
基于智能驾驶员模型算法的长期跟车车速预测研究*
2023-09-26 03:45缴文政孙志强付景顺孙凤
汽车技术 2023年9期
缴文政 孙志强 付景顺 孙凤
(沈阳工业大学,沈阳 110870)
主题词:车速预测算法 智能驾驶员模型 NGSIM 遗传算法 参数标定
1 前言
当前,车速预测算法总体分为随机型车速预测算法和确定型车速预测算法[1]。基于马尔可夫链(Markov Chain,MC)的算法是具有代表性的随机型车速预测算法[2-6]。虽然通过建立多级马尔可夫链模型能够提升车速预测的准确性,但会导致算法体量呈指数级增长。
确定型车速预测算法可分为参数型车速预测算法和非参数型车速预测算法[7]。基于非参数型车速预测算法的研究已经得到了广泛的应用:支持向量机(Support Vector Machine,SVM)主要用于在较短的时间间隔内预测车速[8-9];神经网络可用于数据驱动型算法[10],其因良好的非线性映射能力、较强的鲁棒性,已广泛应用于车速预测领域[11-15],但这种方法依赖大量的训练数据。
基于参数型车速预测的算法中,Rezaei 等人[16]使用自回归移动平均(Autoregressive Moving Average,ARMA)模型,其参数通过历史数据确定,但随着视距增加,该模型会出现预测精度下降的问题;Kesting 等人[17]利用一种新的恒定加速度启发式(Constant-Acceleration Heuristic,CAH)算法对智能驾驶员模型(Intelligent Driver Model,IDM)进行扩展;Li 等人[18]针对驾驶员的参数校准提出了一种新的方法;James 等人[19]对比了校准驾驶员模型中常用的8种方法,证明IDM有较高的车速预测性能。
预测精度和速度往往无法兼顾。Lefèvre 等人[20]比较了参数型和非参数型车速预测算法,在相同的试验环境和试验条件下,非参数模型的表现优于参数模型,然而对于长期预测,选取先进的参数模型更为合适。这主要是由于IDM 等参数模型都被设计为具有约束车辆长期行为的稳定性特性,而非参数模型仅被训练为表示2个时间步之间目标车辆的行为。
