
基于改进YOLOv5 的路面病害检测模型
2023-02-20 09:38王朕李豪严冬梅竺永荣
计算机工程 2023年2期
王朕,李豪,严冬梅,竺永荣
(1.天津财经大学 理工学院,天津 300222;2.天津市交通科学研究院 智能交通研究中心,天津 300060)
0 概述
路面病害检测是评价道路养护的一项重要任务。路面病害的存在会损害路面结构,降低行车速度,缩短道路运营时间。严重的路面病害还会削弱路基承载力,形成路面坍塌,影响交通安全,造成交通经济损失。因此,快速准确地获取路面信息和定期道路养护尤为重要。传统的路面病害检测主要以人工视觉检测为主,存在检测效率低、主观性强等缺点[1]。随着计算机技术的不断发展和硬件设备的不断优化,利用深度学习进行路面病害检测的方法准确率和速度明显提升,具有很强的自适应性和鲁棒性[2]。
基于深度学习的路面病害检测方法无须人工提取路面病害特征,计算机能够通过卷积神经网络进行特征提取并学习目标特征,从而完成检测与分类的任务[3]。常用的基于深度学习的路面病害检测方法有基于区域建议的二阶段预测方法(如R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]、Mask R-CNN[7]等)和基于回归分类的一阶段预测方法(如YOLO[8]、SSD[9]等)。
基于区域建议的二阶段预测方法将检测任务分为病害位置信息定位和病害类别检测2 个阶段进行。GOU等[10]受Faster R-CNN 模型的启发,将区域建议网络和特征提取网络相结合,提出改进Faster R-CNN 的路面裂缝检测算法。文献[11]将Mask RCNN 作为主干框架,通过融入ResNet 结构与特征金字塔网络(Feature Pyramid Network,FPN)提升对病害特征信息提取的准确度,并基于此构建针对裂缝病害识别的检测模型,在复杂背景下实现了对裂缝病害特征的高效识别。
基于回归分类的一阶段预测方法将目标边界框大小预测和目标类别判断合并到单个神经网络中,实现了高准确率的快速病害检测定位与分类[12]。文献[13]将YOLOv3 网络应用到路面裂缝检测研究中,设计了一种基于YOLOv3的路面裂缝检测方法,并对采集的图片进行手动标记,通过YOLOv3 网络训练出实时且准确率较高的路面裂缝检测模型。文献[14]将YOLOv4 作为路面裂缝检测基础模型,在对IEEE 大数据挑战赛提供的公共道路裂缝数据集RDD-2020 作适当数据增强后,训练出一个能够识别多种复杂裂缝类型的道路裂缝检测与分类模型。文献[15]针对复杂环境干扰导致裂缝检测困难的问题,通过在主干特征提取网络中添加可变形卷积,提出一种可变形SSD 的新网络来实现对路面裂缝的高精度实时检测。
在自然语言处理中,Transformer作为主要的应用模型不仅可以提取特征,而且还可以实现多模态融合[16]。因此,构建一种卷积神经网络(Convolutional Neural Network,CNN)和Transformer 结构交融的网络来完成病害检测任务也成为当下的研究热点。文献[17]提出视觉Transformer(Vision Transformer,ViT)证明,通过将图像视为一系列Patch,Transformer结构也可以直接应用于图像,其在图像识别任务中的性能与CNN相当。文献[18]提出了基于Transformer的目标检测网络Swin Transformer,通过引入CNN中常用的层次化构建方式构建层次化Transformer,并引入局部性思想对无重合的窗口区域进行自注意力计算,从而获得高效的检测性能。这些研究促进了路面病害检测的进一步发展。
