
基于Spark和AMPSO的并行深度卷积神经网络优化算法
2023-10-17 23:37:00刘卫明罗全成毛伊敏彭喆
计算机应用研究 2023年10期
刘卫明 罗全成 毛伊敏 彭喆

摘 要:針对并行DCNN算法在大数据环境下存在冗余参数过多、收敛速度慢、容易陷入局部最优和并行效率低的问题,提出了基于Spark和AMPSO的并行深度卷积神经网络优化算法PDCNN-SAMPSO。首先,该算法设计了基于卷积核重要性和相似度的卷积核剪枝策略(KP-IS),通过剪枝模型中冗余的卷积核,解决了冗余参数过多的问题;接着,提出了基于自适应变异粒子群优化算法的模型并行训练策略(MPT-AMPSO),通过使用自适应变异的粒子群优化算法(AMPSO)初始化模型参数,解决了并行DCNN算法收敛速度慢和容易陷入局部最优的问题;最后,提出了基于节点性能的动态负载均衡策略(DLBNP),通过均衡集群中各节点负载,解决了集群并行效率低的问题。实验表明,当选取8个计算节点处理CompCars数据集时,PDCNN-SAMPSO较Dis-CNN、DS-DCNN、CLR-Distributed-CNN、RS-DCNN的运行时间分别降低了22%、30%、37%和27%,加速比分别高出了1.707、1.424、1.859、0.922,top-1准确率分别高出了4.01%、4.89%、2.42%、5.94%,表明PDCNN-AMPSO在大数据环境下具有良好的分类性能,适用于大数据环境下DCNN模型的并行训练。
关键词:并行DCNN算法; Spark框架; PDCNN-SAMPSO算法; 负载均衡策略
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2023)10-012-2957-10
doi:10.19734/j.issn.1001-3695.2023.03.0083
Parallel deep convolution neural network optimization algorithm
based on Spark and AMPSO
Liu Weiming1, Luo Quancheng1, Mao Yimin1,2, Peng Zhe3
(1.College of Information Engineering, Jiangxi University of Science & Technology, Ganzhou Jiangxi 341000, China; 2.College of Information Engineering, Shaoguan University, Shaoguan Guangdong 512026, China; 3.Dachan Customs District, P. R. China, Shenzhen Guangdong 518000, China)
Abstract:This paper proposed a parallel deep convolutional neural network optimization algorithm based on Spark and AMPSO(PDCNN-SAMPSO), aiming to address several issues encountered by parallel DCNN algorithms in big data environments, such as excessive redundant parameters, slow convergence speed, easy to fall into local optimal, and low parallel efficiency. Firstly, the algorithm designed a kernel pruning strategy based on importance and similarity (KP-IS) to address the problem of excessive redundant parameters by pruning the redundant convolution kernels in the model. Secondly, it proposed a model pa-rallel training strategy based on adaptive mutation particle swarm optimization algorithm (MPT-AMPSO) to solve the slow convergence speed and easy to fall into local optimal issues of parallel DCNN algorithms by initializing the model parameters using adaptive mutation particle swarm optimization algorithm (AMPSO). Finally, the algorithm proposed a dynamic load balancing strategy based on node performance (DLBNP) to balance the load of each node in the cluster and improve the parallel efficiency. Experiments show that, when using 8 computing nodes to process the CompCars dataset, the runtime of PDCNN-SAMPSO is 22%, 30%, 37% and 27% lower than that of Dis-CNN, DS-DCNN, CLR-Distributed-CNN and RS-DCNN, respectively, the speedup ratio is higher by 1.707, 1.424, 1.859, and 0.922, respectively, and the top-1 accuracy is higher by 4.01%, 4.89%, 2.42%, 5.94%, indicating that PDCNN-AMPSO has good classification performance in the big data environment and is suitable for parallel training of DCNN models in the big data environment.