新能源汽车的能量管理策略需要精确的车速预测作为前置条件。本文以车辆自身的速度轨迹预测为主要研究对象,以GPS、离线地图数据库、前视测距传感器为信息源,建立基于智能驾驶员模型的车速预测算法。
2 IDM算法建模
受车辆、驾驶员等多重因素的影响,理论上满足约束条件车速预测的解无穷多。为了计算出单一的速度轨迹,以更精确地预测车速,假设驾驶员对外部交通环境的反应遵循一套通用的规则。虽然相对于实际驾驶员的驾驶行为进行了很大程度的简化,但许多驾驶员模型在此基础上都能够很好地反映实际驾驶员的驾驶行为。
2.1 智能驾驶员模型
Treiber 等人[21]最早提出智能驾驶员模型。IDM 的参数都具有明确的物理意义,可以直观地展示驾驶行为的变化情况,并且该模型可以同时适用于通畅与拥堵状态下的车速预测[20]:
式中,S0为拥堵状态的最小车距;Smin为期望最小车距;Tgap为最小安全车头时距;α为最大加速度;β为期望减速度;V为主车车速;V0为当前环境期望车速;VL为前车的速度;SL为主车与前车的距离。
该算法由加速策略和减速策略2个部分组成:加速策略为Vfree(V)=α[1-(V/V0)δ],其中δ为驾驶员加速度指数;减速策略为Vbrake(Smin,V,SL)=-α(Smin/SL)2,当主车和前车的距离与期望的安全间距接近时,Smin开始发挥作用。主车加速行为由期望速度V0、最大加速度α和驾驶员加速度指数δ体现,当δ=1 时,加速度随车速线性下降,当δ→∞时加速度恒定。有效的最小车距Smin由最小车距S0(仅与低速有关)、与速度相关的距离VTgap(对应于以恒定的期望时间间隔Tgap跟随前车)和与前车的动态车速差(V-VL)决定。
为提高IDM的车速预测精度,需要足够多可供预测的输入数据。本文通过考虑3 个方面将不同类型的输入数据集成到改进的智能驾驶员模型中:
a.加速度极限αmax,用于模拟车辆动力系统提供牵引力的能力;
b.速度限制Vlim,用于整合交通环境的速度限制、停车和转弯;
c.最小车距S0、行车时距Tgap、驾驶员加速度指数δ、驾驶员减速度指数b及法定限速度的驾驶员偏差系数γ,用于参数化表示驾驶员行为。
