
异构编码联邦学习
2023-09-22 01:09史洪玮洪道诚施连敏杨迎尧
华东师范大学学报(自然科学版) 2023年5期
史洪玮, 洪道诚, 施连敏, 杨迎尧
(1. 宿迁学院 信息工程学院, 江苏 宿迁 223800; 2. 华东师范大学 上海智能教育研究院 & 计算机科学与技术学院, 上海 200062; 3. 苏州大学 计算机科学与技术学院, 江苏 苏州 215008;4. 武夷学院 认知计算与智能信息处理福建省高校重点实验室, 福建 武夷山 354300)
0 引 言
近年来, 联邦学习(federated learning, FL)由于数据隐私保护效果突出, 已经成为新兴研究领域之一. 通用的FL 系统由单个服务器和多个设备组成, 多个设备拥有本地存储数据, 服务器可以通过多次调度设备在本地完成模型训练, 而训练过程中的所有参数在服务器中聚合则可以完成模型训练. 然而, 异构FL 中包含个人电脑、嵌入式设备等种类繁杂的设备, 其中, 性能较低的设备即掉队者, 会降低模型的收敛速度[1-3].
由于异构FL 中, 部分掉队者参与训练后会不可避免地影响系统性能, 甚至整体的运行状态, 很多学者对异构场景进行了研究. McMahan 等[3]提出可以通过放弃性能较差的掉队者提升系统运行速度;Li 等[4]通过减少掉队者对数据集的训练轮次或降低训练数据量的方式, 提升系统效率; Liu 等[5]研究并设计了高效方案, 允许掉队者训练小型模型, 并通过知识蒸馏的方式实现不同规模模型信息共享.针对掉队者问题, 现有研究大多从减少掉队者训练数据量的角度出发, 以总数据量减小为代价提升性能; 而不同规模模型共享的方法又过分依赖服务器的性能, 与联邦学习的去数据中心化思想有所不符.
在中小型FL 场景中, 掉队者也有必要参与到FL 系统的模型训练中, 以提高可训练数据量及准确率[6-7]. 现有方案大多使用分布式思想来提高掉队者计算速度, 然而分布式计算的基于数据中心化的思想, 会导致数据在整合到数据中心的过程中无法保证数据隐私安全[8-9]. 为了保护隐私, 大多数现有的隐私保护分布式计算方案采用同态加密或差分隐私的方法[10-12]. 然而, 同态加密算法的解密过程会占用指数级别的时间消耗[13-14]; 添加在差分隐私中用来保护数据的扰动值又难以控制, 甚至可能会掩盖真实数据[15-16].
在上述情况下, 部分学者研究并设计出编码分布式计算, 以保护分布式计算中数据聚合以及后续数据外包中的数据隐私[17-18]. Cao 等[19]针对矩阵相乘, 设计了编码方案对矩阵进行保密, 并提升了计算效率. Dhakal 等[20]将线性编码与线性回归相结合来训练线性模型. 此线性编码回归模型方案将本地数据矩阵编码为校验矩阵, 通过控制数据量的方式完成全部客户端的训练. 但是, 校验矩阵依旧是真实数据的映射, 无法完全保护数据隐私.
本文提出并实现了在异构FL 场景下用编码联邦学习(heterogeneous coded federated learning,HCFL)方案来训练卷积神经网络(convolutional nerual networks, CNN)模型. 在HCFL 方案中,CNN 的整体流程会被分为若干片段. 这些片段包含复杂计算函数, 如卷积计算函数、全连接计算函数;以及简单计算函数, 如池化函数、激活函数等. HCFL 仅将CNN 中复杂函数的计算任务进行分发, 以避免激活函数等非线性计算函数与线性编码之间的不兼容. 本文的主要工作有以下4 个方面.
(1) 对于异构FL 场景, 本文结合线性编码和调度算法设计了通用HCFL 框架.
(2) 通用HCFL 框架包含多掉队者任务分发算法. 多掉队者任务分发算法可以应用于存在多掉队者的异构FL 场景中, 在调度全部设备训练以保证数中小型FL 场景下数据的充分性的同时, 极大加速了模型训练.
(3) 通用HCFL 框架中设计了LCC 方案来保护数据分发过程中的隐私.
(4) 在实际实验平台中完成的大量实验表明, HCFL 能够显著加快FL 训练, 并提高异构FL 场景下的训练效率.
