
基于Transformer 的多方面特征编码图像描述生成算法
2023-02-20 09:39衡红军范昱辰王家亮
计算机工程 2023年2期
衡红军,范昱辰,王家亮
(中国民航大学 计算机科学与技术学院,天津 300300)
0 概述
图像描述是将图像的视觉内容转换为符合人类描述习惯的自然语言语句的任务,是一项结合计算机视觉和自然语言处理的多模态任务。图像描述的挑战不仅存在于识别图像中目标与目标之间的关系,而且还存在于不同模态下实现相同语义的转换以及生成人类描述习惯的句子。
现有的图像描述生成方法有基于模板的方法[1-2]、基于检索的方法[3]和基于编码-解码的方法。目前主流图像描述方法倾向于采用基于神经网络的编码器-解码器结构[4-7]。早期图像描述的编码器-解码器结构使用卷积神经网络(Convolutional Neural Network,CNN)作为编码器对输入图像进行编码,使用循环神经网络(Recurrent Neural Network,RNN)作为解码器对编码器产生的结果进行解码。这些方法模型都由一个图像I作为模型的输入,每个时间戳产生的单词的概率P(S|I)作为模型的输出,最终生成的句子S={W1,W2,…,Wn}为图像描述语句。
现有的图像描述模型多采用原始图像或对原始图像进行目标检测得到的目标特征向量作为模型输入,这2 种方案均致力于更加准确地描述图像内的关键目标,但却造成了对图像内部其余信息(图像背景信息、目标之间的关系信息等)的获取缺失,导致生成的图像描述存在误差和局限性。
为了在准确描述图像内部目标的同时对图像内部目标之间的关系进行合理表达,本文提出一种结合目标Transformer 和转换窗口Transformer 的联合编码模型。对于给定图像,采用本文提出的目标Transformer编码器编码目标视觉特征,同时使用转换窗口Transformer编码器编码图像内部关系特征。本文采用拼接方法将视觉特征与编码后的图像内部关系特征进行融合,并对融合后的编码向量使用Transformer 解码器解码,最终生成对应图像内容的描述。
1 相关工作
2014年,谷歌提出了Neural Image Caption Generator[5],这是一个使用CNN 作为编码器、RNN 作为解码器的神经网络模型,展现出了良好的性能。随着研究的深入,研究者发现人类观察图像中的内容时,会从复杂的图像内容中找出关键点,并将注意力集中于此,因此,研究者基于人类注意力机制启发,设计了加入视觉注意力机制的神经网络模型[8]用于图像描述。注意力的加入使模型可以选择性地关注图像的特定区域,而不是无偏好地关注整个图像。JIASEN等[9]注意到在生成描述过程中并非每个单词均来源于图像,也有可能来源于已生成的描述本身(如一些介词、连词的生成),因此设计了自适应注意力(adaptive attention),让模型自行选择应关注于图像还是描述语句。随着目标检测精度的提升,ANDERSON等[10]提出了一种目标检测引导的注意力机制,它被证明可以提高图像描述的准确率。
综上所述,图像描述任务的研究由刚开始对图像的无偏关注,到加入注意力机制的辅助,再到目标检测方法的加入,研究者一直致力于对图像内目标内容的精确识别。但对于图像描述任务,不仅仅需要准确描述目标,更需要对目标之间的互动关系进行准确表达,如果目标之间的互动关系表达错误,则会造成描述与图像内容严重不符。
2017年,谷歌提出了Transformer 模型[11],用于解决Seq2Seq(Sequence to Sequence)问题。Transformer模型也遵循编码器-解码器架构,但模型中编码器和解码器没有使用卷积、池化等网络架构,而是完全依靠自注意机制的并行化架构来捕捉序列依赖。Transformer在自然语言处理(Neural Language Processing,NLP)任务中取得了优异的成绩,但在计算机视觉领域的表现却不尽如人意。研究者一度认为Transformer模型并不适用于计算机视觉任务,直至ViT(Vision Transformer)[12]模型的出现,才使研究者重新聚焦于Transformer 相关模型。经过长期实践证明,Transformer 在计算机视觉领域也能取得比传统CNN 模型更强的性能。2021年,微软亚洲研究院提出了Swin Transformer[13],其结果比ViT 更好,并明显优于CNN 模型,这进一步提升了Transformer在计算机视觉领域的应用。通过实验研究发现,Swin Transformer 不仅在图像分类任务中表现出色,而且在计算图像内部的关系方面也有良好的效果。
得益于Transformer近几年在自然语言处理领域和计算机视觉领域的突出表现,本文借鉴Swin Transformer和基于编码器-解码器框架的ViT 的原理,使用与Transformer 相关的多头注意力机制来处理图像特征并生成与图像对应的描述。本文模型总体架构如图1所示,其具有如下特点:1)使用目标Transformer 对目标检测得到的局部目标特征进行编码;2)使用转换窗口Transformer 对整张图像内容进行编码,用于编码图像内部潜在的关系信息;3)在解码过程中,使用Transformer 解码器代替传统的RNN 解码器。

