
融合用户属性交互的个性化评论摘要生成
2023-08-29 01:10陶嘉鸿卢永美卜令梅于中华
小型微型计算机系统 2023年8期
陶嘉鸿,卢永美,何 东,卜令梅,陈 黎,于中华
(四川大学 计算机学院,成都 610065)
1 引 言
随着网络购物的普及,电商平台积累了大量用户撰写的产品评论,这些评论包含的信息对于普通用户、商家和厂家均具有重要的参考价值.例如,普通用户可以基于这些评论获知产品和服务的口碑,在此基础上更合理地选择自己所需要的产品和服务.然而,阅读大量篇幅长短不一、口语化的评论文本,会引起严重的信息过载问题,显著增加用户(包括普通个人用户、商家和厂家)利用这些信息进行科学决策的负担.表面上看,单评论摘要似乎意义不大,然而据本文对Li等[1]采集的评论文本的统计,其中的酒店评论平均每篇包含10个句子,154个词,而且越具有参考价值的评论,篇幅往往越长.因此,产生单篇评论的摘要,用少量的句子或短语概括表达评论的主要内容,仍然可以显著减轻用户获取评论信息的负担,具有重要意义.
文本摘要是压缩文本内容、缓解信息过载、提高信息获取效率的关键技术,受到学术界和工业界的重视,一直是自然语言处理领域的重要研究方向[2-5].传统的文本摘要研究主要面向科技文献、新闻等以书面语创作的应用文,而产品评论具有口语化、包含大量主观性观点的特点,这使得传统的文本摘要技术无法直接用于产品评论,有必要专门研究面向产品评论的自动摘要技术.在此背景下,产品评论自动摘要成为当前的一个研究热点[6-10].
在选择产品或服务时,不同的用户可能存在偏好上的差异.图1给出了一个示例,在选择酒店时,年长的用户可能关注酒店的设施情况,而其他用户可能聚焦酒店的房间或交通出行的便捷程度.对所有用户一视同仁地产生评论摘要无法满足上述个性化的信息需求,而提供个性化的评论摘要可以进一步提高用户获取有价值信息的效率,优化用户体验.

图1 个性化评论摘要示例
为了弥补现有评论摘要生成方法在个性化方面存在的不足,一些研究者开始研究个性化评论摘要生成问题[11-16],旨在针对一篇评论文本,面向不同用户产生反映他们不同偏好的摘要.需要说明的是,在这些文献中,评论摘要也被称为评论标题(Headline或Title)或贴士(Tips).
个性化评论摘要生成的相关研究才刚刚起步,目前只有为数不多的几项工作[11-16].这些工作提出的方法大多以序列到序列模型(Seq2Seq)为基础,基于某种用户偏好表达(也叫用户模型,或用户画像)捕捉评论文本中用户可能感兴趣的关键信息,据此生成符合用户个性化偏好和用词习惯的评论摘要,它们之间最大的区别主要体现在建模用户偏好上.Liu等[12]利用用户ID嵌入向量来表示用户偏好,而Li等[13]综合利用用户ID嵌入向量和用户个性化词表来表达用户偏好和用词习惯.
上述方法用ID表示用户,通过学习ID嵌入来捕捉用户偏好,这本质上属于直推式学习,只有通过重新训练才能得到新用户ID的嵌入表达.此外,用户ID嵌入面临冷启动和数据稀疏的问题,对于未发表或只发表少量评论/摘要的用户,其ID嵌入无法得到充分训练,因此无法表达他的兴趣偏好.为此,Li等[1]提出了基于用户属性的个性化评论摘要生成算法.该算法首先学习单方面属性特征(年龄、性别、旅行状态等)的嵌入表达,然后拼接一个用户所有属性特征的嵌入表达,作为该用户的偏好表达,用于捕捉评论文本中个性化的关键信息.
利用用户属性避免了新用户ID需要重新训练才能得到嵌入表达的问题,也可以缓解用户ID数据稀疏和冷启动带来的挑战,但是简单拼接不同属性特征的嵌入表达忽略了不同用户属性之间的关联,使得Li等[1]的方法在用户偏好捕捉方面能力偏弱.实际上,尽管具有某种属性特征的用户可能表现出一定的偏好倾向,但这种倾向往往很大程度上受同一用户其他方面属性特征的影响.例如,尽管一些出差人员不太关注酒店价格,但刚参加工作的年轻人即使出差也可能对酒店价格很敏感,倾向于选择价格实惠的酒店.
