算法的构造与执行效率。
3.2 核心树的初始化过程
从叶节点或根节点开始构造树形结构,利用K-means算法进行聚类,使用欧式距离计算节点间的距离,以距离为依据判断节点之间的相似性,并得到核心数据。之后,使用BIRCH 算法构造树形结构,并将K 个类别的中点作为核心树的叶节点,依据叶节点构造核心树,具体构建核心树的过程可以描述如下:
1)提取中点数据,若此中点符合拓展节点条件,则将中点插入到当前节点中,否则转2)。
2)对已知CI 个中点进行判断,若符合叶子节点特征转为3),否则转为4)。
3)计算中点距离,以最小距离的中点为选项,持续运行节点搜索,搜索的流程重新以1)开始进行。
4)该节点Ci 是叶子节点,使用最远距离对该叶子节点进行分裂,使之分裂成为两个叶子节点。第一以Floyd 算法为依据计算叶子节点的中点,挑选两个相似度最小的点,即为距离最远的两个中心点;第二将其他的中点进行距离计算,并将其分裂到相似度最小的两个中点中。最后比较中心点个数与阈值,若小于则完成构建,否则转到第4)步。
3.3 特征迭代完善树
完成了核心树的构建后,还需要完善核心树的各个特征数据,分为以下几个步骤:
1)对于新读入的对象要计算它与每个类别中点之间的距离,并选择距离最近的类别中点作为聚类路径。
2)如果特征数据与叶子节点的距离接近,则计算该叶子节点到根节点的距离,将此距离数值与已设定的阈值进行对比,若距离数值小于阈值,则可以将此特征数据与叶子节点聚为一类,转到3),若距离数值超出阈值则转2)重新计算。
3)如果距离数值小于中心半径,则判断特征数据是本类别的核心数据,反之则不是。然后对核心数据进行排序,并将其存储到链表中。
4)判断聚类中心是否更新,当类别发散度(即数据到聚类中心点的距离)大于2,说明该聚类的所有数据出现了松散,该聚类中心发生了变化,根据式(1)重新计算该聚类中心,以便确定新的距离中心。
其中,core表示核心特征数据的个数,num为总的特征数据个数,参数p 为聚类类别发散度,p 越小说明数据到聚类中心点的距离越小,聚类半径越小;而p越大则说明数据到聚类中心点的距离越大,聚类半径也很大。
3.4 改进的K-means算法
使用增量聚类方法处理输入的特征数据,并为了避免叶子节点全部依赖聚类结果,则需要改进叶子节点。为了得到更好的效果,本文将每个叶子节点与对应的核心树连接起来,形成一个链表结构,如图1所示。
图1 链表结构图
由图1 可知,链接起核心数据与各个叶子节点的聚类中心和核心数据,为了避免剧烈算法过于依赖输入顺序,重置叶子节点的聚类中心位置算法。为了准确地确定是否需要更新聚类中心点,应该通过对比核心数据和非核心数据来确定是否需要更新聚类中心确保叶子节点的聚类中心不过于依赖输入数据的顺序。
本文使用核心数据和聚类中心数据来构建叶子节点聚类中心链表。对于相邻的每个叶子节点,使用它们的数据进行聚类,并定义新的聚类中心。然后,重新将数据源的数据分配到对应的聚类中心中。最后,根据式(2)计算出的方差结果来决定是否重置聚类中心点。
4 实验分析
本文基于python3.6 实现鲁棒性的核心树聚类算法,对养老用户相关数据进行聚类,把分析后的数据分配到与其对应的类别当中,为用户的选择给出决策依据。
本文通过测试6 组养老服务护理文本数据,验正传统算法和改进算法的运行时间,相关结果显示如图2。
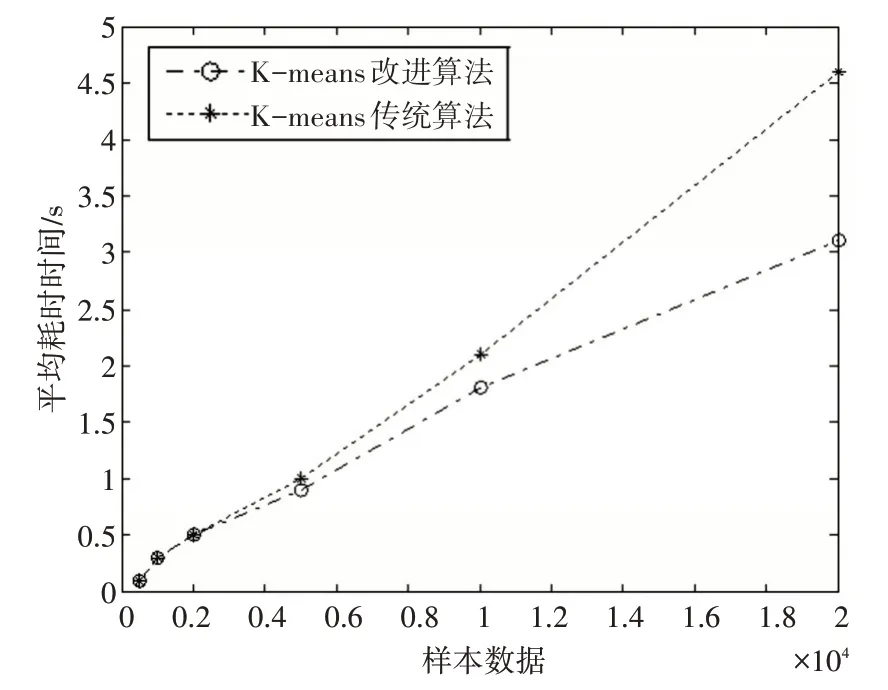
图2 算法运行时间趋势
根据图2 的结果,本文验证了改进算法在计算相同样本数据时具有更短的平均耗时,进而证明了其有效性。因此,本文在养老服务护理系统的聚类模块中采用改进后的K-means算法,并对护理方案模块进行了分析,以满足定制化需求的要求。
5 结语
K-means 算法是无监督学习的聚类算法,存在K 值不好选择、凸数据集较难收敛、并对噪音和异常点比较敏感,本文结合K-means 算法和BIRCH算法构建核心树,可以用较少的时间内完成用户的数据推荐。
猜你喜欢
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
少儿美术·书法版(2016年1期)2016-02-06
新校长(2016年8期)2016-01-10
大众摄影(2015年9期)2015-09-06
电子设计工程(2015年6期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
