
NAGSim:一种基于图神经网络与注意力机制的图相似计算模型
2023-08-29 01:10侯雅静李冠宇
小型微型计算机系统 2023年8期
侯雅静,宁 博,海 潮,周 新,杨 超,李冠宇
1(大连海事大学 信息科学技术学院,辽宁 大连 116000)
2(国网辽宁信通公司,沈阳 110000)
1 引 言
互联网的飞速发展产生了大量复杂并且相互关联的数据,这些数据通常可以用图结构进行表示.但如何高效地存储和查询这些图数据一直以来都是一个研究热点.图数据具有强大的表达力,能够很好地表示对象属性以及对象之间的关系,因此图相似性计算广泛应用于图相似搜索和图数据库分析[1],例如计算机视觉中的图像分类,疾病预测的蛋白相互作用网络分析,计算机安全中的二元函数相似性搜索等.这些实际应用的核心操作是计算两个图之间的距离/相似性.
如图1所示,用热力图展示9个图数据G0~G8之间的相似性,热力图越深表示相似性越高.热力图1(b)中的坐标轴0~8分别对应图1(a)中G0~G8.

图1 热力图展示图数据之间的相似性
传统方法采用多种度量指标来计算图相似性,例如图编辑距离(Graph Edit Distance,GED)[2],最大公共子图、图同构和图核函数等.然而,这些度量的计算通常是一个NP完全问题[3],计算成本非常高.目前最常用的衡量图相似性的指标是基于编辑距离的图相似,与其他度量不同,图编辑距离具有以下3个优势:1)GED适用于各种类型的图,它可以精确地捕获任意类型图之间的结构与标签差异;2)GED具有通用性,其中最大公共子图可以视为它的特殊情况;3)GED可以广泛应用在各种不同的领域,例如计算机视觉的图像分类,化合物的分子分析等等.
在解决图相似搜索问题中,主要分为两大类方法:第1类方法使用过滤-验证框架[4],过滤-验证框架主要是通过迅速且粗略地计算查询图与数据图之间的编辑距离,通过设定的图编辑距离阈值进行过滤,进一步获取到符合条件的数据图的集合,然后再对集合中的数据图进行验证;第2类方法是求解图相似性的近似值[5],这种方法通常需要基于离散优化或组合搜索的方式设计和实现.降低了图相似性计算的成本.同时,深度学习的快速发展为图相似性计算提供新的思路,一些学者将图相似性计算转化为学习问题,具体是将输入的一对图映射为相似性的分数,其关键技术包括:1)表示图数据的图嵌入模型;2)图嵌入的相似性计算模型.经典的图嵌入方法[6],可分为矩阵分解、深度学习、基于边重构的优化、深度图核与生成模型.并且随着深度学习技术的发展,图神经网络(Graph Neural Networks,GNN)[7]逐渐运用于图相似性计算.注意力模型(Attention Model)[8]也被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,注意力模型逐渐与神经网络紧密相连,并应用在各种不同的领域中.如今,虽然有许多不同的图嵌入方法被提出,但现有的大部分研究工作从图的节点嵌入[9]或图级嵌入[10]层面来对图进行表示,不能全面表示图信息,如何有效提取图上的信息仍然是一个极具挑战性的任务.为了能够更好地表示图的全局信息,本文采用了图神经网络与注意力机制分别从节点嵌入与图级嵌入两个层面来表示图数据,并采用神经张量网络模型计算图嵌入之间的相似性.
本文的贡献总结如下:
1.提出了一个端到端的图相似性计算模型NAGSim(Neural Networks and Attention Graph Similarity),该模型利用注意力机制与图神经网络来进行图相似性计算,改进了成对图相似性计算的准确性.
2.使用图注意力网络(Graph Attention Network,GAT)[11]与自注意力汇聚(Self-attention Graph Pooling,SAGPooL)[12]来生成图的节点级嵌入,更好地保留了图的全局特征,提升图嵌入的表达能力.
