
面向半监督节点分类的双通道图随机卷积网络
2023-08-29 02:02李程鸿朱小飞
小型微型计算机系统 2023年8期
李程鸿,朱小飞
(重庆理工大学 计算机科学与工程学院,重庆 400054)
1 引 言
图是描述实体之间的成对关系的基本数据结构,如社交网络、学术网络和蛋白质网络等,学习和挖掘图数据可以帮助解决各类现实应用问题.本文的研究重点是图的半监督学习问题,半监督学习的节点分类是图数据挖掘的一项重要任务,通过给定图中一小部分节点的标签,来预测图中其他节点的标签.图卷积网络(Graph Convolutional Network,GCN)通过聚合邻居节点的特征来生成节点的新表示,实现从图数据中提取有效特征.近年来图神经网络已经被广泛应用于许多领域,包括节点分类[1-4]、图分类[5,6]、链路预测[7]和推荐系统[8,9]等.
最近的一些研究[10]发现GCN存在一些不足:1)GCN仅仅通过聚合拓扑图邻居特征来进行分类任务是远远不够的,由于拓扑图中无法避免地存在噪音边,GCN不能充分融合节点特征和拓扑结构来提取出相关的信息,影响了最终的分类性能.因此,仅通过节点特征在原始拓扑图上的传播无法学习到可以有效区分节点类别的表示.Wang等人[1]通过计算节点特征间相似度后得到一个特征图,然后使节点特征分别在拓扑图和特征图上进行消息传递,该方法有效地利用了节点的特征信息,但由于特征图中也会存在噪音边,并且在消息传递过程中忽略了拓扑图和特征图之间的交互关系,因此该方法不能有效地突出拓扑图和特征图在消息传递过程中间最有价值的信息;2)当GCN层数叠加过多后,节点的表示都倾向收敛于某一个值,即过度平滑.固定的传播结构使每个节点高度依赖于它的邻居,导致在消息传递过程中容易受到节点特征中潜在的噪音干扰,并且容易受到对抗扰动的影响[11].数据增强技术现已应用于许多图像领域[12,13],图像数据增强一般通过改变图像自身的属性来扩充图像,这种方法不会影响到其他图像.但是,图数据和图像数据不同,其中一个显著区别是图数据中的节点是相互连接的,而图像是独立的,因此,图像数据增强的技术无法直接用于图数据增强上.目前,已有一些工作对图数据增强技术进行了研究.例如,Wang等人[14]提出通过修改节点属性和图结构的数据增强策略,对图中的每个节点独立地并行增强.即分别为每个节点用其邻居的属性来替换自身的部分属性,并添加或删除该节点与其邻居的边.但是,这种通过替换节点部分属性的方法不可避免地会导致节点自身属性信息缺失.Zhao等人[15]利用链路预测对原始图有策略的添加边或删除边以提升类内边数并且降低类间边数,从而来提高节点分类的性能.Feng等人[11]提出一种随机传播的方法,使节点的特征可以随机地部分或全部丢弃,然后将扰动的特征表示在拓扑图中进行传播,然后利用一致性正则化来优化不同节点数据增强表示中未标记节点的预测一致性.这两种方法都没有充分利用节点特征中深层次的信息,因此,图数据增强技术仍有较大的研究空间.
对于图数据的半监督分类问题,为了充分挖掘特征空间中的信息,学习到多方面的节点表示,本文提出一种面向半监督节点分类的双通道图随机卷积网络(Dual-channel Graph Random Convolutional Network,DC-GRCN).主要思想是生成多个图节点数据增强,使这多个增强的节点特征表示同时在拓扑空间和特征空间中传播.首先,为了充分利用节点特征中的信息并弥补GCN中节点特征仅在拓扑图上进行信息传播的不足,除原始的拓扑图外,还利用节点特征生成的k近邻图作为特征图,特征图从节点特征空间角度为每个节点选择与拓扑图不同的邻居节点,从而减小拓扑图中噪音边的影响.然后,为了降低噪音数据的影响,本文随机地对节点特征矩阵中的数据进行扰动,并将扰动过程重复多次,从而得到多个增强的节点特征表示.将这些增强的节点特征表示分别在拓扑空间和特征空间中同时传播,使得模型能够关注到节点不同方面的信息,从而达到数据增强的效果.通过数据增强,降低了节点对固定邻居的依赖性,由于同一个节点在不同的增强特征矩阵中学习到的节点表示不同,增加了节点表示的多样性,从而在一定程度上避免了GCN的过度平滑问题.此外,在拓扑图GCN和特征图GCN的传播过程中,引入了一种层级注意力机制,具体做法为,对于拓扑图和特征图的GCN在每个对应隐藏层输出的两种节点表示,通过注意力机制对其进行动态融合,生成的新节点表示分别作为拓扑图GCN和特征图GCN的下一层的输入.层级注意力机制有助于突出节点表示中更有价值的信息,降低噪音特征和噪音边的影响.最后,将拓扑图GCN和特征图GCN最后一层所有的输出动态地进行结合,得到最终用于分类任务的节点表示.此外,本文还设计了一个一致性约束,以保证GCN最后一层的多个节点表示之间保持一致性.
