
基于多特征融合注意力的人脸口罩识别算法
2023-08-24 06:47:48安鹤男邓武才杨佳洲
智能计算机与应用 2023年7期
安鹤男, 马 超, 管 聪, 邓武才, 杨佳洲
(1 深圳大学电子与信息工程学院, 广东 深圳 518060; 2 深圳大学微纳光电子学研究院, 广东 深圳 518060)
0 引 言
目标检测是计算机视觉和数字图像处理的一个热门方向,不仅在监控安全、自动驾驶、工业检测、无人机场景分析等诸多领域[1-2]取得可观进展,目前也已尝试应用在口罩佩戴检测的项目及实践中[3]。该研究利用计算机视觉技术,旨在检测静止图像或视频中感兴趣的对象,对于降低人力资源成本具有重要的现实意义。 具体来说,就是要识别物体属于哪个类别,更重要的是获得物体在图像中的具体位置,也可以理解为物体识别和物体定位的结合。 传统的目标检测算法分别进行特征提取和分类判断,对特征选择的要求就更加严格,在面对复杂场景的时候很难得到理想效果。 研究可知,时下最先进的物体检测器利用深度学习网络作为其骨干和检测网络,分别从输入图像或视频中提取特征,进行分类和定位。 近几年来,随着卷积神经网络(convolute⁃ion neural networks, CNN)的不断发展,目标检测算法取得了很大的突破。 目前主流的算法可以分为2类。 一类是Two-stage 网络基于Region Proposal 的R-CNN 系列算法,如R-CNN、Fast R-CNN 和Faster R-CNN 等[4-5],这类检测算法将检测问题划分为2个阶段。 第一个阶段首先产生候选区域,包含目标大概的位置信息,需要先运算产生目标候选框;在第二个阶段对候选区域进行分类和位置精修。 Twostage 网络识别准确率高,漏识率低,但速度较慢,不能满足实时检测。 针对这一问题,不久又研发出另一类方法,称为One-stage,这类检测算法不需要Region Proposal 阶段,可以通过一个CNN 直接产生物体的类别概率和位置坐标值,已经提出的代表性算法有:YOLO、RetinaNet、SSD 等[6-7],均可到达实时性要求。 其中,RetinaNet 算法核心就是Focal Loss,并在精度上超过Two-stage 网络的精度,在速度上超过One-stage 网络的速度,首次实现单阶段网络对双阶段网络的全面超越。 近年来,对于RetinaNet 网络的研究不断趋于深入,例如李成豪等学者{8}对小目标检测提出的S-RetinaNet 算法,周迎峰等学者[9]提出了基于RetinaNet 改进的海洋鱼类检测算法,由此可见RetinaNet 算法在实际中已得到了广泛应用,但并不适用于直接检测公共场景下的口罩佩戴情况,仍然存在一些不足,亟待改进。
1 原理
RetinaNet 网络如图1 所示。 本次研究深入分析了极度不平衡的正负样本比例导致单阶段检测器精度低于双阶段检测器,基于上述分析,提出了一种简单、但是非常实用的交叉熵损失函数,骨干网络为ResNet-50,特征金字塔模块接收3 个特征图,输出5个特征图,通道数都是256,步长为8、16、32、64、128,其中大步长用于检测大物体,小步长用于检测小物体。 检测头模块包括分类和位置检测两个分支,每个分支都包括4 个卷积层,但是检测头模块的这2 个分支之间参数不共享,分类输出通道是类别数;检测输出通道是anchor 个数,虽然分类和回归分支权重不共享,但是5 个输出特征图的检测头模块权重是共享的。 目前存在的不足主要有以下2 点:
(1)网络较低层级的特征层需要同时学习局部信息和高层全局信息,这种双重学习任务加大了网络训练的复杂度,进而影响检测精度。
(2)利用较低层级的检测小目标的策略完成多种尺度的目标检测,但一般情况下,深度学习神经网络中的较低层特征图能够提取充分的细节特征,但语义信息却不够丰富,反之较深的特征图包含较少的细节特征,却会造成较差的检测结果。
2 方法与改进
本文根据以上不足以及针对特征融合能力的优化做出以下改进, 基于ResNet - 50 骨干网络(backbone network)引入空间金字塔池化(Spatial Pyramid Pooling, SPP)[10]结构,利用空间金字塔池化将网络局部信息和高层信息两种学习任务加以区分,从而实现高效的目标特征学习;结合原网络多尺度特征融合想法,重新设计了PSA(Path Aggregation Strengthen Integration ANN Attention)模块,整合链路结合多尺度特征加强融合模块,先提取丰富的局部特征,再利用自上而下和自下而上的特征融合方式将局部特征和全局特征进行融合,进一步实现特征的充分利用;采用能力更强的GFocal Loss交叉熵损失函数;根据高斯误差线性激活函数(Gaussian Error Linerar Units, GELUs)[11],重做预测模块避免梯度爆炸,最终提出了针对人脸口罩识别的多特征融合注意力PSA-Retina 人脸口罩识别网络,整体结构如图2 所示。