3.为了生成输入图的图级嵌入,本文采用了注意力机制来更好地聚合节点的特征,NAGSim根据卷积汇聚之后所保留的节点特征进行计算,图中的重要节点被分配更多的权重.将节点嵌入聚合为输入图的图级嵌入.
4.基于真实的数据集实验结果证明NAGSim的有效性,相比于传统算法与现有的端到端学习模型,NAGSim的运行时间更低,同时具有更高的准确性.
2 相关工作
基于图神经网络的相似性学习,是以端到端的方式执行相似性学习任务,与此同时采用GNN学习图的表示.例如,成对的输入图(GA,GB,yAB),其中yAB表示(GA,GB)实际的相似性得分,基于GNN的图相似学习方法首先是采用多层GNN来学习图的表示,对于编码空间中的GA和GB,一对图上每个图的表示学习可能会通过某些机制而产生相影响,例如权重分配和两个图之间的GNN跨图交互.GNN层将为每个图输出矩阵或矢量表示,然后添加点积层或全连接层用于预测两图之间的相似性得分.
根据在学习中计算图相似性,将现有的基于GNN的图相似性学习主要分为GNN-CNN模型、暹罗GNN模型、图匹配网络.下面详细介绍每个类别的相关工作.
2.1 用于图形相似性预测的GNN-CNN模型
使用GNN-CNN混合网络进行图相似性预测的工作主要是使用GNN学习图表示,并将学到的图表示映射到CNN中以生成相似性得分,通常用于分类或回归问题.并在端到端模型中加入全连接层,用于生成相似性分数.
1)GSimCNN[13]提出了一种称为GSimCNN的成对图相似性预测方法,该方法包括3个阶段.第1阶段是由多层的图卷积神经网络(Graph Convolutional Network,GCN)[16]生成节点表示,其中每层GCN定义为:
(1)
其中N(i)是包含节点i本身的一阶邻居的集合,di是节点i的度加1,W(l)是第l个GCN层的权重矩阵,b(l)表示偏差,而ReLU=max(0,x)是激活函数.第2阶段,通过不同GCN层,计算两个图之间所有节点嵌入对之间的内积,从而生成了多个相似性矩阵.第3阶段来自不同层的相似性矩阵由多个独立的CNN处理,将CNN的输出送入全连接层中,生成图对GA和GB的相似性得分yAB.
2)SimGNN[14].基于GSimCNN引入了SimGNN模型.除了将成对节点与GCN输出中的节点级嵌入进行比较外,还使用神经张量网络[15](Neural Tensor Network,NTN)关联了两个输入图的图级嵌入.最后,输入图的节点级嵌入和图级嵌入被联合起来作为图的表示,输入CNN全连接层用于预测图相似性.
与本文方法最具有相关性的工作是SimGNN,这两项工作之间的主要区别是:1)图的全局嵌入方法.SimGNN使用GCN来生成图嵌入,因为GCN扩展性较差,本文采用了图注意力网络(GAT)来生成图嵌入,并添加了自注意力图汇聚(SAGPooL)来减少参数,降低处理时间,避免过度拟合.而SimGNN的3层卷积,导致其运行时间成本非常高,并在训练过程中丢失了一定的局部节点信息,使模型最终并不能达到理想的拟合效果.而NAGSim采用了图注意力网络结合自注意力汇聚,可以更好的保留图的全局信息,减少参数计算,实验验证NAGSim模型效果更好,不仅减少了运行时间,还具有更低的错误率;2)节点注意力权重的初始化不同.SimGNN随机初始化一个权重矩阵.但是NAGSim将节点级嵌入阶段由池化层产生的权重矩阵,作为注意力模块的初始权重矩阵.由池化层产生的权重矩阵比随机的参数矩阵更接近真实的权重分布,训练过程更快,大大减少了训练时间.