为了对用户属性特征之间的关联进行建模,从而更准确地捕捉用户的个性化偏好,本文提出一种融合用户属性交互的个性化评论摘要生成算法.该算法首先自动学习单方面属性特征的嵌入表达,然后利用自注意力机制捕捉一个用户不同方面属性特征之间的交互关联,并据此融合一个用户多方面的属性特征,最后得到综合的用户偏好表达.这样的偏好表达既被用于序列到序列模型的编码端,也被用于解码端.编码端凭借用户偏好聚焦用户可能感兴趣的信息,而解码端在用户偏好的指导下生成符合用户个性化兴趣的摘要文本.为了验证上述方法的有效性,本文在Li等[1]发布的、包含用户多方面属性信息的个性化评论摘要数据集TripAtt上进行了一系列对比和消融实验.实验结果表明,融合属性特征之间交互的用户个性化建模方法能更准确地学习用户偏好,生成的个性化评论摘要比现有的先进算法在指标ROUGE-1、ROUGE-2和ROUGE-L上均有明显、稳定的提升.
本文的主要贡献包括:
1)提出了基于自注意力的端到端个性化评论摘要生成算法,该算法能够更好地捕捉用户属性之间的关联,从而提升个性化评论摘要任务的性能;
2)在基准数据集上进行了一系列实验,实验结果表明本文提出的算法明显优于目前已有的先进算法.
2 相关工作
自动文摘是解决信息过载问题的重要方法,因此成为自然语言处理领域经典的研究问题,受到几十年持续的关注和广泛的研究.已经提出的自动文摘方法可以分为抽取式和生成式两类[17-19].随着深度学习特别是序列到序列模型的不断发展,目前先进的自动文摘系统普遍采用基于序列到序列模型的生成式方法.
早期的自动文摘主要面向科技文献,用于解决科技信息获取过程中的过载问题.随着互联网技术的广泛应用,快速获取Web信息成为自动文摘新的应用领域[20-22].科技文献摘要需要客观概括文档的主题和内容,一篇文档只有一篇摘要,和具体受众的个性化需求关系不大.而用于获取Web信息的网页摘要,由于不同用户可能有不同的关注点,个性化成为提升用户获取信息效率、优化用户体验的重要手段[23-26].例如,Díaz1等[23]通过捕捉用户对电子报刊不同版面的关注程度进行用户建模,在此基础上实现了一个抽取式的个性化摘要算法;Móro等[24]利用潜在语义分析对用户-词项矩阵进行分解,据此进行句子选择,由抽取出的句子形成个性化的摘要;Yan等[25]利用用户的点击行为数据来进行用户偏好的动态建模,实现个性化摘要.搜索引擎抽取并展示命中网页中包含查询词的片段,这样的片段属于一种特殊的个性化摘要,用户个性化偏好由查询(Query)来表示[26].
考虑到产品评论对于普通用户、商家和厂家的决策均具有重要参考价值,为了充分利用产品评论所包含的重要信息,降低用户获取这些信息的负担,面向评论文本的自动文摘开始受到重视[6-10].由于评论文本具有口语化严重、文本质量差、主要描述主观感受和观点等特点,一般的自动文摘算法无法直接用于评论,需要针对评论文本的特点进行专门的研究.和一般的自动文摘一样,目前占据主导地位的是以序列到序列模型为基础的生成式评论摘要方法,只不过多数考虑了评论文本的上述特点.例如,Ma等[8]提出了以情绪分类为辅助任务的端到端评论摘要生成模型,Yang等[9]提出了融合情绪和产品方面(Aspect)信息的多因子注意力摘要生成模型.
尽管在评论自动文摘方面已经开展了大量研究,取得了很多有前景的成果,然而,这些工作均忽略了不同用户在获取评论信息方面可能存在的个性化差异.为此,一些研究者开始研究个性化评论摘要生成问题[11-13],并带动了后续的进一步研究,提高了个性化评论摘要的生成质量[14-16].
