
基于点云鸟瞰图的实时车辆目标检测*
2023-09-26 03:45吴庆彭育辉黄炜陈泽辉姚宇捷
汽车技术 2023年9期
吴庆 彭育辉 黄炜 陈泽辉 姚宇捷
(福州大学,福州 350116)
主题词:YOLOv4-tiny 点云RGB特征图 角度预测 双注意力机制
1 前言
近年来,基于车载激光雷达的三维目标检测备受关注,但是存在三维点云数据量大、目标检测算法计算量大和实时性差的问题[1-3],将三维点云构建成鸟瞰图输入二维目标检测网络是一种有效的处理方法。根据信息来源不同,基于鸟瞰图的目标检测算法可以分为两类,一类融合激光雷达与相机采集的信息进行检测,另一类仅基于激光雷达采集的点云信息进行检测。在基于激光雷达与相机的信息融合的目标检测算法方面,多视角3D(Multi-View 3D,MV3D)网络[4]采用3个输入,即RGB图像、鸟瞰图投影图像和前视图投影图像,利用深度融合(ContFusion)网络对3 个输入进行感兴趣区域(Region Of Interest,ROI)提取操作,输出融合特征图,最后细化3D检测框;深度融合网络[5]分别对图像和点云进行特征提取,建立激光雷达点云源数据投影关系,提取融合特征,但计算效率较低。在基于纯点云的鸟瞰图目标检测算法中:BirdNet网络[6]将三维点云信息处理成鸟瞰图,将其输入快速区域卷积神经网络(Fast Region Convolutional Neural Network,Fast R-CNN)[7]中完成检测任务;BirdNet++网络[8]在BirdNet 网络的基础上添加两级对象检测器和特殊回归分支,可以实现由鸟瞰图检测回归到三维边界框;目标分解网络(Matting Objective Decomposition Network,MODet)[9]不考虑三维点云的反射强度,直接对三维点云进行鸟瞰图投影,通过残差结构提取高层语义信息,融合多层次特征图,网络检测速度达到20 帧/s;3D 网格(GridNet-3D)[10]将2D 网格映射用于预处理原始点云,直接输入到区域提议网络模块完成检测,检测频率达到21.5 Hz;BEVDetNet[11]利用关键点检测目标中心,边界框预测和方向预测使用装箱分类在一个更简单的鸟瞰图上表示,检测时间达到0.06 s。FS23D 网络[12]针对鸟瞰图投影后的稀疏特征信息,采用网格前景分割而不采用基于锚框的方法来预测对象,检测网络运行速度达55.1 帧/s。
综上,基于激光雷达与相机的信息融合的目标检测算法利用点云鸟瞰图信息以及其他传感器信息进行特征提取,但是检测效率低,而基于纯点云的鸟瞰图目标检测算法只通过点云鸟瞰图提取特征信息,检测效率有所提升,但是网络的特征信息提取能力较弱,导致检测精度较低。为此,本文提出一种基于点云鸟瞰图的实时车辆目标检测算法,将原始点云的高度、强度和密度信息进行编码,构建RGB特征图,通过添加车辆目标检测旋转框的检测尺度、添加改进空间金字塔池化(Spatial Pyramid Pooling-Fast,SPPF)模块、引入双注意力机制和优化损失函数对YOLOv4-tiny网络进行改进,在实现车辆目标检测网络轻量化的同时保证车辆的检测精度。