然而,现有方法在处理路面病害检测任务上还存在一些缺陷,例如:高速沥青路面病害不如混凝土路面病害特征明显,特征提取困难;其他路面对象(如裂缝表面修补和路面标线)的干扰,以及横向、纵向、龟裂等裂缝类别之间的干扰会增加检测难度;现有的路面病害检测数据集干扰较小,不能满足复杂环境下裂缝检测的需要。为应对这些挑战,本文提出基于改进YOLOv5 的路面病害检测模型YOLOv5l-CBF。针对主干网络病害特征提取不足的问题,引入坐标注意力(Coordinate Attention,CA)机制[19]来增强模型对感兴趣区域的特征提取。同时,将多头自注意力(Multi-Head Self-Attention,MHSA)整合到顶层C3模块中构建CTR3 模块,以提取更多差异化的特征,提高对病害特征的识别度。在此基础上,在颈部网络构建优化的双向加权特征金字塔网络(BiFPN)[20],加强多尺度特征图之间的融合,实现对路面病害高精度的自动化检测与分类。
1 YOLOv5l-CBF 路面病害检测模型
1.1 YOLOv5l 网络模型
对于YOLOv5 目标检测模型,官方给出了4 种网络模型结构:YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x[21]。这4 种结构通过调整相关参数来控制网络的深度和宽度,网络架构都可以概括为输入端(Input)、主干网络(Backbone)、颈部网络(Neck)和预测层(Prediction)[22]等4 个部分。其中:输入端将输入图像的大小统一成固定尺寸;主干网络负责从输入图像中提取关键特征;颈部网络主要利用特征金字塔网络对提取到的图像特征进行融合;预测层的作用是生成含有特征映射的锚框,输出带有检测类别名称和概率的边界框。
本文结合路面病害自动化检测需求,选择网络深度和特征图宽度适中的YOLOv5l_v5 模型作为路面病害检测模型的主体。合适的模型大小和卷积核数量可保证训练后的权重文件能够实现对路面病害高精度的自动化检测。
1.2 坐标注意力机制
为了从众多特征信息中获取对路面病害检测任务起到关键作用的信息,提高图像处理的准确性和效率,笔者拟在特征提取网络中引入注意力机制来提高病害检测性能。然而在现有研究中,大部分注意力机制对于位置信息和通道信息关注较少。由于混合域的注意力机制可以同时考虑位置信息和通道信息[23],因此本文利用混合域的坐标注意力机制获得图像中病害的位置信息和通道关系,并将病害位置信息嵌入通道中,使网络能够获取更多区域的信息,提高网络对于病害特征的提取能力。坐标注意力模块如图1 所示。
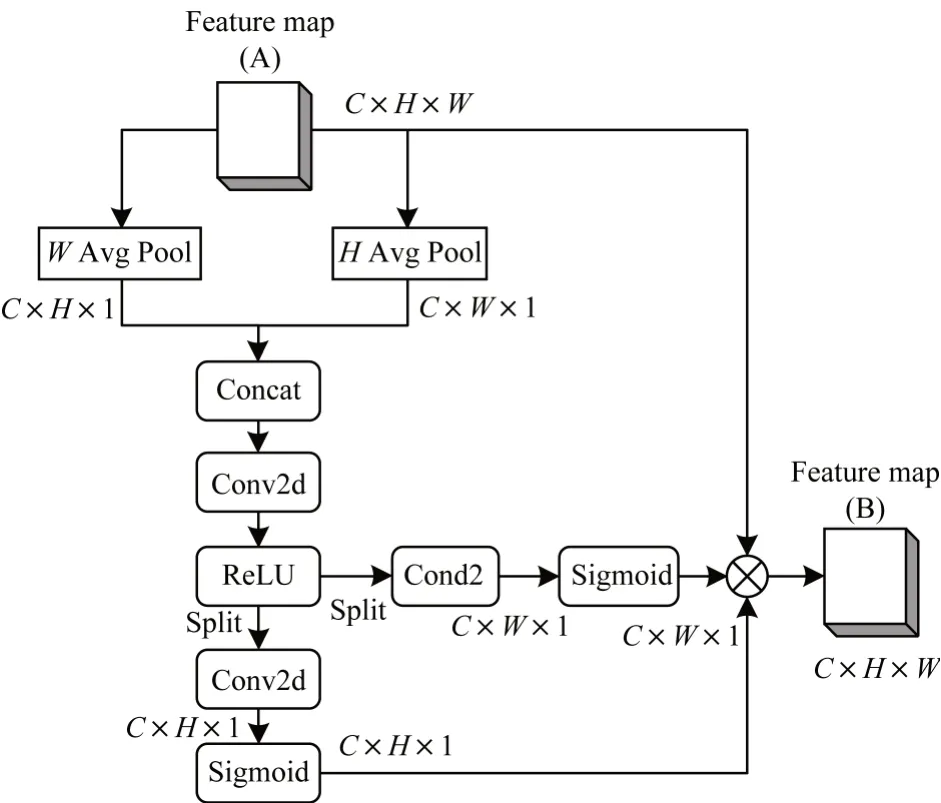
图1 坐标注意力模块Fig.1 Coordinate attention module
