
多声学特征融合的语音自动剪辑深度学习模型
2023-08-29 01:10倪仁倢周立欣侯昌佑
小型微型计算机系统 2023年8期
刘 臣,倪仁倢,周立欣,侯昌佑
1(上海理工大学 管理学院,上海 200093)
2(上海广播电视台,上海 200125)
1 引 言
随着互联网的普及,数字传媒行业高速发展,音视频媒体的数量呈指数型增长,而它们的后期制作离不开剪辑.它是一项艺术性,风格化程度较高的工作,不同类型媒体的剪辑风格与要求也不尽相同[1],且相较于调色或字幕等其它后期工作,剪辑通常花费着更多的人力和时间.
目前自动剪辑模型都是针对某种特定的剪辑需求而建立,现有的模型主要为机器学习算法中的隐马尔可夫模型(Hidden Markov Model,HMM).Leake等人[1]联合提出了一种基于人脸识别和语音识别的剧情类视频剪辑框架.它采用HMM及维比特算法,通过语音识别匹配剧本,同时结合画面元素进行自动剪辑.Roininen等人[2]提出了一个音乐会视频的自动剪辑模型,它使用了马尔科夫链、聚类以及高斯混合模型,通过分析音频信号的变化来进行自动剪辑.鲁雨佳等人[3]联合提出了一种服装类商品短视频的自动剪辑框架.它根据不同分镜所含的信息类别,综合考虑剪辑和片段节奏并进行分割筛选,使用HMM和维比特算法合成最佳的视频序列.但上述基于HMM的模型由于马尔科夫性的限制,无法有效地结合长时间序列的关联信息,导致模型的剪辑结果偏静态.
语言类的音视频在广播和电视中一直占有较高的比重,而它们的持续时间又较长,剪辑师需要综合审阅后再开始剪辑工作[4],所以剪辑此类媒体所花费的时间往往多于其他视频.通过观察上海电视台具有丰富经验的剪辑师们,了解他们的剪辑习性,发现剪辑师们十分注重节奏的掌控[1,5].他们在切分音频时,会根据不同情境在语音部分的两侧保留合适的非语音部分作为缓冲[1,4].如果保留过少会使剪辑节奏过快衔接突兀,相反的保留过多会导致剪辑节奏拖沓冗长.有经验的剪辑师通常会综合考虑前后联系,保留0.5s~1.5s的音频,确保剪辑过后的音频过渡柔和节奏适中.同时不会对连续的语音进行切分,以此来提升剪辑后音频的流畅程度[6].此外还会将一些人为发出的噪声删除[4],保证听众拥有良好的听感.
由于剪辑工作与前后信息有着密切的关联[3],直接使用传统语音端点检测的方法如双门限法,表现并不理想.因为它会机械地在语音的起讫端点处进行切分,导致剪辑过后的媒体衔接生硬,质量较低.语音剪辑相较于语音端点检测难点在于,它需要在精确识别语音起止端点的基础上,使语音前后保留合适的余量,同时不能分割连续的语音,以保证剪辑的流畅性.然而深度学习模型可以分析并学习出数据的内在联系,在同一风格的剪辑工作中往往具有良好表现.近年来卷积神经网络[7](Convolutional Neural Networks,CNN)被广泛应用于计算机视觉和语音识别等领域.它拥有局部感受野,权值共享等特点,计算效率较高[8].并且随着卷积层数的深入,可以抽象出高维度特征[9].但若仅使用CNN或循环神经网络(Recurrent Neural Networks,RNN),将无法有效的获取长时间序列的关联信息,导致模型偏静态.而门控循环单元[10](Gated Recurrent Units,GRU)拥有更新门和重置门,可以对隐藏层信息进行更新,使得它可以有效记忆先前的时间序列信息,避免了梯度消失和爆炸现象.但单向GRU无法结合后续时间的特征来进行预测,同样无法做到接近人工剪辑的效果.此外由于RNN无法在单个图形处理器(Graphic Processing Unit,GPU)上并行计算,音频序列的数据量较大时,会降低模型运行速率的优势.