2 点云RGB特征图构建
目前,自动驾驶领域成熟的点云数据库有KITTI数据库、Apollo Scape 自动驾驶数据库、Waymo 数据库等,为网络模型的训练及验证提供支持。KITTI 数据库中的车辆数据丰富,包含检测的各种场景,且标注完备,故选择KITTI数据库作为本文算法研究的数据支撑。
Chen 等[4]提出MV3D 网络对三维点云的高度、强度和密度分别进行编码,将投影点云离散化为分辨率为0.1 m 的二维网格,然后对每个网格计算高度、强度、密度。但是,投影点云离散化成二维网格中的分辨率对点云特征信息的保留十分重要,MV3D的二维网格的分辨率过大,导致丢失大量的点云特征信息,不利于后期的目标检测。
YOLOv4-tiny 网络输入图片的分辨率为608×608,使二维网格变小,可改善三维点云投影到二维网格中车辆点云特征信息丢失的情况。考虑长度x、宽度y、高度z的取值范围分别为[0,50]m、[-25,25]m、[-2.73,1.27]m的点云集合,YOLOv4-tiny输入的特征图尺寸高度和宽度H×W为608×608,对单帧点云进行区域划分,获得感兴趣区域Ω内的点云数据PΩ满足:
对PΩ中的任意一点Pi(xi,yi,zi)进行鸟瞰图的投影,投影到对应的像素点P'i(mi,ni)上:
式中,xmin、xmax分别为点云感兴趣区域Ω内x坐标的最小值和最大值;ymin、ymax分别为点云感兴趣区域Ω内y坐标的最小值和最大值。
根据PΩ内的点云数据计算每个像素的RGB 通道值,实现三维点云的点云鸟瞰图转换,计算过程为:
式中,N为一个立体栅格中三维点云的数量;g为网格单元的大小;Pg为大小为g的网络单元内点云数据矩阵;zmax为大小为g的网络单位内点云z坐标的最大值;I(Pg)为大小为g的网络单位内点云强度数据矩阵;R为映射到图像上的归一化密度,体现单元网格内的点云分布情况;G为点云归一化最大高度,体现单元网格内的点云高度情况;B为点云归一化最大强度,体现单元网格内的点云强度情况。
将R、G、B3个通道合并,生成点云RGB特征图,如图1所示。网络的输入特征图尺寸H×W×C为608×608×3。

图1 点云RGB特征图构建示意
3 目标检测网络
YOLO(You Only Look Once)网络的核心思想是将目标检测任务作为回归问题处理,以达到快速检测的目的。相较于YOLOv4 网络模型,YOLOv4-tiny 精简了特征提取网络,提高了检测速度。网络由输入(Input)、骨干网络(Backbone)、颈(Neck)和检测头(Head)组成。骨干网络主要用于特征提取,采用CSPDarknet53-tiny网络结构;颈主要用于特征融合,采用特征金字塔网络(Feature Pyramid Network,FPN)结构;检测头根据提取到的特征结果进行最后的预测。
