
融合双残差密集与注意力机制的视网膜血管分割
2023-08-24 06:47徐艳,张乾
智能计算机与应用 2023年7期
徐 艳, 张 乾
(1 贵州民族大学数据科学与信息工程学院, 贵阳 550025; 2 贵州民族大学贵州省模式识别与智能系统重点实验室,贵阳 550025; 3 贵州民族大学教务处, 贵阳 550025)
0 引 言
视网膜血管结构的变化可以辨别多种疾病。 例如,糖尿病视网膜病变是糖尿病引起的并发症,可以通过视网膜血管结构的改变来诊断。 糖尿病视网膜病变有可能导致失明,这意味着早期发现至关重要。高血压性视网膜病变是另一种由高血压引起的视网膜疾病,高血压患者可通过血管弯曲度增加或狭窄来诊断,因此,在现有医疗条件下某些疾病可以通过疾病变化来进行检测和诊断。
视网膜血管的分割是目前视网膜图像分析任务中特别重要的一步。 但人工视网膜血管分割是比较耗时的过程,为了解决这一问题,研究学者提出了许多自动分割的方法。 2015 年,Ronneberger 等学者[1]提出了一种两边完全对称的U-Net 分割网络模型。该方法通过通道拼接融合的方法来获取特征,并未能最大限度地发挥以往特征图重用的潜力。 付顺兵等学者[2]提出了一种融合U-Net 网络和密集网络的分割方法,该网络将密集网络和U-Net 进行融合,同时在卷积层之间引入一种动态激活函数,从而提高网络的特征表达能力。 胡扬涛等学者[3]提出了一种基于U 型的空洞残差U 型网络(Atrous Residual U-Net,AR-Unet),该网络有效避免了网络中梯度消失和信息丢失的问题。 王师玮等学者[4]提出了一种在U-Net 基础上进行改进的CSDUNet,该算法在编码器与解码器部分使用了卷积注意力模块,采用密集上采样卷积作为上采样方法,在分割效果上有一定的提升。
综上所述,以上的算法虽然能提升视网膜血管分割的精度,但存在视网膜血管分割出现细小血管不易分割和断裂的现象,图的对比度低且容易与背景混淆等情况。 因此本文提出一种融合残差密集块与注意力机制的视网膜血管分割算法,该方法以UNet 网络作为基础框架,融合高效通道注意力机制模块(ECA)、密集连接块(Dense Block)和双残差模块(Double Residual Block)来提取特征,为了提取到更多细小血管,使用空洞卷积替换标准卷积来增大感受野,从而提高视网膜血管分割的精度。
1 相关工作
1.1 网络结构
本文针对视网膜血管分割任务,提出一种融合双残差密集与注意力机制的视网膜血管分割算法,整体框架如图1 所示,采用高效通道注意力机制、密集连接模块和双残差块来优化网络结构,使用空洞卷积替换标准卷积,在不增加参数的情况下来增大感受野,以此来获取视网膜血管图像更复杂的特征。 U-Net通过“通道拼接”使之前的特征映射可重用并有效地解决空间信息丢失的问题。 本文为了更好地发挥特征映射重用的潜力,通过自适应聚合块来重用特征。并将双残差密集块的特征映射被自适应地聚合到后续层中作为输入,设置当前的通道数量不变,直到下一步加倍。 同时为了防止过拟合问题,该网络模型引入了DropBlock[5]来更有效地规范网络结构。

图1 双残差密集与注意力网络Fig. 1 Double residual density and attention network
1.2 高效通道注意力模块
注意力机制可用来提高特征选择能力,最早使用在自然语言处理领域[6]。 Wang 等学者[7]在压缩激励(squeeze-and-excitation,SE)模块的基础上,提出了一种高效通道注意力(Effificient Channel Attention,ECA)模块。 高效通道模块如图2 所示。 ECA 模块避免了降维,能够有效捕获跨通道交互的信息,涉及少量参数,同时带来明显的性能增益,也可以保证信息效率和有效性。 ECA 模块是通过一维卷积layers.Conv1D 来完成跨通道间的信息交互,卷积核的大小通过一个函数来适应变化,使得通道数较大的层可以更多地进行跨通道交互。 自适应函数为:

图2 高效通道注意模块Fig. 2 High Efficiency Channel Attention(ECA) module
ECA 模块实现如下:
(1)输入特征图经过全局平均池化, 从[h,w,c] 的矩阵变成[1,1,c] 的向量。
(2)根据特征图的通道数计算得到自适应的一维卷积核大小kernel_size。
(3)将kernel_size用于一维卷积中,得到对于特征图的每个通道的权重。
(4)将归一化权重和原输入特征图逐通道相乘,生成加权后的特征图。
1.3 空洞卷积
在编码器与解码器中使用空洞卷积替换标准卷积,即在编码器和解码器之间布置捕获全局上下文的空洞卷积块[8],在不丢失眼底视网膜血管图像分辨率的情况下增大感受野。 标准卷积和空洞卷积原理如图3 所示。

图3 标准卷积和空洞卷积Fig. 3 Standard convolution and cavity convolution
1.4 双残差密集连接块
在卷积神经网络中,在训练过程中由于梯度消失的问题,简单地增加网络层数可能会阻碍训练,为了解决这一问题,引入了Guo 等学者[9]所提的双残差块。 为了增加视网膜图像的底层信息,从而加强特征的传播能力,引入密集连接块。 结合残差块和密集连接块的优点,提出一个双残差密集连接块(DDRB),如图4 所示。 由图4 可知,双残差密集连接块主要包含BN 归一化、ReLU 激活、3×3 卷积层、DropBlock 和DenseBlock。

