
基于空间域和频率域方法的烟雾检测
2023-09-22 01:09:54盛连军汤致轩茅晓亮黄定江
华东师范大学学报(自然科学版) 2023年5期
盛连军, 汤致轩, 茅晓亮, 白 帆, 黄定江
(1. 国网上海市电力公司 奉贤供电公司, 上海 201499; 2. 华东师范大学 数据科学与工程学院,上海 200062; 3. 上海深其深网络科技有限公司, 上海 200439)
0 引 言
变电站[1]等工业场景内有油浸变压器、输配电线路开关、高压电容器等易燃设备, 容易发生火灾,而火灾发生的前期一般伴随烟雾的产生, 若能在明火出现之前通过检测产生的烟雾进行火灾预警, 则可以有效预防火灾的发生. 因此, 在变电站内进行烟雾检测对保障变电站的安全具有重要意义. 目前,变电站内基本配备有监控摄像头, 这使得使用监控视频进行烟雾检测的方式成为可能.
变电站等工业场景与普通场景, 如民用通道、商场等之间存在着明显的区别. 主要体现在两个方面: 第一, 光照条件不同. 变电站等工业场景通常处于零照度, 使用的是红外补光摄像头采集数据, 而民用通道、商场等场景通常采用可见光的RGB (red, green, blue)数据进行采集, 红外图像是通过获取物体红外光的强度所形成的图像, 可见光图像则是通过相机直接捕捉物体反射的可见光所形成的图像, 这两种数据在本质上存在着差异. 第二, 背景复杂度不同. 在变电站等工业场景中, 背景主要由开关柜、墙面等构成, 相对整洁、简单, 而在民用通道、商场等场景中, 背景包含了人物、各种物体和结构, 呈现出较为复杂多样性特点. 所以, 变电站等工业场景与普通场景在光照条件和场景背景方面存在着明显差异. 本文主要针对零照度红外补光下的变电站等工业场景进行研究和设计算法.
在针对变电站等工业场景的烟雾检测任务中, 现有技术存在两个主要的难点: 第一, 算法的应用场景主要针对变电站等工业场景, 这些场景通常为零照度条件, 这与普通的可见光条件有根本性的区别, 这种特殊条件使得问题变得更具有挑战性. 现有的很多烟雾检测方法, 如基于暗通道先验、可见光RGB 转HSV (hue, value, staturation)色彩空间等常用技术在这种情况下不再适用, 常规方法无法提供可靠的烟雾检测结果. 第二, 如果仅依赖变电站等工业场景已配备的物理传感器, 如感烟报警器等, 只能得到简单的烟雾告警或非告警信号, 而无法获取图像信息. 这种情况下, 无法确定烟雾出现的具体位置, 从而给工作人员的核验带来困难. 然而, 在工业环境中, 准确获知烟雾的位置信息对于及时采取适当的应对措施至关重要[2], 例如确定烟雾源、调整通风系统或启动紧急应对程序等.
综上所述, 烟雾检测领域面临的两个主要难点是应对变电站等场景的零照度条件和传统烟雾传感器无法提供烟雾位置信息的挑战. 因此, 为了解决这些问题, 设计能够应对零照度条件的视觉烟雾检测方法以应对这些难点具有重要意义, 旨在提高烟雾检测的实用性和可靠性, 以有效预防变电站等工业场景的火灾发生, 进而确保工业环境的安全性.
在监控视频画面中, 本文定义的“蒙版特性”是指烟雾出现时所引发的一种视觉效应, 其中在烟雾出现的覆盖区域内产生模糊效果, 类似于将一层灰色蒙版叠加在原始画面上, 而导致的图像块中像素的灰度值整体上升或下降. 本文将该视觉效应定义为烟雾的灰度蒙版特性. 本文定义的“刚体运动”是指在物体运动中, 其形状和尺寸保持不变的一种运动模式. 在刚体运动中, 假设物体的内部结构不发生变化, 物体各个部分以相同的速度和方向进行平移或旋转, 且相对位置保持不变, 那么物体的形态在整个运动过程中保持恒定.
本文提出了一种基于空间域和频率域方法的烟雾检测算法, 通过在空间域提取烟雾运动特性和蒙版特性的方式, 有效地检测疑似烟雾区域, 从而保证了较低的漏检率; 此外, 利用频率域中的信息排除非烟雾的刚体运动, 进一步降低了误检率, 使误检率和漏检率达到了良好的平衡, 并且所提算法仅使用灰度图像进行烟雾检测, 更好地符合了实际工业应用场景的需求.
1 相关工作
目前, 烟雾检测方式主要包括基于物理烟雾感应器和基于视频图像这两种方式. 本文关注基于视频图像的方式, 此方式包括基于传统图像特征的方法和基于深度神经网络(deep neural network,DNN)的方法.
1.1 基于传统图像特征的方法
基于传统图像特征的方法主要是利用烟雾的特征来检测: 首先选取烟雾的候选区域; 然后提取烟雾特征; 最后进行烟雾检测. 宋伟等[3]利用改进的ViBe (visual background extractor) 算法和颜色特征确定疑似烟雾区域, 并结合烟雾面积增长和移动特性识别烟雾区域, 实现了变电站场景的烟雾检测.Töreyin 等[4]利用小波变换分析图像高低频能量, 并结合烟雾边界的周期性和烟雾区域的凸性进行检测, 具有较好的烟雾检测效果. Yu 等[5]提出了一种用于实时火灾烟雾检测的纹理分析方法, 利用灰度共生矩阵分析烟雾纹理特性, 并使用神经网络对烟雾纹理特征和非烟雾纹理特征进行分类, 该方法具有较低的误检率. Alamgir 等[6]提出了一种烟雾检测方法, 该方法将局部二值化模式与 RGB 颜色空间中纹理特征的共现相结合, 以表征烟雾的不同表现形式, 首先从候选烟雾区域中提取烟雾特征, 然后使用支持向量机基于特征进行训练和分类, 以区分烟雾和非烟目标.
1.2 基于DNN 的方法
近年来, 随着深度学习的不断发展, 通过各种神经网络提取更高级、更抽象的特征成为可能, 例如通过卷积神经网络(convolution neural network, CNN)[7]提取特征. 因此, 越来越多的研究者致力于从深度学习的角度出发进行烟雾检测, 促进其在工业领域的应用. 赵丽宏等[8]提出了一种基于CNN 的火灾烟雾视频检测算法, 该算法首先提取可疑区域的烟雾特征, 然后进行模式分类, 最终实现对烟雾的检测. Gagliardi 等[9]提出了一种混合算法来识别视频序列中的烟雾, 该算法结合了基于卡尔曼滤波和运动检测的传统特征检测器, 以及CNN, 提高了视频序列中烟雾检测的速度和精度. Valikhujaev等[10]提出了一种基于扩张CNN 的火灾烟雾自动检测方法, 该方法采用包含扩展卷积的CNN, 具有较高的分类性能. Wu 等[11]提出了一种基于稠密光流和CNN 的两阶段视频烟雾检测方法, 充分利用视频中烟雾的运动特点来提高检测精度. Mardani 等[12]提出了基于Transformer 的视频火灾检测网络,通过计算注意力分数, 识别视频帧中的火焰, 完成分类和检测任务, 从而进行火灾探测. Almeida 等[13]提出了一种轻量级CNN 模型用于对RGB 图像进行野火检测, 并实现了边缘部署, 具有较强的应用性. Chen 等[14]提出了一种改进的纺织车间混合高斯和YOLOv5 烟雾检测算法, 该算法首先采用改进的高斯混合算法提取疑似烟雾区域, 然后在YOLOv5 网络的特征金字塔结构中加入自适应注意力模块, 提高多尺度目标识别能力, 完成烟雾检测, 具有较高的检测精度. de Venâncio 等[15]提出了一种基于空间和时间的火灾探测方法, 此方法分为两个阶段, 第一阶段通过基于视觉的CNN 检测可能的火灾事件, 第二阶段分析事件随时间的动态特征以确定是否为火灾事件, 从而降低误报率. Wu 等[16]提出了一种基于改进YOLOv5 的视频火灾检测方法, 通过在YOLOv5 的SPP (spatial pyramid pooling)模块中引入扩展卷积模块, 并采用激活函数GeLU (Gaussian error linear unit)和预测边界框抑制DIoU (distance-IoU (intersection over union))-NMS (non-maximum suppression)的方式, 提高特征提取和小目标检测能力, 该方法检测速度较快, 精度较高. Yuan 等[17]提出了一种跨尺度混合注意力网络, 通过设计多尺度混合注意力模块, 充分融合跨尺度的信息, 进行烟雾图像分割, 该网络模型效果较好. Ahn 等[18]开发了一种基于计算机视觉的早期火灾探测模型, 实验结果表明召回率和精度较高,且检测速度较快. Huo 等[19]提出了一种基于深度可分CNN 的多尺度目标检测算法, 用于图像烟雾检测, 能更好地提取特征和增强目标检测, 具有较高的准确率.
基于视频图像的烟雾检测有越来越多的研究, 识别的方法和种类也在不断发展, 但面临的挑战也从未中断. 基于传统图像特征的方法大多利用烟雾在RGB 颜色通道、HSV 色彩空间中的特性进行检测, 但对于很多工业场景零照度下的红外灰度视频图像, 其色彩特性无法利用, 检测挑战性高; 基于DNN 的方法大部分基于图片对烟雾进行识别, 难以结合烟雾在时间维度的变化信息, 检测难度高. 当前, 基于视频的烟雾检测技术仍处于发展阶段, 烟雾检测的误检率和漏检率也需进一步降低和平衡,以适应工业应用场景的需求.
2 算法介绍
针对工业场景的烟雾检测算法在误检率和漏检率上较高且难以平衡的问题, 本文提出了一种基于空间域和频率域方法的烟雾检测算法, 算法的总体框架如图1 所示.

