
结合注意力机制的BERT-BiGRU-CRF中文电子病历命名实体识别
2023-08-29 01:10孙艳秋
小型微型计算机系统 2023年8期
陈 娜,孙艳秋,燕 燕
(辽宁中医药大学 信息工程学院,沈阳 110847)
1 引 言
自然语言处理( Natural Language Processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向.它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法[1].被称为“人工智能皇冠上璀璨的明珠”.命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”[2],旨在抽取非结构化文本中的命名实体,主要包括人名、地名、机构名和专有名词等.命名实体识别是自然语言处理的一项基础任务,是文本语义理解的基础,是知识图谱的核心单元,是一项极具实用价值的技术.NER的研究主要经历了早期的基于词典和规则的方法,到基于统计模型的传统机器学习的方法,到近年来大热的基于深度学习的方法[3].基于词典和规则的方法规则往往依赖于具体语言、领域和文本风格,制定规则的过程耗时且难以涵盖所有的语言[4],特别容易产生错误,系统可移植性差,对于不同的系统需要语言学专家重新书写规则,系统建设周期长、需要建立不同领域知识库作为辅助以提高系统识别能力.基于传统机器学习的方法中,NER被当作序列标注问题.利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注.NER任务中的常用模型包括生成式模型隐马尔可夫模型(Hidden Markov Moder,HMM)、判别式模型条件随机场(Conditional Random Field,CRF)等[5].CRF因其解决了标签之间的依赖问题而成为NER目前的主流模型.基于深度学习的方法主要包括循环神经网络模型(RNN)和卷积神经网络模型(CNN),作为RNN改进结构的长短记忆网络(LSTM)和门控神经网络(GRU),由于其解决了长序列训练过程中的梯度消失和梯度爆炸问题,而成为目前研究命名实体识别的热点.受益于深度学习的非线性转换,深度学习模型可以从数据中学到更复杂的特征,避免大量的人工特征的构建,在命名实体识别中获得了比传统方法更好的性能.
本文电子病历命名实体识别的主要任务是从非结构化的电子病历本文中识别出预先定义好的临床术语,包括解剖部位(body),手术(operation),疾病和诊断(diagnosis),药物(medicine),实验室检验(check)和影像检查(examination)6类实体,为电子医疗信息数据抽取、临床诊疗信息挖掘和临床知识图谱构建等奠定了基础.Hammerton[6]最早提出应用LSTM进行文本实体识别,并通过实验验证了模型的有效性.杨红梅[7]等提出了一种基于双向长短神经网络(BiLSTM)的电子病历命名实体的识别模型,实验表明了BiLSTM网络模型实体识别的有效性.冀相冰[8]等将注意力机制融入BiLSTM网络模型中,提高了命名实体识别的准确性.LSTM-CRF 模型逐渐成为实体识别的典型结构.叶蕾[9]等提出了基于 BiLSTM-CRF 的中文电子病历命名实体识模型,并在CCKS2018中文电子病历数据集上进行对比实验,证明了BiLSTM-CRF 模型效果明显优于CRF模型.张华丽[10]等提出将注意力机制添加到BiLSTM-CRF结合的网络模型中,实验表明该模型有效提高了中文电子病历命名实体识别的准确率.陈琛[11]等提出一种基于BERT的命名实体识别模型,该模型在经典BiLSTM-CRF模型基础上引入了BERT预训练模型,利用BERT生成动态词向量,在CCKS2019中文电子病历数据集上实验表明了该模型实体识别的优越性.何涛[12]等提出的基于BERT-CRF 的电子病历实体识别模型能实现较高的实体识别F1分数,其性能显著优于传统的循环神经网络和卷积神经网络模型.马文祥[13]等提出了基于BERT的BiGRU-CRF电子简历命名实体识别模型,利用BERT预训练模型进行字符级编码,有效解决了一词多义的问题,实验表明该模型能够有效提高中文电子简历命名实体识别的准确率.廖涛[14]等提出了融合注意力机制的 BERT-BiLSTM-CRF中文命名实体识别模型,通过注意力机制给不同文字赋予不同的权重,增强了文本语义特征,在 1998 年人民日报数据集上取得了较好的识别效果.