图1 本文模型简要结构Fig.1 Brief structure of the proposed model
2 多方面特征编码
为了提高图像描述的准确性,本文从融合不同方面特征表示的角度出发,重新设计了网络结构,如图2所示。2.1 节介绍了目标Transformer 编码器对目标特征进行编码的方法;2.2 节介绍了转换窗口Transformer对图像内部关系特征进行编码的方法,2.3 节介绍了特征融合以及Transformer 解码器的解码方法。

图2 本文模型详细结构Fig.2 Detailed structure of the proposed model
2.1 目标Transformer 编码器
首先使用Faster R-CNN[14]对图像I进行检测得到图像的k个区域特征{r1,r2,…,rk},每个图像特征向量首先通过一个嵌入层进行处理,该层通过一个全连接层将特征向量的尺寸从2 048 维降至512维,然后通过一个ReLU 激活函数和Dropout 层处理后生成的向量作为目标Transformer 编码器的输入向量。
目标Transformer 编码器共有6层,每层由一个多头注意力层和一个前馈神经网络组成。集合{x1,x2,…,xN}为经过目标检测并嵌入后的N个目标特征向量的集合,xn表示为经过目标检测并嵌入得到的第n个目标所对应的特征向量。所有经过目标检测并嵌入得到的特征向量所拼接成的矩阵作为第1 个编码层的输入,第2~6 个编码层均使用前一层编码层的输出作为输入。对编码层中的每个多头注意力层,每一层中“头”的数量设为8,为N个特征向量分别计算查询向量Qo、键向量Ko和值向量Vo,计算方法如式(1)所示:

其中:X为包含所有的输入{x1,x2,…,xN}所拼接成的矩阵;WQo、WKo、WVo为可学习的权重矩阵。
不同的2 个目标区域之间的相关性分数计算方法如式(2)所示:

Ωo为形状为N×N的权重矩阵,其中的元素ωmn表示为第m个特征区域和第n个特征区域之间的相关性得分。本文对dk的设定与文献[11]中相同,设为64,代表查询向量、键向量和值向量的维度。
多头注意力的计算方法如式(3)所示:

由于本节将多头注意力中“头”的数量设置为8,因此需要通过式(1)~式(3)重复计算8 次来分别表示8 个“头”。计算完成后,将各个“头”矩阵拼接后与可学习的参数矩阵Wo相乘。多头注意力计算方法如式(4)所示:

残差结构和层归一化方法均被应用在多头注意力层和前馈神经网络层中,如式(5)~式(7)所示:

式(5)中的参数X为当前层的输入数据X,最终得到的X作为当前编码层的输出。式(6)和式(7)表示将多头注意力层的输出X输入至前馈神经网络进行计算的计算方法,其中W1、W2和b1、b2分别为可学习的权重和偏置量。
2.2 转换窗口Transformer 编码器
由于Swin Transformer[13]在目标检测及语义分割任务中均有出色的表现,其中Shift Window 操作可以实现不同窗口内信息的交互,因此本文基于Swin Transformer 的Shift Window思想,设计转换窗口Transformer 编码器。
如图3 所示(彩色效果见《计算机工程》官网Html版),在转换窗口Transformer 编码器中,每个转换窗口Transformer 模块中含有2 个子模块,分别为窗口多头注意力模块和转换窗口多头注意力模块,与目标Transformer 的设定相同,为减小训练训练误差并消除奇异样本数据,残差结构和层归一化方法均被应用与多头注意力模块和转换窗口多头注意力模块。