本文的主要贡献如下:
1)提出了一种新的GCN框架DC-GRCN,它更好地利用了拓扑空间和特征空间的信息,使GCN能够关注到节点特征不同方面的信息.
2)提出了一种用于GCN间的信息交互方法,它可以自适应地融合多个GCN隐藏层中更有价值的信息.
3)在5个基准数据集上的大量实验表明,本文提出的DC-GRCN在半监督节点分类任务上性能提升显著.
2 相关工作
现有的图卷积神经网络分为谱方法[16,17]和空间方法[3,18]两类,谱方法从谱域定义图卷积,而空间方法从节点域出发,通过定义聚合函数来聚合每个中心节点和其邻近节点[19].最早的趋势之一是将图的傅里叶变换应用于谱域[16].然后,Defferrard等人[17]进一步利用图拉普拉斯的切比雪夫展开来提高效率.后来,Kipf等人[18]简化了卷积运算,提出只聚合单跳邻居的节点特征的GCN模型:
(1)
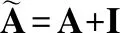
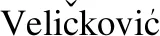
3 问题定义
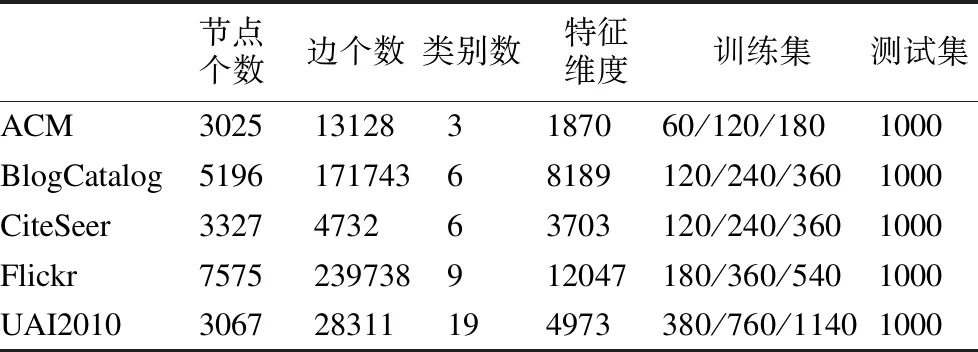
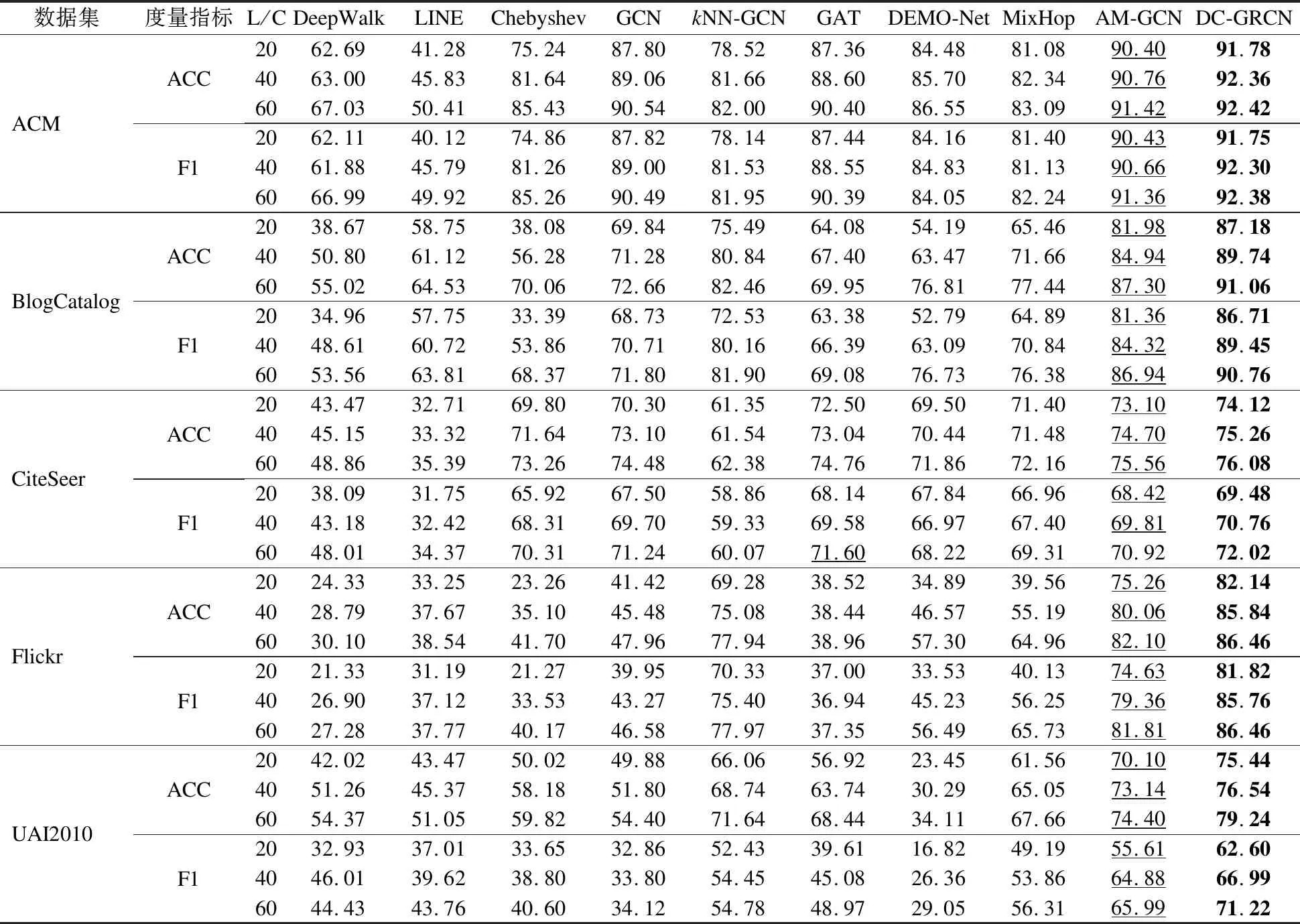
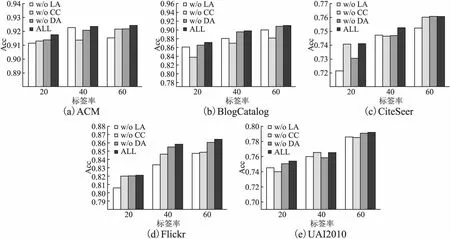
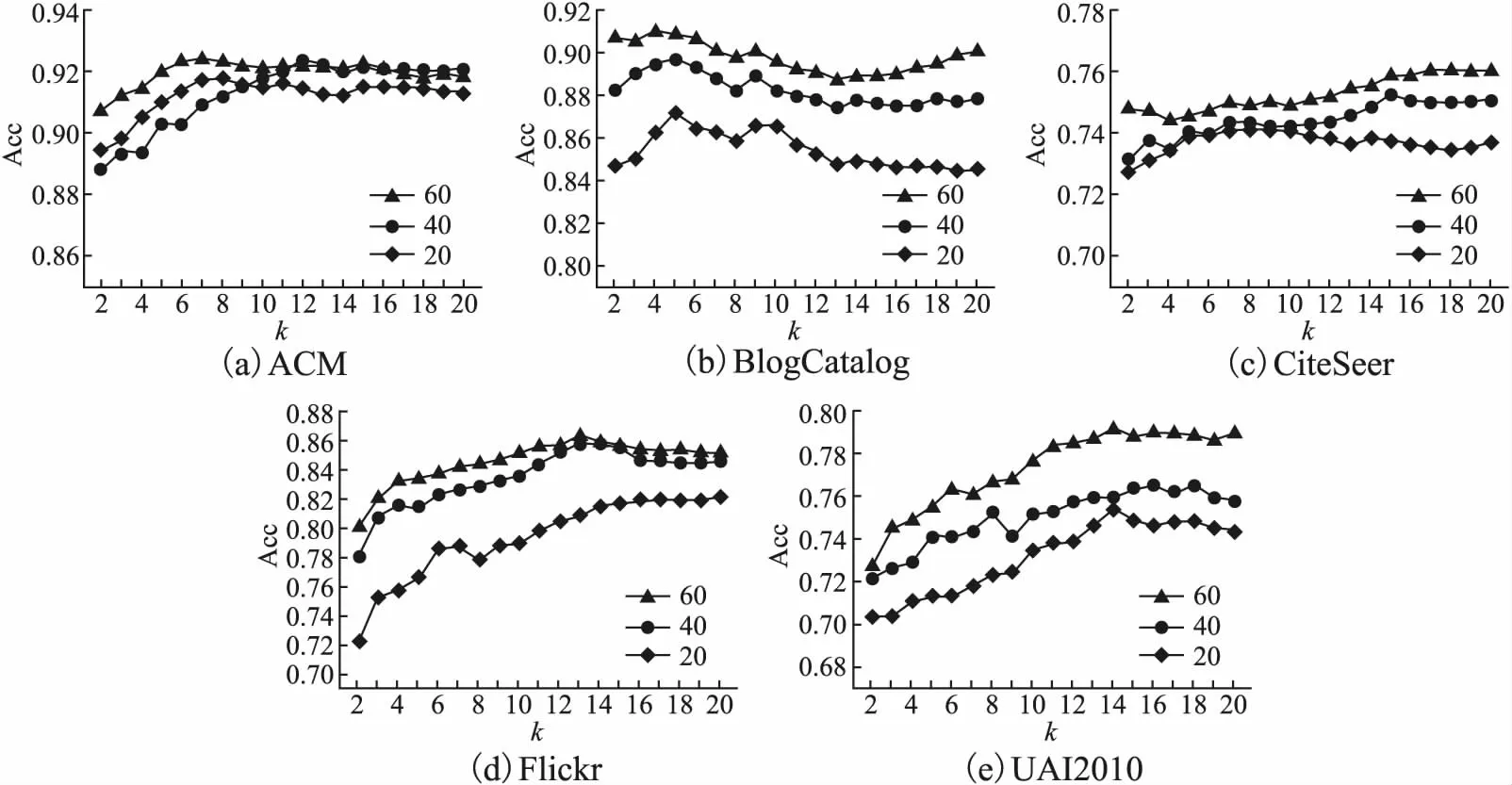
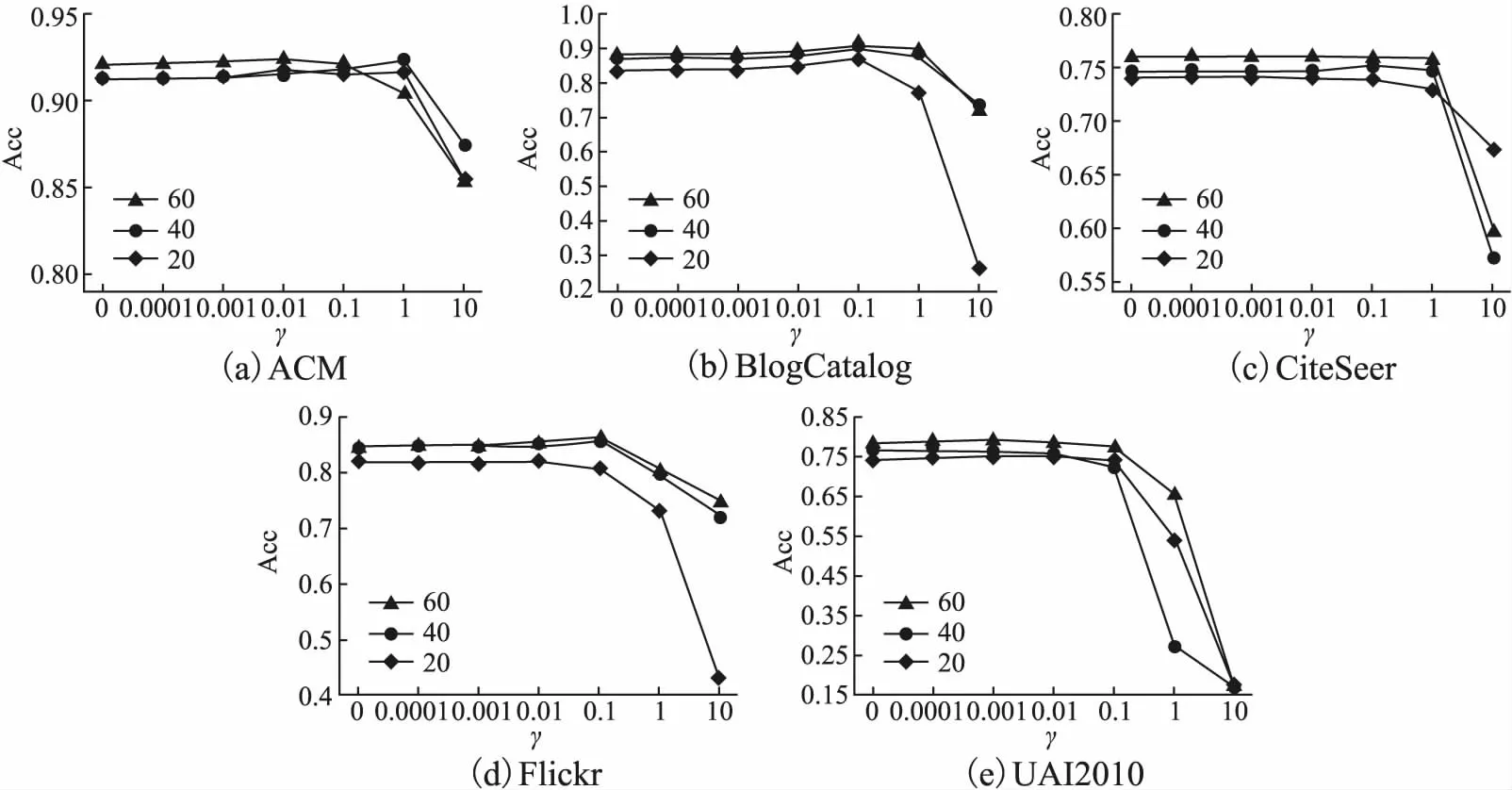
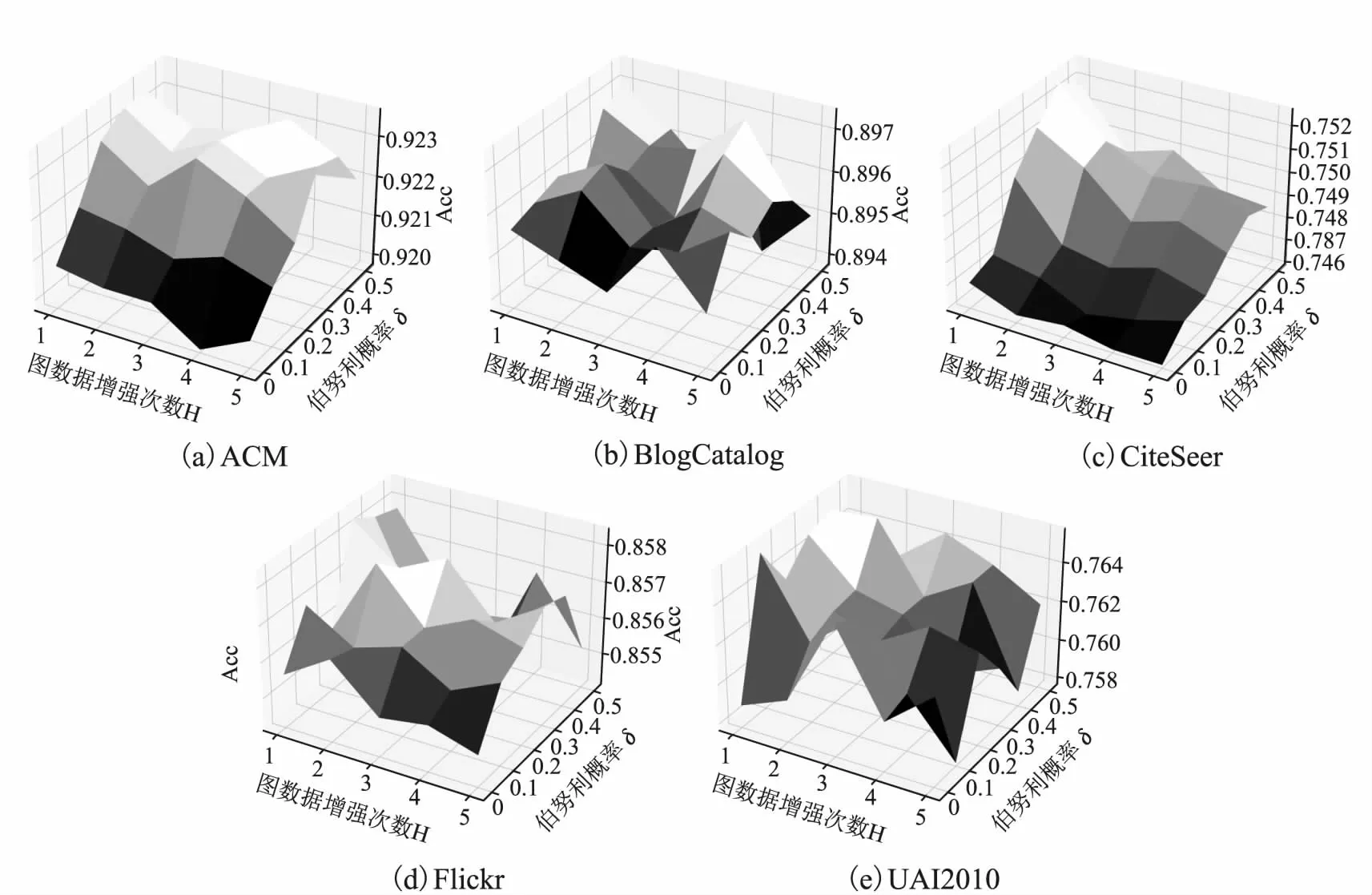
本文主要研究图数据的半监督节点分类任务.设G=(A,X)表示一个图,其中A∈n×n是有n个节点的邻接矩阵,对于其中的一个元素Aij=1表示节点vi与节点vj有一条边相连,否则Aij=0,X∈n×d是n个节点的特征向量,d是特征向量的维度.图中的每一个节点vi有它的特征向量xi∈X和标签yi∈Y∈{0,1}n×c,其中c表示标签类别数.对于半监督分类,给定m个(0 图1 DC-GRCN结构图 经典的GCN通常将邻居节点的特征信息聚合到自身来学习节点表示.