坐标注意力模块通过坐标信息嵌入和坐标注意力生成2 个阶段来编码通道关系和长期依赖关系。
1)坐标信息嵌入
设定输入特征图A 的维度为C×H×W。使用2 个空间范围为(H,1)和(1,W)的平均池化分别沿水平方向和垂直方向对每个通道进行编码。高度为H的第c个通道和宽度为W的第c个通道平均池化后的输出如式(1)和式(2)所示:

2)坐标注意力生成
式(1)和式(2)这2 种变换分别沿2 个空间方向聚合特征,得到一对方向感知特征图(i)和(j),然后在完成Concat 连接、Conv2d 卷积和ReLU 激活后生成在水平方向和垂直方向编码空间信息的中间特征图f,如式(3)所示:

其中:[,]为Concat 连接;F为1×1 的卷积运算;δ为ReLU 激活函数;f为ReLU 层输出的特征图。在沿空间维度将f拆分为2 个单张量fH和fW后,分别使用卷积核大小为1 的卷积运算和激活函数完成对H和W方向的加权,输出如式(4)和式(5)所示:

式(4)中:Fi是沿H方向的卷积运算,输入为yi;σ为Sigmoid 激活函数;生成的wi是空间维度为H方向的自适应权重。式(5)中:Fj是沿W方向的卷积运算,输入为yj;生成的wj是空间维度为W方向的自适应权重。
坐标注意力模块输出的最终特征图B 如式(6)所示:
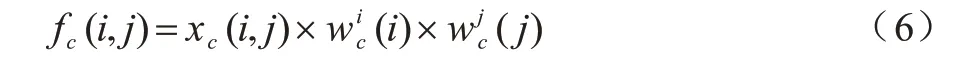
其中:c表示第c个通道;(i)为H方向第i个位置的权值;(j)为W方向上第j个位置的权值;(i,j)为输入特征图A 的值;fc(i,j)为输出特征图B 的值。
坐标注意力模块通过对输入的张量同时进行水平和垂直方向的感知,使其不仅关注了不同通道信息的重要性,而且还考虑了空间信息的编码。但是,在网络结构中不适当的位置添加注意力机制不但不能获得好的特征提取能力,反而会增加计算量和模型的参数量。如果在网络的开头部分添加注意力机制进行特征提取,由于提取的空间注意力通道数较少,概括性不足,且空间注意力敏感难学,更容易造成负面影响;如果加在网络太靠后部分,由于通道数过多,特征图太小容易引起过拟合,且使用卷积操作不当也会引入大比例非像素信息。因此,本文将坐标注意力机制嵌入到YOLOv5 主干网络的中间2 个C3 模块,帮助模型对重点关注区域进行特征提取,使模型对于病害的纹理特征信息更加敏感,从而提高对路面病害检测与分类的精度。融入坐标注意力机制的主干网络如图2 所示。

图2 融入坐标注意力的主干网络Fig.2 Backbone incorporating coordinate attention
1.3 Transformer 多头自注意力
高速路面图像中涉及的病害形态多样、种类众多,应提高图像中语义可分辨性并避免类别混淆,而从大邻域收集特征信息和关联场景信息有助于学习对象之间的关系。然而,卷积操作的局部性限制了捕获全局上下文信息的能力。相比之下,Transformer 不但能够从全局范围内关注图像特征块之间的依赖关系,而且还能够通过多头自注意力为目标检测保留更多的空间信息。为提高学习特征的可转移性,同时捕获上下文信息,本文提出使用多头自注意力替换顶层C3 模块中的3×3 卷积构建CTR3 模块,在二维特征图上实现全局自注意的形式处理并聚合特征图中的信息。CTR3 模块结构如图3 所示。