在个性化评论摘要生成的方法上,绝大多数现有工作均采用带有注意力机制的序列到序列模型,以用户个性化偏好表达为查询向量,利用注意力机制捕捉输入评论中反映用户偏好的关键信息,在此基础上结合用户偏好表达生成符合用户偏好的摘要文本.它们之间的主要差别体现在个性化特征的信息源以及用户建模方法上.Liu等[12]利用用户ID嵌入向量来表示用户偏好,把该嵌入向量视作先验知识,用于初始化序列到序列模型的编码器和解码器,而Li等[13]综合利用用户ID嵌入向量和用户个性化词表来表达用户偏好和用词习惯,并尝试了把它们融入序列到序列模型的4种策略,包括个性化词拷贝和生成相结合的文本生成策略.一些文献认为产品评论摘要除了需要个性化,还应该面向目标产品,提出了在序列到序列模型中同时融合用户ID嵌入和产品ID嵌入的个性化评论摘要生成方法[11,15,16].其中,Xu等[16]还引入了用户对产品评分的嵌入(1-5分,每种得分对应一个自动学习的嵌入向量),提出了基于Transformer、带有内部和外部双重注意力的模型,用于评价用户已发表摘要对捕捉当前评论中关键信息以及生成个性化摘要的影响,在此基础上利用个性化词表、用户嵌入、产品嵌入和评分嵌入生成个性化摘要.
通过嵌入用户ID对用户建模存在冷启动和数据稀疏问题,必须通过重新训练才能得到新用户ID的嵌入向量,无法利用归纳出的模型来预测该向量的表达.为了解决该问题,Li等[1]提出了从用户属性学习用户偏好表达并结合属性个性化词表来生成评论摘要的方法.具体做法是首先学习单方面属性的嵌入表达,然后拼接一个用户所有属性的嵌入表达作为该用户的偏好表达,利用这样得到的偏好表达和属性个性化词表来编码评论文本和生成个性化摘要(文中尝试了4种将这些个性化信息融入序列到序列模型的策略,与Li等[13]类似).
现有工作中,Li等[1]与本文最相关,本文同样试图利用多方面的用户属性信息来捕捉用户的个性化偏好.但与Li等[1]不同,本文利用自注意力机制建模一个用户多方面属性之间的关联,解决Li等[1]忽略属性之间关联带来的个性化信息捕捉能力弱的问题.此外,本文抛弃了Li等[1]所用的属性个性化词表,认为算法能够从训练集中评论、摘要与用户属性之间的对应关系隐含地学习属性个性化词表的信息,并把该信息编码到属性嵌入表达中.抛弃属性个性化词表不仅节约了存储空间,还避免了由于查询它所带来的时间开销.实验结果表明,虽然本文算法没有使用属性个性化词表,但生成的摘要质量仍然高于Li等[1]的方法.
3 本文算法
本文算法以序列到序列模型为基础,编码器采用双向LSTM[27]学习评论中词的向量表达,解码器采用单向LSTM顺序地生成摘要中的每个词.为了更好地对用户偏好进行建模,本文引入属性嵌入之间的自注意力机制来捕捉用户属性之间的关联.在顺序生成摘要中每个词时,解码器以用户偏好表达为查询向量,通过注意力机制聚焦输入评论中用户可能感兴趣的内容,得到个性化的评论表达,用作生成当前词的前后文表达.本节首先给出任务的形式化描述,然后介绍本文算法的技术细节.
3.1 基于用户属性的个性化评论摘要任务描述
为了解决单纯依赖用户ID产生个性化评论摘要存在的冷启动问题,与Li等[1]一样,本文的任务也是基于用户属性信息实现个性化评论摘要生成.该任务可以形式化地描述为:给定评论文本X=x1x2…xN和具有属性特征集合A的用户U,生成反映用户U偏好的摘要Y=y1y2…yM,其中xi和yj分别是评论和摘要中的词.A是用户U的属性-值对的集合(如A={年龄=65+,性别=Male,旅行状态=Traveled as a couple}),用作获取用户偏好的重要信息来源.
