
结合双预训练语言模型的中文文本分类模型
2023-08-24 06:47原明君江开忠
智能计算机与应用 2023年7期
原明君, 江开忠
(上海工程技术大学数理与统计学院, 上海 201620)
0 引 言
文本分类是根据文本所蕴含的信息将其映射到预先定义的带主题标签的2 个或几个类的过程,同时也是信息检索与数据挖掘的基础。 文本分类通常包括特征表示、特征提取和分类三个主要步骤。 特征表示是文本分类任务的首要阶段,也是文本分类的基础。 Mikolov 等学者[1]和Pennington 等学者[2]分别提出 Word2Vec 模型、 全局向量(Global Vectors, GloVe)对文本特征进行表示。 袁磊[3]和宋呈祥等学者[4]使用了改进的CHI 特征选择方法对文本进行分析,但在模型训练时,存在利用文本上下文信息范围有限等问题。
为了改进文本信息表示不准确等问题, Devlin 等学者[5]和Yang 等学者[6]分别提出基于Transformers 的双向编码预训练语言模型(Bidirectional Encoder Representations from Transformers, BERT)和广义自回归预训练语言模型(Generalized Autoregressive Pretraining for Language Understanding,XLNet),进一步提升了词向量分类模型的性能。
1 相关工作
随着深度学习的发展,深度学习模型被用于不同场景的文本分类任务中。 Adhikari 等学者[7]在BiLSTM模型中设置正则化等步骤,陈立潮等学者[8]通过改造传统的BiLSTM 模型,加入对抗训练等步骤,都达到了较好的文本分类效果。 杨青等学者[9]将注意力机制与BiGRU 相结合,提出FFA-BiAGRU 文本分类模型,进一步提高了文本分类的准确性。
孙红等学者[10]用BERT 训练词向量,通过BiGRU 融合注意力机制进行特征提取,有效提高了模型分类的准确率。 梁淑蓉等学者[11]通过XLNet获取词向量,利用LSTM 结合注意力机制进行文本情感分析,进一步提高了模型分类预测的准确性。
通过对已有方法的深入学习,本文将预训练语言模型与BiLSTM、自注意力机制、层归一化相结合,提出了一种结合自编码和广义自回归预训练语言模型的DPT-BRNN(Dual Pre-trained-Bi-directional Recurrent Neural Network)文本分类模型。 该模型综合考虑了不同词向量表达的优劣,分别通过XLNet、BERT 来构建输入文本的动态语义词向量,并将其作为新的特征向量分别输入BiLSTM 提取文本隐藏特征,获取语义间上下文依赖关系,同时与自注意力机制和层归一化连接,使文本分类的权重分配更加合理,从而提高文本分类效果。
2 结合双预训练语言模型的中文文本分类模型的构建
目前现有的主流预训练语言模型分为自回归语言模型(Auto Regression Language Model, AR)和自编码语言模型(Auto Encoding Language Model,AE)。 其中,AR 模型主要用于评估文本的概率分布,该模型为单向模型;AE 模型为双向模型,可以学习到文本的上下文深层语义信息。
BERT 作为AE 模型的典型成功案例,XLNet 作为改进的AR 模型,本文将这2 个模型应用到DPTBRNN 文本分类模型中,其模型结构如图1 所示。该模型由2 个通道组成。 第一个通道通过XLNet 对文本数据进行语义特征提取,构建基于词向量的特征表示;第二个通道使用BERT 预训练语言模型,获取文本整体信息的词向量,然后将新特征输入BiLSTM 以获取上下文语义表示。 两通道都引入自注意力机制层和层归一化捕获文本的特征信息,最终将双通道的文本特征信息进行融合,输入输出层达到文本分类的目的。

图1 DPT-BRNN 文本分类模型Fig. 1 DPT-BRNN text classification model
2.1 广义自回归语言模型
广义自回归语言模型(XLNet)提出的排列语言模型(Permutation Language Model, PLM)解决了传统自回归语言模型无法根据上下文预测结果的问题。 假设当前输入句子的单词构成为[x1,x2,x3,x4,x5],若要预测单词x3,使用PLM 随机打乱单词排列顺序,依次运用自回归方法预测x3。 PLM 部分概览图如图2 所示。

