
基于并行深度森林的配用电通信网络异常流量检测
2023-09-22 01:09周政雷潘俊涛袁培森
华东师范大学学报(自然科学版) 2023年5期
周政雷, 陈 俊, 潘俊涛, 袁培森
(1. 广西电网有限责任公司 计量中心, 南宁 530024; 2. 南京农业大学 人工智能学院, 南京 210031)
0 引 言
随着新一代电力系统的不断升级改造, 智能化电网接入数据的种类及数量呈现几何级倍数增长的态势. 随着配用电领域业务的深化应用与创新, 各类新设备、新功能对配用电终端的智能化程度与灵活扩展能力提出了更高的要求, 但也大幅增加了针对配用电无线专网的异常流量入侵风险[1]. 由于配用电通信网络与居民、工商业用户的生产生活息息相关, 网络攻击事件极有可能会引发用户侧的异常断电, 造成重大安全生产事故与经济损失[2].
配用电终端采用《电能信息采集与管理系统 第4–5 部分: 通信协议—面向对象的数据交换协议》(DL/T 698.45—2017, 简称《面向对象的数据交换协议》) 、《远动设备及系统 第5 部分: 传输规约第102 篇: 电力系统电能累计量传输配套标准》 (DL/T 719—2000, 简称《电力系统电能累计量传输配套标准》) 等通信规约接入无线电力专网. 电力无线信道随着业务变动、通信质量波动存在通信延迟、流量多变等情况. 因此, 通信流量具有特征维度高、非线性变化的特点[3], 这对异常检测处理的时效性与准确性提出了巨大的挑战. 针对此, 现有研究大多对报文流量特征进行分析, 从而诊断异常流量[4], 采用数据挖掘技术对正常模式与异常入侵模式的偏差进行判别. 张嘉誉等[5]基于报文特点提出了一种融合物理信息和差分序列方差的智能过程层变电站网络异常流量检测方法, 通过攻击条件阈值计算和识别异常流量; Qiang 等[6]提出了一种通过阈值模型来表征变电站通信网络流量, 实现了对网络流量突增等异常情形的检测, 并针对通用面向对象变电站事件提出了异常行为分组方法;Robert 等[7]提出了一种入侵检测方法, 即基于监控行为规则, 检测网络中存在的异常流量. 以上这些方法属于使用预先建立的规则进行阈值和规则的匹配, 然而实际运行中, 配电网络流量的波动会造成这些方法存在漏检、误判风险高、阈值的不准确设定等不足. 部分学者使用人工智能相关技术研究网络流量异常检测问题[8]. 吕政权等[9]提出了一种基于门控循环神经网络和卷积神经网络提取流量特征,结合softmax 分类器来实现异常流量检测; 田伟宏等[10]研究了采用注意力机制的长短期记忆神经网络算法, 结合卷积神经网络与长短期记忆递归神经网络的优势提取多维度特征, 实现了电力接入专网流量的异常检测; 付子爔等[11]结合支持向量机和k最邻近(k-nearest neighbor,kNN)设计了一种快速流量分类算法, 降低了异常流量辨别的计算资源与时间消耗; 舒斐等[12]构建的深度置信网络模型, 完成了多个流量特征之间关联特性的深度挖掘, 采用随机森林算法对电网工控系统流量进行预警; 杨永娇等[13]使用注意力机制对流量正常状态估计, 通过对比估计得到正常状态流量与实际流量的残差分布情况, 进而判别流量是否异常; 陶应亮[14]提出了基于三支决策理论和深度学习的入侵检测模型, 对分布式拒绝服务攻击进行了检测.
上述研究大致存在两方面的不足: ① 现有研究在网络流量特征提取方面具有一定局限性, 其通常仅提取时域统计特征, 未充分利用隐藏于频域的异常特征信息; ② 大量研究将深度神经网络用于异常检测的分类, 因而构建分类模型时需要样本数量多、算力要求高、参数对效果影响大, 这类模型难以满足电能计量自动化系统对海量终端通信链接开展异常流量检测的要求.