Key words:parallel DCNN algorithm; Spark; PDCNN-SAMPSO algorithm; load balancing
0 引言
DCNN[1]是一类包含卷积计算且含有深层次结构的前馈神经网络,因具有强大的特征选择和泛化能力,被广泛应用于图像分析[2]、语音识别[3]、目标检测像[4]、语义分割[5]、人脸识别[6]、自动驾驶[7]等领域。然而随着大数据时代[8]的到来,数据的规模和人们对数据价值的提取需求不断增长,传统DCNN模型的训练成本和训练复杂度也随之不断提升。因此,设计适用于大数据环境下的DCNN算法具有十分重要的意义。
随着Google公司开发的分布式计算框架MapReduce的快速发展,基于分布式计算框架的DCNN算法得到了广泛关注。文献[9~12]均使用基于MapReduce的DCNN算法取得了不错的效果,然而随着Spark[13]框架的诞生,其凭借计算速度快、简洁易用、通用性强和支持多种运行模式等优势逐步超越MapReduce,成为并行DCNN研究领域中主流的计算框架。目前已有大量基于Spark框架的并行DCNN算法成功运用到大数据的分析和处理领域中。例如,Xu等人[14]结合Spark提出了Dis-CNN(distributed convolution neural network)模型,该模型采用并行计算的方式对各分布式节点上的模型进行训练,实现了DCNN模型在分布式计算系统上的并行化训练过程,相较于单机器的训练方式,拥有更高的训练效率。基于此,Li等人[15]在模型并行训练阶段引入了一种基于内存的分布式文件系统Alluxio,提出了DS-DCNN(distributed system based on DCNN on Apache Spark and Alluxio)模型,該模型使用Alluxio来存储中间数据,进一步提升了模型的并行训练效率。同时,Sun等人[16]在模型并行训练阶段运用周期学习率[17]的思想,提出了CLR-Distributed-CNN(distributed convolutional neural network with a cycle learning rate)算法,该算法使用周期学习率替代线性变化的学习率,提升了模型的收敛速率。此外,Boulila等人[18]在参数并行更新阶段结合了异步梯度下降法的思想,提出了RS-DCNN(distributed convolutional neural network for hand-ling RS image classification)算法,该算法通过异步更新各节点计算的梯度解决了集群相互等待的问题,进一步提高了集群的并行效率。实验结果表明,以上四种并行DCNN算法对模型的训练效率均有显著的提升,但是仍存在以下不足:a)在模型并行训练之前,由于各分布式节点上的DCNN模型结构过于复杂,若不对其进行有效剪枝,模型将会存在冗余参数过多的问题;b)在模型并行训练过程中,不管是使用周期学习率替代线性变化的学习率,还是使用Alluxio来存储中间数据,虽然都能在一定程度上提升模型的训练效率,但对于大数据环境下更为复杂的DCNN模型,仍存在收敛速度慢和容易陷入局部最优的问题;c)在参数并行更新阶段,虽然使用异步梯度下降法能有效地解决集群相互等待的问题,但这种做法同时也带来了梯度延迟的问题,导致模型精度有所降低。所以如何有效地提高集群的并行效率也是一个亟待解决的问题。
针对以上三个问题,本文提出了一种基于Spark和AMPSO的并行深度卷积神经网络优化算法PDCNN-SAMPSO(parallel deep convolutional neural network optimization algorithm based on Spark and AMPSO),算法从三个方面对并行DCNN算法进行了优化:a)在模型压缩阶段,为了解决冗余参数过多的问题,首先对各卷积层中的卷积核进行剪枝,然而现有的卷积核剪枝策略大多是采用L1范数作为剪枝标准对各卷积层进行剪枝,该做法不仅忽略了各卷积核间的相似度,而且对不同层采用同一剪枝标准的方式剪枝精度不高,PDCNN-AMPSO算法从卷积核重要性和相似度两个维度考虑,设计了KP-IS策略,通过对不同卷积层采用不同的剪枝标准并考虑了卷积核间的相似度,解决了冗余参数过多的问题;b)在模型并行训练阶段,对于并行DCNN算法收敛慢且容易陷入局部最优的问题,考虑到PSO算法[19]收敛速率快和简单易用的特性,基于PSO算法提出了AMPSO算法,并在此基础上设计了MPT-AMPSO策略,通过使用AMPSO算法来初始化模型参数,接着再使用Adam(adaptive momentum algorithm)算法[20]对模型参数进行更新,解决了并行DCNN算法收敛速度慢和容易陷入局部最优的问题;c)在参数并行更新阶段,对于集群并行效率低的问题,大多并行算法采用异步更新的方式对参数进行更新,然而这种做法导致的梯度延迟问题使得模型分类精度有所降低,因此PDCNN-AMPSO算法选择在同步更新的基础上提出了DLBNP策略,通过评估各节点性能对中间数据进行预划分,并在集群实际运行期间对各节点负载进行迁移调整,解决了集群并行效率低的问题。
1 相关概念介绍
1.1 皮尔森相关系数
皮尔森相关系数主要是用来衡量两个向量之间的相关性程度,它的取值是[-1,1]。如果值大于0,表示两个向量成正相关;如果值小于0,则两个向量成负相关;如果值等于0,则两个向量不相关。皮尔森相关系数的计算公式如下:
2.1.2 基于重要性的剪枝
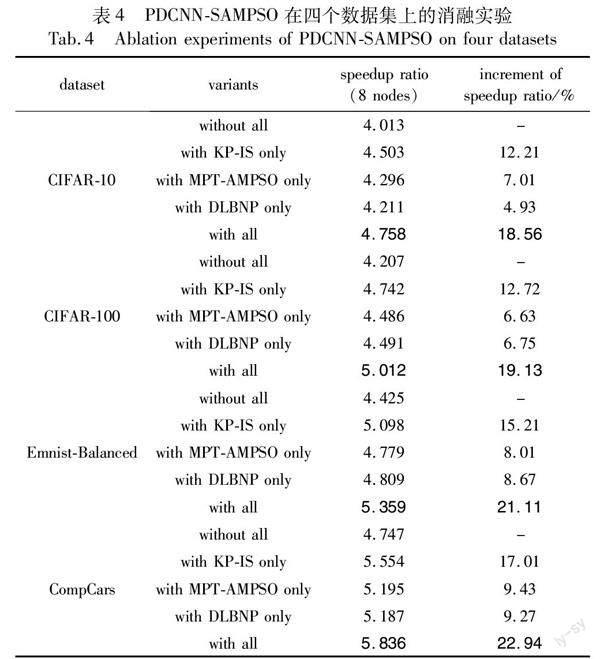
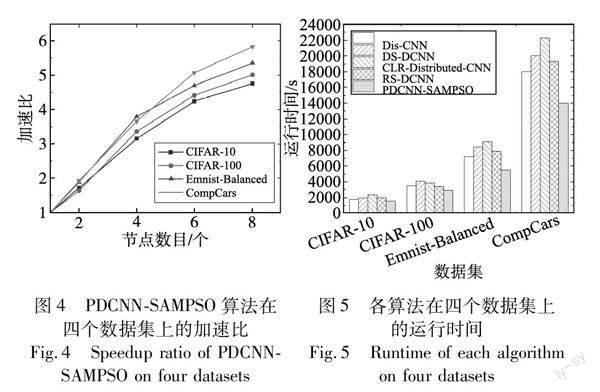
