
基于残差网络和深度可分离卷积增强自注意力机制的窃电识别
2023-09-22 01:10段志尚吕笃良钟佳晨袁培森
华东师范大学学报(自然科学版) 2023年5期
段志尚, 冉 懿, 吕笃良, 祁 杰, 钟佳晨, 袁培森
(1. 国网新疆电力有限公司 营销服务中心(资金集约中心、计量中心), 乌鲁木齐, 830000;2. 南京农业大学 人工智能学院, 南京 210031)
0 引 言
在智能电网系统的运行中存在两种类型的电力损失: 技术性和非技术性损失[1]. 技术性电力损失的产生由电力设备的物理性能量损耗所引起; 非技术性电力损失的产生主要由用户窃电和电表计量错误所引起[2]. 由于技术性电力损失是物理设备产生的, 无法通过其他非物理技术手段来避免, 因此大量的研究都专注于智能电网的非技术性电力损失. 用户窃电是非技术性电力损失影响智能电网电力经济损失的主要原因[3], 全球每年因窃电的损失近千亿美元[4]. 窃电行为是每个国家智能电网系统都要面对的严重问题, 其造成的损失严重危害到国家经济建设和电力安全. 为了免遭损失和维护用电安全,必须进一步加强对窃电行为的检测.
传统的窃电行为检测方法主要依靠突击检查和电能表检测, 但存在的缺陷和不足很大. 伴随着机器学习的发展,Z-score[5]等方法常用作窃电检测的手段, 但是这种完全基于数据统计信息的窃电分类方法, 在分类效果上往往很差. 在传统机器学习中, 分类器不能获得较强的鉴别性特征, 表现结果一般较差. 值得注意的是, 随着计算机算力的提升, 深度学习作为一项特殊的机器学习分支, 逐步体现出强大的模型泛化能力和分类准确度[6]. 因此, 本文考虑将深度学习思想运用在窃电判别工作中, 以尝试获得较强的鉴别性特征, 提升分类器的鉴别能力.
在深度学习中, 卷积神经网络 (convolution neural network, CNN)[6]经常被用于数据的浅层特征和深层特征的学习和提取, 即通过梯度下降法的策略, 使CNN 模型通过分类器的分类评价自动地学习和调整特征提取层的参数, 不断地对数据进行迭代训练, 最终会获得一个非常好的特征提取器.Li 等[7]提出了混合随机森林 (random forest, RF)[8]的CNN 窃电检测模型, 该模型首先使用窃电数据训练卷积特征提取层, 再将获得的特征用于训练RF 分类器, 通过RF 的最终分类结果来决策用户是否窃电. Hossein 等[9]使用引导聚类 (bootstrap aggregating, Bagging)[10]集成学习与CNN 相结合的方法, 对电力消费数据的正常用户和窃电用户识别分类, 但是使用此集成技术的深度神经网络(deep neural network, DNN)计算的代价高昂, 并不适宜用于窃电行为的实时监控.
由于窃电检测的数据通常是时间序列型的, 除了会包含内在的复杂特征, 也会存在时间索引之间的相关性依赖. CNN 模型在局部特征提取上的性能表现得十分优越, 但是在时间序列的长依赖相关性提取上表现效果较差. 注意力机制 (attention mechanism)[11]和长短时记忆网络 (long short-term memory, LSTM)[12]在学习长时间依赖相关性方面要优于CNN 模型. Chen 等[13]利用多尺度卷积(multiscale convolution) 和注意力机制相结合的方法, 提出了多尺度注意力CNN 模型框架, 用于时间序列分类任务. Nazmul 等[14]使用一种基于CNN 和LSTM 的深度学习算法模型, 结合不平衡数据过采样技术对为期一年的窃电数据进行识别, 在评价指标上超过了仅使用CNN 的窃电识别模型.
考虑到传统机器学习的不足以及注意力机制在处理时序数据中的优势, 本文考虑使用自注意力机制学习长时间序列的相关性依赖作为CNN 提取特征的弥补. 最终, 本文结合残差网络 (residual network, ResNet)[15]和深度可分离卷积增强自注意力 (depthwise separable convolution enhanced self attention, DSCAttention)[16]机制, 提出了智能窃电识别方法, 并在真实窃电数据上进行了实验和分析. 相比于其他方法, 本文方法提升了窃电识别的准确率, 并有更好的AUC、MAP@100 和MAP@200 指标结果.