从剪辑工作存在的难点和实际应用角度考虑,本文提出了一种端到端的语音自动剪辑模型 CNN-BiGRU.它通过提取音频中的对数梅尔频谱[11](Filter Banks,Fbank)、短时能量[12]和短时过零率[13]3种声学特征,并将它们分别输入3个不同的CNN.使用LeakyReLU函数[14]进行激活,并将卷积层的输出融合后[15,16],输入由正向GRU、后向GRU和全连接神经网络[17](Fully Connected Neural Networks,FC)组成的双向门控循环神经网络[18](Bidirectional Gated Recurrent Neural Networks,Bi-GRU).最后使用Softmax[19]对最终输出结果进行激活和分类.使用二元交叉熵损失函数[20]计算损失值,采用课程式学习训练模型,将参数优化至最佳.
由于模型需要在考虑整体宏观信息的基础上结合局部微观信息进行预测,常规的小批量梯度下降(mini batch)存在一定局限性,本文考虑使用基于课程式学习的方法来训练模型.Bengio等人[21]于2009年最早提出了课程式学习这一概念,它使用先易后难的数据形式对模型进行训练[22,23],和儿童的学习过程相似.Liu等人[24]指出课程式学习能增强模型读取长时间序列的能力.考虑到剪辑模型也需具备该特性,所以采用先大后小的数据类型进行训练,过程类似于树木生长,由整体到局部.
考虑到实际工程中的应用,本模型在确保准确率的情况下,尽可能减少参数,降低计算复杂度.实验结果表明模型在切分语音时,在前后保留了不同程度的余量,使剪辑后的视频过渡柔和;同时该模型不会分割连续的语音,以确保视频的连贯性.此外它还能检测出非语音部分的人为异常噪声并将其删除,但不会对语音部分出现的环境噪声进行切分.相较于采用传统人工剪辑,使用模型可以大幅缩短剪辑时间,并取得和人工剪辑相近似的结果.在节省人力成本的同时,可使某些与时效性较强的视频尽早发布,从而获得更多的流量和收益.
2 音频特征提取
本文从音频中提取了3种声学特征作为模型的输入.它们分别是声谱特征中的Fbank;韵律学特征中的短时能量和短时过零率(以下简称过零率).其中Fbank主要用于检测语音部分[11],而短时能量和过零率主要用于检测人为异常噪声[25].提取出3种特征后,对其进行预处理,便于后续神经网络的计算.
2.1 声谱特征提取
目前语音识别等领域常用的两种声谱特征为Fbank[11]和梅尔频谱倒谱系数[26](Mel-Frequency Cepstral Coefficients,MFCC).MFCC是在Fbank的基础上进行了一次离散余弦变换,所以Fbank相比较MFCC保有的更多的信息[27].故本文选择Fbank用以检测音频中的语音部分.
Fbank的提取过程如下:首先对波形音频进行帧采样,采样率设为22.05kHz[27].之后进行预加重,预加重系数设为0.97[28].再对音频进行分帧[29],为了缩小数据量,将帧长设为约46ms,帧移约23ms.分帧后进行加窗,窗函数选用汉明窗[30],公式如式(1)所示:
(1)
之后进行快速傅里叶变换,将加窗后的音频信号从时域转换为频域,再将频率标度转化为梅尔尺度[27],转换过程如式(2)所示.在梅尔尺度上使用40个等面积三角过滤器进行滤波[29],得到Fbank特征数据,结果如图1所示.在提取完Fbank特征后分别对其中每个维度的数据进行归一化处理.

图1 对数梅尔频谱图
(2)
2.2 韵律学特征提取
在语音录制的过程中,难免会出现一些如咳嗽,清嗓等人为噪声.而在发出此类噪声时,短时能量和过零率会出现大幅波动[25],如图2所示.所以它们可用来检测异常噪声,同时也能辅助识别语音部分.
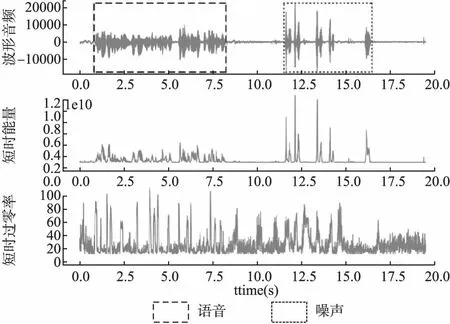
图2 波形音频、短时能量与短时过零率
2.2.1 短时能量
短时能量是指一帧音频中所蕴含的能量信息[12],本文选择每512个采样点作为一帧,窗函数为矩形窗.短时能量的计算过程如式(3)所示:
(3)
其中En为短时能量的值,m为音频帧,ω(n)为窗函数.因为短时能量的数值巨大,所以先对其取对数,再进行归一化.
