
基于SMPL 的人物视频生成算法
2023-08-24 06:47范沈伟李国平王国中
智能计算机与应用 2023年7期
范沈伟, 李国平, 王国中
(上海工程技术大学电子电气工程学院, 上海 201620)
0 引 言
在虚拟现实以及动画的制作中,人物视频的生成是一个重要的研究课题。 由于人物的外观包含大量的细节并且人物的运动由身体各个部分的运动状态决定,所以想要生成高质量的人物视频是一项具有挑战性的工作。
Vid2Vid[1]提出了一种基于条件对抗生成网络CGAN[2]的视频生成模型。 模型能够使用2D 关键点驱动关键帧生成视频。 一方面,模型预测当前帧相对于前一帧的光流,通过扭曲前一帧得到当前帧;另一方面,模型使用CGAN 来生成无法使用光流扭曲得到的部分。
一个Vid2Vid 模型只能对应于一个人物,Fewshot Vid2Vid[3]在Vid2Vid 的基础上实现了一个模型对应多个人物。 模型引入了生成器参数生成模块。 其中的生成器参数不再是固定的,而是根据输入的人物图片来生成对应的生成器参数。 相比于Vid2Vid,Few-shot Vid2Vid 训练更加困难,需要庞大的数据集,并且训练成本很高。
Vid2Vid[1]和Few-shot Vid2Vid[3]在训练以及生成视频的过程中需要使用预训练的关键点提取网络获取关键点标签信息,Monkeynet[4]提出了一种端到端的无监督视频生成模型,不再需要事先提取关键点。 模型使用了自编码器结构,首先使用帧与帧之间关键点的位移来预测帧与帧之间的光流,然后根据光流扭曲自编码器的隐式编码来得到生成的帧。
由于简单的关键点之间的位移并不能很好地表示关键点附近像素点的运动趋势。 所以除了预测关键点之外,FOMM[5]还增加了雅可比矩阵的预测。将关键点及关键点附近像素点的运动趋势看作是2D 平面内的仿射变换。 由于获取了更加准确的光流,FOMM[5]相比于Monkeynet[4]生成的视频质量更好。
国内文献[6-9]在国外工作的基础上提出了几种不同的生成网络结构进行人物视频的生成。
上述算法都使用人物2D 图像作为外观信息,人物关键点在2D 平面内的运动趋势作为运动信息来进行视频的生成,只能生成固定视角的视频。 为了生成多视角的人物视频,本文引入了3D 信息取代2D 信息。 区别于使用贴图的方式进行人物3D建模[10-12],本文提出了一种结合SMPL[13]以及NERF[14]的方法获取人物3D 模型。 考虑到3D 模型由SMPL 获得,因此利用VIBE[15]得到的SMPL 参数可以对其进行驱动,以此完成多视角人物视频的生成。
1 相关技术