图1 基于空间域和频率域的烟雾检测算法框架Fig. 1 Algorithm framework of smoke detection based on spatial and frequency domains
本文所提算法采用基于空间域和频率域的方式, 即对视频样本同时在空间域和频率域进行处理,然后融合检测结果. 算法的具体操作: 首先, 对原始视频帧序列进行图像预处理; 然后, 进行图像分块处理, 得到分块后的图像, 在此基础上, 对分块的图像分别在空间域和频率域上进行处理, 在空间域上, 分别提取烟雾的运动和蒙版特性, 在频率域上, 对频率域处理基本单位进行三维离散傅里叶变换,再分别通过传统滤波方式和深度三维卷积神经网络方式进行烟雾检测; 最后, 在融合后处理策略部分,融合空间域和频率域的烟雾检测信息, 确定烟雾检测结果.
从物理意义的角度来说, 在空间域上, 烟雾在空间域中呈现出像素级的运动和密度变化, 通过利用烟雾运动特性和设计烟雾蒙版特性提取方法, 能够准确地检测出烟雾区域, 从而降低漏检率; 在频率域上, 随时间变化的烟雾在频率域中表现为特定频率范围内的能量变化, 通过频率域分析可以揭示烟雾在不同频率上的特征, 这些特征与烟雾的纹理、结构、随时间变化的强度等属性相关, 通过结合滤波模块和神经网络模块, 进一步降低误检率, 准确地识别烟雾区域. 通过分析烟雾的物理意义, 利用烟雾在不同域中的物理特征, 从而实现高效、准确的烟雾检测.
2.1 基于空间域的烟雾检测
现有的基于空间域的烟雾检测方法大部分以像素点为单位, 但是会存在噪声敏感等缺陷, 这导致了烟雾检测效果不理想. 为克服上述缺点, 本文提出了基于图像块进行烟雾检测的方式, 空间域分块示意图如图2 所示: 当前图像帧与其前 Δc个图像帧按一定粒度划分为图像大块; 将划分的图像大块作为空间域处理的基本单位.

