
生成式人工智能技术进展及其在自动驾驶领域的应用与展望
2023-09-26 03:45夏以柠
汽车技术 2023年9期
夏以柠
(北京师范大学,北京 100875)
主题词:生成式人工智能 大模型 自动驾驶
1 前言
现代人工智能技术的快速发展受益于海量标注数据的生产和计算能力的提升。其以深度学习作为核心技术,深度学习[1]的概念最早在机器学习领域提出,后推广至人工神经网络技术领域。Transformer模型[2]的提出是现代人工智能技术的里程碑式节点,该模型能够保证充足数据分辨率,同时实现高精度数据拟合,广泛应用于生成式人工智能模型。
生成式人工智能技术通常包括一个基于大规模数据训练的监督网络模型(如Transformer 模型)和一个生成器模型[3],前者的主要功能是实现从任意类型的输入到潜在高维数据空间的映射,后者以无监督学习、半监督学习或监督学习的方式进行优化,并通过启发式的行为以固定的方法论实现内容的生成。
自动驾驶技术是近年来备受关注的汽车技术发展方向,面向复杂的场景,要求车辆实现对环境的正确理解,同时做出最优的决策。该技术发展的初期,以激光雷达和高精地图作为主要输入,视觉和专家系统为辅助手段。随着人工智能技术在智能驾驶领域的应用,Waymo、Cruise、百度等公司通过模型完成动态障碍物的实时检测,配合高精地图提供的道路结构、车道线和交通标志等静态信息,实现更有效的智能驾驶。
目前,大模型逐步突破技术壁垒,成为自动驾驶感知的主流范式。2021 年,特斯拉提出的“BEV+Transformer”的技术方案,首次引入重感知、轻地图的自动驾驶解决方案[4]。2022年,特斯拉再次提出基于占用网络(Occupancy Network)的技术方案,开启大模型在自动驾驶领域应用的新篇章[5]。此外,基于生成式人工智能技术,令长尾问题的场景数据可以通过模型主动生成,解决自动驾驶面临的长尾问题,提升算法的可靠性,为自动驾驶的升级优化提供保障。
2 生成式人工智能技术
生成式人工智能模型的输入和输出数据主要包括文本、图像、三维结构、视频、音频和代码等。根据数据的映射关系,模型可分为7类,如图1所示。
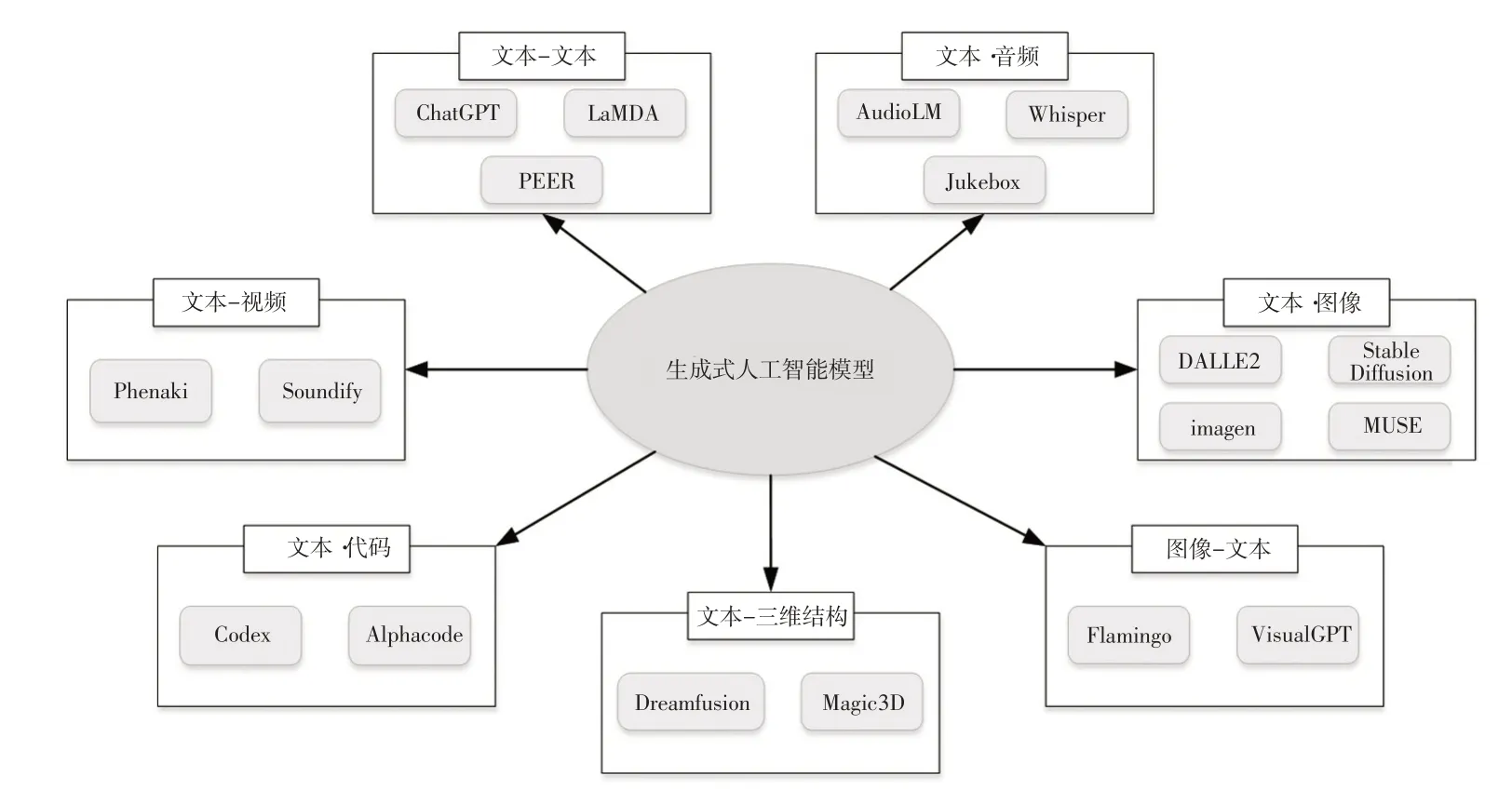
图1 生成式人工智能技术分类及代表性模型
生成式人工智能技术可以实现多模态数据间的相互映射,根据用户需求输出内容。其中,文本—文本、文本—图像、本文—视频和图像—文本4 类模型是能够为自动驾驶领域带来颠覆性技术革新的生成式模型技术。
文本—文本模型以文本数据为输入,生成新的文本数据,是常见序列化数据模型之一,多应用于自然语言处理技术,如语言翻译、问答任务系统等。
文本—图像模型以具有提示性的文本数据作为输入,输出满足对应需求的真实图像数据。该模型可实现不同属性、不同风格信息的输出。OpenAI 提出的DALLE2 模型[6]、Drawbench 公司开源Imagen 模型[7]及由慕尼黑LMU CompVis 小组开发的Stable Diffusion[8]和Muse[9]均为具有代表性的模型。