传统Word2vec模型获得的是输入文本序列的静态词向量,不能解决一词多义问题,为了解决这一问题,本文采用BERT预训练模型获得输入文本序列的字符级动态向量;BiLSTM网络结构复杂,模型参数多,训练时间长,为了节约时间成本,本文利用BiGRU双向门控单元获取输入文本序列的全局语义特征;研究表明引入注意力机制能够解决特征提取中的长距离依赖问题,提高模型实体识别的准确率.结合以上研究,本文提出了一种结合注意力机制的BERT-BiGRU-Att-CRF中文电子病历命名实体识别模型.
2 结合注意力机制的BERT-BiGRU-Att-CRF中文电子病历命名实体识别模型
结合注意力机制的BERT-BiGRU-Att-CRF电子病历命名实体识别模型由向量嵌入层、文本编码层、注意力层和解码输出层4部分组成,模型结构图如图1所示.
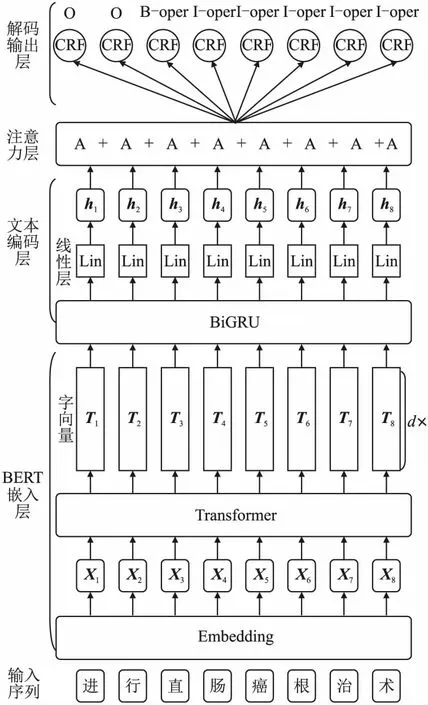
图1 BERT-BiGRU-Att-CRF中文电子病历命名实体识别模型结构
2.1 嵌入层(Embedding Layer)BERT模型
嵌入层(Embedding Layer)采用BERT预训练模型生成文本序列动态字向量.BERT(Bidirectional Enoceder Representations from Transformers)[15],即来自Transformers的双向编码器表示.是谷歌AI团队于2018年10月提出的一个面向自然语言处理任务的无监督预训练语言模型,是近年来自然语言处理领域里程碑式模型.BERT模型的输入主要由词向量(token embedding),段落向量(segment embedding)和 位置向量(position embedding)3部分组成.[CLS]为句首向量,[SEP]为句中和句尾向量.其输入示例(进行直肠癌根治术)如图2所示.