为解决上述不足, 本文将深度森林算法用于配用电通信网络异常流量的检测. 深度森林算法具有依赖样本数量少、调参工作量小等优点[15]. 同时, 针对配用电网络流量的数量大、种类多、速度快、价值密度低等特性导致异常流量监测运行时间长、内存占用多的问题, 本文结合并行计算的思想和分布式计算模型, 对并行深度森林的构建方法开展研究. 本文主要工作: ① 提出了基于自适应冗余提升多小波变换的流量频域特征提取方法, 设计了配用电网络流量的时域特征提取方法, 在此基础上构建了时频域融合的配用电网络流量特征; ② 提出了结合分布式计算的深度森林并行计算优化方法, 以提升异常流量检测模型的运行效率. 仿真实验结果表明, 本文提出的检测模型对不同类型的异常流量具有较优秀的分类能力.
1 时频域融合特征提取方法
1.1 多小波基础理论
多小波分析以多分辨率分析为理论基础, 在小波分析的基础上采用多个小波基函数匹配信号中的多特征波形, 设r重多尺度函数为Φ(t)=[φ1(t),φ2(t),··· ,φr(t)] , 相应的r重多小波函数为Ψ(t)=[ψ1(t),ψ2(t),··· ,ψr(t)] , 满足两尺度矩阵方程
其中,Lpass,k、Hpass,k分别为r×r的多小波低通滤波器稀疏矩阵和多小波高通滤波器稀疏矩阵,D为尺度函数的长度.
多小波包分解为
其中,s2j-1,n、s2j,n分别为第 2j-1 频带、第 2j频带的第n个样本点. 则多小波包的重构公式为
由于多小波分解与重构的滤波器系数为r×r的矩阵形式, 因此需要对实际的一维输入信号进行预处理, 将其转变成r个矢量信号. 可采用平衡多小波的方法解决信号矢量化中高/低频信号混叠的问题[16]. 为了能够从多个维度描述信号中的异常特征信息, 本文改进了多小波后处理方法, 直接输出分解后的多维矢量信号[17].
1.2 自适应冗余提升多小波变换
本文在多小波理论的基础上, 采用第二代小波分解的方法对多小波变换进行自适应冗余提升, 消除了傅里叶变换的计算过程; 根据信号的本身特点设计预测器和更新器, 实现了对信号自身特点的高度匹配, 且计算方法更为简单. 具体操作如下.
1) 计算第l层分解的初始预测器P
设初始预测器P=[p0,p1,··· ,pN-1]T包含N个预测器系数, 构建范德蒙德矩阵V. 相应公式为
其中,i=1,2,··· ,N -1,j=1,2,··· ,N.该矩阵需满足
其中,sl-1表示第l-1 层近似信号, 脚标 o 、e 分别表示信号的奇数位和偶数位. 第l层的初始预测器为式(5)和式(6)联立求解的矩阵P.
2) 计算第l层初始更新器U
设初始更新器U=[u0,u1,··· ,uM-1]T包含M个更新器系数, 构建矩阵W. 相应公式为
其中,n=-N -M+2,-N -M+3,··· ,N+M -2,m=0,1,··· ,M -1.该矩阵需满足条件
其中g为 2N+2M -3 维向量, 其定义为
根据式(8)求解可得初始更新器U.
3) 自适应冗余提升方法
第l层冗余预测器Pl构建方法为
其中,i=1,2,··· ,2l-1N,Pn为第l层初始预测器的第n个元素.
第l层冗余更新器Ul的构建方法为
其中,j=1,2,··· ,2lM,Um为第l层初始更新器的第m个元素.
本文根据信号特征自适应构造初始预测和更新算子; 采用插值补零的方法, 在不同层计算预测和更新算子; 采用二重多小波包两层分解. 具体过程如图1 所示. 图1 中, 虚线框部分是对分解过程的补充解释,s(t) 表示通信流量,scl表示第l层信号,scl(even) 表示第l层信号偶数位,scl(odd) 表示第l层信号奇数位,scH,l+1表示第l+1 层高频信号,scL,l+1表示第l+1 层低频信号.

图1 自适应冗余提升二重小波包变换Fig. 1 Adaptive redundant lifting double wavelet packet transform
1.3 时频域流量特征提取方法
通信流量s(t) 的时序特征通常可以在流量出现显著异常的情况下对异常信息进行有效的描述, 而微小的异常流量往往隐藏在大量的正常数据流下, 流量数据的时域特征难以全面地描述异常流量的特点. 在小波包分解的过程中, 计算量大小与分解层数多少呈正相关, 本文基于自适应提升冗余多小
波包变换的方法, 根据实际需求选择两层分解, 求解出各节点的小波包系数用于提取流量的频谱特征,构建时频域融合的通信流量特征提取方法.