本文研究采用的数据集为Li等[1]发布的TripAtt,其中每条记录是一个三元组,由酒店评论、用户和摘要组成.每个用户由年龄、性别和旅行状态3个方面的属性特征来刻画,分别用a1,a2和a3来表示,即A={a1,a2,a3}.
3.2 模型架构
本文算法的模型框架如图2所示.整个模型由3部分组成:评论编码器、属性编码器和摘要解码器.其中,属性编码器采用自注意力机制捕捉一个用户不同方面属性之间关联,摘要解码器以用户偏好表达为查询向量,捕捉评论中用户可能感兴趣的关键信息,作为生成个性化摘要的前后文向量.本文将分别在3.2.1和3.2.2节详细介绍属性编码器和摘要解码器.
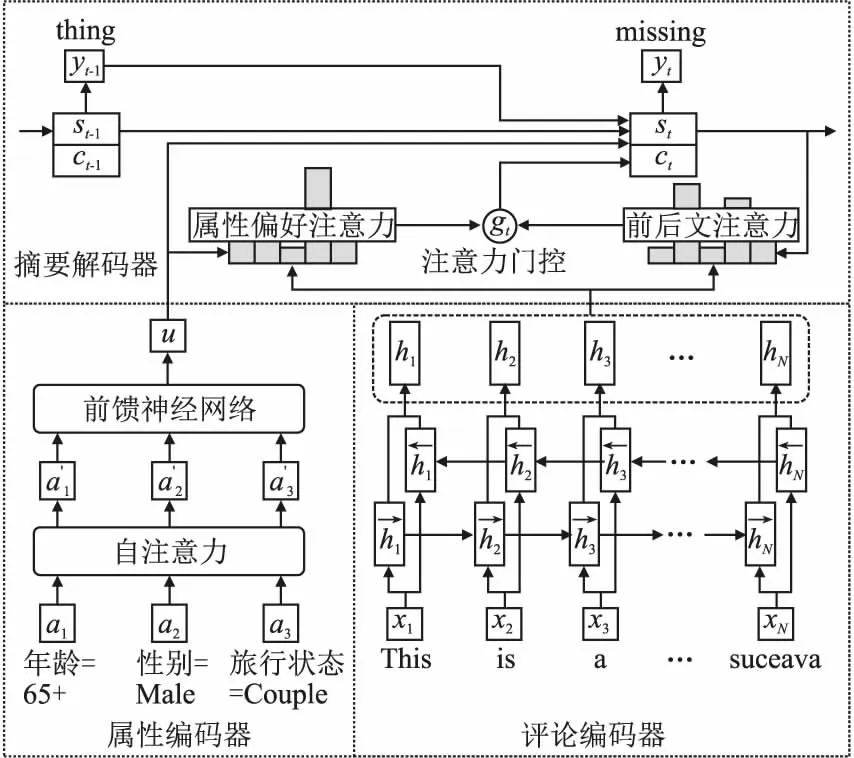
图2 模型示意图
评论编码器首先用预训练的GloVe词向量[28]初始化评论中每个词的嵌入表达,然后利用双向LSTM融合词的前后文信息,拼接每个时刻前向和后向隐藏层的向量表达,作为该时刻词的编码表示hi(如式(1)所示),用于解码器产生摘要.
(1)
3.2.1 属性编码器
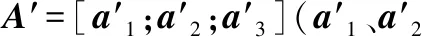
Q=WqA,K=WkA,V=WvA
(2)
(3)
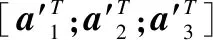
(4)
3.2.2 摘要解码器
摘要解码器基于单向LSTM,首先计算每个时刻的隐藏状态st,然后分别以st和用户偏好表达u为查询向量,利用注意力机制捕捉保持摘要与评论内容一致和反映用户偏好的关键信息,最后通过门控机制融合这两方面的注意力权重,用于计算生成摘要当前词的前后文表达.具体地,假设当前待生成的是摘要的第t个词,摘要解码器首先计算LSTM第t时刻的隐藏状态,如式(5)所示,其中yt-1是t-1时刻生成的词的嵌入表达,st-1是该时刻的隐藏状态.