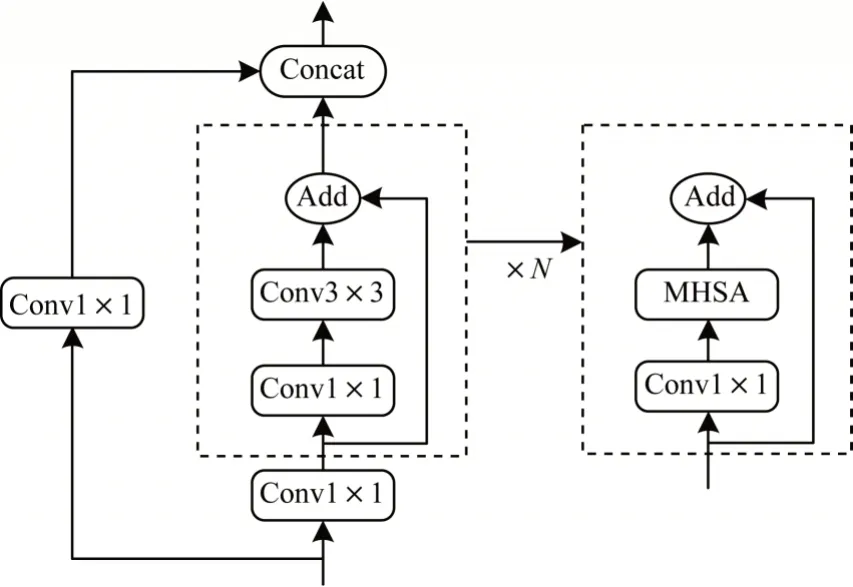
图3 CTR3 模块结构Fig.3 CTR3 module structure
为使用Transformer 机制处理平面图像,MHSA将二维特征图的空间维度X∈RH×W×d展开成一个Xp∈R(H×W)×d的序列。其中:(H,W)是原始特征图的分辨率;d是通道;H×W是作为Transformer 层的有效输入序列的长度。同时,MHSA 通过使用可学习的标准化一维位置嵌入方法来保留位置信息。虽然在Bottleneck 残差网络结构中使用了4 个多头自注意力层,但为了对结构进行简单描述,因此并不在图中展示出来。自注意力层结构如图4 所示。其中:qkT表示注意标记,q、k分别表示查询和关键字;⊕表示元素和;⊗表示矩阵乘法;1×1 表示逐点卷积。
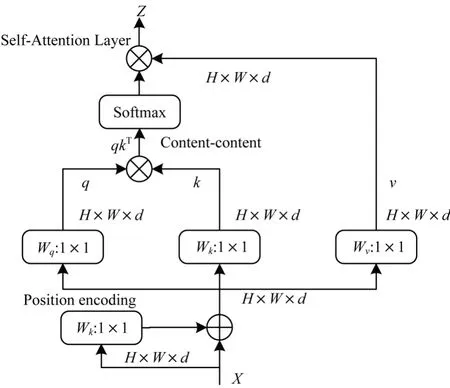
图4 自注意力层结构Fig.4 Self-attention layer structure
在YOLOv5 主干网络的顶部C3 结构中引入多头自注意层的原因在于:当网络相对较浅且特征映射相对较大时,会过早地使用Transformer 来强制执行回归边界,这可能会丢失一些有意义的上下文信息。因此,在改进的主干网络结构中,Transformer 层仅应用于P5而不是P3和P4。此外,考虑到在n个实体中全局的自我注意需要O(n2d)规模的内存和计算量[24],本文选择在主干网络中最低分辨率的特征图P5上合并自注意力。结合多头自注意力和坐标注意力后改进的YOLOv5l 主干网络结构如图5 所示。

图5 改进的YOLOv5l 主干网络结构Fig.5 Improved YOLOv5l Backbone structure
1.4 跨尺度连接和加权特征融合网络
路面病害图像中的物体大小变化很大,而卷积神经网络中单层的特征映射表示能力有限,因此,有效地表示和处理多尺度特征至关重要。目前常用的特征聚合网络结构以FPN+PANet 为主。因为FPN[25]是单向结构,所以PANet 额外增加了一条路径来加强特征融合,但是由于输入特征不同,因此它们对融合的输出特征做出的贡献通常也是不同的。BiFPN 在PANet 的基础上进行改进,对原始的FPN模块添加上下文信息的边,并对每个边乘以一个相应的权重,以便在不增加过多参数量的情况下融合更多的特征。常用的特征融合模块如图6 所示。
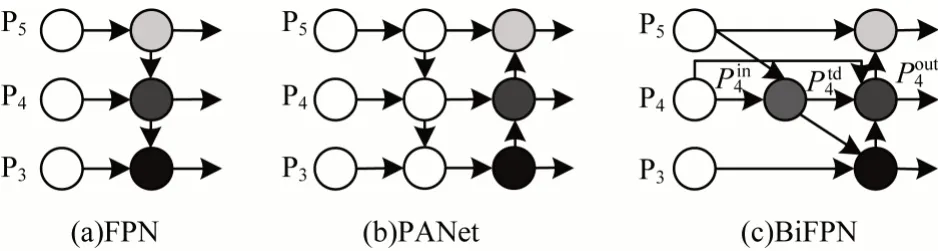
图6 特征融合模块Fig.6 Feature fusion module
图6(a)显示了传统的自顶向下FPN,其中Pi表示不同的特征层,分辨率为输入图像分辨率的1/2i。如果输入图像分辨率为640×640像素,则P3表示第3个特征层,图像分辨率为80×80 像素(640/23=80);P5表示第5 个特征层,图像分辨率为20×20 像素(640/25=20)。P5、P4、P3的输出如式(7)~式(9)所示:

其中:Resize 进行与对应层级分辨率相匹配的上取样或下取样操作;Conv 进行特征处理的卷积操作。