在完成对各卷积层特征聚集程度的量化之后,开始对卷积核进行剪枝。首先从卷积核的重要性这一维度对其进行剪枝,其具体过程如下:首先提出自适应重要性系数AIC作为卷积核重要性的衡量标准,并由此计算出各卷积层中卷积核的AIC;接着,比较各卷积核的自适应重要性系数AIC和给定阈值AIC0的大小,若AIC 定理2 自适应重要性系数AIC。令FCC为第i层卷积层的特征聚集系数,则第i层卷积层的第j个卷积核的重要性系数AIC可由式(14)计算。 证明 令FCC为第i层卷积层的特征聚集系数,当特征分布较为均匀时可知式(8)中LMFj·nGFj·n′趋近于1,即可得lim特征→均匀(FCC)=lim特征→均匀1j·∑ji=1LMFj·nGFj·n′≈1j·∑ji=11=1,此时AIC趋近于L1范数,能够充分考虑该卷积层中各卷积核所包含的信息;当特征分布较为聚集时LMFj·nGFj·n′>1且随聚集程度的增大而增大,此时lim特征→聚集(FCC)=lim特征→聚集1j·∑ji=1‖F‖i,max1·n‖F‖i1·n′>1,AIC趨近于更高阶范数,可以筛选出该卷积层中含有较大元素的卷积核。因此AIC可以通过当前卷积层的特征聚集系数FCC自适应地进行调整,作为卷积核重要性评估的基本准则,证毕。 2.1.3 基于相似度的剪枝 在根据卷积核的重要性对模型进行初步压缩后,考虑到此做法仅考虑了卷积核权重的数值大小,而忽略了它们之间的相关性,导致网络中可能还存在冗余的卷积核,因此还需要从卷积核的相似度这一维度对模型做进一步压缩,其具体过程如下:首先提出特征相似度系数FSC作为卷积核间相似度的衡量标准;然后依次计算每个卷积层中各卷积核两两之间的特征相似度系数FSC,并与给定的特征相似度阈值FSC0进行比较,若FSC>FSC0,则将对应的两个卷积核以元组的形式加入待删除队列Q中;接着,依次取出队列Q中元组(j,k),计算该元组所对应的卷积核j和k的自适应重要性系数AICj和AICk,并删除其中较小者所对应的卷积核;最后,当对每个卷积层完成上述操作后,输出最终剪枝完成的网络模型。 定理3 特征相似度系数FSC。设j和k分别为第i层任意两个卷积核,则卷积核j和k的特征相似度系数FSC为 其中:X和Y分别是卷积核j和k的向量表达形式。 证明 已知PCC(X,Y)代表卷积核j和k的关联程度,即PCC(X,Y)越大,卷积核j和k的相似度越大。而ED(norm(X),norm(Y))的大小反映了卷积核j和k的差异程度,其值越大,卷积核差异越大,反之卷积核差异越小。因此,两者的比值PCC(X,Y)ED(norm(X),norm(Y))在一定程度上可以反映卷积核直接的相似程度,即当该值越大时,表明卷积核之间相似程度越高;反之,表明卷积核之间相似程度越低,证毕。 算法1 模型压缩 输入:预训练得到的网络权值序列{wn}。 输出:压缩后的网络权值序列{wm}。 //特征聚集程度的量化 for each convolution layer i do calculate FCC//计算各卷积层的特征聚集系数 i=FCC//将计算结果标记给该层 end for //基于重要性的剪枝 for each convolution layer i do for each kernel j do calculate AIC//计算各卷积核的自适应重要性系数 if AIC delete j end if end for end for //基于相似度的剪枝 for each convolution layer i do create queue Qi//创建待删除队列 for each kernel j and k do calculate FSC//计算每两个卷积核的特征相似度系数 if FSC>FSC0//根据阈值将两两卷积核加入待删除队列中 Qi.push((j,k)) end if end for while Qi≠ do //遍历待删除队列 j,k←Qi.pop() calculate AICj and AICk if AICj delete j else delete k end if end while end for output {wm} //输出压缩后的网络权值序列 2.2 模型并行训练 针对模型并行训练阶段存在的收敛速度慢且容易陷入局部最优的问题,本文设计了一种基于自适应变异粒子群优化算法的参数并行训练策略MPT-AMPSO,该策略首先提出了AMPSO算法来初始化模型参数,接着使用Adam算法更新模型参数,提升了模型的收敛速率和跳出局部最优位置的能力。其主要包括两个步骤: a)参数初始化。提出了一种自适应变异的粒子群优化算法AMPSO,并使用该算法初始化模型参数。其中,AMPSO算法首先设计了一种惯性因子ω的自适应计算公式(adaptive calculation formula of ω, ACF),使得ω能跟随迭代周期自适应地调整,增加了粒子跳出局部最优的能力,其次又设计了一种粒子自适应变异函数(adaptive mutation function,AMF),AMF结合了柯西变异和高斯变异的优势,提升了PSO算法的收敛速率和跳出局部最优的能力。 b)参数并行训练。在各节点上使用Adam算法进行反向传播,最终获取模型并行训练结果。 2.2.1 参数初始化 为了解决梯度下降算法存在的收敛速度慢且容易陷入局部最优的问题,提出AMPSO算法,并在模型并行训练前,先使用该算法对模型参数进行初始化。AMPSO算法的具体过程如下: 联立式(21)~(25)可知f(x)在[0, 1]上具有关于点(1/2,1/2)对称、单调递增且一阶导在[0,1/2]单调递增,在[1/2,1]单调递减的性质。 故f(x)在横轴满足关于迭代总次数T的对称性,在纵轴满足关于rand取值的对称性,随着迭代次数的增加,AMF能通过f(t/T)的取值自适应地调整变异粒子的变异函数。即在迭代初期时,在更多的周期内有更多的粒子采用柯西变异以增强粒子在初期的全局搜索能力[21];相反在迭代末期,在更多的周期内有更多的粒子会采用高斯变异以增强粒子在末期的局部收敛能力[22]。因此AMF可作为粒子变异的自适应变异函数,证毕。 d)更新粒子群参数。先根据式(18)更新惯性因子ω后,再根据式(6)(7)更新粒子速度和位置,最后对变异粒子的位置采用式(19)进行扰动。 e)粒子群迭代。重复步骤b)~d),直到达到设置的终止条件,最终输出粒子的最优位置。 2.2.2 参数并行更新 在使用AMPSO算法对模型参数进行初始化之后,便开始对模型参数进行并行训练。