
中原官话(河南区域)超音段特征及优选论视域下的成因分析
2023-02-27 05:31牛卉慧
安阳师范学院学报 2023年6期
牛卉慧
(河南开封科技传媒学院 外语学院,河南 开封 475000)
在河南区域内方言种类繁多,对于河南区域的各中原官话在语法、词汇、发音位置的研究均较为深入,对中原官话在超音段方面的研究大多分布在声调方面,其他领域相对贫乏,如超音段特征的文献仍然稀缺。因此,针对中原官话在河南省区域内60个县区方言的超音段特征展开对比研究和类型研究,并对其特点的成因进行分析具有很强的必要性。
一、研究方法与过程
(一) 实验材料
“你不是打算今天不起床了?”作为反义疑问句,其特点是以疑问句的形式表达陈述句的含义,因此,在使用时,说话者对听话者的反馈的需求性不强。由于这一特点,各地方方言在处理反问句时采用的语调性也会出现较大差异,更能凸显地方语调特色,如,“你不是说今个不起床了?”或“你不是说今儿不起床了?”因此,其比较适合作为实验材料。
考虑到为保证实验数据的精确性,研究材料所选取的反义疑问句应被放置于一个场景明确、内容既定的日常对话中,以此保证句子所表达的情绪内容不变,确保采集的实验数据与实际使用的语言的贴合度。因为关注点是句子的整个调型以及重音位置上,所以,个别词语在保证表述含义和句子种类不变的情况下,可按照当地方言的说话的具体习惯与特点,作出适当调整或转换。
参与实验人员以两人为一组进行对话实验,实验中两人分饰二角,根据实验材料展开对话,研究人员进行录音采样。为降低参与实验人员在实验时处理材料的偶发性,每位参与实验的人员对实验材料进行4次采样。
(二) 实验对象
首先,受试人员的选取根据 2012 年《中国语言地图集(第 2 版)》,在河南境内的中原官话中,涉及8个片区(郑开片、洛嵩片、南鲁片、漯项片、商阜片、信蚌片、徐淮片、关中片)共60个县(区)[1](B3)。在每个受试方言区域分别选取3组受试对象(每组2人),以降低受试对象个人口音的偶然性,保证所收集数据的准确度。其次,确保所采集到研究样本中数据不受其他方言或普通话的明显影响,受试人员均选取本土居民、无长期离乡史、最高学历为义务教育阶段,年龄在40-60岁之间的成年女性。最后,为排除家庭成员之间口音的相互影响因素,每位受试人员均来自不同家庭。
(三) 实验过程
1.实验前
