
面向存算分离架构的混合粒度缓存策略
2023-09-22 01:09梅文娟
华东师范大学学报(自然科学版) 2023年5期
梅文娟, 蔡 鹏
(华东师范大学 数据科学与工程学院, 上海 200062)
0 引 言
随着信息时代数据量的增加, 数据库管理系统正逐渐从本地部署转向云端[1-5], 以实现更高的弹性和更低的成本. 现代云数据库采用存储和计算分离(存算分离)架构, 将计算和存储分离到通过网络连接的不同服务器层中, 简化了资源配置并实现了独立的资源扩展. 存储层提供可靠的持久化存储服务,如Amazon Web Service (AWS) 简单云存储 (Simple Storage Service, S3)[6]、Azure Blob 存储[7]、阿里云对象存储服务(object storage service, OSS)[8]和Google Cloud Storage[9]等对象存储, 以及HDFS[10](hadoop distributed file system)类的分布式文件系统是当下云数据库存储层的可选方案. 计算层则由多个计算节点组成, 负责数据库的解析、查询、计算等过程. 然而, 面对存算分离架构, 研究者必须重新考虑分布式数据库管理系统的一个基本原则: 将计算移动到数据而不是将数据移动到计算. 传统的Share-Nothing 体现了这一原则, 并将数据存储在本地磁盘上; 而当前的存算分离架构中的网络通常具有比本地磁盘更低的带宽, 从而可能成为性能瓶颈. 缓存是减轻网络瓶颈的一个重要的方向, 其主要思想是将热数据保留在计算层, 从而减少计算层和存储层之间传输的数据量, 如Snowflake[11]和带有 Alluxio 缓存服务的Presto[12]、Redshift[13]层在 Redshift Spectrum[14]中用户可控制内容的缓存.
作为存储层的分布式文件系统, 如HDFS[10]; 或是对象存储, 如Amazon 的S3[6], 其针对小文件的读写效率都很低. 由于文件系统元数据的管理和开销, 处理大量小文件是分布式文件系统面临的挑战,这也被描述为小文件问题[15]. 在基于MergeTree 的数据库, 如 ClickHouse 中, 会产生很多的小文件;ClickHouse 在插入、删除和数据合并的时候都会存在大量读写或修改小文件的操作. 这些小文件及小文件操作对存储层非常不友好, 会大大降低系统的性能.
MergeTree 引擎在合并数据时, 会将多个小文件合并成一个大文件, 由于数据的分布情况不均匀,导致某些分区的文件数过多, 从而产生大量的小文件. S3 对小文件修改和访问的性能并不好.ClickHouse 本身已经实现了从远程存储端到S3 的缓存, 并在系统初始化时定义了缓存段的大小, 但是其固定缓存段大小时, 并没有考虑缓存粒度与内存是否适配; 除此之外, 缓存段大小的固定还会导致缓存空间的浪费. 因为缓冲区缓存某一段连续的数据往往是因为其中的一小部分为热数据, 而剩下的大部分缓冲区的缓存空间被大量不常用的冷数据占用, 故不能有效地达到提高数据访问效率的目的.
本文提出了一种混合粒度缓存管理方案, 简称为HG-Buffer (hybrid granularity buffer). 其关键思想是将SSD 缓冲区组织成对象(object)和块(block)这两个粒度的缓存: 对象是数据存储到对象存储中的粒度; 块则是数据在本地磁盘上存储的粒度. 同时本文增了一个新度量—热块率, 来自适应地选择数据缓存的位置, 即根据该度量量化页面中热块的比率, 从而判断将数据是存储在基于对象的缓冲区(对象缓冲区, Object Buffer), 还是存储在基于块的缓冲区(块缓冲区, Block Buffer). 综上所述,本文有以下几方面的贡献.
(1) HG-Buffe 使用2 个基于对象的缓冲区和一个基于块的缓冲区来组织缓冲池, 可以适应访问模式, 并根据热块率来选择Object Buffer 或 Block Buffer. 基于此机制, HG-Buffer 基于有限的SSD 空间可容纳更多的热数据, 从而提高了命中率和整体的性能.
(2) Object Buffer 里的热块被移动到Block Buffer 之后, 会失去局部性的优点, 数据访问的速度亦会降低. 与此同时, 如果一个被驱逐的对象是一个热块占比很高的对象, 将其中的热块移动到Block Buffer 会有大量的迁移成本. 为了解决这个问题, HG-Buffer 引入了一个热块率的度量来量化一个对象的热块占比, 从而决定数据是存储在Block Buffer 还是存储在Object Buffer.
(3) 给出了HG-Buffer 的详细架构和详细算法, 包括读操作、删除操作、更新操作的相关算法.
(4) 对几种不同的工作负载进行了实验, 以评估 HG-Buffer 的性能, 并将其与SSD 直接二级缓存、SSD 扩展内存等传统缓存方案进行了对比. 结果表明, HG-Buffer 可以显著提高数据读写的效率.此外, 多变的SSD 缓存空间大小实验亦表明了 HG-Buffer 的鲁棒性.