本文组织结构如下. 第1 章介绍HCFL 框架模型; 调度算法和线性编码计算方案在第2 章中详细解释; 然后在第3 章中通过实验验证HCFL 性能; 最后第4 章对本文进行总结.
1 系统模型
1.1 联邦学习模型
本节将以CNN 为具体模型, 展开和描述联邦学习流程. CNN 模型的具体结构为:L层卷积层、L层下采样层及一层全连接层, 联邦学习基于此CNN 模型通过多轮调度训练得到最优化模型M. 在异构场景中, 联邦学习通常包含一个服务器以及α个异构设备K={k1,··· ,kα}, 此时详细的联邦学习流程如下.
(1) 模型目标确认. 在调度设备参与模型训练之前, 服务器根据具体的深度学习任务, 如图片分类, 随机生成或使用对应的预训练全局模型M0.
(2) 设备选取. 在第i轮训练开始前, 服务器从设备全集K中选取设备子集Ki, 并将当前全局模型Mi-1发送到设备子集Ki中.
(3) 本地训练. 在第i轮训练过程中, 设备子集Ki中的设备使用本地数据对模型进行训练. 令Mij和bji表示第i轮训练中第L层卷积层的权重参数矩阵和偏置参数,Xl-1为第l层数据输入、Yl为第l层结果输出, 其中,X0表示本地数据集. 则CNN 模型前向传播中的核心计算函数如下:
式(1)为卷积计算函数,⊙表示卷积操作; 式(2)为全连接计算函数. 将前向传播计算结果与真实标签集的值通过交叉熵等方式计算后, 设备子集Ki中的第k个设备即可得出误差 Δki及第i轮训练的梯度值∇ki.
(4) 模型聚合. 在第i轮训练过程末, 服务器聚合设备子集Ki的所有训练结果, 得出全局梯度其中,hi表示设备子集Ki中的设备数量. 由于梯度值与模型参数矩阵维度一致, 因此,模型Mi-1通过Mi=Mi-1-r∇i计算后完成此次更新, 其中r表示学习率.
(5) 模型验证. 服务器根据测试数据集对当前模型Mi进行精度验证. 若验证损失值及准确率符合预期, 则服务器将模型Mi发送给全体设备, 完成本次联邦学习训练; 否则, 则基于模型Mi继续第i+1轮训练.
上述流程为经典联邦学习训练流程. 在训练全流程中, 卷积运算和全连接运算需要占用大量计算资源和时间资源, 这部分耗时运算可经由任务分发来进行训练加速.
1.2 线性编码联邦学习模型
本节将通过具体例子来解释HCFL 的原理和模型训练流程.
由于高计算复杂度, 式(1)中卷积计算函数和式(2)中全连接计算函数需要被分发以加速训练. 根据现有研究中的矩阵维度转换, 式(1)中模型权重参数Mil可以转换为符合矩阵维度相乘要求的模型参数矩阵[21]. 参数矩阵转换后, 卷积计算函数可以被转换为矩阵相乘形式, 即同时, 矩阵相乘的计算结果支持转换回Yl[21].
卷积计算函数经过参数矩阵转换和矩阵相乘后, 效率得到极大地提升, 矩阵相乘计算过程中的参数矩阵也能以分块矩阵相乘的形式完成数据编码, 以增强数据保护. 假设第j个设备本地存储有数据集Dj及对应的标签集, 其中j∈{1,··· ,α},α表示设备数量, 数据集Dj满足独立同分布(independent identically distributed, IID); 设 备 集 合K的 计 算 速 度 和 网 速 集 合 分 别 为Vu={vu,1,··· ,vu,α}和Vn={vn,1,··· ,vn,α}. 服务器将上一轮训练中更新得到的模型Mi-1发送到随机选取的设备子集Ki中. 如果设备子集中的设备满足此设备即在本地完成模型训练; 否则, 此设备承担的计算任务则需要被分发.
由于服务器调度的随机性, 服务器可能会在同一批次训练中选取到多个掉队者进行训练. 此时的任务分发流程如图1 所示.

图1 多掉队者场景下单轮训练流程Fig. 1 Single-round training process in multiple straggler scenarios
(1) 服务器在FL 的第i轮训练中调度ki1、ki2和ki3这3 个设备参与对本轮模型Mi-1的训练, 其中,ki1和ki2两个设备为掉队者.
