
面向翻译的语言知识服务系统构建
2023-06-26 17:00:32宁海霖
中国科技术语 2023年2期
摘 要:面向翻译的语言知识服务系统将平行语料库、术语库、本体知识库等语言知识资源统一整合,在此基础上对资源进行客观、直观、动态的描写,挖掘重要语言特征与知识结构,建立知识系统,并通过可视化手段对描述的结果进行形象化表征,提高认知效率与工作效率,满足翻译生态系统内部各个重要环节的知识应用需求和协同创新需求。语言知识服务系统的建设过程遵循协同化、统一化、可视化三原则,其核心部分由基础层、分析层与应用层三部分构成,分别负责语言资源供给、数据分析统计与知识表征运用,形成了模块融合共通、知识循环利用的交互式有机整体。
关键词:语言知识服务系统;资源描述;多模态;知识习得;机器翻译
中图分类号:H083; H059 文献标识码:A DOI:10.12339/j.issn.1673-8578.2023.02.006
Fundamental Layers and Designing Principles of Language-Knowledge Service System for Translational Purposes//NING Hailin
Abstract:The language-knowledge service system for translational purposes is an organic integration of parallel corpora, term banks and ontological knowledge bases. The system is designed towards the achievement of two major functions, through which both wanted knowledge and coordinated innovation in the entire translational ecosystem are accessible: (1) the objective, intuitive and processive resource description aiming at knowledge discovery and construction; (2) visualization of the organized data aiming at the enhancement of cognitive capacity and working efficiency. As a product of collaboration, standardization and visualization, the system structures its kernel section with three layers, named the elementary, the analytical, and the applied layer. The elementary layer firstly delivers basic language resources to the analytical layer, then the processed resources and relative results are transported to the applied layer for visualized representation, thus an interactive system of module connecting and knowledge recycling is composed accordingly.
Keywords: language-knowledge service system; resource description; multi-modality; knowledge acquisition; machine translation