2.2 用于图相似学习的暹罗GNN模型
这类模型采用GNN作为双网络的暹罗网络体系结构,同时从输入的两个图中学习图的表示,然后基于GNN的输出表示形式获得相似性估计.SiameseGCN[16]是在有监督的情况下使用连体图卷积神经网络(S-GCN)学习图相似性.S-GCN将一对图作为输入,并使用频谱GCN来获取每个输入图的图形嵌入,然后,使用点积层和全连接层来生成光谱中两个图之间的相似性估计域.
2.3 基于GNN的图匹配网络
此类模型在学习过程中结合GNN与匹配机制来适应暹罗GNN,并在图表示学习过程中考虑跨图交互.
图匹配网络GMN[17]是基于GNN的架构,其中,每个传播层中的节点更新考虑了图边缘上的聚合消息,并提出了跨图匹配策略:图的节点与另一个图的节点的匹配程度.该模型在给定一对图作为输入的情况下,通过一种新的基于跨图关注度的匹配机制,通过对一对图进行联合推理来计算它们之间的相似性得分.
3 模型介绍

表1 符号定义

图2 NAGSim的总体架构和工作流程
3.1 基于GAT和Attention的图嵌入
3.1.1 图的节点级嵌入
节点嵌入阶段旨在提取图的节点特征.对于输入一对图GA和GB,分别经过图注意力网络(GAT)和自注意力汇聚(SAGPooL)最终提取了各自的节点特征,生成了张量表示UA和UB.
在将图送入GAT之前,需要首先明确图的输入形式.给定任意一个图G=〈V,E〉,其中V是G中所有节点的集合,E是G中所有边的集合.其中每个节点vi采用1个D维的向量xi∈D表示节点特征,图G的特征矩阵表示为X∈N×D.
如图3所示,图3(a)表示真实图数据,图中共有6个顶点.其中不同类型的节点代表具有相同属性的节点,表示节点属性(例如度、组成元素)的不同.图3(b)表示由不同的节点属性所组成的图.节点采用one-hot编码,具有相同属性的节点采用相同的one-hot编码.
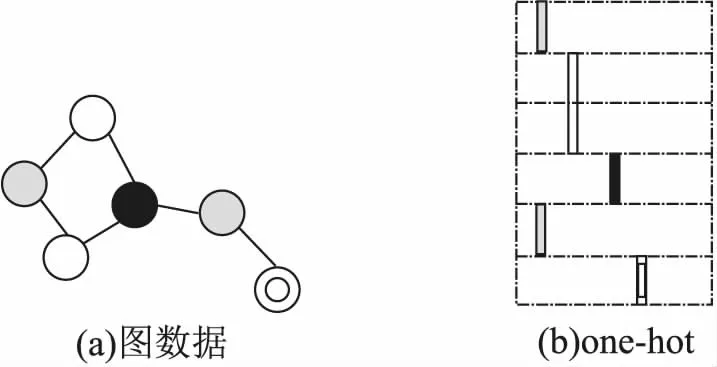
图3 图输入示例
明确图的输入形式后,接下来通过图注意力网络(GAT)提取图中的节点特征,汇聚邻居信息.GAT利用注意力权重将邻居节点的表达以加权和的形式聚合到自身,注意力权重和表达更新的计算公式分别如式(2)、式(3)所示:
(2)
(3)
其中,参数W用于完成每个节点的特征维度变换,参数a是可学习的参数向量,‖表示串联操作,进行向量拼接,αij表示在参数向量下计算得到的节点i,j之间的权重,σ表示非线性激活函数,例如ReLU.
图结构中节点经过GAT图卷积之后来到池化层.池化层使得模型能够通过缩小表示的大小来减少参数数量,从而避免过度拟合.这一部分主要用于特征降维,减少权重参数,减小过拟合,同时提高模型的容错性.通过池化层可以利用相对较少的参数以端到端的方式来学习分层表示.
本文采用了自注意力图汇聚(SAGPool).这是一种在分层图汇聚背景下用于GNN的自注意图汇聚方法.利用自注意力机制来区分应该丢弃的节点和应该保留的节点,基于图卷积计算注意力分数的self-attention机制,同时考虑了节点特征和图的拓扑结构.