传统的自顶向下FPN 本质上受单向信息流的影响。针对这种情况,PANet 增加了一个额外的自底向上路径聚合网络,如图6(b)所示。但是不断地进行上采样和下采样操作会给网络带来较大的参数量和计算量。为了提高模型训练的效率,BiFPN 使用了跨尺度连接的方法,如图6(c)所示:首先基于PANet 去除那些只有一条输入边的节点,简化网络;然后在同一层次的2 个节点之间增加一条额外的边,以融合更多差异化的特征。
同时,本文提出了改进的加权特征融合方法,为每个输入添加一个权重,并通过不断训练调参来调整不同输入的融合权重,以找到每个输入的最优权重值。加权特征融合的计算方法如式(10)所示:

其中:wi≥0 是通过在每个wi之后施加ReLU 激活函数来保证的;同时将初始学习率ε设置为0.000 1,以避免数值不稳定。此处选择第一次迭代作为示例。式(11)描述了P4层的2 个特征融合过程:
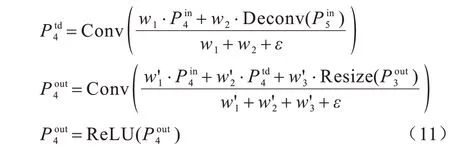
其中:为P4层的中间特征;为P4层的输出特性;通过下采样卷积操作与融合在融合后使用新的ReLU 激活函数激活,在每次卷积后进行权重的批量归一化。
为提高神经网络对病害目标的检测能力,本文在颈部网络构建双向加权特征金字塔网络。采用特征金字塔网络设计思想,通过自顶向下的上采样将高层网络中分辨率低、语义信息强的特征图放大,并与浅层网络中分辨率高、空间信息丰富的特征图进行融合,同时将浅层网络中的定位信息自底向上进行传递,增强整体网络特征层次,提高检测性能。相比于原YOLOv5 模型的PANet 结构,采用改进后的BiFPN 颈部网络能够获得更高效的特征融合和拟合能力,并能有效解决主干网络在道路病害目标检测中特征融合不充分的问题。改进的YOLOv5 网络结构如图7 所示。
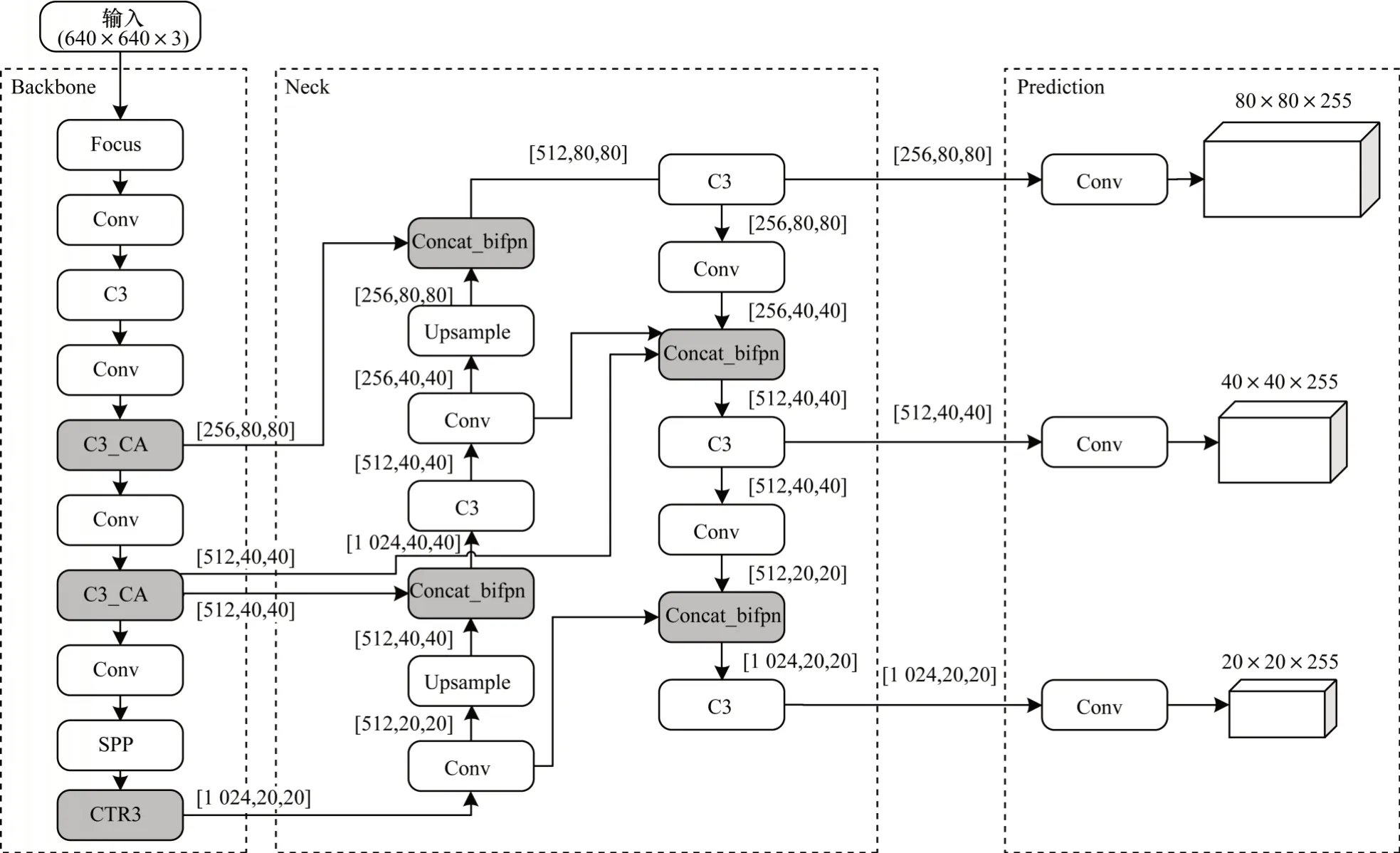
图7 改进的YOLOv5 网络结构Fig.7 Improved YOLOv5 network structure
2 路面病害数据集及模型训练
2.1 Crack_HW 数据集构建
2.1.1 数据来源
本文数据集包含来自天津市交通科学研究院提供的6 条高速公路的高清路面图像,每幅图像的分辨率为2 048×2 000 像素,由路面图像采集车分两车道对近300 km 的高速公路路面图像进行采集得到。数据集中同时还包含了由天津市交通科学研究院道路病害标注技术团队人工标注的病害标注文件,其标注过程严格参照交通运输部公路科学研究院发布的《公路技术状况评定标准》[26]为指导进行病害标注,标注信息包括路面类型、车道、病害类型、病害程度、标注位置、病害长度、病害宽度、病害面积等。
2.1.2 数据标注
要获得良好的病害检测与分类效果,构建一个高质量的数据集尤为重要。首先,本文通过建立一个包含8 071张图片的初始道路病害数据集Crack_HW01进行病害检测模型的选型,其中主要有5 种标注类型,分别是横向裂缝(C01)、纵向裂缝(C02)、龟裂(C03)、坑槽(C05)、修补(C07)。在天津市交通科学研究院提供的道路病害数据中共有7 种病害类型,还包括块状裂缝(C04)和松散(C06),由于这2 类病害数据图像稀少,因此本文主要实现对常见的5 种病害类型的检测。