收稿日期:2022-09-29 修回日期:2023-03-14
基金項目:教育部人文社会科学研究青年基金项目“翻译技术的知识化演进模式研究”(18YJC740067)阶段性成果
0 引言
翻译是一个由翻译理论研究、翻译教学、翻译实践、翻译行业管理、翻译技术应用等多个有机要素相互联动而形成的生态系统,在整个生态系统存续和扩展的过程中,来自科技、经济、军事、法律、医疗等社会认知领域的大量信息在各个要素之间循环往复流动,形成闭合的动态数据链,而整个翻译生态系统的健康程度,取决于该链条中数据的数量、质量与稳定性。面向翻译的整合化语言知识服务系统将信息环流中参与循环的各类数据有序地生成、存储、加工、利用与管理[1],为上述各要素节点提供高质量的信息与知识支持,从而加速数据流动,推动整个翻译生态系统持续高效运转,促进相关领域的知识创新。
1 语言知识服务系统的核心结构
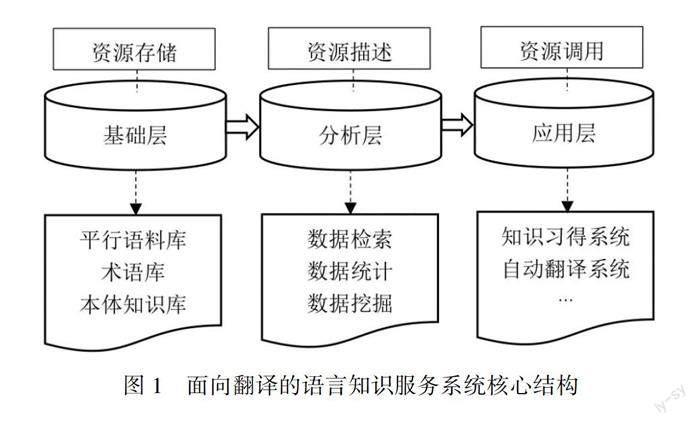
面向翻译的语言知识服务系统由基础层、分析层与应用层构成其核心部分(图1)。基础层负责存储系统内部的基本语言素材与专业知识素材,分析层建立对这些基本素材进行描述的机制,应用层可以直接调用分析层得出的数据,将之运用于翻译研究与生产活动,而产出的成果会重新返回到基础层以更新基础数据。三个层级协同工作,实现资源的统一存储、分类、加工、应用与增长,以满足译者、外语学习者、语言服务需求方、语言服务企业、语言技术开发商、高等院校和研究机构等[2]不同层次或领域用户的需求。该系统支持动态、开放的知识循环机制,随着语言服务内容与服务对象范围的不断扩大,其主干与分支的构成要素还将持续拓展。
1.1 基础层
基础层是语言知识服务系统的基础与核心部分,负责基础素材的存储。以翻译活动的需求为导向,导入基础层的素材类型一般包括平行语料库、术语库、本体知识库[3]等基础语言类数据库以及由此衍生的功能型资源库。基础层的建设是将零散、不规则的碎片化信息进行有序整合的过程,经整合的素材不仅具备噪声小、格式统一、分类清晰的特点,同时也包含相对完整、可靠的专业领域语言信息与知识框架,为进一步的数据分析与知识习得建立了基础条件。
1.1.1 平行语料库
平行语料库是整个系统的知识来源所在,也是数据检索、翻译记忆、知识提取与大规模语言模型训练等多种语言深度处理活动的基础性依据,在其投入使用之前,须将采集的专业领域多语种自然语言素材以实际应用范围为导向进行去噪、对齐、标注等预处理,同时可以在设计阶段进一步细化为多个子语料库或专题子库[4],以应对更为精细化的知识服务需求。平行语料库一般以普通文本的形式存在,也可以存储为通用化的TMX(Translation Memory eXchange),即翻译记忆库格式,从而提升语料的互操作性。一个标准的TMX主体结构包括至少一个tu(translation unit)标签,其下包含若干个tuv标签,用于存储若干个相互对齐的语句(一个tuv标签对应一种语言)。翻译记忆库借助特定领域文本句式的高度程式化和术语的高度一致性实现翻译过程中的相似语对自动调取,避免重复劳动,提升翻译实践效率。目前,该匹配过程主要运用基于字段的完全匹配或基于本体语义的模糊匹配方法实现[5],而语料库的规模、权威性与对齐程度仍然是决定匹配精度的关键因素。
1.1.2 术语库
术语是知识网络的节点,术语库的建设是专业领域知识体系构建的重要组成部分。高质量的平行语料库可以作为术语提取与关系提取的素材[6],用以建设术语库和本体知识库,尤其对于一些前沿领域的术语编纂(terminography)工作而言,自动提取技术能大幅提高双语术语采集的效率。除了资源构建层面的作用,术语库也是最关键的翻译辅助工具之一。术语库将采集后的术语进行粒度化(granularity)处理,根据用户需求设置某个具体词条包含的各项信息[7]。对于翻译工作者来说,较为重要的信息包括词条的译文、语境、可靠度和关联术语等,这些要素是对译文进行筛选与优化的主要依据。以应用TermOnline①术语库进行辅助翻译为例,虽然TermOnline的术语和相关译文需要经过全国科学技术名词审定委員会审定方可公布,但受审定的年份和适用语境等因素影响,许多过审的术语词条仍然存在一词多译现象,此时译者就必须结合发布时间、所属领域、可靠度等多种信息来做出合理的判断。