1 相关工作
1.1 存算分离背景以及缓存方法
随着互联网的发展, 数据量不断增加, 数据分析的要求也日益增加. 与此同时, 网络传输的速度也在不断提高. 为了有更好的扩展性和稳定性, 数据库管理系统供应商正在向云端转移. 云端数据库系统受益于弹性、独立扩展计算和存储的能力、增强的吞吐量和规模经济等特性[3], 将架构分成存储层和计算层: 计算层是一个个无状态的节点, 其多个节点构成一个计算组, 系统通过对计算组中节点的增减来实现计算层的扩缩容; 对于存储层而言, 云端数据库系统越来越多地采用AWS 简单云存储(S3)[6,16]、Azure Blob 存储[7]、阿里云对象存储服务(OSS)[8]和谷歌云存储[9]等对象存储作为其底层存储解决方案. 虽然云端数据库系统也可以采用无共享架构, 但许多云原生数据库选择分解计算层和存储层, 这带来了成本更低、容错更简单和硬件利用率更高的好处. 许多云原生数据库最近都遵循存算分离架构进行开发, 包括SparkSQL[17]、Aurora[18-19]、Redshift Spectrum[14]、Athena[20]、Presto[12]、Hive[3]、Snowflake[11]和Vertica EON[21-22]模式. 虽然存储计算分离架构听起来与共享磁盘架构相似, 但它们实际上存在显著差异. 在共享磁盘架构中, 磁盘通常是集中的, 因此很难横向扩展系统. 相比之下, 存算分离架构像计算层一样水平扩展存储层, 且还在存储层提供非平凡的计算, 而磁盘只是共享磁盘架构中的被动存储设备.
由于较高的网络延迟和较低带宽远程存储, 在计算节点缓存数据是存算分离缓存系统中不可或缺的一步. 虽然本地存储是有限的, 但是它的访问速度比共享存储更快, 通过热数据保存在计算层本地存储如SSD 中, 可以加速数据查询访问的速度. 典型的例子包括Alluxio[12]分析加速器、 Databricks Delta 缓存[1], 以及Snowflake 缓存层[11].
Alluxio 提供分布式共享缓存服务, 其分层存储可以同时利用内存和磁盘 (SSD/HDD (hard disk drive)), 通过自动优化数据放置策略, 来提高内存和磁盘的性能和可靠性. 与此同时, 它还维护了缓存一致性. Alluxio 的缓存对用户是透明的, 它通过将数据存储在计算节点和远程存储的同一位置进行缓存数据的映射管理. Alluxio 的热数据可以保存多个副本, 对多次访问的热数据可以并行I/O(input/output), 从而提高访问效率, 其副本的数量由集群活动动态决定.
Snowflake[11]对数据文件名进行一致性哈希, 将客户的输入文件集分配给节点, 一个文件只能缓存在其散列的节点上. Snowflake 使用传统的两层机制, 每个节点实现一个本地LRU (least recently used)策略用于从本地内存到本地SSD 的逐出, 以及一个独立的LRU 策略用于从本地SSD 到远程持久数据存储的逐出. Snowflake 缓存的数据包括计算结果和可查询的数据, 其中计算结果的缓存包括过去24 h 内执行的每个查询的结果, 这些查询结果可跨虚拟计算组进行使用. 因此, 在数据未被修改的前提下, 返回给一个用户的查询结果可用于系统上执行相同查询的任何其他用户. 而SQL 查询使用的缓存数据则是在每次查询时, 从远程存储中检索数据, 并将其缓存在SSD 和内存中.
Databricks 的 I/O[1]缓存通过使用中间数据格式, 在节点的本地存储中创建远程文件的副本来加速数据读取. 每当必须从远程位置获取文件时, 数据都会自动缓存到计算节点, 然后在计算节点执行相同数据的连续读取, 从而显著提高读取速度. Databricks 的 delta 自动维护文件的一致性, 检测底层数据文件的更改并缓存.
Crystal[23]是微软提出的缓存组件, 它认为不同的数据库管理系统都有自己的缓存实现和不同的数据格式, 在实现上具有非常大的重复性. 为了解决这个问题, Crystal 按照大多数数据库系统都支持的API (application programming interface), 为各类系统实现了一个公共的缓存服务, 不仅支持热数据的缓存, 还会缓存查询的中间结果, 可以满足大多数系统的要求.
除了在计算节点缓存热数据, 利用存储层的计算能力将部分计算下推也是缓解存算分离架构下网络瓶颈的方式之一. FlexPushdownDB[24]将计算下推和缓存相结合, 在查询执行的阶段, 对执行计划中的算子进行评估, 以降低查询的响应延迟为目标, 并采用加权LFU (least frequently used)的方式来决定缓存哪些数据.
1.2 ClickHouse 和S3 的存算分离方案
ClickHouse[25]是一个OLAP (online analytical processing)系统列存数据库, 可以快速地对数据进行实时或批量的分析. 其最典型的特征是MergeTree 引擎. MergeTree 引擎是ClickHouse 内部存储引擎之一, 专门用于处理大规模数据的插入、更新和查询. 它基于列式存储和合并树 (MergeTree) 的概念, 提供了高性能和可扩展的数据处理能力. 其主要特点如下.