要深入贯彻落实《吉林省人民政府办公厅关于加快发展棚膜经济促进农民增收的实施意见》,把发展棚膜经济作为加快推进农业供给侧结构性改革,转变农业发展方式,促进农业增效、农民增收,培育农业农村发展新动能的重要途径。做到主要领导整体抓,分管领导具体抓,层层落实责任[1]。
SAGPool是第1个使用self-attention进行图汇聚并实现高性能的方法.关键在于它使用GNN来提供self-attention分数,关注的是注意力本身公式(4)中计算self-attention分数:
(4)
idx=top_rank(Z,「kn⎤)
(5)
(6)
其中Z∈F×1为self-attention分数,θatt∈F×1是SAGPool中唯一的参数,A表示邻接矩阵,是单位矩阵,是的度矩阵,X代表每一层的特征.公式(5)利用自注意力机制来区分应该丢弃的节点和应该保留的节点.其中k∈(0,1]表示池化比率,是一个超参数,决定要保留的节点数.top「kn⎤的节点是由Z值进行选择的.top_rank是返回top「kn⎤的节点索引的函数.公式(6)中n表示节点数量,xi表示第i个节点的特征,U输出了节点特征.由于使用图卷积计算注意力分数的自注意力机制,模型同时考虑了节点特征和图拓扑.
在经过实验对比(详见表8、表9)后,本文发现采用GraphSAGE作为SAGPool的卷积方式时,SAGPool可以更有效地学习节点的重要性得分.GraphSAGE方法不同于原始的GNN方法,因为它通过汇总节点整个邻域的采样子集中的特征来定义节点的邻域.表示为:
(7)
(8)
(9)
在本文中,将GAT层设置为1,SAGPool层设置为1.
3.1.2 图级嵌入
一旦获得了图的节点嵌入表示,下一步就是有效地组合节点嵌入,以生成整个图的图级嵌入h.这一部分对应图2总体框架图中的图级嵌入阶段,其中Att代指Attention.本文通过注意力机制为节点分配不同权重,使用节点嵌入的加权和表示图级嵌入.
输入一个图的节点级嵌入U,首先通过平均所有节点嵌入并通过非线性激活函数对其进行转换来计算上下文向量(context vector)嵌入c:
(10)
其中WZ是由3.1节中池化层的公式(4)所构成的权重矩阵.所得到的上下文向量c提供了整个图的结构属性,激活函数σ为ReLU.公式(11)中为了计算每个节点n的注意力权重an,取每个节点嵌入Un与上下文向量c的内积.这样计算将对上下文向量c产生更大的影响,并且与上下文向量c最相似的节点嵌入将获得更多的注意力权重.其中激活函数σ(·)为sigmoid函数,再将an映射到(0,1)范围内,并且可以通过图中节点的个数更好地反映图的大小.公式(12)综合了公式(10)、公式(11)计算出h∈D的整体图嵌入.
(11)
(12)
NAGSim的图级嵌入没有使用随机初始化的权重矩阵张量W,而是采用节点嵌入阶段之后所保留的特征WZ(参看公式(4)),这样省去了很多参数训练过程,大大减少了训练时间.
3.2 相似性计算
3.2.1 基于神经张量网络的图关联
现在已经获得了每个图的整体嵌入h,接下来使用神经张量网络(NTN)来比较两个图嵌入来估计它们的相似性.与传统的线性方法相比,神经张量网络的优势在于它能够有效地比较多个维度上的两个嵌入矢量,用一个双线性张量层代替一个标准的线性神经网络层.给定两个图GA和GB的图级嵌入hA与hB,NTN使用双线性张量,用以下函数来计算两个嵌入之间的关系:
(13)

3.2.2 相似性得分计算
最后将NTN(hA,hB)输入到全连接神经网络来生成相似性得分yAB,并使用一个均方误差损失函数将其与真实数据相似性得分进行比较,并使用梯度下降策略将均方误差(MSE)损失降至最低:
(14)
其中P是训练集中图对的集合,而yAB是GA和GB之间的真实相似性.