1.1.3 本体知识库
本体知识库是术语深度操作化(operationalization)的结果[8],它以术语为知识节点,在节点之间引入逻辑关系与推理规则,并建立知识习得与知识挖掘的路径。为了提高译者的认知与学习效率,本体知识库的用户端常引入多模态手段对概念与知识进行直观化表示。本体知识库的建设过程主要包括三个步骤:一是概念构建,这部分和术语编纂过程基本相同;二是概念关系构建[9],可从语料库中自动提取,也可以依据专业领域的知识结构进行人工构建,必要时须联合领域专家协同建设;三是可视化机制构建,包括对概念内涵的多模态表示与领域主题图的设计等[10]。本体知识库是译者进行译前准备和知识习得的高效作业方案,它不仅可以直接调用术语库中的词条信息,还提供特定术语的所有关联术语与逻辑关系索引,能够帮助译者快速了解、掌握与检索内容相关的专业知识,形成对概念的网络型认知。
1.2 分析层
分析层整合数据检索模块、数据统计模块与数据挖掘模块,对基础层中的平行语料库、术语库、本体知识库等数字化资源进行客观化、直观化、过程化的描写,为语言规律分析、隐藏知识挖掘、专业知识习得途径开发等翻译研究、教学或实践工作提供依据。数据分析系统的模块构成需要以功能为导向进行定向设计,以满足用户的特定要求。此外,数据分析系统还重视以数字、表格、图片等多模态手段对分析结果进行可视化表示,形象地体现翻译本质和翻译规律[11]。
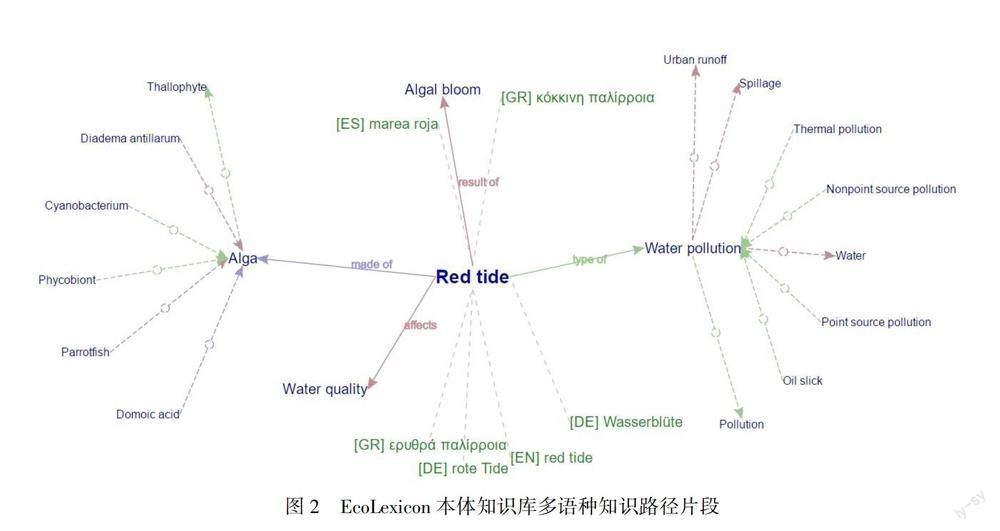
数据检索功能用于信息定位,检索手段有关键词或正则表达式等。平行语料库的检索着重于对语素的翻译、搭配方法及其共现的语境的提取;术语库的检索内容主要是术语词条信息,也可以根据术语库的粒度设置情况,依照词条的领域、发布时间、相关词条等信息标签做进一步的深度检索;本体知识库的检索模块能够清晰地定位知识节点在专业领域知识体系中的位置,译者在深入学习该知识点的同时,还能对以该知识点为中心的知识网络产生宏观认知[12]。数据统计功能用于对语言素材的特征进行客观描述,其描述的对象主要是平行语料库。例如,平行语料库的分析系统一般需嵌入对语料的搭配、型次比、元信息[13]、主题词、特征因子等数据的检索与统计功能,以满足基于语料库的翻译共性分析、修辞手法分析、译者风格比较、译本历时演变、译文质量评价、翻译教学法研究等需求。数据挖掘功能用于对双语术语、逻辑关系和知识链进行自动抽取。例如,本体知识库的数据挖掘机制至少要具备两个功能:一是与术语库对接,读取术语库中存储的知识节点信息,包括前文提及的定义、语境、关联概念等;二是从大规模主题图中抽取一部分由若干概念与概念关系组成的知识链进行独立展示或分析[14],以满足译者在译前准备过程中对特定知识点及其关联知识点的学习需求。以基于EcoLexicon②环境本体知识库的译前准备工作为例(图2),译者不仅可以检索到关于“赤潮(red tide)”这个术语的英、法、德、西等六个语种的表达,还可以在邻近的知识路径中获取掌握赤潮的成因(result of)、引发赤潮的藻类(alga)的种类(type of)、赤潮对水质的影响(affects)等相关专业知识。
1.3 应用层
应用层的主要功能是将基础层存储的素材和分析层处理的数据综合运用于翻译相关的生产实践环节。根据翻译教学、翻译实践、翻译研究等各领域不同的需求,应用层的功能模块也要视具体使用对象做出选择性构建。目前而言,应用层主要由知识习得系统和自动翻译系统两部分构成,随着面向翻译的知识服务的范畴不断扩大,应用层的功能与内涵将继续得以拓展。
1.3.1 知识习得系统