由于原始拓扑图中无法避免存在噪音边,这种只通过原始拓扑图来学习节点表示的方法远远不能准确的区分出节点的类别.为了解决这个问题,自然的想法就是充分地利用节点特征信息.因此,基于节点的特征X,构造出特征图Gf=(Af,X),其中Af∈n×n是特征图的邻接矩阵. 具体来说,首先使用距离度量函数,例如,余弦相似度、欧氏距离等,计算n个节点的相似度矩阵S.本文统一使用余弦相似度来计算节点间的相似度,对于节点vi和vj,将它们的特征向量记为xi和xj,它们的余弦相似度为: (2) 得到n个节点的相似度矩阵S后,为每个节点选择前k个相似节点,这些节点对组成特征图邻接矩阵Af的边. (3) 其中,εi来自Bernoulli(1-δ),δ是用来控制节点特征被置0的概率的超参数,xi表示X的第i行. (4) 通过上面的方法,可以分别在特征空间和拓扑空间上学习到多种节点表示.为了结合这些表示,并突出更有价值的信息[26],本文设计了一种将拓扑图GCN和特征图GCN的隐藏层中对应的节点表示自适应地结合的方法,从而得到更有效的节点表示: (5) 为了计算层级注意力,首先,使用注意力机制学习对应节点表示相应的重要性: (6) wfi=vT·tanh(W1·(zfi)T+b1) (7) 其中,W1∈m×m′是权重矩阵,b1∈m′×1是偏置向量,v∈m′×1是一个共享的注意力向量.同样地,zti的注意力值为wti.然后,使用softmax函数对wfi和wti进行归一化,得到最终的权重: αfi=softmax(wfi) (8) (9) (10) (11) (12) (13) 其中L是训练集中有标签的数据. (14) 结合节点分类任务的交叉熵损失和一致性约束损失,总的损失函数为: L=Lclass+γLcon (16) 其中γ是一致性约束的超参数.在训练集中有标签数据的指导下,通过反向传播来训练模型,学习用于分类的节点表示. 5.1.1 数据集 本文在5个真实数据集上评估了提出的方法,数据集统计汇总如表1所示. 表1 数据集统计 ACM[27]:该网络是从ACM数据集中提取的,其中节点代表论文.