
基于双层记忆网络的多领域端到端任务型对话系统
2023-10-17 23:37:00方明弘万里戴凡杰
计算机应用研究 2023年10期
关键词:任务型
方明弘 万里 戴凡杰
摘 要:为了将知识有效地融入到对话推理,提出了一种基于双层记忆网络的多领域端到端任务型对话系统。首先,该模型用知识行的形式代替三元组的形式表示知识,提升了知识定位的性能;其次,采用了双层记忆网络结构将知识和对话历史进行分别建模,提高了模型的推理能力;最后,使用了动态编码器对多种领域的数据进行编码,提升模型的泛化能力。通过实验分析,该模型的F1和BLEU指标在InCar和CamRest数据集上相较于对比算法均有一定的提升,验证了该模型的有效性和先进性。
关键词:对话系统; 任务型; 双层记忆网络; 多领域; 端到端
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2023)10-010-2945-06
doi:10.19734/j.issn.1001-3695.2023.03.0096
Multi-domain end-to-end task-oriented dialogue system based on
double-layer memory network
Fang Minghong, Wan Li, Dai Fanjie
(College of Computer Science, Chongqing University, Chongqing 400044, China)
Abstract:To effectively incorporate knowledge into dialogue reasoning, this paper proposed a multi-domain end-to-end task-oriented dialogue system based on a double-layer memory network. Firstly, it used the form of knowledge rows instead of triples to represent knowledge, which improved the performance of knowledge location. Secondly, it used a double-layer memory network structure to model knowledge and dialogue history separately, which improved the reasoning ability of the model. Finally, it used a dynamic encoder to encode data in various fields to improve the generalization ability of the model. Through experimental analysis, the F1 and BLEU indicators of the model are improved through compared with the comparison algorithm on the InCar and CamRest datasets, which verifies the effectiveness and advancement of the model.
Key words:dialogue system; task-oriented; double-layer memory network; multi-domain; end-to-end
0 引言
随着科学技术的快速发展和现代计算机运算能力的不断增强,人工智能技术开始深入应用于人们生活的方方面面。此外,对话系统由于在真实世界中蕴涵了巨大的商业价值,在工业界和学术界都被广泛研究和探索,出现了许多智能对话系统,例如微软小冰[1]、苹果Siri[2]、百度小度[3]等对话助手。