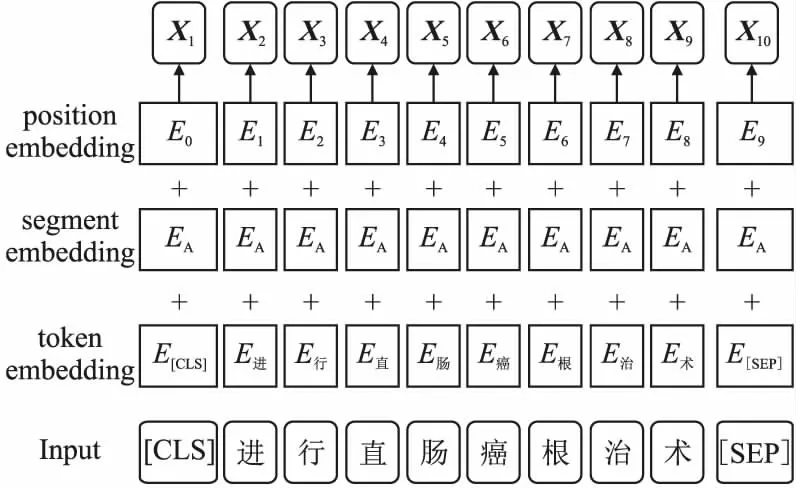
图2 BERT输入示例图
BERT的核心网络结构是由多层双向 Transformer encoder组成的,其网络结构如图3所示,3个embedding相加得到的X1,X2……Xn作为BERT的最终输入序列表示.T={T1,T2……Tn}为BERT模型输出词向量列表,T∈Rn×d,d表示向量维度.BERT 模型借鉴GPT思路使用Transfomer Encoder(包含Multi-Head Attention)作为特征提取器,加强了语义特征提取的能力;采用了word2vec所使用的CBOW训练方法,参考ELMo双向编码思想,利用了每个词的上下文信息,获得了更强的语义提取能力.按照模型参数大小分为:BERTBASE和BERTLARGE,BERTLARGE在语义理解能力上效果更好,在训练集受限的任务上尤为明显,因此本文选用BERTLARGE模型.其Transformer block层数为24、隐藏层维度为1024,Self-Attention头数为16.在预训练阶段做两个无监督任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)[16].MLM随机mask每一个句子中一定比例的词,用其上下文来做预测,训练词的语义理解能力;NSP任务实际上就是段落重排序,只考虑两句话,判断是否是一篇文章中的前后句,是一个句子级的二分类问题[17],训练句子之间的理解能力.两任务联合使用获得全面、准确的输入文本序列向量表示.BERT模型根据上下文语境变化生成动态词向量,能够解决不同语境下一词多义问题.
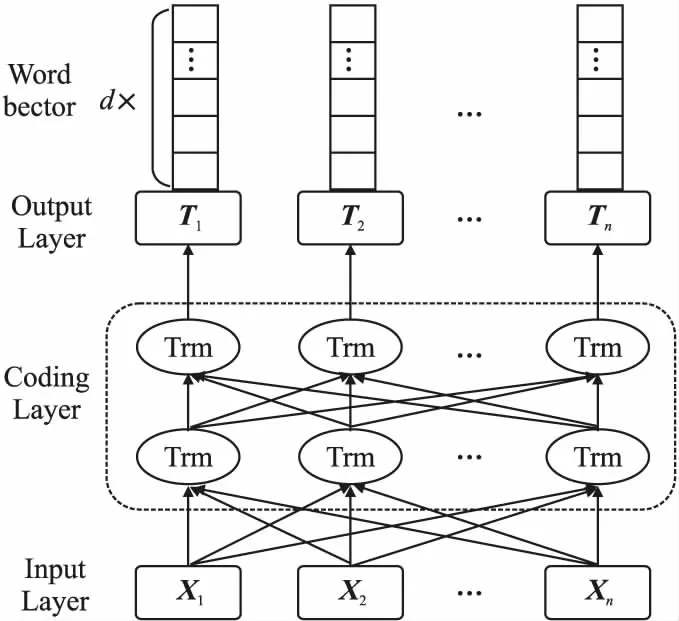
图3 BERT模型网络结构
2.2 文本编码层(Encoder Layer)BiGRU层
文本编码层采用BiGRU模型对词嵌入层输出的向量进行全局特征提取.GRU也是RNN的一种变形结构.和LSTM一样,通过“门”结构来控制信息的通过,可以学习长期依赖信息,解决了传统RNN的长依赖和反向传播中的梯度消失等问题.LSTM包括3个门:忘记门、输入门和输出门.GRU只有两个门,其结构如图4所示.GRU将LSTM中的输入门和遗忘门合二为一,称为更新门(update gate),如图4中的zt,GRU的另一个门称为重置门(reset gate),如图4中rt.由此可见GRU较LSTM网络结构更加简单,因此参数更少,更容易进行训练,能够很大程度上提高训练效率.而基于GRU的实体识别模型效果与LSTM相似.