为确保取样结果的自然性与准确性,在实验前均设立有实验员与受试对象的熟悉期,使实验员与受试对象之间建立较随意的关系。并且,在实验开始前,实验员要给足受试人员时间,使其对实验材料与实验环境的熟悉度得到充分建立。 采集样本的地点采用就地选取的方式,在实验方言当地选取在一间密闭性较好的静室,利用话筒(B&K4131)进行收音,利用Audacity软件进行录制保存,保证实验数据不受杂音干扰。
2.实验中
在实验过程中,受试组以分角色的方式根据实验材料规定的内容完成4次对话。每次对话完成,均进行角色互换,重复测试,最终的实验数据取4次数据的平均值。关于受试组对材料的完成时间长短不作控制,以保证采集到的实验数据的自然性。
3.实验后
在实验后的数据分析阶段,采用Praat对实验数据进行分析,具体研究过程如下:
(1) 对每个录音材料中的杂音进行清除,排除噪音对声波的影响,以免出现数据的偏差;
(2)根据涵义对句子界限和短语界限进行标记;
(3)根据Spectrogram图像,将实验材料中句子里的每个字词进行音节划分;
(4)根据F0数值,对音高的最低处和最高处进行标记;
(5)根据Spectrogram图像,对实验材料中的每一处音高进行记录。
二、研究结果
根据以上对实验材料中每个位置音调的数值的记录数据,音节位置的切割位置,音高最高点与最低点的定位,音调型、重音位置以及音节特点可得出以下结论。
(一) 音调(Pitch)
托森(Thorsen)指出,音调是指声带振动的频率,因为音调属于接收性知觉,通过基本频率F0来展现音调的轨迹,因此,音调所形成的轨迹,就是F0轨迹型[2](P152)。所以,本研究将通过对F0轨迹的观察,分析得出各地方言语调的特征。
1.基本调型
中原官话在河南各地区方言的语调型基本一致,均为‘升-降-升-降’型。具体从以下6个方面展开对实验语句的调型的分析,分别为启势型、收势型、最高点位置、最低点位置、起伏度以及下降度。
1) 启势型
启势型这一概念可以用来描述语调特点,它是指从语句发声开始到句子中第一个音节核之间的语调趋势。河南区域内的中原官话启势出现了两种调型,一种是先下降再上升,即抑扬型,另一种是上升再下降,即扬抑型。根据图1所示,抑扬型占河南区域方言总数的大部分,为62.71%,其余为扬抑型启势方言,占方言总数的37.29%。其中,抑扬型多分布于商埠片区和信蚌片区,占比为83.33%;分布在徐淮片区方言的最少,为0%,徐淮片区的所有方言均为扬抑型启势。
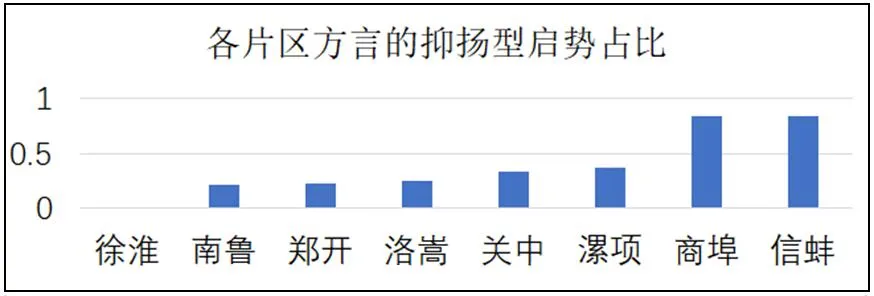
图1
2) 收势型