知识习得系统是在整合基础层和分析层核心功能的基础上建立的教学与自学一体化平台,它在提供优质翻译教学资源的同时,对个体学习行为与知识需求进行分析,优化学习路径并建立互动式学习机制,促进用户技术能力、信息能力、学习能力与翻译实践能力的共同发展[15]。在使用过程中,知识习得系统直接调取基础层中的知识素材,在内容与方法两个层面执行工作。在内容层面,知识素材须包含语言知识、翻译知识与专业知识。语言知识指源语和目标语的语音、词性、语义、语法、搭配等语言特征类知识;翻译知识指翻译理论、翻译技巧、翻译技术、文化比较、翻译史等翻译方向知识;专业知识指涉及社会民生各个领域的系统化知识,如建筑知识、医学知识、商务知识、法律知识等。各类知识素材需要以教学过程或学习过程为导向进行语料标注[16]、术语提取、多模态转写等预处理,为数据的挖掘与利用建立基础。在方法层面,处理素材的手段须包括数据分析机制与教学机制。数据分析机制直接调用分析层的处理结果,建立知识习得过程中的最优化路径。教学机制的主要功能在于为用户提供直观而高效的工作环境,建立知识要点主题图机制、互动交流机制、成绩评价机制与使用偏好分析机制,必要时也可建立跨领域、跨院校的合作网络[17],及时整合、推送优质资源,实现知识共享。
1.3.2 机器翻译系统
在基于规则和基于统计的翻译方法之后,神经网络机器翻译的编码―解码框架把语言理解和语言模型结合起来,大幅度提高了机器翻译的正确率[18]。高效机器翻译系统的实现要具备两个前提条件:一是建立大规模、多领域的语料库,保证语言模型训练的质量;二是建立能够准确分析与掌握深层次语义的算法,提高语言转换的精确度。已投入应用的主流机器翻译平台有谷歌翻译、百度翻译、DeepL等,相对于基于规则或统计手段的机器翻译工具,这些翻译平台的综合翻译水准已经有了质的提高,但在高文化负载文本的处理上依然不尽人意,相较于以机器为主体的自动翻译工具,当前的机器翻译系统更适合定位于“自动化的翻译辅助工具”,人工干预依然不可或缺,但合理地运用机器翻译系统,可以有效提高翻译效率,降低翻译过程中的人力成本,更有利于促进译者翻译能力的扩展和延伸[19]。机器翻译系统的发展应着眼于三个任务:一是挖掘学科交叉优势,推动算法创新,开发综合自然语言处理、知识本体与神经网络技术优势的语言识别机制,提高机器翻译对文本和超文本的理解力和转换能力;二是探索适用于机器翻译的语境、领域和方式,促进人机结合模式的创新,开发适合中国语言市场需求的翻译平台[20];三是深化校企合作,完善大规模语料库与知识库的共建机制,保证机器翻译系统开发的资源基础。
2 语言知识服务系统构建的基本原则
协同化、统一化、可视化是语言知识服务系统构建的三个基本原则,这是由翻译需求决定的。翻译需求是语言知识服务系统构建的核心导向,当前译界对数字化平台的需求主要体现在:(1)规模层面。大规模语料库是各类数据和知识的来源,也是开发知识习得系统和自动翻译系统的前提条件,而随着翻译实践范畴的扩大,译者对领域多样性的要求也在不断提高。(2)质量层面。冯志伟指出,一个内容丰富的多元数据语料可以极大地推动诸如知识推理、数据不确定管理技术的研制[21]。数据分析的质量取决于资源加工程度,为了适应翻译教学模式和研究范式的转变,语言资源的加工方式正在向领域化、知识化、智能化不断发展,包括语料库的语义标注[22]、术语的自动化抽取与筛选、专业知识的逻辑关系与推理规则构建等。(3)操作层面。高质量的语言知识服务系统要具备简易的人机交互界面与多维度的知识表示手段,以提高翻译的工作体验和执行效率。应整合相关研究资源,推进相关领域研究者之间的协作,在理论层面、实际操作层面与应用层面进一步深入探讨[23]。
2.1 协同化