2.2.2 短时过零率
短时过零率指的是一帧音频中信号通过零点的次数.清音时过零率数值较高,浊音时较低.通过计算每一帧时间内信号通过零点的次数,然后除以每帧所含采样点的数目,得出过零率[13],计算过程如式(4)所示.将每512个采样点作为一帧,窗函数选用矩形窗来提取过零率,并进行归一化.
(4)
其中m为音频帧,sgn()为符号函数.
3 语音自动剪辑模型
自动剪辑模型需要遵从一些基本的剪辑技法[3],以提升它的艺术性.例如O′Steen[6]提到综合考虑整体与局部的关联性来把控剪辑的节奏;去除异常噪声提高听众舒适度;不对连续的音频进行切分以提升流畅度等.为了满足上述需求,本文提出了一个融合3种声学特征,结合3种不同神经网络的语音剪辑模型CNN-BiGRU.
3.1 模型总体结构
CNN-BiGRU模型的总体结构如下:从波形音频中提取出Fbank、短时能量和过零率3种声学信号特征,进行预处理后,分别输入3个不同的CNN.将Fbank特征输入由两层二维CNN组成的神经网络中;短时能量和过零率则分别输入两个一维CNN.使用LeakyReLU函数进行激活,并将卷积层的输出融合后,输入Bi-GRU中.Bi-GRU由正向GRU层、后向GRU层[31]和FC层[17]组成.采用Softmax对最终结果进行激活和分类,送入交叉熵损失函数计算损失值,并使用基于课程式学习的方法来优化模型参数.模型总体结构如图3所示.
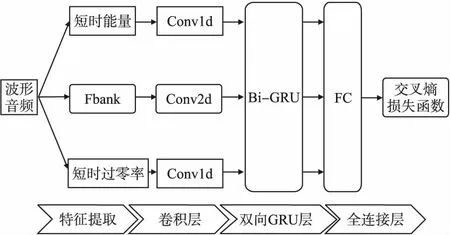
图3 CNN-BiGRU模型结构图
3.2 声学特征融合
由于Fbank、短时能量和过零率它们所包含的信息不同,若简单地将其输入到同一个神经网络中会降低模型的性能.故通过使用3个不同的CNN,分别对3种声学特征进行卷积操作,并为不同的特征分配合适的权重.此外考虑到3种声学特征的数值差异较大,卷积层中所使用的过滤器均添加有偏置向量.
卷积神经网络使用卷积核不断滑动和对应窗口大小的数据进行哈达玛积运算,再与偏置向量求和,从而得出一个新的值[7],计算过程如式(5)所示.
(5)
首先对于Fbank特征,使用两层二维CNN进行卷积操作.第1层使用8个1*40的过滤器进行卷积操作.卷积的步长(stride)设置为1.第1层CNN用来抽象出每个时间节点处的特征.第2层使用3个5*8的过滤器来进行卷积操作,卷积的步长仍设置为1,填充(padding)设为2.第2层CNN可以结合部分周边数据的特征信息.此外考虑到音频特征是高度非线性的,采用LeakyReLU函数[14]来对卷积层的输出进行激活.该激活函数在负区间内有一个待学习参数α,有效的避免了梯度为0的现象.LeakyReLU函数如式(6)所示:
(6)
而对于短时能量特征,使用一层一维CNN对其进行卷积操作,过滤器大小设为5,步长设置为1,填充设为2.短过零率所使用的CNN和短时能量参数相同.最后将卷积层的输出融合后输入Bi-GRU中,卷积层的结构如图4所示.