图2 空间域分块示意图Fig. 2 Schematic of block division in the spatial domain
2.1.1 运动特性提取
在火灾发生的时候, 受热气流影响, 烟雾在视觉上存在随时间动态运动和扩散的特性, 此特性反映在视频中是随着视频序列的推进, 视频帧中的像素产生变化. 因此, 使用良好的运动检测能有效缩小检测范围, 获得疑似烟雾区块.
常见的运动区域检测算法主要有3 种: 背景减除法[20]、光流法[21]和帧间差分法[22]. 背景减除法对亮度和背景变化敏感; 光流法计算量大, 算法实时性难以保证; 帧间差分法算法复杂度和计算量低, 实时性高. 因此, 本文结合烟雾运动特性和算法实时性要求, 采用帧间差分法提取疑似烟雾运动区块. 帧间差分法利用视频帧的时间差分来提取连续图像序列中相邻几帧之间的运动区域. 该方法首先求得相邻图像帧之间所对应的像素值之差, 得到差分后的图像, 然后对差分图像进行二值化处理, 从而提取运动区域和背景.
Δc
本文使用基于图像分块的帧间差分方式, 针对当前图像的每个图像大块, 如果与前 帧的对应图像大块内像素灰度差异绝对值的均值大于阈值, 则判定此图像块为疑似烟雾区块, 否则, 判定为非疑似烟雾区块. 相应判断公式为
式(1)中:Hb为图像分块的块高;Wb为图像分块的块宽;x、y分别表示像素位置的横坐标和纵坐标;bij表示图像分块中位于第i行第j列的图像块;f(x,y,c) 表示在第c帧上, 坐标为 (x,y) 的像素值;f(x,y,c-Δc) 表示在第 (c-Δc) 帧上, 坐标为 (x,y) 的像素值;Td为判定阈值, 可根据实际部署场景进行调整.
2.1.2 蒙版特性提取
在监控视频画面中, 烟雾的出现会使其覆盖区域变得模糊, 类似于在原始画面上蒙上了一层灰色蒙版, 使得图像块中像素的灰度值整体上升或者下降, 故本文将其定义为烟雾的灰度蒙版特性. 对于视频中实物等刚体的运动, 由于其边缘轮廓清晰, 不存在这样的灰度蒙版特性. 因此, 本文利用烟雾和实物等刚体运动之间这样不一致的特性, 进一步区分运动物体的类别, 从而提取疑似烟雾运动区块.
本文认为, 针对当前图像的每个图像大块, 如果与前 Δc帧对应图像大块内像素灰度差异的标准差小于阈值, 则判定此图像块为疑似烟雾区块, 否则, 判定为非疑似烟雾区块. 相应判断公式为
式(2)中:Ts为判定阈值;为图像中位于第i行、第j列的图像块中所有像素点的f(x,y,c)-f(x,y,c-Δc) 的均值; 其余符号含义与式 (1) 相同.
2.2 基于频率域的烟雾检测
早期, 频率域技术常用于音频等一维信号处理领域, 后来逐渐运用于图像处理领域, 包括图像增强、去噪、特征提取等. 常见的频率域变换方式有3 种: 傅里叶变换[23]、离散余弦变换[24]和小波变换[25].本文使用最通用和最常见的傅里叶变换方式, 即三维离散傅里叶变换. 在本文视频数据中, 对于一个大小为M×N ×P的输入张量, 三维离散傅里叶正变换公式为
式 (3) 中:M为视频中帧的宽;N为视频中帧的高;P为视频中连续的帧数;u、v、w分别为频率域中的坐标轴;x、y、z分别为空间域中的坐标轴;F(u,v,w) 为在频率域坐标 (u,v,w) 处的频率分量;f(x,y,z) 为输入张量在坐标 (x,y,z) 处的像素值;u=0,1,2,··· ,M -1 ;v=0,1,2,··· ,N -1 ;w=0,1,2,··· ,P -1.
公式 (3) 相应的傅里叶逆变换公式为
式(4)中各符号含义与式 (3) 相同.
在空间域中, 本文利用烟雾运动和蒙版特性将视频帧划分为图像块; 在频率域中, 本文考虑频率属于更为底层的特性, 从而进一步将空间域中的图像块划分为更小的块, 并分析这些小块中的频率域特性.
在图像处理中, 最常用的是使用二维离散傅里叶变换将图像从空间域转换到频率域, 从另一个角度来观察分析图像. 但是, 此方法缺乏对烟雾变化时间维度信息的利用. 本文为提取和利用时间维度信息, 进一步堆叠连续视频帧, 形成三维张量, 并在此基础上进行处理. 频率域上的分块和连续帧堆叠示意图如图3 所示: 当前图像帧与其前连续 Δc个图像帧按一定粒度划分图像大块; 将每个图像大块划分为粒度更小的图像小块; 将图像小块作为频率域处理的基本单位, 即划分的图像小块的堆叠.
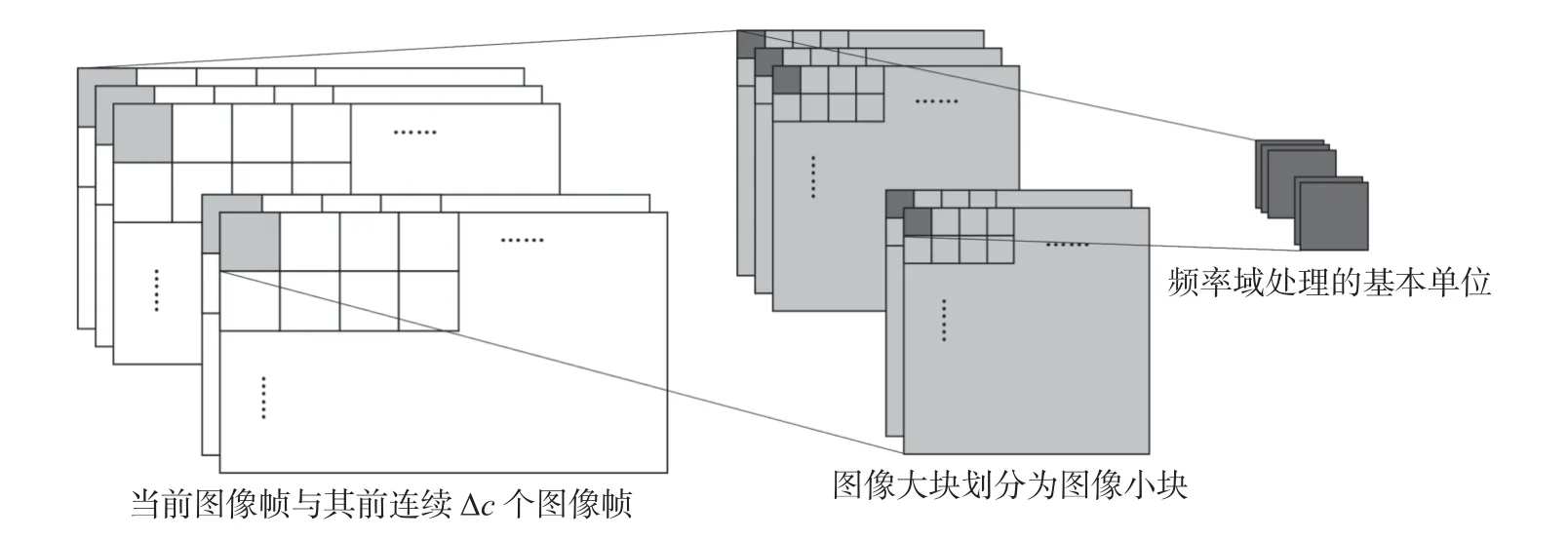
图3 频率域分块示意图Fig. 3 Schematic of block division in the frequency domain
图4 为三维傅里叶变换结果: 图4(a)、图4(c)分别为堆叠烟雾序列中连续8 个图像帧和堆叠相同的8 个图像帧, 其中, 图像大小为 (320 × 176) 像素, 按 (8 × 8) 像素分成图像小块, 共880 个图像小块; 图4(b)、图4(d)分别为图4(a)和图4(c)进行三维傅里叶变换的频谱结果, 其右侧的色度条表示的是频谱中各散点颜色所代表的颜色数值, 数值轴表示的是频域3 个维度的坐标轴信息. 对图4(b)的结果进行分析: 对于880 个三维频谱有烟雾喷射的区域, 其在时间维度上存在变化, 因此, 频谱中此部分w维度的亮度相对于画面中的其他部分亮度较高, 即w维度的频谱幅值较高, 表明此部分为时间上的高频信息, 需要对应w维度幅值较大的正弦波来刻画此变化; 另外, 很明显地, 中间层的亮度明显高于其他层, 可以理解为沿u维度、v维度的正弦波主要用于构成三维张量信息, 沿w维度的正弦波主要刻画时间上的变化, 而时间上的变化相对于图像纹理变化较弱, 因此, 对应正弦波的幅值较低.