(2) 服务器对各设备进行针对性调度. 设备ki3由于速度较快, 进行本地独立训练. 相反,ki1和ki2则需要将自身计算任务进行分发. 在任务分发之前,ki1和ki2将自身数据拆分为3 个相同的数据分块, 其中,D1,1、D1,2和D2,1、D2,2需要在被编码保护后进行分发.
(3) 协作设备利用收到的本轮模型Mi-1完成收到的计算任务. 例如, 设备ki1的协作客户端完成计算, 并得到结果其中,fM(D) 表示数据D经过模型M计算后的结果. 在接收到编码结果矩阵后, 掉队者ki1可以对编码结果矩阵进行解码, 并得到
(4) 服务器整合3 个设备的梯度结果∇1、∇2和∇3, 并将模型Mi-1更新为Mi.
以上为多掉队者的异构FL 任务分发过程. 任务分发能够极大地提升掉队者计算速度, 同时分发过程中的数据隐私也被编码保护.
2 异构编码联邦学习
本章将介绍所设计的基于多掉队者任务分发算法和LCC 方案. 首先研究多掉队者任务分发算法,具体包括基于客户端的任务分发方案以及基于服务器的任务分发方案, 实现解决多掉队者场景下的任务分发问题. 之后, 本研究设计了LCC 方案, 实现了在弱安全级别上的系统数据隐私保护.
2.1 多掉队者任务分发算法
在异构场景下, 掉队者参与联邦学习训练时, 由于协同客户端的性能水平不一致, 导致掉队者本身无法同步完成任务分发以及训练任务. 为平衡数据传输时间以及统一单次训练中各设备的训练所需时间, 任务分发算法将从客户端和服务器角度考虑调度方案.
(1) 基于客户端的任务分发方案. 掉队者各自寻找空闲的协作客户端并进行任务分发. 掉队者按照自身被调度顺序从快到慢来获取协同客户端, 这将导致剩下的客户端速度较慢, 即对于等量训练任务, 后续掉队者所需训练时间会更长.
(2) 基于服务器的任务分发方案. 所有计算任务由服务器统一分发. 存储于多个掉队者中的本地数据首先在被编码后聚合到服务器中, 接着服务器对所有数据计算任务进行分发. 基于服务器的任务分发能够让所有分发任务同时返回计算结果, 而无需如基于客户端的方案中等待被最后调度到的掉队者完成训练.
2.1.1 基于客户端的任务分发方案
设备集合Ki在服务器进行的第i次训练中被调度进行训练, 同时定义序列Ksi代表设备集合Ki中存在的掉队者集合. 同时, 令设备集合Ki的计算速度集合为Vc, 网络速度集合为Vs. 如第1 章所述,卷积计算和全连接计算需要被分发.
在基于客户端的任务分发方案中, 掉队者集合Ksi中的掉队者按照先后顺序被调度, 此时若空闲设备数量充足, 则第p个掉队者ksi,p可以寻求到ρ个设备组成的协作设备集合B1p,i,··· ,Bρp,i] , 其中,Bjp,i表示要分发给第p(p ∈{1,··· ,β}) 个掉队者ksi,p的第j个协作设备{1,··· ,ρ}) 的任务数量. 同时,B0p,i表示分配给第p个掉队者自身的计算任务数量. 假设对于CNN 模型中的一个固定大小的数据, 前向传播和反向传播中分别需要分发的任务量为Gf和Gb, 基于第p(p ∈{1,··· ,β}) 个掉队者ksi,p的初始速度与其对应的协作设备集合中各设备的速度, 掉队者ksi,p和各协作设备分别要完成的任务量为
相应地, 掉队者ksi,p对应的协作设备集合所承担的总任务量减少. 对于协作设备集合中的设备其任务量在考虑网络速度后被更新为
线性编码被加入方案中以保护数据分发中的隐私. 然而, 由于线性编码的特征, 作为编码对象的数据会被分割为大小一致的数据分块, 并且编码所需时间会随着分块数量Rp的变化而线性变化. 当掉队者ksi,p本地存储的全部数据被分为Rp个数据分块后, 单个分块所代表的数据量为Gp=此时协作设备承担的任务量将被更新为对应数量的数据分块, 即
所有由于向下取整而未能分发出去的任务均由掉队者ksi,p自身完成, 以节省数据传输时间, 此时掉队者ksi,p所需完成的任务量为
分块数量Rp的值仅在平衡数据传输时间和编码时间时进行改变. 假设对于一个固定大小的数据矩阵完成一次线性操作的时间为Tc, 此时的数据传输时间和编码时间总和为
当总时间Te取得最小值时, 即可确定分块数量Rp的值.