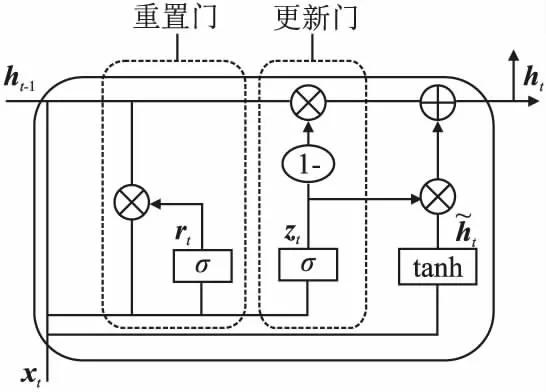
图4 GRU模型内部结构
GRU前向传播公式为:
rt=σ(Wr·[ht-1,xt])
(1)
zt=σ(Wz·[ht-1,xt])
(2)
(3)
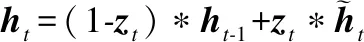
(4)
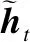
单向GRU状态从前往后输出,不能充分考虑下文信息.因此,本文采用双向GRU网络,其结构如图5所示.BiGRU(Bidirectional Gate Recurrent Unit)利用正向和反向GRU进行上下文信息特征提取,将输出进行加权求和,经过一线性层将d维向量映射为m维向量,得到BiGRU网络最终输出标签向量列表H={h1,h2……hn},H∈Rn×m,其中n为文本序列长度,m为实体类型标签数.
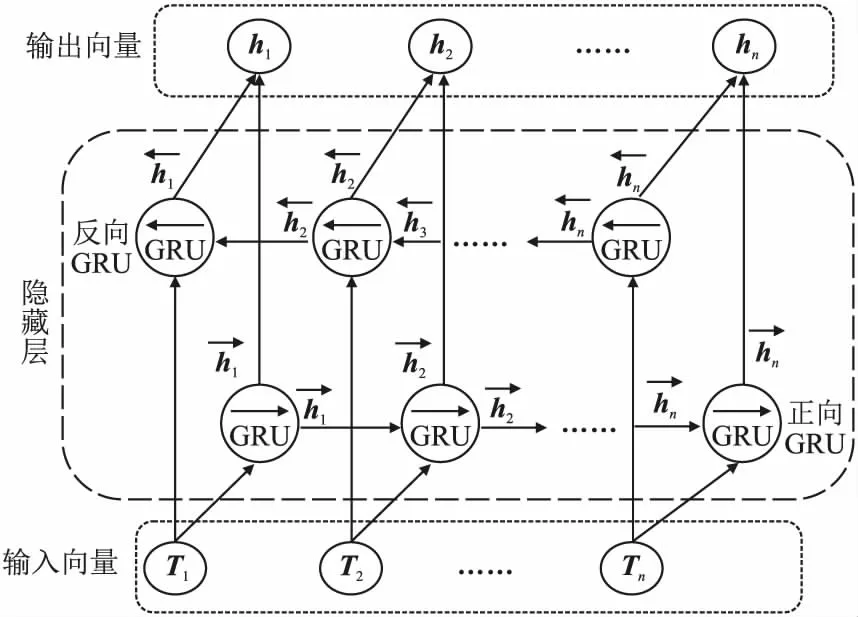
图5 BiGRU结构
计算过程如式(5)~式(7)所示:
(5)
(6)
(7)
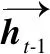
2.3 注意力层
电子病历文本数据中较长语句占据很大比例,BiGRU提取文本特征时无法获得长距离的特征,通过引入注意力机制,对与电子病历命名实体相关的特征分配较多的注意力(即特征权重较大),无关的特征分配较少的注意力(即特征权重较小).例如“患者7月前因′下腹腹胀伴反酸′至我院就诊,完善相关检查,诊断′胃体胃窦癌′(CT4N2M0,IIIB期)”,“患者、7月前、至我院就诊”等对识别“胃体胃窦癌”疾病实体作用较小,分配较小权重,“下腹腹胀伴反酸”对识别“胃体胃窦癌”疾病实体作用大,分配较大权重,有助于提高“胃体胃窦癌”疾病实体识别的准确率.引入注意力机制能够更加有效的获取与当前信息有关联的上下文语义特征,提高模型局部特征提取能力.注意力权重分配不受词间距离的影响,仅由词向量本身决定,有助于解决BiGRU模型长距离依赖问题.