参数并行训练时首先在各节点上对模型进行前向传播,并根据前向传播的结果使用Adam算法对模型参数进行反向传播求得各参数的改变量,进而获得模型并行训练的结果。其具体过程如下: a) 参数并行训练。使用Adam算法对模型参数进行反向传播求得各参数的改变量。 b) 迭代训练。重复步骤a),直到达到设置的终止条件,最终输出参数并行训练的结果,形如〈key=w,value=w〉。 算法2 模型并行训练 输入:压缩后的网络权值序列{wm};迭代次数T;适应度函数fitness(xi)。 输出:参数并行更新结果〈key=w,value=w〉。 //参数初始化 initialize n particles based on {wm} while t for each particle pi do calculate fitness(xi)//计算各粒子的适应度值 update pbesti and gbest //更新全局最优值和局部最优 update ω=(ωmax-ωmin)·cos(tT·π2)+ωmin//更新慣性因子 update vt+1i=ωvti+c1r1×(pbesti-xti)+c2r2×(gbest-xti) //更新速度 update xt+1i=xti+vti//更新位置 if pi is mutation particle update xi=AMF(xi)//对粒子进行变异操作 end if end for end while //参数并行更新 initialize the model parameters based on xi//初始化模型参数 start forward propagation and back propagation //前向传播和反向传播 output 〈key=w,value=w〉//输出参数并行更新结果 2.3 参数并行更新 针对参数并行更新阶段存在的集群并行效率低的问题,本文提出了基于节点性能的动态负载均衡策略DLBNP,该策略主要包括以下两个步骤:a)数据预划分,在reduce任务开始前,根据各节点的性能将中间数据初步划分到不同的reduce节点,充分利用各节点的性能,提高集群的资源利用率;b)数据迁移,在reduce任务实际运行期间,通过监测各节点的实际运行情况,来动态调整各节点的负载率,进一步提高集群的并行效率。 2.3.1 数据预划分 由于reduce阶段每个reduce节点在拉取中间数据时是按照key的hash值进行拉取的,所以无法保证中间数据划分的均衡性,从而导致数据倾斜,进而导致集群的并行效率过低。为了解决这一问题,本文首先根据各节点性能对中间数据进行预划分,以保证中间数据划分的均衡性,其具体步骤如下: a)设集群中有n个reduce节点,其中节点Ni(i=1,2,…,n)的负载能力为Li,当前集群中reduce阶段总任务量为Ttotal,则当集群达到负载均衡时,各节点应分得的任务量Ti为 2.5 算法时间复杂度 相较于单机器的训练方式,Dis-CNN[14]算法采用并行计算的方式实现了模型的并行化训练过程,具有更高的训练效率;DS-DCNN[15]算法使用Alluxio来存储中间数据,提升了模型的并行训练效率;CLR-Distributed-CNN[16]算法使用周期学习率替代线性变化的学习率,提升了模型的并行训练效率;RS-DCNN[18]算法通过异步更新各节点计算的梯度解决了集群相互等待的问题,提高了集群的并行效率。因此,本文选取Dis-CNN、DS-DCNN、CLR-Distributed-CNN以及RS-DCNN算法与PDCNN-SAMPSO算法进行时间复杂度分析和实验对比。 PDCNN-SAMPSO算法的时间复杂度主要是由模型压缩、模型并行训练和参数并行更新这三个部分构成。这些部分的时间复杂度分别为: a)模型压缩阶段。该阶段的时间复杂度主要取决于KP-IS策略的时间复杂度。设模型有c个卷积层,fi表示第i卷积层输出的特征图数量,ni表示第i卷积层输出特征图的边长,n′i和Si分别表示第i卷积层在计算特征聚集系数时滑动窗口的边长和滑动步长,则使用KP-IS策略进行剪枝的时间复杂度T1为 b)模型并行训练阶段。该阶段的时间复杂度主要取决于在各节点上执行MPT-AMPSO策略的时间复杂度。设迭代次数为Iter,k表示AMPSO算法初始化的粒子数,压缩后的模型总参数量为w,则使用MPT-AMPSO策略进行模型并行训练的时间复杂度T2为 c)参数并行更新阶段。该阶段的时间复杂度主要包括各reduce节点并行执行参数的合并。设map节点个数为a,reduce节点个数为b,模型总参数量为w,则参数并行组合阶段的时间复杂度T3为 由于PDCNN-SAMPSO算法在模型训练前对模型进行了有效剪枝,使得模型中第i卷积层的卷积核数量Ci大幅减少,从而大大降低了卷积运算的时间复杂度,即TConv-PDCNN-SAMPSO< 3 实验结果与分析 3.1 实验环境 为了验证PDCNN-SAMPSO算法的性能表现,本文设计了相关实验。在硬件方面,本实验设置了8个计算节点,其中包含1个master节点和7个slaver节点。各节点的配置均为AMD Ryzen 5 5600X CPU、16 GB DDR4 RAM、NVIDIA RTX2080Ti GPU,并通过1 000 Mbps的以太网相连。在软件方面,各节点的配置均为Ubuntu 18.04.6、Python 3.7、TensorFlow 1.14、JDK 1.8.0、Apache Hadoop 2.7.2、Spark 2.1.1。各节点具体配置如表1所示。 3.2 实验数据 本文采用CIFAR-10、CIFAR-100、Emnist-Balanced和CompCars四个真实数据集。其中CIFAR-10和CIFAR-100都是由现实世界中真实物体的彩色图像构成的数据集;Emnist-Balanced是源自NIST Speical Database 19的一个手写字符数字数据集;CompCars是一个车辆数据集。各数据集的详细信息如表2所示。 3.3 评价指标 3.3.1 加速比 加速比是指同一个任务在串行系统和并行系统中运行消耗時间的比率,用来衡量并行系统的性能和效果。