图4 三维傅里叶变换结果Fig. 4 Results of 3D Fourier transform
作为对比, 图4(d)为堆叠相同的8 个图像帧并进行傅里叶变换的频谱结果. 不难发现,w维度中间层的幅值较高, 其余层幅值为0, 这表明, 中间一层频谱是用来刻画这张图像的频率域信息的, 而其他的层则描述变化, 相同的图像堆叠不存在变化, 因此其他层幅值为0. 这也表明三维频谱包含了连续视频帧时空维度的信息, 可以对其进行进一步利用.
下面主要介绍本文在频率域进行的传统滤波方式和DNN 分类方式.
2.2.1 频率域滤波
本文观察并分析了烟雾在频率域信息中的两个特性: 第一, 烟雾图像在时间维度上是变化的, 这个特性在三维频率域上表现为时间维度上的高频信息, 由此, 可以设计滤波器, 取时间维度的高频信息, 过滤掉时间维度的低频信息, 从而得到运动信息; 第二, 烟雾的出现会伴随其覆盖区域画面整体呈现模糊的状态, 即区域的边缘和细节纹理信息减少, 而边缘和细节纹理对应图像中的高频信息, 这在频率域上表现为在空间维度上的低频信息较强, 高频信息削减, 而实物等刚体的运动则为高频信息较强, 低频信息较弱, 由此, 可以设计滤波器, 取空间上的高频信息来提取实物等刚体运动. 为得到烟雾运动, 将上述两部分变换回空间维度并作差, 从而得到烟雾区域.
频率域滤波处理的流程图如图5 所示: 首先, 将频率域处理的基本单位进行三维离散傅里叶变换,将变换后的复数频谱转换为幅值频谱, 再进行中心化处理, 此频谱越靠近频谱中心的为低频信息, 越远离张量中心的为高频信息; 然后, 根据烟雾特性设计2 个三维滤波器, 分别提取频率域信息中的运动部分和实物运动部分, 再分别进行频谱中心化和三维离散傅里叶逆变换; 最后, 通过图像处理的方式, 提取烟雾区域.