1 窃电时序数据预处理
时序数据的预处理与分析过程, 是建立时序分类模型的关键. 特征分析的好坏在很大程度上会影响时序分类模型的质量. 平稳序列是一种可认为在某个固定水平上随机波动的序列, 基本不存在趋势特征. 非平稳序列是一种变量, 无法呈现出一个长期趋势并最终趋于一个常数或是一个线性函数的时间序列[17]. 电力数据通常具有时序特点, 因此电力行业通常研究的是非平稳序列. 图1 所示的本文选取的窃电数据变化曲线即是非平稳序列.

图1 选取2014 年9 月的窃电数据变化曲线Fig. 1 Select change curve of electricity theft data from September 2014
图1 所示是正常用电户和窃电用户在2014 年9 月的用电数据. 其中, 纵轴表示用电量, 单位为千瓦时 (kW·h) ; 横轴表示数据记录的日期; 蓝色时序变化曲线是正常用电户; 红色时序变化曲线是窃电用户. 初步分析正常用电户和窃电用户的时序特征, 通过观察, 难以得出有用的鉴别特征. 因此, 本文使用加性模型分解和格拉姆角场(Gramian angular field, GAF) 这两个方法来完成时序的特征工程处理.
1.1 加性模型分解
非平稳时序数据的趋势项和季节性特征, 一般表现为较为复杂的形式. 因此难以对原序列数据进行特征分析. 使用加性模型对时间序列进行分解, 将时序复杂的内在特征分解为趋势项特征和季节项特征, 从而可容易地分析时序的内在特征. 时序加性模型所对应的公式为
式 (1) 中:Tt是原时间序列;Ttrend,t是时间序列加性模型的趋势项;Sseasonal,t为季节项;Rresid,t是时间序列的加性模型的残差项. 时序加性模型的趋势项Ttrend,t的计算公式为
式(2)中:yt+i表示时间序列T在t+i时刻的值;m=2k+1,表示m阶滑动平均. 本文在时序复杂特征提取上使用二维CNN[16], 采用文献[18] 的以7 d 为1 个周期的划分方法, 将一维时序数据转换为二维空间时序数据, 所以滑动平均的阶数或周期为7, 即k=3 . 根据式 (1) 对加性模型的定义, 季节项与残差项的和为时间序列减去趋势项. 定义t+i的集合为{t+1,t+2,··· ,t+m}, 则时序加性模型季节项的计算公式为
需要指出的是, 式 (1) 中的残差项Rresid,t为原时间序列Tt减去趋势项和季节项; 然而本文最终使用的完整模型已包含残差项的处理(ResNet), 因此, 此处无需重复使用和体现, 即残差项取值为0.
1.2 格拉姆角场
格拉姆角场 (GAF)[19]是一种可以把时序数据转换为空间数据的方法. GAF 将笛卡儿坐标系的时序数据转换到极坐标系, 通过计算极坐标系中各时间上的数据特征之间的夹角, 计算分析时序在不同时间之间的相关性. GAF 的计算公式为
式 (4) 中:G是一个大小为n×n的方阵; c os(φi+φj) 形式的方程是GAF 定义的特殊内积. 设需要计算GAF 的一维向量为X={x1,x2,···,xn}, 向量X的长度刚好为n, 式 (4) 中的φ1为 a rccos(x1) , 那么cos(φi+φj)的具体计算过程所对应的公式为
其中,i、j表示一维向量X的索引. 根据式 (4) 和式 (5), 对正常用电数据和异常用电数据分别求GAF 值, 并进行时间相关性的分析.
2 基于ResNet 和DSCAttention 机制的窃电识别
本文所提的窃电分类算法研究工作的实施流程如图2 所示, 且具体实施步骤如下.