目前,主流的对话系统分为两大类。第一类是开放域对话系统,该对话系统不带有明确的意图,特点是没有特定的任务,只是和用户随便聊天,往往是一问一答的形式,较少或者不会参考对话上下文信息。开放域对话系统即使在某种程度上可以发挥人工智能的作用,但因为其不致力于帮助人们解决真正的现实问题,所以这类对话系统的实际作用相对较小[4]。第二类是任务型对话系统,该对话系统通过有限的对话信息帮助用户完成特定的任务,例如餐厅预定、目的导航、天气查询和车票预定等,使得其对人们的生活很有价值。任务型对话系统的核心是需要正确理解用户的意图,并提供合理且正确的系统回复,这个过程需要依赖当前对话的上下文信息和外部知识库信息,特定领域的任务还需要提供特定领域的知识库信息。
任務型对话系统主要存在流水线和端到端两种模式[5]。流水线的任务型对话系统因存在需要大量的人工标注和多模块之间依赖复杂等缺点,导致系统构建成本昂贵。不同于流水线,端到端的任务型对话系统不需要大量的人工标注和依赖上下游模块,其结构简单、可扩展性强、构建成本低,因此成为对话系统领域的研究热点。然而,现有的端到端任务型对话系统仍然存在一些不足:
a)基于记忆网络的端到端任务型对话系统均采用三元组的形式表示外部知识库,该方法存在对话推理困难和知识定位困难的问题,难以有效地将正确的知识融入到对话中。本文提出用知识行代替三元组的形式表示知识。
b)知识和对话历史都存储于同一个记忆网络之中,使用共享的记忆网络对知识和对话历史进行编码,但是不同的数据格式所包含的信息是有差异的,在同一个网络上对不同的数据进行推理是十分困难和低效率的,并且知识融入程度较低。本文提出双层记忆网络,分别对知识和对话历史进行建模,提高了模型的推理能力。
c)主流的对话系统,要么针对特定领域并且依赖大量标签数据去学习特定的特征,要么混合所有领域的数据去学习共有的特征。虽然这两种方法已经取得了不错的成绩,但是限制了模型的通用性,无法很好地将已经训练好的模型迁移到新的领域,导致了对话系统不具有较好的普适性和通用性。本文利用动态编码器提取共有特征和私有特征,易于将模型迁移到数据量较少或者零数据的领域。
1 相关工作
序列到序列模型[6]是一种由编码器和解码器组成的深度学习模型,即sequence to sequence(Seq2Seq)。序列到序列模型可以学习两个序列之间的映射关系,表现出优异的性能,其迅速在语音识别[7]、机器翻译[8]等领域得到广泛应用。因为序列到序列模型在多个领域的优异表现以及强大的语言建模能力,该模型逐渐被对话系统领域所关注并获得了广泛的应用。
Weston等人[9]提出了记忆网络模型,为传统的推理模型增加一个可读写的记忆模块以便更好地存储长期记忆,然后在推理过程中可以进行相关内容的查询和读取。Sukhbaatar等人[10]提出了一种端到端的记忆网络模型,其在多个嵌入矩阵中写入外部记忆,并且使用查询向量,可以多次读取记忆信息。不同于Weston等人[9]提出的记忆网络模型,该模型是端到端可学习的,因此可以明显减少需要用于训练的监督,使其更加具有普遍性和通用性。此外,该模型中包含多个嵌入矩阵,通过多次查询实现多跳阅读和知识推理,并且对于需要高性能的推理任务而言多跳机制是十分重要的。Dai等人[11]在Sukhbaatar等人[10]的基础上,应用端到端的记忆网络模型作为句子的编码器,记住现有的响应和对话历史,然后,使用与模型无关的元学习[12]来训练框架,以更少次数的方式检索正确的响应。
尽管端到端的记忆网络模型在问答和语言建模等任务中取得了优异的表现,使其逐渐应用于任务型对话系统领域,但由于其只是从预先定义的集合中选择相应回复,而不是逐字生成,所以生成回复的准确性有限。为解决该问题,Madotto等人[13]在端到端的记忆网络模型中加入记忆组件用于构建端到端可学习的任务型对话系统(Mem2Seq)。Mem2Seq模型在记忆组件中存储知识三元组信息和对话历史,并将其与基于序列到序列的生成模型结合直接生成系统回复,从而解决了只从预定义的集合中选择回复的问题。此外,Mem2Seq模型还结合了复制机制直接从记忆组件的知识库信息或者对话历史中复制单词到系统生成的回复中。越来越多的端到端的任务型记忆网络方法在Mem2Seq模型的基础上进行研究和探索。
2 模型
2.1 模型架构
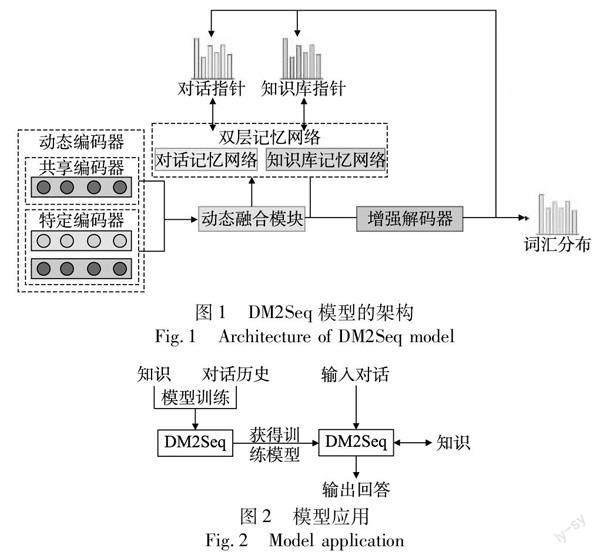
本文提出了一种基于双层记忆网络的多领域端到端任务型对话系统(DM2Seq)。知识库信息用知识行的形式(一组知识信息都存在一行数据上)代替三元组的形式表示,提升了知识定位的性能。采用了双层记忆网络,对知识库信息和对话历史进行分别建模,针对不同类型的数据单独处理,提高了模型的推理能力。使用动态编码器和增强解码器对多种领域的数据进行编码和解码,并且在解码的阶段使用束搜索算法[14]提高模型的单词选择正确率。DM2Seq模型主要结构如图1所示。