图4 双残差密集连接块Fig. 4 Double residual density connection block
1.5 自适应聚合块
在FCN[10]和U-Net[1]研究中,通过添加或连接操作来直接重用以前的特征映射。 为了更好地利用编码部分特征块的特征映射,Zhen 等学者[11]引入了自适应聚合结构。 类似地,本文使用改进的自适应聚合结构来紧密地连接前面的DDRB 块的特征。 自适应聚合块的结构如图5 所示。 由图5 可知,在双残差密集连接块中,来自较低层(DDRB1、DDRB2...)的特征映射具有高分辨率的粗语义信息,而来自较高层(DDRB3、DDRB4……)的特征映射具有低分辨率和包含精细的语义信息。 自适应聚合结构可以将前面所有的DDRB 特征映射融合在一起,生成丰富的空间信息和上下文信息。 由于输入的特征图,比例大小可能会所不同。 为了减少内存消耗,首先使用卷积层来压缩传入的特征映射,除了直接连接的特征映射(黑色箭头)已经被压缩。 压缩层由DropBlock 和1×1 的卷积组成。 为了使所有的特征图在大小上保持一致,将使用最大池化操作进行下采样,而使用转置卷积进行上采样。 最后,将所有生成的特征映射连接到这个块的输出中。
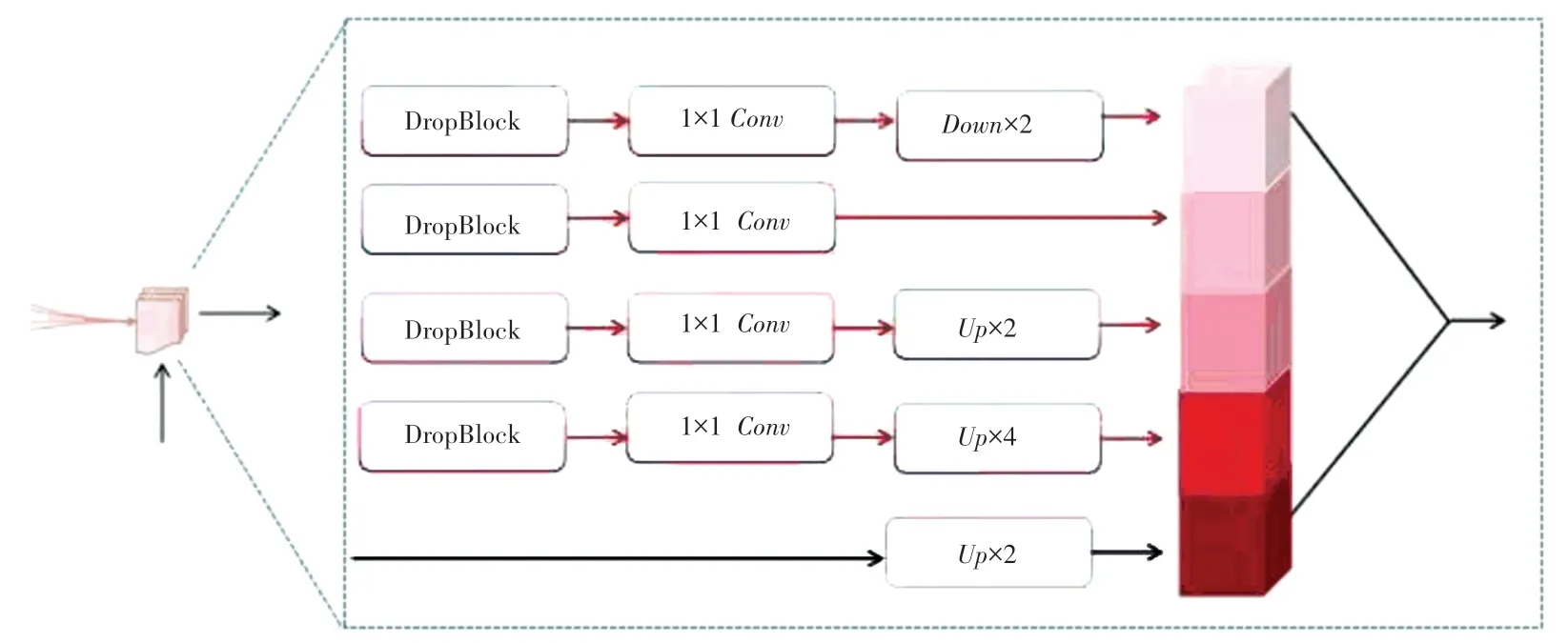
图5 自适应聚合块的结构Fig. 5 The structure of the adaptive polymer block
2 实验及结果分析
2.1 数据集和参数设置
本文使用了视网膜血管分割的2 个公开数据集:DRIVE[12]和STARE[13]数据集。 其中,DRIVE 数据集由40 幅565×584 分辨率的彩色视网膜图像组成,该数据集包含官方划分的20 幅训练集和20 幅测试集,每幅图像有其对应的金标准及掩膜。 STARE 数据集由20 幅700×605 分辨率的彩色视网膜图像组成,每幅图像有其对应的金标准及掩膜,由于该数据集没有划分训练集和测试集,自动划分前10 幅视网膜图像作为训练集,剩下的10 幅视网膜作为测试集。
由于官方公开的DRIVE 和STARE 数据集的图像较少,对DRIVE 和STARE 两个数据集进行数据增强处理,分别通过加入高斯噪声、随机旋转和颜色抖动等操作,DRIVE 和STARE 数据集从原始数据集分别扩增到256 幅和226 幅图像,且对DRIVE 和STARE 两个数据集原始像素进行剪裁,周围使用0进行填充,将DRIVE 和STARE 数据集分别从565×584 调整为592×592,从700×605 调整为704×704。
在训练过程中,将DRIVE 和STARE 数据集的batch_size设置分别为8 和4,总周期设置为50。Adam 作为优化器,学习率为0.000 1。所有的实验均使用后端带有Keras 开源框架进行,并在计算机配置为Intel(R) Core (TM) i7 - 12700F CPU @2.10 GHz,16.0 GB 内存,采用64 位Windows 10 操作系统上运行。
2.2 评价指标
视网膜血管分割问题可视为对所有像素进行二分类的问题,可以使用混淆矩阵来评估各种方法的性能。 混淆矩阵的参数见表1。

