
基于UI 图像的Web 前端代码自动生成
2023-09-22 01:09:24陆雪松
华东师范大学学报(自然科学版) 2023年5期
葛 进, 陆雪松
(华东师范大学 数据科学与工程学院, 上海 200062)
0 引 言
在应用程序中, Web (world wide web)前端扮演着与用户交互的重要角色. 近年来随着移动互联网的普及, Web 前端不再仅仅是桌面应用的一种选择, 它也成为了移动应用提供服务的主要方式之一. 越来越多的应用程序将其用户界面转移到Web 前端, 使得其应用场景愈发广泛而深入. 当前主流的Web 开发流程是, 先由用户交互设计师设计用户界面 (user interface, UI) 稿, 再由前端开发工程师根据设计稿编写代码实现设计稿的效果. 这样开发的弊端是显而易见的, 主要有两个缺点: ① 行业壁垒较高, 没有开发岗位的公司很难根据自己的需求产出前端界面; ② 开发周期过长, 无法满足产品快速落地的需求. 一个可能的解决方案是根据UI 图像自动生成前端代码[1]. 最近十年, 深度学习技术在包括计算机视觉、自然语言处理等领域的发展迅速, 使得根据网页截图生成Web 前端代码成为了可能, 即训练深度学习模型根据网页截图或者UI 设计稿图像自动生成Web 前端布局代码. 这可以使得传统Web 开发方式的弊端在一定程度上得到缓解.
在Web 前端代码生成的研究中, 网页元素结构布局的关系捕捉构成了一项较大的挑战. 现有的研究方法主要使用Encoder-Decoder 模型架构来实现网页截图中元素结构关系的捕捉和相应的前端代码生成. Beltramelli[2]提出的pix2code 第一次把深度学习技术应用在Web 前端代码生成任务上.Pix2code 基于卷积神经网络(convolutional neural network, CNN)[3]和长短期记忆网络(long shortterm memory, LSTM)[4], 由单个UI 截图生成领域特定语言 (domain specific languages, DSL). 为提高模型准确率, Zhu 等[5]提出了加入注意力机制的改进模型, 取得了比基准模型更高的代码生成准确率.Xu 等[6]改进了pix2code 的CNN 结构, 并且使用LSTM 生成可以转化为HTML (hyper text markup language) + CSS (cascading style sheets)代码的Emmet 代码. 相比HTML + CSS 代码, Emmet 代码更加简洁、长度更短, 因此可以提高模型训练效率. 从上述模型可以看出, 从UI 图像生成Web 前端代码可以被视为图像描述任务[7-8]的一种形式. 图像描述任务的目标是从给定的图像中生成相应的文本描述. 作为类比, UI 图像可以作为输入图像, 而生成的Web 前端代码则可以被视为对该截图的描述.
图像描述任务已经广泛使用基于Transformer 的编码器提取图像特征[9-11]. 但是, Transformer 模型中, 计算注意力机制的开销较大, 最后导致的结果是训练效率不高、拟合文本的准确率欠佳. 这对于Web 前端代码生成任务的影响较大. 首先, UI 图像不像普通图像那样包含复杂的元素, 其主要构成元素是各类组件, 包含文本框、按钮、复选框等, 并且组件的布局较为结构化, 因此对整个图像进行全局注意力计算性价比较低; 其次, 代码不同于自然语言描述, 不允许有任何语法错误, 否则会导致生成的代码无法编译, 因此Web 前端代码生成对于生成代码的准确率要求较高.
为了解决上述两个问题, 本文提出了一个编码器-解码器模型image2code, 用于基于UI 图像自动生成相应的Web 前端代码. 在编码器端, 为了降低注意力计算的开销, image2code 在编码UI 图像时采用在图像描述任务中已经得到验证的Swin Transformer[12]结构, 通过滑窗的方式将注意力运算限制在图像局部区域, 减小运算开销, 同时保证不同窗口的元素间仍然可以互相交互; 在解码器端, 为了提高代码生成的效率, image2code 生成较为精简的Emmet 代码[6], 从而提高生成代码的准确率. 利用官方插件(https://emmet.io)可以将Emmet 代码转换为HTML 代码, 实现Web 前端生成. 实验结果表明, 本文提出的image2code 模型在两个数据集上生成的Web 前端代码, 相比对比模型在准确性上有更好的表现. 此外, 本文通过敏感性实验分析了编码器中的滑窗平移步长大小对于模型的影响, 并且展示了利用image2code 生成的代码编译的Web 前端例子.