隐层输出ht经全连接层得到ut,ut为当前信息与上下文信息相关性的注意力权重向量,其中Wt为权重矩阵,bt为偏置项,tanh为激活函数.如式(8)所示:
ut=tanh(Wtht+bt)
(8)
权重向量ut经softmax函数归一化处理后得到注意力分数向量at,其中n为文本序列的长度,如式(9)所示:
(9)
BiGRU层输出ht经注意力机制权重分配后输出加权全局语义特征向量st,如式(10)所示:
(10)
2.4 解码层-CRF层
BiGRU+Attention解决了文本信息处理中的长距离依赖问题,并通过计算得到的每个标签的具体分值,得到最优输出标签,但是其不能解决标签之间依赖关系等问题,例如:“B-check”标签之后不能紧连着“I-body”标签;句子中第一个词的标签应该是以“B-”或“O”开头,而不能是“I-”.因此其输出标签不能作为模型合理的预测结果.CRF的核心作用就是通过转移分数矩阵建模标签之间的依赖关系,从而输出一个全局最优的合理标签序列.
BiGRU+Attention输出得分矩阵为S,S∈Rn×m,sij表示文本序列中第i个字符xi的第j个标签分数.首先计算文本序列X={x1,x2……xn}的预测标签序列Y={y1,y2……yn}的得分,函数如式(11)所示:
(11)
式中A为转移分数矩阵,A∈R(m+2)×(m+2),Ayi,yi+1为标签yi转移到标签yi+1的分数,Si,yi为输入文本序列第i个字符预测为标签yi的概率.
其次利用归一化指数函数Softmax计算输出标签序列Y的概率,如式(12)所示:
(12)
最后利用维特比算法得到文本序列X的全局最优标签序列Y*,Y*为输出概率最大的标签集合.如式(13)所示:
(13)
3 实 验
3.1 实验环境与参数设置
实验环境设置如表1所示.
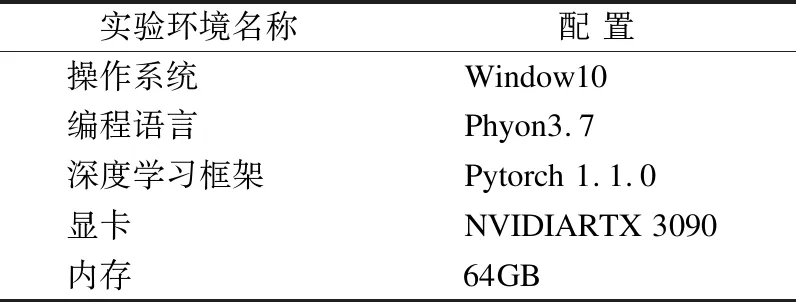
表1 实验环境
实验参数设置如表2所示.