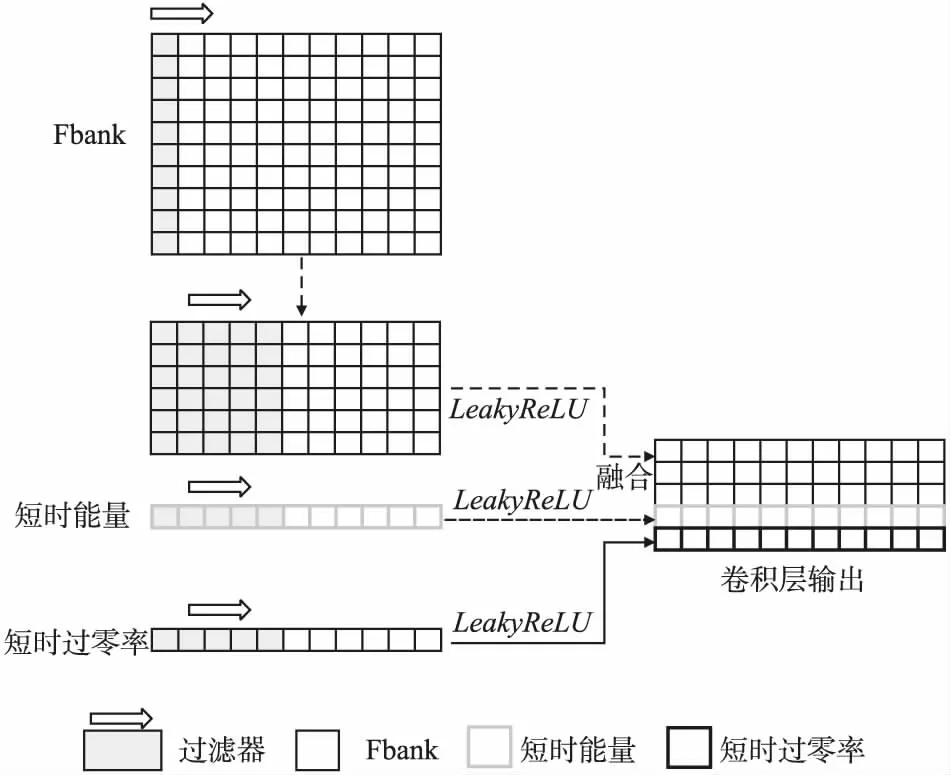
图4 卷积层结构图
经过卷积层处理后的数据一定程度上聚合了周边节点的信息,抽象出了高维度非线性特征[9].同时对原始数据进行降维,减小了Bi-GRU的运算量,而且给3种声学特征分配了不同比例的权重,使得Bi-GRU可以更有效的权衡并优化参数.
3.3 时间信息结合
由于语音剪辑需要在综合考虑宏观信息的基础上结合微观信息来进行,剪辑模型必须能够读取并记忆长时间序列的前后关联性特征.此外考虑到实际应用中的运行效率,模型的计算复杂度又不能过高.综合考虑后决定采用Bi-GRU,来读取时间序列的关联信息.Cho[10]等人在2014年首先提出了门控循环单元(Gated Recurrent Units,GRU),它不同于普通的RNN,另设有重置门和更新门对隐藏层的状态进行更新,使它能有效捕捉长时间序列的依赖关系,一定程度避免了经典RNN存在的梯度消失等问题.它和长短时记忆网络(Long-Short Term Memory,LSTM)类似,不同的是它将LSTM的输入门和遗忘门合并成更新门,使得它的计算复杂度小于LSTM[31,32].GRU的更新门用于确定多少先前的隐藏信息保留到当前节点,重置门用于控制多少信息在当前节点被遗忘.
本文使用一层正向GRU、一层后向GRU和一层FC来组成Bi-GRU,它使模型在每个时间节点的输出都可以充分读取正向和后向的隐藏层状态信息.为了防止模型过学习,同时减少冗余参数,将隐藏层单元的随机失活率dropout[33]设为0.2.FC的输入为正向和后向GRU的隐藏层信息,输出为1维序列,使用Softmax对的输出结果进行激活和分类.Bi-GRU模型结构如图5所示,其中左侧为单个GRU单元.