图5 频率域滤波流程图Fig. 5 Flowchart of filtering in the frequency domain
本文设计的第一个滤波器只保留时间维度的高频信息, 去除时间维度的低频信息, 即只提取图像中所有运动部分. 该滤波器公式为
式 (5) 中:HI(u,v,w) 为频率域坐标 (u,v,w) 处频率幅值, 1 表示保留此位置频率域信息, 0 表示去除此位置频率域信息;TUp,w、TLow,w分别为w维度的上阈值和下阈值.
本文设计的第二个滤波器只保留时间维度和空间维度的高频信息, 即只提取图像中实物等刚体运动部分. 该滤波器公式为
式(6)中:TUp,u、TLow,u分别为u维度的上阈值和下阈值;TUp,v、TLow,v分别为v维度的上阈值和下阈值; 其余符号含义与式 (5) 相同.
为了更加直观地表述, 本文构建了以上2 个三维滤波器作为示例, 图6 分别是这2 个三维滤波器的可视化散点图, 其右侧的色度条表示的是三维频域率滤波器各散点颜色所代表的数值, 数值轴表示的是滤波器3 个维度的坐标轴信息. 在本文的示例中, 设定0 ≤u<8,0 ≤v <8,0 ≤w <8,TLow,w,TLow,u,TLow,v=2,TUp,w,TUp,u,TUp,v=5.图6(a)为只保留时间维度高频信息的滤波器, 图6 (b)为只保留时间维度和空间维度的高频信息的滤波器. 其中,u 轴、v轴分别为图像的宽和高的维度,w轴为时间维度, 黄色散点代表值为1, 即保留此位置频率域信息, 紫色散点代表值为0, 即去除此位置频率域信息. 将滤波器和频率域张量按位相乘, 得到滤波后的频率域张量.

图6 三维频域率滤波器Fig. 6 3D filter of the frequency domain
在图像处理过程中, 处理频率域滤波后变换回空间域的图像帧. 首先, 分别对运动部分和实物等刚体部分二值化, 并对实物等刚体部分进行膨胀; 然后将两部分作减法运算, 结果为负数部分置为0;最后, 为去噪和平滑烟雾轮廓, 进行开运算, 得到烟雾区域. 图像处理流程图如图7 所示.

图7 图像处理流程图Fig. 7 Flowchart of image processing
图像处理示例如图8 所示: 图8(a)为经过预处理的原图像帧, 其中存在烟雾区域和发烟器绳子晃动; 图8(b)为二值化后的所有运动部分; 图8(c)为经过二值化和膨胀后的实物运动部分; 图8(d)为烟雾区域结果. 可以看到, 滤波后较为准确地提取了所有运动区域以及实物等刚体运动区域; 通过图像处理技术, 可得到烟雾区域, 减少了误检的发生.