在基于客户端的分发方案中, 由于第一个掉队者ksi,1会被服务器首先调度, 因此,ksi,1会从空闲设备中选取速度较快的设备来完成任务分发. 在择优选取的策略下, 最后一个掉队者对应的协作设备集合Kcβ,i中的设备速度将比其余掉队者对应协作设备集合中的设备速度都要慢. 在空闲设备数量足够多的情况下, 基于客户端的分发方案所需要的训练时间, 将受限于末位掉队者ksi,β, 具体值为
基于客户端的分发方案训练效率受限于掉队者集合中的末位掉队者ksi,β. 上述的任务分发是建立在设备充足的基础上, 特殊的边界情况将在基于服务器的任务分发方案中进行介绍.
2.1.2 基于服务器的任务分发方案
基于服务器的分发方案将对通信时间和计算时间进行均衡, 从服务器的全局角度出发来进行任务调度, 可以满足更通用的性能优化需求.
在基于服务器的任务分发方案中, 掉队者集合Ksi中所有掉队者本地存储的数据量均会被编码后统一集中到服务器中, 所需数据聚合时间为
根据式(4)—(6)的推导, 可以计算出此时
最终的任务分配数量为
当有足够数量的空闲设备时, 基于服务器的任务分发方案所需要的训练时间包含数据聚合、编码数据分发、神经网络计算中间参数值传输及模型计算时间Tcalc, 训练时间总值为
不同于基于客户端的任务分发方案, 在服务器的总体调度下, 基于服务器的任务分发方案能够使各设备同时返回计算结果. 然而, 基于服务器的任务分发方法需要消耗额外的数据传输时间. 比较两个方案的训练完成时间Tcto和Tsto, 服务器可以从两个方案中选取需求时间较短的方案.
最后, 本节讨论多掉队者场景下异构FL 中的两个边界问题.
(1) 掉队者数量过多: 掉队者的数量占总设备数量的大多数. 当 (α-β)<βρ<Ψ(α-β) 时, 将会有多个掉队者在训练过程中缺少空闲设备来协作计算, 其中 Ψ 表示一个足够大的常数. 从上文可知,基于客户端的任务分发方案的训练完成时间受限于掉队者ksi,β. 然而, 由于掉队者ksi,β无法获取协作设备, 因此其训练时间近似于此时, 基于客户端的任务分发方案总时间为
对基于服务器的任务分发方案而言, 掉队者ksi,β中的计算任务被均摊到所有参与训练的设备中,对系统训练时间几乎不产生影响. 因此, 基于服务器的任务分发方案在多掉队者场景下更加适用.
当掉队者对应的协作设备数量ρ不同时,ρ较小的掉队者训练时间将会更长. 本文仅考虑协作设备数量ρ相同的情况.
(2) 慢网速环境: 与基于客户端的任务分发方案相比, 基于服务器的任务分发方案中需要两倍的传输时间. 若掉队者在外包方案下也无法正常参与训练, 则该掉队者应该被放弃调度或拒绝其加入FL 系统, 否则会导致FL 存在不公平的激励机制.
2.2 LCC 方案
本节将解释如何使用LCC 线性编码计算方案为系统提供数据隐私保护.
对第p个掉队者ksi,p而言, 其需要分发的任务量为掉队者ksi,p在本地存有数据矩阵D、计算矩阵E、编码矩阵C以及协作设备集合编码矩阵C=[C1T,··· ,ksi,p需要将数据矩阵D分发以加速计算任务Y=ED, 此时线性编码分发计算流程如下.
(1) 掉队者对数据D进行编码保护, 计算得出
(4) 掉队者ksi,p聚合所有分发编码计算结果, 并在解码后获得结果Y∗, 公式表达为Y∗=
上述4 个步骤为LCC 方案的隐私保护流程. 在编码保护过程中, 编码消耗时间为在编码过程中, 编码矩阵C是一个随机生成的满秩矩阵, 并且仅存在于掉队者本地, 能够以弱安全级别保护数据隐私.