1 相关工作介绍
1.1 Web 前端代码生成
在Web 前端代码生成任务上, Beltramelli[2]提出的pix2code 模型第一次把深度学习技术应用在Web 前端代码生成任务上. 它基于卷积神经网络和循环神经网络, 由单个UI 屏幕截图生成HTML 源代码. 在pix2code 的基础上, 研究者们提出了提升模型有效性的改进方案, 且大多是由Encoder-Decoder 模型架构的. Zhu 等[5]提出了加入了注意力机制的改进模型并且构建了自己的数据集. Xu 等[6]提出了包含HTML 和CSS 代码的数据集并改进了模型的卷积层结构. Chen 等[7]提出的编码器-解码器模型参照图片描述任务的方法, 采用GRU(gate recurrent unit)作为解码器并加入了注意力机制,取得了比pix2code 模型更高的代码准确率. Bajammal 等[13]提出了从UI 界面生成可重用的Web 组件的VizMoD 工具. 尽管Web 前端代码生成研究已经广泛开展, 但尚未有基于Transformer 的模型提出,并且Web 前端代码生成的任务在提高数据集质量、提升代码生成准确率和模型效率等方面还有很大的探索空间.
1.2 图像描述
图像描述是一个将计算机视觉和自然语言处理技术相结合的综合性研究问题[8]. 其主要过程是设计算法检测图像中的关键物体, 并且能够准确理解图像中物体与物体之间的逻辑关系, 然后用自然语言描述关键物体以及它们之间的关系. 目前解决图像描述任务主要有3 种方法[14]: 基于模板填充的方法, 基于检索的方法和基于生成的方法. 基于模板填充的方法在人为规定的一系列句法模板中留出部分空白, 然后基于提取出的图像特征获得目标、动作及属性, 将它们填充进空白部分, 从而获得对图像的描述[15]. 基于检索的方法将大量的图像描述存储为一个集合, 然后通过比较待描述图像和训练集中图像描述的相似性获得一个待选句集, 最后设计算法从待选句集中选取最合适的描述[8]. 近年来研究较多的是基于生成的方法, 过程是先将图像信息编码, 作为输入送入语言模型, 再利用语言模型生成图像描述[16]. Wang 等[17]提出了基于滑动窗口的Swin Transformer 模型完成图像描述任务, 在多个评价指标上取得了较好的效果. Xian 等[10]提出了全局加强Transformer 来更好地捕捉图像中的全局信息. Tan 等[11]提出了在不影响测试性能的前提下尽可能减小模型大小的ACORT 模型. Wei 等[15]提出了基于原始 Transformer 结构的顺序变换器框架S-Transformer, 其中解码器是outside-in attention和 RNN (recurrent neural network)相结合的结构. Luo 等[18]提出了一种专为图像描述设计的基于扩散模型的框架. Ramos 等[19]提出了轻量级的SmallCap 模型, 使得模型在参数量较小的情况下依然有良好的表现. Wei 等[20]提出了一种基于Transformer 模型的端到端的图像描述框架EURAIC (enhance understanding and reasoning ability for image captioning), 增强了图像描述的理解和推理能力. 尽管图像描述的模型众多, 但是在Web 前端代码生成任务中, UI 图像的结构性和生成代码的规范性对模型的计算效率和代码生成的准确率提出了更高的要求.
2 Image2code 模型
2.1 数据集构建
在基于UI 图像的Web 前端代码生成任务上, 已有的研究大多利用Beltramelli[2]在训练pix2code 模型时构建的合成数据集, 以下称之为pix2code 数据集. pix2code 数据集共包含1 742 张图片及其对应的Web 前端代码, 大多只包含按钮、段落等组件. 由于pix2code 数据集规模较小, 并且没有考虑到其他复杂的网页元素, 其实用性不够. 因此, 有必要构建一个更大规模、包含更丰富组件类型的数据集, 来模拟真实网页. 本文延续pix2code 构建合成数据集的思路, 将Web 前端的组件进一步细分为标题元素、输入元素、列表元素、段落元素、按钮元素和其他元素这六大类. 之后, 随机选择上述组件填充前端代码, 并且确保每一大类不超过3 个, 随后利用Python 中的selenium 第三方包[21]自动操纵浏览器打开文件然后截图, 从而得到截图及其对应的Web 前端代码. 这里随机填充的前端代码是HTML 代码, 代码长度较长, 对模型的训练效率有一定影响. 为了减少模型训练时输入和输出的文本长度以提高训练效率, 本文利用开源工具(https://uhc-elgg.ch/convert)将HTML 代码转换为较为简洁的Emmet 代码. 图1 展示了一段HTML 代码和对应的Emmet 代码, 可以观察到将HTML 代码转换为Emmet 代码能显著降低代码文本的长度, 并且其相互转换过程是确定性的. 利用上述方式, 本文创建了14 252 张图片及其对应的Web 前端代码, 并将这个数据集命名为image2code 数据集, 用于image2code 模型的训练.