(1) 列式存储结构: 将同一列的数据存储在一起, 可以大大提高分析查询中的效率, 使ClickHouse适用于大规模的聚合查询和复杂的分析任务.
(2) 分区与排序: 将数据按照指定的分区键和排序键进行划分和排序. 分区键用于将数据水平分割成多个独立的分区; 排序键用于在每个分区内按特定顺序存储数据. 这种方式可以提高查询性能和过滤效果.
(3) 合并: MergeTree 引擎使用合并操作来优化数据的存储和查询, 将相邻的分区按照一定的策略进行合并, 从而减少了分区数量, 提高了查询性能. 合并操作是通过后台线程异步执行的, 不会对正在进行的查询产生影响.
(4) 支持数据更新: MergeTree 引擎支持数据的插入、更新和删除等操作. 因此, 在MergeTree 引擎中, 数据的更新并不会直接修改原始数据, 而是通过增加新的数据版本来处理更新操作. 这种增量数据更新的方式可以有效地处理大规模数据的更新需求.
ClickHouse 和S3 的存算分离方案是一种数据存储和计算分离的架构, 旨在提高大规模数据处理的性能和效率. 这种方案基于ClickHouse 的分布式计算能力和S3 的高可靠性和低成本存储. 在这种架构下, 数据首先在S3 中进行持久性存储; 当系统需要这些数据进行查询或分析时, ClickHouse 通过与S3 进行交互, 将数据加载到ClickHouse 集群中进行计算. 具体为, ClickHouse 集群通过连接到S3 的接口, 将需要处理的数据从S3 中读取到内存中进行计算. 首先, 由于数据存储和计算被分离开来, 因此, 可以在不影响存储的情况下, 灵活地对计算集群进行扩展或缩小; 其次, S3 提供了高可靠性和低成本的存储, 因此, 可以节约存储成本; 最后, 结合ClickHouse 的高性能和分布式计算能力, 可以快速地对大规模数据进行查询和分析.
MergeTree 引擎在合并数据时, 会将多个小文件合并成一个大文件. 但是在某些情况下, 由于数据的分布不均匀, 会导致某些分区的文件数过多, 从而产生大量的小文件. ClickHouse 和S3 的存算分离方案下, 数据都存放在S3 中, 但是S3 对小文件的修改和访问的性能并不友好, 所以S3 作为对象存储访问的性能具有很大的局限性. 图1 展现了当前ClickHouse 中MergeTree 引擎与S3 结合的存算方案的数据映射关系: 每一次插入数据, MergeTree 引擎会生成一个文件, 这个文件被称为part 文件; 每一个part 文件中的数据文件都被存储到了S3; 每个数据文件包含多个以块(block)为单位的数据,ClickHouse 存储数据文件到S3. 磁盘中的数据文件中不再存放数据本身, 而是存放其与S3 的映射关系, 如图1 中的part 数据内容. 其中, ttdfdsfdd 字符串就是当前数据文件对应的S3 的文件的键, 从上往下第一行的数字(32)表示当前元数据的版本, 第二行数字代表数据文件所包含的对象文件的数量和总大小(1, 30), 第三行及以下的每一行数字代表每个对象文件的大小以及对象文件的键. 当一个ClickHouse 需要某一个块数据的时候, ClickHouse 首先通过访问S3 从而获取到对应的数据文件, 然后将数据文件缓存到本地磁盘, 再从数据文件中获取对应的块数据. 整个过程增加了将数据文件传输到计算节点的网络开销, 同时本地有限的SSD 缓存空间也被不需要的数据文件浪费.

图1 ClickHouse 和S3 的数据映射关系Fig. 1 Mapping relationship between ClickHouse and S3 data
ClickHouse 可以设置本地文件系统上的目录来为远程文件系统保存指定大小的缓存, 如cache_path/012/0123456789abcdef0123456789abcdef/111111_last. 其中, cache_path 是指缓存在本地系统上的位置; 0123456789abcdef0123456789abcdef 是远程文件系统上文件路径; 012 是文件路径的哈希值的前3 个十六进制字母; 111111 是文件中缓存段的起始偏移量 (十进制); last 用于标记缓存段,是系统读取的目标文件中的结束. ClickHouse 将整个条目作为一个缓存粒度, 缓存管理器使用简单的LRU 进行热数据的识别和替换. 因此, 大的缓存段被缓存并作为一个整体被逐出. 简而言之, 虽然ClickHouse 本身已经实现了远程存储端到S3 的缓存, 但是ClickHouse 也存在一些问题: ClickHouse会在系统初始化的时候定义缓存段的大小, 且这个大小是固定的, 并没有考虑缓存粒度与内存是否适配的问题; ClickHouse 本身基于MergeTree 引擎, 其存储层的文件在不断地修改和合并, 文件大小多变, 所以固定大小的缓存粒度会造成其性能的下降; 除此之外, 因需要某一部分的数据, 而缓存一整个缓存段数据, 也会导致缓存空间的浪费.