然后,对初始道路病害数据集Crack_HW01 进行病害标注质量的检查优化,同时增大数据量。优化后的数据集Crack_HW02 包含18 515 幅图像,实现了对5 种病害类型的高质量标注。由于Crack_HW02 数据集中对于龟裂、坑槽病害的标注数据较少,这也导致了模型对于这2种病害类型的泛化识别效果较差,平均准确率被拉低,因此在Crack_HW02的基础上继续清洗出包含龟裂、坑槽的图像加入到数据集中,最终的路面病害数据集Crack_HW包含19 233幅图像,其中有7 170个横向裂缝(C01)、12 133个纵向裂缝(C02)、836个龟裂(C03)、1 110个坑槽(C05)和1 256个修补(C07)。数据集统计信息如表1所示,部分路面病害图像如图8所示。

表1 数据集统计信息 Table 1 Dataset statistics information

图8 数据集部分样本图像Fig.8 Partial sample images of the dataset
2.1.3 数据增强
已有研究成果表明,适当的数据增强可以有效提升网络的训练效果,并使模型对来自不同环境图像的检测具有更高的鲁棒性。由于本文研究的图像来源属于高速路面直角拍摄,主要反映的是路面信息,没有复杂的背景干扰,且网络主要学习的是病害的纹理特征,因此对色彩度要求不高。所以,本文在调整色调、饱和度和亮度后将图像从RGB 空间转化到HSV 空间。除了使用常用的数据增强手段如图像平移、图像缩放、剪切、翻转外,本文还使用了独特的数据增强方法Mosaic。Mosaic 是一种新颖而有效的数据增强技术,它随机将4 幅训练图像按一定的比例拼接成一幅新的图像。使用Mosaic 数据增强技术能够丰富训练数据集,有利于优化检测器性能,避免过拟合。
2.2 RDD-2020 数据集说明
RDD-2020 数据集包含使用智能手机从印度、日本和捷克共和国收集的26 336 幅道路图像,其中有超过31 000个道路病害标注。数据集中包含对4种病害类型的标注,分别是纵向裂缝(D00)、横向裂缝(D10)、龟裂(D20)和坑槽(D40)。本文仅使用该数据集的训练集,共21 041 幅图像。对该数据集按照8∶1∶1 的比例划分后,训练集包含16 833 幅图像,验证集包含2 104 幅图像,测试集包含2 104 幅图像。
2.3 模型训练
本文实验环境基于Ubuntu18.04 操作系统,CPU 型号为Intel®CoreTMi7-10700,内存64 GB,GPU 型号为GeForce GTX 3070(8 GB 显存),使用PyThon3.7.0,深度学习框架PyTorch1.9.0,并安装cuda11.4、cudnn 8.0.5实现训练加速。
训练阶段的实验参数设置如下:使用SGD 优化器对损失函数进行优化,初始学习率为0.01,在学习率更新过程中采用余弦退火算法,直至最终学习率衰减到0.002,权重衰减系数为0.000 5,前3 个epoch进行warm-up,初始化动量参数为0.8,批次大小为8,训练500 个epoch。使用迁移学习的方式通过加载YOLOv5l.pt 权重文件进行预训练加快网络的学习,使网络训练的效果更好。
3 实验结果与分析