1.3.1 频域特征
频域特征:s(t) 经分解后可得各频段信号sij, 其中i=1,2,j=1,2,3,4.计算以下频域特征.
(1)各频段信号的能量占比系数ERi,j.相应公式为
其中N为信号sij的长度. 共提取8 个特征, 通过各频段的能量占比表征能量方面的特征.
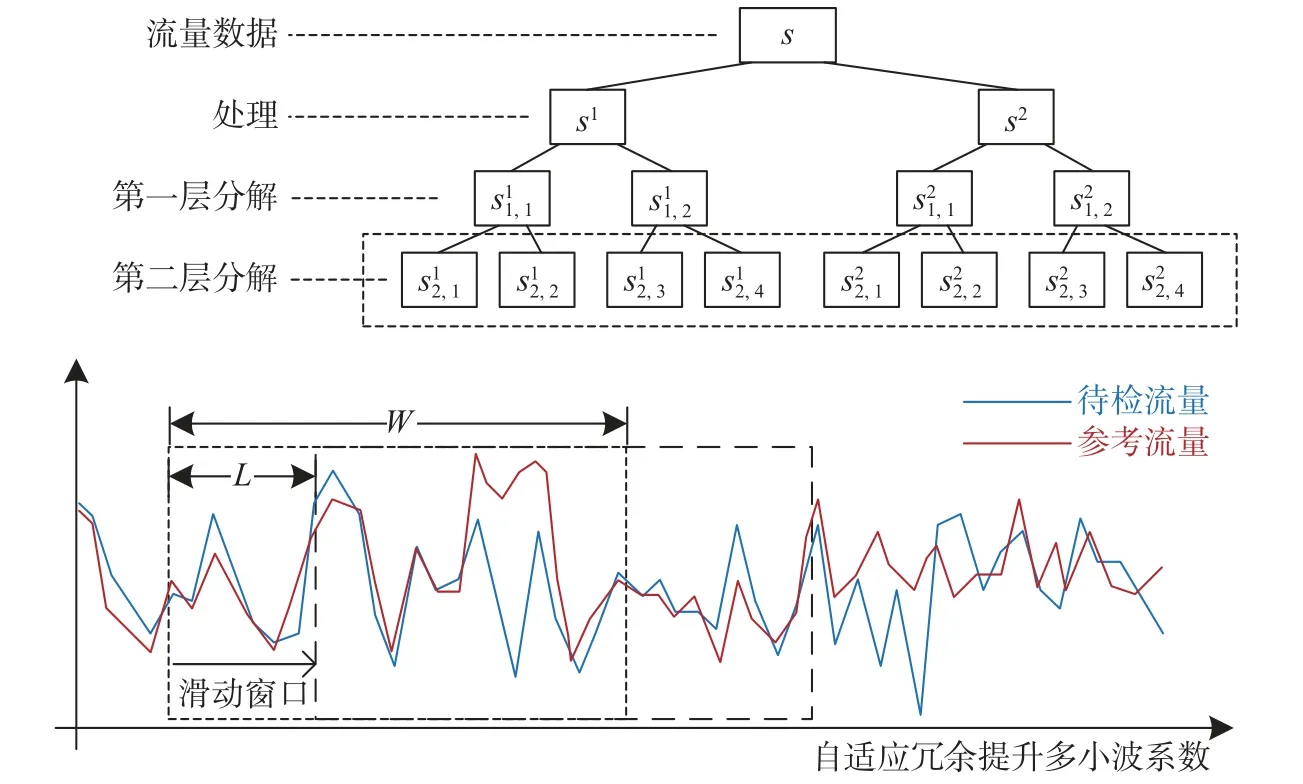
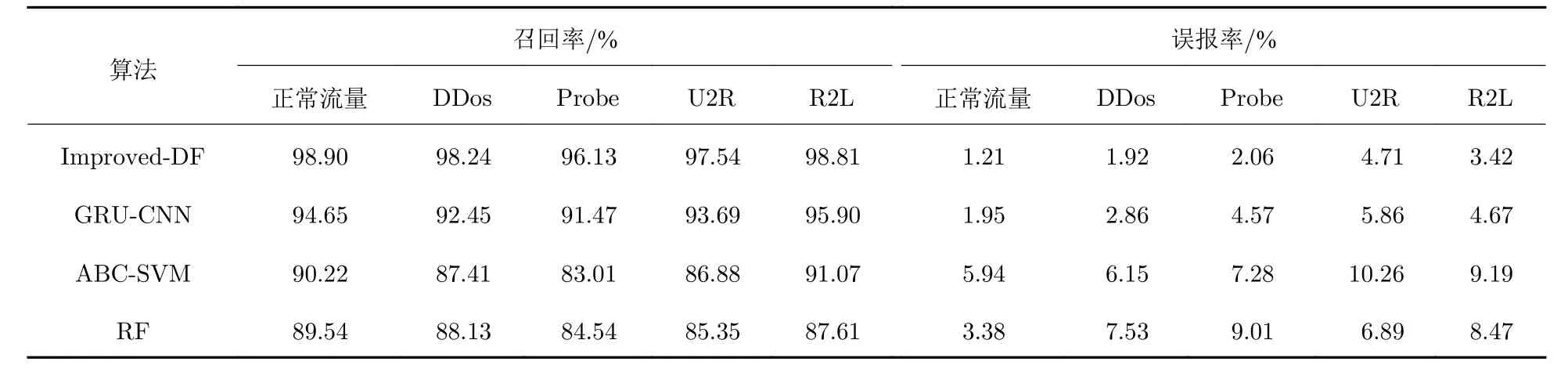
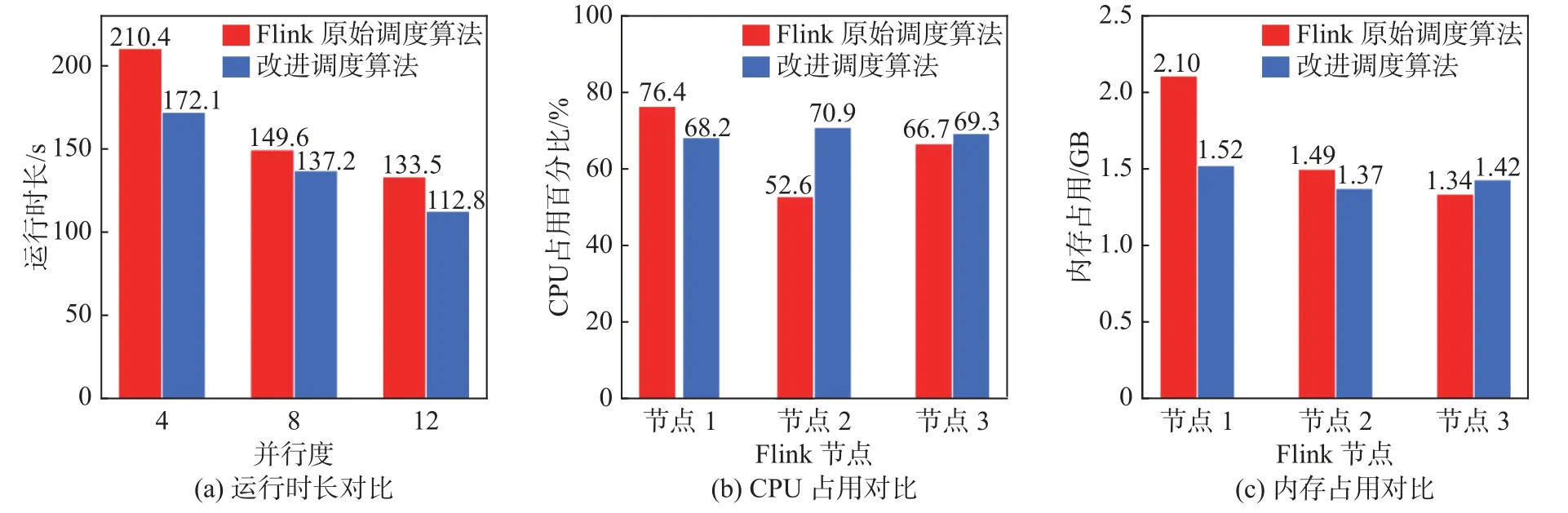
(2) 最大均值对比系数Pmax.用前3 d 同一时段的通信流量均值时间序列sref(t) 作为参考, 对待测流量与参考流量分别进行分解, 在多小波包分解后的每个频段上均构建长度为W的滑动窗口, 步长为L(L 其中,σs,k、σsref,k分别为同一时间窗口下检测流量与参考流量的小波包分解后的系数均值,k=1,2,··· ,K. 将每个频段上的频域统计均值与过去3 d 的差异作为频域统计方面的特征,Pmax越大, 该频段的待检流量与参考流量的差异就越大. 本文对待检流量数据进行了两层多小波包分解, 按照上述特征提取流程, 共获取8 个特征. 1.3.2 时域特征 时域特征由均值参考评分、标准差参考评分和通信业务特征组成. 1) 均值参考评分 流量的均值反应了流量相对于均值的波动情况. 设µ为待测时段流量的均值,µref为前3 d 相同时段的流量均值, 则计算方法为 2) 标准差参考评分 通过待检测时段流量的标准差σ与前3 d 相同时段流量均值的标准差σref的比值, 可反映该时段流量数据的离散程度的变化. 其计算方法为 3) 通信业务特征 待检验时段内, 从配用电无线专网业务层面选择6 个指标: ① 与待检测链路具有终端设备地址的连接数Nlink; ② 与待检测链路具有相同网络地址的连接数量Nclient; ③ 与规定的终端通信协议不一致的报文数量Ntype; ④ 终端通信协议符合规定但内容异常无法解析的报文数量Nprotocol; ⑤ 待检测链路传输层DNS 数据包的数量NDNS; ⑥ 待检测链路网络层ICMP 数据包的数量NICMP. 采用上述频域、时域提取的特征, 构建24 维融合特征. 其具体内容是8 个频段能量占比特征, 8 个最大均值对比系数特征与时域特征的均值参考评分、标准差参考评分, 6 个通信业务特征. 本文在对配用电网络时频域特征提取的基础上, 结合深度森林算法构建异常流量检测模型: 先采用多粒度扫描的增强原始特征的表征能力; 再采用级联结构实现逐层表征学习; 结合大数据并行计算框架构建深度森林并行计算模型. 在多粒度扫描阶段, 采用多种长度的滑动窗口对样本集进行扫描, 获得增强的特征集. 对于本文提出的流量特征向量, 滑动窗口对于空间上邻近的特征扫描次数较多, 因而具备较好的增强效果; 对于特征向量两端的特征扫描的次数较少, 可能会遗失重要信息, 降低两端特征的重要性. 