3 验证实验
实验主要从两个核心标准来评估HCFL 的效率和性能: 准确性和训练时间.
在异构实验环境设置中, 由于多种类型设备的加入, 因此, 系统选用CPU 进行模型训练. 异构设备中的高性能设备包括配备i5-9700 CPU 的台式机、配备i7-9750H CPU 或i7-7700H CPU 的笔记本电脑, 高性能设备均配备GTX2060 显卡; 边缘设备包括Raspberry Pi 4B、Raspberry Pi 3B+ 和两台配置GTX950 显卡的台式机. FL 系统基于CNN 模型对MNIST 数据集的图像分类任务进行模型训练, 其中MNIST 包含60 000 张图片、各设备本地存储6 000 张图片, 各设备本地图片符合IID 分布.实验设置如下.
(1) 配置1∶8 台电脑、1 台Raspberry Pi 4B、 1 台Raspberry Pi 3B+ 进行训练, 掉队者数量占比较小.
(2) 配置2∶3 台电脑、1 台Raspberry Pi 4B、 1 台Raspberry Pi 3B+ 进行训练, 掉队者数量占比较大.
(3) 配置3∶3 台GTX2060 显卡电脑、2 台GTX950 显卡电脑.
在CPU 类型设备中, i7-9750H、i5-9700、i7-7700H、Raspberry Pi 4B 和3B+ 对6 000 张图片进行训练所需的时间分别是6.3、8.23、9.85、66.2 和73.4 s, 因此, CPU 类型设备中Raspberry Pi 为掉队者;在GPU 类型设备中, GTX2060 显卡算力约为6.45 TFLOPS, 约为GTX950 算力1.57 TFLOPS 的4 倍, 因此GTX950 为掉队者.
3.1 数据量与精度验证
在中小型训练场景中, 数据量多少影响模型最终精度, 因此, 本节基于掉队者中数据量占系统整体总数据量的比例来验证此问题. 验证实验中, 控制掉队者中数据量分别占总数据量的33%、20%及10%, 验证结果如图2 所示. 当掉队者拥有的数据量比例较高时, 忽略掉队者, 会导致模型训练的最终准确率极大降低; 而当掉队者拥有数据量比例仅为10%时, 忽略掉队者后, 最终模型精度训练效率依旧下降5.4%. 当数据集的量级增长或存储方式、种类增多时, 忽略掉队者会导致模型训练效果更差.

图2 数据量与精度验证Fig. 2 Verification of data volume and accuracy
3.2 HCFL 效率验证
本节将通过对比实验验证HCFL 方案的性能和效率, 其中设置了3 种对比算法: 传统FL、异构FL 和基于年龄的FL. 在调度方法上, 传统FL 不忽略掉队者, 同时在每轮训练均调度全部设备[3]; 异构FL 在调度掉队者训练时, 根据掉队者的性能控制训练数据量以及本地训练轮次[4]; 而基于年龄的FL 则在单轮训练中仅调度部分设备, 并选择性地控制掉队者参与到特定轮次的训练中[7].
在实验配置1 中完成的对比实验结果如图3 所示. 对比实验共包括4 种配置, 覆盖不同的协作设备数量和不同的网络速度.
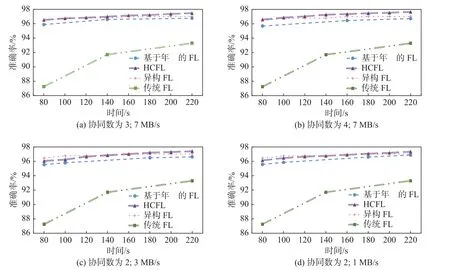
图3 HCFL 效率验证Fig. 3 HCFL efficiency verification
在HCFL 方案中, 增加协同客户端数量能够直接有效地提升系统效率, 当协同客户端数量由3 提升到4 时, 系统效率提升28.23%. 同时, 网络速度的波动对HCFL 影响较大, 而对其他3 种方案几乎没有影响. 当网络速度较快时, 协同客户端数量的增加能带来巨大的性能提升; 而当网速降低到图2(c)中的3 MB/s 和图2(d)中的1 MB/s 时, 相同的训练时间下得到的模型准确率不断降低. 在当前实验配置的4 种情况下, HCFL 对掉队者进行了训练加速, 故其训练效果全程优于传统FL 和基于年龄的FL. 由于异构FL 中的掉队者仅训练少量数据, 并且不需要额外的数据传输, 当网速较低时, 异构FL 能在前阶段训练中训练更优模型; 当网络提升后, 在前阶段训练中HCFL 的训练效率较异构FL 高8.38%. 同时由于异构FL 通过降低训练数据量以提升效率, 其最终模型准确率较HCFL 低0.69%. 即使在网速较低、协同客户端数量较低时, HCFL 较基于年龄的FL 训练效率高31.58%. 而当网速优异、协同客户端数量充足时, HCFL 甚至比基于年龄的FL 训练效率高60.07%. HCFL 能够调度掉队者多次全量地进行训练, 相较于降低训练数据量或降低掉队者训练频率的策略, 在网络状况良好时训练效率更高.