图2 排列语言模型部分概览图Fig. 2 Partial overview diagram of Permutation Language Model
为实现排列语言模型的基本思想。 XLNet 采用基于目标感知表征的双流自注意力掩码机制,即内容流自注意力(Content Stream Attention)和查询流自注意力(Query Stream Attention)。 同时,模型利用改进的注意力掩码(Attention Mask)使模型读取上下文信息。 双流自注意力计算流程如图3、图4 所示。

图3 查询流自注意力计算Fig. 3 Query stream attention calculation

图4 内容流自注意力计算Fig. 4 Content stream attention calculation
图3 、图4 中,g表示各单词的位置信息,h表示各单词的内容信息,g3(0)为被预测词、即x3的位置信息。
XLNet 还应用到了Transformer-XL 中的片段循环机制(Recurrence Mechanism)和相对位置编码(Relative Positional Encoding)。 片段循环机制以分段的形式进行建模,文本序列引入循环机制后实现隐藏层信息循环传递的方式如图5 所示。

图5 片段循环机制信息传递Fig. 5 Recurrence mechanism information transmission
由图5 可知,在对每个序列进行处理时,隐藏层从2 个部分进行学习。 一个是当前序列前面节点的输出,即图5 中每个序列的虚线部分;另一个是当前序列之前序列节点的输出,即图5 中实线部分。
2.2 自编码语言模型
自编码语言模型(BERT)模型体系结构主要由多层Transformer 模型结构组成,模型通过注意力机制将任意2 个位置的单词距离转换为1,有效地解决了NLP 任务中出现的长期依赖问题。 BERT 使用双向Transformer 网络架构中的编码器(Encoder)搭建整个模型框架,同时,其模型框架由多层的Transformer 模型结构组成,研究得出的网络结构模型如图6 所示。

图6 BERT 网络结构模型Fig. 6 BERT network structure model
模型结构中的字向量E1、E2、…、EN不仅包含当前文本的字符级向量(Token Embedding),而且也包括了每个字的位置向量(Position Embedding)和分段向量(Segment Embedding)。 模型将3 个向量相加求和之后,分别在文本的开头和结尾加上CLS和SEP 的标记符号,然后输入双向Transformer 编码器中,完成对每个字的双向编码表示。
2.3 BiLSTM +Attention
LSTM 由t时刻的输入向量xt、单元状态ct、临时单元状态~ct、隐层状态ht、遗忘门的节点操作ft、输入门it和输出门ot组成。 模型t时刻整个过程的计算方法公式具体如下:
虽然LSTM 模型能够很好地捕捉较长距离的文本依赖关系,但仍无法学习文本从后向前的语义信息。 因此,本文使用BiLSTM 模型学习上下文双向的语义信息,同时在BiLSTM 层之后加入自注意力机制层对词语权重进行重新分配。 BiLSTM 结合自注意力机制的模型结构如图7 所示。

图7 BiLSTM-Attention 模型图Fig. 7 BiLSTM-Attention model diagram
由图7 可知,将BiLSTM 模型中的最后一个时序的输出向量ht作为输入自注意力层的特征向量,其计算过程数学公式见如下:
其中,ut为ht的自注意力隐层表示;Ws为权值矩阵;bs为偏置项;αt为ut通过Softmax函数后得到的整个序列的归一化权值。
2.4 归一化机制
为了提高模型的学习能力和表达能力,模型加入层归一化(Layer Normalization)机制对上层输出向量进行归一化处理。 具体操作为根据以下公式将模型某一层所有神经元输入进行处理:
其中,μl、σl分别表示模型各层神经元的均值和方差统计量;H表示模型各层神经元的节点数;表示模型第l隐藏层的输出;y表示模型上层输出经过归一化处理后的输出值;g和b分别表示对输入向量的缩放和平移。
将归一化后的数据进行非线性激活函数运算,即:
2.5 输出层
模型将文本序列经过XLNet 通道和BERT 通道后的特征向量进行融合,输入全连接层, 然后利用Softmax分类器完成对文本内容的分类。Softmax分类器输出类别分类概率的计算公式为:
其中,P表示文本x分类至类别j的概率数值,θ表示模型训练的参数。
3 实验结果与分析
3.1 实验环境与数据
本文的实验环境见表1。