st=LSTM(yt-1,st-1)
(5)
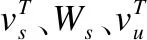
(6)
(7)
两种注意力权重通过门控机制进行融合,得到评论中每个词在第t时刻的综合注意力权重,最后对所有词按照综合注意力权重进行加权求和,得到第t时刻的前后文表达ct,如式(8)-式(10)所示,其中Wg和bg是需要学习的模型参数.
gt=sigmoid(Wg[st;u]+bg)
(8)
(9)
(10)
摘要解码器随后根据式(11)计算读出状态rt,并根据它计算第t时刻词表中每个词出现的概率Pvocab(yt).为了缓解未登录词对摘要生成带来的不利影响,借鉴带有拷贝机制的文本生成方法[3],本文通过生成模式和拷贝模式两种途径产生t时刻的词,生成模式生成词表中的词,拷贝模式则拷贝输入评论中的词.解码器通过这两种模式计算yt作为摘要第t个词输出的概率,计算方式见式(12)和式(13),其中Wvocab为需要学习的模型参数.
rt=tanh(Wr[st;ct;u])
(11)
Pvocab(yt)=softmax(Wvocabrt)
(12)
Pcopy(yt)=∑i;xi=ytβt,i
(13)
而P(yt)是yt作为摘要第t个词输出的最终概率,它是由两种模式的概率以及通过式(15)学习的门,按照式(14)进行融合得到的.
P(yt)=pgPvocab(yt)+(1-pg)Pcopy(yt)
(14)
(15)
3.3 损失函数
给定训练集D={
(16)
4 实 验
为了验证本文算法的效果,本文开展了以下4方面的实验:1)和现有基于属性的方法进行对比,考察属性交互带来的效果;2)和基于用户ID嵌入的方法进行对比,考察在用户ID数据稀疏和冷启动情况下本文算法的优势;3)消融实验,分析本文算法不同模块的作用;4)考察个性化词表的作用.下面首先介绍实验所用的数据集及评价指标.
4.1 数据集及评价指标
目前带有用户属性信息的个性化评论摘要数据集只有Li等[1]发布的TripAtt,其中用户属性包括年龄、性别和旅行状态.图3给出了这些属性各种可能的取值以及在TripAtt中出现的频率分布.TripAtt共有495440条记录,每条记录包括评论文本、用户属性(由年龄、性别和旅行状态3个属性的取值来表示)和相应的评论摘要.为了方便进行实验对比,与Li等[1]的做法一样,本文随机抽取2000条记录作为测试样例,2000条记录作为验证样例,剩下491440条记录作为训练样例.此外,本文采用自动文摘领域广泛使用的ROUGE指标[30]来评价算法生成的摘要质量.该指标基于算法生成的摘要与黄金标准标注的摘要之间共现元词(n-gram)的情况来衡量算法生成的摘要质量,常用的有基于一元词的ROUGE-1、基于二元词的ROUGE-2和基于最长公共子序列的ROUGE-L.
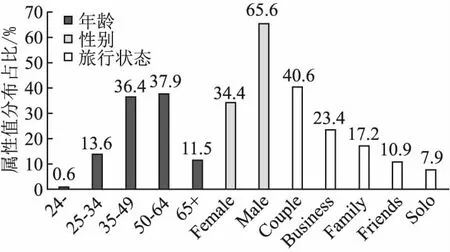
图3 用户属性的取值分布(%)
4.2 实验设置
本文基于深度学习框架PyTorch 1.9.1构建模型,Python版本是3.9.7.所有实验均在同一台服务器上进行,该服务器搭载了一块88核英特尔至强处理器和两张英伟达GeForce RTX 3090显卡,操作系统是Ubuntu 18.04.4 LTS.
本文选用优化器AdamW[31]来训练模型,设置初始学习率为0.001,并在训练过程中通过1cycle策略[32]不断调整学习率以加快模型的收敛速度.测试阶段采用束搜索(Beam Search)算法来搜索最优输出词序列,其中束宽设置为4.表1列出了模型其他超参数的取值.