对YOLOv4-tiny网络的改进体现在:添加车辆偏航角度预测分支,使其适用于车辆在点云鸟瞰图上的检测场景,实现车辆的准确定位;添加SPPF模块,融合点云鸟瞰图的全局特征和局部特征,提升网络的目标定位能力;引入双注意力机制,分别加强学习图像的通道信息和空间位置信息,获得更加丰富的特征,提升网络的目标检测能力;优化目标框位置损失函数,添加目标预测偏航角损失函数,提升网络的检测能力。整个网络的目标检测框架如图2所示,其中卷积块(CBL)由卷积层(Convolution)、批量归一化层(Batch Normalization)和LeakReLU 激活函数组成,CSP(Cross Stage Partial)模块为跨阶段局部模块,Concat为拼接操作,Upsample为下采样模块。
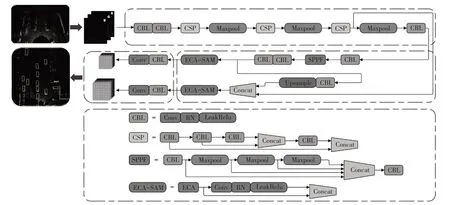
图2 改进YOLOv4-tiny的车辆点云鸟瞰图实时目标检测算法
3.1 目标检测框设计
采用点云RGB 特征图作为YOLOv4-tiny 网络输入,由于车辆在点云鸟瞰图中呈任意方向分布,故在YOLOv4-tiny的原有目标框基础上,添加车辆偏航角度预测分支。
根据实际的检测场景,设定一个目标检测框的参数为(bx,by,bw,bl,bφ),其中(bx,by)为点云鸟瞰图中目标车辆的中心点位置坐标,bw、bl分别为点云鸟瞰图中目标车辆的宽度和长度,bφ为点云鸟瞰图中目标车辆的偏航角:
式中,tx、ty、tw、tl分别为目标检测框中心点的横、纵坐标、宽度和长度的预测参数;tsin、tcos分别为目标检测框的偏航角的正弦值和余弦值的预测参数;cx、cy分别为当前网格与网格原点的距离;pw、pl分别为先验框的宽度和长度;σ()为Sigmoid函数,将预测参数限制在(0,1)范围内;arctan2()为四象限反正切函数。
相较于直接回归车辆的偏航角度,车辆目标偏航角通过正弦值和余弦值计算,一方面可以避免奇点,另一方面对模型泛化存在积极影响,检测框参数示意如图3所示。
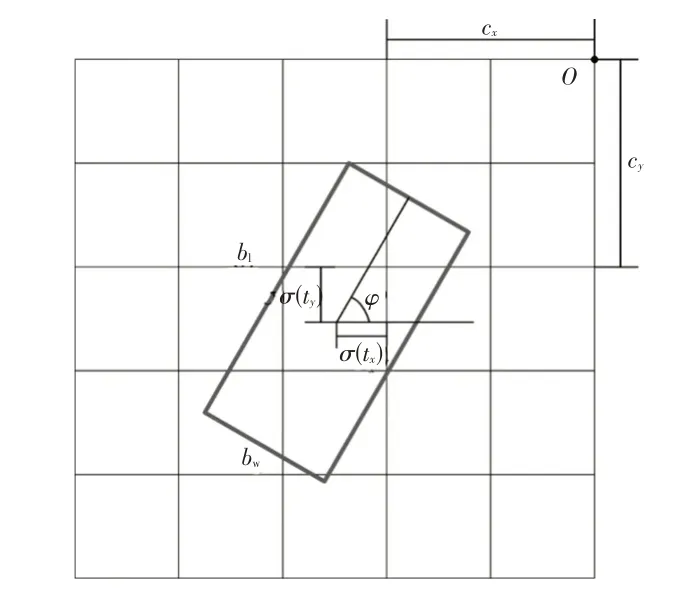
图3 目标检测框回归参数示意
3.2 SPPF结构
为了更好地融合点云鸟瞰图的全局特征和局部特征,学习多尺度特征信息,在YOLOv4-tiny 的骨干网络后引入空间金字塔池化(Spatial Pyramid Pooling,SPP)结构。SPP由He等[13]提出,目的是解决计算机视觉中输入图像尺寸不同造成图像失真的问题,如图4a 所示,YOLOv4 中的SPP 模块由3 个最大池化层(Maxpool)构成,池化层的大小分别为13×13、9×9 和5×5,步长为1。