如果两篇论文的作者相同,那么它们之间有一条边.论文分为数据库、无线通信、数据挖掘3类.其特征是论文关键词的词袋表示. BlogCatalog[28]:它是一个博客社区社交网络的数据集,其中包含5196个用户节点,171743条边表示用户交互.用户可以将他们的博客注册到6个不同的预定义类中,这些类为节点的标签. CiteSeer[18]:这是一个论文引用网络,记录了论文之间引用或被引用信息,节点表示论文,共分为6类,节点属性是论文的词袋表示. Flickr[28]:这是一个包含7575个节点的基准社交网络数据集.每个节点表示一个用户,边代表用户之间的关系.根据用户的兴趣组将所有节点划分为9类. UAI2010[29]:该数据集有3067个节点和28311条边. 5.1.2 基线 为了验证本文提出的模型,将提出的方法与一些最先进的方法进行了比较.本文使用的基线结果来自AM-GCN[1]. DeepWalk[30]是一种网络嵌入方法,它使用随机游走来获取节点序列,然后借助自然语言处理的思想,将生成的节点序列看作由单词组成的句子,所有的序列可以看作一个大的语料库,最后利用word2vec将每一个顶点表示为一个相同维度的向量. LINE[31]是一种大规模的网络嵌入方法,分别保持网络的一阶和二阶邻近性,针对经典随机梯度下降算法的局限性,提出了一种边缘采样算法,提高了推理的效率和效果. Chebyshev[17]是利用切比雪夫滤波器在谱域实现图卷积神经网络的方法. GCN[18]是一种半监督图卷积网络模型,它通过聚合邻居的信息来学习节点表示. kNN-GCN[1]使用由特征矩阵得到的特征图代替传统的拓扑图作为GCN的输入图. GAT[3]在GCN的基础上引入注意力机制,在图卷积过程中为不同的邻居节点分配不同的权重. DEMO-Net[21]是一个具体度的图神经网络,提出多任务图卷积,即为不同度的节点使用不同的图卷积,从而保持具体度的图结构. MixHop[20]针对GCN在图卷积过程中只能使用邻居节点的信息的缺点,提出多阶邻域的卷积,对不同的邻域采用不同的聚合方式,然后将结果拼接或用其他方式结合. AM-GCN[1]同时从节点特征、拓扑结构及其组合中提取两个特定节点表示的和一个共同的节点表示,并利用注意机制学习这3种不同节点表示的重要性权重,将这些节点表示自适应地融合为最终的节点表示. 