为了避免上述问题的产生, 本文将小的块文件进行合并, 并将多个part 文件等数据合并为一个文件存储到S3, 以减轻小文件读写的压力; 同时提出了混合缓存策略, 将缓存的粒度分成块粒度和S3 上的对象粒度, 以减少本地缓存空间的浪费, 并降低多余的网络开销.
2 HG-Buffer 架构
在存算分离的架构下, 对象存储对小文件的读写效率是很大的性能瓶颈. ClickHouse 在写入的时候会产生大量的小文件, 从而导致了系统性能的降低. 如果按照对象存储适用的粒度, 将本地的小文件合并成大文件上传到对象存储, 同样会产生另外的问题: 合并后的大文件中, 有的数据是热数据, 有的数据是冷数据, 冷/热数据在大文件中的占比也都不尽相同; 如果大文件中的热数据占比高, 将大文件缓存到节点中是有效的; 当大文件中的热数据占比较低的时候, 大文件中的冷数据就占用了有限的缓存空间, 无助于提高查询性能; 但是如果不缓存热数据占比较低的大文件, 又因其存在少量的热数据, 这个大文件会被频繁访问, 这个时候就会产生巨大的网络开销.
为了克服上述问题, 本文提出了HG-Buffer. HG-Buffer 的想法和贡献可以概括为以下几点.
(1) HG-Buffer 使用一个块缓冲区(Block Buffer)和2 个对象缓冲区(Object Buffer)来组织整个SSD 缓冲区空间. 如果Object Buffer 的对象将要被驱逐出去, Object Buffer 中的热块就会被移动到Block Buffer, 此时Object Buffer 的空间就得以释放, 为后续的请求提供更多的缓冲空间. 有了这种机制, HG-Buffer 基于有限的SSD 空间可容纳更多的热数据, 从而提高命中率和整体的性能.
(2) Object Buffer 的热块被移动到Block Buffer 之后, 会失去局部性的优点, 数据访问的速度会降低. 如果一个将被驱逐的对象是一个热块率高的对象, 将其中的热块移动到Block Buffer 不仅会使其失去局部性的优点, 还会有大量的迁移成本. 因此, HG-Buffer 引入了一个热块率的概念来量化一个对象的热块占比.
(3) HG-Buffer 的后台线程会执行块数据和对象数据在Block Buffer 和Object Buffer 之间的迁移.实验证明, HG-Buffer 的效率比普通的二级缓存策略更好, HG-Buffer 在不同的SSD 空间下具有鲁棒性.
图2 显示了HG-Buffer 的总体架构, 缓冲区部分由3 个子缓冲区组成: Normal Buffer 和Object Buffer 是对象粒度的缓冲区; Block Buffer 是基于块粒度的缓冲区. 因为计算节点和对象存储之间的数据交换必须以对象(object)为单位, 所以使用Normal Buffer 缓存从对象存储中读取的对象数据.Object Buffer 用于存储热块率高的对象数据, 热块率高的对象数据中包含了大量的热块, 所以它们被整体缓存到Object Buffe. Block Buffer 存储来自Normal Buffer 中被驱逐的对象数据中的热块. HGBuffer 中的热块率是指对象数据中热点块的比例: 一方面, 更高的热块率意味着一个对象中包含更多的热块, 此时对象中的数据更适合由对象粒度缓冲区管理器管理; 另一方面, 较低的热块率意味着缓存整个对象数据没有意义, 将热点块单独取出并使用块粒度缓冲区管理热点块的方式会使访问效率更高.

图2 HG-Buffer 的架构Fig. 2 Architecture of HG-Buffer
当查询引擎请求数据时, 缓冲区管理器首先在内存缓冲区缓存中查找数据, 如果未找到该块数据,则在通过数据文件中的映射关系到SSD 缓存中查找该块; 如果仍未查找到该块数据, 则从对象存储中检索它 (具有更高的延迟), 并将它缓存到计算节点中的Normal Buffer. 随着数据老化, 按照LRU 算法, 数据最终从Normal Buffer 缓存中逐出, 并将根据热块率存储到Block Buffer 或Object Buffer 中.在Block Buffer 和Object Buffer 中, 数据的更新算法同样是按照LRU 算法进行的. 当数据完全从SSD 缓存中被逐出, 这些被逐出的数据会被简单地丢弃. 插入的新数据或是更新的数据总是使用新的对象键写出到对象存储, 然后更新本地数据与新块的映射关系.