针对上述问题, 本文在多粒度扫描阶段增加了特征组合过程, 采用一段与原始特征相同的特征向量与原始特征首尾相接, 获取组合特征向量后; 再采用滑动窗口采样获取特征向量片段, 并在此基础上分别构造了一个随机森林和完全随机森林进行训练和预测分类, 将输出的分类概率向量拼接获得表征增强向量. 本文的多粒度扫描过程见图2. 图2 多粒度扫描过程Fig. 2 Multi-grained scanning process 经过多粒度扫描获得增强特征后, 利用增强特征构建级联森林, 类似于深度神经网络的层叠结构,级联森林中每层的输出用于下一层的输入特征向量, 以训练新一层的随机森林模型. 在层级扩展后,采用验证集对级联的性能增益进行评价, 在分类精度没有显著提升的情况下, 停止增加层级并完成级联森林的训练. 目前, 大数据环境下并行构建深度森林并行化计算主要结合MapReduce 或Spark 框架进行研究,在并行计算的处理场景中, 级联森林训练任务的分割方法与计算调度的方法研究较少. 基于以上原因,本文结合电力大数据平台广泛应用的Flink 并行计算框架, 构建并行化的级联森林阶段每层N个随机森林分类器, 具体分为以下4 个步骤. (1) 将多粒度扫描阶段提取的测试样本的增强特征划分成N个大小相同的有重复的样本子集, 每个样本子集用于一个森林的训练. (2) 将每一层的N个随机森林分类器的训练作为独立的任务, 向Flink 提交计算任务. 每个随机森林训练的过程中通过K折交叉验证的方式对森林中的各个决策树进行训练, 决策树训练完成后采用键值对 (Fn,TD,t) 进行表述, 其中Fn为该决策树所属森林序号,TD,t为该决策树模型, 森林训练完成后将训练完成标识及构建好的森林模型保存至分布式缓存. 当N个分类器的训练全部完成后, 缓存中的所有森林的集合即为本层级联森林的模型. (3) 向各个森林n提交验证样本集合S进行预测, 对于集合中的单个样本s预测的结果采用〈sid,n,vn〉数据结构在分布式缓存中保存, 其中sid,n表示在第n个森林中编号为id的样本s,vn表示在第n个森林中该样本的类概率向量. (4) 从分布式缓存中合并各个森林n对各个样本s的类概率向量, 计算其各森林输出的该样本类概率向量均值, 基于验证样本集合S的分类情况求解本层级模型的准确性, 对分类精度进行评价, 如果精度存在显著提升则将分布式缓存中保存的类概率向量与本层输入向量进行拼接, 继续下一层级的森林训练, 否则中断级联森林过程, 确定学习深度. 上述并行化深度森林的构建方法如图3 所示. 级联森林每一层的各个随机森林分类器的训练、分类预测的过程作为独立的任务交由Flink 集群并行执行. 大数据平台Flink 集群通常采用容器化部署方式, 任务调度器(JobManager)和任务管理器(TaskManager)运行于服务器集群不同的容器中. 图3 并行级联森林训练过程Fig. 3 Paralleled cascading forest process 本文提出的并行化深度森林算法, 将模型训练、分类预测作为计算量基本一致的计算任务, 提交至JobManager, 由JobManager 采用一定的调度方法将任务分配至各个TaskManager 执行. 