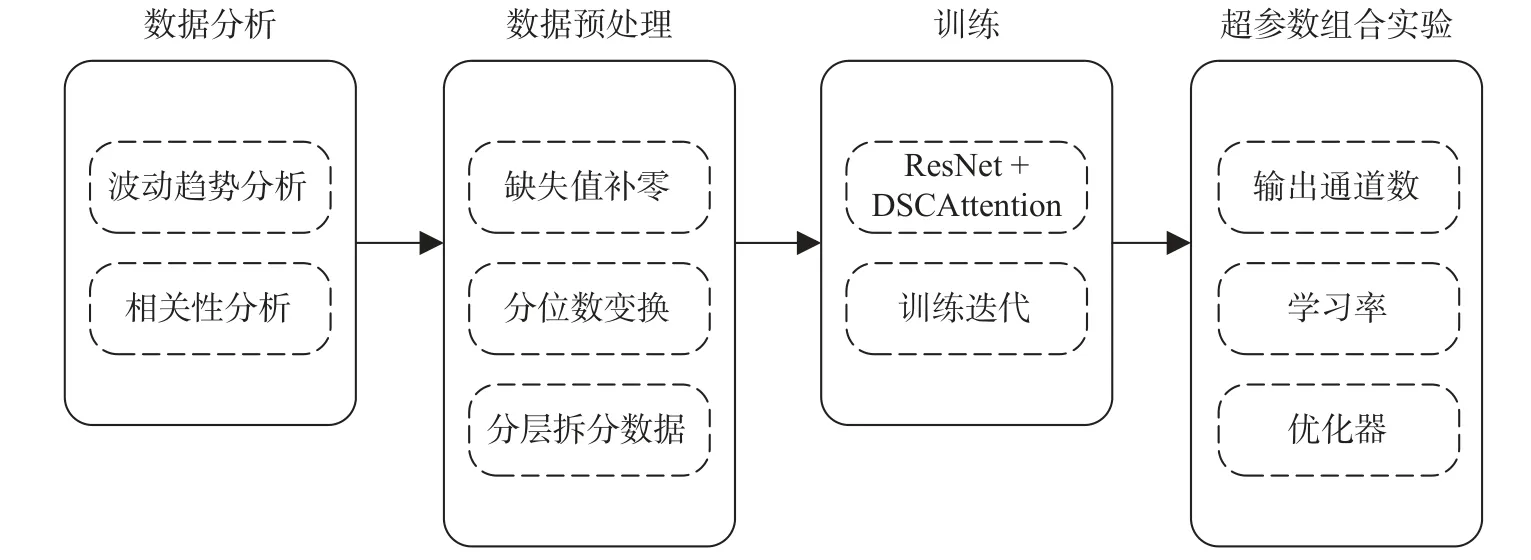
图2 所提的窃电分类模型整体实施流程Fig. 2 Overall implementation process of proposed electric theft classification model
(1) 对获得的数据进行数据分析. 通过趋势季节分析和相关性分析, 得出可鉴别性较强的时序数据特征, 并依此准备深度学习算法模型的设计和构建.
(2) 在进行数据的特征分析之后, 进入数据预处理环节. 数据预处理环节主要是分析和处理数据存在的缺失值, 并构造掩码矩阵. 使用分位数变换对数据规范化降低模型对异常值的敏感度; 使用分层拆分数据集的方法划分训练集和验证集.
(3) 当数据处理完毕, 即进入深度学习模型的搭建和训练阶段. 在模型训练过程中, 需要调整不同的超参数以期找到在分类评价上效果最好的超参数组合. 最后, 用在各评价指标上的最佳模型与其他模型进行对比, 得出本文所用模型的优势所在.
2.1 窃电数据预处理方法
窃电数据预处理方法主要有缺失值、标准化和异常值、不平衡数据处理这3 种.
2.1.1 缺失值
本文采用文献[1] 处理缺失值的方式来解决样本数据缺失的问题. 首先创建一个和样本数据尺寸相同的掩码矩阵, 掩码矩阵初始化为全0 矩阵; 然后确定样本中缺失值的位置, 在掩码矩阵中相同的位置处补1, 样本数据矩阵则在缺失值处补0. 缺失值填充方法所对应的公式为
式(6)中: NaN (not a number)表示非数据类型值;i表示原数据矩阵中值的位置;xi表示原数据矩阵位置i处的值;F(xi) 即为处理后的填充值. 使用的缺失值填充方法中的掩码矩阵的构造方式为
其中H(xi) 即为对应数据在掩码矩阵中的掩码值.