HG-Buffer 将与其数据相关的元数据信息放入内存. 元数据信息是指与块相关的一些信息, 包含块的大小、块在云存储上的ID、块在SSD 缓存中的位置, 以及块是否被缓存等信息. HG-Buffer 中块的数量很多, 无法将3 个缓冲区中所有的块元数据信息都加载到内存, 块元数据信息通常存储在SSD 上的数据映射文件中. 为了加速查询的效率和减少访问磁盘(I/O)的次数, HG-Buffer 在内存中另外存储了Block Buffer 中热块的元数据. 所以, Block Buffer 中的块和块元信息在内存中保持着一个映射关系表, 这个关系表可以表示Block Buffer 中所有的块信息, 即块的位置信息, 以及块的访问频次信息. 存储Block Buffer 中块的元信息的原因有二: 一是Block Buffer 中的块本就已失去了局部性原理的访问优点, 如果每次还要去SSD 中获取块的位置信息, 然后再去SSD 中获取块数据, 这样的两次随机I/O 会导致速度的大大下降; 二是Block Buffer 中的块相对于Object Buffer 的块的数量更少,Object Buffer 中对象的块是连续的, 访问速度更快, 所以如果存储Block Buffer 中的块信息, 则比存储Object Buffer 的元数据信息的价值更高, 收益更大. 为了加快查询块的速度, 在内存中元数据的存储方式是哈希表. 由于Block Buffer 内的数据量不是固定的, Block Buffere 的大小也不是固定的, 所以内存中的元数据组织方式是可扩展哈希表. 可扩展哈希表可以根据数据量的大小动态地改变哈希表的大小, 从而更高效地使用内存数据, 加快查询速度.
3 缓冲区物理布局
混合粒度缓存层使用计算节点的SSD 作为对象存储的缓存. 数据在S3 上的粒度和系统存取数据的粒度是不同的, 本文称前者为对象, 后者为块. 以一个读操作为例, ClickHouse 收到一个查询请求,需要访问某个块数据: 如果内存和计算节点SSD 中均没有这些数据, ClickHouse 则需要从S3 上获取该块数据对应的对象文件, 然后将对象数据放入SSD 缓存; ClickHouse 计算节点从SSD 缓冲区中的对象中获取需要的块数据, 然后将这个块数据直接放入内存, 从而完成查询请求.
对象文件包含对象的头信息和多个块数据: 对象的头信息包含一个visitBitmap 用于保存对象中每个块的访问信息, 即热度信息; 每个块都是一个压缩数据块, 由头信息和压缩数据这两个部分组成.每个压缩块的体积大小控制在64 kB 左右; 头信息固定使用9 B 表示, 具体由1 个uint8 (1 B)和2 个uint32 (4 B)整型组成, 分别代表了使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小. 块的具体数据格式如图2 所示. 每个对象文件由多个块组成, S3 访问文件到最佳的大小是17 MB, 所以每个对象的大小是16 MB 到20 MB. 对象文件的排列如图3 所示, 数据文件的元信息中每一行包含了块的基本信息, 即块数据压缩后的大小、每个块的S3 键信息, 以及块在对象文件中的序号.

图3 对象和块的数据布局关系Fig. 3 Data layout of objects and blocks
关于本地SSD 上缓冲区的组织形式, 本文有两种选择: 第一种是将所有缓存数据存储在一个由HG-Buffer 内部管理的文件中, 并使用扁平文件管理的方式; 第二种是将缓存数据存储在一个由操作系统维护的目录结构中. 关于空间的分配, 第一种方式需要HG-Buffer 将一个文件分成多个块, 然后管理该文件内的空间, 同时还需要兼顾文件的碎片管理; 而第二种方式只需将块数据或对象数据映射的文件直接进行I/O, 其余部分交给操作系统管理即可. 从这点来看, 第二种方式的实现更为简单. 所以本文采用基于目录的方式.
HG-Buffer 的缓冲区在物理上的布局是将缓存的数据存储在一个由操作系统维护的目录结构中,其所包含的3 个缓冲区分别放在不同的目录文件下. 因为数据文件的数量很大, 如果只是扁平化的目录, 查找需要的数据会非常麻烦, 所以通过哈希(Hash)函数将数据文件变成树形结构. 每一个存储在对象存储上的文件都有一个独特的键, 如S3 上存储的文件对应的键是随机的字符串. 为了维护平衡的目录树, HG-Buffer 依赖Hash 算法从对象键生成路径前缀, 也就是说, 给定对象键、目录树的最大高度以及每个目录的最大子文件树, 可以进行如下的计算.
设定:k为一个对象键 (或等效的数字串);f为确定目录中允许的最大子目录数, 且必须是2 的幂次方;h为目录树的最大高度. 具体算法如下.
(1)计算H(k) , 其中H(·) 是将对象键映射到 64 位无符号整数的Hash 函数.
(2)在radix-f中表示前面步骤计算的数.
(3)将radix-f表示的数的低位h位作为每一级路径的目录名, 这里h即是目录树的最大高度.
例如, 设最大子目录数f=32,目录树的最大高度h=2 , 需要计算密钥k=4611686018427387905的路径. 假设H(k) 返回654321, 654321 的radix-32 为19-30-31-17, 获取其最低2 位有效数字, 即31 和17, 将路径构造为/cachelocation/31/17/4611686018427387905,页面写入SSD, 以及从SSD 读回时使用相同的路径. 如果在HG-Buffer 尝试将对象写入SSD 时, 路径中的任何目录或子目录不存在, 则它们将基于这个规则创建目录, 其中叶子目录可以包含大于最大子目录数的文件, 但中间目录的子目录数不能大于最大子目录数.