YOLOv4 通过SPP 模块增强了网络的感受野,更加充分地利用特征层的信息。如图4b 所示,本文在YOLOv4-tiny 的骨干网络后引入SPPF 模块,SPPF 也由3 个最大池化层构成,通过串行3个5×5大小的最大池化层实现多尺度融合,相较于SPP 模块,SPPF 模块在保证与SPP模块具有相同作用的同时,可实现更高的计算效率。
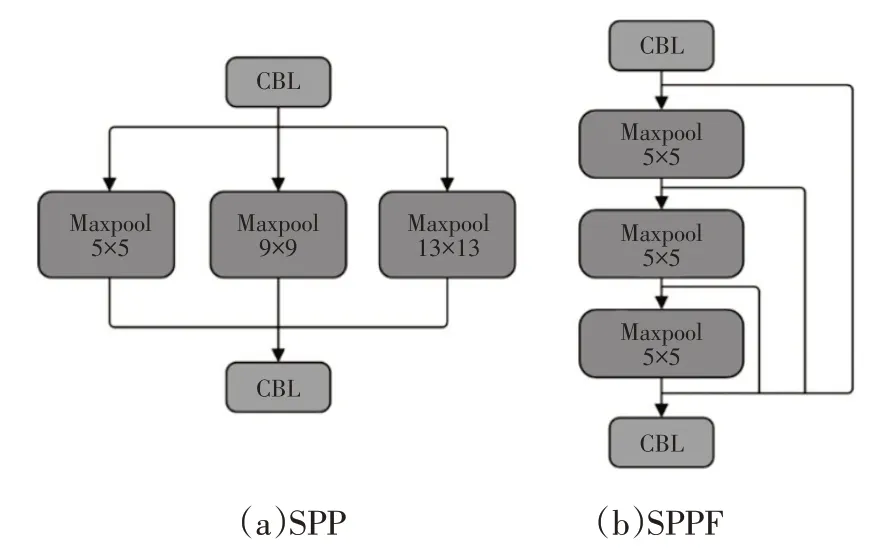
图4 空间金字塔池化结构
3.3 双注意力机制
相较于YOLOv4,YOLOv4-tiny 采用了更加轻量化的网络结构,虽然大幅提高了目标检测效率,但是目标检测精度存在一定程度降低。YOLOv4-tiny 有限的参数量限制了目标检测的效果,故在网络的主干部分添加双注意力机制,以充分利用有限的参数量,加强对通道和空间特征信息的关注。双注意力机制由高效通道注意力(Efficient Channel Attention,ECA)机制与空间注意力模块(Spartial Attention Module,SAM)串联构成。
ECA机制[14]在挤压和激励(Squeeze-and-Excitation,SE)注意力机制[15]的基础上改进而来,结构如图5所示,该机制避免降维,适当的跨通道交互对学习高性能和高效率的通道注意力较为重要。通过ECA机制可以加强特征通道的局部跨通道信息融合,根据全局特征信息对通道权重进行校准,使得网络更加关注重要的特征通道信息,提升网络检测的性能。
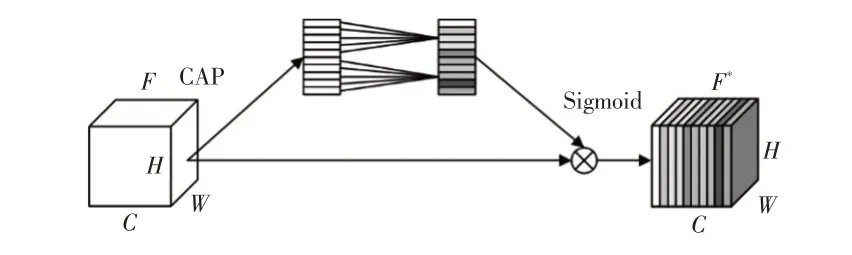
图5 ECA机制
如图5所示,ECA模块首先经过全局平均池化获得一个C×1×1的特征向量,接着用一个权值共享的一维卷积来学习特征通道中的权重,其中一维卷积核k为模块局部跨通道信息交互率,可随通道的变化动态调整:
式中,C为总通道数量;|a|odd为a最近的奇数;b=1;γ=2。
ECA 机制通过使网络更加关注特征通道信息来提升网络检测性能,在ECA 模块后加入点注意力机制。本文的点注意力机制是基于空间注意力机制[16]的简化,通过一个1×1 大小的卷积核与ECA 模块输出的特征图进行卷积,通过网络的前、后传播来自适应调整空间特征信息的权重,输出的最终特征为该权重特征层与原始特征的加权和,从而提高网络对重要空间特征信息的关注,减少对无关空间特征信息的关注,如图6所示。
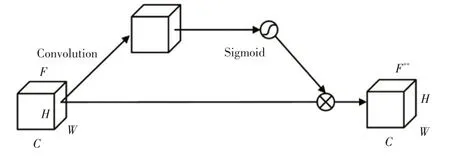
图6 简化的空间注意力机制
3.4 损失函数设计
设计的损失函数Ltol由目标框预测损失Lloc、置信度损失Lconf、分类损失Lcls和预测偏航角损失Lφ组成:
常见的目标框预测损失函数有GIoU(Generalized IOU)、DIoU(Distance-IoU)、CIoU(Complete-IoU)以及基于交并比(Intersection over Union,IoU)损失的统一幂化α-IoU[17],其中α-IoU对目标框的回归更加稳定,收敛速度更快。α-IoU损失函数的表达式为:
式中,sIoU为预测框与真实框的交并比;ρ()为欧式距离;b、bgt分别为预测框、真实框的中心点;c为能同时包含预测框和真实框的最小闭包区域的对角线长度;β为权重参数;υ为衡量长宽比相似性的参数;wgt/hgt、w/h分别为真实框、预测框的宽高比;α为相对梯度权重参数,当α>1时,可提升IoU较高的对象的损失和梯度加权,提高预测框的回归精度,且不会引入额外参数,也不会增加训练、推理时间。
分类损失和置信度损失函数采用交叉熵损失函数,有利于更新模型参数,同时可以加快模型的收敛。
只考虑正样本的目标预测偏航角损失,使用Smooth L1损失函数:
式中,x为误差。
同时在目标预测偏航角后加入惩罚项以保证偏航角的物理意义,目标偏航角损失函数表达式为:
式中,φ、分别为目标偏航角的真实值和预测值。
4 试验验证
4.1 数据集
采用KITTI数据集进行算法的性能评估。KITTI数据集包含相机图像、激光雷达点云数据以及对应的标签文件,其训练集有7 481 帧数据,测试集有7 518 帧数据。KITTI 数据集包含多个场景连续帧的数据,故直接划分训练集和验证集会包含相近帧的数据,无法直接通过验证集来评估模型的泛化能力,故按照采集时间分组随机划分数据。由于KITTI未公布测试集的标签文件,故本文将KITTI 训练集按照6∶2∶2 的比例划分为训练集、验证集和测试集;在KITTI 官方的鸟瞰图性能评估试验中,将KITTI 训练集随机拆分成3 712 帧训练集和3 769帧数据验证集,用于模型网络的训练和本地评估。
4.2 试验环境与参数
应用PyTorch深度学习框架和Python编程语言实现检测网络,试验环境为Ubuntu 16.04操作系统,训练的服务器配置为Intel Xeon Silver 4108 处理器、NVIDIA GTX 1080Ti 显卡、32 GB 运行内存。整个改进YOLOv4-tiny的目标检测网络采用表1的参数训练。
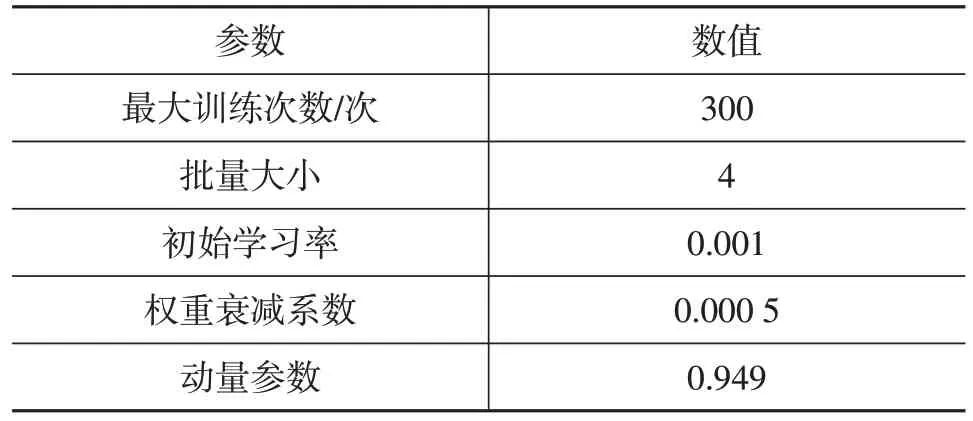
表1 网络参数
4.3 数据增强
KITTI 数据集中训练数据有限,本文通过数据增强增加训练数据量和环境噪声,提升网络的鲁棒性和泛化能力。数据增强具体的步骤为:收集所有真值目标框内的点云作为样本池;对每一帧投入训练的点云,随机抽取样本池中一定数量的样本,从而提高每一帧点云的正样本数量,同时进行碰撞测试,避免违反物理规律;对每一帧点云的目标边界框进行扩充,对增加的真值框进行随机旋转、平移和缩放,引入旋转和平移噪声,同时随机将样本池中的样本进行裁剪(Cutout)操作。通过以上数据增强操作,有效提高了网络训练的泛化能力,同时提高了网络整体的检测精度。