表1 实验环境设置Tab. 1 Setup of experimental environment
本文选取THUCNews 新闻数据集、搜狐新闻标题数据集[12]以及微博数据集,共3 个文本数据集测试DPT - BRNN 文本分类模型的分类效果。THUCNews 新闻数据集由清华大学提供并公开,包含财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐共10 个类别新闻数据。 搜狐新闻标题数据集由搜狗实验室提供,包括财经、健康、教育、军事、科技、汽车、时尚、体育、文化、娱乐共10 个类别新闻数据。 微博数据集来源于新浪微博评论,其中包含时政、社会、财经三个类别新闻数据。
本文将3 个新闻文本数据集随机分为训练集、测试集和验证集,数据集概况见表2。

表2 数据集统计表Tab. 2 Statistical table of datasets
3.2 模型参数设置
本文XLNet 采用哈工大讯飞联合实验室发布的xlnet-base-cased[13]模型,BERT 采用Google 发布的预训练模型进行文本表示,Word2Vec 词向量使用Skip-Gram 模型训练,得到维度为300 维的词向量。模型的参数设置见表3、表4。

表3 预训练模型参数Tab. 3 Parameters of pre-trained models

表4 模型参数设置Tab. 4 Setup of model parameters
3.3 评价指标
大多数分类模型的评估标准是: 准确率(Accuracy)、精确率(Precision)、F1值(F -measure)以及召回率(Recall)。 相关的混淆矩阵结构见表5。