3.1 评价指标
本文使用精度、召回率以及平均精度均值(mean Average Precision,mAP)来评价道路表面病害的识别性能。其中:精度用于反映对道路表面病害预测的准确性,表示为分类器确定的正样本中真实正样本所占的比例;召回率用于反映对道路表面病害是否全部发现,表示为正确判定的正样本在总正样本中所占的比例。精度和召回率的计算公式如式(12)和式(13)所示:

其中:TP表示正确被划分为正样本的个数(真阳性);FP表示错误被划分为正样本的个数(假阳性);FN表示错误被划分为负样本的个数(假阴性);TN表示正确被划分为负样本的个数(真阴性)。
mAP 在目标决策中是衡量检测精度的指标。通过P-R(Precision-Recall)曲线积分计算每种类别的平均精度然后求平均,即得到mAP,计算公式如式(14)所示:

3.2 消融实验分析
为验证本文的改进模型对路面病害检测的影响,对各模块进行评估。使用路面病害数据集Crack_HW 进行训练后在测试集上的实验结果如表2 所示,其中,“√”表示添加相应的方法,YOLOv5l为原始模型。
对表2 所示数据的具体分析如下:
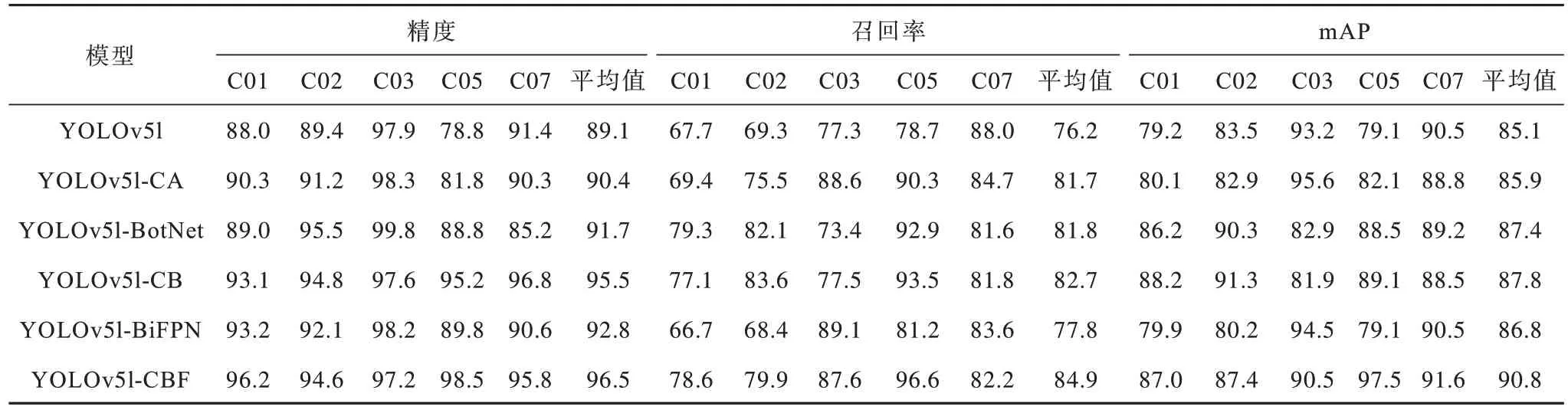
表2 YOLOv5 模型改进前后评价指标对比 Table 2 Comparison of evaluation indexes of YOLOv5 model before and after improvement %
1)YOLOv5l-CA 模型为在主干网络中加入坐标注意力机制的模型。可以看出,注意力机制的嵌入使模型在路面病害检测的精度和召回率上较原始模型分别提升了1.3 和5.5 个百分点。这主要是因为原始模型对病害纹理特征的提取不够明显,难以学习到病害的多种特征,从而造成漏检或误检。添加坐标注意力后的模型对路面病害特征提取更加明确,模型在训练的过程中更加关注图像中病害的特征和位置,这使得检测性能有了进一步的提升,模型对病害检测的平均mAP 达到85.9%。
2)YOLOv5l-BotNet 模型为在主干网络深层部分引入多头自注意力构建CTR3 结构的模型。实验结果显示,模型在测试集上的精度、召回率和mAP较原始模型分别提升了2.6、5.6 和2.3 个百分点。其中,对于坑槽类病害(C05)的检测无论是精度还是召回率都提升了近10 个百分点。这是因为引入MHSA 后的C3 结构具有更强的捕获全局上下文信息的能力,能够更好地帮助模型建立病害和图像背景之间差异性的关系。
3)YOLOv5l-CB 模型为在主干网络中引入坐标注意力机制和Transformer 自注意力结构的模型。实验结果显示,模型的精度、召回率和mAP 较原始模型都有所提升,其中mAP 提升了2.7 个百分点。这说明改进后的主干网络通过添加注意力机制提升了对病害纹理特征的提取能力和对全局依赖关系的捕捉能力。
4)YOLOv5l-BiFPN 模型为在颈部网络采用双向加权特征金字塔网络加强网络特征融合能力的模型。实验结果显示,模型对病害检测与分类的精度较原始模型提升了3.7 个百分点,但是召回率提升并不明显,只提升了1.6 个百分点。这是因为主干网络已经提取到路面病害的各种纹理特征,而BiFPN 主要负责对学习到的纹理特征进行融合,如遇到新的病害纹理,模型难以识别从而造成漏检或误检。