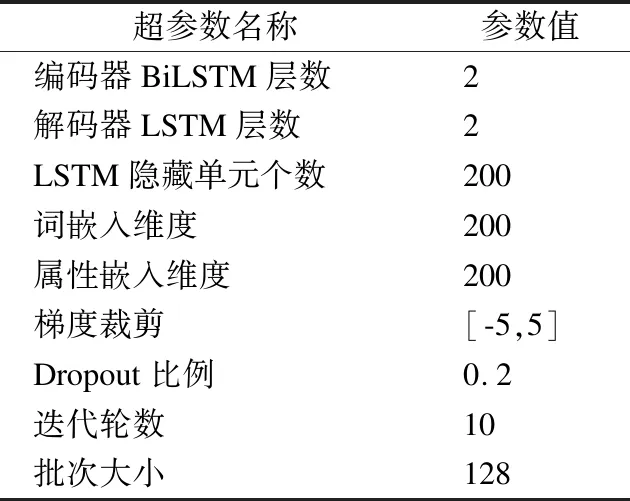
表1 模型超参数
4.3 与基于属性方法的对比
为了验证本文算法利用自注意力机制捕捉属性交互带来的效果,本文与其他基于属性的方法进行了实验对比.目前这方面的工作只有Li等[1]提出的属性感知模型ASN,其中用户偏好的捕捉基于属性个性化词表(利用TF-IDF从具有相同属性取值的用户已发表的摘要中筛选词)的嵌入来实现,该模型将用户三方面属性的嵌入进行拼接和线性变换,用得到的向量来表达用户偏好.此外,属性个性化词表还被用于解码端,解码器通过拷贝机制从中拷贝词实现个性化输出.Li等[1]尝试了将用户偏好表达和属性词表注入模型的不同策略,包括:
1)ASel:将用户偏好表达融入编码器,利用门控机制捕捉输入评论中用户可能感兴趣的内容;
2)APre:将用户偏好表达融入序列到序列模型的解码器,解码器计算读出状态时融合用户的偏好表达;
3)AMP:以用户偏好表达为查询向量,采用注意力机制融合属性个性化词表中词的嵌入表达,解码器计算读出状态时融合该表达;
4)AMG:利用指针生成网络,解码器既可以生成词,也可以拷贝属性个性化词表中的词来输出;
5)ASN:融合上述4种策略.
本文将本文算法与上述5种方法进行了实验对比.由于这些方法的实现代码没有公布,本文对它们进行了复现,并且采用与本文算法相同的数据集划分、调参方式和评价方法对它们进行评价.表2列出了本文算法和这5种方法在数据集10次随机划分下实验结果的平均值和95%置信区间.

表2 对比算法实验结果(%)
从表2可以看出,在3个评价指标上,本文算法比Li 等[1]提出的所有策略都有明显的提升(通过显著性检验,p值小于0.01),比融合4种策略的ASN在ROUGE-1、ROUGE-2和ROUGE-L上分别提高了0.59、0.79和0.64个百分点.上述结果说明,利用自注意力机制建模用户属性之间的关联,能更准确地捕捉用户偏好方面的差别,使生成的评论摘要更满足用户的个性化兴趣.此外,上述结果也说明,用户或属性个性化词表的使用和维护不是必要的,算法能够从训练集数据中学习用户的个性化信息,包括摘要用词方面的信息.
进一步地,本文统计了Li等[1]提出的ASN与本文算法在模型参数规模、训练测试用时方面的情况,用以说明本文算法的性能优势,统计结果如表3所示.根据统计结果可以发现,ASN的参数数量远超本文算法,是本文算法的2.98倍;此外,由于参数数量大,ASN需要耗费更多的时间进行训练直至收敛,在测试阶段,ASN的用时也超过了本文算法.这是因为Li等[1]提出的模型基于属性个性化词表建模用户的偏好,其属性编码模块的参数规模与词表大小成正比;而本文算法没有使用个性化词表的信息,属性编码模块的参数数量只与用户属性的数目以及属性嵌入的维度相关,因此参数更少、模型更轻量、训练和测试的速度更快.

表3 算法参数规模与训练测试用时情况
4.4 与基于用户ID嵌入方法的对比
为了验证本文算法应对冷启动和用户ID数据稀疏问题的能力,本文对测试数据集中出现的用户,按照他们过去发表的评论/摘要的数量,进行了分组,如图4所示.本文统计了本文算法在每组测试数据上的效果,并与目前最好的基于用户ID嵌入的方法(USN[13])进行了对比,如图5所示.