语言知识服务系统工程一般体量大、成本高、维护周期长,且相关技术涉及学科门类复杂,所以应开展协同合作,建立语言知识服务系统的联合共建机制。该机制包括两方面的内容:(1)社会各相关部门的协同合作,如政府机构、高校、语言服务提供商、出版社之间建立的项目合作关系。政府机构能够为系统建设提供立项支持与资金支持,高校与语言服务提供商提供语言素材与技术支持,并监督执行素材的采集、整合与加工,出版社负责系统的发布、宣传与管理,项目的成果由合作方共享,可长期为翻译相关的产学研重要领域提供语言服务,增强各部门的语言能力。另外,高校作为语言资源存储量和使用量最大的部门,应深化合作关系,整合优质资源,共建开放性的教学科研平台,实现校际知识共享。(2)各专业领域开展协同合作。由于语言活动与翻译活动与生俱来的多学科性[24],翻译面向的语言素材也必然源于多个领域,这也决定了译者自身必须构建多学科的知识体系以适应语言服务市场的需求,而缺乏专业知识和相关素材也是译者在职业发展中面临的主要问题之一[25]。除了素材来源于多学科文献之外,语言知识服务系统的建设流程包含对专业知识的提取、构建与挖掘工作,与领域专家建立持续性合作关系、参考吸收相关建议,有利于准确把握专业知识的结构与要点,强化资源质量审核机制,保证资源建设的进度与可靠性。此外,领域专家的参与有助于增加资源中的原创概念定义、知识框架等项目的比重,在促进知识创新的同时保护知识产权。
2.2 统一化
语言知识服务系统是由多个层级、子层和模块构成的有机整体,各个功能单位之间的资源和数据总是处于不断的循环和交互之中,比如术语库中的词条语境信息来源于平行语料库的相关语句,知识习得系统中的专业知识要点来源于本体知识库的知识系统等。在语言知識服务系统的应用过程中,数据的统一性至关重要,这也是评价系统总体质量的主要依据之一。统一化原则的内涵包括两个方面:(1)基础素材统一化。语料库、术语库和本体知识库必须依次为后者的素材来源。生语料在经过去噪、对齐、标注等预处理环节转化为熟语料之后,利用相应工具提取本领域的双语术语和概念关系,双语术语经筛选、编纂工作存入术语库中,进而将术语和概念关系有机结合为知识本体,这样就构建了语言素材之间的一体化联动关系。基础素材统一化保证了资源与数据的高效调用。例如,译者利用本体知识库的知识导航功能进行译前准备工作的同时,还能够以相关术语为关键词,直接检索到存储于语料库中的该术语的词汇搭配和双语例句,也可以直接检索到存储于术语库中的该术语的各项条目信息[26]。另一方面,基础素材统一化保证了语言应用的一致性,能够规避因同义异形词滥用而导致的歧义,在降低语言经济成本的同时确保了翻译的标准化和规范性。(2)翻译技术标准统一化。语言资源的存储和交换应采用业界广泛认同的标准来执行,这样可以提高资源在不同翻译技术工具和语言服务提供商之间的通用性或互操作性(interoperability),保证翻译生态系统中数据环流的通畅,也有利于保护语言资产,避免因市场和技术更新而造成经济损失[27]。当前而言,平行语料库多被存储为TMX格式的翻译记忆库,术语库一般以TBX(Term-Base eXchange)格式进行存储和应用,本体知识库通常以OWL(Web Ontology Language)格式作为标准化存储方式,以便于统一化操作与管理。
2.3 可视化
从本质上讲,翻译活动是将一种符号所包含的思维内涵用另外一种符号表示出来的知识传播行为。符号是一个个体对象客体,它与另一种个体对象客体、概念或者事态长期相互对应,具有代表性地标明这些事物[28],这个对象客体以文字、声音、动作、图片、数字等多模态形式存在。换言之,翻译是一种通过多类型符号进行相互转换来传递和表征一个思维内涵的行为,多模态转换是翻译活动的基本形式。语言知识服务系统在应用层面的最大优势,在于将抽象的数据和知识转换为直观的多模态实体,提高用户的认知效率。可视化的内涵覆盖两个层面:(1)数据可视化,指用图表、图形、动画等方式诠释数据、表征大规模语料的内部属性,借以凸显特征差异和隐形关系,形成对翻译文本更加精确的理解和描述。翻译领域比较重要的数据可视化方法包括词频分析法、共词分析法和多元统计分析法等,借助Prefuse、CiteSpace、SPSS等工具能够可视化地展示相关分析结果。(2)知识可视化,指将专业领域的知识框架与知识脉络用可视化的方式形象地展示给用户,并统一提供知识习得过程中常用的导航、检索、抽取、调用等操作模块。可视化的知识网络是包含了文字、数字、图形、动画、音频、视频的符号集合体,各类符号之间相互关联,共同构成了译者专业领域知识的多模态习得途径。知识习得过程是合理利用各类符号资源进行综合构建的过程,每种符号都具备自身的优势,如动画和视频更加明晰、形象,能有效降低认知难度,而文字与数字则较为详细、具体,能够补偿视频学习中忽略的细节部分。