5)YOLOv5l-CBF 模型为采用本文改进方法的组合模型:首先对先验框进行优化后在主干网络添加坐标注意力机制以及多头自注意力机制,加强对病害纹理特征的提取;然后在颈部网络构建BiFPN对提取到的纹理特征做进一步的融合。实验结果显示,模型的精度、召回率较原始模型分别提升了7.4和8.7 个百分点,mAP 达到90.8%,实现了对5 种病害类型高精度的自动化检测。
本文模型在Crack_HW 测试集上检测的P-R 曲线如图9 所示,括号中数据表示mAP@0.5 指标。可以看出,本文模型对龟裂(C03)、坑槽(C05)、修补(C07)这3 种病害类型的识别效果较好,但是对于横向裂缝(C01)、纵向裂缝(C02)的检测精度不到90%,主要是因为这2 种裂缝类型的纹理特征多样,模型在学习的过程中不能很好地学习到丰富的特征表现形式。

图9 P-R 曲线Fig.9 P-R curve
3.3 实验对比分析
为进一步评价模型性能,对YOLOv5l-CBF 模型与常见的目标检测模型在道路病害数据集Crack_HW 上训练后的实验结果进行比较,如表3 上半部分所示。同时,为验证YOLOv5l-CBF 模型在不同数据集上的检测效果,使用IEEE 大数据挑战赛提供的公共道路裂缝数据集RDD-2020 和本文路面病害数据集Crack_HW,对YOLOv5l-CBF 模型与主流路面病害检测模型训练后的实验结果进行比较,如表3 下半部分和图10 所示。

表3 不同模型的检测性能 Table 3 Comparison of detection performance of different models

图10 不同模型的检测结果Fig.10 Detection results of different models
4 结束语
为应对高速路面病害检测任务的挑战,本文针对YOLOv5l 模型扩展并优化其网络结构。通过在原YOLOv5l 主干网络中加入坐标注意力机制剔除无效的冗余特征,留下对目标分类与定位更加有利的特征信息;引入Transformer 自注意力改进网络的残差结构,提高模型对于全局图像特征块之间依赖关系的捕捉能力;同时优化原YOLOv5l 颈部网络结构,构建双向加权特征融合网络,提高模型的多尺度特征融合能力。在实验过程中,本文实现了一个高质量路面病害数据集Crack_HW 并引入迁移学习的方式,有效地提高了网络模型的检测精度。虽然本文模型较原始模型在精度上有较大提升,但不能满足网络轻量化的要求。下一步将在保证准确率的情况下使用深度可分离卷积对模型进行轻量化改造,同时实现高精度与高速率检测。
猜你喜欢
今日农业(2022年3期)2022-06-05
小雪花·成长指南(2022年1期)2022-04-09
今日农业(2021年8期)2021-11-28
北京航空航天大学学报(2021年9期)2021-11-02
烟台果树(2021年2期)2021-07-21
今日农业(2020年19期)2020-11-06
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