表5 混淆矩阵Tab. 5 Confusion matrix
其中,准确率表示正确预测的样本相对于所有分类样本的比重,计算公式如下:
精确率是指预测结果为正例的样本中,被正确预测为正样本的比例,计算公式如下:
召回率表示正确预测结果为正样本占全样本中实际正样本的比重,计算公式如下:
F1是精确率和召回率的加权平均,计算公式如下:
3.4 实验与分析
3.4.1 与预训练词向量模型的对比
与预训练词向量模型的对比实验结果见表6。由实验结果可以看出,相较于使用2 种单一的预训练词向量模型,同时使用XLNet 和BERT 的模型分类效果有所提升。 本文模型在3 个实验数据集上都取得了较好的分类效果,准确率分别达到了83.68%、79.41%和98.72%;BERT-全连接模型在3个数据集上的准确率分别为81.02%、78.02%和96.43%;XLNet-全连接模型在3 个数据集上的准确率分别为82.28%、78.40%和97.39%。 本文模型设置双通道,在每个通道中分别使用XLNet 和BERT预训练模型,同时又将预训练模型向量输入BiLSTM、BiGRU 模型,并通过自注意力机制获取局部特征,归一化加速模型训练速度,最终将两通道输出信息进行拼接,从而使模型学习到充足的文本特征信息,并获得更加丰富的文本特征,同时又提高了模型的训练精度。 因此,无论准确率、还是F1值,本文模型均优于其它模型。 其中,本文模型较BERT-全连接模型准确率在3 个数据集上分别提高了2.66%、1.39%和2.29%,较XLNet-全连接模型准确率在3 个数据集上分别提高了1.40%、1.01%和1.33%,证明了本文模型的分类有效性。
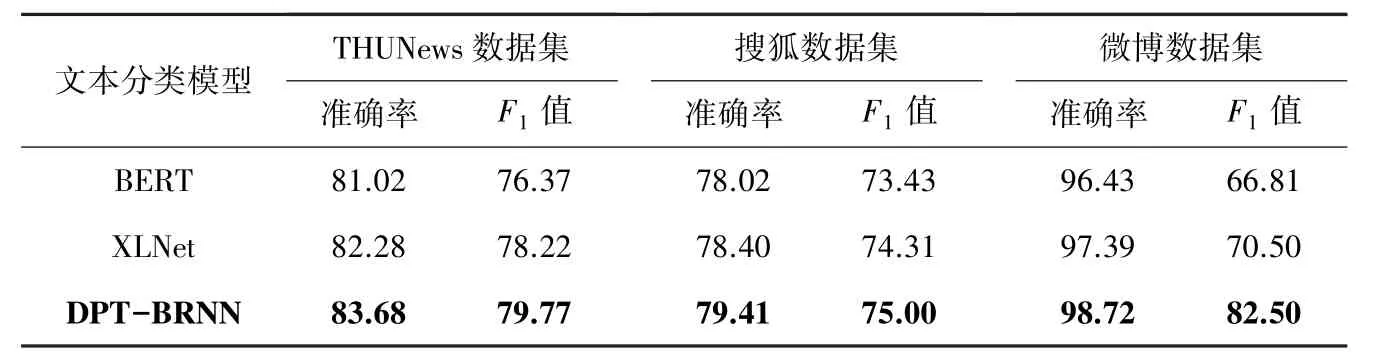
表6 与预训练词向量模型的对比实验结果Tab. 6 Experimental results compared with pre-trained word vector models%
3.4.2 与其它词向量模型的对比
为了进一步验证DPT-BRNN 模型的有效性,本文还对比多个在相同数据集上效果较好的基于Word2Vec 词向量的先进模型,对比模型包括:TextCNN、BiLSTM、BiGRU、BiLSTM-CNN、BiLSTMAttention[14]和MCCL[15]。 模型对比结果见表7。
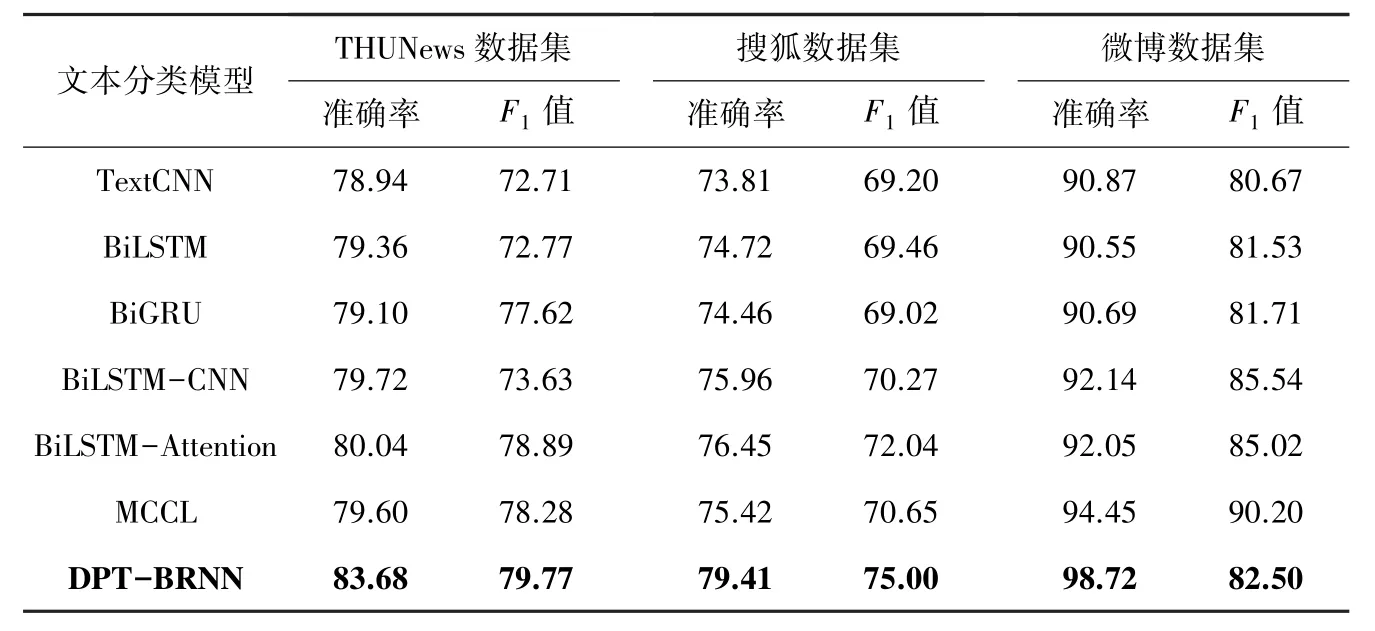
表7 与传统词向量模型的对比实验结果Tab. 7 Comparative experimental results of traditional word vector models%
由实验结果可以看出,对比基于Word2Vec 词向量的模型,本文模型无论准确率、还是F1值都有所提高。 但模型在微博数据集上的实验结果F1值不如部分其他模型,一方面一定程度上可能是微博数据集数据不平衡所致,另一方面可能是词向量维度过高,部分模型出现过拟合所致。 对比TextCNN模型,本文模型在3 个数据集上准确率分别提高了4.74%、5.60%和7.85%。 对比BiLSTM 模型,本文模型在3 个数据集上准确率分别提高了4.32%、4.69%和8.17%。 