2.2 编码器与解码器
原始Transformer 模型[22]的注意力计算公式如下所示. 其中,WQ,WK和WV是3 个可训练的参数矩阵,输入矩阵X分别与WQ,WK和WV相乘,生成查询矩阵Q、键值矩阵K和数值矩阵V.随后Q和K相乘得到关于数值矩阵的权重分布, 并用进行缩放,其中dk是键值向量的维度. 最后对权重矩阵进行softmax 归一化, 并对数值矩阵进行加权求和. 这个计算过程如式(1)—(4)所示.
在利用Transformer 编码图像时, 通常将整个图像切分成多个互不相交的小块区域, 每一块区域在嵌入后对应一个输入token[23]. 这种处理方法使得在模型的注意力层, 图像的每一块区域都要和其他所有区域计算注意力分数, 造成昂贵的计算和存储开销. 由于UI 图像通常是比较结构化的图像, 图像语义集中在其中的组件以及组件之间的相互关系, 因此没有必要对图像的所有区域两两计算注意力分数. 受到Swin Transformer[12]的启发, 本文采用基于窗口的方法, 将UI 图像划分成若干个互不相交的窗口, 将注意力计算限制在每个窗口内部的小块之间, 如图2(a)所示. 这样注意力计算的代价大大降低, 相应的注意力模块被称为基于窗口的多头自注意力 (window-based multi-head self attention,W-MSA). 假设输入图像包含h×w个小块, 每个小块拉伸后的维度为C, 相应地,WQ,WK和WV的维度为C×C. 那么, 在原始的多头注意力MSA 模块中, 计算Q,K和V的时间复杂度为 3hwC2, 计算QKT的时间复杂度为 (hw)2C, 计算 a ttention(Q,K,V) 的时间复杂度为 (hw)2C, 最后线性变换输出编码的时间复杂度为hwC2. 因此, 原始多头注意力MSA 模块的时间复杂度如式(5)所示, 是h×w的二次方, 当h×w很大时计算代价极高.

图2 W-MSA 与SW-MSA Fig. 2 W-MSA and SW-MSA
而在W-MSA 模块中, 注意力计算被限制在每个窗口内部. 假设每个窗口内包含M×M个小块,那么整个图像被分割为个窗口, 则计算QKT和 a ttention(Q,K,V) 的时间复杂度降低为, 因此W-MSA 模块的整体时间复杂度如公式(6)所示. 可以看到复杂度降低为和h×w成线性关系.
不过, W-MSA 的方法也有天然的缺陷, 即属于不同窗口的区域互相之间无法交互, 导致无法捕捉属于不同窗口的组件之间的关系. 因此, 本文沿用Swin Transformer 中的滑动窗口思想, 将所有窗口向右和向下平移, 使得新窗口中包含原本属于不同窗口的区域, 让它们在新窗口中进行局部的注意力计算(图2(b)). 例如, 图2(a)中的紫色列表, 原本被划分进了4 个不同的窗口, 左下角的3 个列表内容无法捕捉到和其他列表的关系; 经过滑窗后, 在图2(b)中, 这3 个列表可以在中间窗口中发现与其他列表属于同一层级. 相应的注意力模块被称为基于滑动窗口的多头自注意力 (shifted window-based multi-head self attention, SW-MSA). 一般来讲, 如果滑动窗口的大小记为S, 那么窗口平移的步长可以设为在具体建模时, Transformer 的每一个block 中的自注意力层, 替换为一个W-MSA 和一个SW-MSA 层, 在降低注意力计算开销的同时, 保证了不同窗口区域之间也可以进行注意力计算.