Block Buffer、Object Buffer 和Normal Buffer 分别处于不同的根目录下. Object Buffer 和Normal Buffer 都是基于对象存储的键散列而成的路径进行存储, 而Block Buffer 除了需要对对象存储的ID 进行散列, 还需要加上块在对应对象文件中的位置, 从而可以唯一标识块的位置.
4 HG-Buffer 的操作
4.1 只读操作
分析型数据库会有大量的查询操作, 并且它的查询操作往往是一次性对少数列的大量数据进行统计分析. 在分析型数据中, 只读操作的占比非常高. 当存储引擎收到一个查询数据的请求时, 它首先查找访问对应块数据的元数据哈希映射表, 查看它们是否在Block Buffer 中, 然后再加载计算节点上的数据文件映射信息, 找到这些数据在HG-Buffer 中存在的位置. 如果该块数据已经在缓冲区了, 那么直接访问SSD 上HG-Buffer 中获取的对应块数据即可; 如果该块数据不在SSD 上的HG-Buffer 中,则需要将访问方式重新定向到对象存储, 从对象存储中获取对应的对象数据, 然后将此对象数据放在Normal Buffer 中, 并修改SSD 中关于这些数据的映射数据信息.
在获取了块数据之后, 还需要修改块的热度信息. 每个缓冲区都记录每个块的访问顺序到日志信息, 在内存中累积到一定量之后落盘到SSD; 后台迁移程序会通过日志信息驱逐对象数据或者是调整它的位置.
4.2 写操作
数据库中的写操作分为3 种: 插入操作、删除操作和更新操作. 数据库的写操作往往涉及缓存一致性的问题: 如果先更新缓存, 再写入远程的对象存储, 可能出现数据不一致的问题; 如果先更新远程的对象存储, 再写入本地的缓存, 则可能出现性能上的问题; 如果同一时间有大批的数据写入, 这些数据将缓存中的热数据都替换到了SSD 中, 但此时写入的数据不是高热度的数据, 这将导致SSD 缓存中原有的热数据信息丢失, 后续的大量访问在SSD 缓存中都不会命中, 导致大量的请求都重新定向到对象存储, 造成对象存储的读写压力加大, 系统的性能整体下降.
为了规避上述问题, 本文在写入数据时, 先增加新数据对应的元数据信息, 然后直接将数据写入对象存储, 最后将本地数据和对象存储数据的映射关系记录到元数据信息中. 如果整个过程中, 写入对象存储发生错误, 整个写过程就会回滚.
对于插入操作, ClickHouse 插入数据时, 插入的一批数据将会产生一个单独的part, 该part 文件包含其相关的所有块数据元信息; 而在对象存储中, 插入的数据会以对象为单位存入对象存储, 当在对象存储中写入成功之后, 则需要将块数据与对象存储数据之间的映射关系更新到块数据的元信息中.
对于删除操作, ClickHouse 将对应的part 文件标记为删除后, 后台线程异步对标记的part 文件进行删除. 对于HG-Buffer 而言, 删除数据时, 首先删除云存储上的数据, 云存储的数据删除之后, 再删除本地与part 相关的数据以及块的元数据. 如果删除的时候有查询访问这些数据, 由于数据在删除之前都被标记为outdated, 即这些数据已经不能访问了, 所以只能是查询失败, 则不会造成缓存不一致的问题.
对于更新操作, ClickHouse 将更新操作分成删除操作和插入操作两个部分. 在系统看来, 删除操作中只要在part 被标记为outdated 之后, 这些数据就已经对系统不可见了; 然后再插入新数据, 插入的流程与上文所述的插入操作相同.
4.3 数据迁移
每个对象文件移动到SSD 上时, 每个对象中只能包含限定数目的块数据. 按照本文所定的规格,平均每个对象数据的大小是17 MB, 每个块数据的大小是64 kB, 则一个对象文件中最多能够存储272 个块数据. 本文在对象数据头信息中存储了visitbitmap, 每一位都对应一个块数据. 如果一个块数据没有被访问, 那么它对应的标记是0; 如果块已经被访问过, 那么它对应的标识就是1. 当一个对象即将被移除的时候, 这些被访问过的块数据就是热块. 本文通过vistbitmap 中标识为1 的统计值除以整体的热块个数来计算热块率. 如果一个热块率超过预定阈值, 那么这个对象数据在被驱逐时, 就应该被放入Object Buffer; 反之, 则将对象数据中的热块取出放入Block Buffer.
HG-Buffer 的缓存分成3 个部分: Normal Buffer、Block Buffer 和Object Buffer. 当数据从共享存储中迁移到计算节点时, 数据首先缓存在Normal Buffer; 当Normal Buffer 满了, 则需要将数据迁移到Block Buffer 或者是Object Buffer. Block Buffer 存储热块率低的块, Object Buffer 存储热块率高的块. 虽然数据会在这3 个缓冲区之间迁移, 但是数据的元数据信息和数据的热度信息不会因为数据的迁移而改变. 对于计算节点而言, 每一个块信息都有一个唯一的标识, 即块在共享存储的键和在对应对象文件中的位置是唯一的. 共享存储中, 每一个块都存储在一个对象中, 对象是共享存储中存储数据的单位, 所以每个块的标识为对象的共享存储键加上块在对象文件中的位置. 块的元数据信息包括块数据在共享存储上的标识、块数据在HG-Buffer 缓存中的映射关系, 以及块的大小等信息. 当发生数据迁移时, 元数据中块在HG-Buffer 中的映射关系会改变, 其余的元信息以及元数据的位置则不会改变.