DM2Seq模型最主要的模块为动态编码器模块、双层记忆网络模块、动态融合模块、增强解码器模块等。
本文模型首先需要对外部知识和对话历史进行模型训练,然后将训练好的模型输入对话即可生成系统回复作为输出,模型应用架构如图2所示。
2.2 动态编码器
现存的端到端任务型对话系统虽然表现出了一定的优势,但是无法将特定领域训练的模型移植到数据量较少或者没有数据的领域,模型的泛化性较差。将特定领域和混合领域的模型相融合是十分重要的,既可以解决多领域共享特征捕获问题,又可以解决特定领域特征捕获问题。
动态解码器首先用特定领域的数据训练私有模型,然后采用混合专家机制(mixture of experts,MoE)[15]进行动态融合,获取特定领域的特征,然后对动态融合后的私有特征与混合特征进行全融合,最后得到输出的编码向量。动态编码器模块的基本结构如图3所示。
a)对于单个领域进行编码。
对于给定的用户与系统之间的对话信息,动态编码器将会对整个对话历史信息进行上下文编码,用于系统推理。假定一个对话历史信息的输入序列表示为X=(x1,x2,…,xn),n表示对话序列的长度。首先根据式(1)获得每个单词的词向量表示ei:
2.4 双层记忆网络指针
双层记忆网络模型分别对对话历史和知识库信息进行建模,构建对话记忆网络和知识库记忆网络,所以需要分别定义对话记忆网络指针Glabeld=(gld,1,gld,2,…,gld,|Rd|+1)和知识库记忆网络指针Glabelkb=(glkb,1,glkb,2,…,glkb,|Rkb|+1)的真實标签。其中相关性的行为表示为1,不相关的行为表示为0,|Rd|和|Rkb|分别表示对话记忆的行数和知识库记忆的行数,|Rd|+1和|Rkb|+1分别表示对话记忆和知识库记忆结束标记所在行。
对于知识库记忆行而言,若这个知识记忆行包含最多数量的单词出现在真实回复Y中,就认为这个知识记忆行与其相关,否则不相关。对于对话记忆行,如果单词存在生成的回复Y中,那么就认为这个对话记忆行与其相关,否则不相关。
在解码器生成回复之前,双层记忆网络指针可以根据对话历史信息和知识库信息获得与当前对话相关的记忆行信息。
双层记忆网络指针模块将动态编码器的最后一个隐藏状态向量hfenc,n作为初始查询向量,然后再进行了K次查询和推理后,可以分别获得记忆网络指针:
最终,通过交叉熵损失函数作为其目标函数来进行训练,式(17)和(18)分别是对话记忆指针和知识库记忆指针的损失计算:
3 实验
3.1 数据集
实验采用的数据集是对话系统领域流行的公开数据集,分别为车载助手对话数据集InCar[16]和餐厅预定对话数据集CamRest[17],如表1所示。
3.2 评价指标
评价指标采用实体F1值和BLEU精度(使用multi-bleu.perl脚本)对DM2Seq模型的实验效果进行分析和评估,主要从真实回复与模型生成回复之间的相似度两个方面进行评估和分析。
由于F1值和BLEU评价指标只能对模型结果进行粗粒度评估,所以本文在自动评价指标的基础上继续引入人工评估指标,对模型进行更加细粒度的分析和评估。
3.3 实验指标
对于双层记忆网络的多领域动态融合的端到端任务型对话系统模型,实验环境如表2所示。在训练的过程中采用Adam优化算法,学习率设置为从0.001线性衰减到0.000 1,dropout设置为0.2,模型中的词向量维度大小和隐藏层向量大小设置为128,数据集InCar和CamRest每个采样大小(batch)设置为16。模型迭代次數最大设置为100,若最新的F1值连续8次低于最大的F1值则提前停止训练。teacher forcing设置为0.5,在模型生成回复的时候有50%的概率使用解码器当前时刻的输出作为下一时刻的输入,而有50%的概率使用Teacher Forcing策略将真实的回复单词作为解码器的输入。
3.4 对比实验
DM2Seq模型与现有的多个端到端的任务型对话系统模型进行对比,结果如表3和4所示。
表3展示了DM2Seq模型与其他对比模型在InCar数据集上的对比实验结果。与之前的工作相比,DM2Seq模型在两个自动评估指标BLEU精度和F1值上均取得了最好的效果,分别是最高的15.2 BLEU精度和最高的62.9%实体F1值,在Navigate和Weather领域也取得了最好的F1值,分别是58.0%和64.6%,虽然在Schedule领域没有取得最高的F1值,但是只比DF-Net模型低2.9%。