收势型这一概念用来描述语调特点,它是指从最后一个音节核到语句发声结束时之间的语调趋势。河南区域的中原官话收势分为3种调型,分别为下降型,持平型、降升型。根据图2所示,其中下降型占河南区域内的方言数量最多,为52.54%,在半数以上;其中持平型占18.64%,主要在信蚌片区和商埠片区占比最大,均占66.67%;降调型占28.81%,主要分布在徐淮片区和关中片区,二者是占比最大的片区,均为100%,其次是分布在南鲁片区和漯项片区,在此两处片区可占多数,分别为85.71%和75%;降升调型主要出现在洛嵩片区,占比为50%。

图2
3) 最高值位置
测试语句按照从后向前的顺序按音节进行划分并标记,共产生1-11号共11个音节。根据实验数据可得,在60个方言中,其音调最高点出现的位置均不相同,大致分为4种,分别出现在第2个音节“床”,第6个音节“今”,第10个音节“不”,以及第11个音节“你”。如下所示:

“你不是打算今天不起床 了?”(11)(10)(9)(8)(7)(6)(5)(4)(3)(2)(1)
河南各区方言最高音的落点大部分位于句子的前半部分,占总数的75%,且均在双数音节上。当最高音在“你”上时,“你”在该方言中所在的测试语句中的位置,因当地方言特点发生变化,而变为双数,如在长垣方言“你不是说今儿不起了?”中,“你”是第8位。
具体实验数据如图3,最高音出现在音节“你”的方言占比35%,最高音出现在音节“不”的方言占比40%,最高音出现在音节“今儿”的方言占比11.67%,最高音出现在音节“床”的方言占比13.33%。徐淮片区和关中片区方言音高最高点均落在第11个音节“你”上;洛嵩片区方言落在第11个音节“你”和第2个音节“床”各占50%;南鲁片区方言最高音在4种落点均有分布,且分布较平均,无明显偏向;郑开片区方言在4种落点也均有分布,但在第11个音节“你”达到最高音的占比最高,占比近50%;漯项片区方言的最高音多分布于第4个音节“不”上,占总数的87.5%;商埠片区内方言的最高音,除去第6个音节“今”,其余3个位置均有分布;信蚌片区超过50%的方言最高音落在第4个音节“不”上。
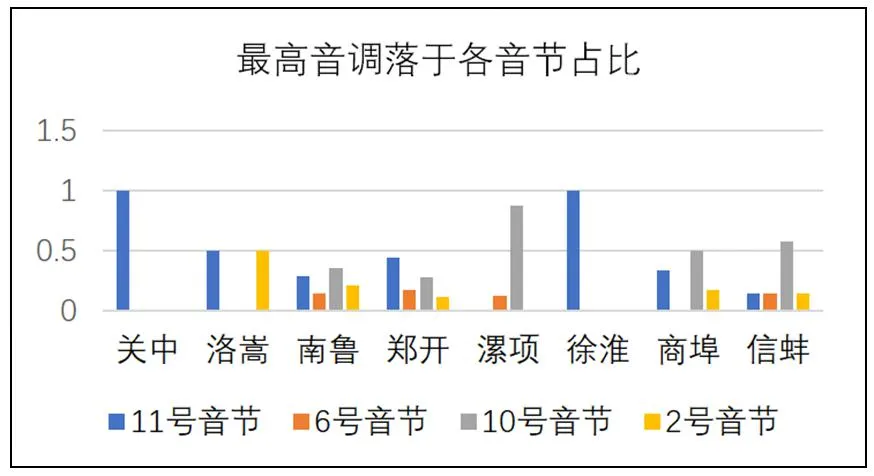
图3
4) 最低值位置
测试语句的音高最低点在60个方言中的分别位置也各不相同,同样分为4种,分别是第1个音节“了”,第4个音节“不”,倒数第6个音节“今”,以及第7个音节“算”。如下所示:
“你不是打算今天不起床 了?”(11)(10)(9)(8)(7)(6)(5)(4)(3)(2)(1)