表1 混淆矩阵Tab. 1 Confusion matrix
本文采用准确率(accuracy,ACC)、 灵敏度(sensitivity,SE)、特异性(specificity,SP)、F1、ROC曲线下面积(AUC) 和Mattews相关系数(MCC) 可以由表1 的4 个参数计算可得,具体公式分别如下:
2.3 消融实验分析
为了验证评估模型改进前后的性能,在相同的实验环境下,以U-Net 网络为基线分别在DRIVE 和STARE 数据集上进行视网膜血管分割实验。 实验结果见表2。
从表2 中DRIVE 和STARE 数据集的实验结果可知,D1 表示原始的U-Net,D2 在D1 基础上加入双残差块,其ACC和SE都有大幅度的提升,整体效果较好,说明残差块能有效地获取特征。D3 在D2 基础上加入高效通道注意力机制,D3 相比较D2 的SE较低,但ACC和SP在2 个数据集上都有一定的提升。D4 在D3 基础上加入密集连接块,D4 与D3 相比,DRIVE 数据集的SE和STARE 数据集的SP有一定的提升,说明密集连接块能够特征重用,有效地重用了特征。D5 在D4 基础上,在编码器与解码器之间用空洞卷积替换标准卷积,其整体性能略有提升,除了SP外,其ACC、SE、AUC、F1 和MCC与D1 相比较均有大幅度提升,说明本文的算法在分割性能上有一定的提升。
DRIVE 和STARE 数据集分割结果如图6 所示。图6 中,前2 列是DRIVE 数据集,后2 列是STARE数据集。 由图6 可看到,D1 与D2 分割图中存在细小血管没有分割出来,D3 与D4 分割图中存在误分割和分割不连续的现象,D5 比D1 分割图在视网膜血管细节分割上效果更佳,与专家手动分割的标准图接近,说明本文算法分割效果好。

图6 DRIVE 和STARE 数据分割结果Fig. 6 Data segmentation results of DRIVE and STARE
DRIVE 和STARE 数据集局部分割结果如图7所示。 图7 中,前2 列是DRIVE 数据集,后2 列是STARE 数据集。 从图7 中分割图结果对比可知,D1与D2 局部分割图中出现误分割和有的细小血管没有被分割的现象,D3 与D4 局部分割图中呈现出血管断裂的情况,D5 与D1 局部分割图相比较,该模型分割的血管更加细腻、血管连续和完整性也较好,D5 局部分割图与金标准局部分割图接近,呈现出较好的分割效果。

图7 DRIVE 和STARE 数据集局部分割结果Fig. 7 Local segmentation results of DRIVE and STARE data sets
2.4 不同分割算法之间的对比
表3 为不同算法在DRIVE 与STARE 数据集上视网膜血管分割不同性能指标对比。 本文算法在DRIVE 与STARE 数据集上的准确率(ACC)、灵敏度(SE)、特异性(SP) 和AUC分别为:96.85%、81.48%、98.33%、98.61%和97.84%、88.51%、98.60%、99.45%。其中,DRIVE 数据集的准确率(ACC) 和AUC均高于其他文献算法,STARE 数据集除特异性(SP) 略低于文献[14] 算法,准确率(ACC)、灵敏度(SP) 和AUC与其他算法相比均有所提升。

表3 不同算法对比Tab. 3 Comparison of different algorithms
本文的DRIVE 与STARE 数据集的ROC曲线如图8 所示。 由图8 可看到,当ROC值接近1 时,能够对血管像素和背景像素进行正确分类,说明模型对视网膜血管分割效果较好。

图8 在DRIVE 与STARE 数据集上的ROC 曲线图Fig. 8 ROC graph on DRIVE and STARE data sets
3 结束语
本文针对视网膜血管的微小血管不易分割和断裂等情况,提出了一种双残差密集与注意力网络用于视网膜血管分割,通过自适应聚合结构将前面的双残差密集块的特征进行压缩后传输到后续层中作为输入,使用自适应聚合块代替传统的通道拼接来实现特征重用,有效地解决视网膜图像分割特征和信息损失的问题,在编码器与解码器之间利用空洞卷积替换标准卷积来增大感受野,可以有效提取视网膜细小血管的特征。 通过实验证明,该网络模型在DRIVE 和STARE 数据集上都呈现出较好的分割效果,说明该网络模型有较好的分割性能。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年9期)2021-11-26
英语文摘(2021年2期)2021-07-22
中医眼耳鼻喉杂志(2021年1期)2021-07-22
中医眼耳鼻喉杂志(2021年2期)2021-07-21
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子测试(2018年4期)2018-05-09
湖南中医药大学学报(2016年1期)2016-12-01