本文使用改进的驾驶员行为模型实现基于模型的速度预测,IDM的输入分别为Vlim、VL和SL,考虑到车速预测过程中驾驶员的减速行为直接影响预测精度,将减速策略中的固定指数2 改为可调的驾驶员减速度指数b,以便于后续参数标定。优化后算法如下:
式中,(k+1)为(k+1)时刻的预测速度;(k+1)为(k+1)时刻预测的覆盖距离;Ts为采样时间;Vlim为所需的期望速度或在探测器探测范围内交通环境对车速的限制;S(k)为k时刻预测车辆行驶的距离;V(k)为k时刻的主车车速;VL(k)为k时刻的前车车速;βmax为最大减速度。
图1所示为速度预测器的方法和架构。
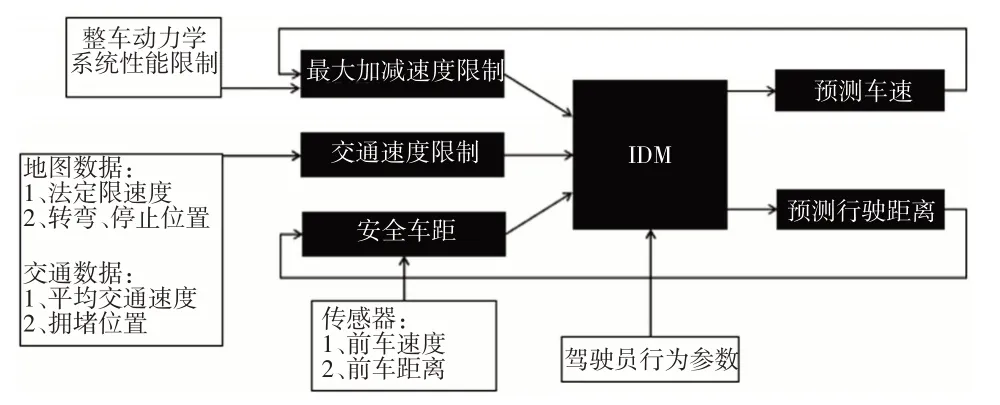
图1 速度预测器框架
2.2 车辆动力系统限制
在传统的IDM 研究中,多数研究者将IDM 的加速度计算为恒定的最大加速度αmax,但其通常无法充分表达复杂的动力系统行为和动力系统极限。在动力系统的限制下,加速度应与车速相关,车速提高,车辆的加速度减小。动力传动极限会直接影响车辆的速度曲线,导致速度预测的准确性下降。
车辆在不同速度下的外力可计算为:
式中,Fdrag为由空气、滚动摩擦和路面坡度施加的力;Meq、m分别为车辆的等效惯量和质量;Fprop为车辆牵引或制动系统施加的力;ρ为空气密度;Cd为空气阻力系数;A为迎风面积;Croll为滚动摩擦因数;θ为以弧度表示的道路坡度;Finertia为车辆的惯性力。
为使车辆加速,施加在车轮的驱动力必须能够抵抗车辆运动时受到的外力。根据牛顿第二定律,发动机产生的多余力与合成加速度成正比。车辆最大加速度曲线如图2所示。

图2 αmax曲线
2.3 交通环境的速度限制
基于交通环境的限制车速Vlim决定了在没有前车情况下车辆的加速度。当前车速V(k)与Vlim的比值决定了驾驶员对车辆加速或减速的期望:如果V(k)/Vlim>1,改进IDM算法将产生减速请求;在没有前车或与前车距离较远的情况下,V(k)/Vlim<1,改进IDM 算法将产生加速请求。由车辆传感器探测到的前方路况和线上实时交通数据等信息都将纳入Vlim的考虑范围,主要包括当前路段的法定车速限制、交通拥堵时的动态车速限制、停止标识限制、车辆转弯时的车速限制。