在实际并行化计算过程中, 需考虑到每个服务器节点上的容器数量不同、容器部署不均等情况带来的节点间的性能差别, 若采用Flink 默认的轮询策略, 会造成任务在节点上分布不均衡, 难以充分发挥并行化级联森林效率的优势. 为此, 本文设计了基于计算资源评分的并行化深度森林平滑轮询调度策略(parallelized deep forest smooth polling strategy), 通过收集容器的资源使用情况, 在对JobManager 所在容器性能权重评价的基础上, TaskManager 在分配任务的过程中, 优先选择性能权重高的节点执行任务, 随后适当调低已选节点的权重避免连续重复选中导致任务积压, 使任务能够依据节点的负载进行均衡的分配,如图4 所示. 具体过程如下: 设可用的计算节点数量为P, 节点p的内存可用率为AMem,p, 节点p的CPU 可用率为ACPU,p, 则基于内存和CPU 使用情况计算节点的有效权重ωpE. 相应计算公式为 图4 基于Flink 的级联森林并行计算逻辑架构Fig. 4 Logical architecture of paralleled cascading forest process based on the Apache Flink framework 其中,α、β分别表示CPU 可用率、内存可用率在有效权重中所占的比例, 且α+β=1.由于Flink 容器集群对CPU 资源敏感性远大于内存资源敏感性,α、β可分别取值为0.9、0.1. 在对一次级联森林并行计算任务调度的过程中, 设待训练的森林个数为N, 对于每个森林训练任务在被分配前, 均计算各节点当前权重ωpC, 将任务分配至当前权重最大的节点.ωpC的计算公式为 这里ωlCast,p是节点p在上一轮分配任务时得到的节点权重. 本文通过每次分配前对各个容器节点权重进行计算, 采用不断累加权重表征节点的可用性, 权重越大, 说明这个节点一直没有被分配到任务, 下一次分配时就越有可能分配到这个节点上. 当拥有最大当前权重的节点p被选中后, 为了避免被连续选中造成训练任务积压, 造成并行训练效率降低, 需削减被选中节点的当前评分. 相应计算公式为 本文首先从流量数据中提取特征, 构建时频域融合的特征样本, 再采用并行化处理的深度森林对提取的样本进行学习训练, 流程如图5 所示. 图5 异常流量检测流程Fig. 5 Abnormal traffic detection flowchart 图5 展示了异常流量检测流程的详细过程: ① 对流量样本采用自适应冗余提升的CL (chuilian)多小波包变换进行分解, 从分解后的各频带中提取最大均值对比系数作为样本的频域特征; ② 从流量样本中提取时域特征, 采用均值参考评分、标准差参考评分、通信业务特征作为样本的时域特征; 将时域特征、频域特征进行组合, 构建流量样本的24 维时频域融合特征向量; ③ 