5.1.3 参数设置 在实验中,数据集采用AM-GCN相同的划分方式,即为训练集选择3种标签率(每类有20、40、60个标签节点),测试集包含1000个节点.数据增强层中,数据增强次数H∈{1,2,…,5},伯努利概率δ∈{0.1,0.2,…,0.5}.同时训练两个具有相同隐藏层数nhid1和相同输出维数nhid2的两层GCN网络,其中nhid1∈{512,768}、nhid2∈{128,256},dropout为0.5.Adam优化器的学习率和权重衰减范围为{0.0001,0.0005,0.001,0.005}.特征图中k近邻的k∈{2,3,…,20}.另外,一致性约束超参数取值范围为γ∈{0.0001,0.001,0.01,0.1,1}.对于所有方法,本文使用随机初始化运行实验5次,然后取平均作为最终的结果. 节点分类的结果如表2所示,L/C为每类标记节点的数量.实验结果分析如下: 表2 节点分类结果(%).(粗体:最优结果;下划线:次优结果) 1)与所有的基线相比,本文提出的DC-GRCN在所有的数据集上均达到了最优水平.与最优的基线AM-GCN[1]相比,本文提出的模型在BlogCatalog数据集上准确率最大提升6.34个百分点,macro F1-score最大提升6.57个百分点;在Flickr数据集上准确率最大提升9.14个百分点,macro F1-score最大提升9.63个百分点.实验结果表明了DC-GRCN的有效性,DC-GRCN能够更加充分地融合拓扑结构和节点特征间更深层次的信息,进一步有效地利用节点特征中的信息. 2)通过对比kNN-GCN和GCN的结果,可以发现拓扑图和特征图确实存在结构差异.并且,对于数据集BlogCatalog、Flickr和UAI2010这3个数据集上,kNN-GCN的结果要明显优于GCN,进一步说明了引入特征图的重要性. 