式(4)中交通环境的速度限制Vlim实现方法为[17]:
式中,VL1为法定限速度限制;VL2为动态交通平均速度限制;VL3为车辆停止-起步速度限制;VL4为车辆转弯速度限制;VSL为车辆行驶位置的法定限速度;Vtraffic为交通拥堵造成的动态平均速度限制;Sstop,i、Sturn,i分别为第i个停止位置和转向位置与预测初始点的距离;fstop、fturn分别为车辆停止位置和转弯位置的车速限制系数。
图3 所示为经大量实车行驶车速数据拟合而成的停止和转弯的车速限制系数,对停止和转弯事件具有良好的预测性,也体现了车辆在停止和转弯位置的速度变化情况,可使车速预测模型具有更高的精度。
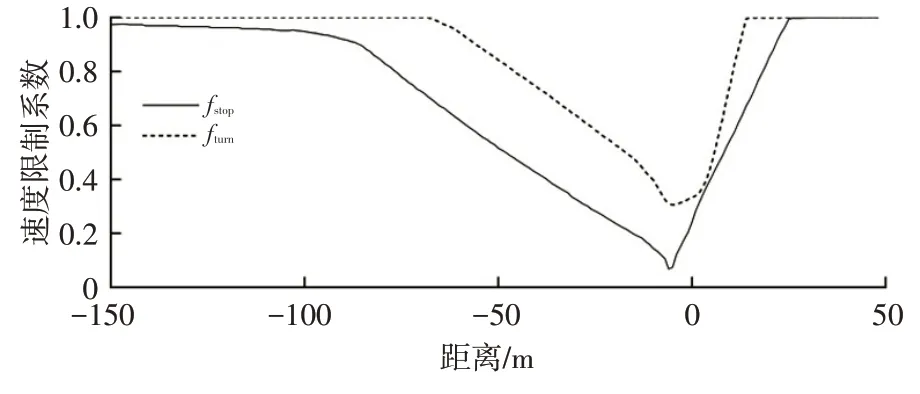
图3 停止和转弯的车速限制系数
2.4 驾驶员参数
在改进的IDM 中主要用5 个参数对驾驶员行为进行参数化:S0、Tgap、γ、δ、b。其中,δ可直接影响车辆的加速过程,b可直接影响车辆的减速过程,γ直接决定车辆的稳定行驶速度。而S0和Tgap相对更难确定,存在很多不确定因素,但二者对于车速预测的精度影响较小。
3 验证数据的来源及处理
本文所使用的仿真分析数据主要来自NGSIM(Next Generation Simulation)数据集,其具有数据开源、采集频率高、数据精准、车辆信息类型丰富等优点。基于以上优点,本文利用其中的US-101 数据集对改进的IDM的参数进行标定,该数据包的数据种类及释义如表1所示。
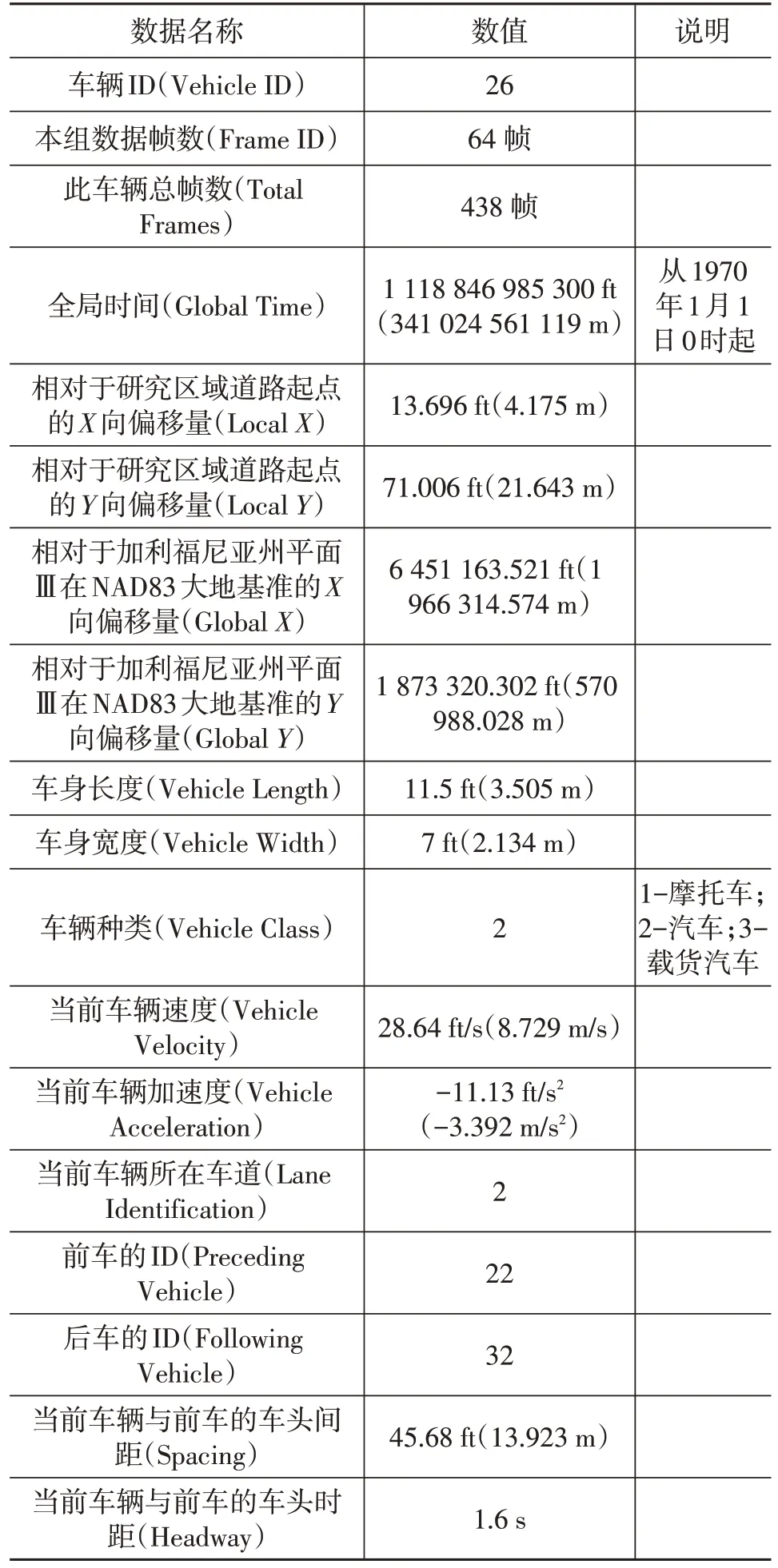
表1 数据种类及数据释义
由于数据过于庞杂,并非所有数据均满足改进的IDM 参数调试、标定的需求,因此必须从数据集的原始数据中筛选出满足相关要求的数据。具体筛选条件为:
a.只选取一直位于同一车道上的车辆。
b.所选取的车辆前方应一直存在车辆,即车队中的第1辆车不作为主车。
c.不同车型的车辆性能存在较大差异,因此选取主车时应排除摩托车和卡车车型,只选取小型汽车作为主车。虽然不同品牌、不同排量的家用轿车也存在性能差异,但由于NGSIM 项目中的US-101 公路数据为交通相对拥堵时的数据,因此小型汽车之间的性能差异可以忽略。