将特征向量首尾组合后再进行多粒度扫描, 采用多尺度滑动窗口从原始特征中进一步提取增强表征信息; ④ 构建一层级联森林分类模型, 将每个随机森林分类器的训练过程采用本文所述的Flink 优化调度策略分配到各服务器节点上执行; ⑤ 用本层训练得到的各个随机森林对训练样本进行分类, 分类精度在分布式缓存中汇聚, 并计算训练精度, 若分类准确度存在显著提升则将各个样本分布式缓存中的分类概率向量与输入特征向量拼接, 重复步骤④进行下一层森林的训练, 否则停止增加层级并结束训练过程; ⑥ 对测试样本进行多粒度扫描增强特征, 并将增强后的特征分发到各服务器节点上, 由各个随机森林生成分类概率向量并保存在分布式缓存中; ⑦ 对分类概率向量进行汇聚并研判分类结果, 计算本文算法的分类性能指标. 为验证本文提出的异常流量检测方法的有效性, 本文实验数据来源于正常流量数据取自某省电力公司计量自动化系统的实际流量数据; 通信协议方面包括低压台区设备使用的《电力用户用电信息采集系统通信协议: 第1 部分 主站与采集终端通信协议》 (Q/GDW 1376.1—2012) 、《面向对象的数据交换协议》(DL/T 698.45—2017), 以及中高压设备使用的《电力系统电能累积量传输配套标准》(DL/T 719—2000)、TEC 60870–5–104—2000《电力远动规约》(IEC104 规约); 异常流量数据取自经典的网络异常检测数据集 (DARPA1999, 包含服务器在DOS、Probe、R2L、U2R 等攻击下捕获网络流量) 、加拿大网络安全研究所发布的DDoS 入侵检测公共数据集(CICDDoS2019, 包含服务器在DDoS 攻击下捕获的网络流量), 本文选用的异常流量类型包括DDoS (distributed denial of service)、Probe、U2R (user to root attack)和R2L (remote to local). 将上述正常流量与异常流量按照时间戳进行聚合, 构建本文实验异常流量检测数据集. 利用本文提出的频域特征提取方法, 采用自适应冗余提升CL 多小波包对采集得到的流量进行二层分解: 滑动窗口提取频域统计特征的方法示意图如图6(a)所示; 对二层多小波包分解后得到的8 个频段, 从每个频段中计算最大均值对比系数Pmax的方法如图6(b)所示. 图6(a) 滑动窗口提取频域特征示意图Fig. 6(a) Schematic diagram of extracting frequency domain features based on a sliding window 图6(b) 各频段最大均值对比系数PmaxFig. 6(b) Pmax of each frequency band 采用本文提出的流量特征提取方法提取时频域流量特征数据集, 提取正常流量样本11 832 例,DDoS、Probe、U2R、R2L 各类型异常流量样本各5 000 例. 构建异常流量检测模型的训练集的测试集比例为7∶3. 