4.4 试验结果及分析
4.4.1 评估指标
网络模型的评价指标为准确率(Precision)、召回率(Recall)、平均精度(Average Precision)、算法耗时(Time)及检测帧率。其中,准确率P、召回率R和平均精度SAP的表达式为:
式中,nTP为模型正确预测的数量;nFP为预测错误检测的数量;nFN为未检测到的目标数量;SAP为PR 曲线与水平轴围成的面积。
4.4.2 网络改进对比
采用原始的YOLOv4-tiny网络对KITTI数据集进行训练和测试,模型在测试集上的平均精度达到93.98%;采用改进后的YOLOv4-tiny网络对KITTI数据集进行训练和测试,模型在测试集的平均精度达到96.92%,相较于原始网络提升了2.94百分点,如图7所示。
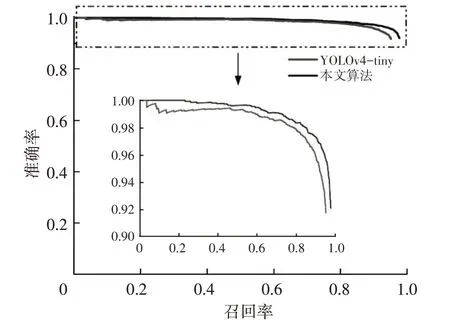
图7 模型改进前、后PR曲线对比
为了验证各改进模块的有效性,通过消融试验逐步验证本文基于YOLOv4-tiny 改进的网络结构改变所引起的性能的变化。表2所示为消融试验对比结果,由表2 可知:YOLOv3 网络和YOLOv4 网络的检测速率较低;YOLOv4-tiny 原网络的检测精度较低,检测速率较快;改进模型1 引入SPPF 模块,对应的AP@0.5(置信度阈值为0.5时的平均精度)提高了1.04百分点,表明空间金字塔池化可以通过增强网络的感受野,充分利用特征信息提升网络的检测精度;改进模型2只引入双注意力机制,对应的AP@0.5提高了1.33百分点,表明双注意力机制促进网络更加关注重要的通道特征信息和空间特征信息,降低对无关通道和空间特征信息的关注,对提升检测精度有积极影响;改进模型3 同时引入SPPF 模块和双注意力机制,对应的AP@0.5提高了2.07百分点;改进模型4 在改进模型3 的基础上,采用α-IoU 作为边界框的回归损失函数,相较于改进模型3,AP@0.5 提高了0.4 百分点,表明采用α-IoU 作为边界框回归损失函数能够提高网络的检测精度。本文模型在以上改进措施条件下,使用马赛克(Mosaic)数据增强进行训练,相较于使用前AP@0.5提高了0.47百分点。本文改进的模型在提升整体网络的检测精度的同时,仍能保证网络的检测速率达到100 帧/s。

表2 消融试验
4.4.3 不同网络对比验证
为了将本文网络模型与其他使用鸟瞰图作为输入的网络模型进行比较,使用KITTI 的官方性能评价标准,设置IoU阈值为0.7进行测试。KITTI数据集根据检测目标的最小边界框高度、遮挡程度和最大截断程度,将检测目标按照简单、中等、困难3 个等级进行划分。由于KITTI官网的测试集未公布标注文件,故不同网络对比试验为采用KITTI 鸟瞰图验证集在不同评价标准下的性能比较,检测结果如表3和图8所示。