在实验配置3 的GPU 类型设备中进行上述实验的对比结果如图4 所示. 由于GPU 的浮点计算速度远胜于CPU, 因此在GPU 类型设备场景下, 各FL 方案的训练模型精度均有极大的提升.GPU 类型设备场景下, 总体训练效果与CPU 类型设备场景下一致, HCFL 方案依旧拥有更高的训练效率, 当网络状况良好时, HCFL 较异构FL 训练效率提升53.83%、较基于年龄的FL 提升23.07%.
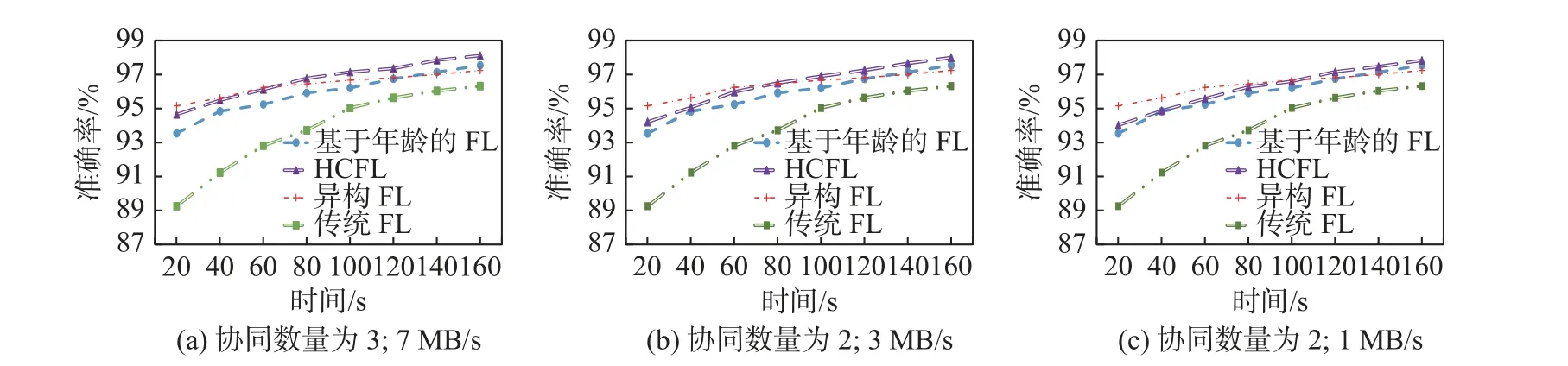
图4 GPU 类型设备下的效率验证Fig. 4 Efficiency verification in GPU-type devices
3.3 基于客户端和服务器的任务分发方案均衡性评估
本节将评估基于客户端的任务分发方案与基于服务器的任务分发方案在多掉队者场景下的实际实验性能.
首先, 在实验配置1 下特定的一轮训练中, 同时调度两台Raspberry Pi, 分别使用基于客户端和服务器的任务分发方案对其计算任务进行分发, 并评估其性能. 当掉队者的协作设备数量为2 时, 两种方案的训练实际对比结果如图5 所示. 当所有设备均拥有足够的协作设备, 且网络速度为7 MB/s时, 基于服务器的任务分发方案性能比基于客户端的任务分发方案高6.24%. 当网络速度降低至3 MB/s时, 由于基于服务器的任务分发方案需要传输两次数据, 因此需要更长的传输时间, 导致基于服务器的任务分发方案所需训练时间比基于客户端的任务分发方案多5.65%. 当网络速度仅为1 MB/s 时,基于客户端的方案性能会比基于服务器的方案显著提高20.87%. 而在上述环境设置中, 与未执行任务分发的掉队者相比, 任务分发方案能够降低掉队者平均89.85%的训练时间.