为了对时频域特征提取与深度森林算法结合的异常流量检测方法的有效性进行评估, 本文从准确率 (accuracy,A) 、召回率(recall,R)和误报率(false positve ratio,F)这3 个指标进行分析. 指标的计算方法为 式(19)中:PT为正确检出的异常流量样本数量;NT为正确检出的正常流量样本数量;PF为被误判为异常流量的样本数量;NF为被误判为正常流量样本数量. 将本文所提的改进深度森林算法(Improved-DF (deep forest)) 、混合卷积神经网络 (convolutional neural network, CNN)和门控循环单元(gated recurrent unit, GRU)的神经网络预测模型(GRU-CNN)[9]、人工蜂群优化支持向量机 (ABC(artificial bee colony)-SVM (support vector machine))[18]的测试结果, 以及传统的随机森林 (random forest, RF) 方法的测试结果进行对比, 不同分类器异常流量检测方法对比结果详见表1. 表1 不同分类器异常流量检测方法对比Tab. 1 Comparison of abnormal traffic detection methods for different classifiers 由表1 所示的对比结果可知, 在时频域融合特征提取方法的基础上, 本文提出的Improved-DF 较其他分类算法在准确率、检出率、误报率这3 个指标上均显现出较明显的优势, 特别在准确率、误报率方面优于其他几种算法, 分别达到了98.29%和2.63%. 各算法对于不同类型流量的检出情况详见表2. 表2 各类型流量分类性能对比Tab. 2 Comparison of abnormal traffic detection methods for different traffic types 由表2 可知, 本文提出的结合流量时频域特征提取与改进深度森林的异常流量检测模型(Improved-DF)对于各类异常的检测召回率较高, 其对于正常流量、DDoS、R2L 类型的异常流量, 召回率均达到98%以上, 并且误报率较低. 与GRU-CNN 相比, 对于正常流量, 召回率提高了4.25%, 误判率降低了0.74%; 对于DDoS 类型异常流量, 召回率提高了5.79%, 误判率降低了0.94%; 对于Probe 类型异常流量, 召回率提高了4.66%, 误判率降低了2.51%; 对于U2R 类型异常流量, 召回率提高了3.85%, 误判率降低了1.15%; 对于R2L 类型异常流量, 召回率提高了2.91%, 误判率降低了1.25%. 综上, 本文所提的配用电异常流量检测方法在准确性方面具有较明显的优势. 本文对深度森林并行化算法训练与分类过程进行了串并行运行时间对比测试, 通过对不采用并行加速的深度森林算法、基于Flink 框架不同并行度下采用默认调度方法与改进调度方法对深度森林算法并行加速这3 种场景的训练分类时长进行对比, 结果如表3 所示, 其中, 加速比 表示采用原始深度森林算法与Flink 改进调度方法的并行计算耗时的比值, 加速比 表示采用Flink 默认调度方法与Flink 改进调度方法的并行计算耗时的比值. 