对比BiGRU 模型,本文模型在3 个数据集上准确率分别提高了4.58%、4.95%和8.03%。BiLSTM 模型、BiGRU 模型在3 个数据集上的训练结果大多较TextCNN 模型优异,这是由于BiLSTM 模型可以学习到句子的正向和逆向信息,从而能够更好地捕捉到上下文文本信息。 对比BiLSTM-CNN模型,本文模型在3 个数据集上准确率分别提高了3.96%、3.45%和6.58%。 BiLSTM-CNN 模型较BiLSTM 模型在3 个数据集上准确率分别提高了0.36%、1.24% 和1.59%。 BiLSTM-CNN 模型较TextCNN 模型在3 个数据集上准确率分别提高了0.78%、2.15%和1.27%。 对比BiLSTM、TextCNN 和BiLSTM_CNN 模型的实验结果,发现TextCNN 与BiLSTM 结合的网络结构能更有效地提取文本中的关键特征, 提升分类准确率。 对比 BiLSTM -Attention 模型,本文模型在3 个数据集上准确率分别提高了3. 64%、 2. 96% 和6. 67%。 BiLSTM -Attention 模型较BiLSTM 模型在3 个数据集上准确率分别提高了0.68%、1.73%和1.50%,引入注意力机制使得文本中每个词语的权重值得到重新分配,关键特征的语义信息更加明确,从而提升了BiLSTM模型读取上下文关键语义信息的能力。 将本文所提模型与MCCL 模型的分类结果进行比较,本文模型的准确率在3 个数据集上分别提高了4.08%、3.99%和4.27%,这表明本文使用预训练语言模型提取词向量作为BiGRU 与BiLSTM 模型的输入,更充分地发挥了深度学习模型对文本特征的提取能力,并且同时在两通道分别引入自注意力机制层和归一化层对通道输出的特征分布进行调整,增强了模型的学习能力,有效地提升了模型分类的准确性。
4 结束语
本文结合预训练语言模型XLNet、 BERT、BiLSTM、自注意力机制以及层归一化,提出了双通道DPT-BRNN 文本分类模型。 模型首先将文本信息分别通过XLNet、BERT 模型输出具有多样化信息的词向量,接着将词向量信息分别输入BiLSTM,使其对文本序列信息进行捕捉学习,提取文本不同层次的上下文语义信息。 然后,利用自注意力机制对文本深层次序列信息进行再提取,从而得到更加准确的文本关键语义信息,并将经过两通道的信息融合,得到更丰富的文本语义表示。 通过将提出的文本分类模型与其他8 种文本分类模型在3 个数据集上进行对比分析,结果表明,本文所提出的文本分类模型在中文数据集上取得了比较好的分类结果,验证了本文模型分类的准确性和有效性。
在接下来的研究中,将通过扩充语料库来不断提升模型的分类性能,并着重从词语的语义扩展以及模型结构、参数方面进行优化改进,从而进一步提高模型学习效果的准确性,并降低训练过程的时间成本。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
中国交通信息化(2018年5期)2018-08-21
数学物理学报(2017年5期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