在解码器端, 通过编码器得到的图像编码序列作为查询, UI 图像对应的Emmet 代码序列作为键值和数值, 输入到Transformer 解码器中, 将UI 图像解码成对应的Emmet 代码. 综上所述, image2code模型的整体框架如图3 所示.
最左侧的嵌入层用于提取输入UI 图像的特征, 经过线性层处理后得到每个小块区域对应的查询、键值和数值, 输入到编码器中. 编码器由N个相同的block 连接构成, 每个block 中依次包含WMSA 层, SW-MSA 层, 层归一化层, 线性层和层归一化层. 解码器也由N个相同的block 组成, 接受编码器的输出和UI 图像对应的Emmet 代码作为输入, 从编码器捕捉的UI 特征表示中解码出目标序列.模型训练的损失函数采用经典的交叉熵, 计算生成代码序列和目标代码序列的差异.
3 实验结果与分析
3.1 实验数据和评估指标
本文的实验数据由两部分组成, 分别是pix2code 模型公开的数据集[2]和本文在其构建方法上扩展并重新构建的数据集. 简便起见, 将两个数据集分别命名为pix2code 数据集和image2code 数据集. 两个数据集的基本信息如表1 所示.

表1 实验数据集信息比较Tab. 1 Comparison of dataset information
在评估Web 前端代码生成效果时, 采用BLEU (bilingual evaluation understudy)和METEOR(metric for evaluation of translation with explicit ordering)这两个在文本生成任务中被广泛采用的技术指标. BLEU 经常被用于评估机器翻译中预测翻译与目标翻译、生成任务中生成句子和真实句子的相似度[24]. BLEU 采用基于n-gram 的匹配规则, 比较生成文本和目标文本之间n-gram 的相似占比.METEOR 基于BLEU 进行了改进[25], 其目的是解决BLEU 基于n-gram 匹配的缺陷. METEOR 使用WordNet 计算特定的序列匹配, 包括同义词、词根和词缀、释义之间的匹配关系, 改善了BLEU 的效果, 使其评估结果跟人工判别具有更强的相关性.
3.2 实验参数设定和训练细节
本文将模型训练时输入的批大小设定为10, 分割图像的窗口大小设定为12, 滑动的步长设定为6.本文使用Adam 算法对模型进行优化, 学习率固定为0.001. 当模型训练损失收敛时, 训练即可停止.训练时观察到所有的模型都会在30 轮后收敛.
3.3 主要结果
本文将image2code 模型和pix2code[2]、image2emmet[6]两个Web 前端代码生成的代表性模型进行比较, 并且将image2code 模型中的编码器替换为普通的Transformer 进行消融实验. 表2 和表3 分别展示了在pix2code 和image2code 两个数据集上的结果.

表2 pix2code 数据集实验结果Tab. 2 Experimental results on the pix2code dataset

表3 Image2code 数据集实验结果Tab. 3 Experimental results on the image2code dataset
从表2 中可以观察到, 本文提出的image2code 模型在衡量代码生成相似度的所有指标上都大幅优于pix2code 和image2emmet 模型. 同时可以观察到, 当采用Swin Transformer 作为模型编码器的骨干网络时, 模型会表现出更好的性能, 证明了采用基于滑窗的Transformer 比普通Transformer 对于Web 组件及其关系的捕捉更为精确.
表3 展示了image2code 数据集上的实验结果. 从表3 中可以观察到, 和前述实验结果类似, 本文提出的image2code 模型在各项指标上都优于pix2code 和image2emmet 模型, 并且采用Swin Transformer 作为模型编码器的骨干网络时, 模型会表现出更好的性能.
2.2 节分析了MSA 和W-MSA 模块的计算复杂度, 可以看到W-MSA 相对于MSA 大幅降低了注意力计算的代价. 通过实验, 本文验证了这种计算代价的降低为模型训练效率带来的影响. 图4 展示了在image2code 数据集上, 各个模型在训练集上的损失以及在验证集上的准确度随epoch 的变化. 从图中可以观察到, 使用Transformer 作为编码器的image2code 模型, 比使用CNN 作为编码器的pix2code 和image2emmet 模型更快达到相同的训练损失和验证准确度; 同时, 使用Swin Transformer的image2code 比使用原始Transformer 的image2code 更快达到相同的训练损失和验证准确度. 实验证明了注意力计算代价的降低, 提高了模型的整体训练效率.