图2 PSA-Retina 口罩检测网络整体结构图Fig. 2 The overall structure of the PSA-Retina mask detection network
2.1 PSA 模块
PSA 多尺度特征融合模块主要分为2 个子模块:整合链路模块和注意力融合模块。
整合链路模块首先要把4 层特征的尺寸调整,P3直接作为M3,再通过2 倍下采样操作与P4相加,通过核为3 的卷积后得到M4,M5同理为M4和P5计算得到,M6则为P6直接输出,得到256 通道的特征图。 因为底层特征分辨率较高,所以专注于细节特征的学习,顶层特征分辨率较低,总是专注于语义特征的学习。 为了平衡该特性,并对特征做进一步融合,采用求和均值来计算,就是先将4 层特征中的M3进行下采样,M5、M6进行上采样,保持与中间层次M4特征图的尺寸相一致,再进行融合处理,综上方法的数学公式见如下:
其中,L表示特征层的层数。
注意力模块将进一步处理融合后的特征图,使得特征更加有辨别力,引入Asymmetric Non-local 注意力机制公式见如下:
其中,N,M特征图尺寸一致;i为输入特征图内某个元素的方位信息;j为所有可能方位信息的索引;g为信息变换函数;卷积核为1;通过f函数计算第i例方位信息和其余全部方位信息的匹配性,是注意力匹配函数。 用匹配计算融合后的特征图直接输出为N4,融合后的特征图再通过上采样的方法算出N3,融合后的特征图再通过下采样的方法算出N5和N6。 共输出4 层特征N3、N4、N5、N6,最终与M层特征图来计算求和,如图3 所示,不同阶段的多尺度特征信息经过整合链路模块进行了有效的增强融合。

图3 PSA 多尺度特征融合注意力模块Fig. 3 PSA multi-scale feature fusion attention module
2.2 特征提取模块
骨干网络负责计算获得特征图,在ResNet-50网络第一个预测特征层中引入空间金字塔池化(Spatial Pyramid Pooling, SPP)结构如图4、图5 所示,得到表达力更强、包含多尺度目标区域信息的卷积特征图。 首先,使用卷积操作将输入进来的特征处理3 次;随后,在池化层中,对于5、9、13 三种不同尺寸的池化核、步距为1,分别进行最大池化下采样操作。 将处理得到的特征图通过SPP 进行拼接后,接下来将经过3 次卷积操作,就可得到不同尺度的特征融合的输出特征图。