加速比越大,算法并行程度越高。加速比的定义如下: 其中:Ts表示算法在串行系统的运行时间;Tm表示算法在并行系统的运行时间。 3.3.2 top-1准确率 top-1准确率是指正确标签为模型输出的最佳标签的样本数与总样本数的比率,用来衡量模型的分类效果。top-1准确率越高,模型分类效果越好。top-1准确率的定义为 其中:Tb是正确标签为模型输出的最佳标签的样本数;N为总样本数。 3.4 参数设置 在设置本文主要参数时,首先,对于文中引入的PSO算法[19]和Adam算法[20]中的参数均取算法一般值,即PSO算法中学习因子c1=c2=2,Adam算法中一阶矩估计指数衰减率β1=0.9、二阶矩估计指数衰减率β2=0.999。其次,对于本文所提主要参数的取值,通过参数对比实验最终确定取值,参数对比实验中使用CompCars数据集,集群节点数目为8。其中,本文主要参数为:a)模型压缩阶段中KP-IS策略滑动窗口的选取比例n′/n;b) 模型并行训练阶段MPT-AMPSO策略中惯性因子ω的最大最小值ωmax、ωmin。根据表3参数对比实验结果,本文设置n′/n=15%,ωmax=1.3,ωmin=0.7。 3.5 算法可行性分析 3.5.1 消融实验 为验证PDCNN-SAMPSO算法中各策略的有效性,本文以算法的加速比作为评价指标,使用VGG-16作为训练模型在CIFAR-10、CIFAR-100、Emnist-Balanced和CompCars数据集上进行了各策略的消融实验。同时,为确保实验结果的可靠性,将算法在每个数据集上独立运行五次,并取其平均值作为最终的实验结果,其中加速比为集群节点数目为8时的数据。实验结果如表4所示。 从表4可以看出,PDCNN-SAMPSO算法中各策略均可显著提升算法的加速比,其中KP-IS策略对算法加速比的提升效果最为明显,且随着数据集规模的增大,三个策略对算法加速比的提升效果更为明显。其中,当处理小规模数据集CIFAR-10时,使用KP-IS、MPT-AMPSO和DLBNP策略分别比不使用这些策略时算法加速比提升了12.21%、7.01%、4.93%,且同时使用三个策略时算法加速比提升了18.56%。当处理大规模数据集CompCars时,使用KP-IS、MPT-AMPSO和DLBNP策略分别比不使用这些策略时算法加速比提升了17.01%、9.43%、9.27%,且同时使用三个策略时算法加速比提升了22.94%。产生这些结果的原因是:PDCNN-SAMPSO算法设计的KP-IS策略,通过剪枝冗余卷积核消除网络中大量的冗余参数,极大地减少了冗余计算,同时MPT-AMPSO策略通过使用AMPSO算法初始化模型参数提升了模型的收敛速率,此外DLBNP策略通过均衡节点间负载,进一步提升了集群的并行效率,且这些提升在数据规模较大的情况下更为显著。由此表明,KP-IS、MPT-AMPSO和DLBNP策略在大数据环境下具有良好的可行性与有效性。 3.5.2 PDCNN-SAMPSO算法可行性分析 为验证PDCNN-SAMPSO算法在大数据环境下的可行性,本文以算法的加速比作为评价指标,对PDCNN-SAMPSO算法在CIFAR-10、CIFAR-100、Emnist-Balanced和CompCars数据集上进行了测试。同时,为确保实验结果的可靠性,将算法在每个数据集上独立运行五次,并取其平均值作为最终的实验结果。实验结果如图4所示。 从图4可以看出,PDCNN-SAMPSO算法随着节点数的增加,其加速比总体呈现上升趋势,且随着四个数据集规模的增加逐步增长。其中当节点数为2时,PDCNN-SAMPSO算法在四个数据集上的加速比差异较小算法相比于单节点的加速比分别增加了0.721、0.636、0.885和0.922;当节点数为4时,算法相比于单节点的加速比分别增加了2.151、2.362、2.794和2.662;当节点数为8时,PDCNN-SAMPSO算法在各数据集上有了显著提升,分别达到了3.758、4.012、4.359和4.836。可以看出在大规模数据集下,随着节点数量的增加,PDCNN-SAMPSO算法的并行训练效率也随之逐渐提升。产生这些结果的原因是:a)PDCNN-SAMPSO算法设计了KP-IS策略,通过剪枝冗余卷积核消除网络中大量的冗余参数,极大地提升了PDCNN-SAMPSO算法的并行训练效率;b)PDCNN-SAMPSO算法设计了MPT-AMPSO策略,通过使用AMPSO算法初始化模型参数并使用Adam算法更新模型参数,进一步提升了模型的并行训练效率。由此表明,PDCNN-SAMPSO算法在大数据环境下具有良好的可行性与有效性。 3.6 算法性能分析比较 3.6.1 算法运行时间分析 为验证PDCNN-SAMPSO算法的时间复杂度,本文在上述四个数据集上对Dis-CNN[14]、DS-DCNN[15]、CLR-Distributed-CNN[16]和RS-DCNN[18]算法分别进行了五次测试,并取五次运行时间的均值作为最终的实验结果。实验结果如图5所示。 从图5可以看出,在对各数据集进行处理时,PDCNN-SAMPSO算法的运行时间始终保持最低,并且随着数据规模的不断上升,PDCNN-SAMPSO算法的运行时间相较于其他四种算法运行时间的差异比例也逐渐扩大。其中,当处理数据量较小的数据集CIFAR-10时,PDCNN-SAMPSO算法运行时间分别比Dis-CNN、DS-DCNN、CLR-Distributed-CNN和RS-DCNN算法减少了13%、21%、33%和22%;当处理数据量较大的数据集CompCars时,PDCNN-SAMPSO算法运行时间分别比Dis-CNN、DS-DCNN、CLR-Distributed-CNN和RS-DCNN算法减少了22%、30%、37%和27%。可以看出PDCNN-SAMPSO算法相较于Dis-CNN、DS-DCNN、CLR-Distributed-CNN和RS-DCNN算法,运行时间更少,且随着数据规模的增长,其他四种算法运行时间与它的差距也在逐步加大。