如果Normal Buffer 满了, 则按照LRU 的缓存替换规则, 将Normal Buffer 的内容替换掉. 如果被驱逐的对象是热块率高于阈值的, 则将其放入Object Buffer; 反之, 则将对象中热度高的块数据放入Block Buffer; 如果Object Buffer 满了, 则需要将对象中的数据逐出. 上文已介绍过, 在数据更新的时候, 会删除缓存区和共享存储中的块, 再插入新的块, 脏数据回写的问题就不存在了. 所以Object Buffer 中不会有更新的块数据, 逐出的对象数据会直接被抛弃. 同理, Block Buffer 被逐出的数据也是这样的处理.
4.4 热块率
热块率是决定一个对象数据是否留在缓冲区的重要指标, 其定义是热块的总数据量除以对象的数据量, 即热块在对象中的占比. 关于设置热块率的大小, 本文使用缓冲区的大小与数据库总大小的比值为热块率的阈值. 当一个对象的热块率超过这个阈值, 它就可以被放入Object Buffer; 反之, 则需要将其中的热块抽取放入Block Buffer.
接下来, 从理论上分析HG-Buffer 的效率. 假设缓冲区与数据库大小的比值为T, HG-Buffer 中Normal Buffer、 Block Buffer、Object Buffer 的占比分别为N、B、O, 其中热块率的阈值及缓冲区与数据库大小的比值相同, 也为T. 针对ClickHouse 现有的单一粒度缓冲区策略, 其热数据占比最高为T.对于HG-Buffer, Block Buffer 热数据的承载量 (Hhot,Blo) 为
Object Buffer 热数据的承载量 (Hhot,Obj) 为
Normal Buffer 热数据的承载量 (Hhot,Nor) 为
则整体HG-Buffer 的热数据承载量 (Hhot,HG) 为
这里, 1-T代表不是热块的概率. 公式(1)中, 第一个 ( 1-T) 代表有 1-T概率的数据会被Normal Buffer 淘汰下来; 第二个 ( 1-T) 代表被淘汰的数据中有 1-T的数据不是热块, 所以这部分数据会被放在Block Buffer 中.
首先, 假设缓冲区的大小是数据库大小的20%, 即热块率的阈值为20%. 现有普通的缓冲区管理器, 最好的情况下热数据的缓存率为20%. 然后对HG-Buffer, 假设Normal Buffer、Block Buffer 和Object Buffer 的缓存率大小分别是20%、40%和40%. 因此, Normal Buffer 中包含了4%的热数据量,Block Buffer 能承载的热数据量最少为25.6%, 而其中Object Buffer 的热数据量为6.4%. 这三者整体加起来的热数据量估计为36%, 大于普通的缓冲区管理器.
5 实验评估
本文实验基于5 台Linux 服务器组成的集群环境, 每台Linux 服务器有相同的软件和硬件配置:Intel(R) Xeon(R) Silver 4110 CPU@2.10 GHz; 128 GB 内存; 10 GB/s 以太网; CentOS Linux release 7.8.2003 操作系统, ClickHouse 版本为22.3.2.2-lts. 实验评估HG-Buffer 的有效性和鲁棒性评估.
5.1 有效性实验
(1) SSD 直接作为二级缓存: 实验设置100 GB 容量的二级缓存和50 GB 内存缓冲区缓存, 并将该二级缓存安装在本地连接SSD 上.
(2) 作为系统交换空间扩展: ClickHouse 的缓冲区缓存不使用二级缓存, 而是将本地连接的SSD 的额外100 GB 通过使用操作系统交换空间进行扩展, 从而将总缓冲区缓存容量增加到150 GB.
(3) SSD 上使用HG-Buffer 为缓存策略作为二级缓存: 除了50 GB 内存缓冲区缓存和100 GB 容量的二级缓存, 与此同时, 系统使用HG-Buffer 缓存策略.
实验依赖于TPC-H 基准测试[26], TPC-H 表是使用具有HighGroup (HG)索引[27]的范围分区创建的, 有如下示例: o_custkey、n_regionkey、s_nationkey、c_nationkey、ps_suppkey、ps_partkey 和l_orderkey. 本文依靠AWS S3[28]作为ClickHouse 的底层对象存储.