3)在所有数据集上,DC-GRCN始终优于GCN和kNN-GCN,这说明DC-GRCN中注意力机制的有效性,它们可以自适应地从拓扑空间和特征空间中提取出最有用的信息. 4)对于同一个数据集,标签率越高,模型的性能越高,表明DC-GRCN能够有效地使用节点的标签指导信息. 本节研究层级注意力、一致性约束和图数据增强对DC-GRCN的贡献.主要包括3部分: 1)w/o LA.移除层级注意力模块,在进行GCN过程中,不对拓扑图GCN和特征图GCN的隐藏层节点表示进行交互. 2)w/o CC.移除一致性约束损失,在损失函数中不对GCN最后一层的各节点表示进行一致性约束. 3)w/o DA.移除图数据增强层,只使用节点原始特征参与训练和推理. 如图2为消融实验的结果,其中ALL为不做消融的DC-GRCN.根据实验结果得到的结论为: 图2 DC-GRCN在5个数据集上的消融实验 1)与完整的DC-GRCN相比,所有移除了某组件的DC-GRCN变体的性能都明显下降,这表明每个组件都起到了积极的作用. 2)删除了层级注意力模块后,在5个数据集上的实验结果均有较大程度的下降.可以看出,层级注意力模块可以自适应地融合从拓扑空间和特征空间中得到的信息,降低噪音信息的影响,从而获取更有用的节点表示,对于分类任务帮助较大. 3)一致性约束能够使多种节点表示尽可能的保持一致,加强了各节点表示的相关性,突出了它们的共同信息. 4)图数据增强模块将原始节点特征转换成多种表示,在图卷积过程中形成多通道,可以让模型关注到不同方面的信息,有助于模型学习到更丰富的信息. 为了更直观的比较本文方法的有效性,在标签率为20的BlogCatalog和Flickr数据集上执行可视化任务.将最后得到的节点表示使用t-SNE进行降维,得到如图3所示的可视化图. 图3 在BlogCatalog和Flickr数据集上学习的节点表示的可视化结果 从图3中可以看出,GCN学习到的节点表示把不同标签的节点都混到一起,不能很好地区分出各节点的类别;AM-GCN学习到的节点表示相对于GCN来说虽然能较为明显的区分各类,但类内相似性不够高;DC-GRCN能够学习到更为紧凑、类内相似性高、类间边界清晰的节点表示. 