2.1.2 标准化和异常值
常见的标准化方法为最大和最小归一化 (maximum and minimum normalization) . 其公式为
式 (8) 中:Xmin是X中 的 最 小 值;Xmax是X中 的 最 大 值;xi是X中 的 值. 最 大 值 和 最 小 值 归 一 化 方 法对异常值敏感. 为了解决这一问题, 使用分位数转换的数据标准化处理方法. 分位数转换是利用数据的分位数信息进行转换的方法, 适合平滑存在异常分布问题的数据.
2.1.3 不平衡数据处理
由于数据集的不平衡性, 随机拆分训练集和验证集的方法将会导致训练集的负样本很少或没有,也可能会导致验证集的负样本很少或没有. 为了解决上述问题, 本文采用分层抽样 (stratified sampling)随机拆分训练集和验证集的方法. 相应公式为
首先, 计算原数据集的正/负样本比例Dold-normal:Dold-outlier; 然后, 在训练集和验证集随机抽取时, 保证训练集和验证集中的正/负样本比例Dnew-normal:Dnew-outlier维持在原数据集中的正/负样本比例.
2.2 基于ResNet 和DSCAttention 的模型框架
基于ResNet 和DSCAttention 的模型框架由ResNet 结构、基于CNN 的窃电数据复杂特征提取、通道自注意力机制和深度可分离卷积增强自注意力机制等组成.
2.2.1 ResNet 结构
本文基于ResNet 卷积网络和深度可分离卷积增强自注意力机制 (DSCAttention) 的窃电分类模型框架如图3 所示. 其中,α表示 depthwise3-8 的输出结果,β表示 depthwise3-16 的输出结果,f表示 pointwise1-48 对结果的联合计算操作, 这些网络结构详见表1. DSCAttention 是图3 模型结构图中红色虚线框部分的深度可分离卷积增强自注意力. 该模型的主要创新点在于将ResNet 卷积网络的直连部分改为由卷积增强的自注意力机制进行加权. DSCAttention 可用于学习时间相关性特征, 以及弥补CNN 在特征提取过程中所缺失的长时间依赖特征.

表1 网络参数对比Tab. 1 Comparision of network parameters

图3 ResNet + DSCAttention 整体模型结构图Fig. 3 ResNet + DSCAttention model structure diagram
本文模型在ResNet18 网络基础上, 加入了注意力层和深度可分离卷积结构, 模型结构的各层网络参数详见表1. 本文模型修改了ResNet18 的第一个卷积层(convolution, Conv)和最大池化层(maxpool), 降低了对原特征输入的下采样倍数; 除了修改了ResNet18 的第二个卷积层和第三个卷积层的输出通道数, 还引入了深度可分离(depthwise)卷积结构中的逐通道卷积和逐通道自注意力(attention)机制; 逐点(pointwise)卷积层与上层逐通道卷积构成完整的深度可分离卷积结构; 两层全连接(full connection, FC)神经网络作为分类器.
2.2.2 基于卷积神经网络的窃电数据复杂特征提取
本文模型用于时序趋势项和季节性特征提取的CNN 是图4 所示的深度可分离卷积(depthwise separable convolution, DSC) 操作计算过程. 逐通道卷积对输入矩阵X的特征通道进行计算, 输出变换后的输出矩阵, 再使用逐点卷积对每个通道的特征进行融合.