产生这种结果的主要原因是:a)PDCNN-SAMPSO算法设计了KP-IS策略,通过剪枝冗余卷积核消除网络中大量的冗余参数,从而降低了模型并行训练的时间开销,加快了算法的运行速度;b)PDCNN-SAMPSO算法设计了MPT-AMPSO策略,通过使用AMPSO算法初始化模型参数并使用Adam算法更新模型参数,进一步加快了算法的运行速度。由此表明,PDCNN-SAMPSO算法在大数据环境下拥有更优良的性能。 3.6.2 算法加速比实验分析 为验证PDCNN-SAMPSO算法在大数据环境下的并行性能,本文在上述四个数据集上对Dis-CNN、DS-DCNN、CLR-Distributed-CNN和RS-DCNN算法在不同数目计算节点下分别进行了五次测试,并用五次运行时间的均值来计算各算法在不同数目计算节点下的加速比。实验结果如图6所示。 从图6可以看出,在处理CIFAR-10、CIFAR-100、Emnist-Balanced和CompCars数据集时,各算法在四个数据集上的加速比随着节点数量的增加都呈逐渐上升的趋势,并且随着数据规模的增大,PDCNN-SAMPSO算法在各数据集上的加速比与其他四种算法的差距也逐步增大。其中,在处理规模较小的数据集CIFAR-10时,如图6(a)所示,各算法之间的加速比相差不大,且随着计算节点数目从2个增加到8个,PDCNN-SAMPSO算法的加速比逐步超过了其他四种算法,当计算节点为8个时,分别比Dis-CNN、DS-DCNN、CLR-Distributed-CNN和RS-DCNN算法的加速比高出了0.482、0.341、0.577和0.134。在处理数据规模较大的数据集CompCars时,如图6(d)所示,随着节点数量的不断增加,PDCNN-SAMPSO算法的優势逐渐凸显,当计算节点为8个时,分别比Dis-CNN、DS-DCNN、CLR-Distributed-CNN和RS-DCNN算法的加速比高出了1.707、1.424、1.859、0.922。产生这种结果的原因是:a)当处理规模较小的数据集时,模型并行训练计算量较小,从而各节点间的通信时间开销相对来说就变得很大,且当数据规模较小时,并行训练对训练效率的提升能力有限,从而导致PDCNN-SAMPSO算法的加速比提升不大;b)当处理规模较大的数据集时,PDCNN-SAMPSO算法设计了DLBNP策略,该策略均衡了各节点间的负载,提升了PDCNN-SAMPSO算法的并行效率,随着计算节点的增加,相较于单机的并行效率逐步提升,从而提升了算法的加速比。由此表明,PDCNN-SAMPSO算法在大数据环境下相较于其他算法具有更好的并行性能。 3.6.3 算法top-1准确率实验分析 为验证PDCNN-SAMPSO算法的分类效果,本文以top-1准确率作为评价指标,将PDCNN-SAMPSO算法分别与Dis-CNN、DS-DCNN、CLR-Distributed-CNN和RS-DCNN算法在CIFAR-10、CIFAR-100、Emnist-Balanced和CompCars四个数据集上进行了对比实验。实验结果如图7所示。 从图7可以看出,虽然在训练初期PDCNN-SAMPSO算法相比其他四种算法的top-1准确率略低,但是随着训练轮次的不断增加,PDCNN-SAMPSO算法比其他四种算法收敛速度更快且准确率更高。其中,在处理较小规模的数据集CIFAR-10上,如图7(a)所示,PDCNN-SAMPSO算法在训练轮次为50轮时便已经开始收敛,比Dis-CNN和RS-DCNN算法的收敛轮次快了10轮,比DS-DCNN和CLR-Distributed-CNN算法的收敛轮次快了20轮,且最终的top-1准确率分别比Dis-CNN、DS-DCNN、CLR-Distributed-CNN和RS-DCNN算法高了3.42%、1.59%、2.38%、4.97%。在处理较大规模的数据集Emnist-Balanced和CompCars上,如图7(c)(d)所示,PDCNN-SAMPSO算法对比其他四种算法,在收敛速度和最终top-1准确率上提升更为明显。产生这种结果的原因是:a)PDCNN-SAMPSO算法设计了KP-IS策略,通过剪枝冗余卷积核消除网络中大量的冗余参数,由于剪枝完成后,模型需要一定的训练轮次来恢复精度,所以在训练初期模型精度会有所降低,但是随着训练轮次的增加,消除冗余参数所带来的训练速度和准确率的提升效果就会愈发显著;b)PDCNN-SAMPSO算法设计了MPT-AMPSO策略,通过使用AMPSO算法初始化模型参数并使用Adam算法更新模型参数,进一步加快了算法的收敛速度和分类精度,且这种提升在数据规模更大的数据集上效果更为明显。由此表明,PDCNN-SAMPSO算法在大数据环境下有着更为优良的分类性能。 4 应用场景 近年来,随着遥感设备的不断发展以及无人机的快速普及,遥感技术已经被广泛应用于灾害预测、环境监测、数字城市等各领域。与此同时,这也使得遥感数据规模呈爆炸式的增长,海量的遥感数据也意味着遥感大数据时代的到来[23],进而给遥感数据的有效信息提取带来了巨大的挑战[24]。PDCNN-SAMPSO针对DCNN算法在大数据环境的改进,给上述问题的解决提供了新的方向。图8展示了将PDCNN-SAMPSO应用于遥感图像分类的具体模型结构。 在该模型结构中, PDCNN-SAMPSO首先调用KP-IS策略剪枝预训练的网络模型,消除了过多的冗余参数,避免了后续信息提取过程中不必要的资源消耗;其次通过调用MPT-AMPSO策略加速了算法从遥感图像中提取信息的速率;最后在Spark框架的并行期间调用DLBNP策略,进一步提升了信息提取效率,从而解决了在遥感大数据时代,传统算法对遥感图像中有效信息提取能力不足的问题。 5 结束语 针对传统深度卷积神经网络算法在大数据环境下的不足,本文提出了一种基于Spark和AMPSO的并行深度卷积神经网络优化算法——PDCNN-SAMPSO。