河南各区方言最低音的落点大部分位于句子的后半部分,占总数的61.7%,且最低音的落点均在单数位上。当落在音节“不”或音节“今”上时,此二者所在的测试语句在该方言的音节数位置,因当地方言特点发生变化,而成为单数位,如在滑县方言中“你不是打算今儿不起啦?”其二者处于在3位和第5位。
具体数据如图4,最低点落在第1个音节“了”的方言占总数的比例最多,占比43.33%,最低点落在其他3个位置上的比例较平均,均不足20%。徐淮片区和关中片区方言,测试语句的最低点均落在第1个音节“了”上;洛嵩片区大部分方言其测试语句的最低音落在第1个音节“了”上,占比50%;南鲁片区没有方言落在第4个音节“不”上,其余分布较为平均;郑开片区方言中,测试语句的最低音的出现位置在4种落点均有分布,各落点占比较平均;漯项片区没有方言的测试语句的最低音落在第7个音节“算”上,其余均有分布,且分布较平均;在商埠片区,缺乏测试语句的最低点落在第6个音节“今”和第7个音节“算”上的方言;在信蚌片区,缺乏测试语句的最低音的落点在第4个音节“不”和第7个音节“算”的方言,大部分方言的最低点均落在第1个音节“了”上。
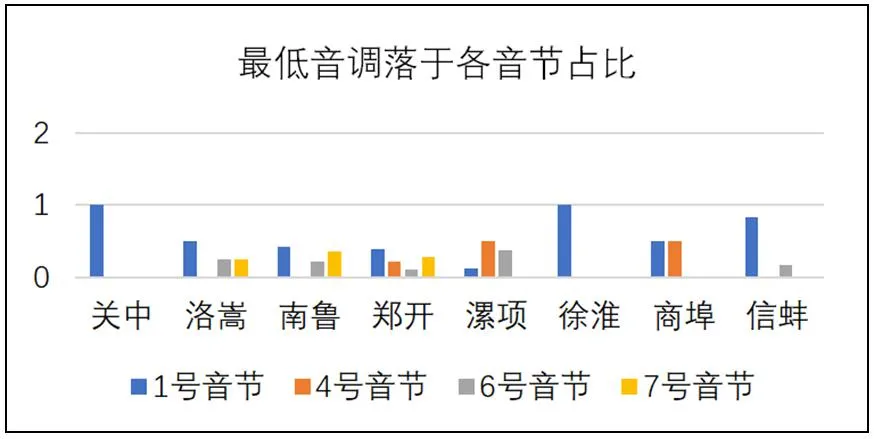
图4
5)起伏度
起伏度这一概念用来描述语调特点,它是指音高在单位时间内的变化的趋势发生转折的程度。音高变动趋势在升降或降升出现的拐点数量与完成测试语句的时间的比的方式来衡量实验中语句的起伏度,比值越大,说明语调的起伏度越大,反之,该方言的语调的起伏度越小。
根据实验数据可得图5,徐淮片区方言起伏度最大,为6.89,其次是信蚌片区方言和商埠片区方言的起伏度也相对较大,分别为6.2467与5.9383,关中片区方言起伏度最小,为1.22。

图5
6)下降度
下降度这一概念用来描述语调特点,它是指在语句进行过程中后一时间的音高低于前一时刻音高所占的时长在发声总时长中的占比。与之相关的另一个概念为上升度,这一概念是与下降度相对应出现的概念,是指在语句进行过程中后一时间的音高高于前一时刻音高所占的时长在总时长中的占比。因为上升度与下降度互为补数(上升度=1-下降度),因此,上升度与下降度可任选其一作为衡量语调特征的维度即可,分析采用下降度是由于下降度在方言语调特征的表现中比较明显。
根据实验数据得出图6,在8个片区的60个方言中,测试语句的语调的下降度均高于其上升度,且下降度的占比均高于50%。下降度最高的方言片区为关中片区,其下降度为67.32%,下降度最低的方言片区为信蚌片区,其下降度为56.32%。