算法1.图相似性计算模型NAGSim
输入:给定图数据库P={G1,G2,…,GA,GB,…,GN},x表示输入的节点特征,图卷积层选择1层GAT,αij为注意力系数,池化层选择1层SAGPool,Z为自注意力分数,U为节点嵌入矩阵,WZ是由Z构成的权重矩阵,h代表图嵌入,NTN中的超参数为k,W[1:k}为张量权重,Q∈k×2d为权重向量,偏置向量b∈k.全连接层数为l.
输出:图相似性得分yAB
1.Begin
2.从图数据库P中选择一对图GA和GB
3.{xv,∀v∈Vi}←输入图GA中结点的one-hot编码
4.{xu,∀u∈Vj}←输入图GB中结点的one-hot编码
5.UA=SAGPool(GAT(xv,αij),Z)
6.UB=SAGPool(GAT(xu,αij),Z)
7.hA=GraphEmbedding(UA,WZ)
8.hB=GraphEmbedding(UB,WZ)
9.score=NTN(hA,hB,W[1:k],Q,b)
10.yAB←fullyconnected(score,l)
11.End
4 实验结果及分析
4.1 数据集
1)ENZYMES.酶素,化合物分子,包含600个图和6个类别,ENZYMES的每个数据都是1个图.本文从中选择了600个图.
2)NCI-1.用于抗癌活性分类的生物学数据集.在数据集中,每个图代表一种化学化合物,节点和边分别代表原子和化学键.NCI-1数据集中包含4110个化合物和2个类别,标签是判断化合物是否有阻碍癌细胞增长的性质.本文从中随机选择了50个图,如表2所示.

表2 数据集统计
表3表示了数据集的基本信息.graphs表示数据集中包含的图的数量,Avg.Nodes表示数据集的平均节点数,Avg.Edges表示数据集的平均连边数,classes表示数据集包含几种类别.

表3 数据集特征
4.2 实验设置
对于每个数据集,分别将所有图的80%和20%随机分为训练集和测试集.数据集中的标签评估反映了图查询的实际情况:对于测试集中的每个图,将其视为查询图,然后通过模型计算查询图与数据库中各个图之间的相似性.根据相似性得分进行排序.
由文献[3]已知即使是最先进的算法也无法在具有超过16个节点的图之间的合理时间内可靠地计算出精确的GED.那么为了正确处理文中数据集,采用了3种著名的近似算法,即Hungarian[18],VJ[19]和HED[20]来计算出近似GED,并选择计算出的最小距离.之所以采用最小值而不是平均值,因为确保返回的GED大于或等于真实的GED.
在本文研究中,选择近似的GED值作为每个图对的基本真实值.如图4、图5所示,描述了数据集中的测试集与训练集的近似GED的分布,可以看出GED分布比例相近,差异并不大.首先将真实的GED归一化,然后通过指数函数将其映射到区间(0,1),然后将这些真实的GED值转换为真实的相似性得分Yground truth.其中|GA|表示GA中的节点数.
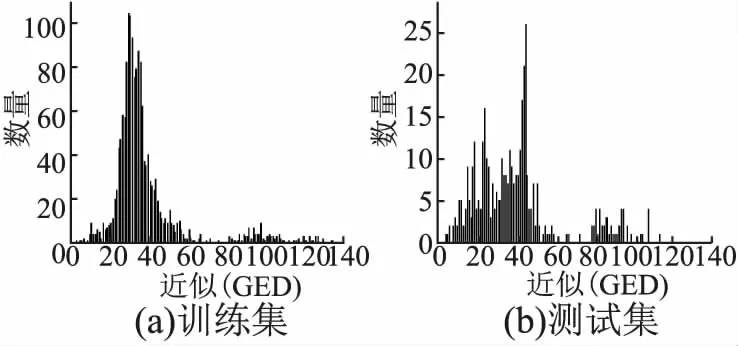
图4 EMZYMES训练和测试集中的近似GED值分布
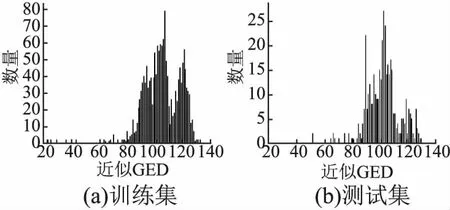
图5 NCI-1训练和测试集中的近似GED值分布
(15)
Yground truth=e-norm
(16)
模型将GAT层数设置为1,多头注意的数量(Number of multi-head-attentions)设为1,并使用ReLU作为激活函数.GAT的输出尺寸为32.之后的池化层的池化比率k设置为0.8.对于NTN层,将超参数K设置为16.使用4个全连接层将NTN模块的合并结果维数从32减小为16、16至8、8至4和4至1.