图3 Shift Window 方法示意图Fig.3 Schematic diagram of Shift Window method
为提高计算效率,本文以不重叠的方式将输入图像均匀地分割为多个窗口,只在局部窗口内计算自注意力。这样就导致了窗口之间缺乏信息交互,因此,本文将Swin Transformer 模型中的Shift Window 的思想引入转换窗口Transformer 编码器。
如图3 所示,基于窗口的多头注意力模块采用正常的窗口划分策略,将一个大小为8×8 的图像均匀地分为2×2 个大小为4×4(M=4)的窗口。为了实现窗口之间信息的交互,本文使用了Shift Window的方法,将像素从规则划分的窗口中循环替换,实现窗口间内容的交互。在这种转换之后,一个局部窗口内可能有图像中的图连续像素块组成,因此采用了遮盖机制,将自注意力的计算限制在每个子窗口内。
在转换窗口Transformer中,以图像矩阵作为输入,首先通过图像分割层进行处理,窗口集合{y1,y2,…,yM}为输入图像中均匀划分的M个子区域而构成的集合,ym代表第m个划分的子区域对应的特征向量。为M个窗口子区域分别计算查询向量Qsw、键向量Ksw和值向量Vsw,计算方法如式(8)所示:

其中:Y为包含所有的输入窗口子区域特征向量{y1,y2,…,yM}所拼接成的矩阵;WQsw、WKsw、WVsw为可学习的权重矩阵。
2 个窗口子区域之间的相关性分数计算方法如式(9)所示:

Ωsw是一个形状为M×M的权重矩阵,其中的元素ωmn表示第m个窗口子区域和第n个窗口子区域之间的关系得分。d的值为查询向量与键向量之间的维度比,表示为dim(Qsw)/dim(Ksw)。
计算自注意力的方法与目标Transformer 不同,如式(10)所示:

其中:参数B的含义为窗口子区域之间的相对位置偏置量。本文中对B的设定与文献[13]中相同,存在一个偏差矩阵,B的值取自。
如图2 所示,转换窗口Transformer 存在2 个子转换窗口Transformer 模块,本文将2 个子转换窗口Transformer 模块的“头”的数量分别设定为6 和12 并进行计算,多头注意力计算方法如式(11)所示:

其中:N为“头”的数量;Wsw为可学习的权重矩阵。
转换窗口Transformer 也使用了残差结构和层归一化方法,其方法与2.1 节目标Transformer 所介绍的方法相同,因此不再赘述。
2.3 Transformer 解码器
对于目标Transformer 编码器编码的目标特征向量X和转换窗口Transformer 编码器编码的关系特征向量Y,本文采用向量拼接的方式将2 个特征向量进行融合,如式(12)所示:

如图4 所示解码器结构,编码结果F作为解码器的一部分输入用于计算解码器中的键向量KD和值向量VD,计算方法如式(13)所示:

图4 Transformer 解码器结构Fig.4 Transformer decoder structure

其中:WKD、WVD为可学习的权重矩阵,而查询向量QD需要将之前时间戳生成的单词经过嵌入后计算多头注意力得到。在此基础上,将得到的解码器查询向量QD、键向量KD和值向量VD计算多头注意力后送入前馈神经网络产生输出,计算多头注意力的方法与2.1 节中目标Transformer 的多头注意力计算方法完全相同,因此不再赘述。值得注意的是,解码器在训练过程中对输入单词采用遮盖方法计算多头注意力,这是因为使用了Ground Truth 中包含即将生成的未来信息,而在实际生成文本描述语句过程中是无法预知的,因此使用遮盖机制保证训练与测试过程的一致性。
对于解码器的输出,经过一个线性层扩展至词汇表长度后输入Softmax 分类层进行分类得到当前时间戳的输出单词,计算方法如式(14)所示:

其中:Woutput表示解码器解码结果;Wnew为当前时间戳生成的单词。接下来会一直重复解码过程,直至解码结果与单词表中结束符一致,代表该模型对当前图像的文本描述语句生成完毕。
3 实验结果与分析
3.1 数据集与实验环境
为了评估本文所提方法的有效性,采用MSCOCO 2014(Common Objects in COntext 2014)[15]数据集进行实验。MSCOCO 数据集可以用于图像分类、目标检测、语义分割、图像描述等任务。数据集中包含91 类目标、328 000 余张图像和2 500 000 余个标签。本文采用文献[6]中对数据集的划分方法将数据集分为训练集、验证集和测试集,其中包含11 300余张训练图像、5 000张验证图像和5 000 张测试图像,每张图像对应5 句英文描述性语句。
实验环境使用Ubuntu 18.04 64 位系统,采用PyTorch深度学习框架进行训练和测试,硬件配置为Intel i9-9900k CPU,Nvidia RTX 2080TI 显卡(11 GB 显存)。
3.2 评价指标
为了对本文算法模型的有效性和先进性做出合理评估,实验采用被广泛应用于图像描述的4 个客观量化评分方法:BLEU-4(BiLingual Evaluation Understudy 4-gram)[16],CIDEr(Consensus-based Image Description Evaluation)[17],METEOR(Metric for Evaluation of Translation with Explicit ORdering)[18],ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation-Longest common subsequence)[19]。
3.3 模型主要参数设置
在实验中,首先对图像数据进行预处理,按照RGB格式读取图片,将图片调整大小为224×224 像素,使用Imagenet[20]上预训练的ResNet-101[21]作为基础的CNN进行图像的特征提取,使用Faster R-CNN[14]进行目标检测。使用ResNet-101 的中间特征作为Faster R-CNN的输入,RPN(Region Proposal Network)为识别的目标生成边界框,使用非最大抑制法丢弃IoU(Intersectionover-Union)超过阈值0.7 的重叠边界框,然后使用Rol(Region-of-Interest)池化层将所有的边界框特征向量转换为相同维度,剩余的CNN 层被用于预测标签和细化每个边界框,最终将所有预测概率值低于阈值0.2 的边界框丢弃,使用平均池化的方法为剩余的每一个边界框生成一个2 048 维的向量作为目标Transformer 编码器的输入。将调整大小后的图像作为转换窗口Transformer 编码器的输入,并将转换窗口Transformer中划分窗口的长宽值大小设定为4 个像素。
实验将语料库规模设为出现频次超过5 次的单词并对语料库中的单词进行独热(one-hot)编码。分批处理图像时,单次输入图像batch size 数量设为10。使用Dropout舍弃单元来提高模型在数据集上的泛化能力,并将Dropout值设为0.1。在模型训练过程中使用集束搜索的方法,将beam 的值设为3,同时使用交叉熵损失和文献[22]中提出的CIDEr-D 优化强化学习方法,定义训练轮次数为50轮,前30 轮使用交叉熵损失进行训练,后20轮使用CIDEr-D优化强化学习方法进行训练。本文使用PyTorch 自带的Adma(Adaptive Moment Estimation)网络优化算法,其中将β1和β2的值分别设置为0.9 和0.999。
3.4 消融实验
3.4.1 Transformer 结构有效性分析
为验证本文采用的Transformer 结构相较于CNN、RNN相关结构的先进性,将本文方法与经典的Up-Down算法[10]进行比较。使用控制变量的思想设计以下消融实验:1)将编码器替换为目标Transformer;2)目标Transformer 与ViT 的组合和目标Transformer 和转换窗口Transformer 的组合,将LSTM 解码器替换为Transformer解码器;3)本文方法,即使用目标Tranformer以及转换窗口Transformer 联合编码结构;4)在本文方法基础上使用beam size 为3 的波束搜索。在相同数据集、相同训练条件下,使用交叉熵损失对模型训练30轮,结果如表1 所示。可以看出,将编码器和解码器分别替换为Transformer 结构之后,各项指标均有所提升。