部分筛选结果如表2所示。
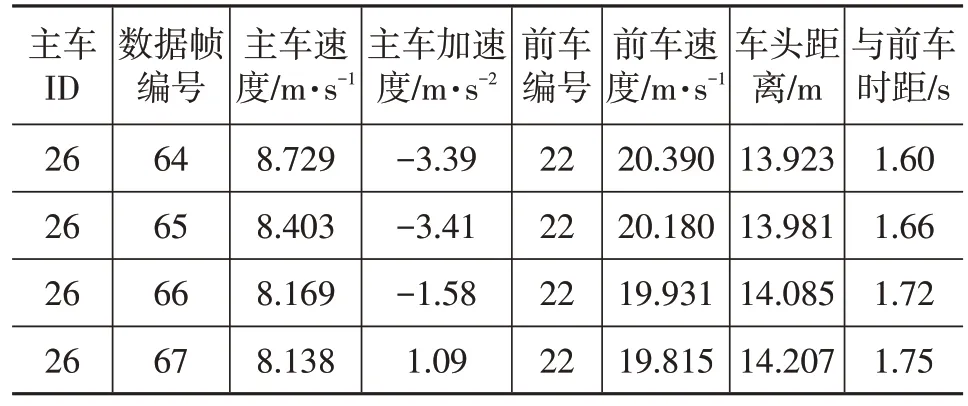
表2 部分筛选结果示例
4 参数标定及校核
改进的IDM 的参数标定及校对过程可视为非线性规划问题求最优解的过程,本文的参数标定通过优化算法寻优的方法完成。
标定过程主要包含仿真输入、仿真算法、仿真步长及仿真结果输出4 个部分。仿真输入主要包括主车的速度、主车的加速度、前车的速度、主车与前车的距离和时距等。仿真算法即为2.1 节中改进的车速预测模型。
4.1 优化算法的选取
遗传算法(Genetic Algorithm,GA)用于解决寻优问题,吸取了Darwin的进化论和Mendel的遗传学理论,具有良好的自适应和寻优能力[22-24]。
目标函数是预测车速与实际车速的误差,需优化的变量是车速预测模型参数,约束是模型参数的物理边界。由于对目标函数的收敛要求,本文采用MATLAB搭建遗传算法来求解近似最优值,遗传算法框架如图4所示。
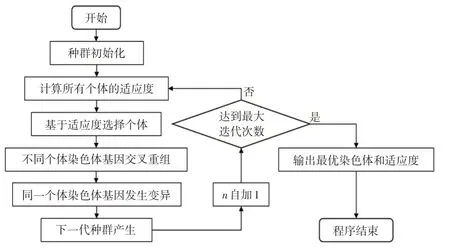
图4 遗传算法框架
a.初始化。确定种群规模N、交叉概率、变异概率和终止进化准则;随机生成个体作为初始种群X(0)。
b.计算或估计X(t)中各个体的适应度。
c.选择母体。从X(t)中运用选择算子选择出M/2对母体(M≥N)。
d.交叉重组。对所选择的M/2对母体,依概率执行交叉形成M个中间个体。
e.发生变异。对其中M个个体分别独立依照概率执行变异,形成M个候选个体。
f.选择子代。从M个候选个体中依适应度选择N个个体组成新一代种群X(t+1)。
g.结束程序。如已满足终止准则或达到最大迭代次数则终止程序,输出最优染色体和适应度。
本文具体校准程序选择Ossen 和Hoogendoorn 推荐的目标函数[25]:
式中,H为预测样本总量;ahsim为车辆h预测的加速度;ahreal为车辆h的实际加速度。
4.2 车速预测模型参数标定结果
根据NGSIM 项目中的实际数据及遗传算法的应用,可以得到改进后的IDM 最优取值,如表3 所示,αmax已在前文中确定。