图8 图像处理示例Fig. 8 Examples of image processing
2.2.2 三维CNN 分类
三维CNN[26]能够更好地提取三维数据的特性. 由此, 本文设计了三维CNN 来提取三维频谱数据的特征. 三维CNN 的输入特征图尺寸通常为N×C×D×H ×W, 其中,N表示批大小,C表示通道数,D、H、W分别为输入特征张量的深度、高度和宽度.
本文使用PyTorch 深度学习框架构建三维CNN 模型, 简称为SmokeNet. 该模型用于烟雾检测,接受上述傅里叶变换后的频谱张量为输入, 输出一个二元分类结果, 表示输入的张量是否包含烟雾.该模型包含两个主要部分: 特征提取部分和分类器部分. 特征提取部分由卷积层、批量归一化层、激活函数层和随机失活层组成, 用于提取输入数据的特征; 分类器部分由一个全连接层组成, 用于将特征映射到二元分类结果. 模型网络结构如图9 所示. 其中, 3D tensor 表示输入网络的三维张量,Conv3d 表示三维卷积层,k表示卷积核大小,s表示步幅大小,p表示填充大小, BatchNorm3d 表示三维归一化层, ReLU 表示修正线性单元激活函数, Dropout 表示随机失活层, Linear 表示全连接层,Result 表示二分类结果.

图9 三维CNN SmokeNet 结构Fig. 9 3D CNN SmokeNet structure
2.3 融合后处理策略
融合后处理策略部分的作用是融合空间域和频率域的检测结果, 得到烟雾检测的最终结果. 引入3 个阈值, 确定后处理策略, 从而降低烟雾检测的误检率.
算法伪代码见算法1. 其中,λ1用于确定某一烟雾大块是否为烟雾区块, 若此图像大块中有烟小块的占比大于λ1, 则判定此大块为烟雾区块, 否则, 为非烟雾区块;λ2用于确定某一视频帧是否为烟雾视频帧, 若此视频帧中烟雾大块的占比大于λ2, 则判定此视频帧为烟雾视频帧, 否则, 为非烟雾视频帧;λ3用于判定视频样本是否为烟雾样本, 若此视频样本中有烟视频帧的占比大于λ3, 则判定此视频样本为烟雾样本, 否则, 为非烟雾样本.

算法1 基于空间域和频率域的烟雾检测算法输入: 一段1 ~ 2 s 的烟雾视频输出: 视频样本中是否包含烟雾1: 对视频帧预处理Δc 2: 对视频帧分小块并连续堆叠 帧, 形成三维张量, 将张量转换到频率域3: 在频率域滤波处理并转换到图像域, 判定图像小块是否为有烟小块4: DNN 判断小块所处三维张量是否为有烟张量, 并以此判定图像小块是否为有烟小块5: 变量初始化:sum = 0, sumBig = 0, count = 0, countBig = 0 6: ForEach 视频图像帧 do 7: sum++8: 对此帧分图像大块9: ForEach 图像大块 do 10: sumBig++11: 计算每块与其前帧对应图像大块的差分和标准差12: If 差分满足2.1.1 节疑似烟雾判定&&标准差满足2.1.2 节疑似烟雾判定 do 13: 对此图像大块分小块, sumSmall = 0, countSmall = 0 14: ForEach 图像小块 do 15: sumSmall++16: If 图像小块在行3 中判定为有烟小块 &&在行4 中判定为有烟小块 do 17: countSmall++18: End if λ1 19: If countSmall /sumSmall> do 20: 确定此图像大块为烟雾区块21: countBig++22: End if 23: End if λ2 24: If countBig / sumBig > do 25: 确定此图像帧为存在烟雾图像帧26: count++27: End if λ3 28: If count /sum > do 29: 返回此视频样本中包含烟雾30: Else do 31: 返回此视频样本中不包含烟雾32: End if
3 实 验
3.1 数据集采集和标注
3.1.1 数据集搜集和采集
本文实验所使用的数据集包含3 个部分, 分别为模拟变电站场景的烟雾数据集、中国科学技术大学火灾科学国家实验室的公开烟雾数据集、互联网上搜集的数据. 实验数据集来源多样, 发烟方式较多, 具有较强的普遍性.
1) 模拟变电站场景的烟雾数据集
由于变电站不允许烟火实验, 因此理想的实验数据较难获取. 本文针对变电站典型场景采集数据集, 使用红外补光摄像头, 发烟方式包括发烟器发烟、电烙铁发烟、燃烧艾条、燃烧碎纸、抽烟等5 种,并包含不同的摄像头角度和烟雾浓度; 采集视频为122 个有烟视频和135 个无烟视频.
2) 中国科学技术大学火灾科学国家实验室的烟雾数据集[27]
中国科学技术大学火灾科学国家实验室的烟雾数据集分别包含3 个有烟视频和无烟视频.
3) 互联网上搜集的数据
本文以与“烟雾”相关的词语为关键词在互联网上搜集相关视频数据, 共搜集到烟雾视频32 个,场景包括车间、室内、变电站等.
图10 为本文部分数据样本实例: 图10(a)为模拟变电站场景的烟雾数据集中的数据, 发烟方式为烟机发烟, 摄像头录制角度较低; 图10(b)为模拟变电站场景的烟雾数据集中的数据, 发烟方式为燃烧碎纸, 摄像头录制角度较高; 图10(c)为中国科学技术大学火灾科学国家实验室烟雾数据集中的数据,画面包含人物移动和起火过程中产生的烟雾; 图10(d)为互联网上搜集的数据, 画面包含电器燃烧过程中产生的烟雾.