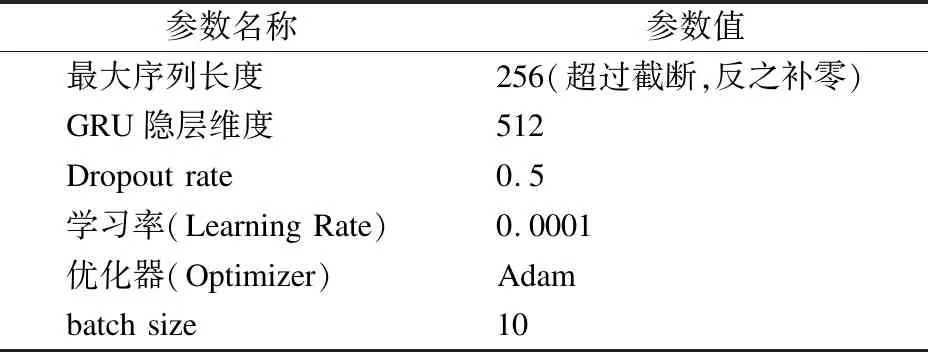
表2 实验参数设置
3.2 实验数据集及序列标注
实验采用CCKS2019面向中文电子病历的命名实体识别数据集,本数据集是根据真实的病历分布由医渡云医学人工编辑而成.共1379条已标注样本,其中训练集1000条,测试集379条.命名实体主要包括6类:1)解剖部位(body):指疾病、症状和体征发生的人体解剖学部位;2)手术(operation):医生在患者身体局部进行的切除、缝合等治疗,如阑尾切除术、胃癌根治术等;3)疾病和诊断(diagnosis):医学上定义的疾病和医生在临床工作中对病因、病生理、分型分期等所作的判断[19];4)药物(medicine):用于疾病治疗的具体化学物质;5)实验室检验(check):指临床工作中检验科进行的化验;6)影像检查(examination):影像检查(X线、CT、MR、PETCT等)+造影+超声+心电图,未避免检查操作与手术操作过多冲突,不包含此外其它的诊断性操作,如胃镜、肠镜等[20].各类实体统计如表3所示.各实体分布比例如图6所示.
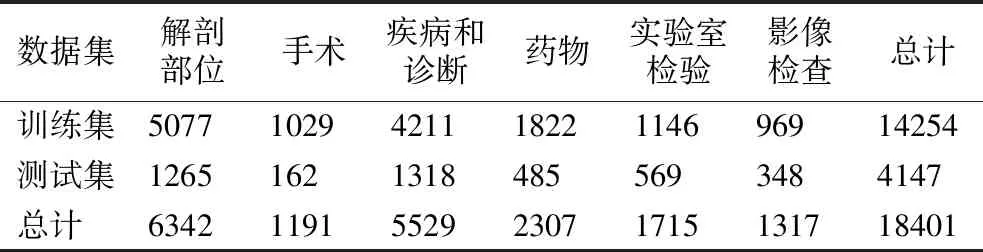
表3 CCKS2019实体统计
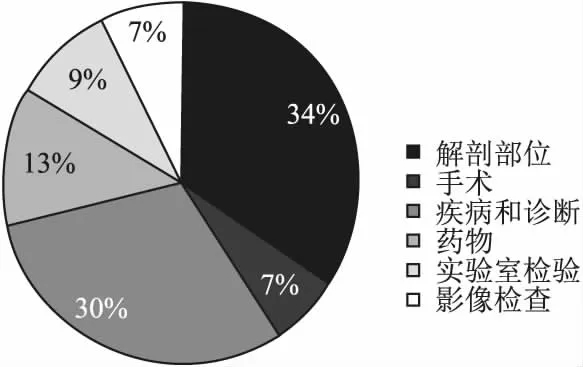
图6 CCKS2019实体分布比例图
本文采用BIO(B-begin,I-inside,O-outside)三位标注规范对语料进行数据标注.其中B-X表示命名实体X的开头,I-X表示命名实体的中间或结尾,O表示不属于任何类型,即非实体部分.共有13种待预测标签,分别是“B-body”、“I-body”、“B-oper”、“I-oper”、“B-diag”、“I-diag”、“B-medi”、“I-medi”、“B-check”、“I-check”、“B-exam”、“I-exam”、“O”.以“患者因直肠癌在我院进行直肠癌根治术,术后患者恢复良好.”为例,采用 BIO三位标注规范进行数据标注,结果如表4所示.