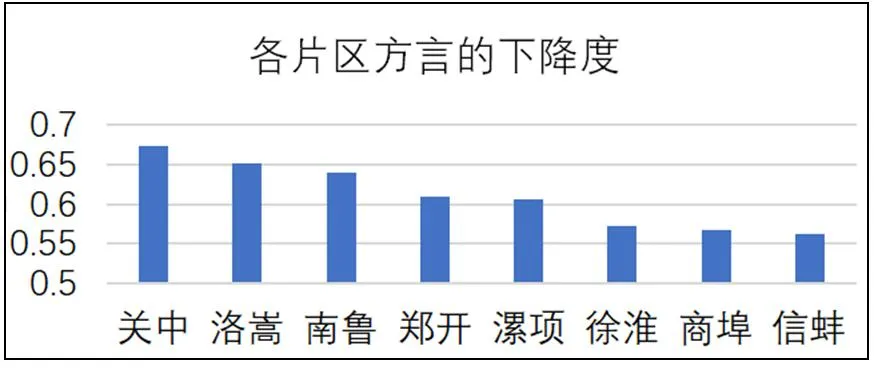
图6
综上所述,根据以上对句调型6个维度的描述,可以发现 60个河南区域的中原官话的语调的起伏度和语调的下降度之间基本呈现反比关系,与扬抑型启势和平调或升调型收势成正比,即起伏度越低,下降度越高,扬抑型启势可能性越大,平调或声调收势可能性也越大。
(二)音节(Syllable)
1.音节特点
音节的基本构成部分为韵头和韵尾,其中韵尾又包括音节核和音节尾两个部分。赵元任(Chao)认为每个音节都有音节首,即使没有一般意义上的辅音,也须由滑音或零音节首组成[3]。但是,音节首消失现象却未曾提及。然而,这在河南区域的中原官话的60个方言中非常普遍。根据实验数据可得,测试语句内所包含的11个音节中,有3个字的音节首在发音过程中会出现消失现象,从而致使2个音节在声波的图像上合为1个音节的现象发生。这3个音节分别为“打算”中的“算”的音节首,“起床”中的“床”的音节首,以及“不是”中“是”的音节首。以下为“不是”中“是”的音节首存在、消失以及半消失的声波特征,见图7~9。
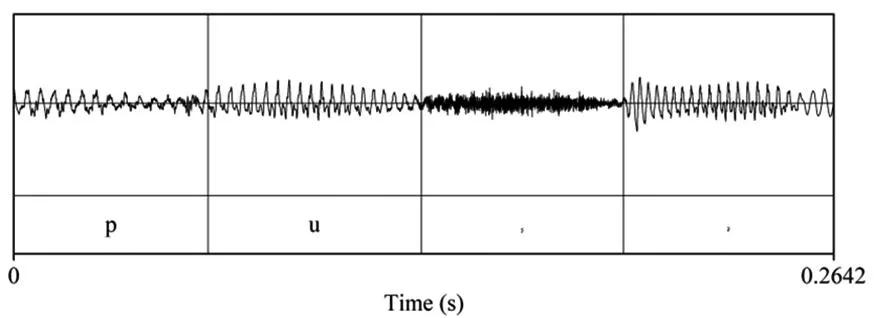
图7 含有音节首的“是”
如图7所示,“不是”中“是”的音节首呈现出无规律小振幅的特征,是一个标准的清摩擦音的声谱;而在图8中,“不是”中的“是”的声谱图像呈现出有规律的振幅且每个振幅内部形态一致,其为典型的元音声谱结构;在图9中“不是”中的“是”的声谱图像呈现出有规律的振幅但单个振幅内部无规律的图像,为典型的浊摩擦音的声谱图特征。因此,研究认为在不同方言中所出现的这3种不同音节首状态说明,河南区域的中原官话中的音节首发生了一个消变过程,即,CV>GV>V。这一音系演变在一些方言里已经完成,而在另一些方言中尚未完成。
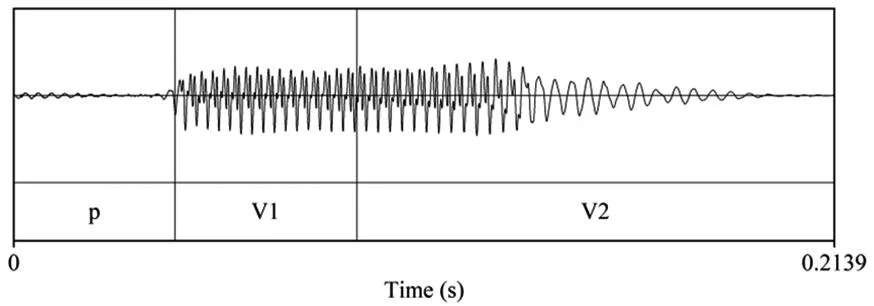
图8 不含有音节首的“是”

图9 含有过渡性音节首的“是”
因此,研究提出音节首丧失度这一概念来描述各方言语句中音节首的丧失情况,比较各方言音节构成特征。丧失度是指,在单位语句中音节首丧失的次数,数值越大,丧失度越强,相反,数值越小,丧失度越弱。测试语句共包含11个音节,具体数据如图10所示,商埠片区方言的音节首的丧失度平均为1.5次,是各方言片区音节首丧失度最严重的片区;关中片区内各方言音节首的丧失度为0,是各片区音节首丧失度最少的片区。