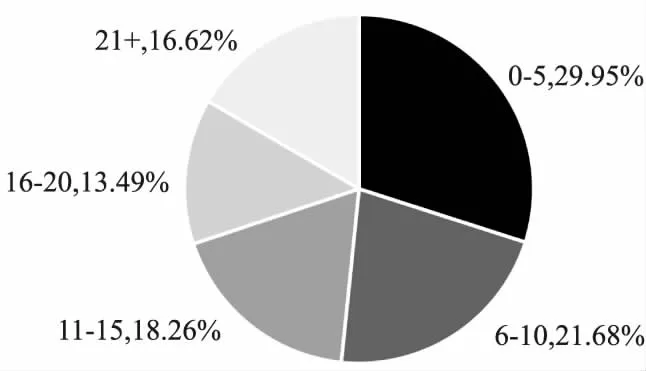
图4 用户发表评论的数量和分组情况
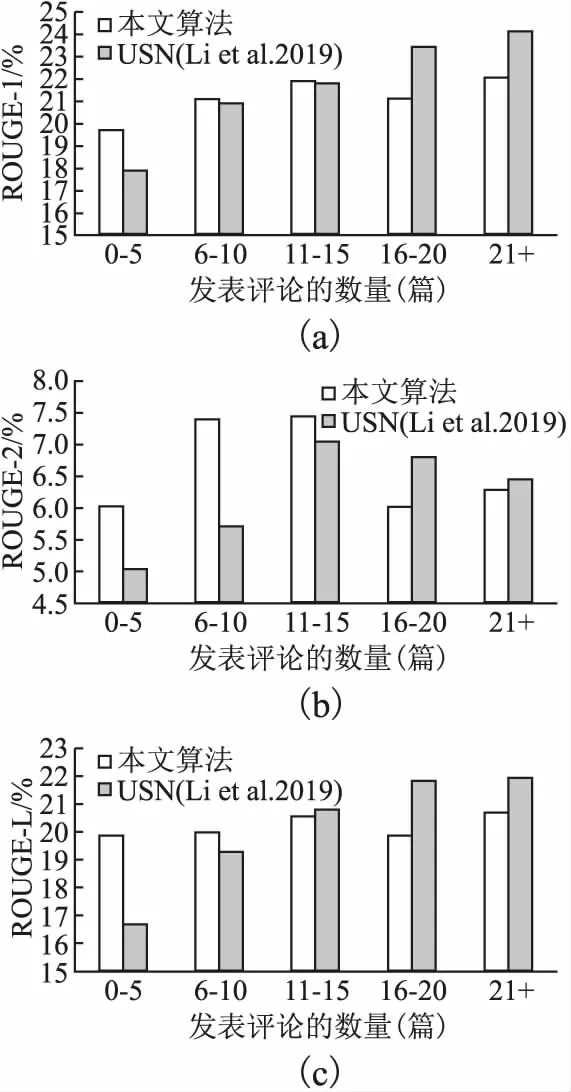
图5 发表评论的数量对算法生成个性化评论摘要的影响
从图5的实验结果可以看出,本文算法受用户ID数据稀疏的影响很小,在不同的稀疏水平下,本文算法表现得更稳定,生成的个性化摘要的质量变化较小,而USN[13]很不稳定,在用户过去发表评论/摘要数量少于5篇的时候效果远低于本文算法(在评价指标ROUGE-1、ROUGE-2和ROUGE-L上分别低了1.79、0.98和3.16个百分点).在用户ID数据稀疏不严重的情况下,例如用户过去发表的评论/摘要数量超过15篇,基于用户ID嵌入的方法优于本文的基于属性的方法,这说明在数据不稀疏的情况下,由于用户ID比属性信息粒度更小,更能区分不同用户在偏好方面的细微差别,用户ID嵌入能使生成的摘要更体现用户的个性化.