为了模拟数据的冷暖行为, 实验每次测试都根据顺序Q1,Q1, Q2,Q2,··· ,Q22,Q22进行, 即执行查询2 次. 每次测试缓存只会在每次测试开始前被清除一次. 在 TPC-H 基准测试的加载阶段, 除索引更新之外, 数据库数据不会被服务器多次读取. 所以, 在大多数情况下, 这些请求可以直接从内存缓冲区缓存中得到满足. 因此, 本文不期望二级缓存会带来性能的提升. 尽管如此, 也不希望二级缓存的启用而导致性能下降. 如图4(a)所示, 只有混合粒度缓存策略即HG-Buffer 可以能实现这一目标. 对于加载数据的场景, 使用操作系统交换空间增加缓冲区缓存容量会导致性能不佳, 因为操作系统内核使用的页面大小、缓存策略不一定与ClickHouse 的缓冲区保持一致. 为此, 没有二级缓存的情况及混合粒度缓存策略可以实现更好的性能.

图4 二级缓存技术TPC-H 基准比较Fig. 4 Comparison of TPC-H between second-level caches
在基准测试的查询阶段, 从图4(b)中可以观察到, 使用操作系统交换空间增加缓冲区缓存容量也会导致查询执行期间的性能不佳. SSD 二级缓存的情况有缓存利用率低下的缺点, 而HG-Buffer 缓存策略克服了这一点. 为此, 本文注意到混合缓存策略的执行时间为0.78 s, 而将SSD 直接作为二级缓存的方法的执行时间为1.06 s, 在混合缓存方法的情况下, 与SSD 直接作为二级缓存相比, 查询执行时间的减少了28.2%.
5.2 鲁棒性实验
鲁棒性验证实验的目的是验证HG-Buffer 在不同的系统和硬件配置下能否提供稳健的性能. 实验中控制总缓存大小, 即内存缓冲区加上HG-Buffer 的总大小不变, 但控制HG-Buffer 缓存大小, 从而有效地控制内存缓冲区与HG-Buffer 大小的比率. 与之前的实验一样, 实验运行TPC-H 基准测试的功耗模式. 对于查询测试, 第一个测试使用150 GB 的总缓存大小, 第二个测试使用200 GB 的总缓存大小. 图5 显示了具有不同HG-Buffer 缓存大小的系统配置的总加载时间, 图6 显示了具有不同HGBuffer 缓存大小的系统配置的总查询执行时间. 关于数据加载和查询, 在两组测试中观察到一致的执行时间. 关于查询, 从图6 中2 个对照组可观察到执行时间一致, 差异很小. 所以关于数据的加载和查询, 通过实验, 可以发现HG-Buffer 具有理想的稳健行为.

图5 TCP-H 基准测试下不同比值下的加载时间Fig. 5 Loading time at different ratios in TCP-H benchmark
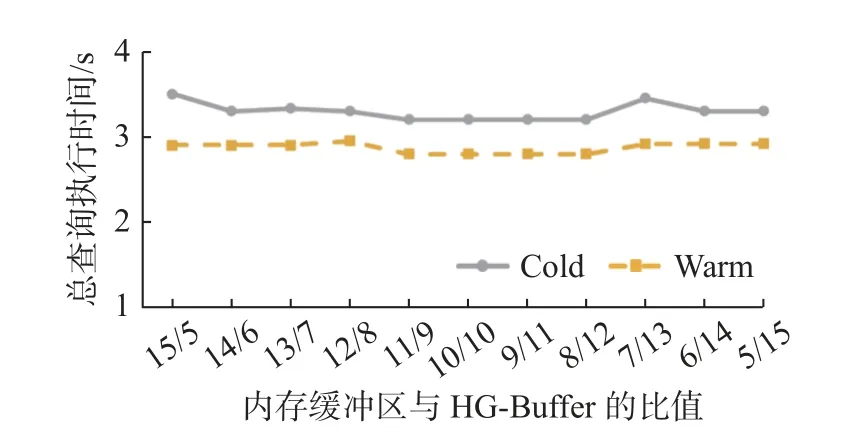
图6 TCP-H 基准测试下不同比值的查询时间Fig. 6 Total query execution time at different ratios in TCP-H
6 总 结
随着信息时代数据量的增加以及以太网的发展, 数据库管理系统正逐渐从本地部署转向云端, 以实现更高的弹性和更低的成本. 存算分离方案是一种数据存储和计算分离的架构, 旨在提高大规模数据处理的性能和效率. 本文基于ClickHouse 和S3 的存算分离方案, 提出了一种基于SSD 的混合粒度缓存管理方案, 简称为HG-Buffer. HG-Buffer 的关键思想是将SSD 缓存空间组织成对象和块这两个粒度的缓存, 其中对象是数据存储到对象存储中的粒度, 而块则是数据在本地磁盘上存储的粒度. 通过控制这两个粒度的缓冲区可提高系统的访问效率. 本文还通过实验验证了HG-Buffer 的有效性和鲁棒性.
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28
高技术通讯(2021年5期)2021-07-16
南京大学学报(自然科学版)(2021年1期)2021-01-30
当代陕西(2019年13期)2019-08-20
水利规划与设计(2017年11期)2017-12-23
系统工程与电子技术(2016年12期)2016-12-24
项目管理技术(2015年3期)2015-04-23
测绘科学与工程(2014年5期)2014-02-27
计算机工程与设计(2012年3期)2012-07-25
淮阴工学院学报(2012年3期)2012-06-08