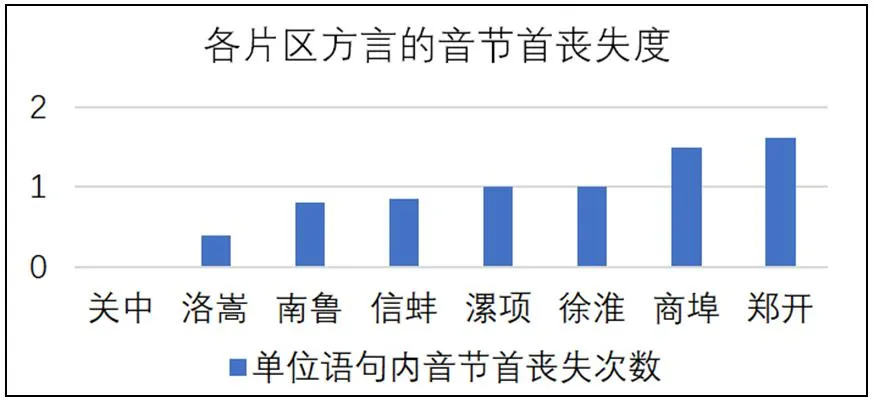
图10
2.特点成因分析
端木三(Duanmu)认为零音节首效应在句中位置并无证据证明,在句首位置也许是偶然[4](P75)。实验数据表明,可将该论点作出反证,并且从优选论的角度对句中音节首消失给出解释,进而产生新理论,即:语言的形态是影响语言发展方向的各个原则之间的相互作用力的合力的结果。
音节的构成基本采用以下两个原则。首先,根据Parse原则规定,深层结构里的每一个因素均要在表层结构中得到表述,防止由于音变引起语义上的模糊或歧义[5](P4)。因此,音节首是无法消失的。其次,根据重音首置原则σ→[+stress/_____ (σ)],即,两个音节连续时,重音落在第一个音节上[6](P287)。因此,第二个音节就会被弱读,从而引起音节首发生弱化进而消失。
根据对60个中原官话方言研究的结果,研究认为,这两个制约原则在评估器中的顺序为:Lenition>Parse。生成器所产生的3种音节种类为,(V)CV,(V)GV,以及(V)V(括号内为上一音节结尾音,均为开音节),经过筛选,结果只有第二种违反的原则最为少,且非关键,成为优胜者,具体过程如表1所示:
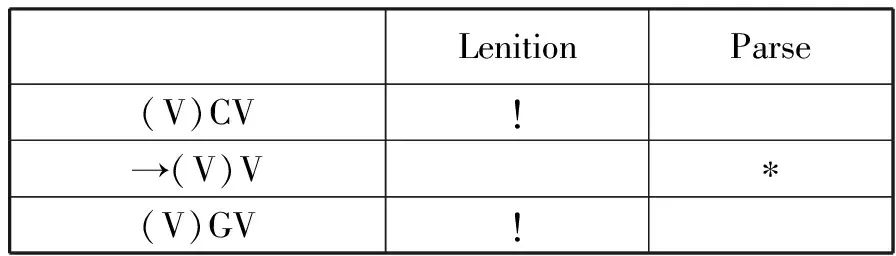
表1
根据表1的描述,第一种音节种类(V)CV和第三种音节种类(V)GV,均违反了弱化原则,使得说话者发声时省力原则未能得到满足,而第二种音节种类违反了Parse原则,但是因为符合阶层更高的弱化原则(V)V,因此,在评估器中胜出。
(三)重音(Stress)
1.重音特点
拉迪福吉德(Ladefoged)指出,重音是指音高、音量以及音长三个参数的综合指称[7](P250)。但在大量的实践中发现,音高的最大值和音量的最大值并不一定出现在音强最大值的同一位置,如图11所示,最大音强出现在0.434553秒处,最高音调出现在2.102344秒处。因此,重音采用单指音强这一个参数的概念,方便与音调研究的参数作出区别,避免研究参数重合所产生的混淆。音强是指单位声波上所承载的能量,通常用瓦特作为单位。
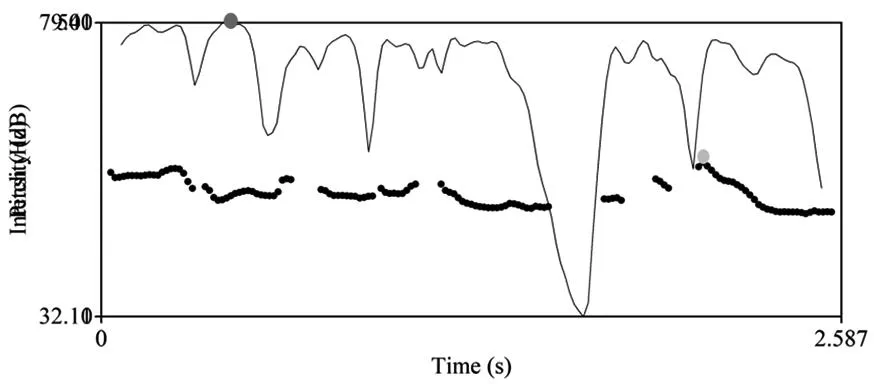
图11
“前后比”的概念用来描述句重音出现,它是指从句首开始计算音节数,承载音强最大值的音节所在的序列位置与从句末开始计数承载音强最大值的音节所在的序列位置所形成的比。前后比越低,说明句重音出现的位置越靠前,前后比越高,说明句重音出现的位置越靠后,前后比为1时,说明句重音出现在语句的中间位置。