实验环境及配置如表4所示.在训练过程中,将批处理大小设置为256,使用Adam算法进行优化[21],并将初始学习率固定为0.001.将迭代次数设置为100,然后根据最低的验证损失选择最佳的模型.

表4 实验环境及配置
4.3 评估指标
为了评估和比较NAGSim的有效性,本文使用了以下指标评估所有模型:
·运行时间(Time).运行时间是指每种方法估算整个数据集的图对相似性得分所花费的总时间.
·均方误差(MSE).使用均方误差(MSE)来计算公式(14)中定义的预测分数与真实相似性之间的损失.MSE具有凸性、对称性和可微性的数学性质,并且对数据集中的异常值具有敏感性.
·Spearman的排名相关系数(ρ)[22]和Kendall的排名相关系数(τ)[23]衡量预测排名结果与真实排名结果的匹配程度.因此两个系数越大表示效果越好,预测和真实数据越相关.公式(17)是计算x、y的Spearman相关系数,公式(18)是计算Kendall相关系数,对于x、y的两对观察值xi,yi和xj,yj,如果xi
(17)
(18)

(19)
以上的4个评估指标中,运行时间(Time)、均方误差(MSE)越小越好,相关系数(ρ、τ)与决定系数(R2)越大越好.
4.4 Baseline方法
本文把以下6个方法作为Baseline,实验对比分析Baseline和NAGSim的性能:
1)Hungarian[18].基于匈牙利二部图匹配算法用于计算近似GED的传统算法;2)VJ[19].基于Volgenant算法和Jonker算法的两种立方时间算法,只考虑有限的边的信息,是用于计算近似GED的次优算法;3)HED[20].根据HausdorffEdit距离计算局部子结构之间的双向分配,确定图形编辑距离的下限;4)SimGNN[14].最初的提出使用图神经网络的计算图相似性的模型;5)funcGNN[24].使用图神经网络的计算程序流程图相似性的模型;6)GMN[17].基于跨图注意力的匹配机制来计算相似性分数的图匹配网络.
4.5 实验结果
表5表示在相同数据集上,不同Baseline所运行的时间对比.实验环境详见表4,所有Baseline均是在相同的实验环境下运行.由于GED估算非常耗时,因此利用了并行计算的功能来加快计算速度.传统方法的近似GED是通过ProcessPoolExecutor6[25]使用24个并发进程池异步计算的.实验结果表明,与所有近似方法的并行执行(24个过程)相比,即使在串行执行时NAGSim也会提供更快的结果.与现有的端到端的图神经网络方法相比(1个进程),NAGSim达到最优,降低了运行时间.