表4展示了DM2Seq模型与其他对比模型在CamRest数据集上的对比实验结果,可以看到,DM2Seq模型在两个自动评估指标BLEU精度和F1值上均取得了18.9 BLEU精度和59.7%实体F1值,略高于其他对比模型。
虽然F1值和BLEU精度常常作为端到端的任务型对话系统中的评价指标,但可能对模型只能进行粗粒度评价,其评价不够全面。因此,本文在自动评价指标的基础上继续引入人工评价指标,对模型进行更加细粒度的分析和评价。
本节主要从InCar数据集上随机选取150个对话的测试集,通过选取GLMP和DF-Net作为对比模型生成系统回复,并请5个人类专家对对比模型和DM2Seq模型生成的系统回复分别从正确性、流畅性以及类人性三个方面进行评价,分数为1~5,对评价的结果取平均值展示。人类评估分布情况如图5所示。
在InCar数据集上的人工评估结果如表5所示,从评估结果可以看出本文提出的DM2Seq模型在正确性方面比对比模型GLMP和DF-Net高出许多,这表明DM2Seq模型较其他的对比模型的实体信息抽取和知识推理能力有较大提升,特别是关系到多种实体选择的对话内容的时候,DM2Seq模型能充分理解用户的意图并生成正确的回复。DM2Seq模型在其他评价指标流畅性和类人性上的评估结果都略高于对比模型,这表明DM2Seq模型的语言生成能力和识别能力比对比模型略微优秀,能生成流利的和与人类回复更加相近的系统回复。
综上所述,根据实验表明DM2Seq在InCar和CamRest数据集上具有不错的信息提取能力和语言建模能力,具有较高的鲁棒性,无论在BLEU精度还是F1值上,都提升了相当大的幅度。BLEU分数提高表明DM2Seq模型的解码器生成回复的误差已经减小了,F1值提高表面DM2Seq模型从外部知识库检索实体比其他对比模型更加准确,能够很好地在系统生成回复中融入正确的外部知识。人工评估实验也表明,DM2Seq模型具有优秀的性能。
3.5 消融实验
对DM2Seq模型进行消融实验,提出了五种变体:
a)DM2Seq模型移除动态编码器(dynamic encoder,DE),使用一个标准的GRU对数据进行编码操作。
b)DM2Seq模型移除增强解码器(enhanced decoder,ED),使用一个标准的GRU对编码器输出的隐藏向量进行解码操作。
c)DM2Seq模型移除双层记忆网络(double-layer memory network,DMN),使用单层记忆网络,将对话信息和知识库信息在一个网络进行建模。
d)DM2Seq模型移除知识行表示(knowledge line representation,KLR),采用三元组的形式表示知识库信息。
e)DM2Seq模型移除束搜索算法。
根据表6中消融实验的结果可知,对于InCar数据集,在BLEU精度方面和F1值方面,双层记忆网络模块对DM2Seq模型提升最多,对模型的语言建模能力和实体信息提取能力影响最大。对于CamRest数据集,在BLEU精度方面和F1值方面,依然是双层记忆网络模块对DM2Seq模型提升最多,语言建模能力和实体信息提取能力影响最大。但是在CamRest数据集上,束搜索对模型提升比InCar数据集上略大,其原因可能是CamRest数据集上局部最优对实体检索以及语言建模影响更大。
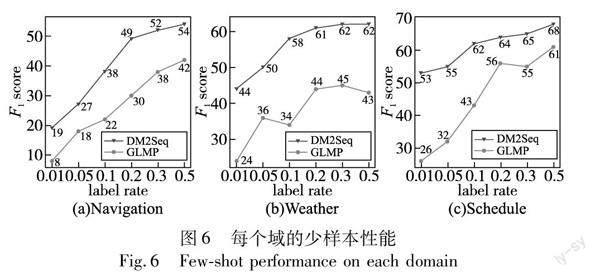
为了进一步验证动态编码器对多领域数据作用,假定DM2Seq模型在某个领域具有较少的资源,然后判定其是否具有良好的性能。对于InCar数据集中三个子领域数据集,保持其中两个子领域的数据集不变,另一个领域的数据集数据比例设置为原数据集的1%、5%、10%、20%、30%、50%,用于验证DM2Seq模型是否易于将拥有海量数据的领域训练出来的模型移植到一个全新的或者数据较少的领域之中。根据图6展示的GLMP和DM2Seq模型的对比结果可以得出:
a)DM2Seq模型在数据量较少的领域比GLMP模型表现出更好的性能,只有1%原始数据的时候,DM2Seq模型比GLMP平均高出19.3%,DM2Seq模型显著高于GLMP模型。
b)DM2Seq模型只需要20%的原始数据就比GLMP模型需要50%原始数据展现出更加优异的性能,能够更有效地学习不同领域之间的特征信息。
这表明,DM2Seq模型能够有效地将模型移植到数据量较少的领域,提高了模型的通用性和普适性。