研究中的60个方言对测试语句的句重音位置如图12所示,平均值为0.587155,没有任何片区方言整体的前后比超过1,说明各方言整体对实验语句的句重音位置较为靠前,处于实验语句的前半部分。徐淮片区方言的前后比最低,为0.25555,因此,徐淮片区方言的句重音位置最为靠前;商埠片区方言的前后比最高,为0.826375,因此,商埠片区方言的句重音位置最为靠后。
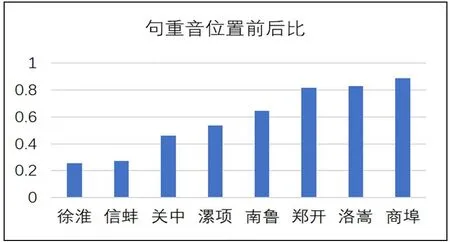
图12
2.特点成因分析
从优选论的角度对句重音的位置确定过程进行分析,对该语言现象提出了评估器的参数应为两个,分别是重音最左原则和音节重量原则。重音最左原则要求句子的重音音节尽可能地出现在语句的最左边,而音节重量原则要求重音的位置的选取,相较于轻音节更倾向于落在重音节上。因此,这两种原则施加在一起的合力决定了最终的重音位置。根据实验中60个方言的重音位置,对评估器中的这两种参数提出以下运行层次排序:Heavy syllable>Left edged。
又根据60个方言的重音位置,生成器中所产生的候选项种类应为以下5个,“你”“床”“打”“不”和“今”,具体运算过程如表2。
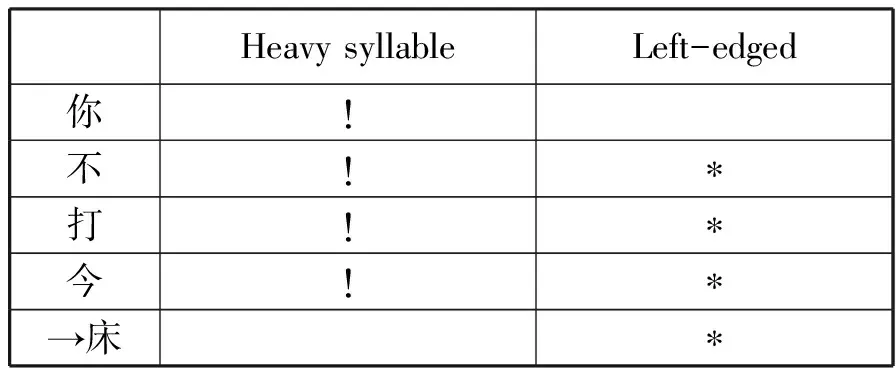
表2
根据表2所示,例如,在巩义方言中,句重音的位置落在了“床”这个音节上。以下是其具体分析过程:因为“你”所含的元音音长相对较短,发音舌位比较高,开口较小,与其他4个音节相比相对偏轻,因此,在评估器中由于违反了第一个原则而首先被筛选掉;其次,“不是”“打算”和“今儿”均以中元音结尾,因此,元音长度和开口度虽比“你”明显,但是相较于“床”字的音节核是低元音加后鼻音(Low V-N)的组合形式,强度相对较弱,因此,“床”在评估器中违反了第二个原则,未违反第一个原则,从而在整个筛选过程中胜出。
四、方言类型图
根据以上对河南区域的60个中原官话的县区方言特征的数据,应采用欧式距离的方法来衡量方言之间的相似度。欧氏距离是计算在n维空间中两个点之间的真实距离,或者向量的自然长度,因此适合测量在高维度空间内两点之间的几何距离。