表3 参数标定结果
5 车速预测算法的仿真结果
本文仿真采用的计算机的中央处理器为酷睿i9-10980XE,在Simulink 模块中建立控制算法和整车动力学模型,然后接入PreScan软件中进行联合仿真[26],仿真架构如图5所示。
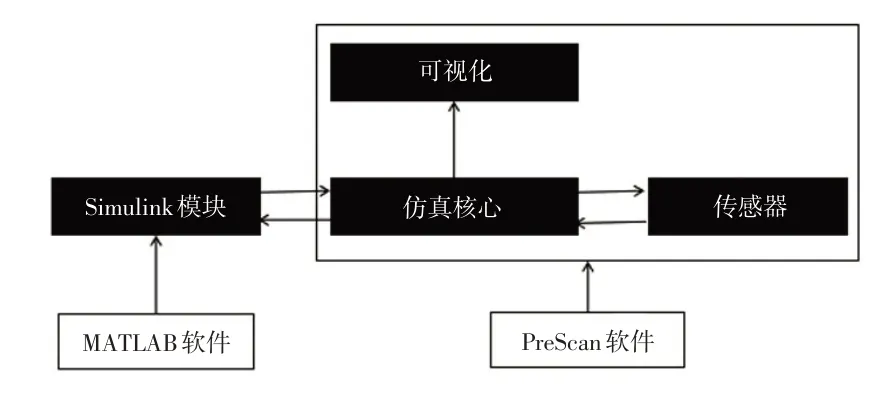
图5 联合仿真框架
5.1 车速预测算法仿真环境的建立
5.1.1 交通环境设置
建立与US-101数据采集路段相同的路况。
5.1.2 车辆模型配置
车辆模型包括主车的车型和前方车辆的车型。试验中车辆过多会使仿真速度变慢,可适当简化环境中的车辆。
5.1.3 主车传感器配置
选择2 个独立技术传感器(Technology Independent Sensor,TIS)负责信号接收,均布置在主车的车头,配置如表4所示。
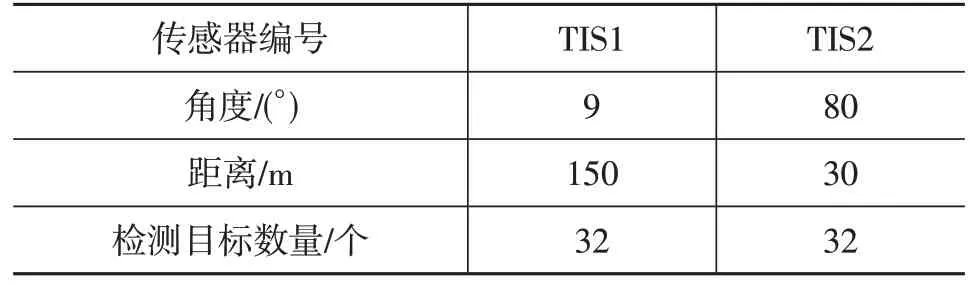
表4 传感器配置
5.1.4 主车和前车驾驶数据设定
本文以NGSIM 项目的US-101数据集为基础数据,选取主车及对应的前车,即可得到两车的速度等相关数据,在仿真过程中,为与实际数据相吻合,在Simulink中插入两车的速度插值表分别与两车的动力学模型连接,直接由插值表控制两车车速。
5.2 预测结果
大量文献显示,短期车速预测时长多集中在1 min以内,而长期车速预测多数可以超过1 min[27],本文研究的车速预测时长为80 s。
本文将主车置于同一路段的不同交通环境下行驶,通过改变交通环境的车流量、车流速度、不同前车、不同车道等交通环境信息得到了80 s 的大量仿真结果。本文预抽取预测精度最低和最高的2组数据和1组转弯停车行驶数据进行分析。
交通拥堵对车速有直接的影响,利用一段道路上的动态平均限速度Vtraffic、法定限速VSL和车辆在i时刻交通动态平均速度Vi(共n个时刻),构建交通拥堵程度评价函数Tseverity,可以更直观地表达交通拥堵情况:
从式(13)中可以看出,交通拥堵程度总是正数,但由于交通过度拥堵时车速可能为0,故设定Tseverity的最大阈值为20。3次仿真过程的交通拥堵情况如图6所示。