4.5 消融实验
为了进一步分析本文算法不同模块的作用,本文设计了以下消融实验:
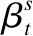
2)w/o C2:解码器计算读出状态时不融合用户的偏好表达u;
3)w/o C3:属性编码器不使用自注意力机制捕捉属性间的关联;
4)w/o C4:不考虑用户属性信息,只根据评论内容生成摘要,在这种情况下模型退化成非个性化摘要生成模型.
表4列出了消融实验的结果,可以看到本文算法各个模块在提高个性化摘要生成质量方面的不同贡献.
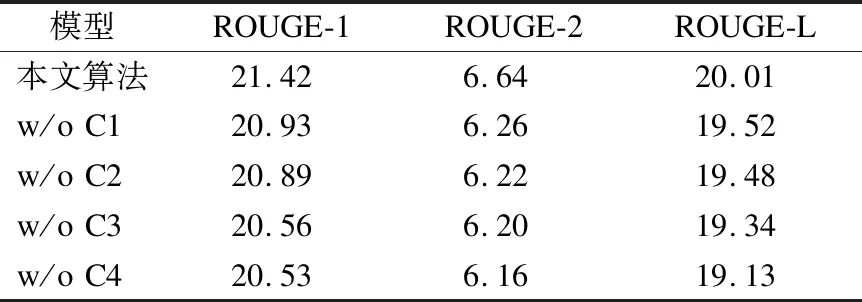
表4 消融实验结果(%)
首先,在本文算法的基础上分别设置门控信号gt等于1(w/o C1)和解码器计算读出状态时不拼接用户的偏好表达u作为输入(w/o C2)以后,算法生成的个性化摘要的质量都有明显下降,其中w/o C2下降幅度高于w/o C1,说明模块C1和C2都是有效的,并且C2的贡献大于C1.其次,w/o C3只是对用户的不同属性进行简单的拼接,忽略了属性之间的关联,导致算法生成个性化摘要的质量明显下降.这个结果说明自注意力机制很好地捕捉了属性之间的交互,能够提高个性化摘要的质量.最后,不考虑用户的属性信息、只根据评论内容进行摘要生成(w/o C4)产生的摘要的质量远差于本文算法,说明捕捉用户偏好,据此面向用户个性化地生成评论摘要,能更好地满足用户的评论信息需求,缓解信息过载带来的压力.
4.6 属性个性化词表的作用
本文利用属性嵌入层自动学习用户属性的嵌入表达,而现有相关工作[1,13,16]基于个性化词表对用户建模.为了比较这两种方法的效果,本文按照Li等[1]的描述,基于前馈神经网络实现了相同的属性编码模块C5.该模块的输入是属性个性化词表,输出是用户属性的嵌入表达.用模块C5替换本文算法中的属性嵌入层进行对比实验,实验结果如表5所示.

表5 属性个性化词表作用实验结果(%)
根据表5可以发现,虽然本文算法没有使用属性个性化词表,但生成的评论摘要在ROUGE-2和ROUGE-L上均高于使用个性化词表的版本,说明算法能够从训练集数据中学习用户的个性化信息,包括摘要用词方面的信息,用户或属性个性化词表的使用和维护不是必要的.考虑到查找和维护属性个性化词表所带来的时空开销,本文算法更具有优势.
5 结 语
本文提出了融合用户属性交互的个性化评论摘要生成算法,并进行了充分的实验验证.所提出的算法不但具有更好的摘要生成质量,而且可以解决现有方法采用用户ID嵌入带来的冷启动问题.此外,利用自注意力机制建模用户属性之间的交互,比忽略这些交互的现有方法能够更准确地捕捉用户的偏好,从而提高个性化摘要的生成效果.
目前带有用户属性信息的个性化评论摘要数据集只有Li等[1]发布的TripAtt,因此本文只基于TripAtt对所提出的算法进行了实验验证.在更多、更反映实际应用需求的数据集上验证本文算法,是本文后续工作的一个方向.此外,将本文算法经过改造应用于多评论的个性化摘要生成,是另一个有意义的工作方向.
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
英语世界(2021年13期)2021-01-12
文苑(2020年4期)2020-05-30
家庭影院技术(2019年8期)2019-12-04
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
国家图书馆学刊(2016年2期)2016-10-09
中国卫生(2015年1期)2015-01-22