上述消融实验证明DM2Seq模型所提出的动态编码器模块、增强解码器模块、双层记忆网络模块、知识行以及束搜索对模型的提升都具有不同程度的有效性。
3.6 对话展示
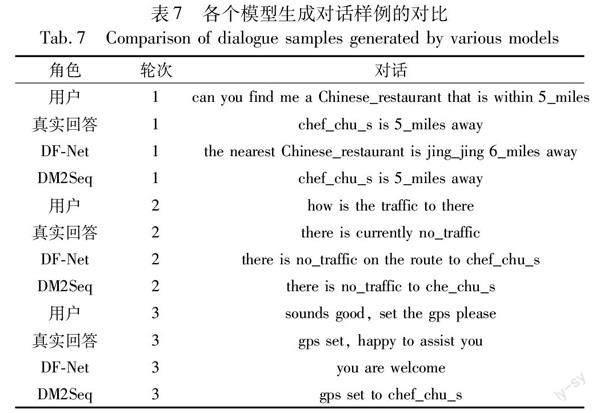
表7展示了在InCar数据集上DM2Seq、DF-Net模型和数据集真实回复的对话样例。
在第一轮对话中,用户提问“can you find me a Chinese_restaurant that is within 5_miles”,DF-Net模型采用三元组表示知识库信息就定位错了实体“jing_jing”和“6_miles”,造成了错误的系统回复,而DM2Seq模型提出采用知识行代替三元组的形式,准确定位了真实的实体“chef_chu_s”和“5_miles”,并且DM2Seq模型生成的系统回复更加贴近真实回复。在第二和第三轮对话中,虽然DF-Net和DM2Seq模型都精准定位到了知识库信息,但是DM2Seq模型生成的回复更加贴合真实回复。
4 结束语
本文主要介绍了基于双层记忆网络的多领域端到端任务型对话系统的研究和实现。首先,介绍了基于记忆网络的端到端任务型对话系统方法存在的一些不足和挑战,提出了解决方案(DM2Seq模型),并且详细阐述了DM2Seq模型的整体结构,主要包括动态编码器模块、双层记忆网络模块、增强解码器模块、双层记忆网络指针等。此外,通过详细介绍实验设置、结果分析、消融实验等,与多个主流的端到端的任务型对话系统方法进行比对。实验表明,DM2Seq模型在知识信息提取和语言建模能力等方面都有不错的提升。
尽管本文模型在一定程度上解决了现有方法的不足与缺点,但是仍然存在许多问题需要在未来的工作中继续探索和研究。可以从下面几个方向展开后续的探索和研究:
a)本文模型都是在英文公开数据集上进行研究和实验的,没有应用于中文领域,所以在将来的工作中可以将模型应用到中文数据集上进行研究和实验,提高模型处理各种自然语言的能力。
b)本文模型只针对了任务型的对话进行实验和分析,但是这并不能完全适应现实世界,有时候往往也需要处理开放域的对话,所以探索和研究一个兼顾任务型对话和开放域对话的方法是十分必要的。
参考文献:
[1]Zhou Li, Gao Jianfeng, Li Di, et al. The design and implementation of Xiaoice, an empathetic social chatbot[J].Computational Linguistics,2020,46(1):53-93.
[2]Sigtia S, Marchi E, Kajarekar S, et al. Multi-task learning for spea-ker verification and voice trigger detection[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing.Piscataway,NJ:IEEE Press,2020:6844-6848.
[3]陳东升.百度AI黑科技小度在家智能音箱[J].计算机与网络,2018,44(22):22-24.(Chen Dongsheng. Baidu AI black technology Xiaodu smart speaker at home[J].Computer & Network,2018,44(22):22-24.)
[4]赵阳洋,王振宇,王佩,等.任务型对话系统研究综述[J].计算机学报,2020,43(10):1862-1896.(Zhao Yangyang, Wang Zhenyu, Wang Pei, et al. A survey on task-oriented dialogue systems[J].Chinese Journal of Computers,2020,43(10):1864-1896.)
[5]曹亚如,张丽萍,赵乐乐.多轮任务型对话系统研究进展[J].计算机应用研究,2022,39(2):331-341.(Cao Yaru, Zhang Liping, Zhao Lele. Research progress of multi-turn task-oriented dialogue system[J].Application Research of Computers,2022,39(2):331-341.)