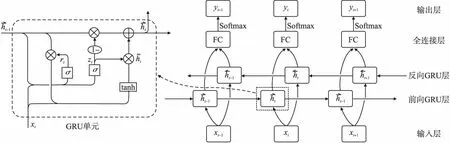
图5 Bi-GRU结构图
(7)
由于剪辑是一个二分类的任务,采用二元交叉熵损失函数[20]来计算模型最终的损失值,计算过程如式(8)所示:
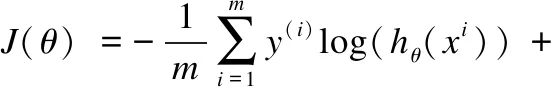
(8)
4 实 验
4.1 数据准备与标签处理
为了保证训练集数据的平衡性,人工录制了约30分钟的音频,其中语音占比约60%,语言为中文.录制时在语句之间停顿3秒,段落间停顿30秒,同时发出一些人为噪声.之后向其添加城市街道噪声,以此模拟户外录制环境.相较于稳定的白噪声,城市噪声属于随机噪声,更具干扰性.经过加噪处理后的语音信噪比在0db左右,以此来增加模型训练难度,强化模型的鲁棒性.
验证集和测试集使用CHiME-5数据集,它是一个嘈杂环境下的语音识别挑战数据集[34].该数据集包含真实、仿真和干净的录音,其中真实录音由6个四通道麦克风阵列所录制,内容为家庭晚宴,语言为英语,每段录音的时长在两小时左右.选取距离说话者位置最远的麦克风所录制的音频,从不同音频中分别截取各60分钟作为验证集和测试集,其中语音部分占比均在75%左右.数据集中音频的语音响度较低,同时环境中存在着大量随机噪声、宽带噪声以及远场混响等干扰因素,约有15%的语音达到平均意见评分[35]等级2的标准,需要集中相当的注意力才能听清,使用此数据来查看模型在极端环境下的表现.
标签以人工标注的方式进行,邀请上海广播电视台的剪辑师对数据集进行标注.音频以波形图的方式显示,人工听取后再选取需要保留的音频,保留部分为正例样本,反之亦然,标注过程如图6所示.以下为剪辑师的标注习性:在语句间停顿超过2s时,剪辑师会对其进行切分,同时在句子两端分别保留0.5~1s作为缓冲.当语音段落和段落之间具有较长停顿时,会在段落的起始和结尾处分别保留约1~2s空余.而当语句连续时,例如语句间的停顿小于2s,剪辑师不会对其进行切分.此外它会删去人为发出的噪声,但不会删除语音部分处出现的环境噪声.经过人工剪辑后的音频过渡流畅,无明显停顿,同时听者也能区分出不同的段落.原始标签以二进制时间序列的形式保存,标签数量与音频采样点数量相同,之后对其进行下采样,使之和特征序列长度相同.
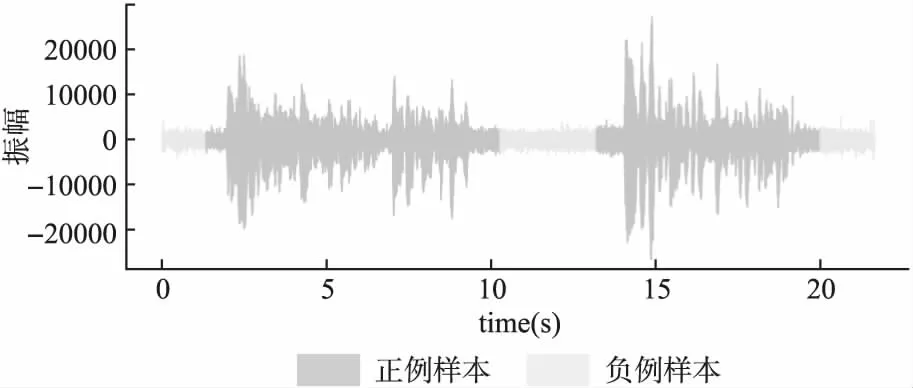
图6 标签标注
4.2 基于课程式学习的训练
剪辑工作不同于语音端点检测,需要模型在考虑整体宏观信息的基础上结合局部微观信息进行预测.所以常规的小批量训练存在一定局限性,为了能更好地训练模型,本文采用基于课程式学习[21-23]的方法进行训练,来强化模型读取长时间序列的能力[24].为了让本模型能更好的结合音频特征之间的前后联系进行剪辑,使用先整体后局部的数据形式进行训练,过程类似于树木生长,由树干到树支.同时训练的过程先快后慢,整体部分快而局部则慢.