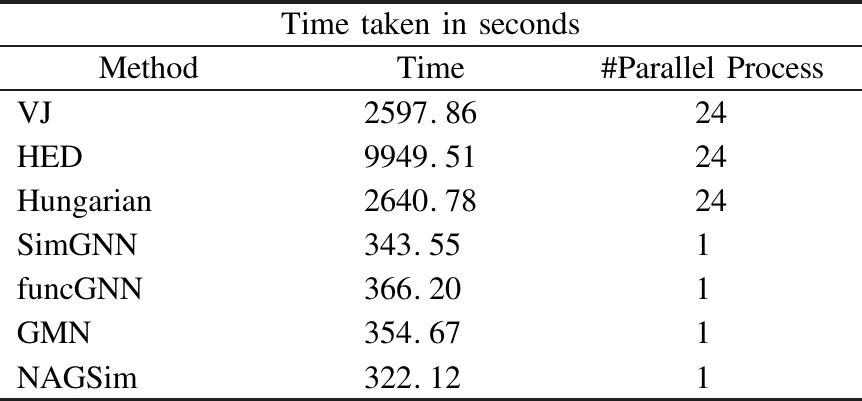
表5 ENZYMES数据集上,不同方法运行时间的对比
如图6所示,为NAGSim针对训练和测试数据集获得的MSE损失函数曲线.可以推断出,针对训练数据集和测试数据集,NAGSim模型已经收敛.针对模型的性能和收敛行为表明,MSE是优化NAGSim模型以学习成对图之间相似性的好的方法.在表6、表7中比较了NAGSim与不同图神经网络模型方法获得的MSE误差值.与现有的端到端方法相比,可以看出NAGSim在不同的数据集上均取得了较好的结果.

表6 不同图神经网络模型在ENZYMES数据集的精确性

表7 不同图神经网络模型在NCI-1数据集的精确性
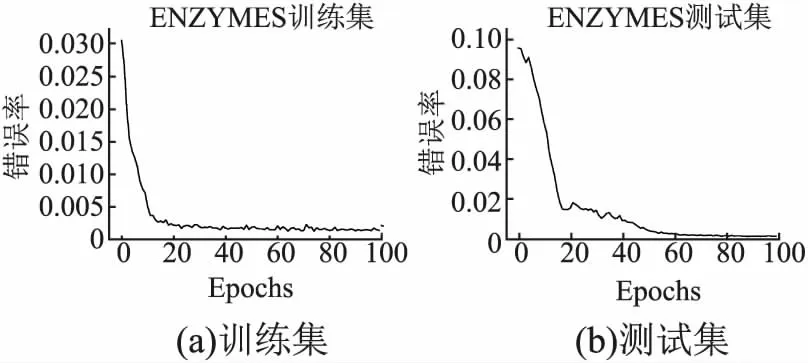
图6 ENZYMES训练集和测试集的错误率
为了确定本文模型的有效性与准确性,对模型自身进行了对比实验.本文评估NAGSim的各个关键模块对NAGSim性能的影响:
1)GCN.基于频域卷积的方式融合图结构特征;2)GraphSAGE.使用随机采样方法生成子图,通过子图更新节点嵌入;3)GAT.使用注意力来学习边上权重的图神经网络;4)GAT+SAGPool(GCN).卷积方式采用GAT,池化层选择SAGPool,SAGPool中选择GCN学习注意力分数的self-attention机制;5)GAT+SAGPool(GraphSAGE).卷积方式采用GAT,池化层选择SAGPool,SAGPool中选择GraphSAGE学习注意力分数的self-attention机制;6)GAT+SAGPool(GAT).卷积方式采用GAT,池化层选择SAGPool,SAGPool中选择GAT学习注意力分数的self-attention机制.
通过不同的对比实验,本文最终确定模型的各模块组成部分.表8、表9表示在不同数据集上的对比实验,从中可以看出NAGSim效果均达到最优.因此可以判断模型的有效性.如表8、表9所示,在GCN、GraphSAGE、GAT 3种卷积方式中,GAT采用注意力机制可以更好融合提取图的节点特征.在确定了卷积层(GAT)后,加入SAGPool池化层避免了过拟合,减少参数从而降低了时间复杂度.在SAGPool中采用GraphSAGE作为卷积方式,可以更为有效地学习节点的注意力分数.GraphSAGE通过聚合采样可以更好地汇聚邻居节点的特征.在确定了卷积层(GAT)与池化层(SAGPool)后,最后加入注意力机制从而生成图级嵌入,送入神经张量网络层与全连接层输出相似性得分.