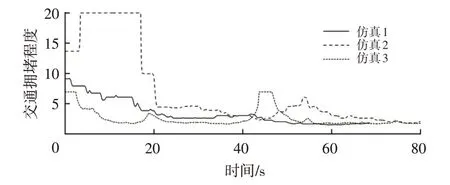
图6 交通拥堵情况
在拥堵路段,前车速度是影响主车的主要因素,主车的速度主要通过前车的行为预测。IDM 的速度预测结果如图7 所示,仅利用速度限制作为输入数据的预测,获得的预测车速会随速度限制的变化而变化。
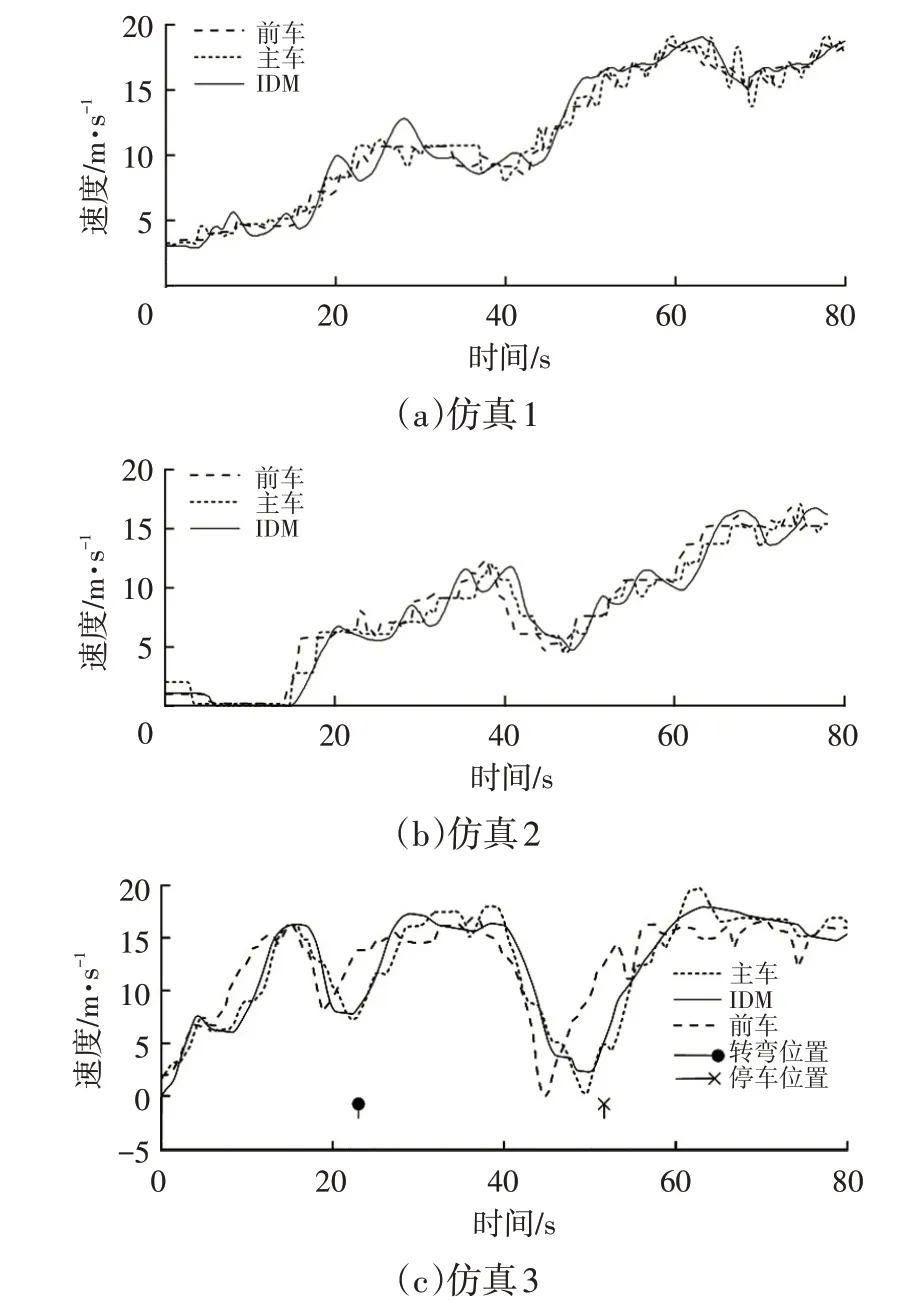
图7 车速预测结果
图8 所示为3 次仿真的车速误差。从图8a 和图8b中可以明显地看出,由于仿真1的交通环境拥堵程度相对于仿真2的更低,所以预测误差更小,同时可以看出,加、减速转换过程中误差相对较大,由于不同的驾驶员对于前方车辆的大幅度加减速转变所采取的反应有所不同,且反应能力不同,因此会产生较大误差。由图7c和图8c 可以看出,车速预测算法中加入停止和转弯的车速限制系数控制车辆在转弯和停止处的车速可以很好地模拟驾驶员行为趋势,减小车速预测算法在转弯和停车行为中的误差。根据上述仿真结果可以确定,优化后的车速预测算法在交通拥堵、路况复杂的环境中仍可实现较高的车速预测精度。

图8 仿真车速误差
图9 所示为3 次仿真的加速度对比结果,由图9 可知,当车速升高时,车辆的加速能力普遍不足,加速能力随车速和挡位的升高而降低,这也更符合实际行驶中车辆的动力学性能。此外,该模型还对前车紧急制动后的加速行为表现出了一定的预判,但是,由于模型预测较为保守,预测获得的车辆加速度相较于真实值偏低,这主要与δ和b相关,但是由于每个驾驶员的驾驶习惯不同,将这2个参数调高反而会影响此算法对其他车辆的预测精度。

图9 仿真加速度对比
本文使用的预测精度评价指标是均方根误差Erms、平均绝对百分比误差Emap:
式中,(k)、x(k)分别为模型预测的数据和车辆的真实数据;u为数据数量。
表5 列出了3 次仿真结果的车速预测误差,由于车辆在停止(车速为0)时会引起式(14)、式(15)的失常,带来计算上的错误,故在进行性能评价时忽略了车辆的停止持续时间。从图6中可以看出,由于仿真1相对于仿真2的交通情况更加简单,故仿真1的预测精度高于仿真2的预测精度,不同的驾驶员行为所带来的差异更大,驾驶员的操作差异更加难以预料,故仿真2 的误差更大。从图7c中可以看出,仿真3虽然存在车辆转弯和停止等事件,但加入停止和转弯的车速限制系数控制后,仍然有着较高的车速预测精度。