表3 并行深度森林加速性能对比Tab. 3 Performance comparison of parallel deep forest and original deep forest algorithms 由表3 可知, 深度森林经并行化处理后, 整个异常流量检测模型训练分类的时长随着并行度的增加显著缩短; 改进并行调度的深度森林算法较原始深度森林串行计算的加速比最高可达4.01, 较默认并行调度的深度森林加速比在最高可达1.22; 改进调度算法的并行深度森林算法在执行效率方面的提升可达9% ~ 22%, 如图7(a)所示. 图7 优化并行深度森林调度算法效果Fig. 7 Performance of the improved scheduling algorithm for the parallel deep forest process 本文用于执行训练和分类任务的3 台Flink 服务器节点的平均CPU 占用百分比和内存占用对比分别如图7(b)和 图7(c)所示, 它们对比了并行深度森林和改进调度算法的深度森林资源占用情况.从图中可见, 经改进调度算法的深度森林在3 台Flink 服务器节点上, CPU 占用分别为68.2%和 S原始S默认69.3%, 内存占用分别为1.37 GB 和1.42 GB, 资源分配较原始调度算法更加均衡. 由此可知, 通过将深度森林训练与分类过程并行化处理, 结合改进的Flink 调度算法, 可将计算任务均衡地分配在各个服务器节点上, 有效降低了算法整体运行时间. 本文基于并行深度森林构建了配用电通信网络异常流量检测模型, 相比较其他传统方法, 在设计的配用电通信流量时域特征提取方法的基础上, 利用自适应冗余提升小波提取通信流量频域特征, 利用深度森林模型对时频域融合特征进行分类检测; 提出了基于Flink 框架优化调度的并行深度森林算法, 大幅提升深度森林训练与分类效率. 实验结果表明, 本文方法具备更短的执行时间、更高的准确率和更低的误判率, 因此可以准确快速地对配用电通信网络异常状况进行检测, 支撑配用电通信网络安全态势感知, 保障电网安全可靠运行.2 并行深度森林异常流量检测方法
2.1 改进多粒度扫描
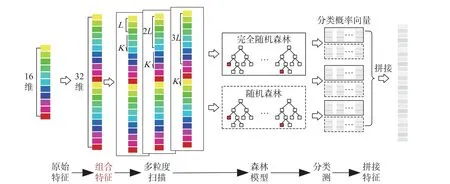
2.2 并行化级联森林


2.3 并行深度森林异常流量检测方法

3 实验验证



4 结束语
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
雷达学报(2018年3期)2018-07-18
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24
火控雷达技术(2016年1期)2016-02-06