文本—视频模型通过文本数据生成连续的图像序列。Google开源的Phenaki[10]与Runway开源的Soundify[11]属于此类模型。
图像—文本模型可以获得描述图像的文本,是文本—图像的逆映射。Deepmind 创建的视觉语言模型Flamingo[12]是其代表性模型之一,通过小样本学习策略实现,具有灵活性强、可执行多模态任务等优势。该模型利用2个互补的模型实现:分析视觉场景的视觉模型与执行基本推理形式的大型语言模型。通过无缝摄取图像或视频交织的文本标记序列,转换为文本数据作为输出。OpenAI提出的图像字幕模型VisualGPT[13]是现阶段最优秀的图像—文本模型之一,其通过预训练语言模型GPT-2 实现。为了弥合不同模态之间的语义差距,特别设计了具有不饱和门控功能的编码器-解码器注意力机制。该模型的最大优势在于,它无需其他图像—文本模型的大规模数据,具备小样本学习能力。
3 生成式人工智能与自动驾驶技术
随着生成式人工智能技术的发展,基于该技术衍生的大模型在自动驾驶领域受到广泛关注[14]。基于生成式人工智能的大模型在自动驾驶中规控模型的应用将成为未来产业新趋势[15]。Waymo 通过生成式人工智能技术构建世界模型,通过大模型实现自动驾驶领域的整体功能集成[16]。同时,该公司提出基于自动驾驶模型与自然语言处理模型结合的技术方案,通过模型以可理解、人机互动的流程方式,达成清晰有效的沟通,进一步增强其结果的可解释性。
3.1 面向自动驾驶的数据闭环与自动标注
由数据采集、数据挖掘、数据标注和模型训练环节组成的数据闭环系统是自动驾驶厂商必须具备的基础技术能力。当下,随着高速智能导航辅助驾驶、城市导航辅助驾驶以及城市智慧领航功能等技术的不断推进,自动驾驶公司或整车制造商数据量逐年增长,甚至达到拍字节(PB)级别。与此同时,数据生成的速度较快(以dSPACE 公司的数据生产为例,4K 800 万像素的摄像头、激光雷达、毫米波雷达等传感器同时工作,每秒的数据生产量为40 GB),使用方的数据处理能力面临极大的考验。由此可见,如何实现数据利用的最大化是提升自动驾驶方案稳定性的关键问题之一。
3.1.1 数据采集与挖掘技术
为保证自动驾驶场景下采集数据的质量,提升驾驶模型性能,算法采用特定的触发机制实现数据的收集与上传。其中,触发机制包括人工干预自动驾驶、特殊场景(近距离跟车、并线以及明显的光照变化等)。特斯拉公司在2022年AI DAY上表示其拥有221种触发机制[17]。
为了能以最精简规模的数据集对模型进行训练,有效的数据挖掘技术不可忽视,其核心目的是从收集的海量数据中提取有效数据,过滤无效数据。传统的模型采用基于标签的方式实现,仅能实现固定类别的分辨,缺少更深层次的特征提取。基于生成式人工智能技术,采用图像—文本模型即可实现,用模型生成的描述检索图像的有效特征,实现更高效的数据挖掘。基于现有人工智能技术,当前数据挖掘方案逐渐以大模型为主。目前,国内外主要汽车公司和自动驾驶公司等均致力于开发基于大模型的数据挖掘技术。