图10 采集数据示例Fig. 10 Examples of data collected
3.1.2 数据预处理
本文对数据集进行标注和预处理, 然后在此基础上进行实验.
在数据预处理阶段, 首先对数据进行清洗, 删除包含坏帧、摄像头移动、镜头变焦等片段的脏数据, 并且将视频划分成1 ~ 2 s 的视频片段, 共得到正样本片段400 个, 负样本片段380 个, 并按6∶2∶2 的比例随机划分为训练集、验证集和测试集.
在数据标注阶段, 根据视频片段中是否有烟来确定正/负样本, 即视频片段中有烟为正样本, 无烟为负样本. 另外, 为训练2.2.2 节所述的DNN, 使用CVAT (computer vision annotation tool) 标注工具对数据预处理后的视频帧进行标注, 标注采用多边形语义分割的方式.
3.2 实验环境
实验的服务器配置和环境: CPU 为12th Gen Intel(R) Core(TM) i7-12700; GPU 为RTX3080; 显存大小12 GB; 内存大小128 GB; NPU 为瑞芯微RK3588; 操作系统为Linux; 编程语言Python; 所采用的深度学习框架PyTorch.
3.3 算法评价指标
本文用于算法评价的标准为误检率和漏检率.
(1) 误检率: 定义为在真实所有负样本中, 被错误预测为正样本的比例, 亦称为假阳性率, 用RFP表示. 其计算公式为
式(7)中:NFP为负样本预测为正样本的数量;NTN为负样本预测为负样本的数量.
(2) 漏检率: 定义为在真实所有正样本中, 被错误预测为负样本的比例, 用RFN表示. 其计算公式为
式(8)中:NFN为正样本预测为负样本的数量;NTP为正样本预测为正样本的数量.
3.4 实验参数配置
3.4.1 基于空间域检测的参数配置
在2.1.1 节的烟雾运动特性提取中,Hb、Wb均为80, Δc为8,Td为2.3; 在2.1.2 节的烟雾蒙版特性提取中,Ts为6.4.
3.4.2 基于频率域检测的参数配置
在2.2.1 节的滤波器设置中, 设置 0 ≤u<8 , 0 ≤v <8 , 0 ≤w <8 ,TLow,w,TLow,u,TLow,v=1,TUp,w,TUp,u,TUp,v=6;在2.2.2 节的神经网络训练过程中, 设优化函数为Adam, 学习率为1.0 × 10–5,batch size 设为256, epoch 设为50.
3.4.3 融合后处理的参数配置
在2.3 节融合后处理设置中,λ1设为0.04,λ2设为0.03,λ3设为0.12.
3.5 实验结果分析
3.5.1 参数选择实验
在三维CNN 分类的实验中, 分块部分全为人工标注的烟雾部分才确定为分类正样本, 否则, 为分类负样本. 由此进行训练, 并通过验证集表现调整学习率、优化函数等超参数, 最终在验证集上的准确率为0.93.
在融合后处理阈值的选取上, 对于λ1、λ2、λ3这3 个阈值, 由于λ1、λ2的选择较为固定, 因此, 本文对λ3的选择进行实验, 以获取更好的阈值. 接收者操作特征曲线也称ROC (receiver operating characteristic) 曲线, 是一种坐标图式的分析工具, 可以通过变化阈值绘制曲线, 从而在算法中设置最佳阈值. 本文在验证集上, 对不同的λ3数值进行选择并计算真阳性率 (RTP) 和假阳性率 (RFP) , 绘制关于λ2阈值的ROC 曲线, 如图11 所示. 其中, 纵轴真阳性率RTP亦为召回率, 定义为在真实所有正样本中, 被正确预测为正样本的比例,RTP=NTP/(NTP+NFN); 横轴RFP是假阳性率, 也就是评价指标的误检率; 绿色曲线为ROC 曲线; 红色虚线为完全随机(random chance)的分类曲线. 图11 中, 一个点越接近左上角, 说明此参数下算法的预测效果越好. 因此, 本文选取ROC 曲线最接近左上角的点所对应的阈值作为λ3的阈值, 为0.12.

图11 ROC 曲线Fig. 11 ROC curve
3.5.2 消融实验
本文在上述数据集上, 对算法的不同部分进行了实验, 表1 展示了各部分的实验结果. 由表1 可以看到, 本文算法(基线算法 + 蒙版特性 + 频域滤波 + 三维神经网络)在给定的数据集上取得了较好的结果, 其误检率为0.053, 漏检率为 0.113. 基线算法表示仅使用烟雾运动特性的方法. 在基线算法上增加烟雾蒙版特性模块, 漏检率无明显增加, 误检率小幅降低; 进一步加入频率域滤波模块后, 相较于使用基线算法 + 蒙版特性方法, 虽然漏检率上升了0.063, 但误检率大幅降低了0.605; 此外, 通过增加三维神经网络分类模块, 误检率进一步降低了 0.013.

表1 不同模块的实验结果Tab. 1 Results of different modules
因此, 提取烟雾的运动和蒙版特性, 能够获得较低的漏检率, 并且融合频率域进行烟雾检测, 能够在漏检率小幅上升的条件下, 大幅降低烟雾误检率, 算法最终达到漏检率和误检率的平衡, 能够有效提升变电站等工业场景下烟雾检测的性能.
3.5.3 对比实验
表2 列出了本文算法与文献[4] 基于小波变换的烟雾检测算法、文献[5] 基于纹理分析的烟雾检测算法、文献[16] 基于改进YOLOv5 的烟雾检测算法关于烟雾检测的误检率和漏检率的对比结果.