首先,将训练集中的音频每95秒划分为一个批次,优化器使用Adam[36],学习率设置为0.01,进行第1轮训练.训练的目的是让模型能学习到整体的关联性特征,即段落与段落之间的联系.在经过一定数量地迭代,当模型尚未完全收敛时,停止训练.倘若使用大批次数据训练模型至完全收敛,会导致模型过拟合,在验证集上性能有所下降.第2轮训练时,将每21秒音频划分为一个批次,优化器同样使用Adam,但初始学习率下降为0.001.此外设置指数学习率衰减[37],即每进行一次迭代后将当前学习率乘以衰减系数γ,这里将设γ为0.95.第2轮训练的目的是能让模型将注意力集中在细节处,即句子与句子之间的联系.由于小批次数据变化较大,较小的学习率可使模型参数相对保持稳定.
相较于传统固定批次的mini batch,课程式学习通过变换批次的大小,提高数据的差异性,使模型能有效的权衡宏观与微观的信息,从而将模型优化到最佳状态.训练结束后选取验证集上表现最优的模型,在测试集上进行测试.考虑实际工程中的应用,不对验证集和测试集的数据进行切分,以此来保证测试数据的完整性.
4.3 评价指标
使用Softmax对模型的输出结果进行分类,判断模型的预测与标签是否一致.使用准确率(Accuracy)作为模型的评价指标之一,公式如式(9)所示:
(9)
其中,TP代表预测正确的正例样本数,TN为预测正确的负例样本数,R为原始音频的总样本数.但在剪辑任务中当音频中的负例样本远多于正例样本时,准确率并不能显著地体现模型之间的性能差异.
所以除了准确率,剪辑质量的判断还将采用误剪率作为衡量标准,误剪率(Miss)的含义是剪辑非所需内容和所需内容之间的比值.误剪率在样本分布不平衡时,仍然能精确地衡量模型的性能,误剪率的计算过程如式(10)所示:
(10)
其中FP为预测错误的正例样本数,FN为预测错误的负例样本数,R+为标签中正例样本的总数.
准确率越高,说明模型预测越准确;误剪率越低,说明模型与人工剪辑越相似.
4.4 消融实验
本次实验的环境配置如下:操作环境Windows 10 pro,CPU为AMD Ryzen 2700 @3.2GHz,GPU采用Nvidia Geforce GTX1080 1708MHz,内存使用双通道16g ddr4 2666MHz,开发环境是Pytorch 1.9.0+cuda11.2,开发工具为微软Visual Studio Code.
首先对比不同声学特征在CNN-BiGRU上的表现,实验结果如表1所示.为了验证多特征融合此方法的有效性,实验中所使用的对比模型其CNN数量与输入特征数量保持一致,且均采用课程式学习在验证集上训练至最佳.
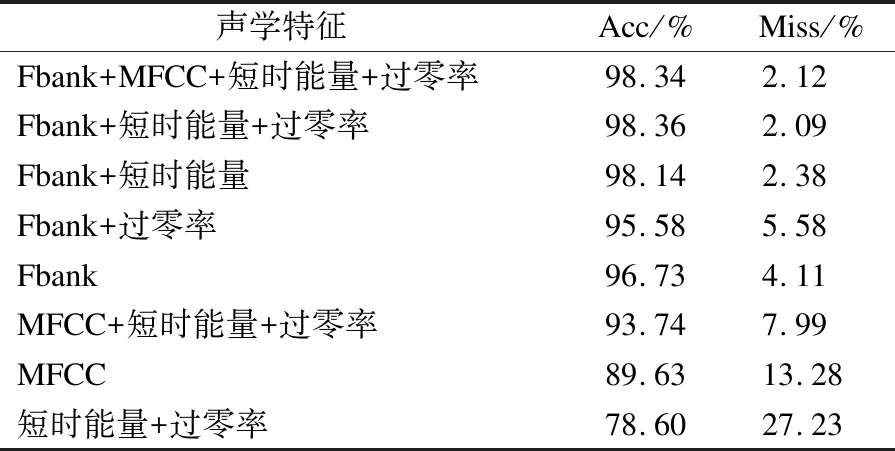
表1 声学特征对比
实验结果表明,使用频谱特征与韵律学特征融合的方式能有效提升模型性能,使用Fbank+短时能量+过零率时模型性能达到最优.MFCC结合短时能量+过零率比MFCC提升了约4%.Fbank+短时能量也使性能有所提升.但Fbank+过零率则使性能略微下降,原因在于过零率主要用于区分清音和浊音,当环境中存在大量随机噪声时会产生一定的虚假的过零率,反而会干扰模型的判断,所以过零率通常与短时能量结合使用.