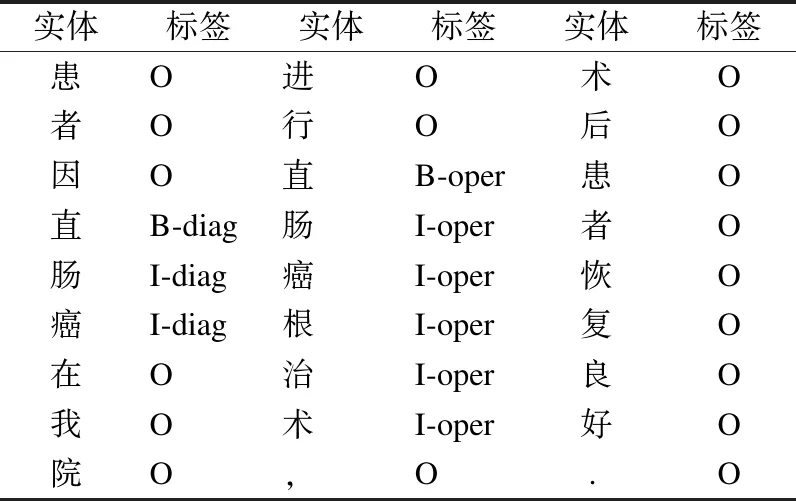
表4 BIO标注序列示例
3.3 实验结果与分析
3.3.1 模型评价指标
命名实体识别通常是通过召回率(或查全率,R)、精确率(或查准率,P)和F1(或F1-score)3个指标来评估的.F1为召回率(R)和精确率(P)的调和平均数(harmonic mean).各指标计算公式见式(14)~式(16),公式中各参数含义如表5所示.

表5 公式参数含义
(14)
(15)
(16)
3.3.2 实验结果与分析
作为专业领域的中文电子病历数据集中存在大量的缩写、专业名词和中英文交替等,常用的分析工具易发生错误分词而影响实体识别的效果.文献[11,18]研究表明了电子病历实体识别领域基于字层面模型识别效果优于基于词层面的模型.因此本文模型在字符层面进行序列标注.
为了验证本文提出的BERT-BiGRU-Att-CRF模型的有效性,进行了两组对比实验.第1组对比实验对比模型包括本文模型、BERT-BiLSTM-Att-CRF模型、BERT+BiGRU+CRF模型、BERT+BiLSTM-CRF模型、BiGRU+CRF模型和BiLSTM+CRF模型.第1组对比实验各模型总体识别效果如表6所示.
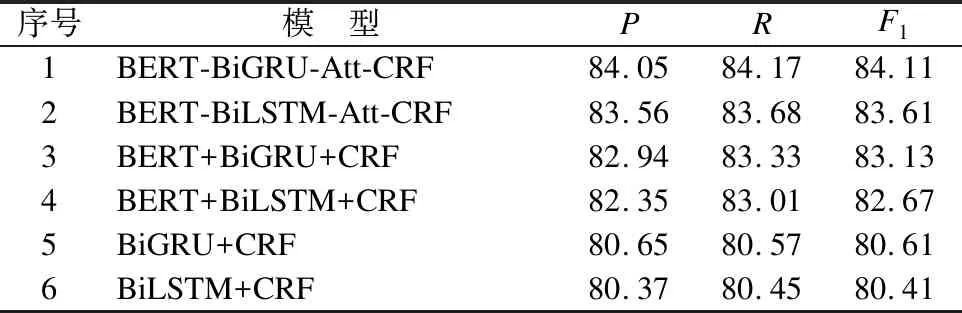
表6 模型总体识别效果对比(%)
在实验过程中本文模型训练时间为175.25min,BERT-BiLSTM-Att-CRF模型训练时间为186.32min,可见用BiGRU替换BiLSTM可以大幅缩短模型训练时间,节约时间成本.根据表6,比较模型1、3、5和模型2、4、6可以看出GRU模型在实体识别方面的各项性能均略优于LSTM模型,说明本文提出模型在节约训练成本的基础上保证了实体识别效果.比较模型3、4和模型5、6可以看出引入BERT预训练模型后,各项指标均有提高,从而证明了BERT模型的有效性.因为BERT预训练模型生成词向量时充分考虑不同语境下的语义信息,从而获得了输入文本序列的动态词向量,解决了一词多义问题.比较模型1、2和模型3、4可以看出引入注意力机制后模型的实体识别能力进一步提高,说明引入注意力机制增强了模型语义特征提取能力,有助于提高模型实体识别性能.