表2 误检率和漏检率对比实验结果Tab. 2 Results of false and missed detection rate comparison experiment
由表2 可知, 本文算法的误检率和漏检率均低于基于小波变换的烟雾检测算法, 基于小波变换的烟雾检测算法对复杂背景或画面中存在运动物体情况的误检率较高, 且烟雾漏检率较高, 对较薄的烟雾易产生漏检的情况, 而本文算法可以排除实物等刚体运动的干扰, 具有非常低的误检率, 并且通过烟雾运动和蒙版特性提取维持低漏检率. 基于纹理分析的烟雾检测算法使用灰度共生矩阵和分块的方式, 漏检率较低, 但是其误检率较高, 为0.092, 容易将与烟雾纹理特征相似的物体误检为烟雾, 这样的误检率难以匹配工业场景的应用要求, 而本文算法的误检率仅为0.053, 相比基于纹理分析的烟雾检测算法低了近4 个百分点, 并且漏检率相对较低, 为0.113. 基于改进YOLOv5 的烟雾检测算法对YOLOv5 目标检测网络进行了改进, 误检率较低, 为0.079, 但是其漏检率较高, 为0.173, 分析原因是此方法基于图像信息, 无法利用烟雾的运动特性识别烟雾, 导致早期的淡烟易存在漏检情况, 而本文算法的误检率和漏检率都较低.
与现有的算法相比, 本文算法在性能上做到了误检率和漏检率的平衡, 在保证非常低误检率的基础上, 具有较低的漏检率, 性能较好. 为了验证本文算法的效率, 本文进一步做了效率的对比实验, 即单张图片在GPU、CPU、NPU 上的平均推理时间. 实验在3.2 节中提到的实验平台上进行, 实验结果如表3 所示.

表3 效率实验结果Tab. 3 Results of efficiency comparison experiment
由表3 可知, 本文算法的单张图片推理时间在GPU、CPU、NPU 上分别为48 ms、161 ms 和65 ms,相比于未使用深度学习的基于小波变换的烟雾检测算法和基于纹理分析的烟雾检测算法推理速度较慢; 但是, 本文算法在误检率和漏检率上的综合表现相比于这两种算法要好很多; 而相比于在误检率上表现较好的基于改进YOLOv5 的烟雾检测算法, 本文算法的效率明显优于基于改进YOLOv5 的烟雾检测算法, 有较高的效率. 因此, 本文所提算法做到了性能和效率上的平衡, 能够对烟雾及时做出检测和响应, 作为服务于应急灾害的一种手段, 适用于变电站等实际工业场景环境的环境辅控.
3.5.4 实验结果
实验结果展示如图12 所示: 在行a 图像、行b 图像的数据中, 存在较少实物等刚体运动; 在行c 图像、行d 图像的数据中, 同时存在烟雾和实物等刚体运动, 行c 图像为晃动的烟机线, 行d 图像为走动的人物; 列A 为原始帧经过预处理后的视频帧; 列B 中标为红色区块的为符合烟雾运动特性的烟雾大块; 列C 标为绿色区块的为符合烟雾运动和蒙版特性的烟雾大块; 列D 中标为蓝色区块的为频率域处理判定为烟雾的图像大块; 列E 为算法最终检测出视频帧中的烟雾区块.

图12 烟雾检测结果示例Fig. 12 Examples of smoke detection results
从图12 所示的结果中可以看出, 本文算法在烟雾运动特性和蒙版特性提取模块中, 对烟雾的检测存在较低的漏检率, 在进行频率域处理后, 有效地去除了实物等刚体运动, 如烟机的线、行走的人等, 保证了算法具有很低的误检率. 因此, 本文算法虽然将少部分有烟区块判定为无烟区块, 但是所有检测为有烟的区块都为真实有烟区块, 即能够保证非常低的误检率, 同时, 具有较低的漏检率, 符合变电站等工业场景算法应用的需求.
4 结 论
基于变电站等工业场景, 本文基于空间域和频率域方法, 提出了一种新的烟雾检测算法. 在空间域上, 提取烟雾的运动和蒙版特性, 保证了较低的漏检率; 在频率域上, 分别通过传统滤波和DNN 的方式, 有效降低了误检率, 并且, 通过融合后处理策略结合空间域和频率域的中间结果, 得到烟雾检测最终结果. 实验证明, 本文提出的算法能够较好地平衡误检率和漏检率, 能够作为环境辅控手段, 进一步提升变电站等工业场景的安全性.
猜你喜欢
小学阅读指南·低年级版(2021年3期)2021-03-19 06:12:40
天天爱科学(2020年6期)2020-09-10 07:22:44
华人时刊(2019年13期)2019-11-26 00:54:38
中华诗词(2019年7期)2019-11-25 01:43:00
当代陕西(2017年12期)2018-01-19 01:42:05
美术文献(2016年6期)2016-11-10 09:09:40
灯与照明(2016年4期)2016-06-05 09:01:45
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:24
全球定位系统(2015年4期)2015-02-28 12:38:08
科学启蒙(2014年12期)2014-12-09 05:47:06