3 结语
面向翻译的语言知识服务系统是翻译技术研究向知识化方向演进发展的成果,是集存储、分析、应用于一体的综合型翻译研究、实践与教学平台。语言知识服务系统的构建过程以翻译需求为导向,体现了翻译学、语料库语言学、术语学、计算机科学、统计学等多学科交叉研究模式与数字人文研究方法,深化了翻译产学研结合的发展路径,也为翻译的认知研究、计算方法研究、数字化教学模式研究等前沿领域的开拓奠定基础。同时,伴随翻译活动范畴的延伸和体量的增长,翻译生态链中的数据环流也在迅速增大,鉴于此,语言知识服务系统的各个模块应在功能性、易用性、可靠性、专业性等方面不断升级拓展,以满足学者和译者对数据和知识的获取、应用与创新持续增长的需求。
注释
① http://www.termonline.cn/index.htm
② http://ecolexicon.ugr.es/visual/index_en.html
參考文献
[1] WLOKA B,WINIWARTER W,BUDIN G. DASISH: An Initiative for a European Data Humanities Infrastructure[C]//Proceedings of International Conference on Information Integration and Web-based Applications & Services, 2013: 433.
[2] 王传英,崔启亮,朱恬恬. “一带一路”走出去的国家语言服务基础设施建设构想[J]. 中国翻译,2017 (6):62-67.
[3] 刘志,郝克俊. 基于Protégé的人工影响天气术语本体知识库设计与实现[J]. 中国科技术语, 2019, 21 (6):17-23.
[4] 杨明星,吴丽华, 牛桂玲, 等.“互联网+” 背景下多模态、多语种外交话语平行语料库设计与创建探析[J]. 外语教学, 2018, 39 (6):13-19.
[5] 汪美侠. 基于句法和语义的英汉翻译记忆系统的研究与实现[J]. 电子设计工程,2016,24(21):24-26,30.
[6] ARAZ L P,REIMERINK A,FABER P. Knowledge Extraction on Multidimensional Concepts: Corpus Pattern Analysis (CPA) and Concordances[C]//The 8th International Conference on Terminology and Artificial Intelligence, Toulouse, 2009.
[7] BUDIN G, KABAS H, MRTH K. Towards Finer Granularity in Metadata: Analyzing the Contents of Digitised Periodicals[J/OL]. Journal of the Text Encoding Initiative, 2012(2). http://jtei.revues.org/416.DOI : 10.4000/jtei.416.
[8] KOCKAERT H,STEURS F. Handbook of Terminology[M]. Amsterdam: John Benjamins Publishing Company, 2015:128.
[9] 原伟. 面向中亚地区的多语种专业领域术语库及本体知识库构建[J]. 中国科技术语, 2019, 21 (6):11-16.