3.1.2 数据标注技术
传统的数据标注技术仍以人工标注为主,人工成本高、耗时长,速度远远低于原始数据的生产速度,数据应用面临瓶颈。此外,由于标注人员对标注内容的理解不一致,存在标注数据可靠性问题,因此数据的二次检验仍需要较大的工作量。
生成式模型的显著优势在于,主动理解视频内容进行自动打标签,并形成产品化管理,提取高价值场景并自动筛选。与人工标注的方法相比,基于生成式模型的标注方法速度更快、精度及标注结果一致性更高,能够实现更加全面的标注。
小鹏汽车推出的全自动标注大模型的执行效率相比于人工标注提升约45 000 倍,即大约16.7 天可实现2 000 人/年的标注工作量[18]。毫末智行科技有限公司(以下简称毫末智行)提出的视觉自监督大模型[19]可实现100%的4D Clip 自动标注,降低约98%的标注成本。商汤科技绝影在自动驾驶产品的感知任务开发过程中的标注均基于大模型实现[20],相比人工标注的方式,相同数量样本的标注周期和成本都可以缩减90%以上。
3.2 面向自动驾驶的一体化大模型
现阶段,基于人工智能的自动驾驶方案多采用模块化设计思路,即感知、预测、规划等子系统独立实现功能。尽管模块化能够简化研发人员的工作流程,提供高效的问题回溯、调试及更新接口,但各子模块间的信息仍缺少有效传递,无法保持模块之间的优化通道。对此,开发面向自动驾驶系统的多任务一体化大模型是提升整体算法性能的有效方案。
目前,学术界和工业界均对一体化多任务大模型的方案进行了深入研究。英伟达(NVIDIA)公司在2016年即提出了基于端到端模型的自动驾驶系统,Uber 也在该领域发表了较多的学术研究成果[21-22]。为了使自动驾驶车辆通过平台“理解世界”,英国Wayve公司也创立并发表其端到端的自动驾驶方案。同时,特斯拉公司“FSD META V12”版本系统将采用端到端的自动驾驶模型。
商汤科技与上海人工智能实验室、武汉大学联合提出首个集感知决策一体化的端到端自动驾驶大模型UniAD[23],并指出限制自动驾驶模型性能的根本原因在于任务的独立拆解,无法保证丰富的高维信息的提取,由此提出了以最终任务为导向、多模块联合优化的端到端自动驾驶方案。UniAD 充分发挥数据驱动的系统性优势,达到感知、预测、决策多个任务结合的最优解,将生成式人工智能大模型充分融入任务的场景理解。
3.3 面向自动驾驶模型的可解释性问题
自动驾驶模型的可解释性是提升其性能与优化迭代速度的重要前提。深度学习技术的最大痛点之一是其过程完全隐藏于“黑匣子”中,缺少明确的可解释性,即使用方无法根据深度学习模型输出的结果逆向推导其原理。
基于生成式人工智能技术的自动驾驶模型在其理解及决策过程中,可以某种方式输出(例如文本)理解过程及决策原因,即结果误判时,可快速地查找对应的原因。受益于启发式的自监督强化学习技术,自动驾驶模型可进一步逆向对自身进行优化和调整,实现模型的自动迭代。