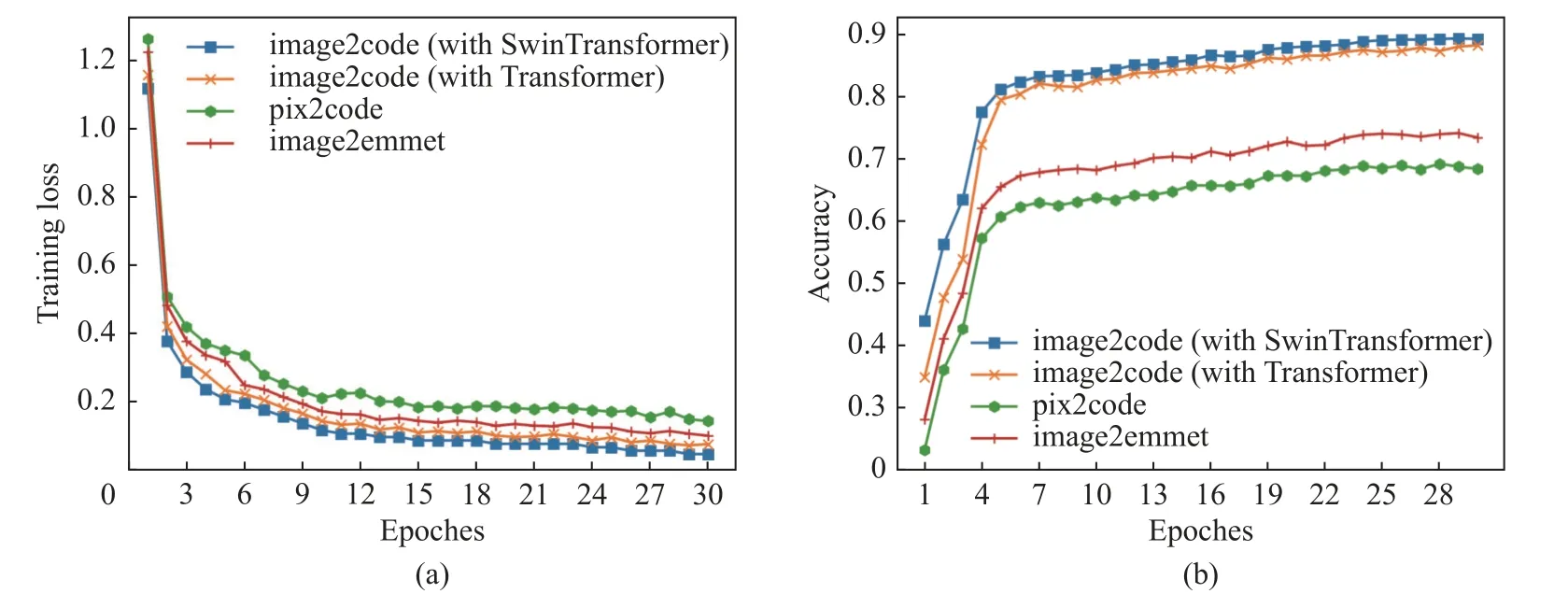
图4 模型的训练损失(a)与验证准确度(b)Fig. 4 Training loss (a) and validation accuracy (b) of the models
3.4 敏感度分析
本节通过更改image2code 的SW-MSA 窗口滑动步长的大小, 分析这个超参对于模型性能的影响.其他超参固定, 将滑动步长大小分别设置为0、3 和6. 其中6 为image2code 模型采用的滑动步长大小.在此超参设置为0 的情况下, 模型的SW-MSA 结构则退化为W-MSA 结构, 即没有窗口滑动的过程,注意力计算被限制在每个窗口的内部元素之间. 表4 和表5 分别展示了在pix2code 数据集和image2code 数据集上的实验结果.

表4 基于pix2code 数据集调节image2code 滑动步长大小Tab. 4 Varying the stride size of image2code based on the pix2code dataset

表5 基于imag2code 数据集调节image2code 滑动步长大小Tab. 5 Varying the stride size of image2code based on the image2code dataset
从实验结果可以观察到, 当滑动步长越大时, 生成代码的准确率会越高, 这也许是因为有更多的原本属于不同窗口的区域之间产生了交互. 特别地, 当滑动步长大小为0 时, image2code 的编码器不会在不同窗口之间进行注意力计算, 可能会导致无法精准捕捉Web 组件之间的关系, 从而导致生成代码的准确率欠佳.