第2组对比实验为本文模型和目前主流命名实体识别模型IDCNN(迭代膨胀卷积)+CRF模型、BERT+IDCNN+CRF模型.第2组对比实验各模型总体识别效果如表7所示.

表7 本文模型与主流模型总体识别效果对比(%)
对比表6和表7,可以看出基于BERT+BiGRU+CRF模型的实体识别效果略优于基于BERT+IDCNN+CRF模型.从表7可以看出,本文模型实体识别效果优于主流命名实体识别模型.以上两组实验结果分析,表明了本文提出的模型在电子病历命名实体识别中的有效性.
本文模型各类实体识别效果如表8所示.
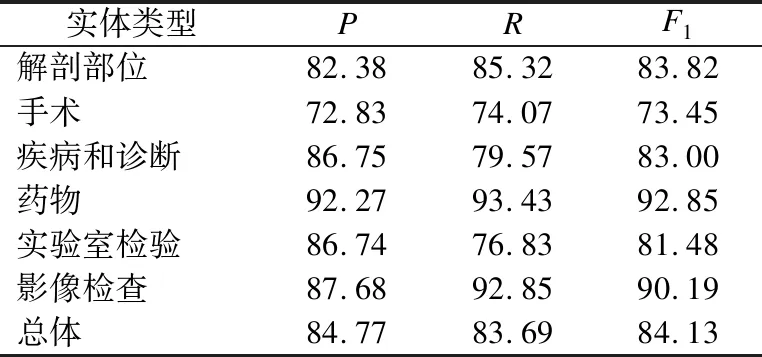
表8 各类实体识别效果(%)
从表8中可以看出本文提出的模型对解剖部位、药物和影像检查实体识别效果较好,对手术实体识别效果较差.识别效果较差的原因包括训练数据集较小,数据集中涉及中英文混写、医疗专业词汇较多等.
4 结 论
本文提出了一种结合注意力机制的BERT-BiGRU-Att-CRF中文电子病历命名实体识别模型.利用BERT预训练模型获得输入文本序列的字符级动态向量,解决了一词多义的问题;利用BiGRU双向门控单元获取输入文本序列的全局语义特征,节约了模型的训练时间成本;利用注意力机制增强特征向量的语义信息,解决了特征提取中的长距离依赖问题,提高了模型实体识别的准确率;用CRF处理标签之间的相互依赖问题,改善了中文电子病历命名实体识别的效果.实验表明,本文提出模型能有效识别解剖部位、药物和影像检查医疗实体,在CCKS2019数据集上进行对比实验得到本文提出的模型F1值达到84.11%,高于其他模型.在今后的工作中,考虑改进预训练模型,进一步减少模型训练时间,丰富训练数据集,提高模型训练效果,还可以将本文提出模型应用于其他的命名实体识别领域.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
趣味(语文)(2021年9期)2022-01-18
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
数学小灵通·3-4年级(2020年9期)2020-10-27
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
传媒评论(2017年3期)2017-06-13
中国卫生(2016年10期)2016-11-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2015年10期)2015-11-10