表1 使用不同编码器和解码器的消融实验结果对比 Table 1 Comparison of ablation experiment results by using different encoders and decoders %
3.4.2 转换窗口Transformer 有效性分析
为验证转换窗口Transformer提取关系信息的有效性,在实验中使用无位置编码的方法和按照目标边界框由大到小进行位置编码的方法与转换Transformer编码器进行比较。在相同数据集、相同训练条件下,使用交叉熵损失对模型训练30轮,结果如表2 所示。可以看出,通过转换窗口Transformer获取全局特征的方法,最终的到评价指标CIDEr 的值明显高于无位置编码和按边界框由大到小进行编码的方法。
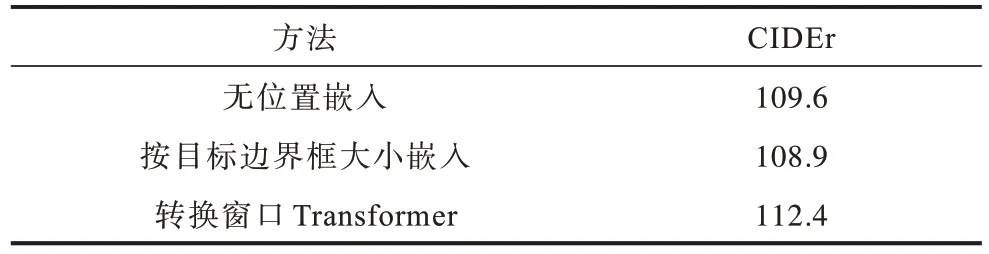
表2 不同位置嵌入方式与转换窗口Transformer 编码方式消融实验结果对比 Table 2 Comparison of ablation experiment results between different embedding methods and shift window Transformer encoding method %
3.5 实验结果对比与分析
3.5.1 定量分析
本文算法与Google NIC(Google Neural Image Caption)[5]、Soft-Atten[8]、Hard-Atten[8]、Deep VS(Deep Visual-Semantic alignments)[6]、MSM(Multimodal Similarity Model)[23]、AFAR(attention feature adaptive recalibration)[24]、ASIA(Attention-guided image captioning)[25]、GO-AMN(Gated Object-Attribute Matching Network)[26]算法的对比结果如表3 所示。可以看出:本文算法的CIDEr达到127.4%,BLUE-4 达到38.6%。METEOR 达到28.7%,ROUGEL 达到58.2%。在相同的数据集、相同的训练条件下,本文算法的性能指标得分最高。

表3 不同图像描述算法的实验结果 Table 3 Experimental results of different image description algorithms %
3.5.2 定性分析
在模型训练完成后,选取测试集中的图像结果与基线模型Up-Down 模型的实验结果以及数据集中给出的标准描述语句作比较,如图5 所示。可以看出,Up-Down 模型生成的描述和图像内容具有一定的关联性,在逻辑上是正确的,而本文提出的模型得到的结果对于图像细节和图像内目标之间的关系描述更加准确生动。例如,在第3 幅图中Up-Down模型生成的“holding a tennis ball”内容与图像内的视觉信息并不一致,而本文模型生成的“swinging a tennis racket at a tennis ball”对图像内的视觉信息的描述更加准确,把图像内目标之间的关系描述得更加生动,再次证明了本文提出的算法捕捉图像内目标之间关系的有效性。

图5 生成结果定性对比Fig.5 Qualitative comparison of generation results
4 结束语
本文设计了基于转换窗口Transformer的图像描述生成算法。该算法使用目标Transformer 和转换窗口Transformer 2 个编码器,分别对Faster R-CNN 目标检测提取的图像和整张图像编码后进行特征融合,以Transformer 解码器代替传统RNN 模型。本文算法的图像描述效果以及BLEU-4、CIDEr、METEOR、ROUGEL等评价指标,相较于基线模型都取得了较高的得分,其中BLEU-4 和CIDEr 得分达到了38.6%和127.4%。实验结果表明,本文提出的转换窗口Transformer 方法提高了模型的图像内部关系识别能力,提升了描述的准确性,提高了模型的泛化能力。下一步工作是利用Shift Window 方法的优良性能显式地提取图像的内部关系,明确图像内所含关系的具体信息,进一步提高图像描述模型的内部关系表达能力。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
网络安全与数据管理(2022年1期)2022-08-29
保定学院学报(2022年2期)2022-04-07
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