[10] 苗菊,宁海霖. 翻译技术的知识体系化演进:以双语术语知识库建设与应用为例[J]. 中国翻译,2016 (6):60-64.
[11] 胡开宝. 数字人文视域下翻译研究的进展与前景[J]. 中国翻译,2018,39(6):24-26.
[12] GIL-BERROZPE J, FABER P. The Role of Terminological Knowledge Bases in Specialized Translation: The Use of Umbrella Concepts[C]//Temas actuales de terminología y estudios sobre el léxico. Publisher: Comares, Editors: Miguel ngel Candel-Mora, Chelo Vargas Sierra, 2017: 8.
[13] 梁茂成,许家金. 双语语料库建设中元信息的添加和段落与句子的两级对齐[J]. 中国外语,2012,9 (6):37-42,63.
[14] 宁海霖. 面向汽车工程翻译的可视化知识服务平台构建[J]. 中国科技术语,2020,22(1):21-25.
[15] 王少爽,李春姬. 技术赋能时代翻译教师能力结构模型构建与提升策略探究[J]. 外语界,2021(1):71-78.
[16] 朱纯深,慕媛媛. 以文本解释力为导向的语料库翻译教学:香港城大翻译与双语写作在线教学/自学平台的设计与试用分析[J]. 中国翻译, 2013, 34 (2):56-62,127.
[17] 孙喜晨. EMT及其派生项目分析与MTI教育产学研合作网络构建[J]. 外语界,2017(4):44-50.
[18] 冯志伟. 机器翻译与人工智能的平行发展[J]. 外国语,2018,41(6):35-48.
[19] 王少爽. 机器翻译素养的概念内涵与表现形式:代主持人语[J]. 语言教育,2021,9(2):54,62.
[20] 王贇,张政. 翻译研究新路径:数字人文新释[J]. 外语教学,2020,41 (2):81-86.
[21] 冯志伟.自然语言处理的重要资源:“知识图谱”[J]. 外语学刊,2021(5):1-9.
[22] KUBLER S, ZINSMEISTER H. Corpus Linguistics and Linguistically Annotated Corpora[M]. London & New York: Bloomsbury, 2015: 83.
[23] 寧海霖.论翻译技术研究的知识维度[J]. 外语学刊,2021(5):66-71.
[24] 陈平. 语言交叉学科研究的理论与实践[J]. 语言战略研究,2021,6(1):13-25.
[25] 丁大刚,李照国,刘霁. MTI教学:基于对职业译者市场调研的实证研究[J]. 上海翻译,2012(3):41-44.
[26] LACASTA J, NOGUERAS-ISO J, ZARAZAGA-SORIA F J. Terminological Ontologies: Design, Management and Practical Applications[M]. New York: Springer, 2010: 131.
[27] 王华树. 翻译技术教程:上册[M]. 北京:商务印书馆;上海:上海外语音像出版社,2017:14.
[28] 费尔伯. 术语学、知识论和知识技术[M]. 邱碧华,译. 北京:商务印书馆,2011:91.
作者简介:
宁海霖(1982—),男,博士,天津商业大学外国语学院讲师,研究方向为术语学与翻译技术。2016年维也纳国际术语学暑期学校学员,教育部人文社会科学基金项目主持人,参与国家社会科学基金重大项目、全国翻译专业学位研究生教育研究项目各1 项,在《中国翻译》《中国科技翻译》《翻译界》《中国科技术语》等期刊发表论文10 余篇。通信方式: computerherald@163.com。
猜你喜欢
考试周刊(2017年2期)2017-01-19 09:13:50
考试周刊(2017年2期)2017-01-19 09:12:54
电影文学(2016年19期)2016-12-07 19:57:57
新教育时代·教师版(2016年33期)2016-12-02 13:10:17
智富时代(2016年12期)2016-12-01 17:03:10
戏剧之家(2016年22期)2016-11-30 18:20:43
科教导刊(2016年26期)2016-11-15 19:54:13
知音励志·社科版(2016年8期)2016-11-05 02:46:03
科教导刊·电子版(2016年23期)2016-10-31 10:14:04
现代经济信息(2016年10期)2016-05-24 22:55:15