1.1 NERF
神经辐射场(NERF)是一种通过稀疏的不同视角的图片,对静态三维物体进行重建的技术。 过程中使用一个神经网络(多层感知机MLP)来表示一个静态的三维物体。 研究输入是观测视角(θ,ϕ)和三维坐标点(x,y,z),输出是体密度σ以及三维坐标点的颜色c。 使用输出(σ,c) 进行体渲染,就能得到三维物体在不同视角下的二维图像。
体渲染首先根据观测视角和相机参数确定观测点以及图像平面。 以观测点为起点,以图像平面每个像素的中心为目标发射射线。 在近平面和远平面之间,将射线均分成n段。 每段的长度记为δ。 在每一个小段中进行随机采样,并送入NERF 得到对应三维坐标点的σ,c。 根据式(1)进行积分得到射线与图像平面交点处像素的值:
1.2 SMPL
SMPL 模型是一个裸体的3D 人体模型,具有N=6 890 个顶点和K=23 个关节。 由和两个参数来分别控制模型的体型和姿势。的维度为10,的维度|=3∗K+3 =72,每个关节对应一个三维旋转向量,外加一个全局旋转向量。 该过程可由如下公式进行描述:
其中,∈是SMPL 模型的平均模板,保持T-pose。 当和变化时,模型顶点会在的基础上发生偏移。 偏移量的大小由Bs和Bp函数计算得到;S表示一个3N∗的矩阵;P表示一个3N∗9K的矩阵;R表示罗德里格斯公式,将三维旋转向量变换为3∗3 的旋转矩阵。 关节点的三维坐标由式(3)计算得到:
其中,ℑ 表示一个(K+1)∗N的矩阵。进一步地,研究推得的数学公式可写为:
得到了TP(),J(),之后,SMPL 模型使用混合矩阵W作为权重,通过混合函数W得到最终的顶点。 式(4)中,混合矩阵W是N∗(K+1) 的矩阵,表示每个关节对每个顶点的影响。A(k) 表示前k个关节的集合。Gk(,J) 表示关节k相对于世界坐标系的变换,(,J) 表示关节k相对于Tpose 的变换。
2 本文方法
2.1 算法流程
本文提出的基于SMPL 的人物视频生成算法主要包括3 个模块,分别是:视频前后景分割模块、NERF 三维重建模块、以及SMPL 参数预测模块。算法整体流程如图1 所示。
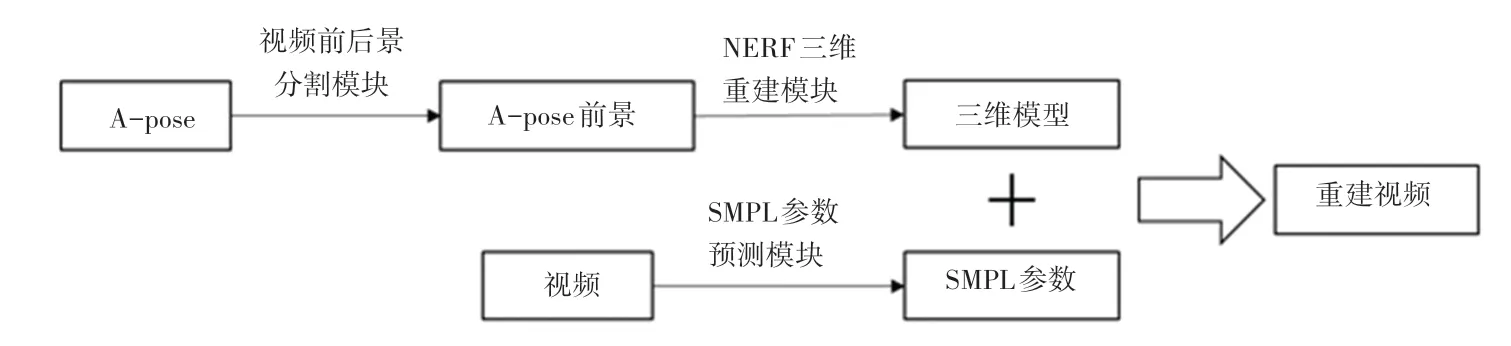
图1 算法流程图Fig. 1 Overview of the method
算法首先需要对视频中的人物完成三维建模。使用单目摄像头固定好拍摄位置,拍摄一段目标人物保持A-pose,原地360°旋转的视频,如图2 所示。为了不让背景影响三维重建的过程,使用视频前后景分割模块[16]将目标人物作为前景提取出来,然后送入NERF 训练得到三维模型。