表3 KITTI数据集下不同网络性能比较
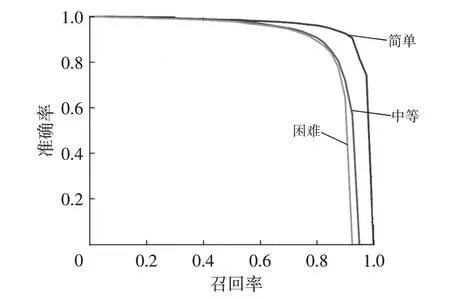
图8 KITTI验证集不同目标难度下的PR曲线
由表3 和图8 可知,本文提出的车辆目标检测网络的算法耗时为0.01 s,检测速度可达到100 帧/s。相较于BirdNet、MODet、GridNet-3D 等使用点云鸟瞰图信息的网络,本文在检测精度上具有优势,说明改进后的YOLOv4-tiny 的网络能够较好地提取车辆点云的特征信息;相较于MV3D、F-PointNet(Frustum PointNet)、ContFusion 等使用点云鸟瞰图信息和图像信息的网络,本文在检测速度上具有明显优势,说明将三维点云转换成点云RGB特征图以及采用轻量化的单阶段目标检测网络能够有效提高检测速度。以KITTI 鸟瞰图数据集中等难度下的平均精度和帧速率作为评价指标,本文算法在检测精度和检测速度上具有优势,说明改进的YOLOv4-tiny 网络能够更好地提取点云RGB 特征图的特征信息,如图9所示。同时,将本文算法在KITTI官方测试集上进行检测,其部分检测结果如图10所示。
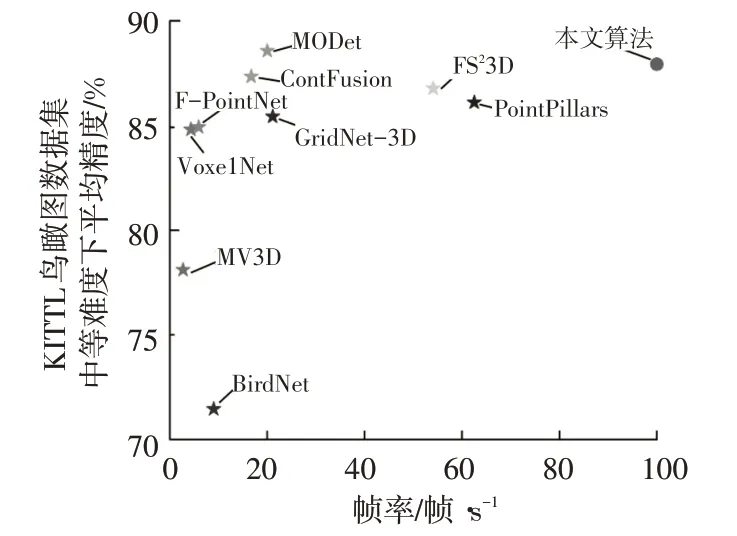
图9 不同网络下的性能比较

图10 在KITTI测试集上的部分检测结果
5 结束语
针对基于三维点云的车辆检测算法存在实时性差的问题,本文提出基于点云鸟瞰图的实时车辆目标检测算法,该算法通过将三维点云进行鸟瞰图投影,根据点云的高度、强度和密度信息制作点云RGB特征图,在保证车辆的特征信息的同时,有效降低了原始点云的数据量;其次,在YOLOv4-tiny网络上进行改进优化,添加车辆偏航角度预测分支来实现车辆的准确定位,引入空间金字塔池化结构、双注意力机制和采用α-IoU边界框回归损失函数来提高车辆目标的检测精度。试验结果表明:基于YOLOv4-tiny网络的改进优化措施相较于原网络具有更高的检测精度;与其他网络相比较,本文网络在KITTI数据集下具有更高的检测速度,达到100 帧/s,能够满足目标检测的实时性要求。
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
数学年刊A辑(中文版)(2019年3期)2019-10-08
电子制作(2018年11期)2018-08-04
小太阳画报(2018年3期)2018-05-14
北京航空航天大学学报(2017年6期)2017-11-23
阅读与作文(小学低年级版)(2016年12期)2016-12-22
浙江大学学报(工学版)(2016年10期)2016-06-05
测绘科学与工程(2016年5期)2016-04-17
汽车文摘(2015年11期)2015-12-02
电子设计工程(2015年3期)2015-02-27