首先,设计了基于卷积核重要性和相似度的卷积核剪枝策略KP-IS,通过从卷积核重要性和相似度两个维度对模型进行剪枝,解决了冗余参数过多的问题;其次,设计了基于自适应变异粒子群优化算法的模型并行训练策略MPT-AMPSO,在该策略中先提出了一种自适应变异的粒子群优化算法AMPSO,通过使用AMPSO算法来初始化模型参数,接着再使用Adam算法对模型参数进行更新,解决了并行DCNN算法收敛速度慢和容易陷入局部最优的问题;最后,提出了基于节点性能的动态负载均衡策略DLBNP,通过评估各节点性能对中间数据进行预划分,并在集群实际运行期间对各节点负载进行迁移调整,解决了集群并行效率低的问题。实验表明,PDCNN-SAMPSO算法相較于其他算法,在处理大数据时具有更优的性能表现。虽然PDCNN-SAMPSO算法在大数据环境下的深度卷积神经网络模型的并行训练方面取得了不小的进步,但该算法在分类精度上仍存在一定的提升空间,未来的工作重点也将集中在卷积核剪枝标准的选择方面,使其对模型的压缩更为精准,从而进一步提升算法的分类精度。 参考文献: [1]Gu Jiuxiang, Wang Zhenhua, Kuen J, et al. Recent advances in convolutional neural networks[J].Pattern Recognition,2018,77:354-377. [2]Russakovsky O, Deng Jia, Su Hao, et al. ImageNet large scale visual recognition challenge[J].International Journal of Computer Vision,2015,115(3):211-252. [3]Sarma B D, Prasanna S R M. Acoustic-phonetic analysis for speech recognition: a review[J].IETE Technical Review,2018,35(3):305-327. [4]Deng Jun, Xuan Xiaojing, Wang Weifeng, et al. A review of research on object detection based on deep learning[J].Journal of Physics:Conference Series,2020,1684(1):012028. [5]Mo Yujian, Wu Yan, Yang Xinneng, et al. Review the state-of-the-art technologies of semantic segmentation based on deep learning[J].Neurocomputing,2022,493:626-646. [6]Li Lixiang, Mu Xiaohui, Li Siying, et al. A review of face recognition technology[J].IEEE Access,2020,8:139110-139120. [7]Mozaffari S, Al-Jarrah O Y, Dianati M, et al. Deep learning-based vehicle behavior prediction for autonomous driving applications:a review[J].IEEE Trans on Intelligent Transportation Systems,2020,23(1):33-47. [8]Kaisler S, Armour F, Espinosa J A, et al. Big data: issues and challenges moving forward[C]//Proc of the 46th Hawaii International Conference on System Sciences.Piscataway,NJ:IEEE Press,2013:995-1004. [9]Leung J, Chen Min. Image recognition with MapReduce based convolutional neural networks[C]//Proc of the 10th Annual Ubiquitous Computing,Electronics & Mobile Communication Conference.Pisca-taway,NJ:IEEE Press,2019:119-125. [10]Wang Qicong, Zhao Jinhao, Gong Dingxi, et al. Parallelizing convolutional neural networks for action event recognition in surveillance videos[J].International Journal of Parallel Programming,2017,45(4):734-759. [11]Li Binquan, Hu Xiaohui. Effective vehicle logo recognition in real-world application using MapReduce based convolutional neural networks with a pre-training strategy[J].Journal of Intelligent & Fuzzy Systems,2018,34(3):1985-1994. [12]毛伊敏,張瑞朋,高波.大数据下基于特征图的深度卷积神经网络[J].计算机工程与应用,2022,58(15):110-116.