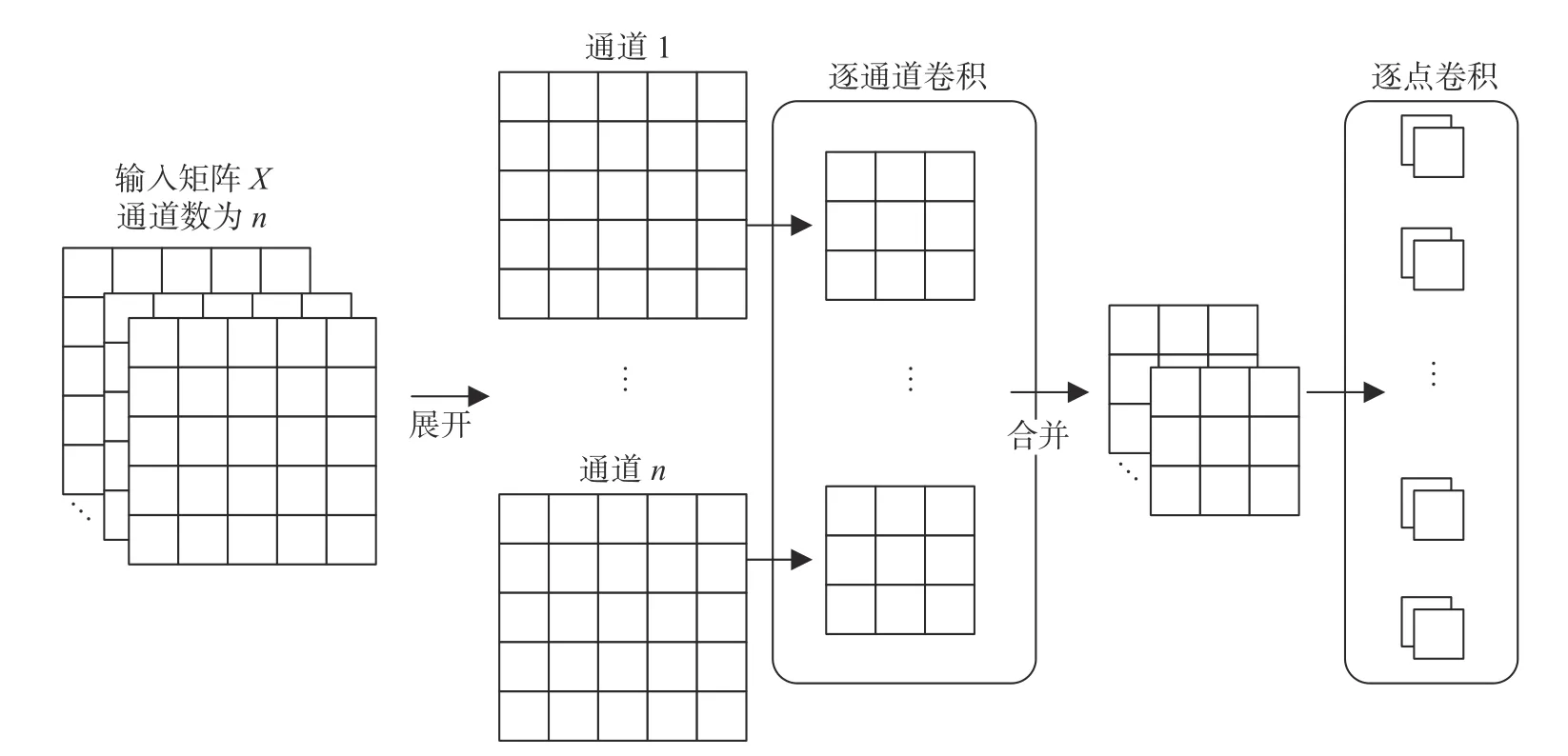
图4 深度可分离卷积操作Fig. 4 Depthwise separable convolution (DSC) operation
2.2.3 通道自注意力机制
注意力机制是一种考虑全局信息的方法. 卷积神经网络的缺点一般在于具有很强的提取局部信息的能力, 而对全局信息的考虑和关注则较少. 在窃电时序数据中, 用户的用电行为具有长时间相关性, 局部性卷积无法胜任学习长时间相关性的任务.
注意力机制主要有Soft Attention[20]、Hard Attention[21]和自注意力[22]这3 种, 本文使用的注意力机制方法多头自注意力机制, 它是自注意力机制方法中的一种, 其计算公式为
其中,Q、K、V为输入矩阵X经过权重参数分别为WQ、WK、WV的全连接层映射后的输出矩阵.使用公式 (10) 即可计算出输入矩阵X的自注意力分布. 本文使用的自注意力分布计算方法是文献[1] 结合通道注意力思想的多头自注意力机制方法. 其计算过程详见图5.