3.4 面向自动驾驶场景的生成模型
长尾问题包括各种零碎的场景、极端情况和无法预测的人类行为,是自动驾驶系统面临的难题之一[24]。该领域现有的人工智能技术大多是用人工采集标注的数据集训练。由于实际数据为复杂场景,人工标注通常无法包含全部场景的数据信息支持,从而降低模型的鲁棒性。
通常,自动驾驶模型发现车辆行为存在边界情况时,需要补全额外的数据,对模型参数进行优化。实际上,该方法一定程度上令长尾问题的场景复现难度过大,无法保证数据采集的有效性,导致采集效率低下。同样地,虽然传统的3D建模可实现虚拟场景仿真,但由于建模机制不够完善,无法保证生成场景数据的质量,进而使生成的场景数据无法有效支持模型优化。
通过生成式人工智能技术,如文本—图像,文本—视频生成模型,可通过对其模型的优化与训练实现近似于真实场景的仿真数据的生成[25]。同时,上述生成式人工智能技术可通过其强大的数据映射能力实现场景数据的快速变换,为自动驾驶模型的快速优化与迭代提供最基本的前提保障。
4 面向大模型的云端算力与芯片架构
同早期人工智能技术相比,基于现代生成式人工智能的大模型的主要区别在于模型参数和数据的提取方式。其中,模型参数的大幅增长提高了对云端算力的需求,数据相关性提取方式的改变为计算芯片架构提供了新的设计导向。
4.1 面向大模型的算力需求
大模型技术已经逐步应用于各大汽车制造商和自动驾驶公司的产业化项目[26]。特斯拉2022年AI DAY表示训练其模型需要14 亿帧图像数据。Momenta 公司提出要实现L4 级自动驾驶的产业化[27],自动驾驶系统达到人类的安全水平甚至比人类安全水平高一个数量级,至少需要千亿公里的数据训练、测试与验证。
为使模型能够在海量数据中实现快速训练,提升计算资源成为各大汽车厂商与自动驾驶公司亟需解决的首要问题[28]。基础设施建设方面,特斯拉在2021 年和2022 年分别拥有约1 万块和1.4 万块图形处理器(Graphics Processing Unit,GPU),预计2024 年将拥有等效10 万块NVIDIA A100 GPU 的算力资源。2022 年8月,小鹏汽车成立自动驾驶AI 智算中心“扶摇”,具备60 亿亿浮点运算能力。此外,国内其他公司包括吉利汽车、毫末智行、智己汽车、百度和商汤科技等也都完成了算力的积累,如表1所示。
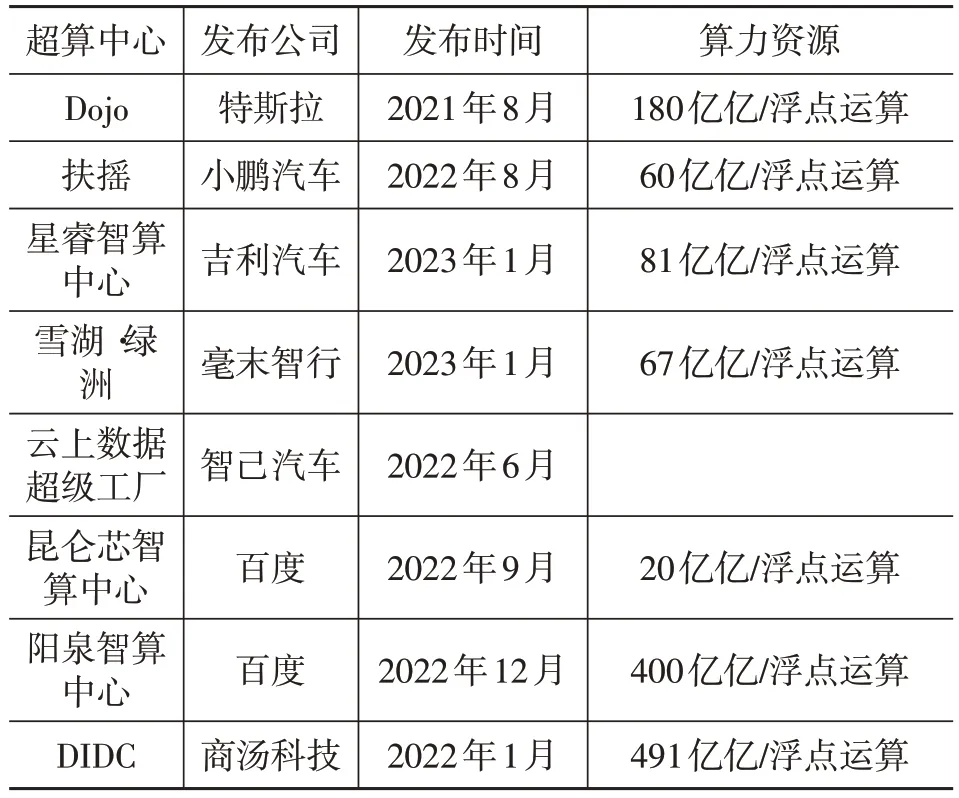
表1 自动驾驶公司算力对比
4.2 面向大模型的芯片架构
基于现代生成式人工智能技术的大模型需要大量的计算资源,如何实现海量计算资源的最大化利用是汽车制造商、自动驾驶公司和芯片公司面临的另一难题。前文提出,大模型多是基于Transformer 实现的,内部采用的是记忆力机制单元模块。不同于基于传统神经网络的人工智能模型(如卷积神经网络、循环神经网络),Transformer 在提取数据之间的相关性过程中存在更多的访存密集型算子。因此,为提升大模型的运行效率,芯片的架构需进行针对性改进:
a.运算精度要求。Transformer 的建模是通过不断加权映射实现,因此,对芯片的运算精度存在一定的要求。现阶段,面向人工智能的主流芯片大多采用INT8即整型精度算力,而基于Transformer的大模型需要在浮点运算的芯片平台上运行,才可取得较高的精度结果。目前,特斯拉已经完成“D1”芯片的自研,并构建超算平台解决自动驾驶大模型的训练与优化。
b.运算算子要求。访存密集是大模型的运算特点,需要针对性地设计访存密集型算子,解决芯片的计算效率问题,从而实现稳定性高、可移植性高、并行化程度高、计算精度高的高效运算算子。
5 大模型自动驾驶技术的未来展望
5.1 多任务大模型与自动驾驶
受ChatGPT的启发,毫末智行开发面向自动驾驶的生成式大模型DriveGPT[29],采用无监督学习进行初始模型的训练,强化学习实现模型优化。通过输入感知级的激励数据(如障碍物信息、道路环境以及关键交通要素),DriveGPT 能够完成障碍物预测、决策规划控制以及决策逻辑链的输出等任务。目前,生成式大模型已经在自动驾驶的部分领域取得了巨大的创新性成果,构建多任务、一体化的大模型将是面向自动驾驶领域的重大技术创新。
5.2 车端模型的功能解耦
至今,大模型仍受到海量模型参数与计算资源的限制,由于其运行均在云端实现,无法完成车端的独立运行。如何对大模型进行功能解耦,实现车端的运行成为未来要攻克的难题。以知识蒸馏[30]的方式,完成大模型对车端小模型进行优化是解决上述问题的有效手段之一,亦是大模型到车端功能落地的有效方案。
5.3 多任务生成式大模型
理论上,基于多任务生成式人工智能模型可同时实现仿真数据生成、标注、感知、预测和决策多种功能。UniAD模型的成功表明,多任务联合优化能够实现多源数据相关性的有效提取并提升整体性能。因此,如何通过多任务生成式大模型实现高效数据闭环、模块化功能解耦等技术将是推动自动驾驶技术走向成熟的关键环节。
6 结束语
生成式人工智能技术在文本、图像等多个领域均取得了丰富的研究成果,基于生成式人工智能的大模型技术也为自动驾驶领域提供了新的解决方案。未来,随着研究人员对技术研究的深入以及硬件水平的提升,基于轻量化平台的应用将进一步拓展技术的应用范围,扩展其应用量产落地能力。
猜你喜欢
学生天地(2020年5期)2020-08-25
制造技术与机床(2019年10期)2019-10-26
商界(2019年12期)2019-01-03
电子制作(2018年18期)2018-11-14
IT经理世界(2018年20期)2018-10-24
电子测试(2018年10期)2018-06-26
小康(2017年16期)2017-06-07
汽车博览(2016年9期)2016-10-18
南风窗(2016年19期)2016-09-21
小学教学参考(2015年20期)2016-01-15