3.5 案例分析
本节在image2code 数据集中挑选两个UI 图像, 采用image2code 模型和pix2code 基准模型分别生成相应的前端代码, 然后编译成Web 前端, 并进行对比.
挑选的第一个UI 图像如图5(a)所示, 利用image2code 模型和pix2code 模型生成代码编译的UI 如图5(b)和图5(c)所示. 对比图5 中3 个子图可以发现, image2code 相比pix2code 生成了更为精确的列表元素. 此外, image2code 成功捕捉了原图中的文本框, 而pix2code 则没有发现原图中文本框的存在.
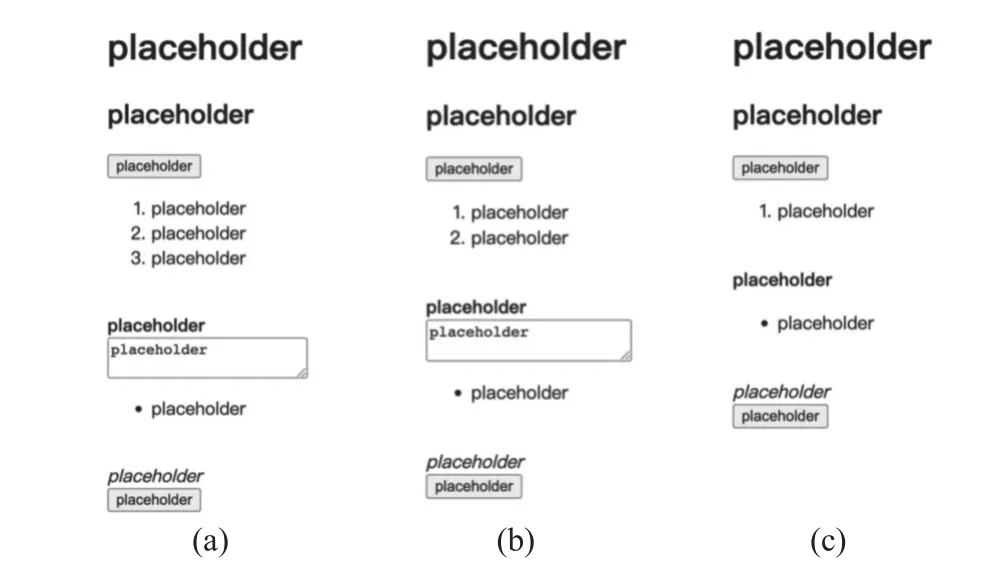
图5 案例分析1Fig. 5 Case study 1
挑选的第二个UI 图像如图6(a)所示, 在image2code 模型和pix2code 基准模型下生成的代码对应的UI 如图6(b)和图6c 所示. 对比图(6)的3 个子图可以发现, 当对应的UI 原图较为简单时,image2code 模型和pix2code 模型都可以生成比较完整的标题元素、表格元素和段落元素. 但是,image2code 模型生成的Web 前端仍然比pix2code 更加接近原始的UI 图像.

图6 案例分析2Fig. 6 Case study 2
4 结论和展望
本文提出了一个基于编码器-解码器结构的模型image2code, 用于从UI 图像自动生成Web 前端代码. 首先使用Swin Transformer 提取图像的网格特征, 表示UI 图像中组件的编码和位置信息. 然后, 利用Swin Transformer 基于窗口和滑动窗口的注意力机制计算方法, 缓解了普通自注意力机制计算在UI 图像上开销过大的问题. 解码器接受编码器输出和前端代码的输入, 从编码器生成的特征表示中解码出目标序列. 实验结果表明, 相比pix2code、image2emmet 等对比模型, 本文提出的image2code 在生成Web 前端代码的准确性上有更好的表现. 在未来的工作中, 一方面将寻求在编码器部分加入目标检测的算法, 以更好地捕捉UI 图像组件, 进一步降低注意力计算的开销; 另一方面将利用Web 前端代码数据集预训练解码器, 改进解码器的解码效果, 进一步提升模型生成代码的准确性. 此外, 我们计划通过挖掘开源仓库的方法, 得到网页UI 截图及其Web 前端代码, 在真实数据集上训练模型.
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
仪器仪表用户(2020年5期)2020-05-04 12:36:18
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电子世界(2016年15期)2016-08-29 02:14:28
电子器件(2015年5期)2015-12-29 08:42:24
电子科技(2015年2期)2015-12-20 01:09:20