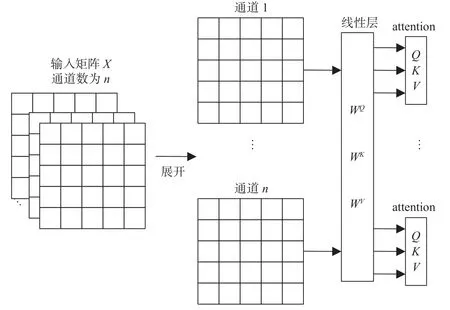
图5 逐通道自注意力计算Fig. 5 Channel-by-channel self-attention computation
2.2.4 深度可分离卷积增强自注意力机制
由于本文使用的自注意力机制是逐通道多头自注意力方法, 因此将卷积增强部分的常规卷积神经网络替换成了逐通道卷积神经网络, 从而形成基于深度可分离卷积(DSC)增强的自注意力方法,即DSCAttention. 该方法的计算过程如图6 所示.

图6 深度可分离卷积增强自注意力机制Fig. 6 DSC enhanced self-attention mechanism
3 实验及结果分析
3.1 实验环境
实验平台为Windows10 操作系统, CPU 处理器为Intel(R) Core(TM) i7-8750H CPU @ 2.20 GHz,内存为16 GB, GeForce GTX 1050, 显存为8 GB. 模型采用PyTorch 1.10.2、 Python 3.9.7、 scikitlearn1.2.1 和CUDA 10.2 实现.
3.2 数据集
本文实验数据来自https://github.com/henryRDlab/ElectricityTheftDetection, 该数据集包含从2014-01-01—2016-10-31 共1 034 d 的42 372 条样本数据. 样本数据详见表2.

表2 样本数据Tab. 2 Sample data
3.3 评价指标
本文采用ROC (receiver operating characteristic) 曲线下与坐标轴围成的面积 (area under curve,AUC) 和平均准确率 (mean average precision, MAP) 这2 个评价指标.
3.3.1 AUC
AUC 评价指标是模型对正样本和负样本的预测, 且正样本预测值大于负样本预测值的概率, 本文用SAUC表示. 相应公式为
3.3.2 MAP
MAP 也常被用来评价模型的质量, 本文用PMA表示. MAP 计算如下. 首先, 定义公式
式 (12) 中:k表示对预测进行降序排序后的前k个用电用户;Yk表示前k个用电用户当中实际产生窃电行为的用户数;P@k表示前k个用电用户中预测为窃电用户并且真实值为窃电用户的平均概率. 然后定义MAP. 其计算公式为
式 (13) 中:S表示对预测值降序排序后的前S个用电用户;r表示这S个用电用户中实际产生窃电行为的用户数;ki表示实际发生窃电行为的用户在S中的位置. 本文使用MAP@100 和MAP@200 分别对排序后的预测值向量选取前100 和200 个用户进行实际分类效果评价.
3.4 实验结果
3.4.1 基于加性模型分解的窃电趋势和季节特征实验分析
对原时间序列使用趋势项分解方法, 得到图7 所示的时间序列趋势变化曲线, 其中, 纵坐标的趋势值通过公式 (2) 计算得出, 其单位为千瓦·时 (kW·h) . 在电力时间序列的趋势项中, 正常用电户样本的趋势值整体要比窃电用户样本的趋势值的波动性更强.

图7 电力消费数据的趋势变化曲线Fig. 7 Variation curve of electricity consumption data in trend
本文采用文献[18] 划分时序周期的方法, 设置滑动平均阶数为7, 故需要对每7 d 的用电量的时间变化曲线进行分析和二维重建. 正常用户和切点用户的趋势项每7 d(1 周)的变化曲线, 如图8 (a)和8 (b) 所示.