在单特征中Fbank比MFCC性能高出约7%,这说明在深度学习模型中Fbank的性能优于MFCC.短时能量+过零率效果最差,说明在低信噪比情况下韵律学特征的抗干扰能力较弱.此外使用四种特征时,模型的性能不再有提升,表明特征数量与模型性能并非完全的正相关.
通过对比不同模型间的准确率和误剪率来判断其性能,实验结果如表2所示,其中对比模型均选择验证集上表现最优时的参数设置.实验结果表明CNN-BiGRU在准确率和误剪率上均明显优于其他模型.该模型在测试集上的准确率为98.36%,误剪率为2.09%.Bi-GRU和Bi-LSTM模型的性能相似,准确率在97.1%左右.而CNN-GRU模型由于仅使用单向GRU,无法结合后向信息进行预测,所以模型的准确率稍低为93.05%.CNN和DNN-HMM因为无法有效结合长时间序列的信息,在处理高度非线性的音频特征时效果较差,准确率均在78.5%左右.
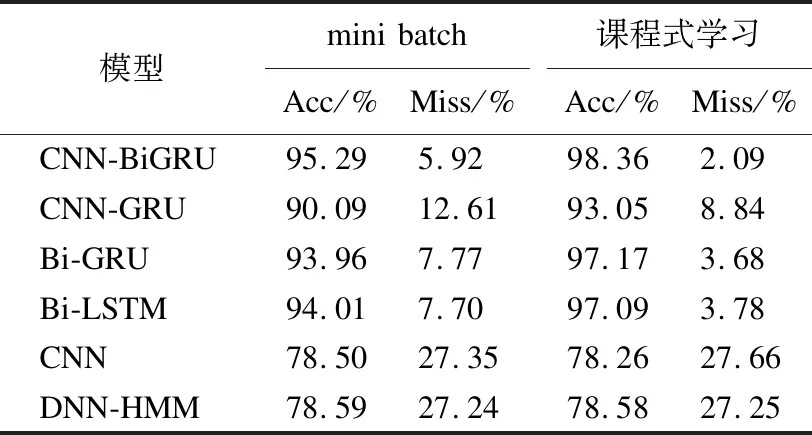
表2 模型性能对比
实验还对比了不同训练方式对模型性能造成的影响,结果如表2所示,其中mini batch固定使用50秒的音频作为每个批次的数据,优化器使用Adam,学习率固定为0.01.实验结果表明相比较传统的mini batch,课程式学习使CNN-BiGRU、CNN-GRU、Bi-GRU和Bi-LSTM模型的准确率均提升了约3%,说明课程式学习可以在一定程度上提升RNN的性能.然而DNN-HMM则由于马尔科夫性的限制,变换数据长度的训练方式基本没有对模型性能造成影响.而CNN模型因为其结构简单,参数较少,数据变化较大时会略微影响性能.
实验分别记录了模型计算60分钟音频数据所需的运行时间和内存占用,来衡量模型的计算效率,结果如表3所示.其中CNN运行时间最少,但其预测效果过差,不具备应用价值.Bi-LSTM和Bi-GRU的运行时间和运行内存都较高,它们对硬件的需求也较高.而本文提出的CNN-BiGRU其运行内存和时间均为Bi-GRU的86%左右,说明使用卷积层可以在一定程度上减小RNN的计算量,同时也降低了模型的参数量.CNN-BiGRU使用更少的运行内存获得了比CNN-GRU更优异的性能,但它的运行时间多于CNN-GRU.CNN-BiGRU使用GPU进行剪辑运算仅需6.25秒,而标注数据集的剪辑师使用索贝非线性编辑系统进行剪辑平均花费了约35分钟.显然相较人工剪辑,模型可以大幅度节省时间成本,此外它的性能不会随着数据量的增大而下降,但人工效率却会因疲劳等因素逐渐下滑.