图5 通用场景下网速对系统影响Fig. 5 Impact of network speed on system in general scenarios
其次, 通过实验配置2 来评估2.1.2 节中边界情况1 下的两种任务分发方案性能. 此实验场景中,两台Raspberry Pi 会在特定训练轮次中被调度, 并分别使用两种方案进行调度, 不同网络速度情况下的训练时间如图6 所示. 在边界情况下的基于客户端分发方案中, Raspberry Pi 会缺少协作设备, 在训练过程中一直在等待其余协作设备完成接收到的任务. 因此, 当网络速度较快时, 基于服务器分发方案要优于基于客户端的分发方案. 当网速达到7 MB/s 时, 基于服务器的分发方案效率比基于客户端的分发方案高23.89%. 而当网络速度仅有1 MB/s 时, 两种方案的性能依旧接近. 综合各场景及各网速情况, 在训练所需计算资源固定的情况下, HCFL 方案利用任务外包方式加速训练过程, 此过程中需要57.42%的额外资源开销. 此部分开销主要用于数据格式转换与网络传输, 并随网速的提升而降低.
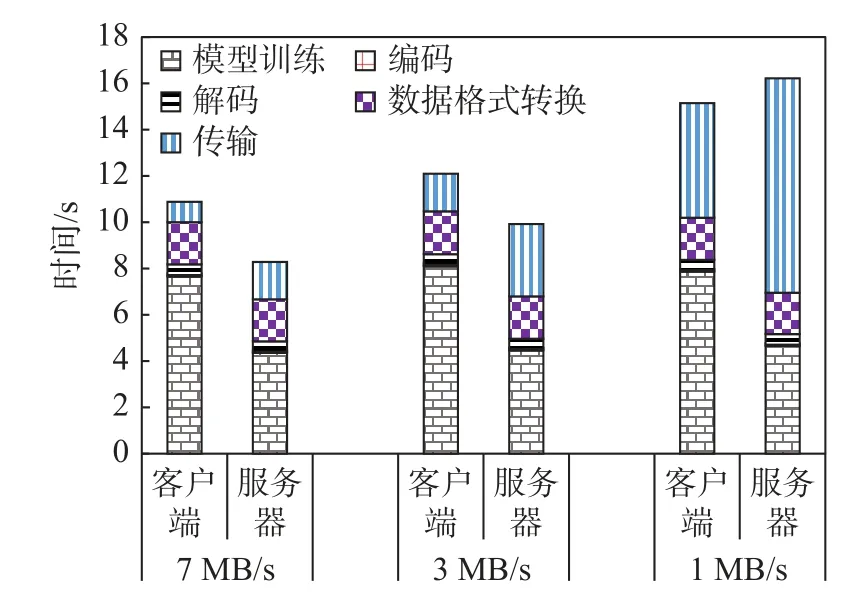
图6 边界场景下网速对系统影响Fig. 6 Impact of network speed on system in boundary scenarios
结合以上实验, 基于服务器的任务分发方案更适用于存在多掉队者场景下的通用FL 训练. 同时,基于客户端的任务分发方案能够补足网速较慢的场景, 能够使HCFL 系统适用于大多数场景.
4 结 论
为了应对掉队者带来的挑战, 并提高异构FL 的整体效率, 以及在掉队者计算任务加速过程中保护数据隐私, 本文提出了异构编码联邦学习(HCFL)框架. HCFL 框架中分别从客户端以及服务器的角度设计了多掉队者任务分发算法, 能够选取合适的设备, 并分配合适的任务量来完成计算任务分发.此外, 系统中设计了利用线性编码保护数据分发过程中隐私问题的线性编码计算方案. 最后, 大量实验表明, 当设备之间性能存在较大差异时, HCFL 能够将掉队者训练时间减少89.85%, 并且以多次全量地调度掉队者的方法保证了模型的精度.
猜你喜欢
小学教学研究(2022年5期)2022-04-28
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
电子测试(2018年10期)2018-06-26
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