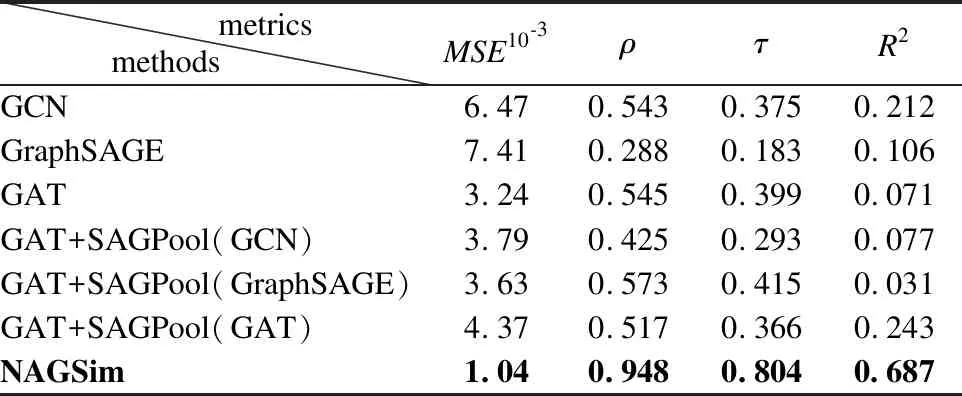
表8 ENZYMES数据集下NAGSim变种模型的准确性对比
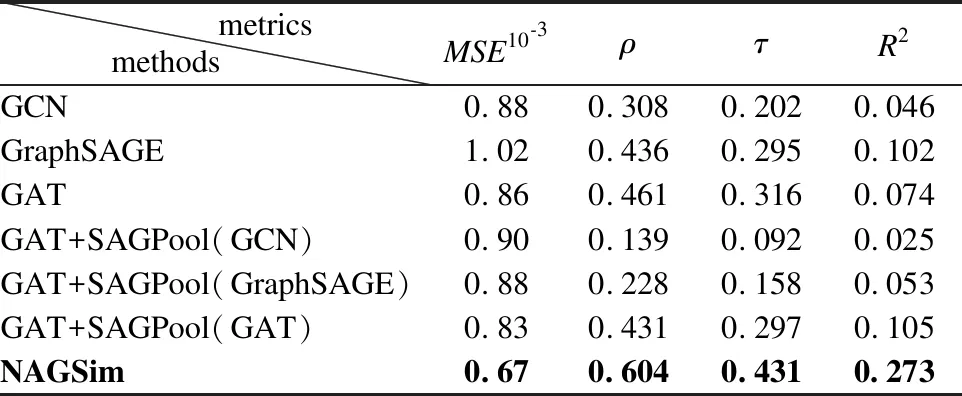
表9 NCI-1数据集下NAGSim变种模型的准确性对比
5 结 论
传统的基于图编辑距离的图相似性计算算法模型复杂,时间成本高并且精确度不高,深度学习技术的发展为传统的图相似计算问题提供了新的思路.本文提出了NAGSim——一种基于图神经网络与注意力机制的图相似计算模型,在图数据库中查找与给定的查询图相似的图的集合,来预测图结构之间的相似性.为了预测一对图结构之间的相似性,本文首先分析了图的整体结构表示.NAGSim继承了图卷积网络的归纳和节点顺序不变属性,并使用它为图中的每个节点创建语义丰富的嵌入,并加入了注意力机制使得模型优于现有的端到端学习模型.实验结果表明,NAGSim与现有的经典算法和端到端的学习方法相比,模型在近似的图编辑距离计算上运行速度非常快,在各项评价指标上都有一定的提升,并且具有非常高的竞争力.之后还将考虑如何应用NAGSim解决相关的图相似性挑战,例如蛋白质分子查找,程序流程图的安全性,对于这些实际应用而言,寻找图结构的相似性至关重要.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
河北画报(2020年8期)2020-10-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
浙江大学学报(工学版)(2016年2期)2016-06-05
电视技术(2014年19期)2014-03-11