(Mao Yiming, Zhang Ruipeng, Gao Bo. Deep convolutional neural network algorithm based on feature map in big data environment[J].Computer Engineering and Applications,2022,58(15):110-116.) [13]Zaharia M, Xin R S, Wendell P, et al. Apache Spark: a unified engine for big data processing[J].Communications of the ACM,2016,59(11):56-65. [14]Xu Jiangfeng, Ma Shenyue. Image classification model based on spark and CNN[C]//Proc of the 2nd International Conference on Material Engineering and Advanced Manufacturing Technology.2018. [15]Li Chen, Jiang Linhua, Chen Xiaodong. A distributed CBIR system based on DCNN on Apache Spark and Alluxio[C]//Proc of International Conference on Image and Video Processing, and Artificial Intelligence.[S.l.]:SPIE,2018. [16]Sun Yulu, Yun Bensheng, Qian Yaguan, et al. A Spark-based method for identifying large-scale network burst traffic[J].Journal of Computers,2021,32(4):123-136. [17]Smith L N. Cyclical learning rates for training neural networks[C]//Proc of IEEE Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE Press,2017:464-472. [18]Boulila W, Sellami M, Driss M, et al. RS-DCNN: a novel distributed convolutional-neural-networks based-approach for big remote-sen-sing image classification[J].Computers and Electronics in Agriculture,2021,182:106014. [19]Shi Yuhui, Eberhart R. A modified particle swarm optimizer[C]//Proc of IEEE International Conference on Evolutionary Computation and IEEE World Congress on Computational Intelligence.Piscataway,NJ:IEEE Press,1998:69-73. [20]Kingma D P, Ba J. Adam: a method for stochastic optimization[EB/OL].(2017-01-30).https://arxiv.org/abs/1412.6980. [21]杜曉昕,张剑飞,郭媛,等.基于柯西—高斯动态消减变异的果蝇优化算法研究[J].计算机工程与科学,2016,38(6):1171-1176.(Du Xiaoxin, Zhang Jianfei, Guo Yuan, et al. A fruit fly optimization algorithm with Cauchy-Gaussian dynamic reduction mutation[J].Computer Engineering and Science,2016,38(6):1171-1176.) [22]Song Xiaoxin, Jian Ling, Song Yunquan. A chunk updating LS-SVMs based on block Gaussian elimination method[J].Applied Soft Computing,2017,51:96-104. [23]刘伟权,王程,臧彧,等.基于遥感大数据的信息提取技术综述[J].大数据,2022,8(2):28-57.(Liu Weiquan, Wang Cheng, Zang Yu, et al. A survey on information extraction technology based on remote sensing big data[J].Big Data Research,2022,8(2):28-57.) [24]张兵.遥感大数据时代与智能信息提取[J].武汉大学学报:信息科学版,2018,43(12):1861-1871.(Zhang Bing. Remote sensing big data era and intelligent information extraction[J].Geomatics and Information Science of Wuhan University,2018,43(12):1861-1871.) 收稿日期:2023-03-31;修回日期:2023-04-25 基金项目:科技创新2030-“新一代人工智能”重大项目(2020AAA0109605);广东省重点提升项目(2022ZDJS048);韶关市科技计划资助项目(220607154531533) 作者简介:刘卫明(1964-),男,江西新余人,教授,硕导,硕士,主要研究方向为大数据和数据挖掘;罗全成(1997-),男,河南信阳人,硕士研究生,主要研究方向为大数据和数据挖掘;毛伊敏(1970-),女(通信作者),新疆伊犁人,教授,硕导,博士,主要研究方向为大数据和数据挖掘(mymlyc@163.com);彭喆(1990-),男,湖南邵阳人,硕士研究生,主要研究方向为大数据和数据挖掘.