5.5.1 特征图参数的敏感性分析 为了测试特征图中k近邻的超参数k的影响,实验测试了k从2~20之间的DC-GRCN的性能,结果如图4所示.可以看出,随着k值的增加,DC-GRCN的性能呈现逐渐上升然后缓慢下降的趋势.例如,在数据集ACM标签率为60时,随着k值从2开始增加,准确率逐渐上升,当k为7时,准确率达到最高,然后准确率随着k值的增加缓慢下降.其他数据集也呈现与ACM相同的趋势.这说明,在一定范围内,特征图中增加的大多数是有助于分类的高质量的边.但随着边的增加,特征图越来越稠密,引入的噪音边就越多,从而导致分类性能下降. 图4 参数k的研究 5.5.2 一致性系数γ的敏感性分析 本节分析了公式(16)中一致性约束系数γ的影响,γ越大,一致性约束损失占比就越大.取值范围为γ∈{0,0.0001,0.001,0.01,0.1,1,10},结果如图5所示.从实验结果中可以观察到,随着γ的增加,准确率呈现先缓慢上升然后急速下降的趋势.例如,在数据集BlogCatalog中,随着γ从0开始增加,准确率先缓慢上升,当γ为0.1时模型达到最佳性能,当γ的值大于1后,模型性能开始下降.其他数据集也呈现与BlogCatalog数据集相同的趋势,这说明,一致性约束Lcon能够在一定程度上进一步提高本文提出模型的表达能力. 图5 参数γ的研究 5.5.3 图数据增强层超参数敏感性分析 本节分析分析图数据增强层中的超参数对模型的性能影响,主要的参数一个是特征增强个数H,另一个是Bernoulli概率δ.参数敏感性结果如图6所示,可以观察到,H和δ对模型的性能影响都起着积极的作用.对于ACM数据集,当δ固定时,对于不同的H相对来说比较稳定;当H固定时,不同的δ对模型性能影响较大.对于Flickr数据来说,当δ取值较大时(δ≥0.3),不同的H对模型性能产生影响较大.实验结果表明,图数据增强层能够有效地提升模型的性能. 图6 参数H和δ的研究 本文提出了一个面向半监督节点分类的图随机卷积网络DC-GRCN.首先,该模型利用节点特征矩阵生成一个特征图.然后,使用图数据增强层生成多个增强的节点特征矩阵,使其分别在拓扑空间和特征空间中进行传播,在传播过程中将两种空间中的节点表示动态地进行信息交互.最后,对于传播完成后的多个节点表示,使用注意力机制自适应地将它们结合,同时,对这些节点表示进行一致性正则化约束.在5个真实数据集上的大量的实验表明,本文的提出的方法优于最先进的方法.4 模 型
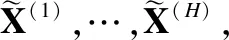

4.1 构建特征图
4.2 图数据增强层
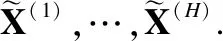
4.3 双通道图卷积网络

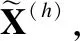

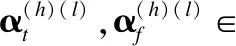
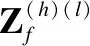
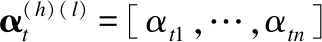
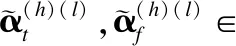
4.4 注意力机制
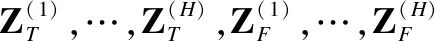
4.5 损失函数
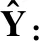
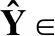
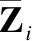
5 实 验
5.1 实验设置
5.2 节点分类
5.3 消融实验
5.4 可视化

5.5 参数敏感性实验
6 总 结
猜你喜欢
电子设计工程(2023年2期)2023-01-24
数学年刊A辑(中文版)(2022年1期)2022-08-20
公民与法治(2022年5期)2022-07-29
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
数学年刊A辑(中文版)(2020年2期)2020-07-25
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
燕山大学学报(2015年4期)2015-12-25