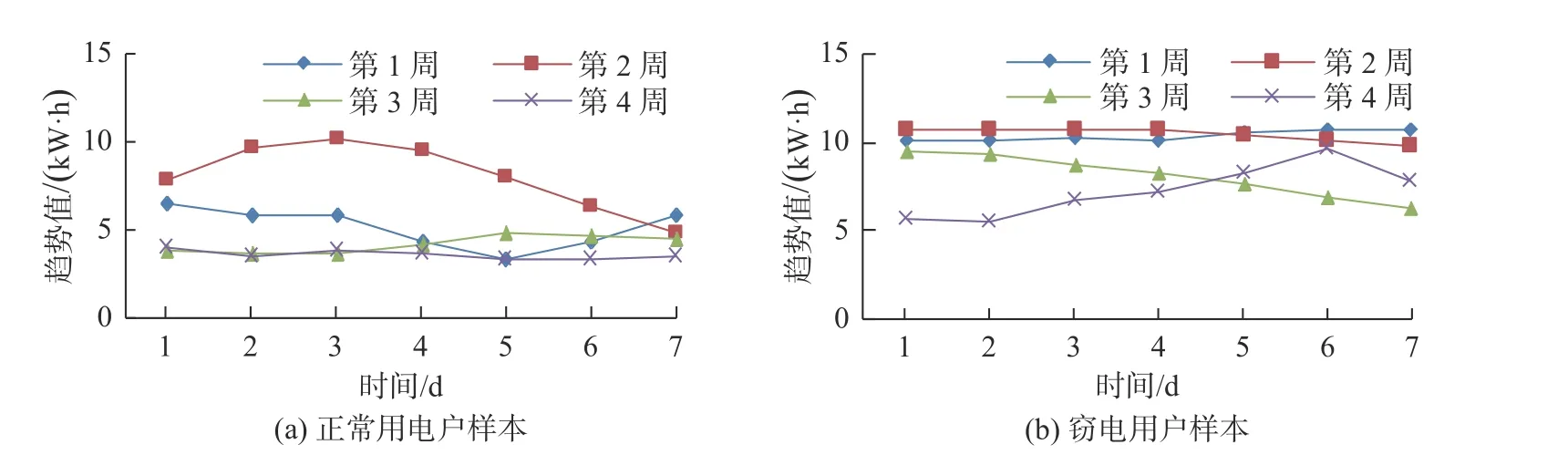
图8 以周为间隔的趋势变化曲线Fig. 8 Variation curve of trend with weekly intervals
图8 所示的以周(7 d)为间隔划分的趋势项, 在正常用电户样本和窃电用户样本之间的区别与图7中所示没有改变.
对原时间序列分解得到时序季节项如公式 (3) , 得到如图9 所示的时间序列季节性特征. 季节项是使用每7 d 的原时间序列减去趋势项后, 求平均得到的每7 d 的季节项值. 该季节项值反映的是每7 d为1 个周期的季节项变化.
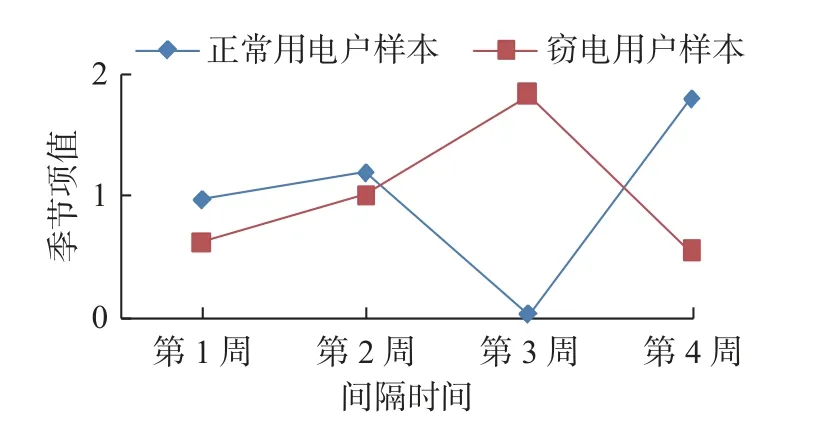
图9 以周为间隔的季节项变化曲线Fig. 9 Variation curve of season with weekly intervals
从图9 可以看到, 正常用电户样本的季节项与窃电用户样本的季节项区别明显. 从序列的周期性方面分析, 正常用电户样本的季节性变化刚好落后于窃电用户样本的季节性变化1 个周期的时间.
3.4.2 基于格拉姆角场的窃电时序相关性实验分析
时间序列除季节性、趋势等内在复杂特征外, 还存在时间索引之间的相关性特征. 为了证明电力消费数据之间存在时间索引的相关性, 本文使用GAF 公式计算样本内周与周之间的相关性. 其结果如图10 所示. 图10 是以周为间隔划分数据后, 求得的周与周之间的GAF 相关性值的可视化结果.