图2 A-pose 示意图Fig. 2 A-pose explanation
有了目标人物的三维模型,要生成人物视频,还需要获得一组SMPL 模型参数作为运动信息。SMPL 参数由SMPL 参数预测模块VIBE[15]从一段视频中提取。
2.2 人物三维重建
2.2.1 三维坐标转换
NERF 三维重建模块需要将A-pose 图像序列转化为相应的三维模型,详见图2。 由于在A-pose获取的过程中,需要人物在原地360°转圈。 在没有特殊设备的情况下,人的姿态不可避免地会有改变。而NERF 适用于静态场景的重建,人物姿态的变化会导致重建质量的下降。
为此,本文将图像中人物不同姿态所对应的3D空间坐标使用SMPL 模型统一变换为SMPL 平均模板中的姿态T-pose,如图3 所示。 接着,再使用NERF 进行重建。 在式(4)基础上,继而可推得:

图3 A-pose 到T-pose 的空间坐标转换示意图Fig. 3 Coordinate transformation from A-pose to T-pose
空间坐标变换方法参考文献[10],见式(6):
其中,v表示SMPL 模型顶点,bs,i和bp,i分别是顶点i的体型函数以及姿势函数。 式(6)的左边是T-pose 的人物顶点坐标,右边的是A-pose 的人物顶点坐标。
2.2.2 三维重建模块整体结构与损失函数
去除背景的A-pose 作为输入,经过SMPL 参数预测模块后得到弱透视相机参数以及SMPL 参数。根据相机参数进行采样。 以相机为起点发射射线,射线的方向穿过每个像素的中心。 在视频前后景分割时可以得到人物的轮廓掩膜,只有在轮廓内部的射线才得到保留。 另外,根据SMPL 模型的顶点信息可以得到一个包围3D 人体的立方体。 三维重建模块整体结构如图4 所示。 假如射线和立方体有两个交点,则在该条射线与立方体的2 个交点之间在三维空间中进行采样。 NERF 的采样分2 次,第一次粗略采样,第二次在粗略采样的基础上再进行一次精细采样。 2 次采样经过体渲染(volume rendering)后会得到2 个重建的A-pose 前景。 计算其与输入的A-pose 的前景的MSE并相加就能得到重建损失,数学定义见下式:

图4 三维重建模块整体结构图Fig. 4 Overview of the 3D reconstruction module
3 实验结果与分析
3.1 数据集
研究使用了 IPER[17]数据集以及 people sanpshot[10]数据集进行实验。 people snapshot 包含12 个人物,24 段视频。 IPER 数据集包含30 个人物,206 段视频,视频长度从218 到3 629 帧不等。平均每个视频的长度为1 172 帧。
3.2 算法结果
图5~图7 是本文模型的效果图。 图5 中,第一行是原始视频,第二行是从视频中提取的SMPL 参数渲染得到的,第三行和第四行则是根据SMPL 参数,使用预训练的NERF 三维模型重建得到的结果。图6 修改了相机模型的参数,改变了重建视频的视角。 图7 则修改了人物的体型。

图7 改变体型Fig. 7 Change shape
3.3 算法对比
效果对比如图8 所示,文中将提出的模型与Vid2Vid[1]以及FOMM[5]算法进行了比较。 Vid2Vid和FOMM 都是基于GAN 的深度学习压缩方法,使用二维平面的运动信息配合关键帧进行重建。 可以看到当人体各个部分之间存在重叠的时候,二维平面的运动信息并不足以精确区分人体的各个部分。而本文所提的模型基于三维模型SMPL,即使人体的各个部分存在重叠,依旧能够保证重建的效果。

图8 效果对比Fig. 8 Comparison of the results
4 结束语
本文提出了一种基于SMPL 的人物视频生成算法。 首先,由人物2D 图像重建出人物3D 模型获取外观信息。 然后,从视频中估计SMPL 模型参数获取人物3D 运动信息。 最后,将人物外观信息与运动信息相结合生成人物视频。 算法将人物视频生成从2D 扩展到了3D。 实现多视角人物视频生成的同时,可以修改SMPL 模型参数实现人物体型的改变。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
中等数学(2021年9期)2021-11-22
软件(2020年3期)2020-04-20
山东科学(2018年6期)2018-12-20
光学精密工程(2016年6期)2016-11-07
腹腔镜外科杂志(2016年12期)2016-06-01
中国医疗美容(2015年1期)2015-07-12
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