图4 骨干网络结构图Fig. 4 Backbone network structure diagram

图5 空间金字塔池化网络结构图Fig. 5 Spatial pyramid pooling network structure diagram
2.3 预测器
改进预测器结构如图6 所示。 考虑通过加入正则化来提高泛化能力而避免过拟合,但是仍然存在梯度爆炸问题。 为解决这一问题引入GELUs函数,其依据中心极限定理,大量独立随机变量的总体是服从近似正态分布的,现实中有很多复杂人脸口罩情况可以被建模成近似正态分布,使用类正态分布函数作为激活函数就更加合理,而且在具有相同方差的所有可能的分布中,正态分布具有最大不确定性、即熵最大。 本文中,将Class Subnet 和Box Subnet 中的8 个3×3 的卷积层后的加入GELUs函数。
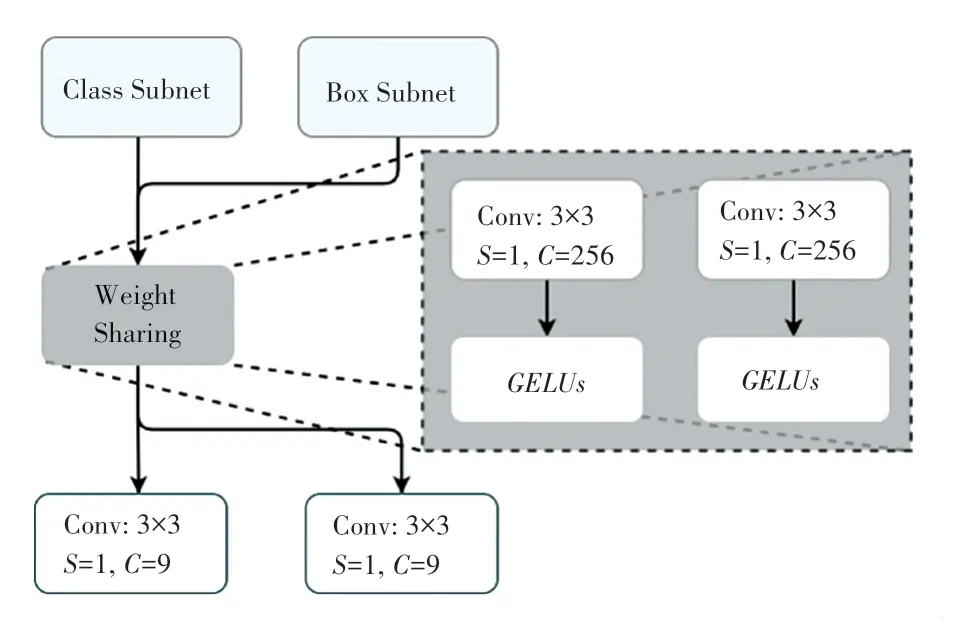
图6 改进预测器结构图Fig. 6 Structure of the improved predictor
2.4 损失函数
GFocal Loss交叉熵损失函数能够有效判断真实检测框与预测检测框之间的重合度,解决了正负样本不匹配问题,进行梯度回传。 为了保证训练和测试一致,同时还能够兼顾分类分数和质量预测分数都能够训练到所有的正负样本。GFocal Loss将两者的表示进行联合,保留分类的向量,对应类别位置的置信度改为质量预测的分数,用离散化的方式直接回归一个任意分布来做建模框的表示,这里涉及到的数学公式为:
其中,y为标签,β为超参。 从物理上来讲,依然还是保留分类的向量,但是对应类别位置的置信度的物理含义不再是分类的分数,而是改为质量预测的分数。 由δ分布转为通用分布的形式:
离散化后,可得:
为了尽快拟合到真实分布,使用DFL。 研究推得的数学公式如下:
其中,y0到yn为积分区域;y为标签点;Si为激活函数后的结果;yi以及yi+1为靠近真实位置的左右邻近。 在此基础上,研究推得:
QFL和DFL的作用是正交的,两者的增益互不影响,可以统一地表示为GFL。 式(7)中,y为0~1的质量标签;QFL的全局最小解即是δ=y,实验中发现一般取β=2 为最优。
3 实验分析
3.1 训练配置
训练所使用的服务器配置见表1。 本文使用SSD、RetinaNet、YOLOv3 和PSA-Retina 网络在同一数据集上历经相同参数的训练后进行比较,评价指标为平均精度(Average Precision,AP)、平均精度均值(mean Average Precision,mAP) 和每秒传输帧数(Frames Per Second,FPS)。