图10 电力消费数据的格拉姆角场Fig. 10 Gramian angular field (GAF) of electricity consumption data
由图10 (a) 和图10 (b) 中的GAF 值可知, 正常用电户样本和窃电用户样本的第1 周与其他周的相关性有明显不同. 通过使用GAF 计算时间序列之间的相关性, 并可视化分析后可得, 本文所使用的时间序列数据的正负样本之间存在可区别的时间相关性特征.
3.4.3 本文模型与其他模型实验结果对比
为评价本文模型在窃电识别任务上的性能, 将本文模型与 RF[8]、支持向量机 (support vector machine, SVM)[23]和 WDCNN (wide & deep convolutional neural networks)[18]这3 种模型在指标AUC、MAP@100 和MAP@200 上的评价进行对比. 比对结果如表3 所示.

表3 不同方法的分类评价指标Tab. 3 Classification evaluation indicators for different methods
⑴ 在各模型最佳的AUC 上, 本文模型比RF 提升了11.84%, 比SVM 提升了10.34%, 比WDCNN提升了11.46%.
⑵ 在MAP@100 上, 本文模型比RF 提升了14.33%, 比SVM 提升了9.23%, 比WDCNN 提升了31.01%.
⑶ 在MAP@200 上, 本文模型比RF 提升了20.62%, 比SVM 提升了13.04%, 比WDCNN 提升了29.76%. 相比MAP@100, MAP@200 在不同模型下的性能均有所下降. 这是因为MAP@200 所选取的数据更多, 模型拟合情况也更为复杂. 考虑到窃电数据中存在的噪声等系统性干扰, MAP@200 的实验结果依然是符合预期的.
图11 是本文模型与其他对比模型实验的ROC 曲线. 通过观察这4 个模型的ROC 曲线, 可以看到, 本文模型的ROC 曲线 (图中的蓝色曲线) 比WDCNN、SV 和RF 的都要高, 即本文模型在窃电识别任务上的性能表现更好.
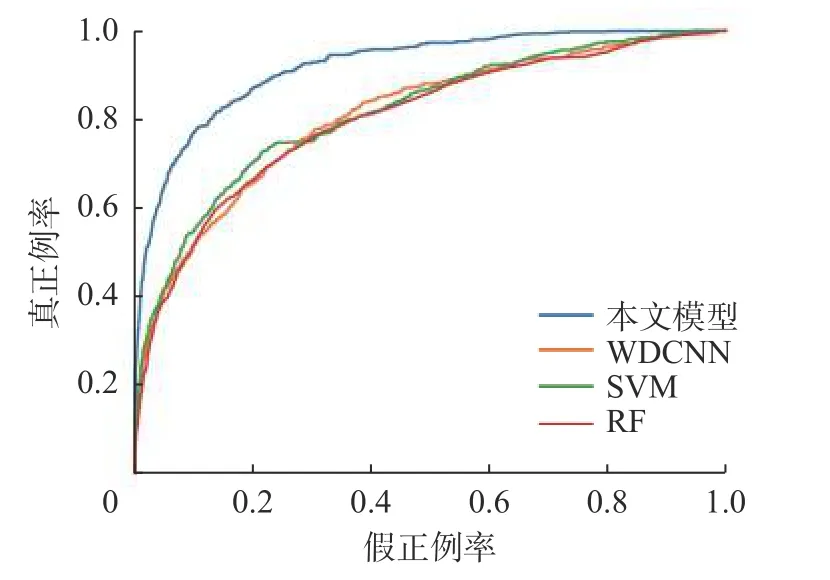
图11 不同模型的ROC 曲线Fig. 11 Receiver operating characteristic (ROC) curves of different models
因此可得出结论, 本文模型相比于RF、SVM 和WDCNN, 在电力数据的窃电识别任务上表现更好, 识别的准确度更高.
4 结 论
本文在ResNet 结构基础上, 引入注意力机制提取时间序列相关性特征, 使用深度可分离卷积作为卷积增强学习序列周期间和周期内的局部相关性, 对窃电用户进行智能化分类, 并在真实用电数据集上进行了实验对比与分析. 实验结果表明, 相比于本文中所对比的其他模型, 本文方法的AUC、MAP@100 和MAP@200 指标都较好, 本文方法可以用于窃电智能化检测.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中国农业信息(2021年3期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2017年13期)2017-12-15
传媒评论(2017年3期)2017-06-13
电子制作(2016年15期)2017-01-15
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