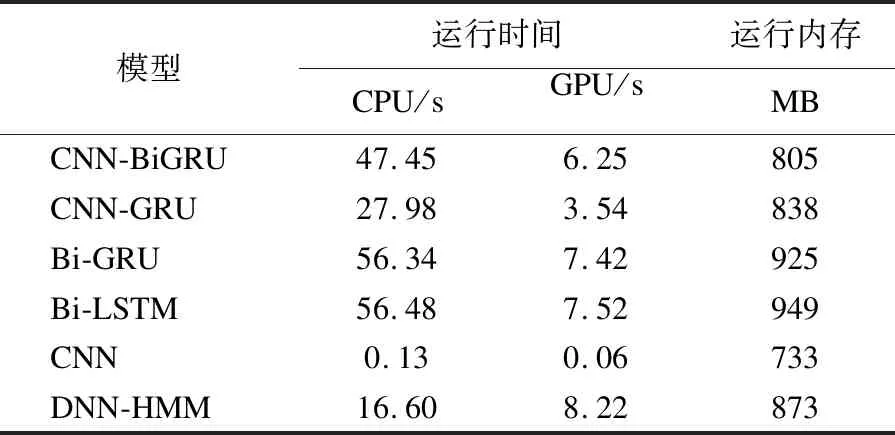
表3 模型计算效率对比
按照CNN-BiGRU模型的预测输出和人工标注的标签,对测试集的音频进行实例化剪辑,结果如图7所示.经研究发现,人工切分语音时在两侧保留的时间存在一定的波动,并且随着剪辑工作的推移,浮动越大.CNN-BiGRU在切分句子时会在语句的前后分别保留约0.8s的余量,切分段落时则会保留约1.5s的余量.另外在一处噪声严重干扰的语音部分,剪辑师误将其删除,但模型正确地进行了保留.此外模型和剪辑师一样,能准确地删除人为发出的异常噪声,同时不会对语音部分出现的环境噪声进行切分,而Bi-GRU和Bi-LSTM均无法做到这一点.表3中的其余对比模型,剪辑后音频的听感都明显逊色于CNN-BiGRU.最后请20名广播行业内的剪辑师对模型和人工剪辑的结果进行区分,13人表示无法判断,3人判断错误,仅有4人判别正确,表明模型的剪辑性能十分接近人工水平.
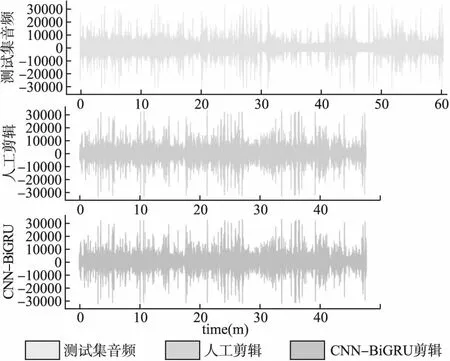
图7 CNN-BiGRU与人工剪辑结果对比
5 结 语
本文提出了一种多声学特征融合的语音自动剪辑模型CNN-BiGRU.通过提取Fbank、短时能量和短时过零率3种声学特征,使用CNN对音频特征进行融合,之后通过Bi-GRU结合双向时间信息进行预测,并采用课程式学习这一方法,将模型训练至最优.实验结果表明该模型在CHiME-5测试集上的准确率高达98.36%,剪辑过后的音频过渡流畅节奏适中,与人工剪辑的结果十分接近.该模型参数较少,运行效率高,处理一个小时的视频仅需几秒,相比较人工剪辑可以大幅减少耗时.
本模型拥有较强的鲁棒性,即使在低信噪比环境下,依然能保持良好的性能,能够胜任如户外采访,赛事解说等剪辑工作.在广播电视台等需要大量剪辑语音类媒体的场所,有着较高的应用价值.另外模型也可应用于其他领域,例如网课、会议等音视频中.通过使用不同类型的标签数据,该模型也可用于语音端点检测领域.目前随着5G时代的来临,网络视频和音频的数量呈指数型上升,届时该模型将拥有广泛的应用前景.
由于该模型根据语音进行自动剪辑,如果输入视频音画不同步,剪辑质量也会受到影响.未来可以考虑在此模型基础上,自动添加过渡转场提高艺术性,也可搭载语音识别模块生成文本,直接嵌入视频字幕中,进一步降低人工成本.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
家庭影院技术(2018年11期)2019-01-21
小说界(2018年5期)2018-11-26
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2017年9期)2017-04-17