[6]Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Proc of Annual Conference on Neural Information Processing Systems.Cambridge,MA:MIT Press,2014:3104-3112.
[7]Zhou Shiyu, Dong Linhao, Xu Shuang, et al. Syllable-based sequence-to-sequence speech recognition with the transformer in Mandarin Chinese[EB/OL].(2018-04-28)[2023-03-15].https://arxiv.org/abs/1804.107 52.
[8]Wang Wenxuan, Jiao Wenxiang, Hao Yongchang, et al. Understan-ding and improving sequence-to-sequence pretraining for neural machine translation[EB/OL].(2022-03-16)[2023-03-15].https://arxiv.org/abs/2203.08442.
[9]Weston J, Chopra S, Bordes A. Memory networks[EB/OL].(2015-10-15)[2023-03-15].https://arxiv.org/abs/1410.3916.
[10]Sukhbaatar S, Weston J, Fergus R. End-to-end memory networks[C]//Proc of Annual Conference on Neural Information Processing Systems.Cambridge,MA:MIT Press,2015:2440-2448.
[11]Dai Yinpei, Li Hangyu, Tang Chengguang, et al. Learning low-resource end-to-end goal-oriented dialog for fast and reliable system deployment[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.2020:609-618.
[12]Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//Proc of the 34th International Conference on Machine Learning.2017:1126-1135.
[13]Madotto A, Wu C S, Fung P. mem2seq: effectively incorporating knowledge bases into end-to-end task-oriented dialog systems[C]//Proc of the 56th Annual Meeting of the Association for Computational Linguistics.2018:1468-1478.
[14]Freitag M, Al-Onaizan Y. Beam search strategies for neural machine translation[EB/OL].(2017)[2023-03-15].https://arxiv.org/abs/1702.01806.
[15]Guo Jiang, Shah D J, Barzilay R. Multi-source domain adaptation with mixture of experts[C]//Proc of Conference on Empirical Me-thods in Natural Language Processing.2018:4694-703.
[16]Eric M, Krishnan L, Charette F, et al. Key-value retrieval networks for task-oriented dialogue[C]//Proc of the 18th Annual SIGdial Meeting on Discourse and Dialogue.2017:37-49.
[17]Wen T H, Gasic M, Mrksic N, et al. Conditional generation and snapshot learning in neural dialogue systems[C]//Proc of the 2016 Conference on Empirical Methods in Natural Language Processing.2016:2153-2162.
[18]Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[C]//Proc of the 3rd International Conference on Learning Representations.2015.
[19]Wu C S, Socher R, Xiong Caiming. Global-to-local memory pointer networks for task-oriented dialogue[C]//Proc of the 7th International Conference on Learning Representations.2018.
[20]Qin Libo, Xu Xiao, Che Wanxiang, et al. Dynamic fusion network for multi-domain end-to-end task-oriented dialog[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.2020:6344-6354.
[21]Qin Libo, Liu Yijia, Che Wanxiang, et al. Entity-consistent end-to-end task-oriented dialogue system with KB retriever[C]//Proc of the 9th International Joint Conference on Natural Language Processing.2019:133-142.
收稿日期:2023-03-15;修回日期:2023-05-06
基金項目:重庆市技术创新与应用发展专项重点项目(CSTB2022TIAD-KPX0141);重庆市科卫联合重点项目(2021ZY014004)
作者简介:方明弘(1997-),男,重庆人,硕士研究生,主要研究方向为自然语言处理;万里(1981-),男(通信作者),重庆人,副教授,硕导,博士,主要研究方向为知识图谱、对话系统、计算机视觉(wanli@cqu.edu.cn);戴凡杰(1998-),男,湖南人,硕士研究生,主要研究方向为计算机视觉.
猜你喜欢
未来英才(2016年14期)2017-01-12 18:25:28
文理导航·教育研究与实践(2016年12期)2017-01-11 20:29:15
都市家教·上半月(2016年12期)2016-12-29 09:50:43
读与写·教育教学版(2016年12期)2016-12-23 08:10:27
亚太教育(2016年35期)2016-12-21 19:46:39
中学课程辅导·教师教育(上、下)(2016年20期)2016-12-01 02:19:24
考试周刊(2016年85期)2016-11-11 01:10:56
小学教学参考(综合)(2016年8期)2016-09-21 23:30:33
考试周刊(2016年60期)2016-08-23 07:04:52
考试周刊(2016年54期)2016-07-18 08:20:24