选用欧式距离是因为如果要对每种方言从5个不同维度进行了考察,即是将每个方言放置于一个5维的空间之内,每个方言在这个空间内所构成的坐标中形成了一个位置,位置到位置之间的距离就是方言之间的距离。这个5维欧氏空间,组成了一个位置集,它的每个位置 X 可以表示为 x1,x2,…,xi,其中 xi(i = 1,2,…,60)取值范围为整实数,表示实验所涉及的60个方言。那么两个点 XA和XB之间的距离等于点A的5项参数a1,a2,a3,a4,a5和 点B的5项参数b1,b2,b3,b4,b5之间差值的平方和再开方,AB两点之间的欧式距离即为下面的公式:
两个方言之间的相似度越高,两点之间的欧式距离值就越小,方言之间的相似度越低,两点之间的距离就越大。具体各方言间的相似度结果如图13所示。
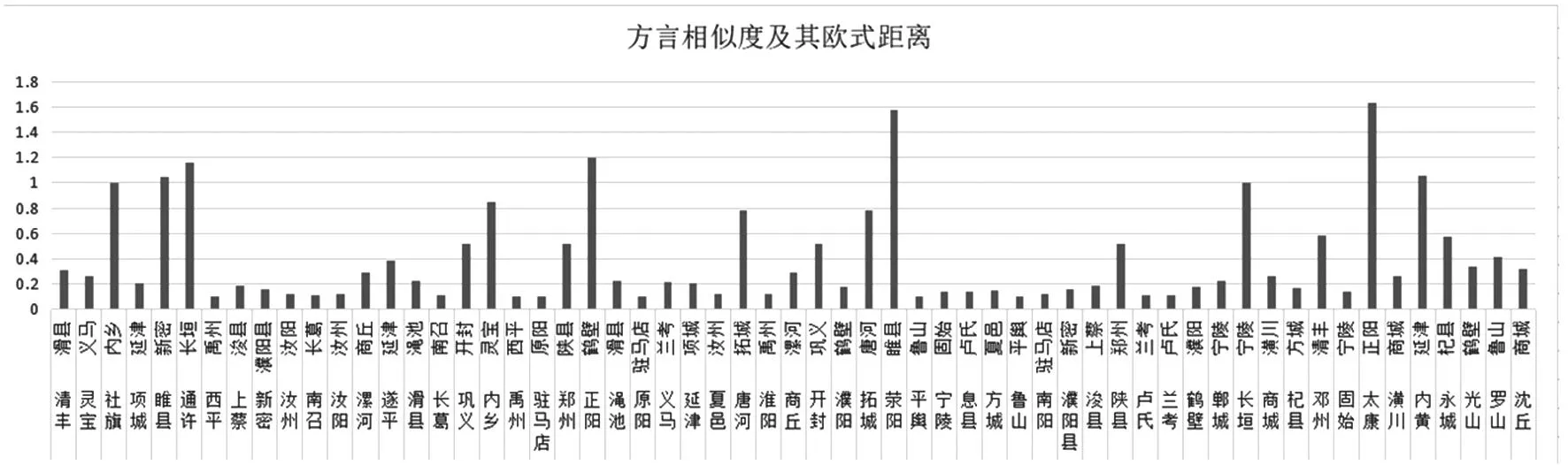
图13
首先,由图13可见,对于方言A欧氏距离最大的是方言B,而对于方言B而言,欧氏距离最小的不一定是A,相反,可能是另一方言C。例如,与清丰欧式距离最近的是滑县,与滑县欧式距离最近的是渑池。这两个结论之间存在差异的原因是,当以方言A为中心时,存在方言B为距离方言A的最小值,当以方言B为中心时,存在方言C距离方言B的最小值,而方言A此时并不是以方言B为中心时的最短距离方言。
其次,由图13可见,方言间的最小距离值差别较大。根据数值可得,各方言间的欧氏距离值范围在0-1.8之间浮动。与太康方言欧氏距离最大的是正阳方言,其欧式距离值达到1.6353,与鲁山方言欧式距离最小的是平舆方言,其欧式距离为0.0985,两个欧式距离之间的差距值为1.5368,此数值近似于位于具有最大欧氏距离最小值第二位的荥阳方言与睢县方言之间距离值1.5792。根据图13的数据,为说明各方言之间相似度间的差异,各方言间的欧氏距离最小值的波动与离散程度采用标准差的方式来显示,各方言间的欧氏距离最小值的平均数为0.3925,标准差为0.3794(数据均保留小数点后4位)。由此可得,由于数据离散距离相对较大,因此各方言之间相似度间存在较大的差异。
猜你喜欢
厦门大学学报(哲学社会科学版)(2021年5期)2021-12-21
艺术家(2020年5期)2020-12-07
快乐作文(1.2年级)(2019年9期)2019-09-10
疯狂英语(双语世界)(2017年1期)2017-07-01
北方音乐(2017年4期)2017-05-04
西藏大学学报(自然科学版)(2016年1期)2016-11-15
语言与翻译(2015年4期)2015-07-18
大众文艺(2015年5期)2015-01-27
湖北科技学院学报(2014年6期)2014-07-12
中国音乐教育(2014年11期)2014-05-18