表1 服务器环境和参数Tab. 1 Server configuration and environment
3.2 训练数据集
武汉大学国家多媒体软件工程技术研究中心制作的RMFD 数据集结合本次研究中经网络下载整理清洗和标注处理的真实口罩人脸识别数据集,该数据集包含6 000 张口罩人脸和91 000 张不戴口罩人脸,挑选其中5 000 张戴口罩,5 000 张不戴口罩、总共10 000 张图片,并将该数据集的60%用作训练集,40%用作测试集。 基于平均检测精度、平均精度均值及运行帧率评价指标,将提出的PSA-Retina 网络进行实验和评估,设置IoU为0.4,所有模型训练批尺寸设置为8,初始学习率设置为0.000 1,训练200 个周期。
3.3 实验结果与分析
不同网络实验结果见表2。 基于多特征融合的PSA-Retina 网络对戴口罩的AP值达到87.21%,对未佩戴口罩的AP值达到83.05%,检测器的mAP值达到85.13%,FPS值达到33.7 f/s。 本文提出的网络要比SSD、RetinaNet、YOLOv3 网络的检测精度均高出3%以上,且检测速度也表现最优,说明本网络结构更适用于口罩的识别检测。
将训练后的网络在测试集上进行测试,获得了召回率-精确度(P -R) 曲线如图7 所示。 图7 中,曲线下围成的面积即为平均检测精度AP。

图7 检测召回率-精度曲线图Fig. 7 Detection Recall-Precision plot
为更加直观地感受PSA-Retina 网络对口罩识别的有效性,图8 展示了SSD 网络、RetinaNet 原网络、YOLOv3 网络、改进的PSA-Retina 网络在人脸口罩数据集的检测效果对比结果,其中置信度阈值设置为0.4,非极大值抑制NMS阈值设为0.45。 由对比结果可以看出,SSD 网络对小目标的检测效果并不好;RetinaNet 网络相比SSD 略有提升,但是容易漏检,有些很明显的目标反而没有被检测到;YOLOv3 网络效果较好,但仍然有漏框出现;本文提出的算法对小目标和遮挡都表现出良好的效果,绝大部分漏检、错检情况都被修复,更加适合实际应用中高检测精度的需求。

图8 不同网络检测效果对比图Fig. 8 Comparison chart of different network detection effects
4 结束语
本文根据ResNet-50和SPP 空间金字塔结构的优缺点,基于整合链路网络和注意力融合网络的特性改进得到了PSA 模块,并将其融入到RetinaNet中,同时改进预测器的GELUs激活函数以避免梯度爆炸,进一步结合GFocal Loss损失函数,最终提出了一个全新的适用于口罩识别的PSA-Retina 检测网络。 实验结果表明,PSA-Retina 网络能够有效检测人脸戴口罩和未戴口罩情况,平均检测精度达到85.13%,运行帧率为33.7 f/s,且非口罩物体遮挡嘴部情况下,该网络对于检测人脸未戴口罩情形也能同样进行高效识别,在公共场景下的口罩检测也取得了显著效果,证明了该网络在检测口罩上的有效性和优越性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
意林(2020年9期)2020-06-01 07:26:22
海峡姐妹(2020年4期)2020-05-30 13:00:08
电子制作(2019年11期)2019-07-04 00:34:38
作文大王·笑话大王(2019年3期)2019-04-22 23:58:02
电子制作(2018年11期)2018-08-04 03:25:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
作文评点报·低幼版(2017年8期)2017-03-11 20:44:08
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