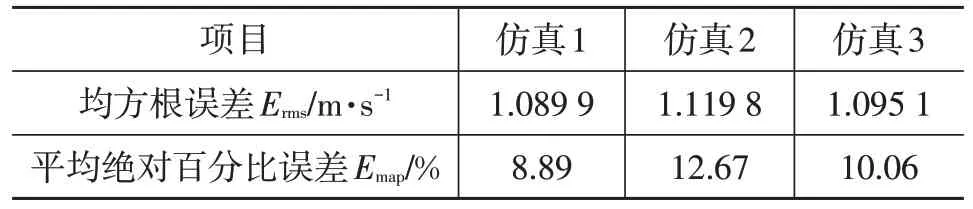
表5 车速预测误差分析
查阅大量资料发现,在复杂的交通环境下长期车速预测平均百分比误差通常在10%以上,而本文采用IDM跟车车速预测方法平均百分比误差可控制在8%~13%。
路程预测结果会作为输入重新返回到改进的IDM中,也会影响整体模型的预测精度。如图10所示,由于车速的预测结果精度很高,路程预测结果也有着很高的精度。
由于平均绝对百分比误差是从数据整体进行评估,故对路程预测的评价只从平均绝对百分比误差方面分析,仿真1~仿真3平均绝对百分比误差分别为0.024%、0.408%、0.575%,车速预测结果虽然有一定的波动性,但整体的路程预测精度依然很高。
6 结束语
本文系统地概括了影响车辆速度的道路交通特征和相应的前瞻数据,建立了具有车辆和车辆动力系统的参数化模型及基于前瞻性数据的速度预测器,通过对2条性质不同路线的仿真研究,证明了预测器处理不同水平的前瞻信息和提供准确预测的能力。
此外,可以观察到预测精度最低和最高水平的前瞻数据之间的差异取决于交通环境的特征。高速公路行驶工况下,观察到有关停车标志和转弯的前瞻性数据几乎没有增加优势,因为高速公路上缺乏此类道路特征。然而,在城市的交通环境中,与仅限速的前瞻数据相比,本算法具有显著优势。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年4期)2022-03-07
汽车与驾驶维修(维修版)(2021年11期)2021-12-01
汽车与驾驶维修(维修版)(2021年11期)2021-11-24
时代汽车(2018年4期)2018-05-31
汽车维护与修理(2018年1期)2018-04-04
山东青年(2017年7期)2018-01-11
公民与法治(2016年4期)2016-05-17
汽车维护与修理(2015年5期)2015-02-28
警察技术(2015年6期)2015-02-27
